

Spry advanced master and detail region overview and structure
In some cases, you might want to create master and detail relationships that involve more than one data set. For example, you might have a list of menu items that has a great deal of detail information associated with it. (This section uses a list of ingredients to illustrate the point.) Fetching all of the information associated with every menu item in a single query might be an inefficient use of bandwidth not to mention unnecessary, given that many users might not even be interested in the details of everything on the menu. Instead, it is more efficient to download only the detail data that the user is interested in when the user requests it, thus improving performance and reducing bandwidth. Limiting the amount of data exchange in this way is a common technique used to improve performance in AJAX applications.
Following is the XML source code for a sample file called cafetownsend.xml:
<?xml version="1.0" encoding="UTF-8"?> <specials> <menu_item id="1"> <item>Summer Salad</item> <description>organic butter lettuce with apples, blood oranges, gorgonzola, and raspberry vinaigrette.</description> <price>7</price> <url>summersalad.xml</url> </menu_item> <menu_item id="2"> <item>Thai Noodle Salad</item> <description>lightly sauteed in sesame oil with baby bok choi, portobello mushrooms, and scallions.</description> <price>8</price> <url>thainoodles.xml</url> </menu_item> <menu_item id="3"> <item>Grilled Pacific Salmon</item> <description>served with new potatoes, diced beets, Italian parlsey, and lemon zest.</description> <price>16</price> <url>salmon.xml</url> </menu_item> </specials>
The cafetownsend.xml file supplies the data for the master data set. The url node of the cafetownsend.xml file points to a unique XML file (or URL) for each menu item. These unique XML files contain a list of ingredients for the corresponding menu items. The summersalad.xml file, for example, might look as follows:
<?xml version="1.0" encoding="iso-8859-1" ?> <item> <item_name>Summer salad</item_name> <ingredients> <ingredient> <name>butter lettuce</name> </ingredient> <ingredient> <name>Macintosh apples</name> </ingredient> <ingredient> <name>Blood oranges</name> </ingredient> <ingredient> <name>Gorgonzola cheese</name> </ingredient> <ingredient> <name>raspberries</name> </ingredient> <ingredient> <name>Extra virgin olive oil</name> </ingredient> <ingredient> <name>balsamic vinegar</name> </ingredient> <ingredient> <name>sugar</name> </ingredient> <ingredient> <name>salt</name> </ingredient> <ingredient> <name>pepper</name> </ingredient> <ingredient> <name>parsley</name> </ingredient> <ingredient> <name>basil</name> </ingredient> </ingredients> </item>
When you are familiar with the structure of your XML code, you can create two data sets to use to display data in master and detail dynamic regions. In the following example, a master dynamic region displays data from the dsSpecials data set, and a detail dynamic region displays data from the dsIngredients data set:
<head>
. . .
<script type="text/javascript" src="../includes/xpath.js"></script>
<script type="text/javascript" src="../includes/SpryData.js"></script>
<script type="text/javascript">
<!--Create two separate data sets-->
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
var dsIngredients = new Spry.Data.XMLDataSet("data/{dsSpecials::url}", "item/ingredients/ingredient");
</script>
</head>
. . .
<body>
<!--Create a master dynamic region-->
<div id="Specials_DIV" spry:region="dsSpecials">
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<!--User clicks to reset the current row in the data set-->
<tr spry:repeat="dsSpecials" spry:setrow=”dsSpecials”>
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
<!--Create the detail dynamic region-->
<div id="Specials_Detail_DIV" spry:region="dsIngredients">
<table id="Specials_Detail_Table">
<tr>
<th>Ingredients</th>
</tr>
<tr spry:repeat=”dsIngredients”>
<td>{name}</td>
</tr>
</table>
</div>
. . .
</body>
In the example, the third script block contains the statement that creates two data sets, one called dsSpecials and one called dsIngredients:
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
var dsIngredients = new Spry.Data.XMLDataSet("data/{dsSpecials::url}", "item/ingredients/ingredient");
The URL for the second data set, dsIngredients, contains a data reference ({dsSpecials::url}) to the first data set, dsSpecials. More specifically, it contains a data reference to the url column in the dsSpecials data set. When the URL or XPath argument in the constructor that creates a data set contains a reference to another data set, the data set being created automatically becomes an observer of the data set it’s referencing. The new data set depends on the original data set, and reloads its data or reapplies its XPath whenever the data or current row changes in the original data set.
The following example shows the observer relationships established between data sets and master and detail dynamic regions. In the preceding example, the dsIngredients data set (data set B) is an observer of the dsSpecials data set (data set A).
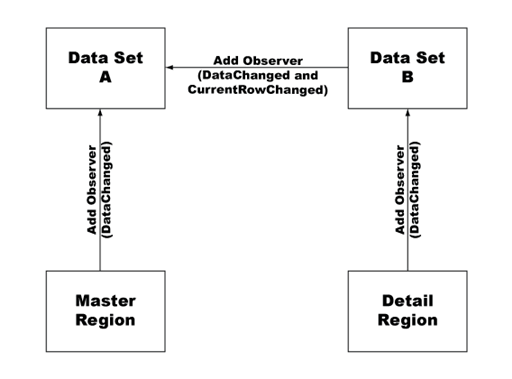
In the example, changing the current row in the dsSpecials data set sends a notification to the dsIngredients data set that it also needs to change. Because each row of the dsSpecials data set contains a distinct URL in the url column, the dsIngredients data set must update to include the correct URL for the selected row.
By default, the dsIngredients data set (whose data is displayed in the detail region) is created using the data it obtains from the URL specified in the constructor—in this case a reference to the data in the url column of the dsSpecials data set. The default current row in the dsSpecials data set (the first row) contains a unique path to the summersalad.xml file, and thus the detail region displays the information from that file when the page loads in a browser. When the current row of the dsSpecials data set changes, however, the URL also changes—to salmon.xml for example—and the dsIngredients data set (and by association, the detail dynamic region) updates accordingly.
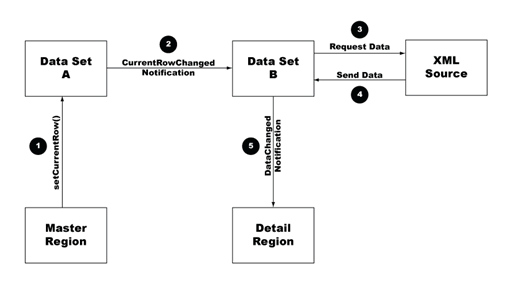
This process is functionally equivalent to the one illustrated in Spry basic master/detail region overview and structure, the technical difference being that in the advanced case, the second (or detail) data set is listening for data and row changes in the master data set, whereas in the basic example, the detail region is listening for data and row changes in the master data set.
In the example code, spry:region is used for the detail region instead of spry:detailregion. The difference between a spry:region and a spry:detailregion is that the spry:detailregion specifically listens for CurrentRowChange notifications (in addition to DataChanged notifications) from the data set, and updates itself when it receives one. Because the current row of the dsIngredients data set never changes (it’s the current row of the dsSpecials data set that changes), a spry:detailregion attribute is not needed. In this case, the spry:region attribute, which defines a region that only listens for DataChanged notifications, suffices.