{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "matching_models.ipynb",
"version": "0.3.2",
"views": {},
"default_view": {},
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"accelerator": "GPU"
},
"cells": [
{
"metadata": {
"id": "PMqaGwuXb-b-",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"# Matching Models\n",
"\n",
"A matching model (an instance of class `MatchingModel`) is a neural network to perform entity matching. It takes in the contents of a tuple pair, i.e., two sequnces of words for each attribute, as input and produces a match score as output. This tutorial describes the structure of this network and presents options available for each of its components. \n",
"\n",
"Important Note: Be aware that creating a matching model (`MatchingModel`) object does not immediately instantiate all its components - `deepmatcher` uses a lazy initialization paradigm where components are instantiated just before training. Hence, code examples in this tutorial manually perform this initialization to demonstrate model customization meaningfully."
]
},
{
"metadata": {
"id": "LEmjZgCIb-b_",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "76c75084-bccc-4465-d0e4-b907f2295fd3",
"executionInfo": {
"status": "ok",
"timestamp": 1529117451971,
"user_tz": 300,
"elapsed": 6972,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"import deepmatcher as dm\n",
"import logging\n",
"import torch\n",
"\n",
"logging.getLogger('deepmatcher.core').setLevel(logging.INFO)\n",
"\n",
"# Download sample data.\n",
"!mkdir -p sample_data/itunes-amazon\n",
"!wget -qnc -P sample_data/itunes-amazon https://raw.githubusercontent.com/sidharthms/deepmatcher/master/examples/sample_data/itunes-amazon/train.csv\n",
"!wget -qnc -P sample_data/itunes-amazon https://raw.githubusercontent.com/sidharthms/deepmatcher/master/examples/sample_data/itunes-amazon/validation.csv\n",
"!wget -qnc -P sample_data/itunes-amazon https://raw.githubusercontent.com/sidharthms/deepmatcher/master/examples/sample_data/itunes-amazon/test.csv\n",
"\n",
"train_dataset, validation_dataset, test_dataset = dm.data.process(\n",
" path='sample_data/itunes-amazon',\n",
" train='train.csv',\n",
" validation='validation.csv',\n",
" test='test.csv',\n",
" ignore_columns=('left_id', 'right_id'))\n",
"\n",
"model = dm.MatchingModel()\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 1,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17757810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "oj3Jq4-ob-cN",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"For more details on lazy initialization, please refer to the [Lazy Initialization](#Design-Note:-Lazy-Initialization) section of this tutorial.\n",
"\n",
"At its core, a matching model has 3 main components: 1. Attribute Embedding, 2. Attribute Similarity Representation, and 3. Classifier. This is illustrated in the figure below:\n",
"\n",
"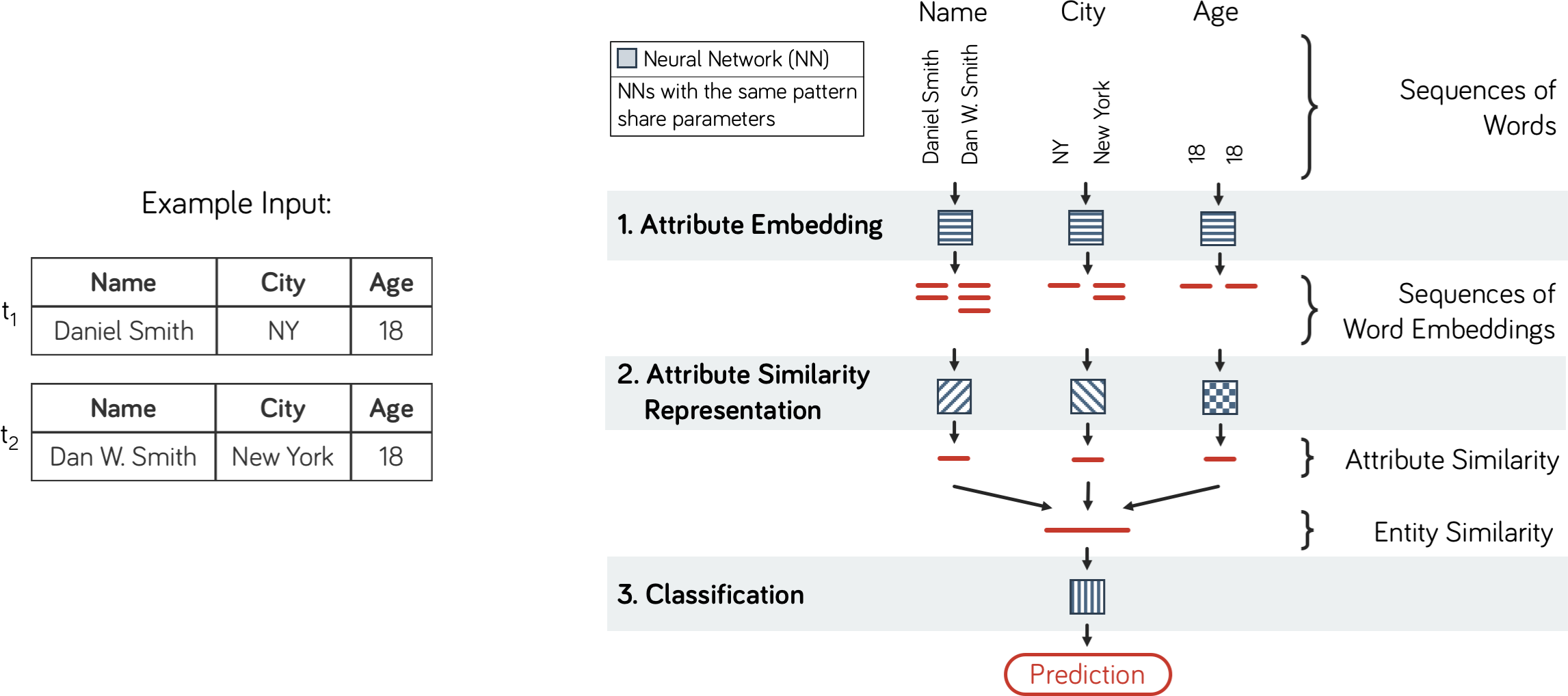\n",
"\n",
"\n",
"We briefly describe these components below. For a more in-depth explanation, please take a look at [our paper](http://pages.cs.wisc.edu/~anhai/papers1/deepmatcher-sigmod18.pdf). \n",
"\n",
"The 3 components are further broken down into sub-modules as shown:\n",
"\n",
"1. [Attribute Embedding](#1.-Attribute-Embedding)\n",
"2. [Attribute Similarity Representation](#2.-Attribute-Similarity-Representation)\n",
" 1. [Attr Summarizer](#2.1.-Attribute-Summarization)\n",
" 1. [Word Contextualizer](#2.1.1.-Word-Contextualizer)\n",
" 2. [Word Comparator](#2.1.2.-Word-Comparator)\n",
" 3. [Word Aggregator](#2.1.3.-Word-Aggregator)\n",
" 2. [Attr Comparator](#2.2.-Attribute-Comparator)\n",
"3. [Classifier](#3.-Classifier)\n",
"\n",
"## 1. Attribute Embedding\n",
"\n",
"The Attribute Embedding component (AE) takes in two sequences of words corresponding to the value of each attribute and converts each word in them to a word embedding (vector representation of a word). This produces two sequences of word embeddings as output for each attribute. This is illustrated in the figure below. For an intuitive explanation of word embeddings, please refer [this blog post](http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/#word-embeddings). The Attribute Embedding component is also presented in more detail in [our talk](http://bit.do/deepmatcher-talk). Note that this component is shared across all attributes - the same AE model is used for all attributes.\n",
"\n",
"\n",
"\n",
"### Customizing Attribute Embedding\n",
"\n",
"This component uses word embeddings that were loaded as part of data processing. To customize it, you can set the `embeddings` parameter in `dm.data.process`, as described in the [tutorial on data processing](https://nbviewer.jupyter.org/github/sidharthms/deepmatcher/blob/master/examples/data_processing.ipynb#3.-Word-Embeddings).\n",
"\n",
"## 2. Attribute Similarity Representation\n",
"\n",
"This component (ASR) takes attribute value embeddings, i.e., two sequences of word embeddings, and encodes them into a representation that captures their similarities and differences. Its operations are split between two modules as described below and as illustrated in the following figure:\n",
"\n",
"**2.1 Attribute Summarization (AS):** This module takes as input the two word embedding sequences and summarizes the information in them to produce two summary vectors as output. The role of attribute summarization is to aggregate information across all tokens in an attribute value sequence of an entity mention. This summarization process may\n",
"consider the pair of sequences of an attribute jointly to perform more sophisticated operations such as alignment. Folks in NLP: this has nothing to do with [text summarization](https://en.wikipedia.org/wiki/Automatic_summarization).\n",
"\n",
"**2.2 Attribute Comparison (AC):** This module takes as input the two summary vectors and applies a comparison function over those summaries to obtain the final similarity representation of the two attribute values. \n",
"\n",
"\n",
"\n",
"Note that unlike Attribute Embedding, this component is not shared across attributes - each attribute has its own dedicated ASR model. They share the same structure but do not share their parameters.\n",
"\n",
"### Customizing Attribute Similarity Representation\n",
"\n",
"The ASR can be customized by specifying the `attr_summarizer` and optionally the `attr_comparator` parameter as follows:"
]
},
{
"metadata": {
"id": "wF5xAr54b-cO",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "a767124d-3fd6-4392-b1c5-c05fdd6529b5",
"executionInfo": {
"status": "ok",
"timestamp": 1529117452705,
"user_tz": 300,
"elapsed": 669,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_summarizer='sif', attr_comparator='diff')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 2,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 662602 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "85kO7cLvb-cR",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `attr_summarizer` can be set to one of the following:\n",
"\n",
"- A string: One of the following 4 string literals\n",
" 1. 'sif': Use the SIF attribute summarizer (refer [our paper](http://pages.cs.wisc.edu/~anhai/papers1/deepmatcher-sigmod18.pdf) for details on SIF and other attribute summarizers). Equivalent to setting `attr_summarizer = dm.attr_summarizers.SIF()`.\n",
" 2. 'rnn': Use the RNN attribute summarizer. Equivalent to setting `attr_summarizer = dm.attr_summarizers.RNN()`.\n",
" 3. 'attention': Use the Attention attribute summarizer. Equivalent to setting `attr_summarizer = dm.attr_summarizers.Attention()`.\n",
" 4. 'hybrid': Use the Hybrid attribute summarizer. Equivalent to setting `attr_summarizer = dm.attr_summarizers.Hybrid()`.\n",
"\n",
"\n",
"- An instance of `dm.AttrSummarizer` or one of its subclasses:\n",
" 1. An instance of [`dm.attr_summarizers.SIF`](https://anhaidgroup.github.io/deepmatcher/html/attr_summarizers.html#deepmatcher.attr_summarizers.SIF): Use the SIF attribute summarizer.\n",
" 2. An instance of [`dm.attr_summarizers.RNN`](https://anhaidgroup.github.io/deepmatcher/html/attr_summarizers.html#deepmatcher.attr_summarizers.RNN): Use the RNN attribute summarizer.\n",
" 3. An instance of [`dm.attr_summarizers.Attention`](https://anhaidgroup.github.io/deepmatcher/html/attr_summarizers.html#deepmatcher.attr_summarizers.Attention): Use the Attention attribute summarizer.\n",
" 4. An instance of [`dm.attr_summarizers.Hybrid`](https://anhaidgroup.github.io/deepmatcher/html/attr_summarizers.html#deepmatcher.attr_summarizers.Hybrid): Use the Hybrid attribute summarizer.\n",
"\n",
"\n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module). The module must behave like an Attribute Summarizer, i.e., takes two word embedding sequences, summarizes the information in them and returns two vectors as output. Note that we cannot accept a PyTorch module directly as input because we may need to create multiple instances of this module, one for each attribute. Thus, we require that you specify custom modules via a `callable`.\n",
" - Input to module: Two 3d tensors of shape `(batch, seq1_len, input_size)` and `(batch, seq2_len, input_size)`. These tensors will be wrapped within [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor)s which will contain metadata about the batch. \n",
" - Expected output from module: Two 2d tensors of shape `(batch, output_size)`, wrapped within [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor)s (with metadata information unchanged). `output_size` need not be the same as `input_size`.\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "H8nDn46Qb-cS",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "84e2d8c2-815d-4c27-ef8d-3593d8c3a615",
"executionInfo": {
"status": "ok",
"timestamp": 1529117453323,
"user_tz": 300,
"elapsed": 432,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_summarizer='sif')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 3,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 662602 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "Kfn79k-7b-cV",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.AttrSummarizer` arg example:"
]
},
{
"metadata": {
"id": "_IgxP2nqb-cW",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "5e9a57f0-5bff-43fe-ddc6-8df503a79212",
"executionInfo": {
"status": "ok",
"timestamp": 1529117454271,
"user_tz": 300,
"elapsed": 761,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_summarizer=dm.attr_summarizers.RNN())\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 4,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 3917002 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "9FWiurKGb-cY",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom attribute summarizer, one that simply sums up all the word embeddings in each sequence. To do this we use two helper modules:\n",
"- [`dm.modules.Lambda`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Lambda): Used to create PyTorch module from a lambda function without having to define a class.\n",
"- [`dm.modules.NoMeta`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.NoMeta): Used to remove metadata information from the input and restore it back in the output.\n",
"\n",
"Note that since we are using a custom `attr_summarizer`, the `attr_comparator` must be specified."
]
},
{
"metadata": {
"id": "yRxf7nb7b-cZ",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "7481a1f5-4c71-4776-8190-c748bf060cd3",
"executionInfo": {
"status": "ok",
"timestamp": 1529117455488,
"user_tz": 300,
"elapsed": 1016,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"my_attr_summarizer_module = dm.modules.NoMeta(dm.modules.Lambda(\n",
" lambda x, y: (x.sum(dim=1), y.sum(dim=1))))\n",
"\n",
"model = dm.MatchingModel(attr_summarizer=\n",
" lambda: my_attr_summarizer_module, attr_comparator='abs-diff')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 5,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 662602 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "WeyyBuDNb-cd",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `attr_comparator` can be set to one of the following:\n",
"\n",
"- A string: One of the `style`s supported by the [`dm.modules.Merge`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Merge) module.\n",
"- An instance of [`dm.modules.Merge`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Merge)\n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module). The module must take in two vectors as input and produces one vector as output.\n",
" - Input to module: Two 2d tensors of shape `(batch, input_size)`. \n",
" - Expected output from module: One 2d tensor of shape `(batch, output_size)`. `output_size` need not be the same as `input_size`.\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "8C1VOXnFb-ce",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "63789da8-b22b-435a-a935-c2dbd882a8b2",
"executionInfo": {
"status": "ok",
"timestamp": 1529117457043,
"user_tz": 300,
"elapsed": 1248,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_comparator='concat')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 6,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17517810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "NAeR_qn5b-ci",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.modules.Merge` arg example:"
]
},
{
"metadata": {
"id": "KdzxO-Dtb-cj",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "589ad407-9537-496c-9c23-e6ac3a0bbaa9",
"executionInfo": {
"status": "ok",
"timestamp": 1529117458085,
"user_tz": 300,
"elapsed": 988,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_comparator=dm.modules.Merge('mul'))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 7,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17277810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "cnsb7iHXb-cm",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom attribute comparator, one that concatenates the two attribute summaries and their element-wise product. We use the [`dm.modules.Lambda`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Lambda) helper module again to create PyTorch module from a lambda function."
]
},
{
"metadata": {
"id": "ZTAzt8jub-cm",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "92caa9d0-3db6-4f09-a33a-61f541799b61",
"executionInfo": {
"status": "ok",
"timestamp": 1529117459107,
"user_tz": 300,
"elapsed": 983,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"my_attr_comparator_module = dm.modules.Lambda(\n",
" lambda x, y: torch.cat((x, y, x * y), dim=x.dim() - 1))\n",
"\n",
"model = dm.MatchingModel(attr_comparator=lambda: my_attr_comparator_module)\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 8,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17757810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "JXiwezYxb-cp",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"If `attr_comparator` is not set, `deepmatcher` will try to automatically set it based on the `attr_summarizer` specified. The following mapping shows the `attr_comparator` that will be used for various kinds of atrribute summarizers: \n",
"- Instance of `dm.attr_summarizers.SIF`: `attr_comparator='abs-diff'`\n",
"- Instance of `dm.attr_summarizers.RNN`: : `attr_comparator='abs-diff'`\n",
"- Instance of `dm.attr_summarizers.Attention`: : `attr_comparator='concat'`\n",
"- Instance of `dm.attr_summarizers.Hybrid`: : `attr_comparator='concat-abs-diff'`\n",
"\n",
"If the specified `attr_summarizer` is not a supported string and is not an instance of any of these classes, then `attr_comparator` must be specified.\n",
"\n",
"## 2.1. Attribute Summarization\n",
"\n",
"The Attribute Summarization module is the most critical component of a matching model. As mentioned earlier, it takes in two word embedding sequences and summarizes the information in them to produce two summary vectors as output. It consists of 3 sub-modules, described below and illustrated in the following figure:\n",
"\n",
"\n",
"\n",
"### 2.1.1. Word Contextualizer\n",
"This is an optional module that takes as input a word embedding sequence and produces a *context-aware* word embedding sequence as output. For example, consider the raw word embedding sequence for sentences \"Brand : Orange\" and \"Color : Orange\". In the first case, the output word embedding for \"Orange\" may be adjusted to represent the color orange, and in the second case, it may be adjusted to represent the brand orange. This module is shared for both word embedding sequences, i.e., the same neural network is used for both sequences. \n",
"\n",
"### 2.1.2. Word Comparator\n",
"This is an optional module takes as input two word embedding sequence (may or may not be context-aware), one of which is treated as the primary sequence and the other is treated as *context*. Intuitively, this modules does the following: \n",
"- For each word in the primary sequence, find the corresponding aligning word in the context sequence.\n",
"- Compare each word in the primary sequence with its corresponding word in the context sequence to obtain a *word comparison vector* for each word.\n",
"\n",
"The output of this module is the sequence of word comparison vectors, i.e., one word comparison vector for each word in the primary word embedding sequence. This module is shared for both word embedding sequences, i.e., the 1st word embedding sequence is compared to the 2nd to obtain a word comparison vector sequence for the 1st sequence, and the same network is used to compare the 2nd sequence to the 1st to obtain a word comparison vector sequence for the 2nd sequence.\n",
"\n",
"### 2.1.3. Word Aggregator\n",
"This module takes as input a sequence of vectors - either a sequence of word embedding or a sequence of word comparison vectors. It aggregates this sequence to produce a single vector as summarizing this sequence. This module may optionally make use of the other sequence as context. This module is shared for both word embedding sequences, i.e., the same neural network is used for both sequences. \n",
"\n",
"\n",
"### Customizing Attribute Summarization\n",
"\n",
"Attribute Summarization can be customized by specifying the `word_contextualizer`, `word_comparator`, and `word_aggregator` parameters while creating a `dm.AttrSummarizer` or any of its four sub-classes discussed above. For example, "
]
},
{
"metadata": {
"id": "vpDW9qNnb-cp",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "1523091c-b94d-459f-84b2-92d838bb89ec",
"executionInfo": {
"status": "ok",
"timestamp": 1529117460181,
"user_tz": 300,
"elapsed": 1015,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer=dm.attr_summarizers.Hybrid(\n",
" word_contextualizer='self-attention',\n",
" word_comparator='general-attention',\n",
" word_aggregator='inv-freq-avg-pool'))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 9,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 11973802 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "34SfYCr6b-cs",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `word_contextualizer` can be set to one of the following:\n",
"\n",
"- A string: One of the `unit_type` supported by : [`dm.word_contextualizers.RNN`](https://anhaidgroup.github.io/deepmatcher/html/word_contextualizers.html#deepmatcher.word_contextualizers.RNN) or 'self-attention'\n",
" 1. 'gru': Equivalent to setting `word_contextualizer = dm.word_contextualizers.RNN(unit_type='gru')`.\n",
" 2. 'lstm': Equivalent to setting `word_contextualizer = dm.word_contextualizers.RNN(unit_type='lstm')`.\n",
" 3. 'rnn': Equivalent to setting `word_contextualizer = dm.word_contextualizers.RNN(unit_type='rnn')`.\n",
" 4. 'self-attention': Equivalent to setting `word_contextualizer = dm.word_contextualizers.SelfAttention()`.\n",
" \n",
" \n",
"- An instance of `dm.WordContextualizer` or one of its subclasses:\n",
" 1. An instance of [`dm.word_contextualizers.RNN`](https://anhaidgroup.github.io/deepmatcher/html/word_contextualizers.html#deepmatcher.word_contextualizers.RNN): Use the RNN word contextualizer.\n",
" 2. An instance of [`dm.word_contextualizers.SelfAttention`](https://anhaidgroup.github.io/deepmatcher/html/word_contextualizers.html#deepmatcher.word_contextualizers.SelfAttention): Use the Self-Attention word contextualizer.\n",
" \n",
" \n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module).\n",
" - Input to module: One 3d tensor of shape `(batch, seq_len, input_size)`. The tensor will be wrapped within [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor) which will contain metadata about the batch.\n",
" - Expected output from module: One 3d tensor of shape`(batch, seq_len, output_size)`, wrapped within an [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor) (with metadata information unchanged). `output_size` need not be the same as `input_size`.\n",
"\n",
"We show some examples on how to customize word contextualizers for Hybrid attribute summarization modules (`dm.attr_summarizers.Hybrid`) below, but these are also applicable to other attribute summarizers:\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "z_5z8z93b-ct",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "fecbcb15-6c61-4c2c-9feb-14f45e4e66ac",
"executionInfo": {
"status": "ok",
"timestamp": 1529117461330,
"user_tz": 300,
"elapsed": 984,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer=dm.attr_summarizers.Hybrid(word_contextualizer='gru'))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 10,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 20645010 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "WUNLWeadb-cw",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.WordContextualizer` arg example:"
]
},
{
"metadata": {
"id": "-oC2UZ0Ob-cx",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "29118715-cb69-4fe7-aa50-03a4e05f2ceb",
"executionInfo": {
"status": "ok",
"timestamp": 1529117462682,
"user_tz": 300,
"elapsed": 1176,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"# Example 2: dm.AttrSummarizer arg.\n",
"model = dm.MatchingModel(\n",
" attr_summarizer = dm.attr_summarizers.Hybrid(\n",
" word_contextualizer=dm.word_contextualizers.SelfAttention(heads=2)))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 11,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 26059410 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "dPcQtRPwb-c1",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom convolutional word contextualizer. To do this, we need the `input_size` dimension. This will be provided if the `callable` takes in one argument named `input_size` as shown. We then use this input size to create a convolutional layer. But the convolutional layer expects the sequence length dimension to be last. To deal with this we swap the 2nd and 3rd dimensions of the tensor before and after convolution. We also use [`dm.modules.Lambda`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Lambda) and [`dm.modules.NoMeta`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.NoMeta) as in earlier examples."
]
},
{
"metadata": {
"id": "2FjnTxl_b-c2",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "d62bafd5-fa89-462f-deb9-c9a40f69dc0d",
"executionInfo": {
"status": "ok",
"timestamp": 1529117463975,
"user_tz": 300,
"elapsed": 1157,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"def my_word_contextualizer(input_size):\n",
" return dm.modules.NoMeta(torch.nn.Sequential(\n",
" dm.modules.Lambda(lambda x: x.transpose(1, 2)),\n",
" torch.nn.Conv1d(in_channels=input_size, out_channels=512, \n",
" kernel_size=3, padding=1),\n",
" dm.modules.Lambda(lambda x: x.transpose(1, 2))))\n",
"\n",
"model = dm.MatchingModel(attr_summarizer=dm.attr_summarizers.Hybrid(\n",
" word_contextualizer=my_word_contextualizer))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 12,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 38093682 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "nL_xR4-Ub-c5",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `word_comparator` can be set to one of the following:\n",
"\n",
"- A string: One of the following 3 string literals:\n",
" 1. 'decomposable-attention': Equivalent to setting `word_comparator = dm.word_comparators.Attention(alignment_network='decomposable')`.\n",
" 2. 'general-attention': Equivalent to setting `word_comparator = dm.word_comparators.Attention(alignment_network='general')`.\n",
" 3. 'dot-attention': Equivalent to setting `word_comparator = dm.word_comparators.Attention(alignment_network='dot')`.\n",
" \n",
" \n",
"- An instance of `dm.WordComparator` or one of its subclasses:\n",
" 1. An instance of `dm.word_comparators.Attention`: Use the Attention word comparator. \n",
" \n",
" \n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module). \n",
" - Inputs to module: Four input tensors, all of which will be wrapped within [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor)s.\n",
" 1. Primary context-aware word embedding sequence. Shape: `(batch, seq1_len, input_size)`\n",
" 2. Secondary context-aware word embedding sequence, i.e., the sequence to compare the primary sequence with. Shape: `(batch, seq1_len, input_size)`\n",
" 3. Raw word embedding sequence (context-unaware). Shape: `(batch, seq1_len, raw_input_size)`\n",
" 4. Raw secondary context-aware word embedding sequence (context-unaware). Shape: `(batch, seq2_len, raw_input_size)`\n",
" - Expected output from module: One 3d tensor of shape`(batch, seq1_len, output_size)`, wrapped within an [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor) (with the same metadata information as the first input tensor). `output_size` need not be the same as `input_size`.\n",
" - Notes:\n",
" - The custom module may choose to ignore the last two raw context-unaware inputs if they are deemed unnecessary.\n",
" - If no Word Contextualizer is used, the last two inputs will be the same as the first two inputs. \n",
"\n",
"We show some examples on how to customize word comparators for Hybrid attribute summarization modules (`dm.attr_summarizers.Hybrid`) below, but these are also applicable to other attribute summarizers:\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "TcH8sEQ5b-c6",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "9f79bd7b-dde2-4b64-d71f-0a049b2a8754",
"executionInfo": {
"status": "ok",
"timestamp": 1529117465409,
"user_tz": 300,
"elapsed": 1240,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer=dm.attr_summarizers.Hybrid(word_comparator='dot-attention'))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 13,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 20645010 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "fxd9LfQEb-c9",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.WordComparator` arg example:"
]
},
{
"metadata": {
"id": "SMuzQpBWb-c-",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "c267c2e8-c592-484e-f2d1-f13f31fd5a9c",
"executionInfo": {
"status": "ok",
"timestamp": 1529117467489,
"user_tz": 300,
"elapsed": 2031,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer = dm.attr_summarizers.Hybrid(\n",
" word_comparator=dm.word_comparators.Attention(heads=4, input_dropout=0.2)))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 14,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 29675010 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "B3_J6fO-b-dC",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom word comparator, one that uses the Attention word comparator but has a 2 layer RNN following it. Since there are multiple inputs, we cannot use the standard `torch.nn.Sequential`, but we can instead use the [`dm.modules.MultiSequential`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.MultiSequential) utility module."
]
},
{
"metadata": {
"id": "d_dYrzbCb-dC",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "5b86a089-590f-4eac-ea18-6da3f70cfcbd",
"executionInfo": {
"status": "ok",
"timestamp": 1529117468905,
"user_tz": 300,
"elapsed": 1276,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(attr_summarizer=dm.attr_summarizers.Hybrid(\n",
" word_comparator=lambda: dm.modules.MultiSequential(\n",
" dm.word_comparators.Attention(),\n",
" dm.modules.RNN(unit_type='gru', layers=2))))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 15,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 27153810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "ChpHrGsib-dH",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `word_aggregator` can be set to one of the following:\n",
"\n",
"- A string: One of the following string literals:\n",
" - One of the `style`s supported by the [`dm.modules.Pool`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Pool) module suffixed by '-pool', e.g., 'avg-pool', 'sif-pool', 'divsqrt-pool', etc.\n",
" - Equivalent to setting `word_aggregator = dm.word_aggregators.Pool()`\n",
" - E.g. equivalent to setting `word_aggregator = dm.word_aggregators.Pool('avg')`\n",
" - 'attention-with-rnn': Equivalent to setting `word_aggregator = dm.word_aggregators.AttentionWithRNN()`\n",
" \n",
" \n",
"- An instance of `dm.WordAggregator` or one of its subclasses:\n",
" 1. An instance of [`dm.word_aggregators.Pool`](https://anhaidgroup.github.io/deepmatcher/html/word_aggregators.html#deepmatcher.word_aggregators.Pool): Use the Pool word aggregator.\n",
" 2. An instance of [`dm.word_aggregators.AttentionWithRNN`](https://anhaidgroup.github.io/deepmatcher/html/word_aggregators.html#deepmatcher.word_aggregators.AttentionWithRNN): Use the AttentionWithRNN word aggregator.\n",
" \n",
" \n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module).\n",
" - Input to module: Two 3d tensor of shape `(batch, seq1_len, input_size)` and `(batch, seq2_len, input_size)`. The tensors will be wrapped within [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor)s which will contain metadata about the batch.\n",
" - Expected output from module: One 2d tensor of shape`(batch, output_size)`, wrapped within an [`AttrTensor`](https://anhaidgroup.github.io/deepmatcher/html/batch.html#deepmatcher.batch.AttrTensor) (with the same metadata information as the first input tensor). This output must be the aggregation of the sequence of vectors in the first input (primary input), optionally taking into account the context input, i.e., the second input. `output_size` need not be the same as `input_size`.\n",
"\n",
"We show some examples on how to customize word aggregators for Hybrid attribute summarization modules (`dm.attr_summarizers.Hybrid`) below, but these are also applicable to other attribute summarizers:\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "GMVh9V2Qb-dH",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "970c2e55-8e5f-4771-f8f0-d703c090bf38",
"executionInfo": {
"status": "ok",
"timestamp": 1529117469564,
"user_tz": 300,
"elapsed": 633,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer=dm.attr_summarizers.Hybrid(word_aggregator='max-pool'))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 16,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 11616202 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "nOc2iUUlb-dM",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.WordAggregator` arg example:"
]
},
{
"metadata": {
"id": "ld_V1eHJb-dM",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "487dbbbf-445f-4a50-82bb-0d7263831fe5",
"executionInfo": {
"status": "ok",
"timestamp": 1529117470745,
"user_tz": 300,
"elapsed": 1040,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(\n",
" attr_summarizer = dm.attr_summarizers.Hybrid(\n",
" word_aggregator=dm.word_aggregators.AttentionWithRNN(\n",
" rnn='lstm', rnn_pool_style='max')))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 17,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 21729810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "-YbfwIqnb-dQ",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom word aggregator, one that concatenates the average and max of the given input sequence. We also use [`dm.modules.Lambda`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Lambda) and [`dm.modules.NoMeta`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.NoMeta) as in earlier examples."
]
},
{
"metadata": {
"id": "VEZXGYFIb-dQ",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "427c80db-dbd2-4729-9152-d5068ab29e87",
"executionInfo": {
"status": "ok",
"timestamp": 1529117472065,
"user_tz": 300,
"elapsed": 1058,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"my_word_aggregator_module = dm.modules.NoMeta(dm.modules.Lambda(\n",
" lambda x, y: torch.cat((x.mean(dim=1), x.max(dim=1)[0]), dim=-1)))\n",
"\n",
"# Next, create the matching model.\n",
"model = dm.MatchingModel(\n",
" attr_summarizer = dm.attr_summarizers.Hybrid(word_aggregator=\n",
" lambda: my_word_aggregator_module))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 18,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 11856202 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "YXPO5dLUb-dT",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"## 3. Classifier\n",
"\n",
"This component takes the attribute similarity representations and uses those as features for a classifier that determines whether the input tuple pair refers to the same real-world entity.\n",
"\n",
"### Customizing Classifier\n",
"\n",
"The ASR can be customized by specifying the `classifier` parameter as follows:"
]
},
{
"metadata": {
"id": "KGhviLybb-dV",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "1fe88908-9392-41f6-826a-b6234f7470ad",
"executionInfo": {
"status": "ok",
"timestamp": 1529117473950,
"user_tz": 300,
"elapsed": 935,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(classifier='3-layer-residual-relu')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 19,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17938410 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "EI4baGlub-da",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"#### `classifier` can be set to one of the following:\n",
"\n",
"- A string: A valid `style` string supported by the [`dm.modules.Transform`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Transform) module.\n",
"- An instance of [`dm.Classifier`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Transform).\n",
"- A [`callable`](https://docs.python.org/3/library/functions.html#callable): Put simply, a function that returns a PyTorch [Module](http://pytorch.org/docs/master/nn.html#torch.nn.Module). The module must take in one vectors as input and produce the log probability of non-match and match as output. Two outputs are used instead of one to work around a numerical stability issue in torch.\n",
" - Input to module: Two 2d tensors of shape `(batch, input_size)`. \n",
" - Expected output from module: One 2d tensor of shape `(batch, 2)`. The second dimension must contain non-match and match class probabilities, in that order.\n",
"\n",
"`string` arg example:"
]
},
{
"metadata": {
"id": "fq7ZGYHXb-db",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "8b8cdbb4-5675-4e6f-89a2-d64a7c96e474",
"executionInfo": {
"status": "ok",
"timestamp": 1529117474933,
"user_tz": 300,
"elapsed": 943,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(classifier='2-layer-highway-tanh')\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 20,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17757810 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "YzOKQvU3b-de",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`dm.Classifier` arg example:"
]
},
{
"metadata": {
"id": "6K_xh6-Rb-de",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "7b3a640f-16d0-4d3a-8a49-98c7c8ffc0b1",
"executionInfo": {
"status": "ok",
"timestamp": 1529117475998,
"user_tz": 300,
"elapsed": 946,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"model = dm.MatchingModel(classifier=dm.Classifier(\n",
" dm.modules.Transform('3-layer-residual', non_linearity=None, \n",
" hidden_size=512)))\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 21,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 19137482 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "doO4TR6Eb-dh",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"`callable` arg example: We create a custom classifier, one that outputs 3 class probabilities (e.g., for text entailment). We also use [`dm.modules.Lambda`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.Lambda) and [`dm.modules.NoMeta`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.NoMeta) as in earlier examples."
]
},
{
"metadata": {
"id": "rHJs4tORb-dh",
"colab_type": "code",
"colab": {
"autoexec": {
"startup": false,
"wait_interval": 0
},
"base_uri": "https://localhost:8080/",
"height": 33
},
"outputId": "f77f4726-15c1-4d30-fceb-76be90e9be36",
"executionInfo": {
"status": "ok",
"timestamp": 1529117476963,
"user_tz": 300,
"elapsed": 948,
"user": {
"displayName": "",
"photoUrl": "",
"userId": ""
}
}
},
"cell_type": "code",
"source": [
"my_classifier_module = torch.nn.Sequential(\n",
" dm.modules.Transform('2-layer-highway', hidden_size=300),\n",
" dm.modules.Transform('1-layer', non_linearity=None, output_size=3),\n",
" torch.nn.LogSoftmax(dim=1))\n",
"\n",
"model = dm.MatchingModel(classifier=lambda: my_classifier_module)\n",
"model.initialize(train_dataset) # Explicitly initialize model."
],
"execution_count": 22,
"outputs": [
{
"output_type": "stream",
"text": [
"INFO:deepmatcher.core:Successfully initialized MatchingModel with 17758111 trainable parameters.\n"
],
"name": "stderr"
}
]
},
{
"metadata": {
"id": "nA93naN-b-dl",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
"## Design Note: Lazy Initialization\n",
"\n",
"As mentioned earlier, `deepmatcher` follows a lazy initialization paradigm. This enables it to:\n",
"1. Easily create clones of modules: These clones share the same structure but have their own separate trainable parameters.\n",
"2. Automatically infer input sizes: In order to initialize the model `deepmatcher` performs one full forward pass through the model. In this process, each component is initialized sonly after initializing all its parent modules in the computational graph. This makes automatic input size inference for modules possible. As a result, plugging in custom modules in the middle of the network is much easier as you do not have to manually compute the input size.\n",
"3. Verify module output shapes: Having incorrect output shapes in custom modules can introduce subtle bugs that are difficult to catch. As part of initialization, `deepmatcher` verifies that all modules output tensors with the correct output shapes. This verification is done only once during initialization to avoid slowing down training.\n",
"\n",
"It's becase of the above reasons 1 and 2 that `deepmatcher` does not permit custom modules to be specified directly and requires them to be specified via functions.\n",
"\n",
"The core module that enables lazy initialization is [`dm.modules.LazyModule`](https://anhaidgroup.github.io/deepmatcher/html/modules.html#deepmatcher.modules.LazyModule) which is a base class for most modules in `deepmatcher`."
]
}
]
}