# 🎨 需求场景
在`ThreadLocal`的需求场景即是`TTL`的潜在需求场景,如果你的业务需要『在使用线程池等会池化复用线程的组件情况下传递`ThreadLocal`』则是`TTL`目标场景。
下面是几个典型场景例子。
-------------------------------
- [🔎 1. 分布式跟踪系统](#-1-%E5%88%86%E5%B8%83%E5%BC%8F%E8%B7%9F%E8%B8%AA%E7%B3%BB%E7%BB%9F)
- [🌵 2. 日志收集记录系统上下文](#-2-%E6%97%A5%E5%BF%97%E6%94%B6%E9%9B%86%E8%AE%B0%E5%BD%95%E7%B3%BB%E7%BB%9F%E4%B8%8A%E4%B8%8B%E6%96%87)
- [`Log4j2 MDC`的`TTL`集成](#log4j2-mdc%E7%9A%84ttl%E9%9B%86%E6%88%90)
- [`Logback MDC`的`TTL`集成](#logback-mdc%E7%9A%84ttl%E9%9B%86%E6%88%90)
- [👜 3. `Request`级`Cache`](#-3-request%E7%BA%A7cache)
- [🛁 4. 应用容器或上层框架跨应用代码给下层`SDK`传递信息](#-4-%E5%BA%94%E7%94%A8%E5%AE%B9%E5%99%A8%E6%88%96%E4%B8%8A%E5%B1%82%E6%A1%86%E6%9E%B6%E8%B7%A8%E5%BA%94%E7%94%A8%E4%BB%A3%E7%A0%81%E7%BB%99%E4%B8%8B%E5%B1%82sdk%E4%BC%A0%E9%80%92%E4%BF%A1%E6%81%AF)
- [上面场景使用`TTL`的整体构架](#%E4%B8%8A%E9%9D%A2%E5%9C%BA%E6%99%AF%E4%BD%BF%E7%94%A8ttl%E7%9A%84%E6%95%B4%E4%BD%93%E6%9E%84%E6%9E%B6)
-------------------------------
## 🔎 1. 分布式跟踪系统 或 全链路压测(即链路打标)
关于『分布式跟踪系统』可以了解一下`Google`的`Dapper`(介绍的论文:[中文](https://bigbully.github.io/Dapper-translation/)| [英文](https://research.google.com/pubs/pub36356.html))。分布式跟踪系统作为基础设施,不会限制『使用线程池等会池化复用线程的组件』,并期望对业务逻辑尽可能的透明。
分布式跟踪系统的实现的示意Demo参见[`DistributedTracerUseDemo.kt`](../ttl2-compatible/src/test/java/com/alibaba/demo/distributed_tracer/refcount/DistributedTracerUseDemo.kt)
从技术能力上讲,全链路压测 与 分布式跟踪系统 是一样的,即链路打标。
PS: 多谢 [@wyzssw](https://github.com/https://github.com/wyzssw) 对分布式追踪系统场景说明交流和实现上讨论建议:
- [Issue: 分布式追踪系统场景下,如何使用TTL](https://github.com/alibaba/transmittable-thread-local/issues/53)
## 🌵 2. 日志收集记录系统上下文
由于不限制用户应用使用线程池,系统的上下文需要能跨线程的传递,且不影响应用代码。
### `Log4j2 MDC`的`TTL`集成
`Log4j2`通过[`Thread Context`](https://logging.apache.org/log4j/2.x/manual/thread-context.html)提供了`Mapped Diagnostic Context`(`MDC`,诊断上下文)的功能,通过[`ThreadLocal`](https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/lang/ThreadLocal.html)/[`InheritableThreadLocal`](https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/lang/InheritableThreadLocal.html)实现上下文传递。
在[`Thread Context文档`](https://logging.apache.org/log4j/2.x/manual/thread-context.html)中提到了在使用线程池等会池化复用线程的组件(如`Executors`)时有问题,需要提供一个机制方案:
> The Stack and the Map are managed per thread and are based on ThreadLocal by default. The Map can be configured to use an InheritableThreadLocal by setting system property isThreadContextMapInheritable to "true". When configured this way, the contents of the Map will be passed to child threads. However, as discussed in the [Executors](https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/util/concurrent/Executors.html#privilegedThreadFactory%28%29) class and in other cases where thread pooling is utilized, the ThreadContext may not always be automatically passed to worker threads. In those cases the pooling mechanism should provide a means for doing so. The getContext() and cloneStack() methods can be used to obtain copies of the Map and Stack respectively.
即是`TTL`要解决的问题,提供`Log4j2 MDC`的`TTL`集成,详见工程[`log4j2-ttl-thread-context-map`](https://github.com/oldratlee/log4j2-ttl-thread-context-map)。对应依赖:
```xml
com.alibaba
log4j2-ttl-thread-context-map
1.3.0
```
可以在 [maven.org](https://repo1.maven.org/maven2/com/alibaba/log4j2-ttl-thread-context-map/maven-metadata.xml) 查看可用的版本。
PS: 多谢 @bwzhang2011 和 @wuwen5 对日志场景说明交流和实现上讨论建议:
- [Issue: 能否提供与LOG4J(2)中的MDC集成或增强](https://github.com/alibaba/transmittable-thread-local/issues/49) [@bwzhang2011](https://github.com/bwzhang2011)
- [Issue: slf4j MDCAdapter with multi-thread-context 支持](https://github.com/alibaba/transmittable-thread-local/issues/51) [@bwzhang2011](https://github.com/bwzhang2011)
### `Logback MDC`的`TTL`集成
`Logback`的集成参见[@ofpay](https://github.com/ofpay)提供的[`logback-mdc-ttl`](https://github.com/ofpay/logback-mdc-ttl)。对应依赖:
```xml
com.ofpay
logback-mdc-ttl
1.0.2
```
可以在 [maven.org](https://repo1.maven.org/maven2/com/ofpay/logback-mdc-ttl/maven-metadata.xml) 查看可用的版本。
这个集成已经在 **_线上产品环境_** 使用的。说明详见[欧飞网的使用场景](https://github.com/alibaba/transmittable-thread-local/issues/73#issuecomment-300665308)。
## 👜 3. `Request`级`Cache`
对于计算逻辑复杂业务流程,基础数据读取服务(这样的读取服务往往是个外部远程服务)可能需要多次调用,期望能缓存起来,以避免多次重复执行高成本操作。
同时,在入口发起不同的请求,处理的是不同用户的数据,所以不同发起请求之间不需要共享数据,这样也能避免请求对应的不同用户之间可能的数据污染。
因为涉及多个上下游线程,其实是`Session`级缓存。
通过`Request`级缓存可以
- 避免重复执行高成本操作,提升性能。
- 避免不同`Request`之间的数据污染。
更多讨论与使用方式参见[**_`@olove`_**](https://github.com/olove) 提的Issue:[讨论:Session级Cache场景下,TransmittableThreadLocal的使用](https://github.com/alibaba/transmittable-thread-local/issues/122)。
## 🛁 4. 应用容器或上层框架跨应用代码给下层`SDK`传递信息
举个具体的业务场景,在`App Engine`(`PAAS`)上会运行由应用提供商提供的应用(`SAAS`模式)。多个`SAAS`用户购买并使用这个应用(即`SAAS`应用)。`SAAS`应用往往是一个实例为多个`SAAS`用户提供服务。
\# 另一种模式是:`SAAS`用户使用完全独立一个`SAAS`应用,包含独立应用实例及其后的数据源(如`DB`、缓存,etc)。
需要避免的`SAAS`应用拿到多个`SAAS`用户的数据。一个解决方法是处理过程关联好一个`SAAS`用户的上下文,在上下文中应用只能处理(读/写)这个`SAAS`用户的数据。请求由`SAAS`用户发起(如从`Web`请求进入`App Engine`),`App Engine`可以知道是从哪个`SAAS`用户,在`Web`请求时在上下文中设置好`SAAS`用户`ID`。应用处理数据(`DB`、`Web`、消息 etc.)是通过`App Engine`提供的服务`SDK`来完成。当应用处理数据时,`SDK`检查数据所属的`SAAS`用户是否和上下文中的`SAAS`用户`ID`一致,如果不一致则拒绝数据的读写。
应用代码会使用线程池,并且这样的使用是正常的业务需求。`SAAS`用户`ID`的从要`App Engine`传递到下层`SDK`,要支持这样的用法。
### 上面场景使用`TTL`的整体构架
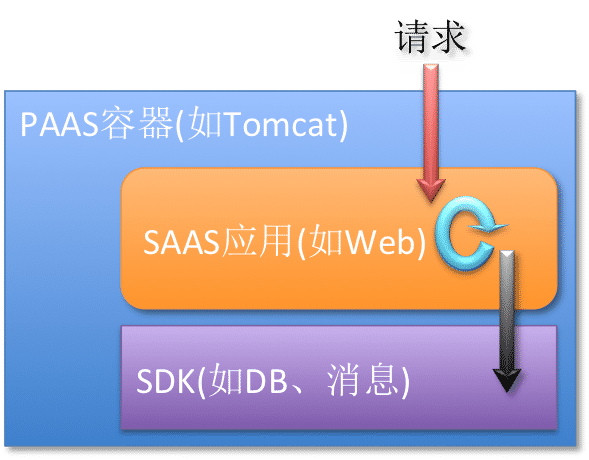 构架涉及3个角色:容器、用户应用、`SDK`。
整体流程:
1. 请求进入`PAAS`容器,提取上下文信息并设置好上下文。
2. 进入用户应用处理业务,业务调用`SDK`(如`DB`、消息、etc)。
用户应用会使用线程池,所以调用`SDK`的线程可能不是请求的线程。
3. 进入`SDK`处理。
提取上下文的信息,决定是否符合拒绝处理。
整个过程中,上下文的传递 对于 **用户应用代码** 期望是透明的。
构架涉及3个角色:容器、用户应用、`SDK`。
整体流程:
1. 请求进入`PAAS`容器,提取上下文信息并设置好上下文。
2. 进入用户应用处理业务,业务调用`SDK`(如`DB`、消息、etc)。
用户应用会使用线程池,所以调用`SDK`的线程可能不是请求的线程。
3. 进入`SDK`处理。
提取上下文的信息,决定是否符合拒绝处理。
整个过程中,上下文的传递 对于 **用户应用代码** 期望是透明的。