). Licensed under [CC BY 4.0 Creative Commons](http://creativecommons.org/licenses/by/4.0/)*\n",
"\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline\n",
"\n",
"import pandas as pd\n",
"import geopandas"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"countries = geopandas.read_file(\"zip://./data/ne_110m_admin_0_countries.zip\")\n",
"cities = geopandas.read_file(\"zip://./data/ne_110m_populated_places.zip\")\n",
"rivers = geopandas.read_file(\"zip://./data/ne_50m_rivers_lake_centerlines.zip\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Spatial relationships\n",
"\n",
"An important aspect of geospatial data is that we can look at *spatial relationships*: how two spatial objects relate to each other (whether they overlap, intersect, contain, .. one another).\n",
"\n",
"The topological, set-theoretic relationships in GIS are typically based on the DE-9IM model. See https://en.wikipedia.org/wiki/Spatial_relation for more information.\n",
"\n",
"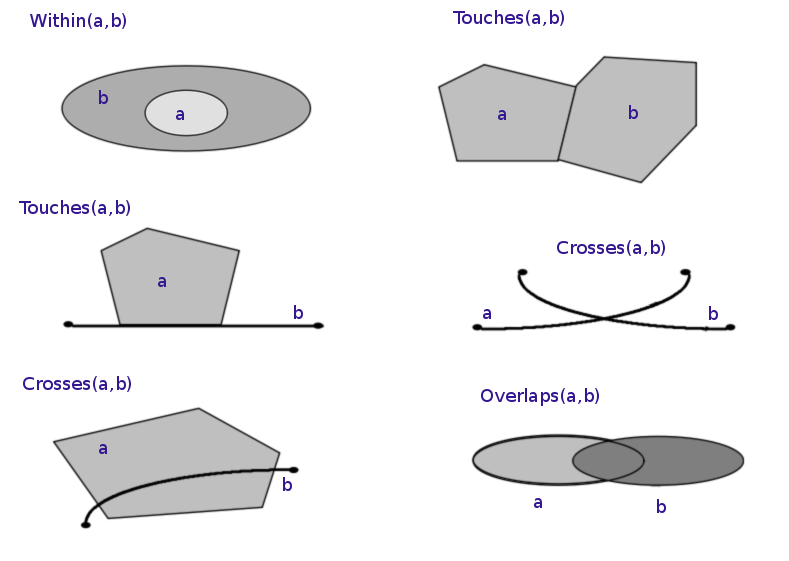\n",
"(Image by [Krauss, CC BY-SA 3.0](https://en.wikipedia.org/wiki/Spatial_relation#/media/File:TopologicSpatialRelarions2.png))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Relationships between individual objects"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's first create some small toy spatial objects:\n",
"\n",
"A polygon (note: we use `.item()` here to to extract the scalar geometry object from the GeoSeries of length 1):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"belgium = countries.loc[countries['name'] == 'Belgium', 'geometry'].item()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Two points:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"paris = cities.loc[cities['name'] == 'Paris', 'geometry'].item()\n",
"brussels = cities.loc[cities['name'] == 'Brussels', 'geometry'].item()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And a linestring:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from shapely.geometry import LineString\n",
"line = LineString([paris, brussels])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's visualize those 4 geometry objects together (I only put them in a GeoSeries to easily display them together with the geopandas `.plot()` method):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"geopandas.GeoSeries([belgium, paris, brussels, line]).plot(cmap='tab10')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can recognize the abstract shape of Belgium.\n",
"\n",
"Brussels, the capital of Belgium, is thus located within Belgium. This is a spatial relationship, and we can test this using the individual shapely geometry objects as follow:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"brussels.within(belgium)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And using the reverse, Belgium contains Brussels:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"belgium.contains(brussels)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"On the other hand, Paris is not located in Belgium:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"belgium.contains(paris)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"paris.within(belgium)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The straight line we draw from Paris to Brussels is not fully located within Belgium, but it does intersect with it:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"belgium.contains(line)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"line.intersects(belgium)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Spatial relationships with GeoDataFrames\n",
"\n",
"The same methods that are available on individual `shapely` geometries as we have seen above, are also available as methods on `GeoSeries` / `GeoDataFrame` objects.\n",
"\n",
"For example, if we call the `contains` method on the world dataset with the `paris` point, it will do this spatial check for each country in the `world` dataframe:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"countries.contains(paris)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Because the above gives us a boolean result, we can use that to filter the dataframe:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"countries[countries.contains(paris)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And indeed, France is the only country in the world in which Paris is located."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Another example, extracting the linestring of the Amazon river in South America, we can query through which countries the river flows:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"amazon = rivers[rivers['name'] == 'Amazonas'].geometry.item()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"countries[countries.crosses(amazon)] # or .intersects"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**REFERENCE**:\n",
"\n",
"Overview of the different functions to check spatial relationships (*spatial predicate functions*):\n",
"\n",
"* `equals`\n",
"* `contains`\n",
"* `crosses`\n",
"* `disjoint`\n",
"* `intersects`\n",
"* `overlaps`\n",
"* `touches`\n",
"* `within`\n",
"* `covers`\n",
"\n",
"\n",
"See https://shapely.readthedocs.io/en/stable/manual.html#predicates-and-relationships for an overview of those methods.\n",
"\n",
"See https://en.wikipedia.org/wiki/DE-9IM for all details on the semantics of those operations.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Let's practice!\n",
"\n",
"We will again use the Paris datasets to exercise. Let's start importing them again, and directly converting both to the local projected CRS:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"districts = geopandas.read_file(\"data/paris_districts.geojson\").to_crs(epsg=2154)\n",
"stations = geopandas.read_file(\"data/paris_bike_stations.geojson\").to_crs(epsg=2154)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: The Eiffel Tower**\n",
"\n",
"The Eiffel Tower is an iron lattice tower built in the 19th century, and is probably the most iconic view of Paris.\n",
"\n",
"The location of the Eiffel Tower is: x of 648237.3 and y of 6862271.9\n",
"\n",
"* Create a Shapely point object with the coordinates of the Eiffel Tower and assign it to a variable called `eiffel_tower`. Print the result.\n",
"* Check if the Eiffel Tower is located within the Montparnasse district (provided).\n",
"* Check if the Montparnasse district contains the bike station location.\n",
"* Calculate the distance between the Eiffel Tower and the bike station (note: in this case, the distance is returned in meters).\n",
"\n",
"\n",
"Hints
\n",
"\n",
"* The `Point` class is available in the `shapely.geometry` submodule\n",
"* Creating a point can be done by passing the x and y coordinates to the `Point()` constructor.\n",
"* The `within()` method checks if the object is located within the passed geometry (used as `geometry1.within(geometry2)`).\n",
"* The `contains()` method checks if the object contains the passed geometry (used as `geometry1.contains(geometry2)`).\n",
"* To calculate the distance between two geometries, the `distance()` method of one of the geometries can be used.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Import the Point geometry\n",
"from shapely.geometry import Point"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins1.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins2.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Accessing the Montparnasse geometry (Polygon)\n",
"district_montparnasse = districts.loc[52, 'geometry']\n",
"bike_station = stations.loc[293, 'geometry']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins3.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins4.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins5.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: In which district in the Eiffel Tower located?**\n",
"\n",
"In previous exercise, we constructed a `Point` geometry for its location, and we checked that it was not located in the Montparnasse district. Let's now determine in which of the districts of Paris it *is* located.\n",
"\n",
"* Create a boolean mask (or filter) indicating whether each district contains the Eiffel Tower or not. Call the result `mask`.\n",
"* Filter the `districts` dataframe with the boolean mask and print the result.\n",
"\n",
"\n",
"Hints
\n",
"\n",
"* To check for each polygon in the districts dataset if it contains a single point, we can use the `contains()` method of the `districts` GeoDataFrame.\n",
"* Filtering the rows of a DataFrame based on a condition can be done by passing the boolean mask into `df[..]`.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Construct a point object for the Eiffel Tower\n",
"eiffel_tower = Point(648237.3, 6862271.9)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins6.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins7.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: How far is the closest bike station?**\n",
"\n",
"Now, we might be interested in the bike stations nearby the Eiffel Tower. To explore them, let's visualize the Eiffel Tower itself as well as the bikes stations within 1km.\n",
"\n",
"To do this, we can calculate the distance to the Eiffel Tower for each of the stations. Based on this result, we can then create a mask that takes `True` if the station is within 1km, and `False` otherwise, and use it to filter the stations GeoDataFrame. Finally, we make a visualization of this subset.\n",
"\n",
"* Calculate the distance to the Eiffel Tower for each station, and call the result `dist_eiffel`.\n",
"* Print the distance to the closest station (which is the minimum of `dist_eiffel`).\n",
"* Select the rows the `stations` GeoDataFrame where the distance to the Eiffel Tower is less than 1 km (note that the distance is in meters). Call the result `stations_eiffel`.\n",
"\n",
"Hints
\n",
"\n",
"* The `.distance()` method of a GeoDataFrame works element-wise: it calculates the distance between each geometry in the GeoDataFrame and the geometry passed to the method.\n",
"* A Series has a `.min()` method to calculate the minimum value.\n",
"* To create a boolean mask based on a condition, we can do e.g. `s < 100`.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins8.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins9.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins10.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Make a plot of the close-by restaurants\n",
"ax = stations_eiffel.to_crs(epsg=3857).plot()\n",
"geopandas.GeoSeries([eiffel_tower], crs='EPSG:2154').to_crs(epsg=3857).plot(ax=ax, color='red')\n",
"import contextily\n",
"contextily.add_basemap(ax)\n",
"ax.set_axis_off()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Spatial joins"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"In the previous section of this notebook, we could use the spatial relationship methods to check in which country a certain city was located. But what if we wanted to perform this same operation for every city and country? For example, we might want to know for each city in which country it is located. \n",
"\n",
"In tabular jargon, this would imply adding a column to our cities dataframe with the name of the country in which it is located. Since country name is contained in the countries dataset, we need to combine - or \"join\" - information from both datasets. Joining on location (rather than on a shared column) is called a \"spatial join\".\n",
"\n",
"So here we will do:\n",
"\n",
"- Based on the `countries` and `cities` dataframes, determine for each city the country in which it is located.\n",
"- To solve this problem, we will use the the concept of a \"spatial join\" operation: combining information of geospatial datasets based on their spatial relationship."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Recap - joining dataframes\n",
"\n",
"Pandas provides functionality to join or merge dataframes in different ways, see https://chrisalbon.com/python/data_wrangling/pandas_join_merge_dataframe/ for an overview and https://pandas.pydata.org/pandas-docs/stable/merging.html for the full documentation."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To illustrate the concept of joining the information of two dataframes with pandas, let's take a small subset of our `cities` and `countries` datasets: "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cities2 = cities[cities['name'].isin(['Bern', 'Brussels', 'London', 'Paris'])].copy()\n",
"cities2['iso_a3'] = ['CHE', 'BEL', 'GBR', 'FRA']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cities2"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"countries2 = countries[['iso_a3', 'name', 'continent']]\n",
"countries2.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We added a 'iso_a3' column to the `cities` dataset, indicating a code of the country of the city. This country code is also present in the `countries` dataset, which allows us to merge those two dataframes based on the common column.\n",
"\n",
"Joining the `cities` dataframe with `countries` will transfer extra information about the countries (the full name, the continent) to the `cities` dataframe, based on a common key:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cities2.merge(countries2, on='iso_a3')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**But** for this illustrative example we added the common column manually, it is not present in the original dataset. However, we can still know how to join those two datasets based on their spatial coordinates."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Recap - spatial relationships between objects\n",
"\n",
"In the previous section, we have seen the notion of spatial relationships between geometry objects: within, contains, intersects, ...\n",
"\n",
"In this case, we know that each of the cities is located *within* one of the countries, or the other way around that each country can *contain* multiple cities.\n",
"\n",
"We can test such relationships using the methods we have seen in the previous notebook:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"france = countries.loc[countries['name'] == 'France', 'geometry'].squeeze()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cities.within(france)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The above gives us a boolean series, indicating for each point in our `cities` dataframe whether it is located within the area of France or not. \n",
"Because this is a boolean series as result, we can use it to filter the original dataframe to only show those cities that are actually within France:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cities[cities.within(france)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We could now repeat the above analysis for each of the countries, and add a column to the `cities` dataframe indicating this country. However, that would be tedious to do manually, and is also exactly what the spatial join operation provides us.\n",
"\n",
"*(note: the above result is incorrect, but this is just because of the coarse-ness of the countries dataset)*"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Spatial join operation\n",
"\n",
"\n",
" \n",
"**SPATIAL JOIN** = *transferring attributes from one layer to another based on their spatial relationship*
\n",
"\n",
"\n",
"Different parts of this operations:\n",
"\n",
"* The GeoDataFrame to which we want add information\n",
"* The GeoDataFrame that contains the information we want to add\n",
"* The spatial relationship we want to use to match both datasets ('intersects', 'contains', 'within')\n",
"* The type of join: left or inner join\n",
"\n",
"\n",
"\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "-"
}
},
"source": [
"In this case, we want to join the `cities` dataframe with the information of the `countries` dataframe, based on the spatial relationship between both datasets.\n",
"\n",
"We use the [`geopandas.sjoin`](http://geopandas.readthedocs.io/en/latest/reference/geopandas.sjoin.html) function:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"joined = geopandas.sjoin(cities, countries, op='within', how='left')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"joined"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"joined['continent'].value_counts()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Let's practice!\n",
"\n",
"We will again use the Paris datasets to do some exercises. Let's start importing them:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"districts = geopandas.read_file(\"data/paris_districts.geojson\").to_crs(epsg=2154)\n",
"stations = geopandas.read_file(\"data/paris_bike_stations.geojson\").to_crs(epsg=2154)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE:**\n",
"\n",
"* Determine for each bike station in which district it is located (using a spatial join!). Call the result `joined`.\n",
"\n",
"Hints
\n",
"\n",
"- The `geopandas.sjoin()` function takes as first argument the dataframe to which we want to add information, and as second argument the dataframe that contains this additional information.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins11.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins12.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: Map of tree density by district (I)**\n",
"\n",
"Using a dataset of all trees in public spaces in Paris, the goal is to make a map of the tree density by district. We first need to find out how many trees each district contains, which we will do in this exercise. In the following exercise, we will use this result to calculate the density and create a map.\n",
"\n",
"To obtain the tree count by district, we first need to know in which district each tree is located, which we can do with a spatial join. Then, using the result of the spatial join, we will calculate the number of trees located in each district using the pandas 'group-by' functionality.\n",
"\n",
"- Import the trees dataset `\"paris_trees.gpkg\"` and call the result `trees`. Also read the districts dataset we have seen previously (`\"paris_districts.geojson\"`), and call this `districts`. Convert the districts dataset to the same CRS as the trees dataset.\n",
"- Add a column with the `'district_name'` to the trees dataset using a spatial join. Call the result `joined`.\n",
"\n",
"Hints
\n",
"\n",
"- Remember, we can perform a spatial join with the `geopandas.sjoin()` function.\n",
"- `geopandas.sjoin()` takes as first argument the dataframe to which we want to add information, and as second argument the dataframe that contains this additional information.\n",
"- The `op` argument is used to specify which spatial relationship between both dataframes we want to use for joining (options are `'intersects'`, `'contains'`, `'within'`).\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins13.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins14.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins15.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: Map of tree density by district (II)**\n",
"\n",
"Calculate the number of trees located in each district: group the `joined` DataFrame by the `'district_name'` column, and calculate the size of each group. Call the resulting Series `trees_by_district`.
\n",
"\n",
"We then convert `trees_by_district` to a DataFrame for the next exercise.\n",
"\n",
"Hints
\n",
"\n",
"- The general group-by syntax in pandas is: `df.groupby('key').aggregation_method()`, substituting 'key' and 'aggregation_method' with the appropriate column name and method. \n",
"- To know the size of groups, we can use the `.size()` method.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins16.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins17.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins18.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"**EXERCISE: Map of tree density by district (III)**\n",
"\n",
"Now we have obtained the number of trees by district, we can make the map of the districts colored by the tree density.\n",
"\n",
"For this, we first need to merge the number of trees in each district we calculated in the previous step (`trees_by_district`) back to the districts dataset. We will use the [`pd.merge()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.merge.html) function to join two dataframes based on a common column.\n",
"\n",
"Since not all districts have the same size, we should compare the tree density for the visualisation: the number of trees relative to the area.\n",
"\n",
"- Use the `pd.merge()` function to merge `districts` and `trees_by_district` dataframes on the `'district_name'` column. Call the result `districts_trees`.\n",
"- Add a column `'n_trees_per_area'` to the `districts_trees` dataframe, based on the `'n_trees'` column divided by the area.\n",
"- Make a plot of the `districts_trees` dataframe, using the `'n_trees_per_area'` column to determine the color of the polygons.\n",
"\n",
"\n",
"Hints
\n",
"\n",
"- The pandas `pd.merge()` function takes the two dataframes you want to merge as the first two arguments.\n",
"- The column name on which you want to merge both datasets can be specified with the `on` keyword.\n",
"- Accessing a column of a DataFrame can be done with `df['col']`, while adding a column to a DataFrame can be done with `df['new_col'] = values` where `values` can be the result of a computation.\n",
"- Remember, the area of each geometry in a GeoSeries or GeoDataFrame can be retrieved using the `area` attribute. So considering a GeoDataFrame `gdf`, then `gdf.geometry.area` will return a Series with the area of each geometry.\n",
"- We can use the `.plot()` method of a GeoDataFrame to make a visualization of the geometries. \n",
"- For using one of the columns of the GeoDataFrame to determine the fill color, use the `column=` keyword.\n",
"\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins19.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins20.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"clear_cell": true
},
"outputs": [],
"source": [
"# %load _solutions/04-spatial-relationships-joins21.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
}
},
"nbformat": 4,
"nbformat_minor": 4
}