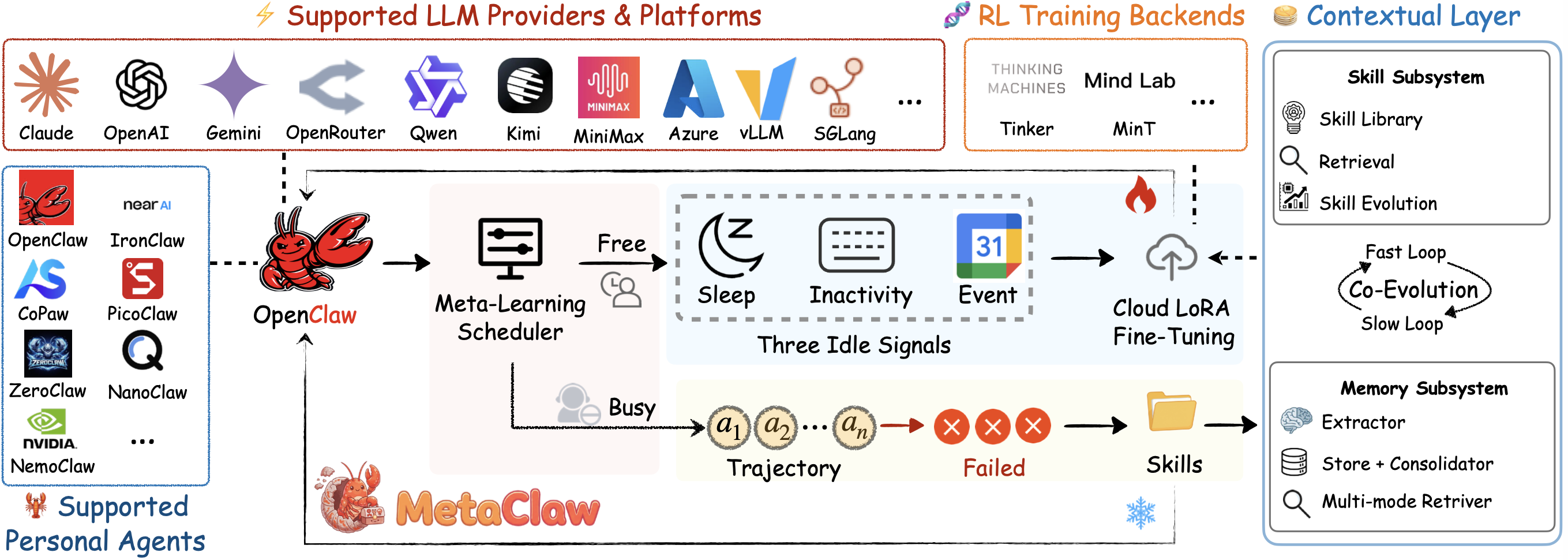
# Apenas converse com seu agente, ele aprende e *EVOLUI*.
Inspirado em como o cerebro aprende. Meta-aprenda e evolua seu 🦞 a partir de cada conversa real. Sem necessidade de GPU. Compativel com Kimi, Qwen, Claude, MiniMax e mais.
[🇺🇸 English](../README.md) • [🇨🇳 中文](./README_ZH.md) • [🇯🇵 日本語](./README_JA.md) • [🇰🇷 한국어](./README_KO.md) • [🇫🇷 Français](./README_FR.md) • [🇩🇪 Deutsch](./README_DE.md) • [🇪🇸 Español](./README_ES.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇸🇦 العربية](./README_AR.md) • [🇮🇳 हिन्दी](./README_HI.md)
[Visao Geral](#-visao-geral) • [Inicio Rapido](#-inicio-rapido) • [Configuracao](#️-configuracao) • [Modo Skills](#-modo-skills) • [Modo RL](#-modo-rl) • [Modo MadMax](#-modo-madmax-padrao) • [Citacao](#-citacao)
