{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Assignment 4 - Naive Machine Translation and LSH\n",
"\n",
"You will now implement your first machine translation system and then you\n",
"will see how locality sensitive hashing works. Let's get started by importing\n",
"the required functions!\n",
"\n",
"If you are running this notebook in your local computer, don't forget to\n",
"download the twitter samples and stopwords from nltk.\n",
"\n",
"```\n",
"nltk.download('stopwords')\n",
"nltk.download('twitter_samples')\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import pdb\n",
"import pickle\n",
"import string\n",
"\n",
"import time\n",
"\n",
"import gensim\n",
"import matplotlib.pyplot as plt\n",
"import nltk\n",
"import numpy as np\n",
"import scipy\n",
"import sklearn\n",
"from gensim.models import KeyedVectors\n",
"from nltk.corpus import stopwords, twitter_samples\n",
"from nltk.tokenize import TweetTokenizer\n",
"\n",
"from utils import (cosine_similarity, get_dict,\n",
" process_tweet)\n",
"from os import getcwd"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"# add folder, tmp2, from our local workspace containing pre-downloaded corpora files to nltk's data path\n",
"filePath = f\"{getcwd()}/../tmp2/\"\n",
"nltk.data.path.append(filePath)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 1. The word embeddings data for English and French words\n",
"\n",
"Write a program that translates English to French.\n",
"\n",
"## The data\n",
"\n",
"The full dataset for English embeddings is about 3.64 gigabytes, and the French\n",
"embeddings are about 629 megabytes. To prevent the Coursera workspace from\n",
"crashing, we've extracted a subset of the embeddings for the words that you'll\n",
"use in this assignment.\n",
"\n",
"If you want to run this on your local computer and use the full dataset,\n",
"you can download the\n",
"* English embeddings from Google code archive word2vec\n",
"[look for GoogleNews-vectors-negative300.bin.gz](https://code.google.com/archive/p/word2vec/)\n",
" * You'll need to unzip the file first.\n",
"* and the French embeddings from\n",
"[cross_lingual_text_classification](https://github.com/vjstark/crosslingual_text_classification).\n",
" * in the terminal, type (in one line)\n",
" `curl -o ./wiki.multi.fr.vec https://dl.fbaipublicfiles.com/arrival/vectors/wiki.multi.fr.vec`\n",
"\n",
"Then copy-paste the code below and run it."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"```python\n",
"# Use this code to download and process the full dataset on your local computer\n",
"\n",
"from gensim.models import KeyedVectors\n",
"\n",
"en_embeddings = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin', binary = True)\n",
"fr_embeddings = KeyedVectors.load_word2vec_format('./wiki.multi.fr.vec')\n",
"\n",
"\n",
"# loading the english to french dictionaries\n",
"en_fr_train = get_dict('en-fr.train.txt')\n",
"print('The length of the english to french training dictionary is', len(en_fr_train))\n",
"en_fr_test = get_dict('en-fr.test.txt')\n",
"print('The length of the english to french test dictionary is', len(en_fr_train))\n",
"\n",
"english_set = set(en_embeddings.vocab)\n",
"french_set = set(fr_embeddings.vocab)\n",
"en_embeddings_subset = {}\n",
"fr_embeddings_subset = {}\n",
"french_words = set(en_fr_train.values())\n",
"\n",
"for en_word in en_fr_train.keys():\n",
" fr_word = en_fr_train[en_word]\n",
" if fr_word in french_set and en_word in english_set:\n",
" en_embeddings_subset[en_word] = en_embeddings[en_word]\n",
" fr_embeddings_subset[fr_word] = fr_embeddings[fr_word]\n",
"\n",
"\n",
"for en_word in en_fr_test.keys():\n",
" fr_word = en_fr_test[en_word]\n",
" if fr_word in french_set and en_word in english_set:\n",
" en_embeddings_subset[en_word] = en_embeddings[en_word]\n",
" fr_embeddings_subset[fr_word] = fr_embeddings[fr_word]\n",
"\n",
"\n",
"pickle.dump( en_embeddings_subset, open( \"en_embeddings.p\", \"wb\" ) )\n",
"pickle.dump( fr_embeddings_subset, open( \"fr_embeddings.p\", \"wb\" ) )\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### The subset of data\n",
"\n",
"To do the assignment on the Coursera workspace, we'll use the subset of word embeddings."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"en_embeddings_subset = pickle.load(open(\"en_embeddings.p\", \"rb\"))\n",
"fr_embeddings_subset = pickle.load(open(\"fr_embeddings.p\", \"rb\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Look at the data\n",
"\n",
"* en_embeddings_subset: the key is an English word, and the vaule is a\n",
"300 dimensional array, which is the embedding for that word.\n",
"```\n",
"'the': array([ 0.08007812, 0.10498047, 0.04980469, 0.0534668 , -0.06738281, ....\n",
"```\n",
"\n",
"* fr_embeddings_subset: the key is an French word, and the vaule is a 300\n",
"dimensional array, which is the embedding for that word.\n",
"```\n",
"'la': array([-6.18250e-03, -9.43867e-04, -8.82648e-03, 3.24623e-02,...\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Load two dictionaries mapping the English to French words\n",
"* A training dictionary\n",
"* and a testing dictionary."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The length of the English to French training dictionary is 5000\n",
"The length of the English to French test dictionary is 5000\n"
]
}
],
"source": [
"# loading the english to french dictionaries\n",
"en_fr_train = get_dict('en-fr.train.txt')\n",
"print('The length of the English to French training dictionary is', len(en_fr_train))\n",
"en_fr_test = get_dict('en-fr.test.txt')\n",
"print('The length of the English to French test dictionary is', len(en_fr_train))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Looking at the English French dictionary\n",
"\n",
"* `en_fr_train` is a dictionary where the key is the English word and the value\n",
"is the French translation of that English word.\n",
"```\n",
"{'the': 'la',\n",
" 'and': 'et',\n",
" 'was': 'était',\n",
" 'for': 'pour',\n",
"```\n",
"\n",
"* `en_fr_test` is similar to `en_fr_train`, but is a test set. We won't look at it\n",
"until we get to testing."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1.1 Generate embedding and transform matrices\n",
"\n",
"#### Exercise: Translating English dictionary to French by using embeddings\n",
"\n",
"You will now implement a function `get_matrices`, which takes the loaded data\n",
"and returns matrices `X` and `Y`.\n",
"\n",
"Inputs:\n",
"- `en_fr` : English to French dictionary\n",
"- `en_embeddings` : English to embeddings dictionary\n",
"- `fr_embeddings` : French to embeddings dictionary\n",
"\n",
"Returns:\n",
"- Matrix `X` and matrix `Y`, where each row in X is the word embedding for an\n",
"english word, and the same row in Y is the word embedding for the French\n",
"version of that English word.\n",
"\n",
"
\n",
" Figure 2
\n",
"\n",
"Use the `en_fr` dictionary to ensure that the ith row in the `X` matrix\n",
"corresponds to the ith row in the `Y` matrix."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Instructions**: Complete the function `get_matrices()`:\n",
"* Iterate over English words in `en_fr` dictionary.\n",
"* Check if the word have both English and French embedding."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
Sets are useful data structures that can be used to check if an item is a member of a group.
\n",
"
You can get words which are embedded into the language by using keys method.
\n",
"
Keep vectors in `X` and `Y` sorted in list. You can use np.vstack() to merge them into the numpy matrix.
\n",
"
numpy.vstack stacks the items in a list as rows in a matrix.
\n",
"
\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def get_matrices(en_fr, french_vecs, english_vecs):\n",
" \"\"\"\n",
" Input:\n",
" en_fr: English to French dictionary\n",
" french_vecs: French words to their corresponding word embeddings.\n",
" english_vecs: English words to their corresponding word embeddings.\n",
" Output: \n",
" X: a matrix where the columns are the English embeddings.\n",
" Y: a matrix where the columns correspong to the French embeddings.\n",
" R: the projection matrix that minimizes the F norm ||X R -Y||^2.\n",
" \"\"\"\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
"\n",
" # X_l and Y_l are lists of the english and french word embeddings\n",
" X_l = list()\n",
" Y_l = list()\n",
"\n",
" # get the english words (the keys in the dictionary) and store in a set()\n",
" english_set = english_vecs.keys()\n",
"\n",
" # get the french words (keys in the dictionary) and store in a set()\n",
" french_set = french_vecs.keys()\n",
"\n",
" # store the french words that are part of the english-french dictionary (these are the values of the dictionary)\n",
" french_words = set(en_fr.values())\n",
"\n",
" # loop through all english, french word pairs in the english french dictionary\n",
" for en_word, fr_word in en_fr.items():\n",
"\n",
" # check that the french word has an embedding and that the english word has an embedding\n",
" if fr_word in french_set and en_word in english_set:\n",
"\n",
" # get the english embedding\n",
" en_vec = english_vecs[en_word]\n",
"\n",
" # get the french embedding\n",
" fr_vec = french_vecs[fr_word]\n",
"\n",
" # add the english embedding to the list\n",
" X_l.append(en_vec)\n",
"\n",
" # add the french embedding to the list\n",
" Y_l.append(fr_vec)\n",
"\n",
" # stack the vectors of X_l into a matrix X\n",
" X = np.vstack(X_l)\n",
"\n",
" # stack the vectors of Y_l into a matrix Y\n",
" Y = np.vstack(Y_l)\n",
" ### END CODE HERE ###\n",
"\n",
" return X, Y\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we will use function `get_matrices()` to obtain sets `X_train` and `Y_train`\n",
"of English and French word embeddings into the corresponding vector space models."
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# getting the training set:\n",
"X_train, Y_train = get_matrices(\n",
" en_fr_train, fr_embeddings_subset, en_embeddings_subset)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2. Translations\n",
"\n",
"
Figure 1
\n",
"\n",
"Write a program that translates English words to French words using word embeddings and vector space models. \n",
"\n",
"## 2.1 Translation as linear transformation of embeddings\n",
"\n",
"Given dictionaries of English and French word embeddings you will create a transformation matrix `R`\n",
"* Given an English word embedding, $\\mathbf{e}$, you can multiply $\\mathbf{eR}$ to get a new word embedding $\\mathbf{f}$.\n",
" * Both $\\mathbf{e}$ and $\\mathbf{f}$ are [row vectors](https://en.wikipedia.org/wiki/Row_and_column_vectors).\n",
"* You can then compute the nearest neighbors to `f` in the french embeddings and recommend the word that is most similar to the transformed word embedding."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Describing translation as the minimization problem\n",
"\n",
"Find a matrix `R` that minimizes the following equation. \n",
"\n",
"$$\\arg \\min _{\\mathbf{R}}\\| \\mathbf{X R} - \\mathbf{Y}\\|_{F}\\tag{1} $$\n",
"\n",
"### Frobenius norm\n",
"\n",
"The Frobenius norm of a matrix $A$ (assuming it is of dimension $m,n$) is defined as the square root of the sum of the absolute squares of its elements:\n",
"\n",
"$$\\|\\mathbf{A}\\|_{F} \\equiv \\sqrt{\\sum_{i=1}^{m} \\sum_{j=1}^{n}\\left|a_{i j}\\right|^{2}}\\tag{2}$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Actual loss function\n",
"In the real world applications, the Frobenius norm loss:\n",
"\n",
"$$\\| \\mathbf{XR} - \\mathbf{Y}\\|_{F}$$\n",
"\n",
"is often replaced by it's squared value divided by $m$:\n",
"\n",
"$$ \\frac{1}{m} \\| \\mathbf{X R} - \\mathbf{Y} \\|_{F}^{2}$$\n",
"\n",
"where $m$ is the number of examples (rows in $\\mathbf{X}$).\n",
"\n",
"* The same R is found when using this loss function versus the original Frobenius norm.\n",
"* The reason for taking the square is that it's easier to compute the gradient of the squared Frobenius.\n",
"* The reason for dividing by $m$ is that we're more interested in the average loss per embedding than the loss for the entire training set.\n",
" * The loss for all training set increases with more words (training examples),\n",
" so taking the average helps us to track the average loss regardless of the size of the training set."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### [Optional] Detailed explanation why we use norm squared instead of the norm:\n",
"\n",
"\n",
" Click for optional details\n",
"\n",
"
\n",
"
\n",
"
The norm is always nonnegative (we're summing up absolute values), and so is the square. \n",
"
When we take the square of all non-negative (positive or zero) numbers, the order of the data is preserved. \n",
"
For example, if 3 > 2, 3^2 > 2^2\n",
"
Using the norm or squared norm in gradient descent results in the same location of the minimum.\n",
"
Squaring cancels the square root in the Frobenius norm formula. Because of the chain rule, we would have to do more calculations if we had a square root in our expression for summation.\n",
"
Dividing the function value by the positive number doesn't change the optimum of the function, for the same reason as described above.\n",
"
We're interested in transforming English embedding into the French. Thus, it is more important to measure average loss per embedding than the loss for the entire dictionary (which increases as the number of words in the dictionary increases).\n",
"
\n",
" \n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Exercise: Implementing translation mechanism described in this section.\n",
"\n",
"#### Step 1: Computing the loss\n",
"* The loss function will be squared Frobenoius norm of the difference between\n",
"matrix and its approximation, divided by the number of training examples $m$.\n",
"* Its formula is:\n",
"$$ L(X, Y, R)=\\frac{1}{m}\\sum_{i=1}^{m} \\sum_{j=1}^{n}\\left( a_{i j} \\right)^{2}$$\n",
"\n",
"where $a_{i j}$ is value in $i$th row and $j$th column of the matrix $\\mathbf{XR}-\\mathbf{Y}$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Instructions: complete the `compute_loss()` function\n",
"\n",
"* Compute the approximation of `Y` by matrix multiplying `X` and `R`\n",
"* Compute difference `XR - Y`\n",
"* Compute the squared Frobenius norm of the difference and divide it by $m$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n",
"\n",
" Hints\n",
"\n",
"
Be careful about which operation is elementwise and which operation is a matrix multiplication.
\n",
"
Try to use matrix operations instead of the numpy norm function. If you choose to use norm function, take care of extra arguments and that it's returning loss squared, and not the loss itself.
\n",
"\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C3 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def compute_loss(X, Y, R):\n",
" '''\n",
" Inputs: \n",
" X: a matrix of dimension (m,n) where the columns are the English embeddings.\n",
" Y: a matrix of dimension (m,n) where the columns correspong to the French embeddings.\n",
" R: a matrix of dimension (n,n) - transformation matrix from English to French vector space embeddings.\n",
" Outputs:\n",
" L: a matrix of dimension (m,n) - the value of the loss function for given X, Y and R.\n",
" '''\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # m is the number of rows in X\n",
" m = X.shape[0]\n",
" \n",
" # diff is XR - Y\n",
" diff = np.dot(X,R)-Y\n",
"\n",
" # diff_squared is the element-wise square of the difference\n",
" diff_squared = diff**2\n",
"\n",
" # sum_diff_squared is the sum of the squared elements\n",
" sum_diff_squared = np.sum(diff_squared)\n",
"\n",
" # loss i the sum_diff_squard divided by the number of examples (m)\n",
" loss = sum_diff_squared/m\n",
" ### END CODE HERE ###\n",
" return loss\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Step 2: Computing the gradient of loss in respect to transform matrix R\n",
"\n",
"* Calculate the gradient of the loss with respect to transform matrix `R`.\n",
"* The gradient is a matrix that encodes how much a small change in `R`\n",
"affect the change in the loss function.\n",
"* The gradient gives us the direction in which we should decrease `R`\n",
"to minimize the loss.\n",
"* $m$ is the number of training examples (number of rows in $X$).\n",
"* The formula for the gradient of the loss function $𝐿(𝑋,𝑌,𝑅)$ is:\n",
"\n",
"$$\\frac{d}{dR}𝐿(𝑋,𝑌,𝑅)=\\frac{d}{dR}\\Big(\\frac{1}{m}\\| X R -Y\\|_{F}^{2}\\Big) = \\frac{2}{m}X^{T} (X R - Y)$$\n",
"\n",
"**Instructions**: Complete the `compute_gradient` function below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
Remember to use numpy.dot for matrix multiplication
\n",
"
\n",
"\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C4 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def compute_gradient(X, Y, R):\n",
" '''\n",
" Inputs: \n",
" X: a matrix of dimension (m,n) where the columns are the English embeddings.\n",
" Y: a matrix of dimension (m,n) where the columns correspong to the French embeddings.\n",
" R: a matrix of dimension (n,n) - transformation matrix from English to French vector space embeddings.\n",
" Outputs:\n",
" g: a matrix of dimension (n,n) - gradient of the loss function L for given X, Y and R.\n",
" '''\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # m is the number of rows in X\n",
" m = X.shape[0]\n",
"\n",
" # gradient is X^T(XR - Y) * 2/m\n",
" gradient = np.dot(X.transpose(),np.dot(X,R)-Y)*(2/m)\n",
" ### END CODE HERE ###\n",
" return gradient\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Step 3: Finding the optimal R with gradient descent algorithm\n",
"\n",
"#### Gradient descent\n",
"\n",
"[Gradient descent](https://ml-cheatsheet.readthedocs.io/en/latest/gradient_descent.html) is an iterative algorithm which is used in searching for the optimum of the function. \n",
"* Earlier, we've mentioned that the gradient of the loss with respect to the matrix encodes how much a tiny change in some coordinate of that matrix affect the change of loss function.\n",
"* Gradient descent uses that information to iteratively change matrix `R` until we reach a point where the loss is minimized. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Training with a fixed number of iterations\n",
"\n",
"Most of the time we iterate for a fixed number of training steps rather than iterating until the loss falls below a threshold.\n",
"\n",
"##### OPTIONAL: explanation for fixed number of iterations\n",
"\n",
"\n",
" click here for detailed discussion\n",
"\n",
"
\n",
"
\n",
"
You cannot rely on training loss getting low -- what you really want is the validation loss to go down, or validation accuracy to go up. And indeed - in some cases people train until validation accuracy reaches a threshold, or -- commonly known as \"early stopping\" -- until the validation accuracy starts to go down, which is a sign of over-fitting.\n",
"
\n",
"
\n",
" Why not always do \"early stopping\"? Well, mostly because well-regularized models on larger data-sets never stop improving. Especially in NLP, you can often continue training for months and the model will continue getting slightly and slightly better. This is also the reason why it's hard to just stop at a threshold -- unless there's an external customer setting the threshold, why stop, where do you put the threshold?\n",
"
\n",
"
Stopping after a certain number of steps has the advantage that you know how long your training will take - so you can keep some sanity and not train for months. You can then try to get the best performance within this time budget. Another advantage is that you can fix your learning rate schedule -- e.g., lower the learning rate at 10% before finish, and then again more at 1% before finishing. Such learning rate schedules help a lot, but are harder to do if you don't know how long you're training.\n",
"
\n",
"
\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Pseudocode:\n",
"1. Calculate gradient $g$ of the loss with respect to the matrix $R$.\n",
"2. Update $R$ with the formula:\n",
"$$R_{\\text{new}}= R_{\\text{old}}-\\alpha g$$\n",
"\n",
"Where $\\alpha$ is the learning rate, which is a scalar."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Learning rate\n",
"\n",
"* The learning rate or \"step size\" $\\alpha$ is a coefficient which decides how much we want to change $R$ in each step.\n",
"* If we change $R$ too much, we could skip the optimum by taking too large of a step.\n",
"* If we make only small changes to $R$, we will need many steps to reach the optimum.\n",
"* Learning rate $\\alpha$ is used to control those changes.\n",
"* Values of $\\alpha$ are chosen depending on the problem, and we'll use `learning_rate`$=0.0003$ as the default value for our algorithm."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Instructions: Implement `align_embeddings()`"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
Use the 'compute_gradient()' function to get the gradient in each step
\n",
"\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C5 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def align_embeddings(X, Y, train_steps=100, learning_rate=0.0003):\n",
" '''\n",
" Inputs:\n",
" X: a matrix of dimension (m,n) where the columns are the English embeddings.\n",
" Y: a matrix of dimension (m,n) where the columns correspong to the French embeddings.\n",
" train_steps: positive int - describes how many steps will gradient descent algorithm do.\n",
" learning_rate: positive float - describes how big steps will gradient descent algorithm do.\n",
" Outputs:\n",
" R: a matrix of dimension (n,n) - the projection matrix that minimizes the F norm ||X R -Y||^2\n",
" '''\n",
" np.random.seed(129)\n",
"\n",
" # the number of columns in X is the number of dimensions for a word vector (e.g. 300)\n",
" # R is a square matrix with length equal to the number of dimensions in th word embedding\n",
" R = np.random.rand(X.shape[1], X.shape[1])\n",
"\n",
" for i in range(train_steps):\n",
" if i % 25 == 0:\n",
" print(f\"loss at iteration {i} is: {compute_loss(X, Y, R):.4f}\")\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # use the function that you defined to compute the gradient\n",
" gradient = compute_gradient(X,Y,R)\n",
"\n",
" # update R by subtracting the learning rate times gradient\n",
" R -= learning_rate * gradient\n",
" ### END CODE HERE ###\n",
" return R\n"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"loss at iteration 0 is: 3.7242\n",
"loss at iteration 25 is: 3.6283\n",
"loss at iteration 50 is: 3.5350\n",
"loss at iteration 75 is: 3.4442\n"
]
}
],
"source": [
"# UNQ_C6 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# Testing your implementation.\n",
"np.random.seed(129)\n",
"m = 10\n",
"n = 5\n",
"X = np.random.rand(m, n)\n",
"Y = np.random.rand(m, n) * .1\n",
"R = align_embeddings(X, Y)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected Output:**\n",
"```\n",
"loss at iteration 0 is: 3.7242\n",
"loss at iteration 25 is: 3.6283\n",
"loss at iteration 50 is: 3.5350\n",
"loss at iteration 75 is: 3.4442\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Calculate transformation matrix R\n",
"\n",
"Using those the training set, find the transformation matrix $\\mathbf{R}$ by calling the function `align_embeddings()`."
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"loss at iteration 0 is: 963.0146\n",
"loss at iteration 25 is: 97.8292\n",
"loss at iteration 50 is: 26.8329\n",
"loss at iteration 75 is: 9.7893\n",
"loss at iteration 100 is: 4.3776\n",
"loss at iteration 125 is: 2.3281\n",
"loss at iteration 150 is: 1.4480\n",
"loss at iteration 175 is: 1.0338\n",
"loss at iteration 200 is: 0.8251\n",
"loss at iteration 225 is: 0.7145\n",
"loss at iteration 250 is: 0.6534\n",
"loss at iteration 275 is: 0.6185\n",
"loss at iteration 300 is: 0.5981\n",
"loss at iteration 325 is: 0.5858\n",
"loss at iteration 350 is: 0.5782\n",
"loss at iteration 375 is: 0.5735\n"
]
}
],
"source": [
"# UNQ_C7 (UNIQU\n",
"#E CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"R_train = align_embeddings(X_train, Y_train, train_steps=400, learning_rate=0.8)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Expected Output\n",
"\n",
"```\n",
"loss at iteration 0 is: 963.0146\n",
"loss at iteration 25 is: 97.8292\n",
"loss at iteration 50 is: 26.8329\n",
"loss at iteration 75 is: 9.7893\n",
"loss at iteration 100 is: 4.3776\n",
"loss at iteration 125 is: 2.3281\n",
"loss at iteration 150 is: 1.4480\n",
"loss at iteration 175 is: 1.0338\n",
"loss at iteration 200 is: 0.8251\n",
"loss at iteration 225 is: 0.7145\n",
"loss at iteration 250 is: 0.6534\n",
"loss at iteration 275 is: 0.6185\n",
"loss at iteration 300 is: 0.5981\n",
"loss at iteration 325 is: 0.5858\n",
"loss at iteration 350 is: 0.5782\n",
"loss at iteration 375 is: 0.5735\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2.2 Testing the translation\n",
"\n",
"### k-Nearest neighbors algorithm\n",
"\n",
"[k-Nearest neighbors algorithm](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm) \n",
"* k-NN is a method which takes a vector as input and finds the other vectors in the dataset that are closest to it. \n",
"* The 'k' is the number of \"nearest neighbors\" to find (e.g. k=2 finds the closest two neighbors).\n",
"\n",
"### Searching for the translation embedding\n",
"Since we're approximating the translation function from English to French embeddings by a linear transformation matrix $\\mathbf{R}$, most of the time we won't get the exact embedding of a French word when we transform embedding $\\mathbf{e}$ of some particular English word into the French embedding space. \n",
"* This is where $k$-NN becomes really useful! By using $1$-NN with $\\mathbf{eR}$ as input, we can search for an embedding $\\mathbf{f}$ (as a row) in the matrix $\\mathbf{Y}$ which is the closest to the transformed vector $\\mathbf{eR}$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Cosine similarity\n",
"Cosine similarity between vectors $u$ and $v$ calculated as the cosine of the angle between them.\n",
"The formula is \n",
"\n",
"$$\\cos(u,v)=\\frac{u\\cdot v}{\\left\\|u\\right\\|\\left\\|v\\right\\|}$$\n",
"\n",
"* $\\cos(u,v)$ = $1$ when $u$ and $v$ lie on the same line and have the same direction.\n",
"* $\\cos(u,v)$ is $-1$ when they have exactly opposite directions.\n",
"* $\\cos(u,v)$ is $0$ when the vectors are orthogonal (perpendicular) to each other."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Note: Distance and similarity are pretty much opposite things.\n",
"* We can obtain distance metric from cosine similarity, but the cosine similarity can't be used directly as the distance metric. \n",
"* When the cosine similarity increases (towards $1$), the \"distance\" between the two vectors decreases (towards $0$). \n",
"* We can define the cosine distance between $u$ and $v$ as\n",
"$$d_{\\text{cos}}(u,v)=1-\\cos(u,v)$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Exercise**: Complete the function `nearest_neighbor()`\n",
"\n",
"Inputs:\n",
"* Vector `v`,\n",
"* A set of possible nearest neighbors `candidates`\n",
"* `k` nearest neighbors to find.\n",
"* The distance metric should be based on cosine similarity.\n",
"* `cosine_similarity` function is already implemented and imported for you. It's arguments are two vectors and it returns the cosine of the angle between them.\n",
"* Iterate over rows in `candidates`, and save the result of similarities between current row and vector `v` in a python list. Take care that similarities are in the same order as row vectors of `candidates`.\n",
"* Now you can use [numpy argsort]( https://docs.scipy.org/doc/numpy/reference/generated/numpy.argsort.html#numpy.argsort) to sort the indices for the rows of `candidates`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
numpy.argsort sorts values from most negative to most positive (smallest to largest)
\n",
"
The candidates that are nearest to 'v' should have the highest cosine similarity
\n",
"
To get the last element of a list 'tmp', the notation is tmp[-1:]
\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C8 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def nearest_neighbor(v, candidates, k=1):\n",
" \"\"\"\n",
" Input:\n",
" - v, the vector you are going find the nearest neighbor for\n",
" - candidates: a set of vectors where we will find the neighbors\n",
" - k: top k nearest neighbors to find\n",
" Output:\n",
" - k_idx: the indices of the top k closest vectors in sorted form\n",
" \"\"\"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" similarity_l = []\n",
"\n",
" # for each candidate vector...\n",
" for row in candidates:\n",
" # get the cosine similarity\n",
" cos_similarity = cosine_similarity(v,row)\n",
"\n",
" # append the similarity to the list\n",
" similarity_l.append(cos_similarity)\n",
" \n",
" # sort the similarity list and get the indices of the sorted list\n",
" sorted_ids = np.argsort(similarity_l)\n",
"\n",
" # get the indices of the k most similar candidate vectors\n",
" k_idx = sorted_ids[-k:]\n",
" ### END CODE HERE ###\n",
" return k_idx\n"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[9 9 9]\n",
" [1 0 5]\n",
" [2 0 1]]\n"
]
}
],
"source": [
"# UNQ_C9 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# Test your implementation:\n",
"v = np.array([1, 0, 1])\n",
"candidates = np.array([[1, 0, 5], [-2, 5, 3], [2, 0, 1], [6, -9, 5], [9, 9, 9]])\n",
"print(candidates[nearest_neighbor(v, candidates, 3)])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected Output**:\n",
"\n",
"`[[9 9 9]\n",
" [1 0 5]\n",
" [2 0 1]]`"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test your translation and compute its accuracy\n",
"\n",
"**Exercise**:\n",
"Complete the function `test_vocabulary` which takes in English\n",
"embedding matrix $X$, French embedding matrix $Y$ and the $R$\n",
"matrix and returns the accuracy of translations from $X$ to $Y$ by $R$.\n",
"\n",
"* Iterate over transformed English word embeddings and check if the\n",
"closest French word vector belongs to French word that is the actual\n",
"translation.\n",
"* Obtain an index of the closest French embedding by using\n",
"`nearest_neighbor` (with argument `k=1`), and compare it to the index\n",
"of the English embedding you have just transformed.\n",
"* Keep track of the number of times you get the correct translation.\n",
"* Calculate accuracy as $$\\text{accuracy}=\\frac{\\#(\\text{correct predictions})}{\\#(\\text{total predictions})}$$"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C10 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def test_vocabulary(X, Y, R):\n",
" '''\n",
" Input:\n",
" X: a matrix where the columns are the English embeddings.\n",
" Y: a matrix where the columns correspong to the French embeddings.\n",
" R: the transform matrix which translates word embeddings from\n",
" English to French word vector space.\n",
" Output:\n",
" accuracy: for the English to French capitals\n",
" '''\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # The prediction is X times R\n",
" pred = np.dot(X,R)\n",
"\n",
" # initialize the number correct to zero\n",
" num_correct = 0\n",
"\n",
" # loop through each row in pred (each transformed embedding)\n",
" for i in range(len(pred)):\n",
" # get the index of the nearest neighbor of pred at row 'i'; also pass in the candidates in Y\n",
" pred_idx = nearest_neighbor(pred[i],Y)\n",
"\n",
" # if the index of the nearest neighbor equals the row of i... \\\n",
" if pred_idx == i:\n",
" # increment the number correct by 1.\n",
" num_correct += 1\n",
"\n",
" # accuracy is the number correct divided by the number of rows in 'pred' (also number of rows in X)\n",
" accuracy = num_correct / len(pred)\n",
"\n",
" ### END CODE HERE ###\n",
"\n",
" return accuracy\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's see how is your translation mechanism working on the unseen data:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [],
"source": [
"X_val, Y_val = get_matrices(en_fr_test, fr_embeddings_subset, en_embeddings_subset)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"accuracy on test set is 0.557\n"
]
}
],
"source": [
"# UNQ_C11 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"#print((np.dot(X,R)[0]))\n",
"acc = test_vocabulary(X_val, Y_val, R_train) # this might take a minute or two\n",
"print(f\"accuracy on test set is {acc:.3f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected Output**:\n",
"\n",
"```\n",
"0.557\n",
"```\n",
"\n",
"You managed to translate words from one language to another language\n",
"without ever seing them with almost 56% accuracy by using some basic\n",
"linear algebra and learning a mapping of words from one language to another!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3. LSH and document search\n",
"\n",
"In this part of the assignment, you will implement a more efficient version\n",
"of k-nearest neighbors using locality sensitive hashing.\n",
"You will then apply this to document search.\n",
"\n",
"* Process the tweets and represent each tweet as a vector (represent a\n",
"document with a vector embedding).\n",
"* Use locality sensitive hashing and k nearest neighbors to find tweets\n",
"that are similar to a given tweet."
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [],
"source": [
"# get the positive and negative tweets\n",
"all_positive_tweets = twitter_samples.strings('positive_tweets.json')\n",
"all_negative_tweets = twitter_samples.strings('negative_tweets.json')\n",
"all_tweets = all_positive_tweets + all_negative_tweets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.2 Getting the document embeddings\n",
"\n",
"#### Bag-of-words (BOW) document models\n",
"Text documents are sequences of words.\n",
"* The ordering of words makes a difference. For example, sentences \"Apple pie is\n",
"better than pepperoni pizza.\" and \"Pepperoni pizza is better than apple pie\"\n",
"have opposite meanings due to the word ordering.\n",
"* However, for some applications, ignoring the order of words can allow\n",
"us to train an efficient and still effective model.\n",
"* This approach is called Bag-of-words document model.\n",
"\n",
"#### Document embeddings\n",
"* Document embedding is created by summing up the embeddings of all words\n",
"in the document.\n",
"* If we don't know the embedding of some word, we can ignore that word."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Exercise**:\n",
"Complete the `get_document_embedding()` function.\n",
"* The function `get_document_embedding()` encodes entire document as a \"document\" embedding.\n",
"* It takes in a docoument (as a string) and a dictionary, `en_embeddings`\n",
"* It processes the document, and looks up the corresponding embedding of each word.\n",
"* It then sums them up and returns the sum of all word vectors of that processed tweet."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
You can handle missing words easier by using the `get()` method of the python dictionary instead of the bracket notation (i.e. \"[ ]\"). See more about it here
\n",
"
The default value for missing word should be the zero vector. Numpy will broadcast simple 0 scalar into a vector of zeros during the summation.
\n",
"
Alternatively, skip the addition if a word is not in the dictonary.
\n",
"
You can use your `process_tweet()` function which allows you to process the tweet. The function just takes in a tweet and returns a list of words.
\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C12 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def get_document_embedding(tweet, en_embeddings): \n",
" '''\n",
" Input:\n",
" - tweet: a string\n",
" - en_embeddings: a dictionary of word embeddings\n",
" Output:\n",
" - tweet_embedding: a\n",
" '''\n",
" doc_embedding = np.zeros(300)\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # process the document into a list of words (process the tweet)\n",
" processed_doc = process_tweet(tweet)\n",
" for word in processed_doc:\n",
" # add the word embedding to the running total for the document embedding\n",
" doc_embedding+=en_embeddings.get(word,0)\n",
" ### END CODE HERE ###\n",
" return doc_embedding\n"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([-0.00268555, -0.15378189, -0.55761719, -0.07216644, -0.32263184])"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# UNQ_C13 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# testing your function\n",
"custom_tweet = \"RT @Twitter @chapagain Hello There! Have a great day. :) #good #morning http://chapagain.com.np\"\n",
"\n",
"tweet_embedding = get_document_embedding(custom_tweet, en_embeddings_subset)\n",
"tweet_embedding[-5:]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected output**:\n",
"\n",
"```\n",
"array([-0.00268555, -0.15378189, -0.55761719, -0.07216644, -0.32263184])\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Store all document vectors into a dictionary\n",
"Now, let's store all the tweet embeddings into a dictionary.\n",
"Implement `get_document_vecs()`"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C14 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def get_document_vecs(all_docs, en_embeddings):\n",
" '''\n",
" Input:\n",
" - all_docs: list of strings - all tweets in our dataset.\n",
" - en_embeddings: dictionary with words as the keys and their embeddings as the values.\n",
" Output:\n",
" - document_vec_matrix: matrix of tweet embeddings.\n",
" - ind2Doc_dict: dictionary with indices of tweets in vecs as keys and their embeddings as the values.\n",
" '''\n",
"\n",
" # the dictionary's key is an index (integer) that identifies a specific tweet\n",
" # the value is the document embedding for that document\n",
" ind2Doc_dict = {}\n",
"\n",
" # this is list that will store the document vectors\n",
" document_vec_l = []\n",
"\n",
" for i, doc in enumerate(all_docs):\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # get the document embedding of the tweet\n",
" doc_embedding = get_document_embedding(doc,en_embeddings)\n",
"\n",
" # save the document embedding into the ind2Tweet dictionary at index i\n",
" ind2Doc_dict[i] = doc_embedding\n",
"\n",
" # append the document embedding to the list of document vectors\n",
" document_vec_l.append(doc_embedding)\n",
"\n",
" ### END CODE HERE ###\n",
"\n",
" # convert the list of document vectors into a 2D array (each row is a document vector)\n",
" document_vec_matrix = np.vstack(document_vec_l)\n",
"\n",
" return document_vec_matrix, ind2Doc_dict\n"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [],
"source": [
"document_vecs, ind2Tweet = get_document_vecs(all_tweets, en_embeddings_subset)"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"length of dictionary 10000\n",
"shape of document_vecs (10000, 300)\n"
]
}
],
"source": [
"# UNQ_C15 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"print(f\"length of dictionary {len(ind2Tweet)}\")\n",
"print(f\"shape of document_vecs {document_vecs.shape}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Expected Output\n",
"```\n",
"length of dictionary 10000\n",
"shape of document_vecs (10000, 300)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.3 Looking up the tweets.\n",
"\n",
"Now you have a vector of dimension (m,d) where `m` is the number of tweets\n",
"(10,000) and `d` is the dimension of the embeddings (300). Now you\n",
"will input a tweet, and use cosine similarity to see which tweet in our\n",
"corpus is similar to your tweet."
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [],
"source": [
"my_tweet = 'i am sad'\n",
"process_tweet(my_tweet)\n",
"tweet_embedding = get_document_embedding(my_tweet, en_embeddings_subset)"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"@zoeeylim sad sad sad kid :( it's ok I help you watch the match HAHAHAHAHA\n"
]
}
],
"source": [
"# UNQ_C16 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# this gives you a similar tweet as your input.\n",
"# this implementation is vectorized...\n",
"idx = np.argmax(cosine_similarity(document_vecs, tweet_embedding))\n",
"print(all_tweets[idx])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Expected Output\n",
"\n",
"```\n",
"@zoeeylim sad sad sad kid :( it's ok I help you watch the match HAHAHAHAHA\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.4 Finding the most similar tweets with LSH\n",
"\n",
"You will now implement locality sensitive hashing (LSH) to identify the most similar tweet.\n",
"* Instead of looking at all 10,000 vectors, you can just search a subset to find\n",
"its nearest neighbors.\n",
"\n",
"Let's say your data points are plotted like this:\n",
"\n",
"\n",
"
Figure 3
\n",
"\n",
"You can divide the vector space into regions and search within one region for nearest neighbors of a given vector.\n",
"\n",
"
Figure 4
"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Number of vectors is 10000 and each has 300 dimensions.\n"
]
}
],
"source": [
"N_VECS = len(all_tweets) # This many vectors.\n",
"N_DIMS = len(ind2Tweet[1]) # Vector dimensionality.\n",
"print(f\"Number of vectors is {N_VECS} and each has {N_DIMS} dimensions.\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Choosing the number of planes\n",
"\n",
"* Each plane divides the space to $2$ parts.\n",
"* So $n$ planes divide the space into $2^{n}$ hash buckets.\n",
"* We want to organize 10,000 document vectors into buckets so that every bucket has about $~16$ planes.\n",
"* For that we need $\\frac{10000}{16}=625$ buckets.\n",
"* We're interested in $n$, number of planes, so that $2^{n}= 625$. Now, we can calculate $n=\\log_{2}625 = 9.29 \\approx 10$."
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [],
"source": [
"# The number of planes. We use log2(256) to have ~16 vectors/bucket.\n",
"N_PLANES = 10\n",
"# Number of times to repeat the hashing to improve the search.\n",
"N_UNIVERSES = 25"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.5 Getting the hash number for a vector\n",
"\n",
"For each vector, we need to get a unique number associated to that vector in order to assign it to a \"hash bucket\".\n",
"\n",
"### Hyperlanes in vector spaces\n",
"* In $3$-dimensional vector space, the hyperplane is a regular plane. In $2$ dimensional vector space, the hyperplane is a line.\n",
"* Generally, the hyperplane is subspace which has dimension $1$ lower than the original vector space has.\n",
"* A hyperplane is uniquely defined by its normal vector.\n",
"* Normal vector $n$ of the plane $\\pi$ is the vector to which all vectors in the plane $\\pi$ are orthogonal (perpendicular in $3$ dimensional case).\n",
"\n",
"### Using Hyperplanes to split the vector space\n",
"We can use a hyperplane to split the vector space into $2$ parts.\n",
"* All vectors whose dot product with a plane's normal vector is positive are on one side of the plane.\n",
"* All vectors whose dot product with the plane's normal vector is negative are on the other side of the plane.\n",
"\n",
"### Encoding hash buckets\n",
"* For a vector, we can take its dot product with all the planes, then encode this information to assign the vector to a single hash bucket.\n",
"* When the vector is pointing to the opposite side of the hyperplane than normal, encode it by 0.\n",
"* Otherwise, if the vector is on the same side as the normal vector, encode it by 1.\n",
"* If you calculate the dot product with each plane in the same order for every vector, you've encoded each vector's unique hash ID as a binary number, like [0, 1, 1, ... 0]."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Implementing hash buckets\n",
"\n",
"We've initialized hash table `hashes` for you. It is list of `N_UNIVERSES` matrices, each describes its own hash table. Each matrix has `N_DIMS` rows and `N_PLANES` columns. Every column of that matrix is a `N_DIMS`-dimensional normal vector for each of `N_PLANES` hyperplanes which are used for creating buckets of the particular hash table.\n",
"\n",
"*Exercise*: Your task is to complete the function `hash_value_of_vector` which places vector `v` in the correct hash bucket.\n",
"\n",
"* First multiply your vector `v`, with a corresponding plane. This will give you a vector of dimension $(1,\\text{N_planes})$.\n",
"* You will then convert every element in that vector to 0 or 1.\n",
"* You create a hash vector by doing the following: if the element is negative, it becomes a 0, otherwise you change it to a 1.\n",
"* You then compute the unique number for the vector by iterating over `N_PLANES`\n",
"* Then you multiply $2^i$ times the corresponding bit (0 or 1).\n",
"* You will then store that sum in the variable `hash_value`.\n",
"\n",
"**Intructions:** Create a hash for the vector in the function below.\n",
"Use this formula:\n",
"\n",
"$$ hash = \\sum_{i=0}^{N-1} \\left( 2^{i} \\times h_{i} \\right) $$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Create the sets of planes\n",
"* Create multiple (25) sets of planes (the planes that divide up the region).\n",
"* You can think of these as 25 separate ways of dividing up the vector space with a different set of planes.\n",
"* Each element of this list contains a matrix with 300 rows (the word vector have 300 dimensions), and 10 columns (there are 10 planes in each \"universe\")."
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [],
"source": [
"np.random.seed(0)\n",
"planes_l = [np.random.normal(size=(N_DIMS, N_PLANES))\n",
" for _ in range(N_UNIVERSES)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
numpy.squeeze() removes unused dimensions from an array; for instance, it converts a (10,1) 2D array into a (10,) 1D array
\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C17 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"def hash_value_of_vector(v, planes):\n",
" \"\"\"Create a hash for a vector; hash_id says which random hash to use.\n",
" Input:\n",
" - v: vector of tweet. It's dimension is (1, N_DIMS)\n",
" - planes: matrix of dimension (N_DIMS, N_PLANES) - the set of planes that divide up the region\n",
" Output:\n",
" - res: a number which is used as a hash for your vector\n",
"\n",
" \"\"\"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
" # for the set of planes,\n",
" # calculate the dot product between the vector and the matrix containing the planes\n",
" # remember that planes has shape (300, 10)\n",
" # The dot product will have the shape (1,10)\n",
" dot_product = np.dot(v,planes)\n",
" \n",
" # get the sign of the dot product (1,10) shaped vector\n",
" sign_of_dot_product = np.sign(dot_product)\n",
" \n",
" # set h to be false (eqivalent to 0 when used in operations) if the sign is negative,\n",
" # and true (equivalent to 1) if the sign is positive (1,10) shaped vector\n",
" h = sign_of_dot_product>=0\n",
"\n",
" # remove extra un-used dimensions (convert this from a 2D to a 1D array)\n",
" h = np.squeeze(h)\n",
"\n",
" # initialize the hash value to 0\n",
" hash_value = 0\n",
"\n",
" n_planes = planes.shape[1]\n",
" for i in range(n_planes):\n",
" # increment the hash value by 2^i * h_i\n",
" hash_value += np.power(2,i)*h[i]\n",
" ### END CODE HERE ###\n",
"\n",
" # cast hash_value as an integer\n",
" hash_value = int(hash_value)\n",
"\n",
" return hash_value\n"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" The hash value for this vector, and the set of planes at index 0, is 768\n"
]
}
],
"source": [
"# UNQ_C18 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"np.random.seed(0)\n",
"idx = 0\n",
"planes = planes_l[idx] # get one 'universe' of planes to test the function\n",
"vec = np.random.rand(1, 300)\n",
"print(f\" The hash value for this vector,\",\n",
" f\"and the set of planes at index {idx},\",\n",
" f\"is {hash_value_of_vector(vec, planes)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Expected Output\n",
"\n",
"```\n",
"The hash value for this vector, and the set of planes at index 0, is 768\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.5 Creating a hash table\n",
"\n",
"Given that you have a unique number for each vector (or tweet), You now want to create a hash table. You need a hash table, so that given a hash_id, you can quickly look up the corresponding vectors. This allows you to reduce your search by a significant amount of time.\n",
"\n",
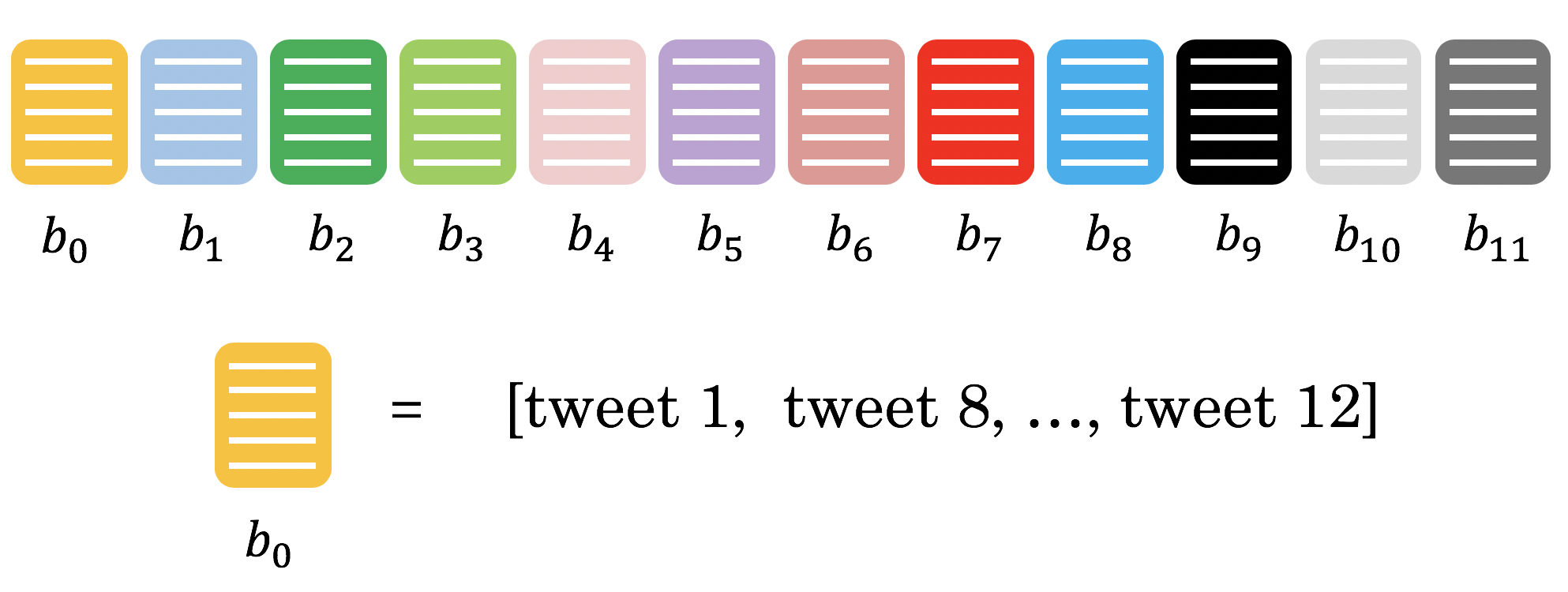
"
\n",
"\n",
"We have given you the `make_hash_table` function, which maps the tweet vectors to a bucket and stores the vector there. It returns the `hash_table` and the `id_table`. The `id_table` allows you know which vector in a certain bucket corresponds to what tweet."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
a dictionary comprehension, similar to a list comprehension, looks like this: `{i:0 for i in range(10)}`, where the key is 'i' and the value is zero for all key-value pairs.
\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C19 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# This is the code used to create a hash table: feel free to read over it\n",
"def make_hash_table(vecs, planes):\n",
" \"\"\"\n",
" Input:\n",
" - vecs: list of vectors to be hashed.\n",
" - planes: the matrix of planes in a single \"universe\", with shape (embedding dimensions, number of planes).\n",
" Output:\n",
" - hash_table: dictionary - keys are hashes, values are lists of vectors (hash buckets)\n",
" - id_table: dictionary - keys are hashes, values are list of vectors id's\n",
" (it's used to know which tweet corresponds to the hashed vector)\n",
" \"\"\"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
"\n",
" # number of planes is the number of columns in the planes matrix\n",
" num_of_planes = planes.shape[1]\n",
"\n",
" # number of buckets is 2^(number of planes)\n",
" num_buckets = 2**num_of_planes\n",
"\n",
" # create the hash table as a dictionary.\n",
" # Keys are integers (0,1,2.. number of buckets)\n",
" # Values are empty lists\n",
" hash_table = {i:[] for i in range(num_buckets)}\n",
"\n",
" # create the id table as a dictionary.\n",
" # Keys are integers (0,1,2... number of buckets)\n",
" # Values are empty lists\n",
" id_table = {i:[] for i in range(num_buckets)}\n",
"\n",
" # for each vector in 'vecs'\n",
" for i, v in enumerate(vecs):\n",
"\n",
" # calculate the hash value for the vector\n",
" h = hash_value_of_vector(v,planes)\n",
" #print(h)\n",
" #print('******')\n",
" # store the vector into hash_table at key h,\n",
" # by appending the vector v to the list at key h\n",
" hash_table[h].append(v)\n",
"\n",
" # store the vector's index 'i' (each document is given a unique integer 0,1,2...)\n",
" # the key is the h, and the 'i' is appended to the list at key h\n",
" id_table[h].append(i)\n",
"\n",
" ### END CODE HERE ###\n",
"\n",
" return hash_table, id_table\n"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(300, 10) \n",
"The hash table at key 0 has 3 document vectors\n",
"The id table at key 0 has 3\n",
"The first 5 document indices stored at key 0 of are [3276, 3281, 3282]\n"
]
}
],
"source": [
"# UNQ_C20 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"np.random.seed(0)\n",
"planes = planes_l[0] # get one 'universe' of planes to test the function\n",
"vec = np.random.rand(1, 300)\n",
"print(planes.shape,'')\n",
"\n",
"tmp_hash_table, tmp_id_table = make_hash_table(document_vecs, planes)\n",
"#print(tmp_hash_table[0])\n",
"#print(tmp_id_table[0])\n",
"print(f\"The hash table at key 0 has {len(tmp_hash_table[0])} document vectors\")\n",
"print(f\"The id table at key 0 has {len(tmp_id_table[0])}\")\n",
"print(f\"The first 5 document indices stored at key 0 of are {tmp_id_table[0][0:5]}\")\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Expected output\n",
"```\n",
"The hash table at key 0 has 3 document vectors\n",
"The id table at key 0 has 3\n",
"The first 5 document indices stored at key 0 of are [3276, 3281, 3282]\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.6 Creating all hash tables\n",
"\n",
"You can now hash your vectors and store them in a hash table that\n",
"would allow you to quickly look up and search for similar vectors.\n",
"Run the cell below to create the hashes. By doing so, you end up having\n",
"several tables which have all the vectors. Given a vector, you then\n",
"identify the buckets in all the tables. You can then iterate over the\n",
"buckets and consider much fewer vectors. The more buckets you use, the\n",
"more accurate your lookup will be, but also the longer it will take."
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"working on hash universe #: 0\n",
"working on hash universe #: 1\n",
"working on hash universe #: 2\n",
"working on hash universe #: 3\n",
"working on hash universe #: 4\n",
"working on hash universe #: 5\n",
"working on hash universe #: 6\n",
"working on hash universe #: 7\n",
"working on hash universe #: 8\n",
"working on hash universe #: 9\n",
"working on hash universe #: 10\n",
"working on hash universe #: 11\n",
"working on hash universe #: 12\n",
"working on hash universe #: 13\n",
"working on hash universe #: 14\n",
"working on hash universe #: 15\n",
"working on hash universe #: 16\n",
"working on hash universe #: 17\n",
"working on hash universe #: 18\n",
"working on hash universe #: 19\n",
"working on hash universe #: 20\n",
"working on hash universe #: 21\n",
"working on hash universe #: 22\n",
"working on hash universe #: 23\n",
"working on hash universe #: 24\n"
]
}
],
"source": [
"# Creating the hashtables\n",
"hash_tables = []\n",
"id_tables = []\n",
"for universe_id in range(N_UNIVERSES): # there are 25 hashes\n",
" print('working on hash universe #:', universe_id)\n",
" planes = planes_l[universe_id]\n",
" hash_table, id_table = make_hash_table(document_vecs, planes)\n",
" hash_tables.append(hash_table)\n",
" id_tables.append(id_table)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Approximate K-NN\n",
"\n",
"Implement approximate K nearest neighbors using locality sensitive hashing,\n",
"to search for documents that are similar to a given document at the\n",
"index `doc_id`.\n",
"\n",
"##### Inputs\n",
"* `doc_id` is the index into the document list `all_tweets`.\n",
"* `v` is the document vector for the tweet in `all_tweets` at index `doc_id`.\n",
"* `planes_l` is the list of planes (the global variable created earlier).\n",
"* `k` is the number of nearest neighbors to search for.\n",
"* `num_universes_to_use`: to save time, we can use fewer than the total\n",
"number of available universes. By default, it's set to `N_UNIVERSES`,\n",
"which is $25$ for this assignment.\n",
"\n",
"The `approximate_knn` function finds a subset of candidate vectors that\n",
"are in the same \"hash bucket\" as the input vector 'v'. Then it performs\n",
"the usual k-nearest neighbors search on this subset (instead of searching\n",
"through all 10,000 tweets)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
" Hints\n",
"\n",
"
\n",
"
\n",
"
There are many dictionaries used in this function. Try to print out planes_l, hash_tables, id_tables to understand how they are structured, what the keys represent, and what the values contain.
\n",
"
To remove an item from a list, use `.remove()`
\n",
"
To append to a list, use `.append()`
\n",
"
To add to a set, use `.add()`
\n",
"
\n",
""
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C21 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# This is the code used to do the fast nearest neighbor search. Feel free to go over it\n",
"def approximate_knn(doc_id, v, planes_l, k=1, num_universes_to_use=N_UNIVERSES):\n",
" \"\"\"Search for k-NN using hashes.\"\"\"\n",
" assert num_universes_to_use <= N_UNIVERSES\n",
"\n",
" # Vectors that will be checked as p0ossible nearest neighbor\n",
" vecs_to_consider_l = list()\n",
"\n",
" # list of document IDs\n",
" ids_to_consider_l = list()\n",
"\n",
" # create a set for ids to consider, for faster checking if a document ID already exists in the set\n",
" ids_to_consider_set = set()\n",
"\n",
" # loop through the universes of planes\n",
" for universe_id in range(num_universes_to_use):\n",
"\n",
" # get the set of planes from the planes_l list, for this particular universe_id\n",
" planes = planes_l[universe_id]\n",
"\n",
" # get the hash value of the vector for this set of planes\n",
" hash_value = hash_value_of_vector(v, planes)\n",
"\n",
" # get the hash table for this particular universe_id\n",
" hash_table = hash_tables[universe_id]\n",
"\n",
" # get the list of document vectors for this hash table, where the key is the hash_value\n",
" document_vectors_l = hash_table[hash_value]\n",
"\n",
" # get the id_table for this particular universe_id\n",
" id_table = id_tables[universe_id]\n",
"\n",
" # get the subset of documents to consider as nearest neighbors from this id_table dictionary\n",
" new_ids_to_consider = id_table[hash_value]\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n",
"\n",
" # remove the id of the document that we're searching\n",
" if doc_id in new_ids_to_consider:\n",
" new_ids_to_consider.remove(doc_id)\n",
" print(f\"removed doc_id {doc_id} of input vector from new_ids_to_search\")\n",
"\n",
" # loop through the subset of document vectors to consider\n",
" for i, new_id in enumerate(new_ids_to_consider):\n",
"\n",
" # if the document ID is not yet in the set ids_to_consider...\n",
" if new_id not in ids_to_consider_set:\n",
" # access document_vectors_l list at index i to get the embedding\n",
" # then append it to the list of vectors to consider as possible nearest neighbors\n",
" document_vector_at_i = document_vectors_l[i]\n",
" \n",
"\n",
" # append the new_id (the index for the document) to the list of ids to consider\n",
" vecs_to_consider_l.append(document_vector_at_i)\n",
" ids_to_consider_l.append(new_id)\n",
" # also add the new_id to the set of ids to consider\n",
" # (use this to check if new_id is not already in the IDs to consider)\n",
" ids_to_consider_set.add(new_id)\n",
"\n",
" ### END CODE HERE ###\n",
"\n",
" # Now run k-NN on the smaller set of vecs-to-consider.\n",
" print(\"Fast considering %d vecs\" % len(vecs_to_consider_l))\n",
"\n",
" # convert the vecs to consider set to a list, then to a numpy array\n",
" vecs_to_consider_arr = np.array(vecs_to_consider_l)\n",
"\n",
" # call nearest neighbors on the reduced list of candidate vectors\n",
" nearest_neighbor_idx_l = nearest_neighbor(v, vecs_to_consider_arr, k=k)\n",
" print(nearest_neighbor_idx_l)\n",
" print(ids_to_consider_l)\n",
" # Use the nearest neighbor index list as indices into the ids to consider\n",
" # create a list of nearest neighbors by the document ids\n",
" nearest_neighbor_ids = [ids_to_consider_l[idx]\n",
" for idx in nearest_neighbor_idx_l]\n",
"\n",
" return nearest_neighbor_ids\n"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {},
"outputs": [],
"source": [
"#document_vecs, ind2Tweet\n",
"doc_id = 0\n",
"doc_to_search = all_tweets[doc_id]\n",
"vec_to_search = document_vecs[doc_id]"
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"removed doc_id 0 of input vector from new_ids_to_search\n",
"removed doc_id 0 of input vector from new_ids_to_search\n",
"removed doc_id 0 of input vector from new_ids_to_search\n",
"removed doc_id 0 of input vector from new_ids_to_search\n",
"removed doc_id 0 of input vector from new_ids_to_search\n",
"Fast considering 77 vecs\n",
"[26 8 0]\n",
"[51, 105, 154, 160, 195, 253, 1876, 2478, 701, 1205, 1300, 1581, 1681, 1685, 2714, 4149, 4157, 4232, 4753, 5684, 6821, 9239, 213, 339, 520, 1729, 2140, 2786, 3028, 3162, 3259, 3654, 4002, 4047, 5263, 5492, 5538, 5649, 5656, 5729, 7076, 9063, 9207, 9789, 9927, 207, 254, 1302, 1480, 1815, 2298, 2620, 2741, 3525, 3837, 4704, 4871, 5327, 5386, 5923, 6033, 6371, 6762, 7288, 7472, 7774, 7790, 7947, 8061, 8224, 8276, 8892, 9096, 9153, 9175, 9323, 9740]\n"
]
}
],
"source": [
"# UNQ_C22 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n",
"# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n",
"\n",
"# Sample\n",
"nearest_neighbor_ids = approximate_knn(doc_id, vec_to_search, planes_l, k=3, num_universes_to_use=5)"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Nearest neighbors for document 0\n",
"Document contents: #FollowFriday @France_Inte @PKuchly57 @Milipol_Paris for being top engaged members in my community this week :)\n",
"\n",
"Nearest neighbor at document id 2140\n",
"document contents: @PopsRamjet come one, every now and then is not so bad :)\n",
"Nearest neighbor at document id 701\n",
"document contents: With the top cutie of Bohol :) https://t.co/Jh7F6U46UB\n",
"Nearest neighbor at document id 51\n",
"document contents: #FollowFriday @France_Espana @reglisse_menthe @CCI_inter for being top engaged members in my community this week :)\n"
]
}
],
"source": [
"print(f\"Nearest neighbors for document {doc_id}\")\n",
"print(f\"Document contents: {doc_to_search}\")\n",
"print(\"\")\n",
"\n",
"for neighbor_id in nearest_neighbor_ids:\n",
" print(f\"Nearest neighbor at document id {neighbor_id}\")\n",
" print(f\"document contents: {all_tweets[neighbor_id]}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4 Conclusion\n",
"Congratulations - Now you can look up vectors that are similar to the\n",
"encoding of your tweet using LSH!"
]
}
],
"metadata": {
"coursera": {
"schema_names": [
"NLPC1-4"
]
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.1"
}
},
"nbformat": 4,
"nbformat_minor": 1
}
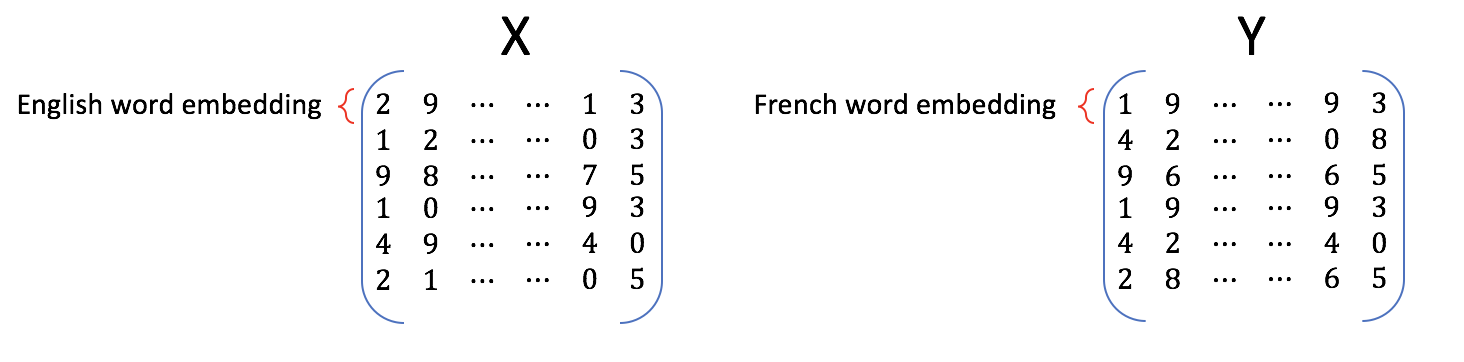 Figure 2
Figure 2  Figure 1
Figure 1  Figure 3
Figure 3 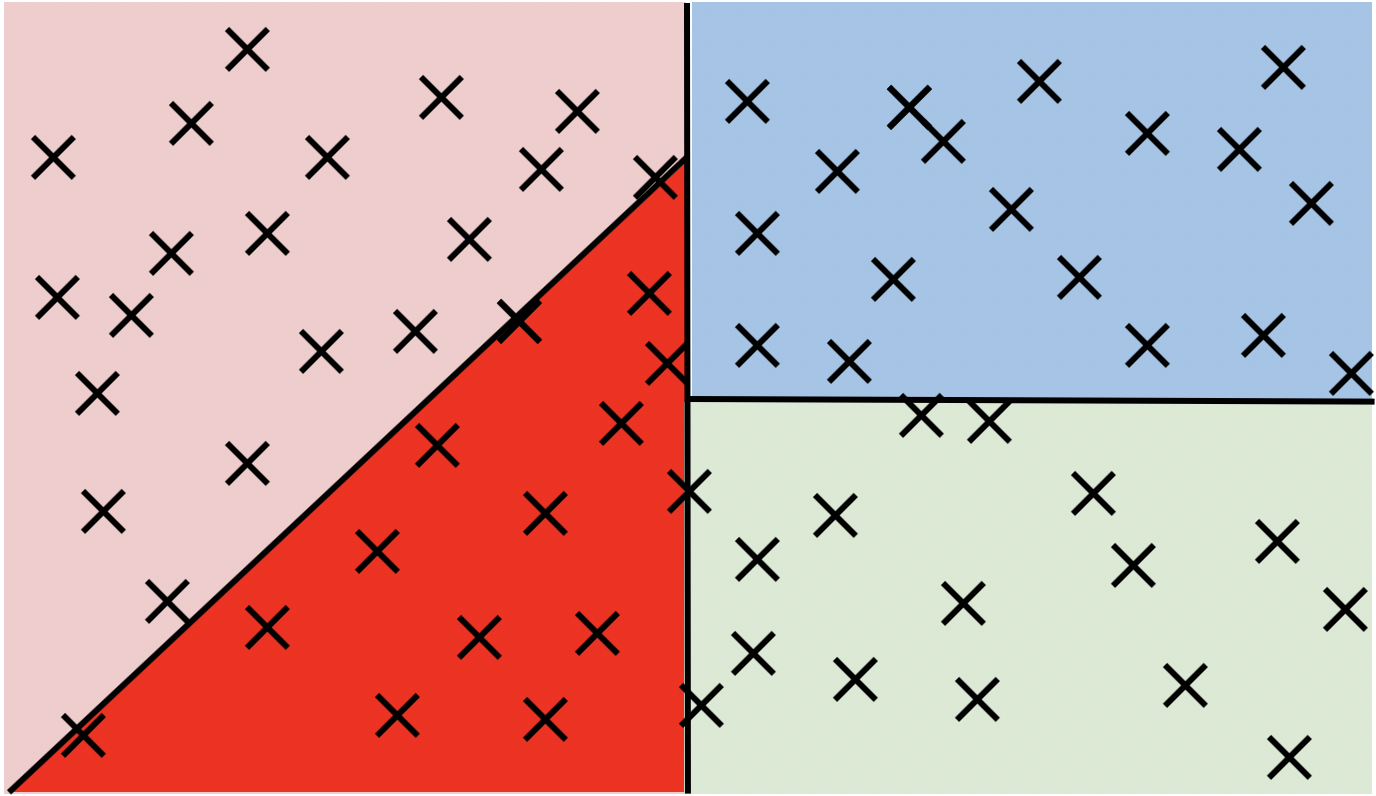 Figure 4
Figure 4