{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Modified Triplet Loss : Ungraded Lecture Notebook\n",
"In this notebook you'll see how to calculate the full triplet loss, step by step, including the mean negative and the closest negative. You'll also calculate the matrix of similarity scores.\n",
"\n",
"## Background\n",
"This is the original triplet loss function:\n",
"\n",
"$\\mathcal{L_\\mathrm{Original}} = \\max{(\\mathrm{s}(A,N) -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"It can be improved by including the mean negative and the closest negative, to create a new full loss function. The inputs are the Anchor $\\mathrm{A}$, Positive $\\mathrm{P}$ and Negative $\\mathrm{N}$.\n",
"\n",
"$\\mathcal{L_\\mathrm{1}} = \\max{(mean\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{2}} = \\max{(closest\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{Full}} = \\mathcal{L_\\mathrm{1}} + \\mathcal{L_\\mathrm{2}}$\n",
"\n",
"Let me show you what that means exactly, and how to calculate each step.\n",
"\n",
"## Imports"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Similarity Scores\n",
"The first step is to calculate the matrix of similarity scores using cosine similarity so that you can look up $\\mathrm{s}(A,P)$, $\\mathrm{s}(A,N)$ as needed for the loss formulas.\n",
"\n",
"### Two Vectors\n",
"First I'll show you how to calculate the similarity score, using cosine similarity, for 2 vectors.\n",
"\n",
"$\\mathrm{s}(v_1,v_2) = \\mathrm{cosine \\ similarity}(v_1,v_2) = \\frac{v_1 \\cdot v_2}{||v_1||~||v_2||}$\n",
"* Try changing the values in the second vector to see how it changes the cosine similarity.\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Inputs --\n",
"v1 : [1. 2. 3.]\n",
"v2 : [1. 2. 3.5] \n",
"\n",
"-- Outputs --\n",
"cosine similarity : 0.9974086507360697\n"
]
}
],
"source": [
"# Two vector example\n",
"# Input data\n",
"print(\"-- Inputs --\")\n",
"v1 = np.array([1, 2, 3], dtype=float)\n",
"v2 = np.array([1, 2, 3.5]) # notice the 3rd element is offset by 0.5\n",
"### START CODE HERE ###\n",
"# Try modifying the vector v2 to see how it impacts the cosine similarity\n",
"# v2 = v1 # identical vector\n",
"# v2 = v1 * -1 # opposite vector\n",
"# v2 = np.array([0,-42,1]) # random example\n",
"### END CODE HERE ###\n",
"print(\"v1 :\", v1)\n",
"print(\"v2 :\", v2, \"\\n\")\n",
"\n",
"# Similarity score\n",
"def cosine_similarity(v1, v2):\n",
" numerator = np.dot(v1, v2)\n",
" denominator = np.sqrt(np.dot(v1, v1)) * np.sqrt(np.dot(v2, v2))\n",
" return numerator / denominator\n",
"\n",
"print(\"-- Outputs --\")\n",
"print(\"cosine similarity :\", cosine_similarity(v1, v2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Two Batches of Vectors\n",
"Now i'll show you how to calculate the similarity scores, using cosine similarity, for 2 batches of vectors. These are rows of individual vectors, just like in the example above, but stacked vertically into a matrix. They would look like the image below for a batch size (row count) of 4 and embedding size (column count) of 5.\n",
"\n",
"The data is setup so that $v_{1\\_1}$ and $v_{2\\_1}$ represent duplicate inputs, but they are not duplicates with any other rows in the batch. This means $v_{1\\_1}$ and $v_{2\\_1}$ (green and green) have more similar vectors than say $v_{1\\_1}$ and $v_{2\\_2}$ (green and magenta).\n",
"\n",
"I'll show you two different methods for calculating the matrix of similarities from 2 batches of vectors.\n",
"\n",
"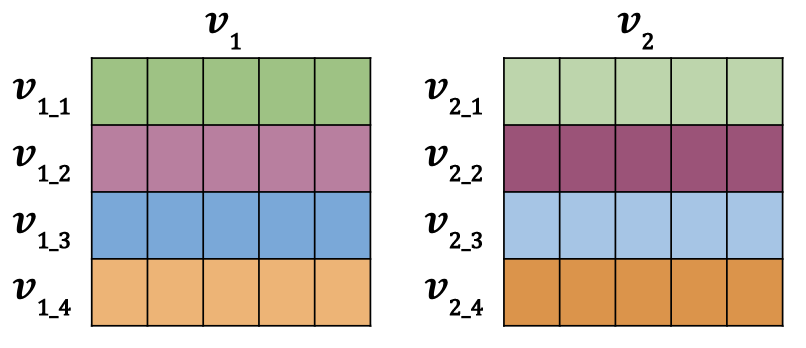 "
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"lines_to_next_cell": 2,
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Inputs --\n",
"v1 :\n",
"[[ 1 2 3]\n",
" [ 9 8 7]\n",
" [-1 -4 -2]\n",
" [ 1 -7 2]] \n",
"\n",
"v2 :\n",
"[[ 3.05355692 5.33818771 3.78698539]\n",
" [10.83986411 9.50985774 8.49505888]\n",
" [-6.85966066 -2.24826935 -0.47195371]\n",
" [ 1.1661863 -5.28159625 3.93834295]] \n",
"\n",
"batch sizes match : True \n",
"\n",
"-- Outputs --\n",
"option 1 : loop\n",
"[[ 0.92848755 0.8837943 -0.47185833 0.09658801]\n",
" [ 0.96124381 0.99996737 -0.82400906 -0.04494739]\n",
" [-0.96626591 -0.85884122 0.50667279 0.39410361]\n",
" [-0.50383127 -0.31498546 0.14925448 0.93588049]] \n",
"\n",
"option 2 : vec norm & dot product\n",
"[[ 0.92848755 0.8837943 -0.47185833 0.09658801]\n",
" [ 0.96124381 0.99996737 -0.82400906 -0.04494739]\n",
" [-0.96626591 -0.85884122 0.50667279 0.39410361]\n",
" [-0.50383127 -0.31498546 0.14925448 0.93588049]] \n",
"\n",
"outputs are the same : True\n"
]
}
],
"source": [
"# Two batches of vectors example\n",
"# Input data\n",
"print(\"-- Inputs --\")\n",
"v1_1 = np.array([1, 2, 3])\n",
"v1_2 = np.array([9, 8, 7])\n",
"v1_3 = np.array([-1, -4, -2])\n",
"v1_4 = np.array([1, -7, 2])\n",
"v1 = np.vstack([v1_1, v1_2, v1_3, v1_4])\n",
"print(\"v1 :\")\n",
"print(v1, \"\\n\")\n",
"v2_1 = v1_1 + np.random.normal(0, 2, 3) # add some noise to create approximate duplicate\n",
"v2_2 = v1_2 + np.random.normal(0, 2, 3)\n",
"v2_3 = v1_3 + np.random.normal(0, 2, 3)\n",
"v2_4 = v1_4 + np.random.normal(0, 2, 3)\n",
"v2 = np.vstack([v2_1, v2_2, v2_3, v2_4])\n",
"print(\"v2 :\")\n",
"print(v2, \"\\n\")\n",
"\n",
"# Batch sizes must match\n",
"b = len(v1)\n",
"print(\"batch sizes match :\", b == len(v2), \"\\n\")\n",
"\n",
"# Similarity scores\n",
"print(\"-- Outputs --\")\n",
"# Option 1 : nested loops and the cosine similarity function\n",
"sim_1 = np.zeros([b, b]) # empty array to take similarity scores\n",
"# Loop\n",
"for row in range(0, sim_1.shape[0]):\n",
" for col in range(0, sim_1.shape[1]):\n",
" sim_1[row, col] = cosine_similarity(v1[row], v2[col])\n",
"\n",
"print(\"option 1 : loop\")\n",
"print(sim_1, \"\\n\")\n",
"\n",
"# Option 2 : vector normalization and dot product\n",
"def norm(x):\n",
" return x / np.sqrt(np.sum(x * x, axis=1, keepdims=True))\n",
"\n",
"sim_2 = np.dot(norm(v1), norm(v2).T)\n",
"\n",
"print(\"option 2 : vec norm & dot product\")\n",
"print(sim_2, \"\\n\")\n",
"\n",
"# Check\n",
"print(\"outputs are the same :\", np.allclose(sim_1, sim_2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Hard Negative Mining\n",
"\n",
"I'll now show you how to calculate the mean negative $mean\\_neg$ and the closest negative $close\\_neg$ used in calculating $\\mathcal{L_\\mathrm{1}}$ and $\\mathcal{L_\\mathrm{2}}$.\n",
"\n",
"\n",
"$\\mathcal{L_\\mathrm{1}} = \\max{(mean\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{2}} = \\max{(closest\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"You'll do this using the matrix of similarity scores you already know how to make, like the example below for a batch size of 4. The diagonal of the matrix contains all the $\\mathrm{s}(A,P)$ values, similarities from duplicate question pairs (aka Positives). This is an important attribute for the calculations to follow.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"lines_to_next_cell": 2,
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Inputs --\n",
"v1 :\n",
"[[ 1 2 3]\n",
" [ 9 8 7]\n",
" [-1 -4 -2]\n",
" [ 1 -7 2]] \n",
"\n",
"v2 :\n",
"[[ 3.05355692 5.33818771 3.78698539]\n",
" [10.83986411 9.50985774 8.49505888]\n",
" [-6.85966066 -2.24826935 -0.47195371]\n",
" [ 1.1661863 -5.28159625 3.93834295]] \n",
"\n",
"batch sizes match : True \n",
"\n",
"-- Outputs --\n",
"option 1 : loop\n",
"[[ 0.92848755 0.8837943 -0.47185833 0.09658801]\n",
" [ 0.96124381 0.99996737 -0.82400906 -0.04494739]\n",
" [-0.96626591 -0.85884122 0.50667279 0.39410361]\n",
" [-0.50383127 -0.31498546 0.14925448 0.93588049]] \n",
"\n",
"option 2 : vec norm & dot product\n",
"[[ 0.92848755 0.8837943 -0.47185833 0.09658801]\n",
" [ 0.96124381 0.99996737 -0.82400906 -0.04494739]\n",
" [-0.96626591 -0.85884122 0.50667279 0.39410361]\n",
" [-0.50383127 -0.31498546 0.14925448 0.93588049]] \n",
"\n",
"outputs are the same : True\n"
]
}
],
"source": [
"# Two batches of vectors example\n",
"# Input data\n",
"print(\"-- Inputs --\")\n",
"v1_1 = np.array([1, 2, 3])\n",
"v1_2 = np.array([9, 8, 7])\n",
"v1_3 = np.array([-1, -4, -2])\n",
"v1_4 = np.array([1, -7, 2])\n",
"v1 = np.vstack([v1_1, v1_2, v1_3, v1_4])\n",
"print(\"v1 :\")\n",
"print(v1, \"\\n\")\n",
"v2_1 = v1_1 + np.random.normal(0, 2, 3) # add some noise to create approximate duplicate\n",
"v2_2 = v1_2 + np.random.normal(0, 2, 3)\n",
"v2_3 = v1_3 + np.random.normal(0, 2, 3)\n",
"v2_4 = v1_4 + np.random.normal(0, 2, 3)\n",
"v2 = np.vstack([v2_1, v2_2, v2_3, v2_4])\n",
"print(\"v2 :\")\n",
"print(v2, \"\\n\")\n",
"\n",
"# Batch sizes must match\n",
"b = len(v1)\n",
"print(\"batch sizes match :\", b == len(v2), \"\\n\")\n",
"\n",
"# Similarity scores\n",
"print(\"-- Outputs --\")\n",
"# Option 1 : nested loops and the cosine similarity function\n",
"sim_1 = np.zeros([b, b]) # empty array to take similarity scores\n",
"# Loop\n",
"for row in range(0, sim_1.shape[0]):\n",
" for col in range(0, sim_1.shape[1]):\n",
" sim_1[row, col] = cosine_similarity(v1[row], v2[col])\n",
"\n",
"print(\"option 1 : loop\")\n",
"print(sim_1, \"\\n\")\n",
"\n",
"# Option 2 : vector normalization and dot product\n",
"def norm(x):\n",
" return x / np.sqrt(np.sum(x * x, axis=1, keepdims=True))\n",
"\n",
"sim_2 = np.dot(norm(v1), norm(v2).T)\n",
"\n",
"print(\"option 2 : vec norm & dot product\")\n",
"print(sim_2, \"\\n\")\n",
"\n",
"# Check\n",
"print(\"outputs are the same :\", np.allclose(sim_1, sim_2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Hard Negative Mining\n",
"\n",
"I'll now show you how to calculate the mean negative $mean\\_neg$ and the closest negative $close\\_neg$ used in calculating $\\mathcal{L_\\mathrm{1}}$ and $\\mathcal{L_\\mathrm{2}}$.\n",
"\n",
"\n",
"$\\mathcal{L_\\mathrm{1}} = \\max{(mean\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{2}} = \\max{(closest\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"You'll do this using the matrix of similarity scores you already know how to make, like the example below for a batch size of 4. The diagonal of the matrix contains all the $\\mathrm{s}(A,P)$ values, similarities from duplicate question pairs (aka Positives). This is an important attribute for the calculations to follow.\n",
"\n",
"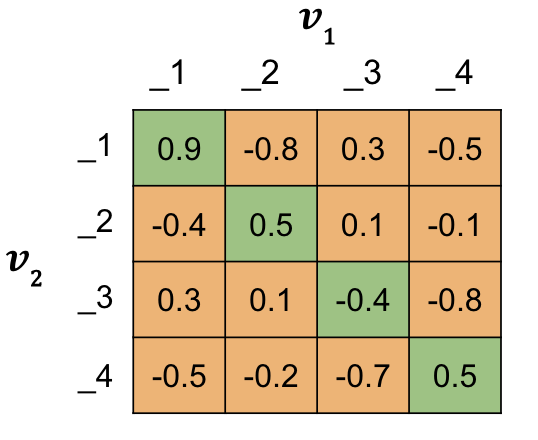 \n",
"\n",
"\n",
"### Mean Negative\n",
"$mean\\_neg$ is the average of the off diagonals, the $\\mathrm{s}(A,N)$ values, for each row.\n",
"\n",
"### Closest Negative\n",
"$closest\\_neg$ is the largest off diagonal value, $\\mathrm{s}(A,N)$, that is smaller than the diagonal $\\mathrm{s}(A,P)$ for each row.\n",
"* Try using a different matrix of similarity scores. "
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Inputs --\n",
"sim :\n",
"[[ 0.9 -0.8 0.3 -0.5]\n",
" [-0.4 0.5 0.1 -0.1]\n",
" [ 0.3 0.1 -0.4 -0.8]\n",
" [-0.5 -0.2 -0.7 0.5]]\n",
"shape : (4, 4) \n",
"\n",
"sim_ap :\n",
"[[ 0.9 0. 0. 0. ]\n",
" [ 0. 0.5 0. 0. ]\n",
" [ 0. 0. -0.4 0. ]\n",
" [ 0. 0. 0. 0.5]] \n",
"\n",
"sim_an :\n",
"[[ 0. -0.8 0.3 -0.5]\n",
" [-0.4 0. 0.1 -0.1]\n",
" [ 0.3 0.1 0. -0.8]\n",
" [-0.5 -0.2 -0.7 0. ]] \n",
"\n",
"-- Outputs --\n",
"mean_neg :\n",
"[[-0.33333333]\n",
" [-0.13333333]\n",
" [-0.13333333]\n",
" [-0.46666667]] \n",
"\n",
"closest_neg :\n",
"[[ 0.3]\n",
" [ 0.1]\n",
" [-0.8]\n",
" [-0.2]] \n",
"\n"
]
}
],
"source": [
"# Hardcoded matrix of similarity scores\n",
"sim_hardcoded = np.array(\n",
" [\n",
" [0.9, -0.8, 0.3, -0.5],\n",
" [-0.4, 0.5, 0.1, -0.1],\n",
" [0.3, 0.1, -0.4, -0.8],\n",
" [-0.5, -0.2, -0.7, 0.5],\n",
" ]\n",
")\n",
"\n",
"sim = sim_hardcoded\n",
"### START CODE HERE ###\n",
"# Try using different values for the matrix of similarity scores\n",
"# sim = 2 * np.random.random_sample((b,b)) -1 # random similarity scores between -1 and 1\n",
"# sim = sim_2 # the matrix calculated previously\n",
"### END CODE HERE ###\n",
"\n",
"# Batch size\n",
"b = sim.shape[0]\n",
"\n",
"print(\"-- Inputs --\")\n",
"print(\"sim :\")\n",
"print(sim)\n",
"print(\"shape :\", sim.shape, \"\\n\")\n",
"\n",
"# Positives\n",
"# All the s(A,P) values : similarities from duplicate question pairs (aka Positives)\n",
"# These are along the diagonal\n",
"sim_ap = np.diag(sim)\n",
"print(\"sim_ap :\")\n",
"print(np.diag(sim_ap), \"\\n\")\n",
"\n",
"# Negatives\n",
"# all the s(A,N) values : similarities the non duplicate question pairs (aka Negatives)\n",
"# These are in the off diagonals\n",
"sim_an = sim - np.diag(sim_ap)\n",
"print(\"sim_an :\")\n",
"print(sim_an, \"\\n\")\n",
"\n",
"print(\"-- Outputs --\")\n",
"# Mean negative\n",
"# Average of the s(A,N) values for each row\n",
"mean_neg = np.sum(sim_an, axis=1, keepdims=True) / (b - 1)\n",
"print(\"mean_neg :\")\n",
"print(mean_neg, \"\\n\")\n",
"\n",
"# Closest negative\n",
"# Max s(A,N) that is <= s(A,P) for each row\n",
"mask_1 = np.identity(b) == 1 # mask to exclude the diagonal\n",
"mask_2 = sim_an > sim_ap.reshape(b, 1) # mask to exclude sim_an > sim_ap\n",
"mask = mask_1 | mask_2\n",
"sim_an_masked = np.copy(sim_an) # create a copy to preserve sim_an\n",
"sim_an_masked[mask] = -2\n",
"\n",
"closest_neg = np.max(sim_an_masked, axis=1, keepdims=True)\n",
"print(\"closest_neg :\")\n",
"print(closest_neg, \"\\n\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The Loss Functions\n",
"\n",
"The last step is to calculate the loss functions.\n",
"\n",
"$\\mathcal{L_\\mathrm{1}} = \\max{(mean\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{2}} = \\max{(closest\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{Full}} = \\mathcal{L_\\mathrm{1}} + \\mathcal{L_\\mathrm{2}}$"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Outputs --\n",
"loss full :\n",
"[[0. ]\n",
" [0. ]\n",
" [0.51666667]\n",
" [0. ]] \n",
"\n",
"cost : 0.517\n"
]
}
],
"source": [
"# Alpha margin\n",
"alpha = 0.25\n",
"\n",
"# Modified triplet loss\n",
"# Loss 1\n",
"l_1 = np.maximum(mean_neg - sim_ap.reshape(b, 1) + alpha, 0)\n",
"# Loss 2\n",
"l_2 = np.maximum(closest_neg - sim_ap.reshape(b, 1) + alpha, 0)\n",
"# Loss full\n",
"l_full = l_1 + l_2\n",
"# Cost\n",
"cost = np.sum(l_full)\n",
"\n",
"print(\"-- Outputs --\")\n",
"print(\"loss full :\")\n",
"print(l_full, \"\\n\")\n",
"print(\"cost :\", \"{:.3f}\".format(cost))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Summary\n",
"There were a lot of steps in there, so well done. You now know how to calculate a modified triplet loss, incorporating the mean negative and the closest negative. You also learned how to create a matrix of similarity scores based on cosine similarity."
]
}
],
"metadata": {
"jupytext": {
"formats": "ipynb,py:percent",
"main_language": "python"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
\n",
"\n",
"\n",
"### Mean Negative\n",
"$mean\\_neg$ is the average of the off diagonals, the $\\mathrm{s}(A,N)$ values, for each row.\n",
"\n",
"### Closest Negative\n",
"$closest\\_neg$ is the largest off diagonal value, $\\mathrm{s}(A,N)$, that is smaller than the diagonal $\\mathrm{s}(A,P)$ for each row.\n",
"* Try using a different matrix of similarity scores. "
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Inputs --\n",
"sim :\n",
"[[ 0.9 -0.8 0.3 -0.5]\n",
" [-0.4 0.5 0.1 -0.1]\n",
" [ 0.3 0.1 -0.4 -0.8]\n",
" [-0.5 -0.2 -0.7 0.5]]\n",
"shape : (4, 4) \n",
"\n",
"sim_ap :\n",
"[[ 0.9 0. 0. 0. ]\n",
" [ 0. 0.5 0. 0. ]\n",
" [ 0. 0. -0.4 0. ]\n",
" [ 0. 0. 0. 0.5]] \n",
"\n",
"sim_an :\n",
"[[ 0. -0.8 0.3 -0.5]\n",
" [-0.4 0. 0.1 -0.1]\n",
" [ 0.3 0.1 0. -0.8]\n",
" [-0.5 -0.2 -0.7 0. ]] \n",
"\n",
"-- Outputs --\n",
"mean_neg :\n",
"[[-0.33333333]\n",
" [-0.13333333]\n",
" [-0.13333333]\n",
" [-0.46666667]] \n",
"\n",
"closest_neg :\n",
"[[ 0.3]\n",
" [ 0.1]\n",
" [-0.8]\n",
" [-0.2]] \n",
"\n"
]
}
],
"source": [
"# Hardcoded matrix of similarity scores\n",
"sim_hardcoded = np.array(\n",
" [\n",
" [0.9, -0.8, 0.3, -0.5],\n",
" [-0.4, 0.5, 0.1, -0.1],\n",
" [0.3, 0.1, -0.4, -0.8],\n",
" [-0.5, -0.2, -0.7, 0.5],\n",
" ]\n",
")\n",
"\n",
"sim = sim_hardcoded\n",
"### START CODE HERE ###\n",
"# Try using different values for the matrix of similarity scores\n",
"# sim = 2 * np.random.random_sample((b,b)) -1 # random similarity scores between -1 and 1\n",
"# sim = sim_2 # the matrix calculated previously\n",
"### END CODE HERE ###\n",
"\n",
"# Batch size\n",
"b = sim.shape[0]\n",
"\n",
"print(\"-- Inputs --\")\n",
"print(\"sim :\")\n",
"print(sim)\n",
"print(\"shape :\", sim.shape, \"\\n\")\n",
"\n",
"# Positives\n",
"# All the s(A,P) values : similarities from duplicate question pairs (aka Positives)\n",
"# These are along the diagonal\n",
"sim_ap = np.diag(sim)\n",
"print(\"sim_ap :\")\n",
"print(np.diag(sim_ap), \"\\n\")\n",
"\n",
"# Negatives\n",
"# all the s(A,N) values : similarities the non duplicate question pairs (aka Negatives)\n",
"# These are in the off diagonals\n",
"sim_an = sim - np.diag(sim_ap)\n",
"print(\"sim_an :\")\n",
"print(sim_an, \"\\n\")\n",
"\n",
"print(\"-- Outputs --\")\n",
"# Mean negative\n",
"# Average of the s(A,N) values for each row\n",
"mean_neg = np.sum(sim_an, axis=1, keepdims=True) / (b - 1)\n",
"print(\"mean_neg :\")\n",
"print(mean_neg, \"\\n\")\n",
"\n",
"# Closest negative\n",
"# Max s(A,N) that is <= s(A,P) for each row\n",
"mask_1 = np.identity(b) == 1 # mask to exclude the diagonal\n",
"mask_2 = sim_an > sim_ap.reshape(b, 1) # mask to exclude sim_an > sim_ap\n",
"mask = mask_1 | mask_2\n",
"sim_an_masked = np.copy(sim_an) # create a copy to preserve sim_an\n",
"sim_an_masked[mask] = -2\n",
"\n",
"closest_neg = np.max(sim_an_masked, axis=1, keepdims=True)\n",
"print(\"closest_neg :\")\n",
"print(closest_neg, \"\\n\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The Loss Functions\n",
"\n",
"The last step is to calculate the loss functions.\n",
"\n",
"$\\mathcal{L_\\mathrm{1}} = \\max{(mean\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{2}} = \\max{(closest\\_neg -\\mathrm{s}(A,P) +\\alpha, 0)}$\n",
"\n",
"$\\mathcal{L_\\mathrm{Full}} = \\mathcal{L_\\mathrm{1}} + \\mathcal{L_\\mathrm{2}}$"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-- Outputs --\n",
"loss full :\n",
"[[0. ]\n",
" [0. ]\n",
" [0.51666667]\n",
" [0. ]] \n",
"\n",
"cost : 0.517\n"
]
}
],
"source": [
"# Alpha margin\n",
"alpha = 0.25\n",
"\n",
"# Modified triplet loss\n",
"# Loss 1\n",
"l_1 = np.maximum(mean_neg - sim_ap.reshape(b, 1) + alpha, 0)\n",
"# Loss 2\n",
"l_2 = np.maximum(closest_neg - sim_ap.reshape(b, 1) + alpha, 0)\n",
"# Loss full\n",
"l_full = l_1 + l_2\n",
"# Cost\n",
"cost = np.sum(l_full)\n",
"\n",
"print(\"-- Outputs --\")\n",
"print(\"loss full :\")\n",
"print(l_full, \"\\n\")\n",
"print(\"cost :\", \"{:.3f}\".format(cost))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Summary\n",
"There were a lot of steps in there, so well done. You now know how to calculate a modified triplet loss, incorporating the mean negative and the closest negative. You also learned how to create a matrix of similarity scores based on cosine similarity."
]
}
],
"metadata": {
"jupytext": {
"formats": "ipynb,py:percent",
"main_language": "python"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}