Modificare Stopwords in NLTK
Spesso capita di voler analizzare un corpus in modo molto semplice e preliminare in Python con la libreria NLTK vedendo semplicemente le frequenze dei lemmi.
Nonostante le stopwords italiane presenti nell'omonimo modulo (scaricabile usando la funzione nltk.download() nello shell di Python) siano molte capita spesso, soprattutto con corpora raw e txt, di ritrovarsi simboli trai lemmi più numerosi.
Cosa sono le stopwords?
Una stopword è una parola che non è utile nell'analisi di un corpus. La congiunzione "e" oppure parole molto ricorrenti come "che" o "come" possono essere considerate stopwords. NLTK fornisce dei "corpora" di stopwords molto utili, che permettono di filtrare parole inutili quando si fa un'analisi di frequenza. Nonostante le stopwords fornite dalla library siano molte, alle volte può essere necessario, a seconda dei casi o ogni volta, aggiungere delle nuove stopwords.
Modificare le stopwords
Un modo semplice ed applicabile al singolo caso è quello di usare la funzione add(), dopo aver messo le stopwords italiane in una variabile in type set, aggiungendo i contenuti di una lista (o un file di testo).
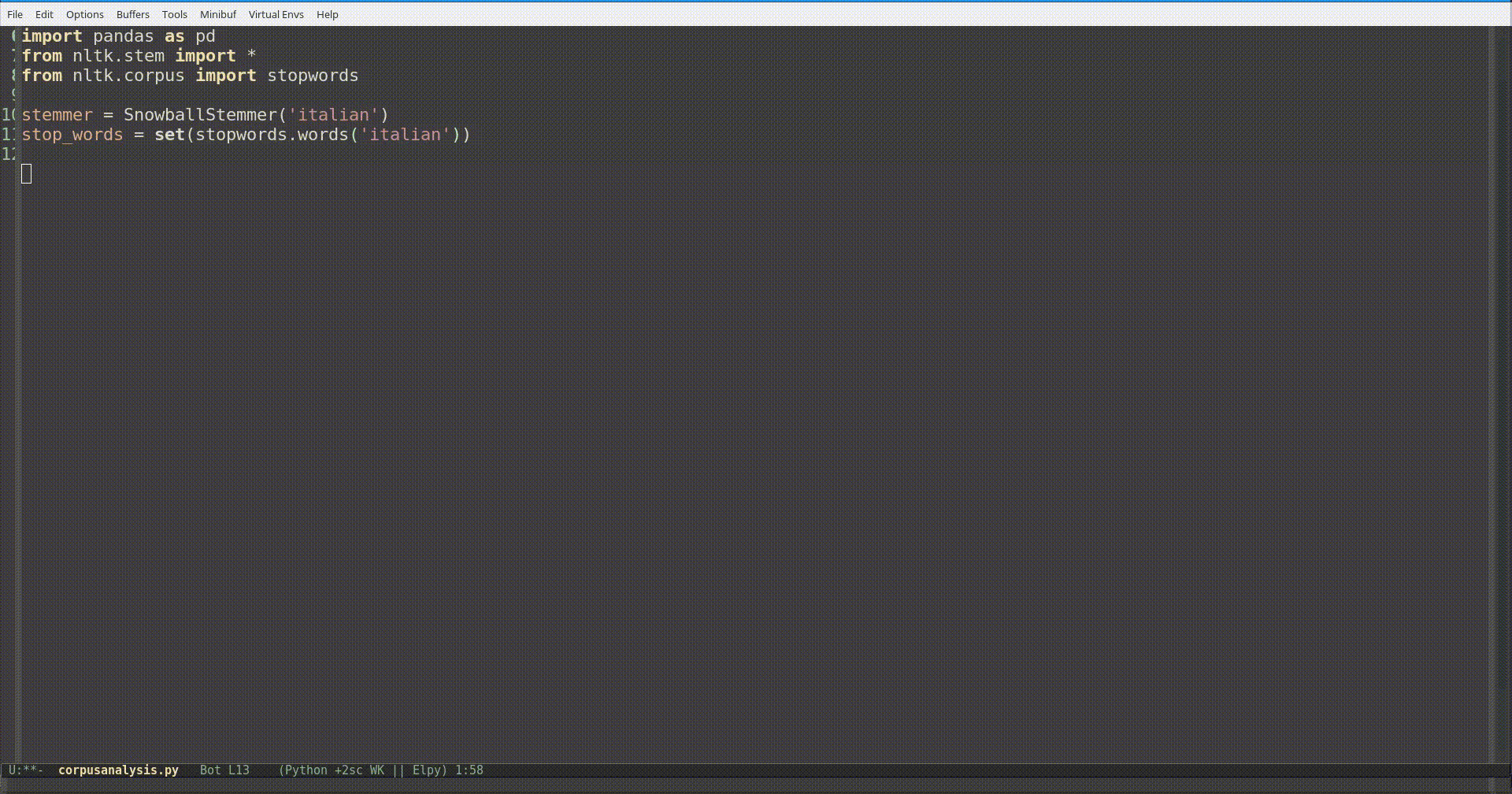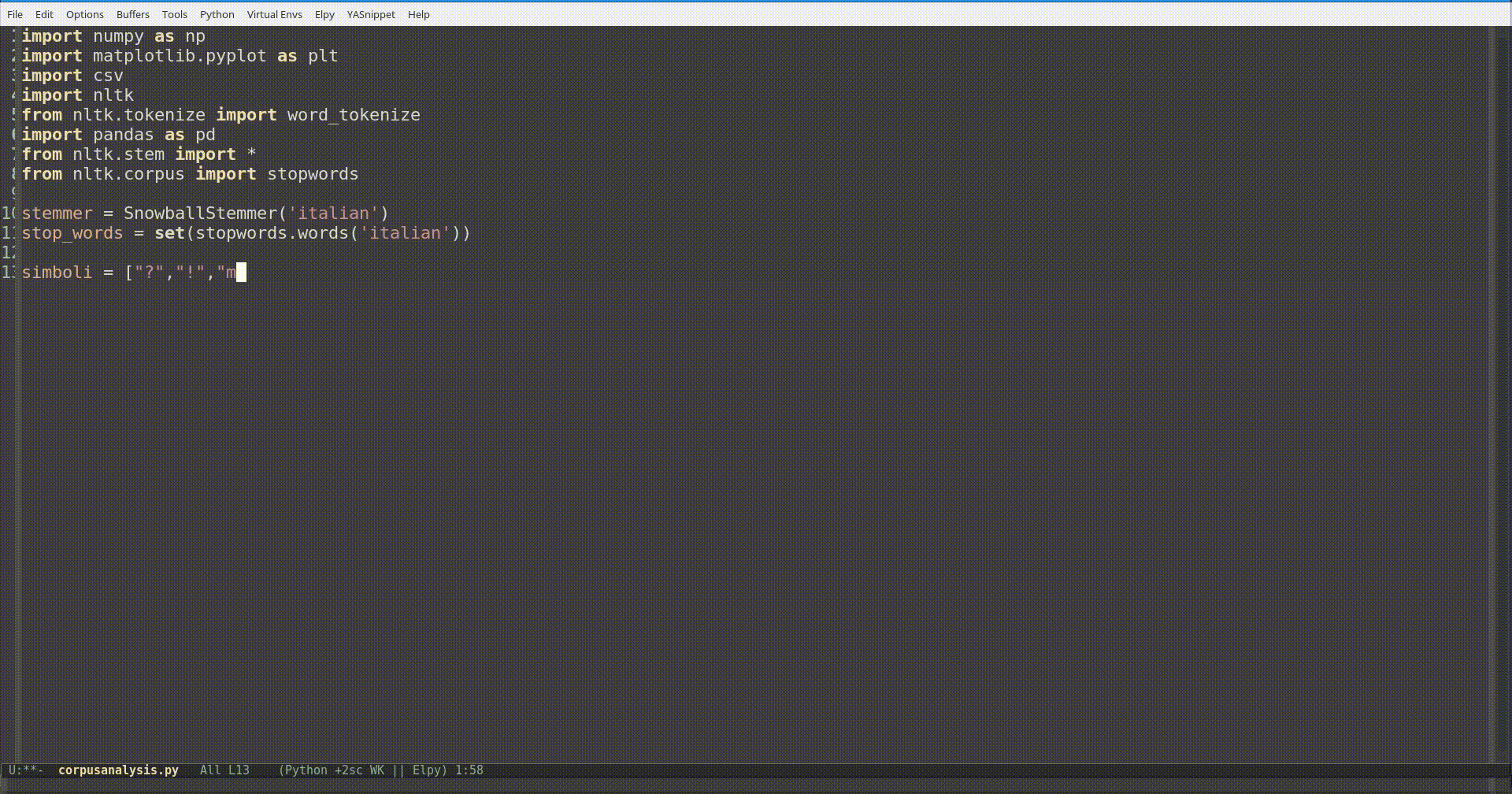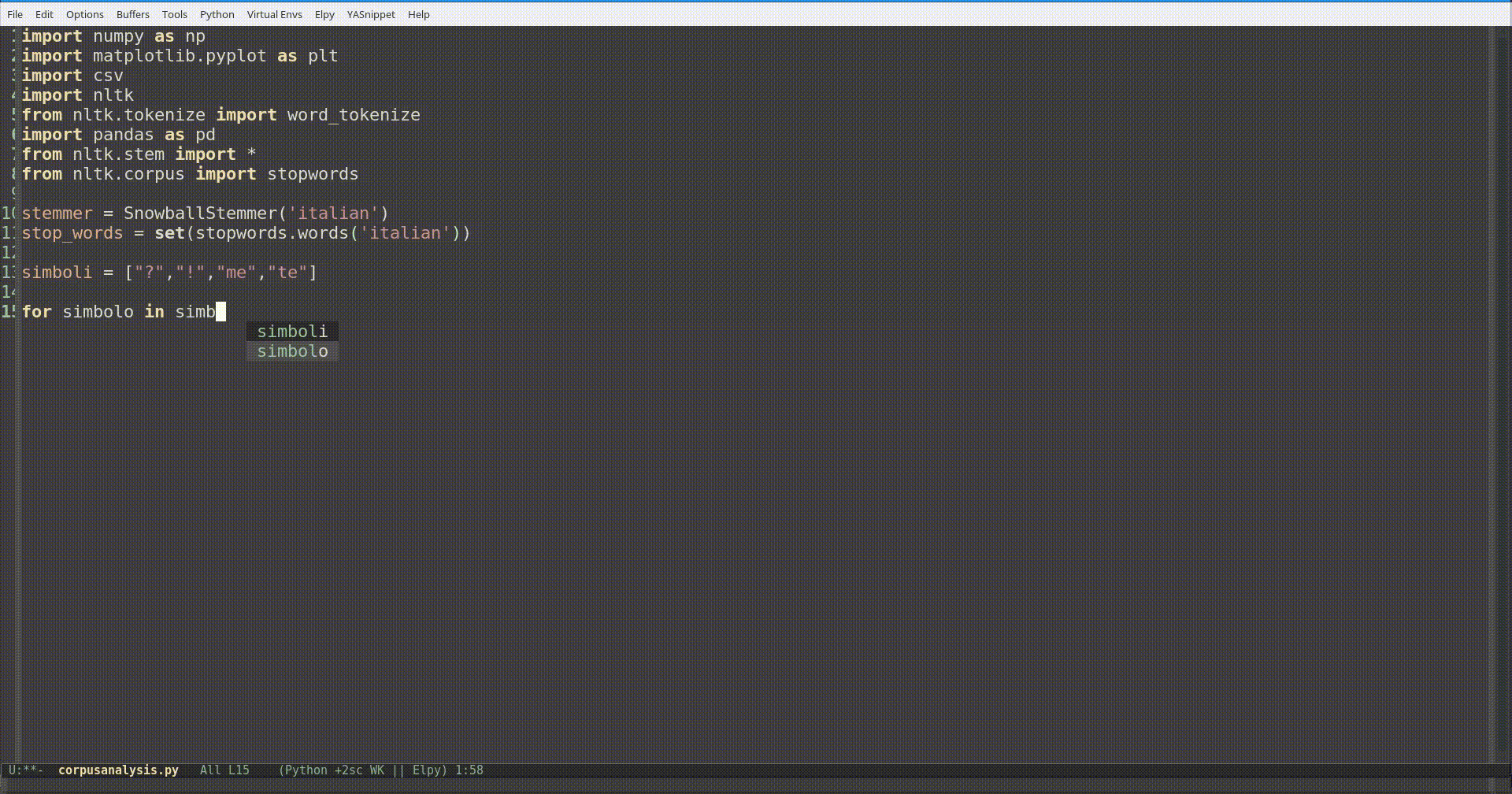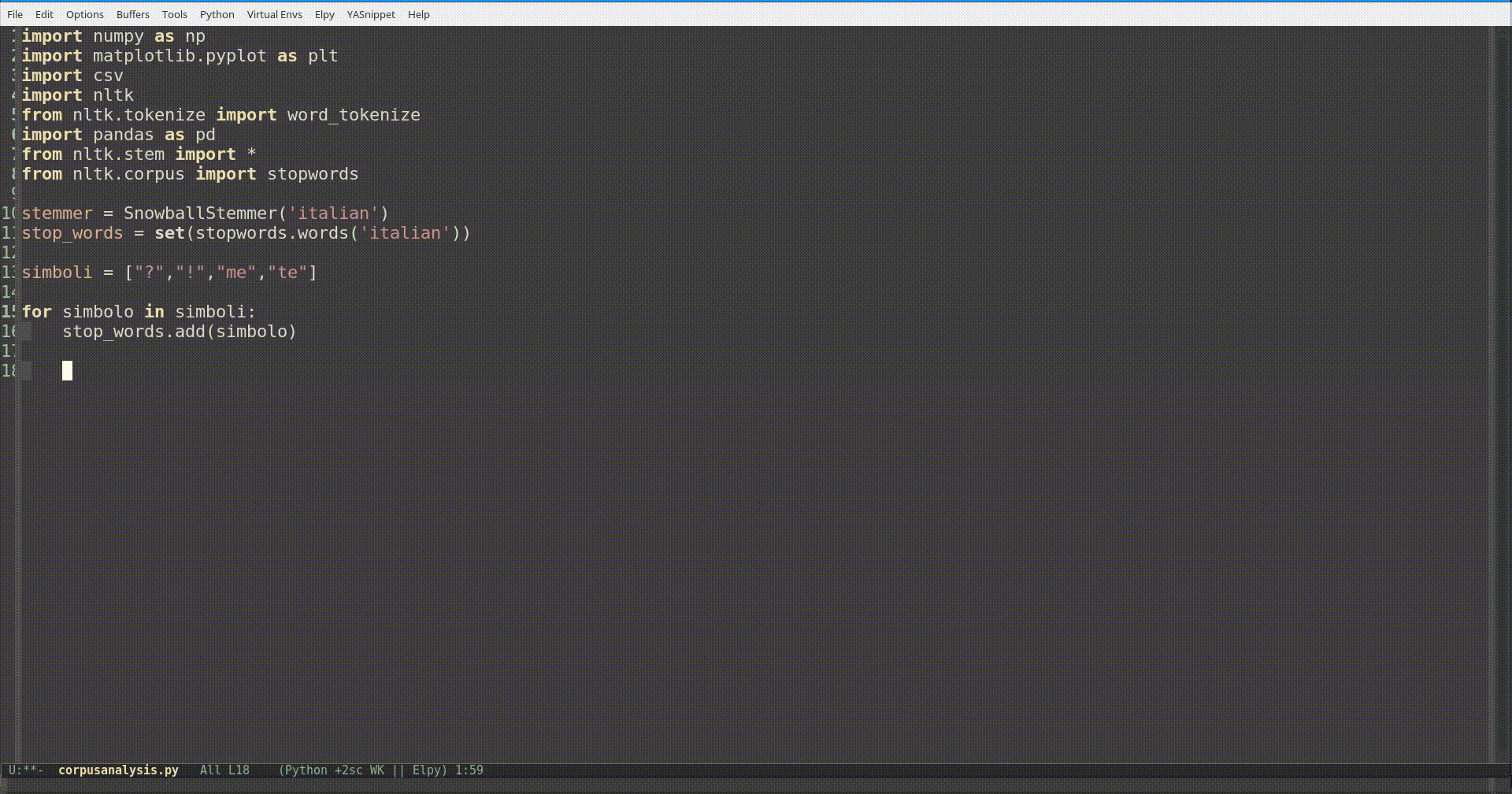
Se invece vi ritrovate spesso ad aggiungere gli stessi simboli o parole, forse è arrivato il momento di modificare permanentemente il modulo. Per fare ciò basta aprire il file che si trova nella cartella nltk_data/corpora/stopwords/ nella vostra home.
In questa directory potrete modificare la lista delle stopwords in varie lingue. Il consiglio è ovviamente quello di mettere le parole aggiunte alla fine del file in modo da poterle togliere senza problemi in futuro.
Se si vogliono invece togliere stopwords (oltre che eliminarle permanentemente dai file in nltk_data/corpora/stopwords/ si possono usare nei casi singoli le funzioni remove() o discard(), dove la prima darà un errore nel caso la parola che si vuole togliere non sia presente, mentre la seconda contiuerà ad eseguire il programma nel caso.