{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"%matplotlib inline\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Unsupervised Learning Part 2 -- Clustering"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Clustering is the task of gathering samples into groups of similar\n",
"samples according to some predefined similarity or distance (dissimilarity)\n",
"measure, such as the Euclidean distance.\n",
"\n",
"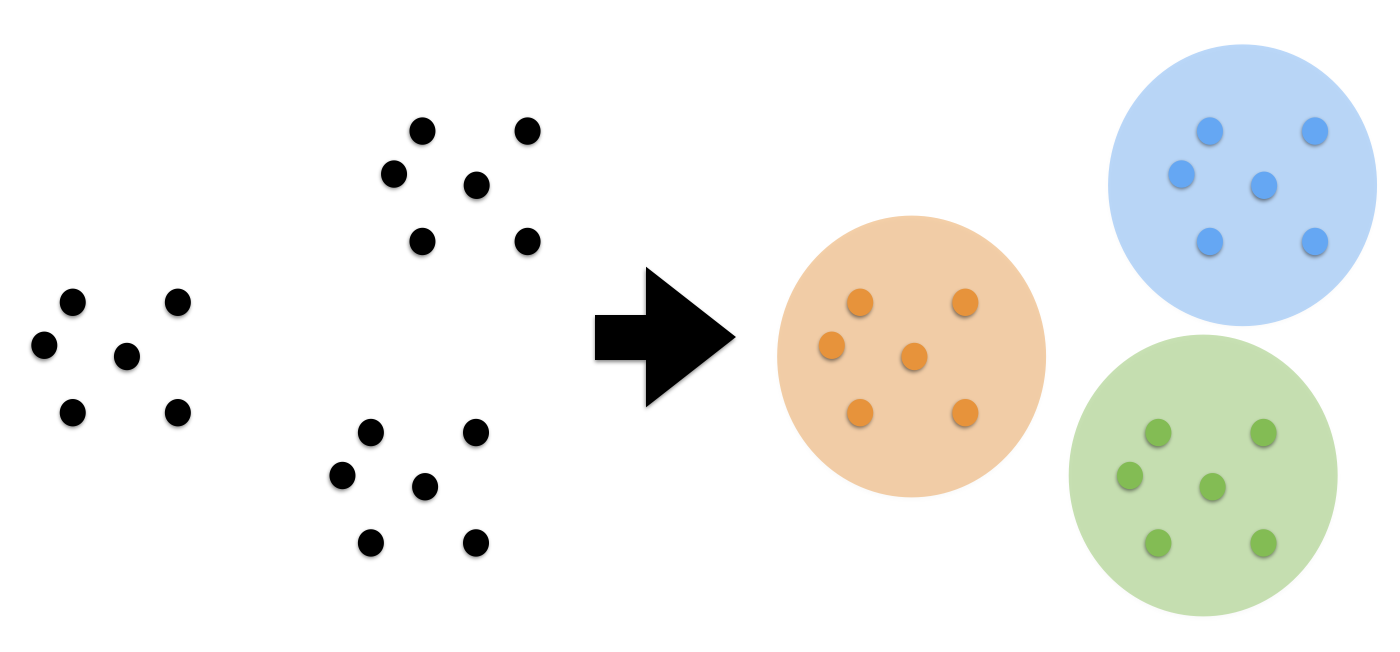 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this section we will explore a basic clustering task on some synthetic and real-world datasets.\n",
"\n",
"Here are some common applications of clustering algorithms:\n",
"\n",
"- Compression for data reduction\n",
"- Summarizing data as a reprocessing step for recommender systems\n",
"- Similarly:\n",
" - grouping related web news (e.g. Google News) and web search results\n",
" - grouping related stock quotes for investment portfolio management\n",
" - building customer profiles for market analysis\n",
"- Building a code book of prototype samples for unsupervised feature extraction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's start by creating a simple, 2-dimensional, synthetic dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.datasets import make_blobs\n",
"\n",
"X, y = make_blobs(random_state=42)\n",
"X.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.figure(figsize=(8, 8))\n",
"plt.scatter(X[:, 0], X[:, 1])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the scatter plot above, we can see three separate groups of data points and we would like to recover them using clustering -- think of \"discovering\" the class labels that we already take for granted in a classification task.\n",
"\n",
"Even if the groups are obvious in the data, it is hard to find them when the data lives in a high-dimensional space, which we can't visualize in a single histogram or scatterplot."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we will use one of the simplest clustering algorithms, K-means.\n",
"This is an iterative algorithm which searches for three cluster\n",
"centers such that the distance from each point to its cluster is\n",
"minimized. The standard implementation of K-means uses the Euclidean distance, which is why we want to make sure that all our variables are measured on the same scale if we are working with real-world datastets. In the previous notebook, we talked about one technique to achieve this, namely, standardization.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this section we will explore a basic clustering task on some synthetic and real-world datasets.\n",
"\n",
"Here are some common applications of clustering algorithms:\n",
"\n",
"- Compression for data reduction\n",
"- Summarizing data as a reprocessing step for recommender systems\n",
"- Similarly:\n",
" - grouping related web news (e.g. Google News) and web search results\n",
" - grouping related stock quotes for investment portfolio management\n",
" - building customer profiles for market analysis\n",
"- Building a code book of prototype samples for unsupervised feature extraction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's start by creating a simple, 2-dimensional, synthetic dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.datasets import make_blobs\n",
"\n",
"X, y = make_blobs(random_state=42)\n",
"X.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.figure(figsize=(8, 8))\n",
"plt.scatter(X[:, 0], X[:, 1])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the scatter plot above, we can see three separate groups of data points and we would like to recover them using clustering -- think of \"discovering\" the class labels that we already take for granted in a classification task.\n",
"\n",
"Even if the groups are obvious in the data, it is hard to find them when the data lives in a high-dimensional space, which we can't visualize in a single histogram or scatterplot."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we will use one of the simplest clustering algorithms, K-means.\n",
"This is an iterative algorithm which searches for three cluster\n",
"centers such that the distance from each point to its cluster is\n",
"minimized. The standard implementation of K-means uses the Euclidean distance, which is why we want to make sure that all our variables are measured on the same scale if we are working with real-world datastets. In the previous notebook, we talked about one technique to achieve this, namely, standardization.\n",
"\n",
"
\n",
"\n",
"
Question:\n",
"
\n",
" - \n",
" what would you expect the output to look like?\n",
"
\n",
"
\n",
"
\n",
"
EXERCISE:\n",
"
\n",
" - \n",
" After looking at the \"True\" label array y, and the scatterplot and `labels` above, can you figure out why our computed accuracy is 0.0, not 1.0, and can you fix it?\n",
"
\n",
"
\n",
"
\n",
" The simplest, yet effective clustering algorithm. Needs to be provided with the\n",
" number of clusters in advance, and assumes that the data is normalized as input\n",
" (but use a PCA model as preprocessor).\n",
"- `sklearn.cluster.MeanShift`:
\n",
" Can find better looking clusters than KMeans but is not scalable to high number of samples.\n",
"- `sklearn.cluster.DBSCAN`:
\n",
" Can detect irregularly shaped clusters based on density, i.e. sparse regions in\n",
" the input space are likely to become inter-cluster boundaries. Can also detect\n",
" outliers (samples that are not part of a cluster).\n",
"- `sklearn.cluster.AffinityPropagation`:
\n",
" Clustering algorithm based on message passing between data points.\n",
"- `sklearn.cluster.SpectralClustering`:
\n",
" KMeans applied to a projection of the normalized graph Laplacian: finds\n",
" normalized graph cuts if the affinity matrix is interpreted as an adjacency matrix of a graph.\n",
"- `sklearn.cluster.Ward`:
\n",
" Ward implements hierarchical clustering based on the Ward algorithm,\n",
" a variance-minimizing approach. At each step, it minimizes the sum of\n",
" squared differences within all clusters (inertia criterion).\n",
"\n",
"Of these, Ward, SpectralClustering, DBSCAN and Affinity propagation can also work with precomputed similarity matrices."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
EXERCISE: digits clustering:\n",
"
\n",
" - \n",
" Perform K-means clustering on the digits data, searching for ten clusters.\n",
"Visualize the cluster centers as images (i.e. reshape each to 8x8 and use\n",
"``plt.imshow``) Do the clusters seem to be correlated with particular digits? What is the ``adjusted_rand_score``?\n",
"
\n",
" - \n",
" Visualize the projected digits as in the last notebook, but this time use the\n",
"cluster labels as the color. What do you notice?\n",
"
\n",
"
\n",
"