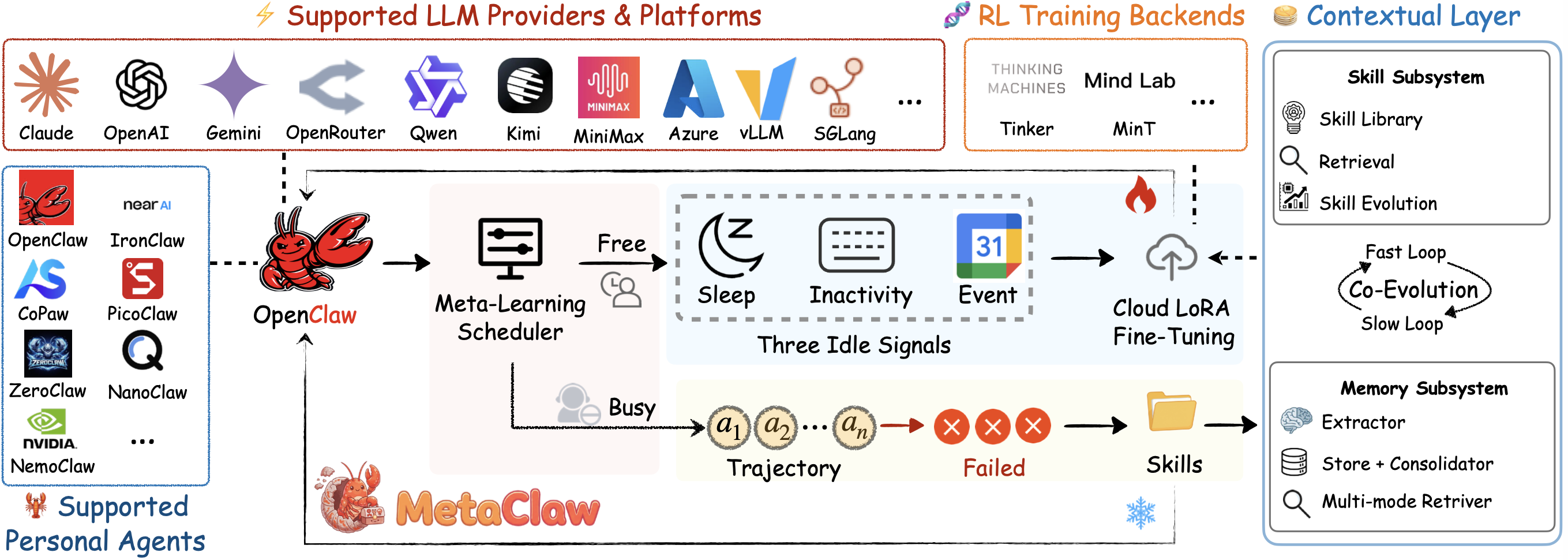
# Sprich einfach mit deinem Agenten — er lernt und *ENTWICKELT* sich weiter.
Inspiriert davon, wie das Gehirn lernt. Meta-lernen und entwickeln Sie Ihren 🦞 aus jedem Gespräch. Keine GPU nötig. Kompatibel mit Kimi, Qwen, Claude, MiniMax und mehr.
[🇺🇸 English](../README.md) • [🇨🇳 中文](./README_ZH.md) • [🇯🇵 日本語](./README_JA.md) • [🇰🇷 한국어](./README_KO.md) • [🇫🇷 Français](./README_FR.md) • [🇪🇸 Español](./README_ES.md) • [🇧🇷 Português](./README_PT.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇦🇪 العربية](./README_AR.md) • [🇮🇳 हिन्दी](./README_HI.md)
[Übersicht](#-übersicht) • [Schnellstart](#-schnellstart) • [Konfiguration](#️-konfiguration) • [Skills-Modus](#-skills-modus) • [RL-Modus](#-rl-modus) • [MadMax-Modus](#-madmax-modus-standard) • [Zitierung](#-zitierung)
