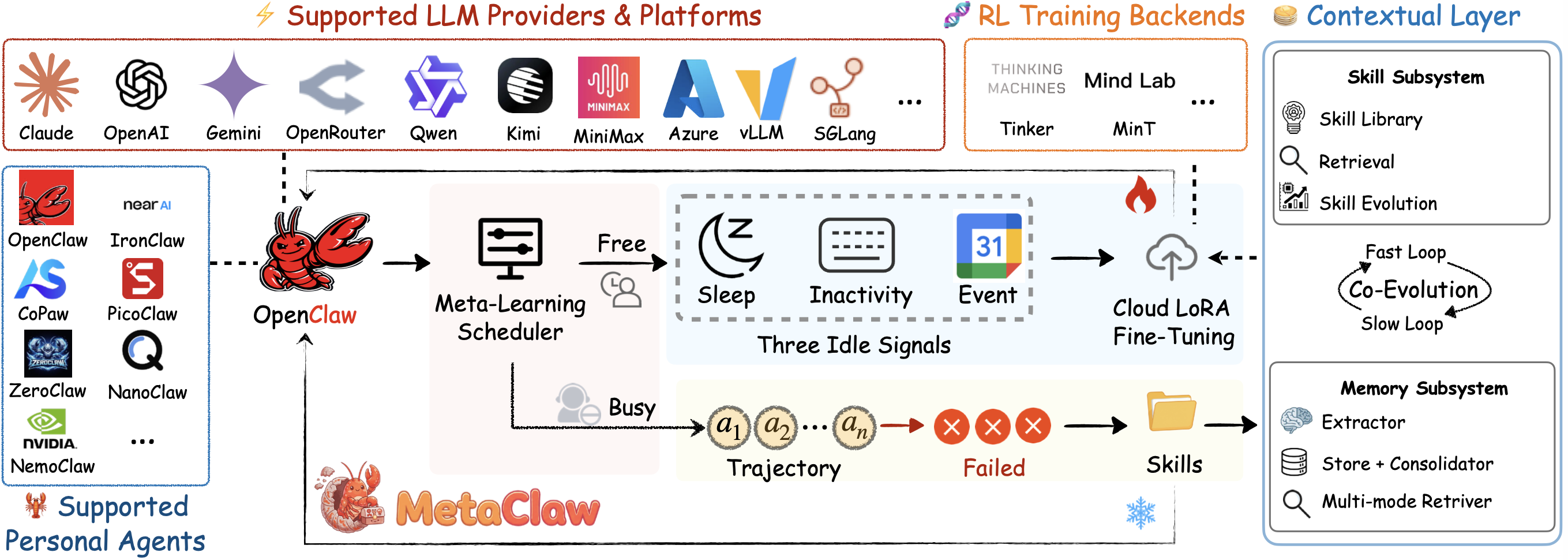
# बस अपने Agent से बात करें, यह सीखता रहेगा और *विकसित* होता रहेगा।
मस्तिष्क की सीखने की प्रक्रिया से प्रेरित। अपने 🦞 को वास्तविक बातचीत में मेटा-लर्निंग और विकास करने दें। GPU की आवश्यकता नहीं। Kimi, Qwen, Claude, MiniMax आदि के साथ काम करता है।
[🇺🇸 English](../README.md) • [🇨🇳 中文](./README_ZH.md) • [🇯🇵 日本語](./README_JA.md) • [🇰🇷 한국어](./README_KO.md) • [🇫🇷 Français](./README_FR.md) • [🇩🇪 Deutsch](./README_DE.md) • [🇪🇸 Español](./README_ES.md) • [🇵🇹 Português](./README_PT.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇸🇦 العربية](./README_AR.md)
[अवलोकन](#-अवलोकन) • [त्वरित शुरुआत](#-त्वरित-शुरुआत) • [कॉन्फ़िगरेशन](#️-कॉन्फ़िगरेशन) • [Skills मोड](#-skills-मोड) • [RL मोड](#-rl-मोड) • [MadMax मोड](#-madmax-मोड-डिफ़ॉल्ट) • [उद्धरण](#-उद्धरण)
