From a one-line idea to a conference-ready paper — fully autonomous, zero human intervention.
|
**💡** **Idea** |
➜ |
**📚** **Literature** 300–470 papers |
➜ |
**🧪** **Hypothesis** experiment design |
➜ |
**💻** **Code** 2K–15K lines |
➜ |
**🔬** **Execute** sandbox + refine |
➜ |
**📝** **Write** review & audit |
➜ |
**📄** **Paper** NeurIPS PDF |
Each run traverses 23 autonomous stages with iterative self-healing, multi-agent peer review, and citation verification — no human in the loop.
---Generated on Machine A · 4 papers across 4 non-ML domains
--- ### 📄 Paper I · Random Matrix Theory

👆 Click to read the full paper |
#### 💡 Idea
Systematically quantify pre-asymptotic, finite-*N* deviations of empirical eigenvalue densities from the Marchenko–Pastur law across *N* = 50 to 5,000, decomposing error into bulk vs. edge components and testing lightweight correction models.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 473 papers collected → 26 cited |
| 💻 **Code** | 10,290 lines of Python |
| ⏱️ **Runtime** | ~2 h 25 min |
| 📊 **Figures** | 5 auto-generated charts |
| 📑 **Pages** | 16 pages (NeurIPS format) |
#### 🎯 Key Result
Produced a finite-*N* correction atlas showing convergence rates of spectral densities, with edge deviations persisting significantly longer than bulk errors — providing practical guidance for when the MP law is "close enough."
|
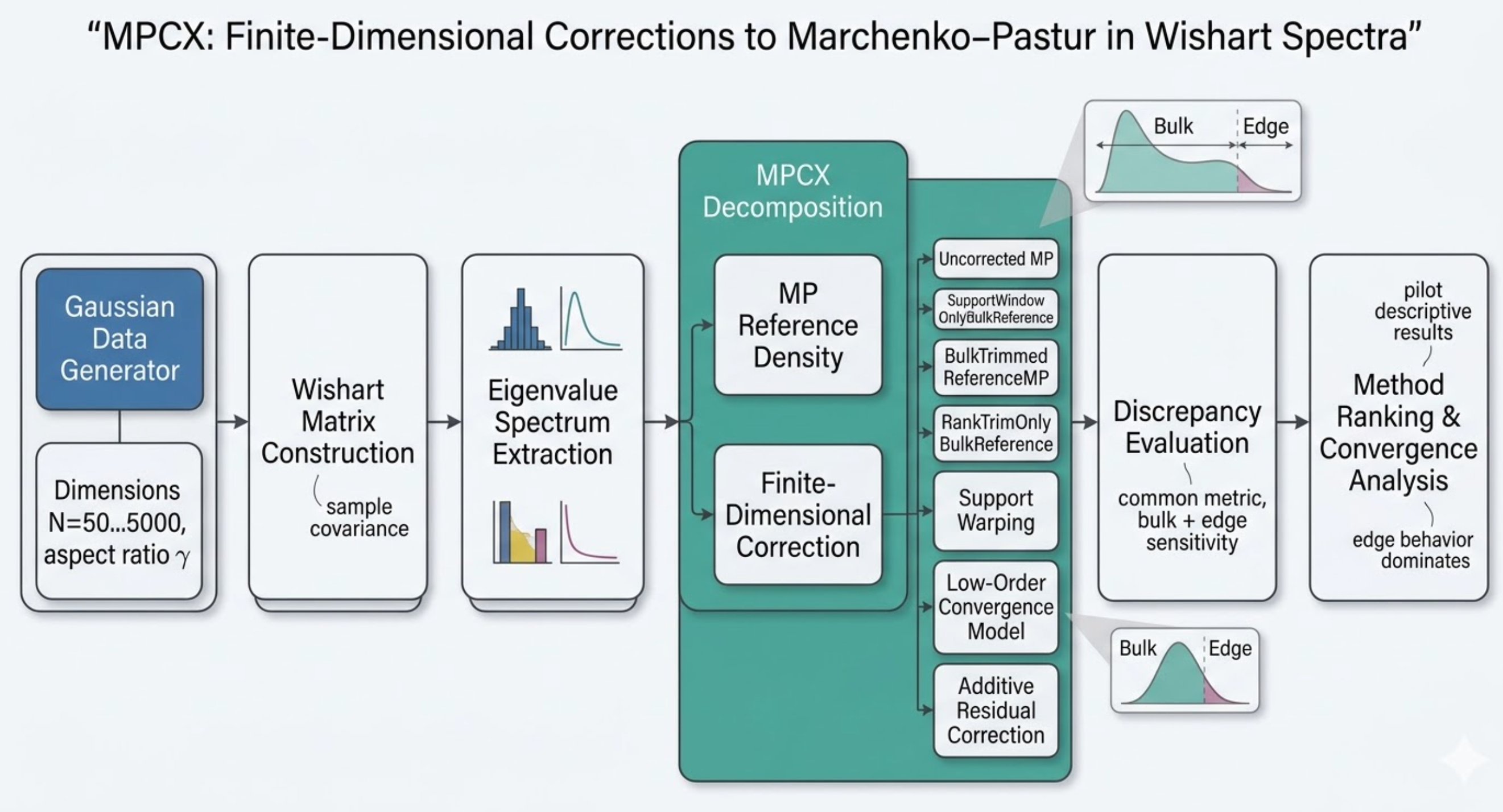
Finite-dimensional correction pipeline: Wishart matrix generation → empirical spectral density estimation → MP baseline comparison → bulk/edge error decomposition → correction model fitting. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Reframe the classical 2SLS / LIML / Fuller-*k* / JIVE comparison around decision-relevant *risk surfaces*, mapping finite-sample phase diagrams that show where each estimator is preferred under realistic weak-IV conditions.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 366 papers collected → 41 cited |
| 💻 **Code** | 10,062 lines of Python |
| ⏱️ **Runtime** | ~2 h 56 min |
| 📊 **Figures** | 6 auto-generated charts |
| 📑 **Pages** | 14 pages (NeurIPS format) |
#### 🎯 Key Result
Generated estimator-switching phase diagrams revealing that Fuller-*k* dominates in specific small-*n*, many-instrument regions, while JIVE's bias reduction is systematically offset by variance inflation — providing actionable guidance for empirical researchers.
|
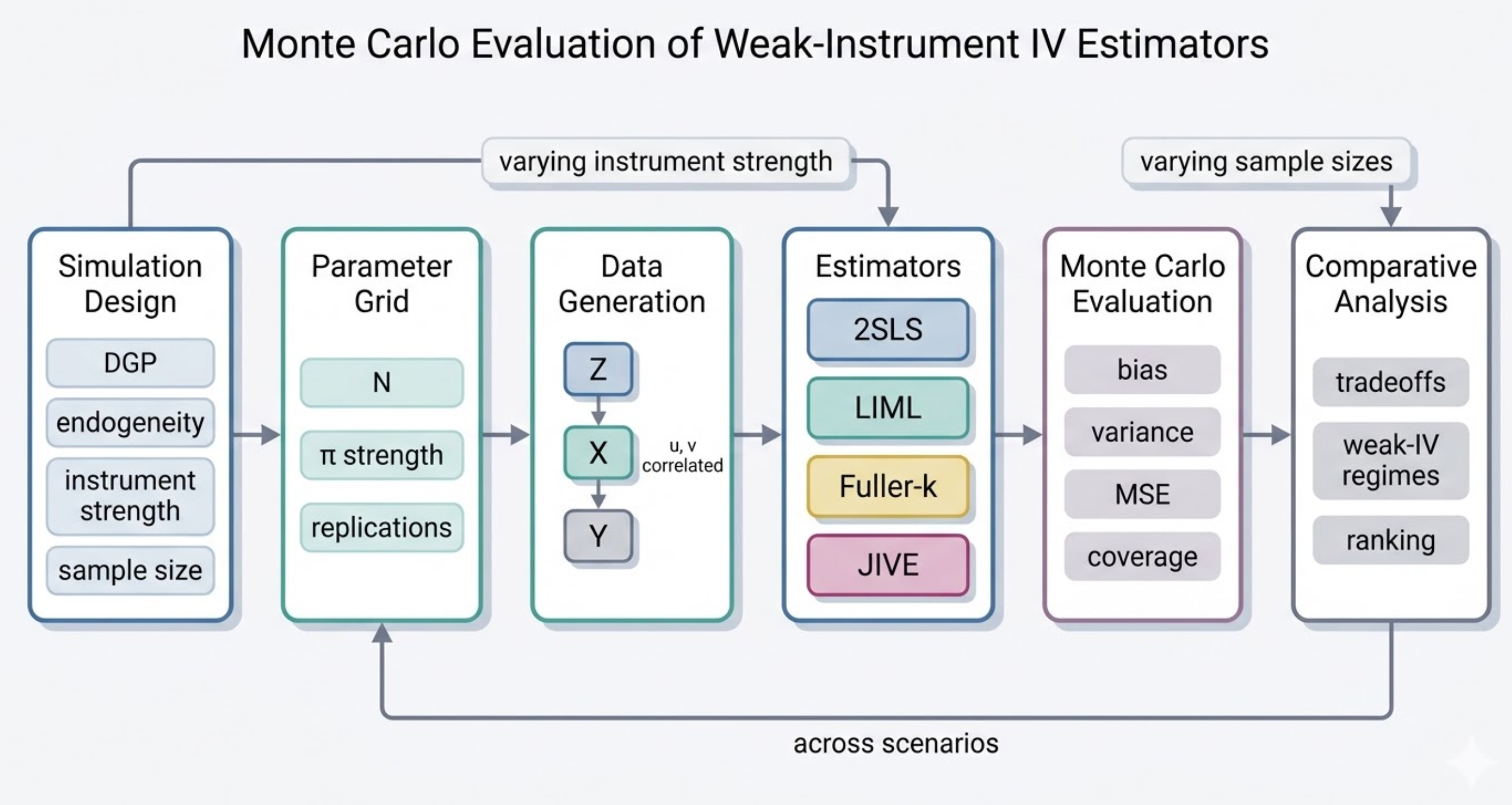
Monte Carlo IV evaluation pipeline: DGP specification → estimator suite (2SLS, LIML, Fuller-k, JIVE) → finite-sample risk surfaces → phase diagram construction. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Map the boundary between structural and practical identifiability in SIR vs. SEIR models across realistic observation regimes, and quantify when Fisher Information Matrix gives false confidence relative to profile likelihood.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 388 papers collected → 29 cited |
| 💻 **Code** | 9,374 lines of Python |
| ⏱️ **Runtime** | ~2 h 23 min |
| 📊 **Figures** | 6 auto-generated charts |
| 📑 **Pages** | 18 pages (NeurIPS format) |
#### 🎯 Key Result
Demonstrated that parameterization and observer design choices affect identifiability diagnostics more strongly than the choice between SIR and SEIR structure — with FIM producing overconfident estimates in specific observation-limited regimes where profile likelihood correctly flags non-identifiability.
|
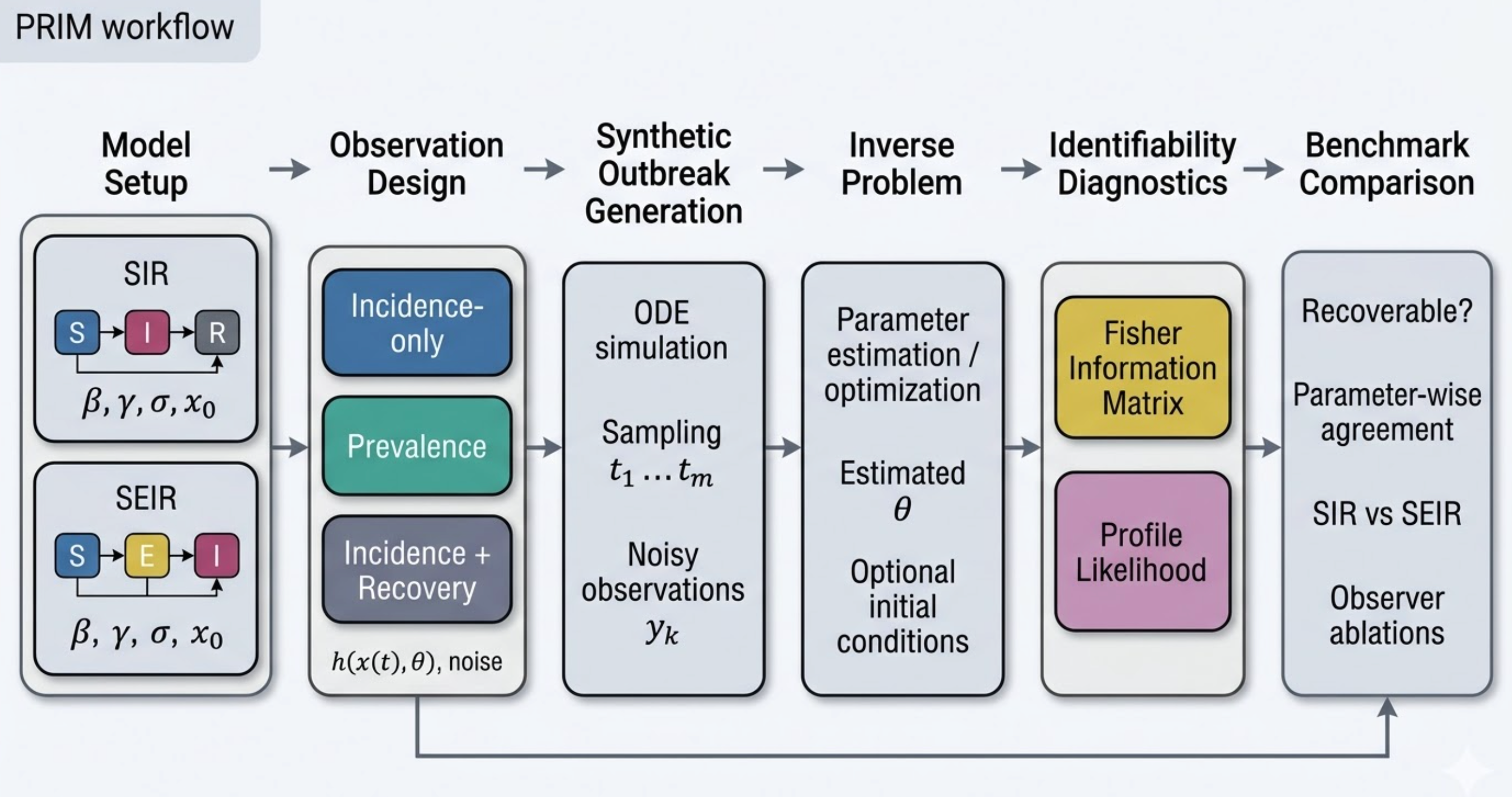
PRIM benchmark workflow: synthetic outbreak generation (SIR/SEIR) → parameter estimation → profile likelihood vs. FIM diagnostics → identifiability regime mapping. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Go beyond "which preconditioner wins" — build a feature-conditioned decision map for ILU / Jacobi / SSOR / AMG with CG / GMRES / BiCGSTAB, stratified by sparsity-graph structure and matrix pathology under realistic setup-vs-solve cost budgets.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 320 papers collected → 33 cited |
| 💻 **Code** | 14,557 lines of Python |
| ⏱️ **Runtime** | ~2 h 30 min |
| 📊 **Figures** | 4 auto-generated charts |
| 📑 **Pages** | 16 pages (NeurIPS format) |
#### 🎯 Key Result
Produced a setup-vs-solve tradeoff analysis showing that methods considered "best" under solve-time alone are often suboptimal under realistic memory and setup budgets — with AMG dominance limited to specific elliptic SPD matrix families.
|
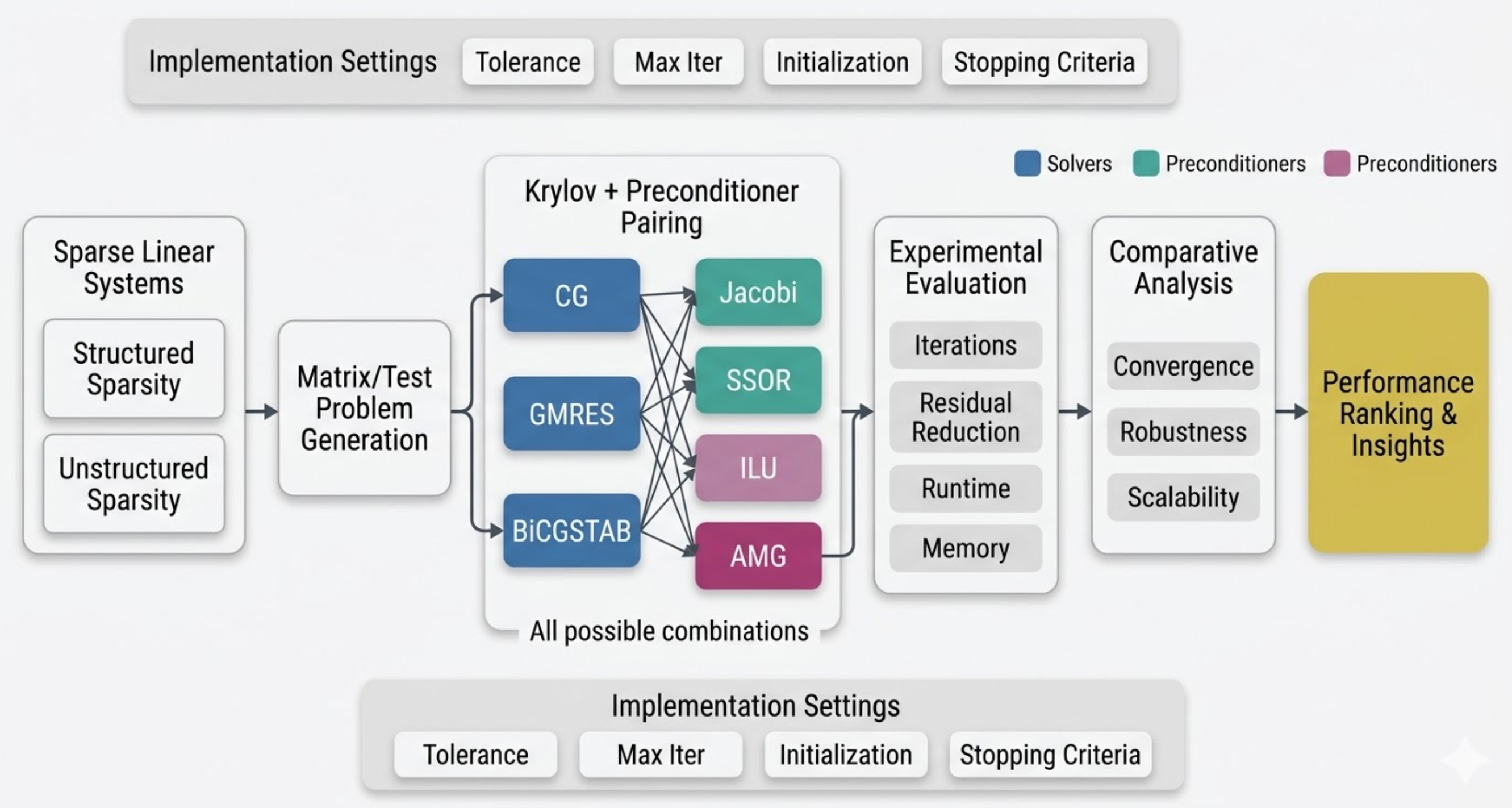
Feature-conditioned preconditioner evaluation: sparse matrix collection → structural descriptor extraction → solver–preconditioner grid (CG/GMRES/BiCGSTAB × ILU/Jacobi/SSOR/AMG) → setup-vs-solve tradeoff analysis → decision map. Entirely auto-generated by the FigureAgent subsystem.
Generated on Machine B · NVIDIA RTX 6000 Ada (48 GB) · 4 papers across 4 ML sub-fields
--- ### 📄 Paper V · Parameter-Efficient Fine-Tuning

👆 Click to read the full paper |
#### 💡 Idea
Most LoRA configurations use a fixed, uniform rank across all layers. GARD proposes using the *spectrum of layer-wise gradients* — eigenvalues of gradient covariance — to dynamically allocate rank where it matters most, under a strict parameter budget.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 60 references cited (100% verified) |
| 💻 **Code** | 2,894 lines of Python (5 files) |
| ⏱️ **Runtime** | ~50 min |
| 📊 **Figures** | 7 auto-generated charts |
| 📑 **Pages** | 17 pages (NeurIPS format) |
#### 🎯 Key Contribution
A principled alternative to uniform rank allocation: GARD links intrinsic gradient dimensionality to low-rank adapter capacity, periodically updating ranks during training using smoothed spectra.
|
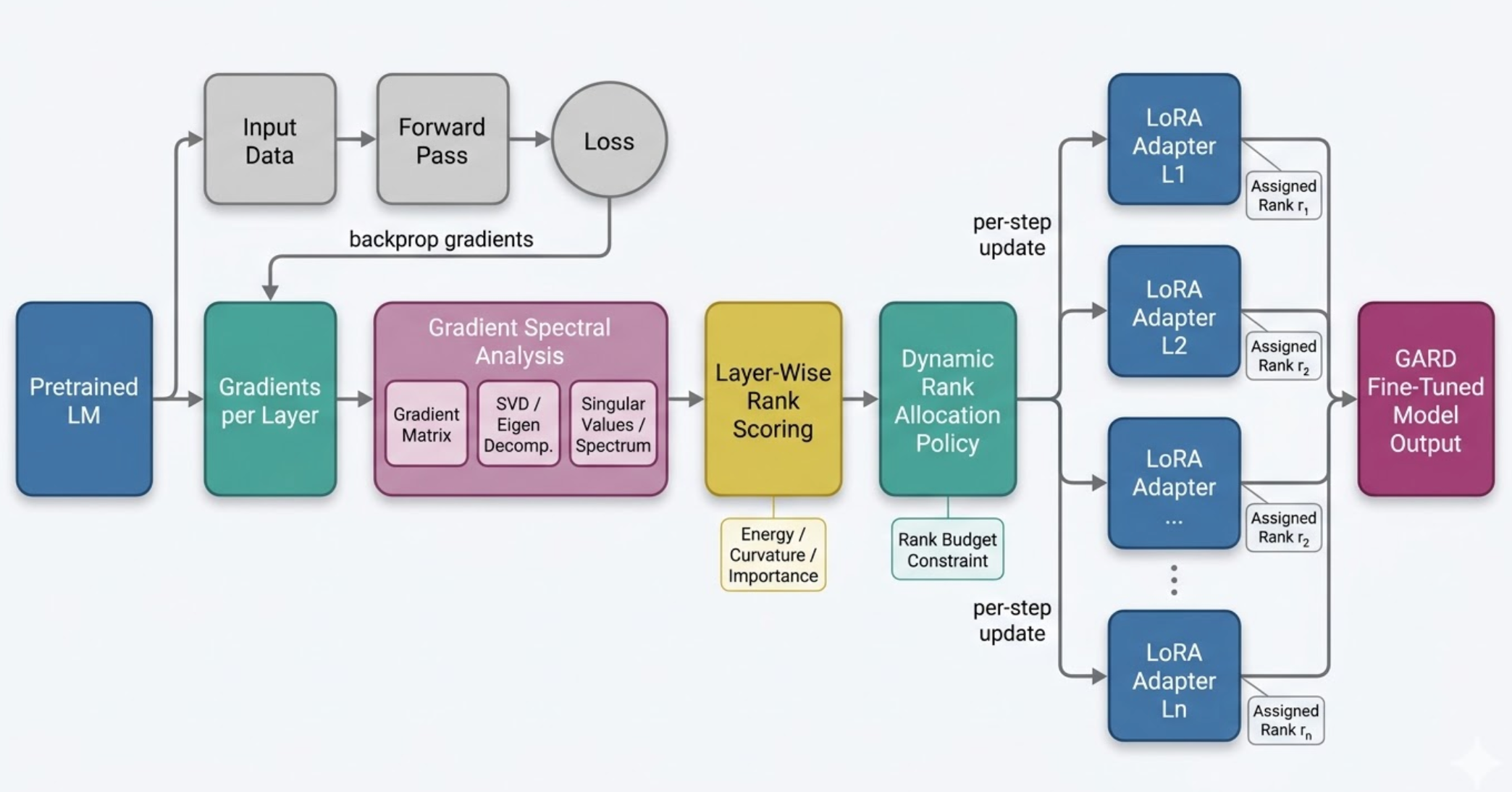
Gradient spectral analysis → layer-wise rank scoring → dynamic rank allocation under budget constraint. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Count-based exploration in RL relies on state visitation counts, but raw state spaces are too large for effective counting. LACE designs *online-learned, task-aware state abstractions* optimized specifically for count-based exploration in sparse-reward environments.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 25 references cited (100% verified) |
| 💻 **Code** | 2,067 lines of Python (4 files) |
| 🐳 **Experiment** | 32 min GPU sandbox execution |
| ⏱️ **Runtime** | ~6.8 hrs total |
| 📊 **Figures** | 6 auto-generated charts |
| 📑 **Pages** | 11 pages (NeurIPS format) |
#### 🎯 Key Result
DQN baseline achieves **356.7 mean reward** in sparse-reward gridworld tasks. The paper analyzes the trade-off between abstraction compactness for counting and information sufficiency for downstream control.
|
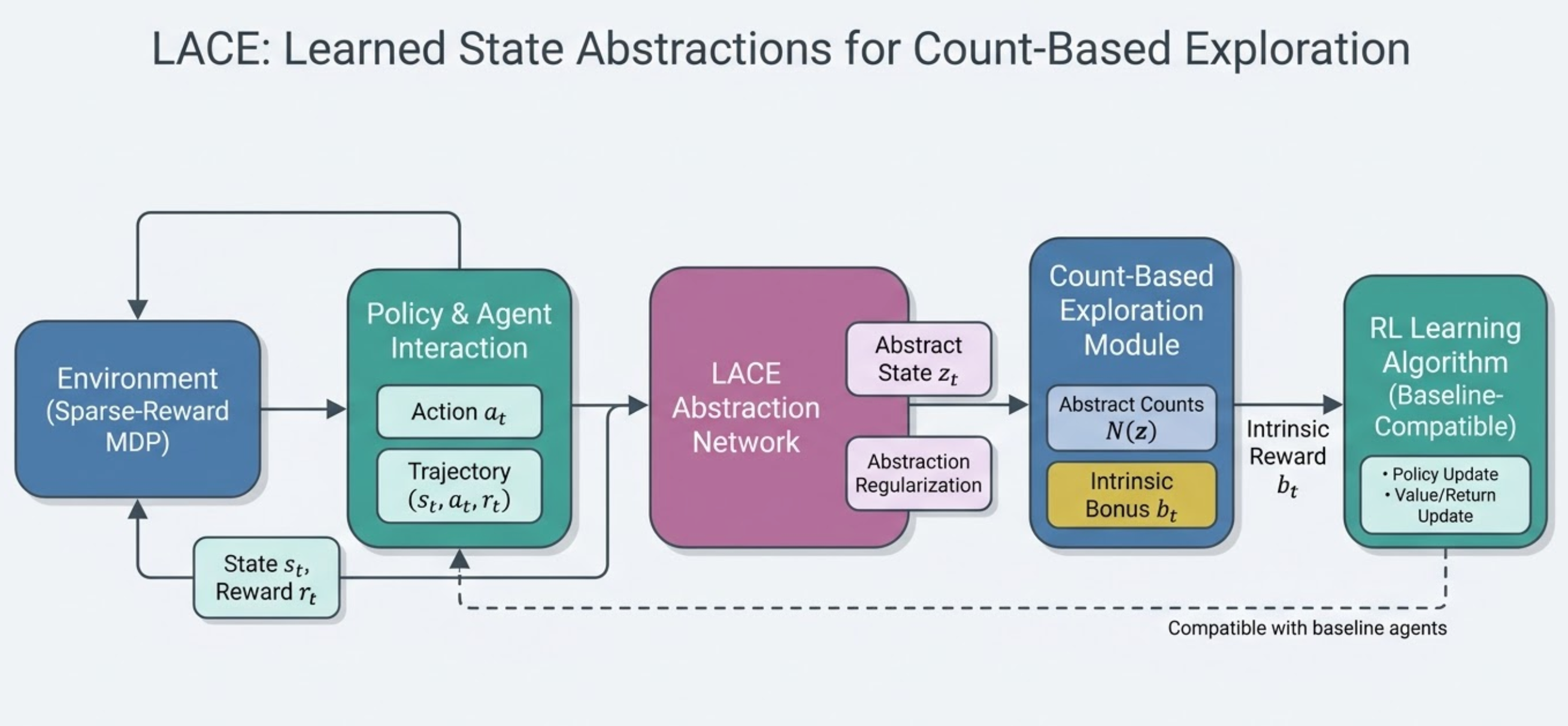
Learned state abstraction module integrated with count-based exploration in the DQN agent loop. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Existing ViT token pruning methods reduce tokens based on attention or saliency without considering *frequency content*. FAME uses DCT/FFT-based spectral filters to distinguish high-frequency detail tokens from low-frequency background tokens, merging progressively across layers.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 40 references cited (100% verified) |
| 💻 **Code** | 2,873 lines of Python (5 files) |
| 🐳 **Experiment** | 32 min GPU sandbox execution |
| ⏱️ **Runtime** | ~3.3 hrs total |
| 📊 **Figures** | 7 auto-generated charts |
| 📑 **Pages** | 10 pages (NeurIPS format) |
#### 🎯 Key Result
ViT-B/16 baseline: **56.54% accuracy** (3 seeds). Detailed analysis of the accuracy-efficiency tradeoff and per-layer metric breakdowns for frequency-aware vs. similarity-based merging.
|
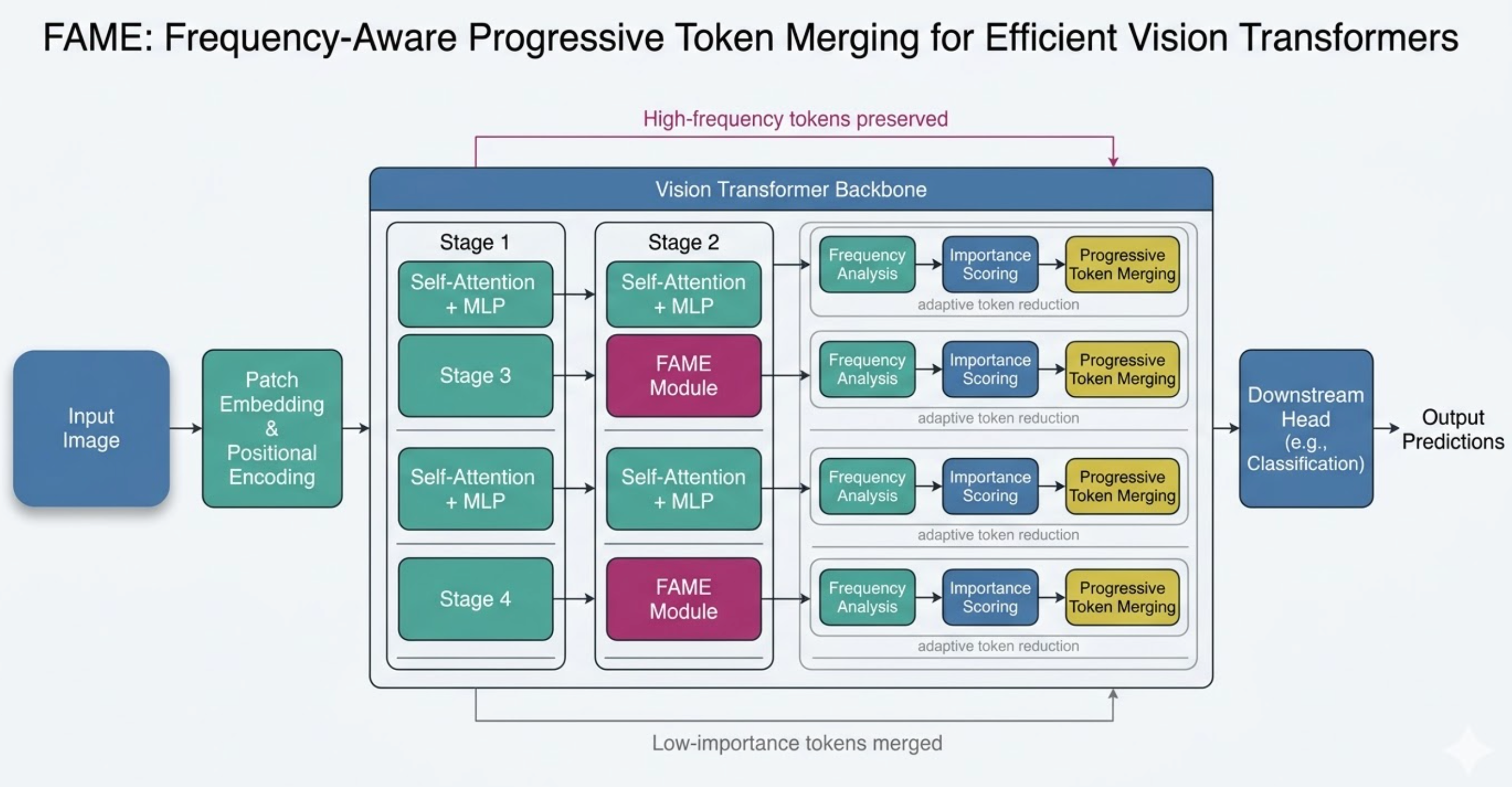
Frequency-aware token merging applied progressively across ViT layers with DCT-based spectral filtering. Entirely auto-generated by the FigureAgent subsystem.

👆 Click to read the full paper |
#### 💡 Idea
Standard knowledge distillation transfers teacher knowledge assuming train/test distributions match. CRAFT introduces *reliability-aware contrastive feature alignment* that aligns teacher-student features across clean and corrupted views, while suppressing fragile teacher directions via a de-alignment loss.
#### ⚙️ Pipeline Journey
| | |
|:---|:---|
| 🔗 **Stages** | 23 stages + 2 refinement iterations |
| 📚 **Literature** | 37 references cited (97% verified) |
| 💻 **Code** | 2,231 lines of Python (4 files) |
| 🐳 **Experiment** | 33 min GPU sandbox execution |
| ⏱️ **Runtime** | ~5.8 hrs total |
| 📊 **Figures** | 9 auto-generated charts |
| 📑 **Pages** | 19 pages (NeurIPS format) |
#### 🎯 Key Result
| Method | Clean Acc | Robust Acc |
|:---|:---:|:---:|
| ERM (baseline) | 81.22% | 62.96% |
| LogitKD | 82.33% | 64.68% |
| **AttentionKD** | **82.08%** | **65.95%** |
| CRD | 68.03% | 50.57% |
Attention-based feature KD improves robustness by **+3 pts** over ERM, while naive CRD degrades it by **-12 pts** — motivating CRAFT's reliability-aware design.
|
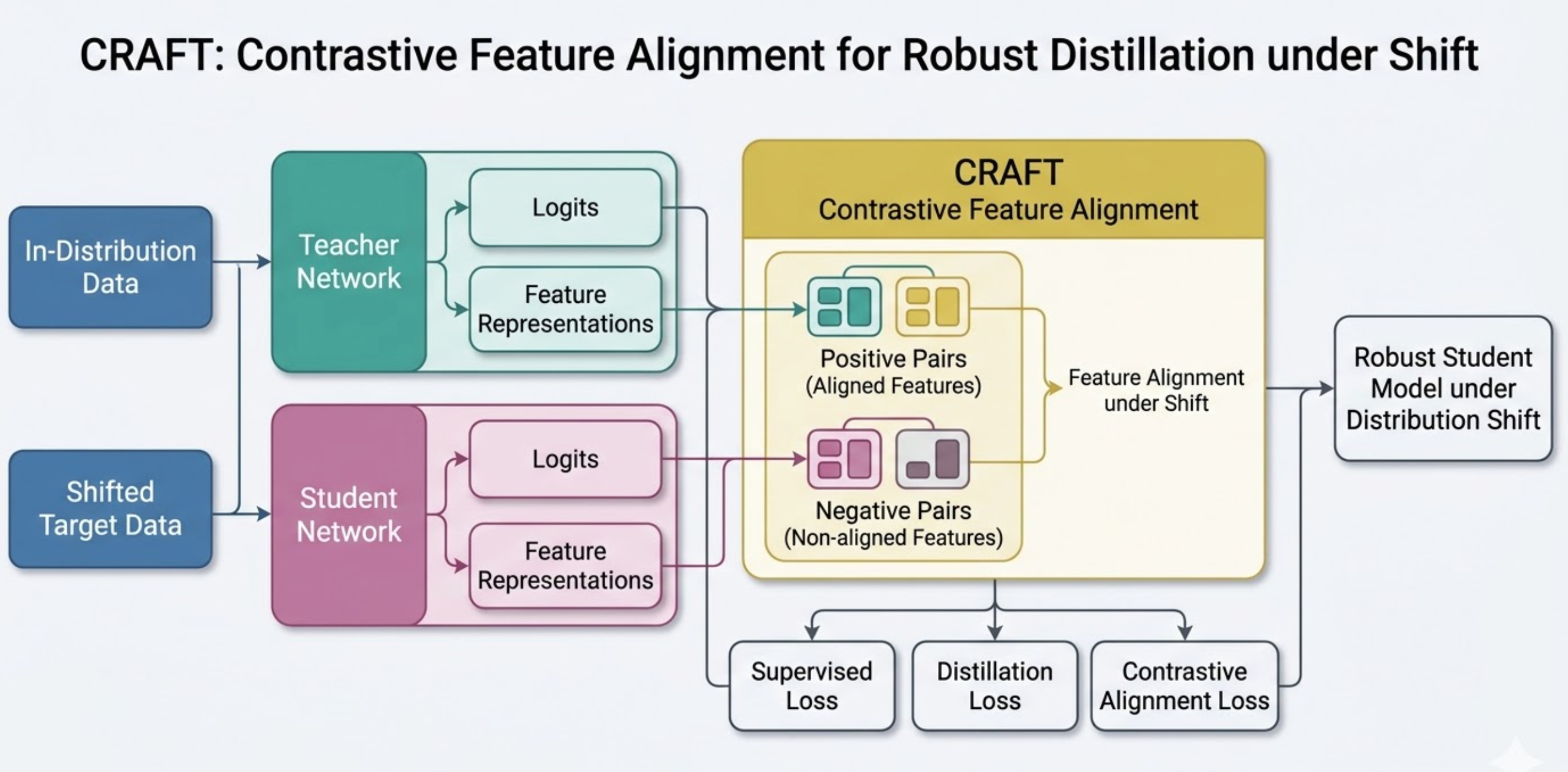
Reliability-aware contrastive feature alignment between teacher and student across clean and corrupted views, with de-alignment on fragile teacher directions. Entirely auto-generated by the FigureAgent subsystem.
| 📋 Metric | I | II | III | IV | V | VI | VII | VIII | 🏆 Total |
|---|---|---|---|---|---|---|---|---|---|
| 🏷️ Domain | Math | Stats | Bio | NumLA | NLP | RL | CV | KD | 8 fields |
| 💻 Code (LOC) | 10,290 | 10,062 | 9,374 | 14,557 | 2,894 | 2,067 | 2,873 | 2,231 | 54,348 |
| ⏱️ Pipeline Time | 2h25m | 2h56m | 2h23m | 2h30m | 50m | 6h48m | 3h18m | 5h48m | ~27 hrs |
| 🔗 References | 26 | 41 | 29 | 33 | 60 | 25 | 40 | 37 | 291 cited |
| 📊 Figures | 5 | 6 | 6 | 4 | 7 | 6 | 7 | 9 | 50 figs |
| 📑 Pages | 16 | 14 | 18 | 16 | 17 | 11 | 10 | 19 | 121 pages |
Every paper above was generated by a single command:
```bash researchclaw run --topic "Your research idea here" --auto-approve ```