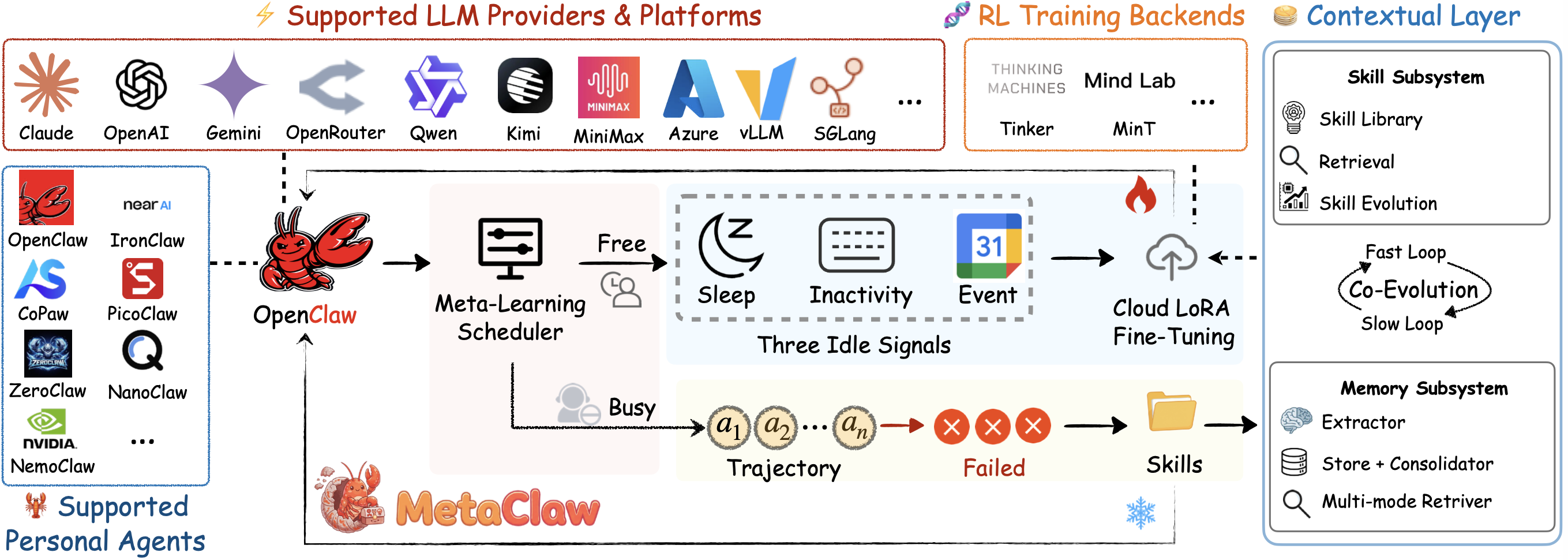
# 에이전트와 대화하기만 하면 됩니다, 학습하고 *진화*합니다.
뇌의 학습 방식에서 영감을 받았습니다. 모든 대화에서 🦞 를 메타학습하고 진화시킵니다. GPU 불필요. Kimi, Qwen, Claude, MiniMax 등 지원.
[🇺🇸 English](../README.md) • [🇨🇳 中文](./README_ZH.md) • [🇯🇵 日本語](./README_JA.md) • [🇫🇷 Français](./README_FR.md) • [🇩🇪 Deutsch](./README_DE.md) • [🇪🇸 Español](./README_ES.md) • [🇧🇷 Português](./README_PT.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇦🇪 العربية](./README_AR.md) • [🇮🇳 हिन्दी](./README_HI.md)
[개요](#-개요) • [빠른 시작](#-빠른-시작) • [설정](#️-설정) • [스킬 모드](#-스킬-모드) • [RL 모드](#-rl-모드) • [MadMax 모드](#-madmax-모드-기본) • [인용](#-인용)
