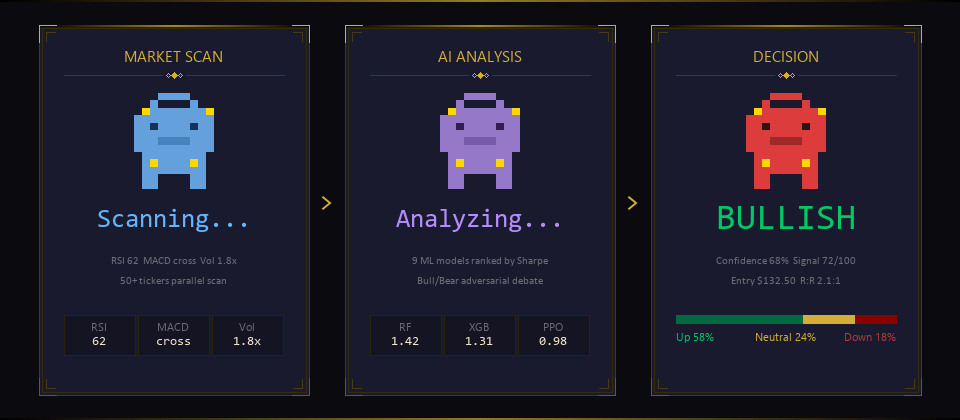
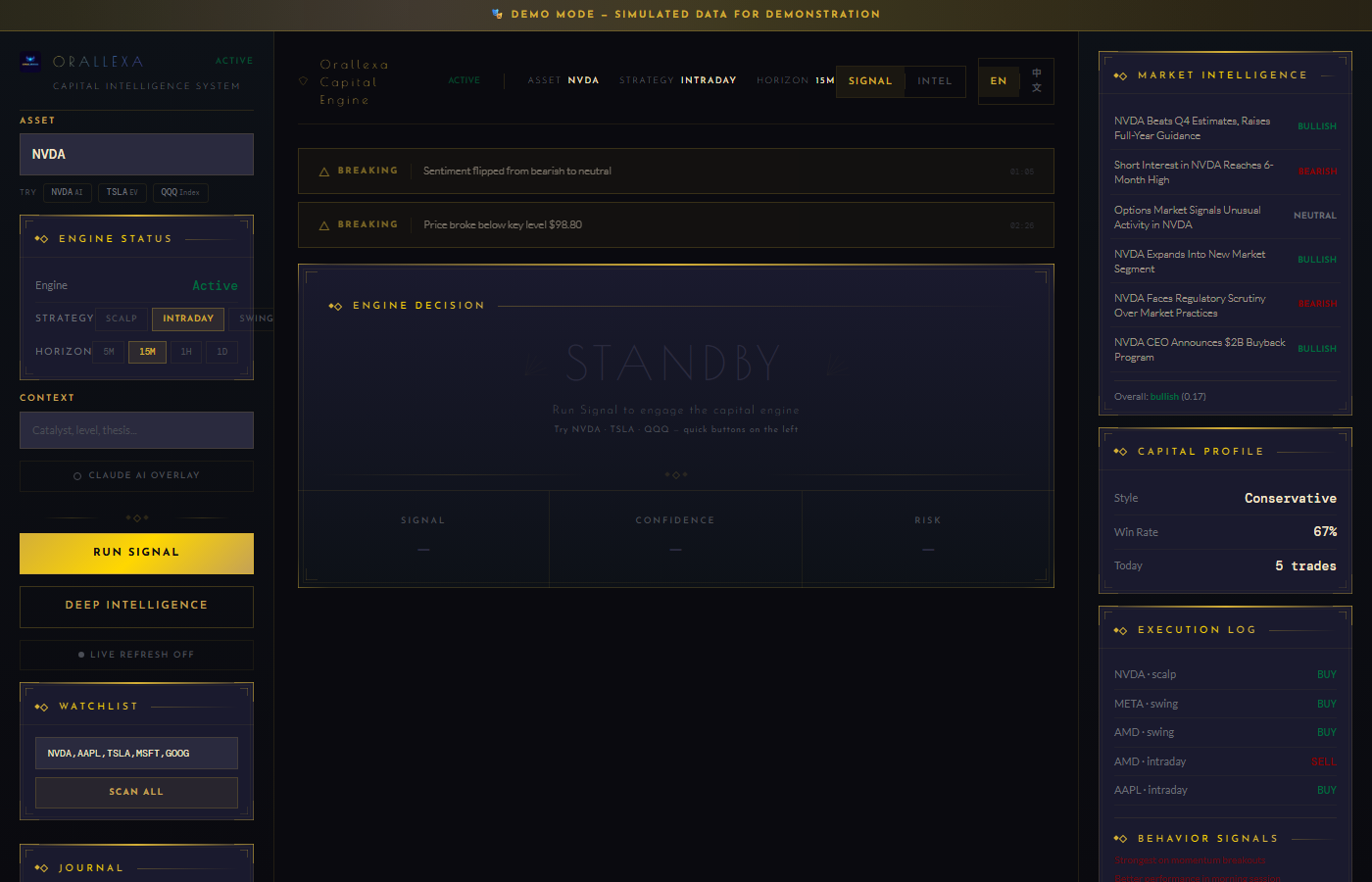
### Self-tuning multi-agent AI trading system **8-source signal fusion · 10 ML models incl. Kronos · Bull/Bear/Judge debate on Claude Opus 4.7**
Polymarket + Kalshi prediction markets vote alongside ML models. Weights adapt to per-source accuracy automatically.
[](https://github.com/alex-jb/orallexa-ai-trading-agent) [](https://python.org) [](https://nextjs.org) [](https://anthropic.com) [](docs/NEW_MODULES.md) [](https://github.com/alex-jb/orallexa-ai-trading-agent/actions/workflows/ci.yml) [](tests/) [](.coveragerc) [](https://github.com/alex-jb/orallexa-ai-trading-agent/issues) [](LICENSE)
[**Live Demo**](https://orallexa-ui.vercel.app) · [**Presentation**](https://alex-jb.github.io/orallexa-ai-trading-agent/presentation.html) · [**Evaluation Report**](docs/evaluation_report.md) · [**中文**](README_CN.md)