# 只需与你的 Agent 对话,它会不断学习,持续进化。
受大脑学习方式启发。让你的 🦞 在真实对话中持续元学习与进化。无需 GPU。支持 Kimi、Qwen、Claude、MiniMax 等。
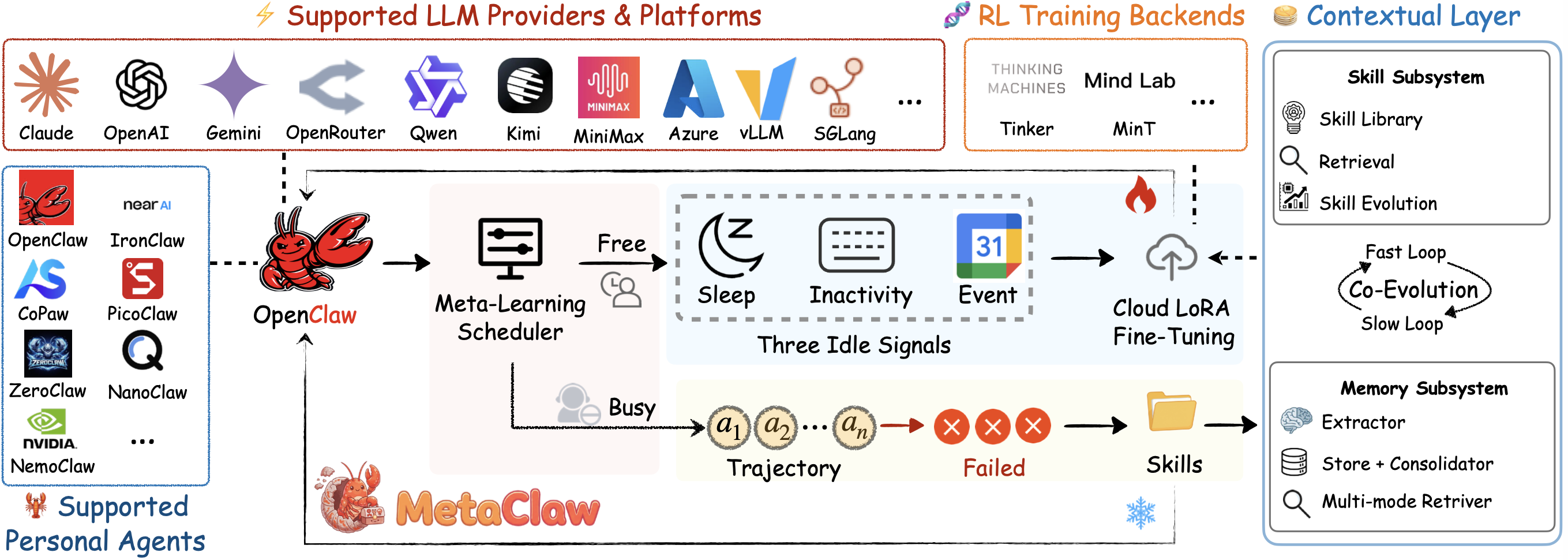
[🇺🇸 English](../README.md) • [🇯🇵 日本語](./README_JA.md) • [🇰🇷 한국어](./README_KO.md) • [🇫🇷 Français](./README_FR.md) • [🇩🇪 Deutsch](./README_DE.md) • [🇪🇸 Español](./README_ES.md) • [🇧🇷 Português](./README_PT.md) • [🇷🇺 Русский](./README_RU.md) • [🇮🇹 Italiano](./README_IT.md) • [🇻🇳 Tiếng Việt](./README_VI.md) • [🇦🇪 العربية](./README_AR.md) • [🇮🇳 हिन्दी](./README_HI.md)
[概述](#-概述) • [快速开始](#-快速开始) • [配置说明](#️-配置说明) • [Skills 模式](#-skills-模式) • [RL 模式](#-rl-模式) • [MadMax 模式](#-madmax-模式默认) • [引用](#-引用)
