Ultimamente ho iniziato a dare uno sguardo a PRAW, un wrapper per l'API di Reddit che permette di fare data mining in modo molto semplice.
Per prima cosa installiamo le librerie di cui abbiamo bisogno attraverso pip. Pandas trasformerà il nostro csv in un dataframe che potremo gestire più facilmente, mentre matplotlib ci permetterà di creare grafici.
pip install pandas
pip install matplotlib
Apriamo adesso l'IDE ed cominciamo a scrivere il programma in python3
# Iniziamo importando tutto il necessario
import numpy as np
import matplotlib.pyplot as plt
import csv
from nltk.tokenize import word_tokenize
import pandas as pd
from nltk.stem import SnowballStemmer
from nltk.corpus import stopwords
Una parte importante dell'analisi dei testi è la preparazione. Se non impostiamo tutte le premesse che intendiamo implementare, o non lo facciamo correttamente, i risultati non saranno accurati con i nostri obbiettivi.
La prima cosa da fare, quindi, è impostare lo stemmer (serve a togliere tutti i suffissi dalle parole e lasciare solo la radice). Fatto ciò possiamo raccogliere il set delle stopwords italiane e importare i nostri dati contenuti nel csv con Pandas.
stemmer = SnowballStemmer('italian')
stop_words = set(stopwords.words('italian'))
df1=pd.read_csv("ilmiocorpus.csv")
Iniziamo il nostro filtraggio iniziale. Prima di tutto vogliamo che per ogni cella (o commento) nella colonna dei commenti, il testo venga tokenizzato e diviso in singole parole.
Successivamente, rendiamo tutte le parole ottenute in lettere minuscole per rendere più facile l'esclusione delle stopwords.
parole= list()
for x in df1["comment"]:
for j in word_tokenize(str(x)):
parole.append(j)
parole2 = list()
for e in parole:
lowered = e.lower()
parole2.append(lowered)
Adesso possiamo finalmente togliere tutte le stopwords dalle parole trovate (io ho modificato la mia lista di stopwords inserendo anche simboli come [, ], ?, !, etc…).
Dopo, creaiamo la variabile in cui mettere le parole senza suffissi facendole passare attraverlo lo stemmer snowball.
filtered = [h for h in filtered if not h in stop_words]
stemmed = list()
for v in filtered:
stemmato = stemmer.stem(v)
stemmed.append(stemmato)
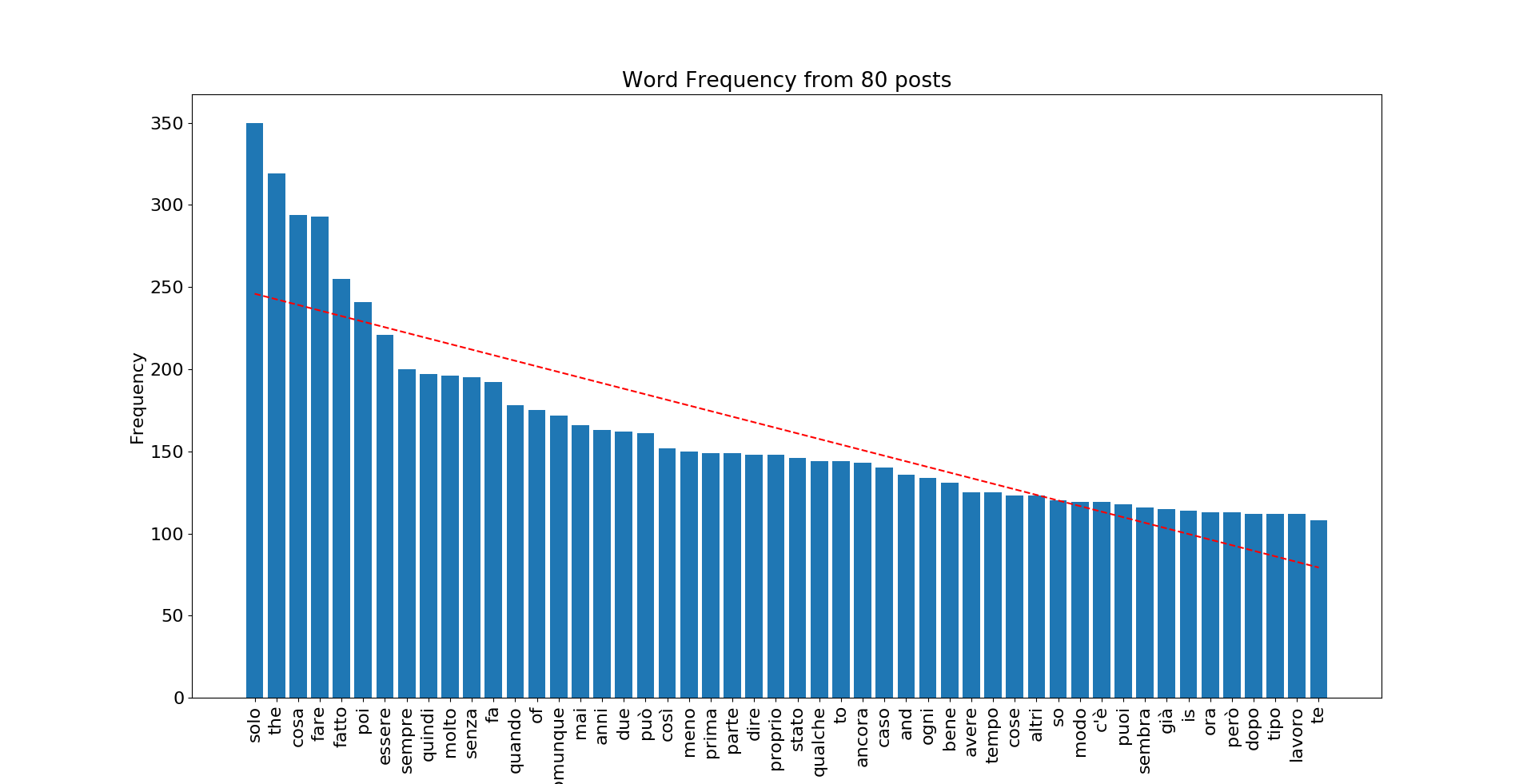
Adesso possiamo vedere, tramite la funzione FreqDist di nltk, le parole più comuni (nel mio caso ho scelto le 50 più comuni) e possiamo scegliere se analizzare quelle passate per lo stemmer o quelle integre.
fdist = nltk.FreqDist(filtered) #ma possiamo anche usare stemmed
mostcomm = fdist.most_common(50)
print(mostcomm)
Adesso, per poter plottare la frequenza delle parole più comuni, dobbiamo convertire mostcomm, che è una lista di tuples, in due liste separate per ogni elemento. Per fare ciò utilizzeremo zip(), dicendo che vogliamo nella variabile word gli elementi 0 di mostcomm (cioè il nome della parola), e nella variabile freq gli elementi 1, cioè la quantità.
word = list(zip(*mostcomm))[0]
freq = list(zip(*mostcomm))[1]
x_pos = np.arange(len(word))
Per terminare il tutto, usiamo matplotlib per rappresentare graficamente i risultati.
plt.rcParams.update({'font.size': 16})
# Sull'asse X avremo una barra con il valore della frequenza per ogni parola
plt.bar(x_pos, freq,align='center')
# L'asse X indicherà ad ogni barra la parola corrispondente in verticale (per risparmiare spazio)
plt.xticks(x_pos, word, rotation='vertical')
plt.ylabel('Frequency')
plt.title('Word Frequency from 80 posts')
plt.show()
Ed ecco il risultato finale
Date:
Other posts