Analysing companies 10-Ks for changes to predict stock price movement¶
Introduction¶
Publicly traded companies in the United States are required by law to file reports with the Securities and Exchange Commission (SEC) on "10-K" and "10-Q." These reports include qualitative as well as quantitative explanations of the success of the business, from sales estimates to qualitative risk factors.
"Companies are required to disclose" important pending litigation or other legal proceedings "details. As such, 10-Ks and 10-Qs also provide useful insights into the success of a company. As such, 10-Ks and 10-Qs often hold valuable insights into a company's performance.
However, these observations can be hard to obtain. In 2013, the average 10-K was 42,000 words long. Beyond the sheer length, for many investors, dense terminology and tons of boilerplate will further obscure real sense.
In order to extract meaning from the data they contain, we do not need to read the 10-Ks of cover-to-cover businesses.
Hypothesis¶
When major things happen to their business, companies make major textual modifications to their 10-Ks . We consequently consider textual changes to 10-Ks to be a signal of the movement of future share prices.
Since the vast majority (86 percent) of textual changes have negative sentiment, we usually expect a decrease in stock price to be signaled by significant textual changes (Cohen et al . 2018).
Starting Rationale:¶
Major text changes in 10-K over time indicate significant decreases in future returns. We can short the companies with the largest text changes in their filings and long the companies with the smallest text changes in their filings.
Methodology¶
- Scrape the 10-K documents from the SEC EDGAR Database for a set of publicly traded firms. Upon scraping, we perform some basic data-cleaning and pre-processing for the 10-K document (removing HTML Tags and numerical tables, converting to txt files, lemmatisation, stemming, removing stop words, and so on).
- After pre-processing we analyse the textual data from one of the 10-K documents using Exploratory Data Analysis(EDA) techniques such as Bag of Words(BoW), TF_IDF, Wordcloud, LDA modeling with interactive pyLDAvis, Top 20 most frequently used words, and Positivity score of the 10-K document using Textblob library.
- For a particular company, we calculate the cosine similarity and the Jaccard similarity over the set of 10-Ks that were scraped(cosine and Jaccard similarity are relatively less computationally intensive to compute). We calculate the similarity by comparing each 10-K document with the previous year's 10-K and given it a score. We then calculate the difference between these similarity scores and compare this over the years.
- Try to map these text changes with the stock price movement for the firm. We download the prices of the stock from the first-time the 10-K document was available till the day the lasted 10-K document was filed. Upon carefully analysing, we can conclude as to whether the results align with the hypothesis or not.
# Importing built-in libraries
import os
import re
import unicodedata
from time import gmtime, strftime
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings("ignore")
# Importing libraries you need to install
import requests
from lxml import html
import bs4 as bs
from tqdm import tqdm
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
%matplotlib inline
import nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
from nltk.corpus import stopwords
from gensim import corpora
from gensim.models import TfidfModel, LdaMulticore
from wordcloud import WordCloud
import pyLDAvis.gensim
from datetime import datetime
from collections import Counter
import seaborn as sns
from textblob import TextBlob
import pandas_datareader.data as web
Scraping
Stock Tickers to CIK¶
stock_tickers = ["AMZN"] #for this example I am using the Amazon's Stock ticker, feel free to add many more stocks to the lists
The SEC indexes the filings of companies by means of its own internal identifier, the "Central Index Key"(CIK). We'll need to convert tickers into CIKs in order to find for business filings on EDGAR.
def TickerToCik(tickers): #helper function to convert ticker into CIK for SEC
_url = 'http://www.sec.gov/cgi-bin/browse-edgar?CIK={}&Find=Search&owner=exclude&action=getcompany'
cik_re = re.compile(r'.*CIK=(\d{10}).*') #checking for CIK = 10 digit number
dict = {}
for ticker in tqdm(tickers, desc='Mapping Tickers to CIK', unit=' Mappings'): # Use tqdm lib for progress bar
results = cik_re.findall(requests.get(_url.format(ticker)).text)
if len(results):
dict[str(ticker).lower()] = str(results[0]) #saving the in the format "AMZN" : '0001018724'
return dict
ciks = TickerToCik(stock_tickers)
ciks
Converting the Ticker with corresponding CIKs into a Dataframe¶
tick_cik_df = pd.DataFrame.from_dict(data=ciks, orient= 'index')
tick_cik_df.reset_index(inplace=True)
tick_cik_df.columns = ["ticker", "cik"]
tick_cik_df['cik'] = tick_cik_df['cik'].str.lower()
tick_cik_df
P.S: Some CIKs might be linked to multiple tickers. However for this scope of this project, I will not be checking the uniqueness of the ticker-cik pairing. Therefore please check manually if there are multiple tickers for the same cik.
Now with the list of CIKs, we would like to download the 10-Ks from the EDGAR database from the offical SEC website.
From past experiences, I had to ensure some technical considerations before proceeding:
- The SEC limits users to a maximum of 10 requests per second, so we need to make sure we're not making requests too quickly.
- When scrapping massive amount of information, it is very likely the scrapper will runing into am error or breaking. Trying to ensure we can continue from where the scrapper stops is one of the most important and efficient things to do inorder to ensure efficiency.
The function below scrapes all 10-Ks for one particular CIK. This web scraper primarily depends on the 'requests' and 'BeautifulSoup' libraries.
We will create different directory for each CIK, and puts all the filings for that CIK within that directory. After scraping, the file structure should look like this:
- 10Ks
- CIK1
- 10K #1
- 10K #2
...
- CIK2
- 10K #1
- 10K #2
...
...The scraper will create the directory for each CIK. However, we need to create different directories to hold our 10-K files.
Defining Paths¶
We need to create different directories to hold our 10-K and 10-Q files. The exact pathname depends on your local setup, so please enter your correct path in the below format.
path_10k = '/Users/amruth/Desktop/HKU/Academics/Year 4 Sem 1/FINA4350/Midterm Project/'
def makefolder(x):
try:
os.mkdir(x+"10Ks")
except:
print("Folder/Directory for 10K already created")
return path_10k+"10Ks"
path_10k = makefolder(path_10k) #helps in making the two folders 10Ks and 10Qs
Actual Scraping¶
Scrapes all 10-Ks for a particular CIK from EDGAR.
Step 1: Scrap the webpage that contains the table with 10K documents over the years.
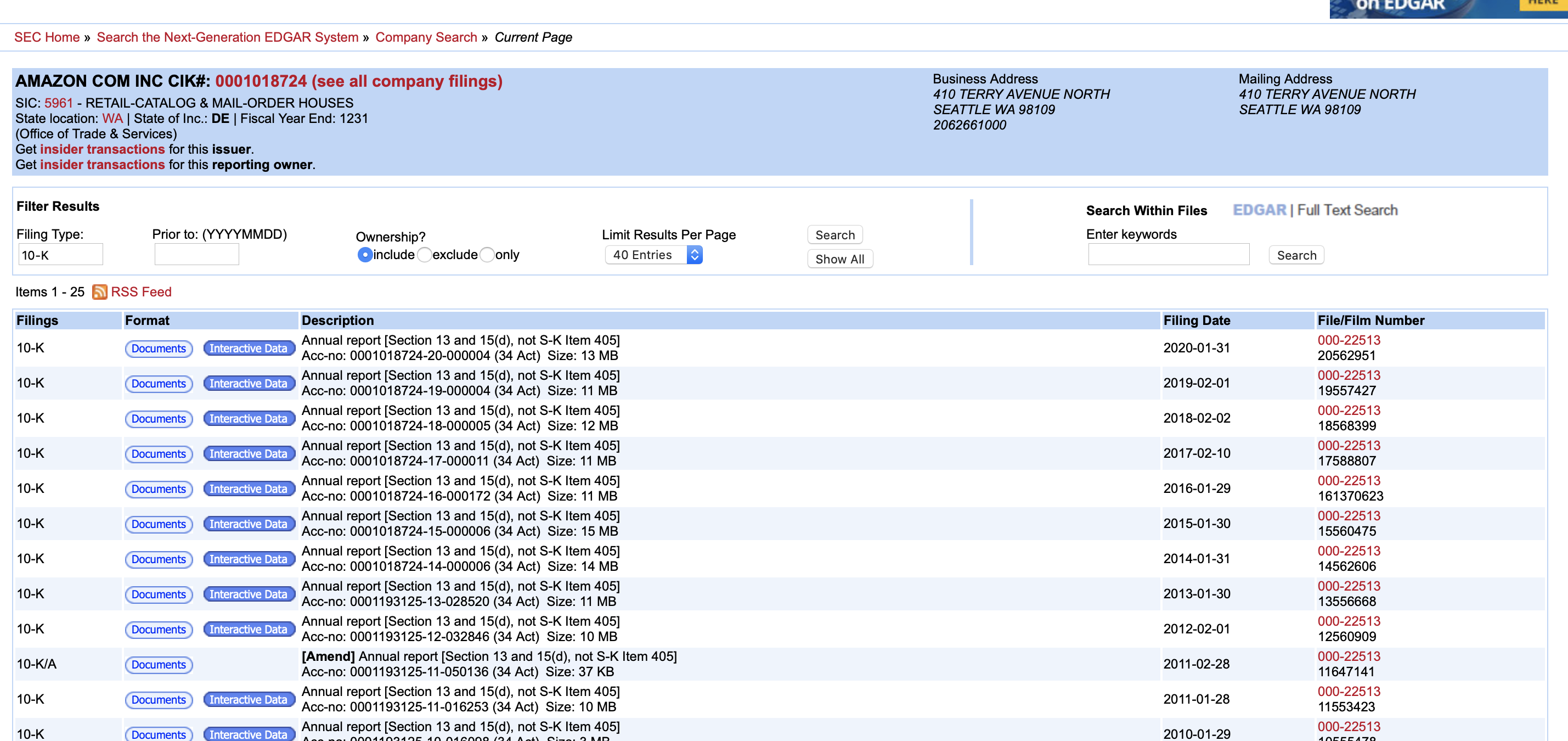
Step 2: Access the table that stores the "Documents" link for each 10K document. After that we load up the individual links for each of the 10K documents, one by one.
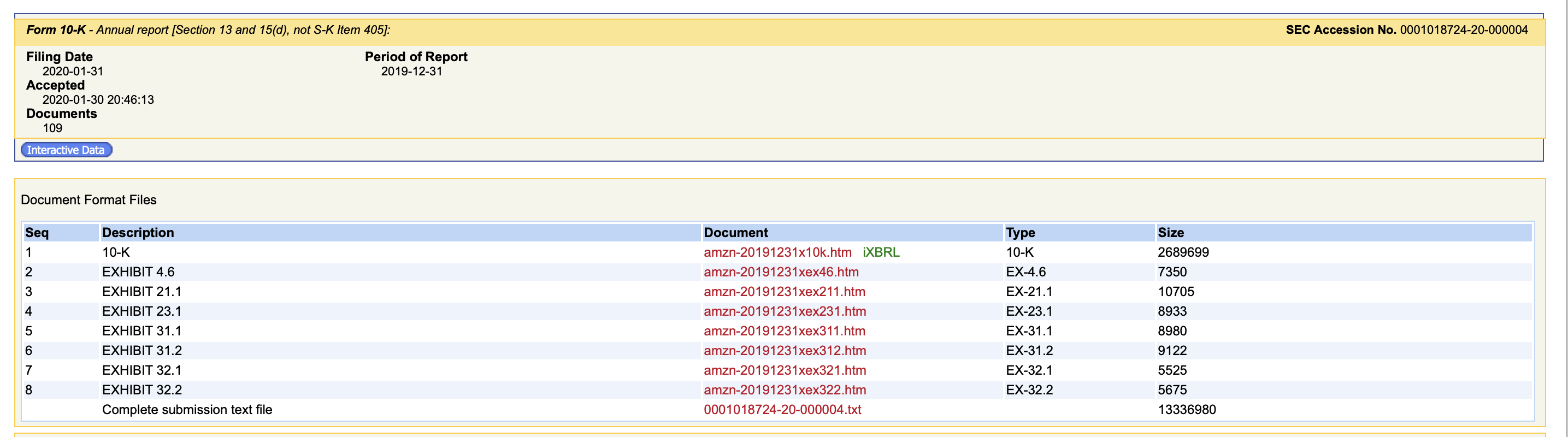
Step 3: Access the corresponding document link which has "Description" as 10-K. This loads up the entire 10-K document in html format for that particular filling.

#Examples of the links that we will be scraping from
browse_url_base_10k = 'https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=%s&type=10-K'
filing_url_base_10k = 'http://www.sec.gov/Archives/edgar/data/%s/%s-index.html'
doc_url_base_10k = 'http://www.sec.gov/Archives/edgar/data/%s/%s/%s'
def Scrape10K(base_url, filing_url, doc_url, cik):
# Check if we've already scraped this CIK
try:
os.mkdir(cik)
except OSError:
print("The CIK has already been scraped", cik)
return
# Setting current directory for that CIK
os.chdir(cik)
print('Scraping CIK', cik)
# Request list of 10-K filings --> STEP 1 in the pictures
base_res = requests.get(base_url % cik) # STEP 1 in the pictures
# Parse the response HTML using BeautifulSoup
base_soup = bs.BeautifulSoup(base_res.text, "lxml")
# Extract all tables from the response
base_html_tables = base_soup.find_all('table')
# Check that the table we're looking for exists and If it doesn't, exit
if len(base_html_tables)<3:
os.chdir('..')
return
# Parse the Filings table
fil_table = pd.read_html(str(base_html_tables[2]), header=0)[0]
fil_table['Filings'] = [str(y) for y in fil_table['Filings']]
# Get only 10-K and 10-K405 document filings
fil_table = fil_table[(fil_table['Filings'] == '10-K')| (fil_table['Filings'] == '10-K405') ]
# If filings table doesn't have any 10-Ks or 10-K405s, exit
if len(fil_table)==0:
os.chdir('..')
return
# Get accession number for each 10-K and 10-K405 filing
fil_table['Acc_No'] = [x.replace('\xa0',' ')
.split('Acc-no: ')[1]
.split(' ')[0] for x in fil_table['Description']]
#print(fil_table)
# Iterate through each filing and scrape the corresponding document...
for index, row in fil_table.iterrows():
# find the uniquie accession number for filing
acc_no = str(row['Acc_No'])
# find the page with the accession number and Parse the table of documents for the filing
docs_page_html = bs.BeautifulSoup(requests.get(filing_url % (cik, acc_no)).text, 'lxml') # STEP 2 in the pictures
docs_tables = docs_page_html.find_all('table')
if len(docs_tables)==0:
continue
#converting the HTML table to a Dataframe
docs_df = pd.read_html(str(docs_tables[0]), header=0)[0]
docs_df['Type'] = [str(x) for x in docs_df['Type']]
# Get the 10-K for the filing
docs_df = docs_df[(docs_df['Type'] == '10-K')| (docs_df['Type'] == '10-K405')]
# If there aren't any 10-K, skip to the next filing
if len(docs_df)==0:
continue
elif len(docs_df)>0:
docs_df = docs_df.iloc[0]
docname = docs_df['Document']
if str(docname) != 'nan':
# STEP 3 in the pictures
#print(str(doc_url % (cik, acc_no.replace('-', ''), docname)).split()[0])
file = requests.get(str(doc_url % (cik, acc_no.replace('-', ''), docname)).split()[0])
# # Save the file in appropriate format
# if '.txt' in str(docname):
# # Save text as TXT
# date = str(row['Filing Date'])
# filename = cik + '_' + date + '.txt'
# html_file = open(filename, 'a')
# html_file.write(file.text)
# html_file.close()
# else:
# Save text as HTML
date = str(row['Filing Date'])
filename = cik + '_' + date + '.html'
html_file = open(filename, 'a')
html_file.write(file.text)
html_file.close()
# Move back to the main 10-K directory
os.chdir('..')
return
os.chdir(path_10k)
# Iterate over CIKs and scrape 10-Ks
for cik in tqdm(tick_cik_df['cik']):
Scrape10K(base_url=browse_url_base_10k, filing_url=filing_url_base_10k, doc_url=doc_url_base_10k, cik=cik)
Data Cleaning¶
We now have 10-Ks in HTML format for each CIK. Before computing our similarity scores, however, we need to clean the files up a bit.
The following needs to be done:
- Remove all tables and tags (if their numeric character content is greater than 15%), HTML tags, XBRL tables, exhibits, ASCII-encoded PDFs, graphics, XLS, and other binary files.
- Convert the HTML file to .txt file
def DelTags(file_soup):
# Remove HTML tags
doc = file_soup.get_text()
# Remove newline characters
doc = doc.replace('\n', ' ')
# Replace unicode characters with their "normal" representations
doc = unicodedata.normalize('NFKD', doc)
return doc
def DelTables(file_soup):
def GetDigitPercentage(tablestring):
if len(tablestring)>0.0:
numbers = sum([char.isdigit() for char in tablestring])
length = len(tablestring)
return numbers/length
else:
return 1
# Evaluates numerical character % for each table
# and removes the table if the percentage is > 15%
[x.extract() for x in file_soup.find_all('table') if GetDigitPercentage(x.get_text())>0.15]
return file_soup
def ConvertHTML(cik):
# Remove al the following such as newlines, unicode text, XBRL tables, numerical tables and HTML tags,
# Look for files scraped for that CIK
try:
os.chdir(cik)
# ...if we didn't scrape any files for that CIK, exit
except FileNotFoundError:
print("Directory not available CIK", cik)
return
print("Parsing CIK %s..." % cik)
parsed = False # flag to tell if we've parsed anything
# Make a new directory with all the .txt files called "textonly"
try:
os.mkdir('textonly')
except OSError:
pass
# List of file in that directory
file_list = [fname for fname in os.listdir() if not (fname.startswith('.') | os.path.isdir(fname))]
# Iterate over scraped files and clean
for filename in file_list:
# Check if file has already been cleaned
new_filename = filename.replace('.html', '.txt')
text_file_list = os.listdir('textonly')
if new_filename in text_file_list:
continue
# If it hasn't been cleaned already, keep going...
# Clean file
with open(filename, 'r') as file:
parsed = True
soup = bs.BeautifulSoup(file.read(), "lxml")
soup = DelTables(soup)
text = DelTags(soup)
with open('textonly/'+new_filename, 'w') as newfile:
newfile.write(text)
# If all files in the CIK directory have been parsed
# then log that
if parsed==False:
print("Already parsed CIK", cik)
os.chdir('..')
return
os.chdir(path_10k)
# Iterate over CIKs and clean HTML filings
for cik in tqdm(tick_cik_df['cik']):
ConvertHTML(cik)
Data Preprocessing¶
As you can see, the text for the documents are very messy. To clean this up, we'll remove the html and lowercase all the text.
After running the two cells above, we have cleaned plaintext 10-K for each CIK. The file structure looks like this:
- 10Ks
- CIK1
- 10K #1
- 10K #2
...
- textonlyString Lemmatization¶
After the text is cleaned up, it's time to distill the verbs down. Implement the lemmatize function to lemmatize verbs in the list of words provided.
def lemmetize(words):
lemmatized_words = [WordNetLemmatizer().lemmatize(w.lower()) for w in words]
return lemmatized_words
Removing StopWords and Punctuations¶
stop_words = set(stopwords.words('english'))
fin_stop_words = ("million","including","billion","december","january")
stop_words.update(fin_stop_words)
# removing stop words, numbers , removing punctuations and special characters and spaces
def remove_stopwords(words):
filtered = [re.sub(r'[^\w\s]','',w) for w in words if not re.sub(r'[^\w\s]','',w) in stop_words and not re.sub(r'[^\w\s]','',w).isnumeric() and not re.search('^\s*[0-9]',re.sub(r'[^\w\s]','',w)) and len(re.sub(r'[^\w\s]','',w)) > 3 ]
return filtered
Stemming Words¶
from nltk.stem import PorterStemmer
from nltk.stem.snowball import SnowballStemmer
#ps = PorterStemmer()
ps = SnowballStemmer("english")
def stem_words(words):
stemmed = [ps.stem(w) for w in words]
return stemmed
String Tokenization for each 10K document¶
from nltk.tokenize import sent_tokenize,word_tokenize
wordcount={} #dictionary to count the sentences and tokens in each 10-K document
docs = {} #dictionary to save the tokens after preprocessing for each 10-K document
file_doc=[] # Saving only the first document for the scope of this project
for cik in tqdm(tick_cik_df['cik']):
#setting directory to the .txt files folder
os.chdir(path_10k+'/'+cik+"/textonly")
#listing files in directory
files = [j for j in os.listdir()]
files.sort(reverse=True)
#iterating over each 10-K file
for file in files:
text = open(file,"r").read()
#using sentence
sents = sent_tokenize(text)
file_doc = sents
tokens = word_tokenize(text.lower())
partial_lem = lemmetize(tokens)
after_stopwords = remove_stopwords(partial_lem)
docs[file] = after_stopwords
counts = {}
counts["tokens"]=len(tokens)
counts["sentences"]= len(sents)
wordcount[file] = counts
continue #Looping over just one document for now-
Exploratory Data Analysis(EDA) on the latest 10-K Document¶
For the scope of the project, all the EDA will be done only on the most latest 10-K document.
TokenID using Genism¶
dataset = [lemmetize(remove_stopwords(d.lower().split())) for d in file_doc]
dictionary = corpora.Dictionary(dataset)
Creating BoW¶
It is a basically object that contains the word id(token id) and its frequency in each document (just lists the number of times each word occurs in the sentence).
corpus = [dictionary.doc2bow(file) for file in dataset]
TF-IDF¶
Term Frequency – Inverse Document Frequency(TF-IDF) is also a bag-of-words model but unlike the regular corpus, TFIDF down weights tokens (words) that appears frequently across documents.In simple terms, words that occur more frequently across the documents get smaller weights.
tfidf= TfidfModel(corpus)
#For printing the TF-IDF Model
# for doc in tfidf[corpus]:
# for id, freq in doc:
# print([dictionary[id], np.around(freq, decimals=2)])
Printing words with more than .5 Tf-IDF score, these are words that occur rarely in the document(Might have a higher meaning)
for doc in tfidf[corpus]:
for id, freq in doc:
if np.around(freq,decimals=2)> .5:
print([dictionary[id], np.around(freq, decimals=2) ])
WordCloud for the given 10K document¶
The wordCloud helps us visualize some of the most frequently used words in the document.
wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", width=800, height=400).generate(" ".join(docs[list(docs.keys())[0]])) #first documents tokens from docs(which contains many tokens from different docs)
# Display the generated image:
plt.figure( figsize=(20,10), facecolor='k' )
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

LDA Modelling¶
Train our lda model using gensim.models.LdaMulticore and save it to ‘lda_model’. For each topic, we will explore the words occuring in that topic and its relative weight. The pyLDAvis helps us visualize this LDA modelling in a very user-friendly manner.
lda_model = LdaMulticore(corpus, num_topics = 6, id2word = dictionary,passes = 10,workers = 2)
lda_model.show_topics()
pyLDAvis¶
The area of circle represents the importance of each topic over the entire corpus, the distance between the center of circles indicate the similarity between topics. For each topic, the histogram on the right side listed the top 30 most relevant terms. From these topics, we can try to tell a story from them.
The first topic has the word "loss" appearing the most number of times. This might represent some invesment the company had undertaken that lead to this loss.¶
P.S.: This is just an example and it might not be very accurate.
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, dictionary)
vis
Top 20 used words in the 10K report¶
counter=Counter(docs[list(docs.keys())[0]]) #first documents tokens from docs(which contains many tokens from different docs)
most=counter.most_common()
x, y=[], []
for word,count in most[:20]:
x.append(word)
y.append(count)
plt.figure(figsize=(16,6))
sns.barplot(x=y,y=x)

Positivity Score of the 10K document¶
Finding the sentiment value of the document using the Texblob library.
positivity = TextBlob(" ".join(docs[list(docs.keys())[0]])) #first documents tokens from docs(which contains many tokens from different docs)
print(positivity.sentiment)
The polarity value ranges from [-1,1]. -1 meaning that the given string has a very negative context and whereas 1 has a very postive intent. 0 means that the statment is neutral, hence its neither positive or negative. For the document that we used, the score is about .08, refering that the document is more or less neutral or slightly positive. Again this doesnt help too much with our quantitative analysis.
def polarity(text):
return TextBlob(" ".join(text)).sentiment.polarity
sentences = pd.DataFrame(columns=["sentences","polarity_score"])
for sent in dataset:
sentences = sentences.append({'sentences':sent, 'polarity_score':polarity(sent) }, ignore_index=True)
sentences['polarity_score'].hist(figsize=(10,8))

The above graph shows us the distribution of polarity over the sentences. As we can see here that most of the words used in the 10-K document are very neutral and use their words very consciously.
# Displaying the sentences that had a polarity score of over .5
sentences[sentences['polarity_score']>.5]
Calculating the Similarity Score¶
For this part, I will use cosine similarity and Jaccard similarity to compare the various 10K documents over the years from a particular company and find their similarity over years.
def CosSimilarity(A, B):
'''
The input paramters A and B are words from two different documents
'''
# Compile complete set of words in A or B
words = list(A.union(B))
# Determine which words are in A
vec_A = [1 if x in A else 0 for x in words]
# Determine which words are in B
vec_B = [1 if x in B else 0 for x in words]
# Compute cosine score using scikit-learn
array_A = np.array(vec_A).reshape(1, -1)
array_B = np.array(vec_B).reshape(1, -1)
cosine_score = cosine_similarity(array_A, array_B)[0,0]
return cosine_score
def JaccardSimilarity(A, B):
'''
The input paramters A and B are words from two different documents
and this function return the JaccardSimilarityScore
'''
# Count number of words in both A and B
intersect = len(A.intersection(B))
# Count number of words in A or B
union = len(A.union(B))
# Compute Jaccard similarity score
jaccard_score = intersect / union
return jaccard_score
def ComputeSimilarityScores10K(cik):
# Open the directory that holds text filings for the CIK
os.chdir(cik+'/textonly')
print("Parsing CIK %s..." % cik)
# Get list of files to over which to compute scores
# excluding hidden files and directories
flist = [fname for fname in os.listdir()]
flist.sort()
# Check if scores have already been calculated...
try:
os.mkdir('../metrics')
# ... if they have been, exit
except OSError:
print("Similarity Scores are already calculated")
os.chdir('../..')
return
# Check if enough files exist to compute sim scores...
# If not, exit
if not len(flist):
return
if len(flist) < 2:
print("No files to compare for CIK", cik)
os.chdir('../..')
return
# Initialize dataframe to store sim scores
#find the dates from the names of the files that are present in the "textonly directory"
dates = [x[-14:-4] for x in flist]
#creating an empty array according to match the size of the cosine score
cosscore = [0]*len(dates)
jaccard_score = [0]*len(dates)
data = pd.DataFrame(columns={'cosine_score': cosscore,
'jaccard_score': jaccard_score},
index=dates)
# Open first file
file_A = flist[0]
with open(file_A, 'r') as file:
text_A = file.read()
# Iterate over each 10-K file...
for i in range(1, len(flist)):
file_B = flist[i]
# Get file text B
with open(file_B, 'r') as file:
text_B = file.read()
# Get set of words in A, B
words_A = set(re.findall(r"[\w']+", text_A))
words_B = set(re.findall(r"[\w']+", text_B))
# Calculate similarity scores
cos_score = CosSimilarity(words_A, words_B)
jaccard_score = JaccardSimilarity(words_A, words_B)
# Store score values
date_B = file_B[-14:-4]
data.at[date_B, 'cosine_score'] = cos_score
data.at[date_B, 'jaccard_score'] = jaccard_score
# Reset value for next loop
# (We don't open the file again, for efficiency)
text_A = text_B
# Save scores
os.chdir('../metrics')
data.to_csv(cik+'_sim_scores.csv', index=True)
os.chdir('../..')
print("Metics Successfully Calulated, Check Metrics Directory")
# Calculating the similarity score for the nearest 10-K files in the "metrics" directory
os.chdir(path_10k)
for cik in tqdm(tick_cik_df['cik']):
ComputeSimilarityScores10K(cik)
Constructing the similarity index dataframe¶
cik = tick_cik_df['cik'][0]
sim_df = pd.read_csv(path_10k+"/"+cik+"/metrics/"+cik+"_sim_scores.csv")
new_columns = sim_df.columns.values
new_columns[0] = 'Dates'
sim_df.columns = new_columns
sim_df = sim_df.set_index('Dates')
sim_df = sim_df.fillna(0)
sim_df['cosine_score'] = sim_df['cosine_score'].astype(float)
sim_df['jaccard_score'] = sim_df['jaccard_score'].astype(float)
sim_df = pd.concat( [sim_df, sim_df.pct_change()] , axis = 1, sort=False)
sim_df
In the above dataframe, we can observe that over the years the cosine similarity score and the jaccard score are very close and barely any difference.
Comparing our hypothesis with the real stock market situation¶
tickers = [tick_cik_df['ticker'][0]]
time_series =web.DataReader(tickers, "av-monthly-adjusted", start=datetime(2001, 3, 23),end=datetime(2020, 10, 31),api_key='UGBIPKZSN5NWM5LV')
time_series
x = time_series.index.values.tolist()
y = time_series['adjusted close']
# dates = [datetime.strptime(date,"%Y-%m-%d")for date in x ]
# i = 2001
# years = [i for i in range(2021)]
# plt.xticks(x,x[::12],rotation='vertical')
# plt.locator_params(axis='x', nbins=len(x)/11)
plt.figure(figsize=(20,8))
plt.xticks(rotation=90)
plt.xlabel("Dates starting from 2001")
plt.plot(x,y)
plt.show()

Conclusion¶
From the above graph, we can see that the stock price of amazon has steadily increased over the span of 20 years. From the similarities score generated in the 'sim_df' dataframe, we know that the changes in the cosine similarities and jaccard similarities between the years is very low. Hence from the hypothesis we started, were we suggested 'Major text changes in 10-K over time indicate significant decreases in future returns.' can be proven true for this case. AMZN had little text changes in its 10-K documents overtime and this suggested to the steady growth of the company.
However we can stop here. It is important to test the hypothesis with other stocks before we come to any concrete conclusion.