# Habla con tu agente — aprende y *EVOLUCIONA*.
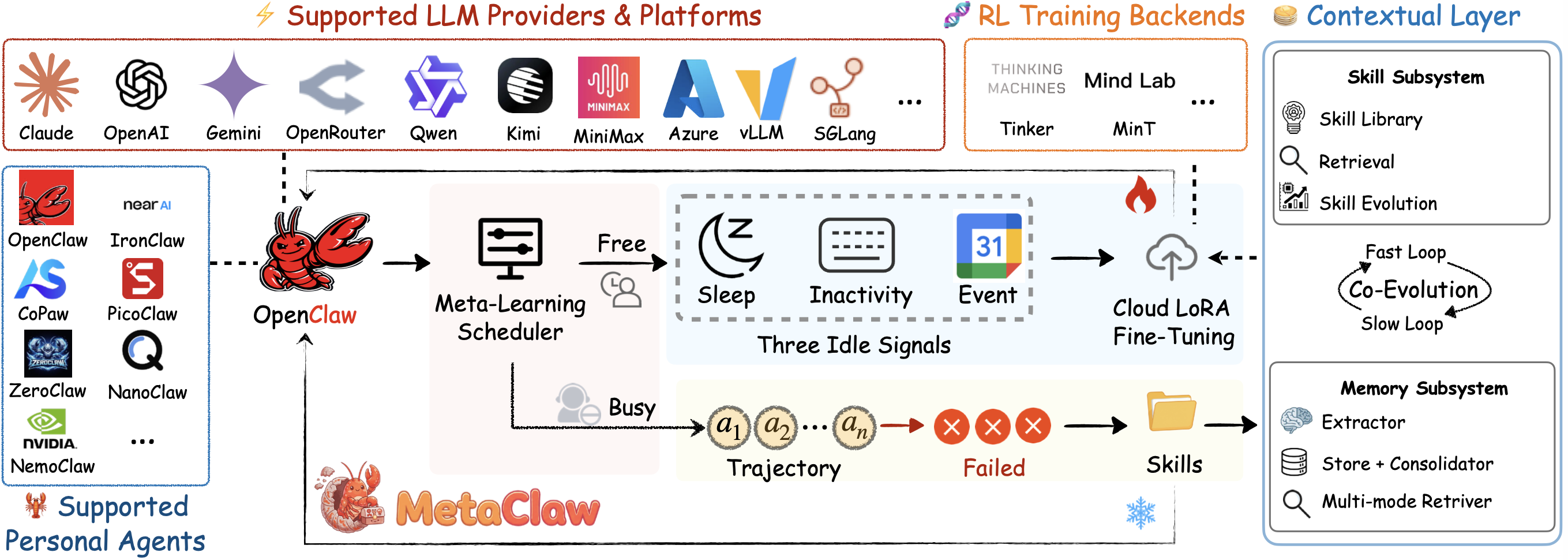
Inspirado en cómo aprende el cerebro. Meta-aprende y evoluciona tu 🦞 con cada conversación. Sin GPU. Compatible con Kimi, Qwen, Claude, MiniMax y más.
[🇺🇸 English](../README.md) • [🇨🇳 中文](./README_ZH.md) • [🇯🇵 日本語](./README_JA.md) • [🇰🇷 한국어](./README_KO.md) • [🇫🇷 Français](./README_FR.md) • [🇩🇪 Deutsch](./README_DE.md) • [🇧🇷 Português](./README_PT.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇦🇪 العربية](./README_AR.md) • [🇮🇳 हिन्दी](./README_HI.md)
[Descripcion](#-descripción) • [Inicio rapido](#-inicio-rápido) • [Configuracion](#️-configuración) • [Modo Skills](#-modo-skills) • [Modo RL](#-modo-rl) • [Modo MadMax](#-modo-madmax-por-defecto) • [Cita](#-cita)
