{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"slideshow": {
"slide_type": "skip"
}
},
"outputs": [],
"source": [
"---\n",
"jupyter:\n",
" jupytext:\n",
" cell_markers: region,endregion\n",
" comment_magics: false\n",
" formats: ipynb,.pct.py:hydrogen,Rmd,md\n",
" text_representation:\n",
" extension: .py\n",
" format_name: hydrogen\n",
" format_version: '1.1'\n",
" jupytext_version: 1.1.5\n",
" kernelspec:\n",
" display_name: Python 3\n",
" language: python\n",
" name: python3\n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"*ANLY 580: Natural Language Processing for Data Analytics*
\n",
"*Fall 2019*
\n",
"# 1. Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Logistics\n",
"- [Syllabus](https://georgetown.instructure.com/courses/81464/assignments/syllabus) on Canvas\n",
"- [Course GitHub repository](https://anyl580.github.io)\n",
"- Assignments\n",
"- Scientific Paper\n",
"- Rubrics\n",
"- Readings"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"If you haven't yet filled out the questionnaire, please go to canvas to get the Survey in Canvas. This is a rather large class and this should facilitate our getting to know each other and the skills / background you bring to the program. Hopefully, this will also help us to somewhat tailor the course to your needs and interests!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Course Objectives\n",
"* Ability to identify language data problems, translate to NLP tasks, and communicate findings clearly\n",
"* Understanding of NLP tasks\n",
"* Familiarity with NLP tools for data science\n",
"* Ability to evaluate performance in applied settings\n",
"* Knowledge about where to find NLP resources\n",
"* Practice at producing and presenting scientific work"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Understanding the Problem\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram\n",
"\n",
"What is domain expertise?\n",
"For NLP this can mean:\n",
"- Domain expertise in linguistics\n",
"- Domain expertise in a particular language or culture\n",
"- Domain expertise with respect to the business need and genre of language (e.g., contract language)\n",
"\n",
"Perhaps, the most important skill as a data scientist is your ability to understand the user problem so that you solve the *right* problem. It's extremely easy to get caught up in hearing \"translation\" problem and immediately gravitating to the assumption that the problem is \"Machine Translation.\"\n",
"\n",
"When you have the opportunty, visit users in *their* environment and ask them to show you what they are trying to do. Try to understand the problem from their perspective and think about different ways to solve the problem. Get feedback on your ideas and try to avoid talking about tools, rather focus on ideas. Keep in mind that you are solving both a business problem and a user problem.\n",
"\n",
"More thoughts in this vein: [Don't do Data Science, Solve Business Problems](https://towardsdatascience.com/dont-do-data-science-solve-business-problems-6b70c4ee0083)"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Properties of Language\n",
"- Cooperative - SOCIAL\n",
"- Multi-signal: spoken (incl. gesture), signed, written\n",
"- Generative - symbolic, logical, compositional, structurally complex\n",
"- Encode information grammatically and through convention\n",
"- Perpetually changing"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"More than 6ooo human languages today. 94% of the world's language account for only 6% of the world's population. (Check https://www.ethnologue.com to learn more!)\n",
"\n",
"\n",
"There is no clear distinction between a language and dialect. Languages tend to be grouped sociopolitically and also in terms of mutual intelligibility, writing systems, geography, and culture.\n",
"\n",
"Regardless, language is a *social* phenomenon. What makes human language unique from other forms of animal communication is it's *productivity* (i.e.,, generative nature) and it's *expressiveness.* Theoretical linguistics has long sought to tease out universal principles that underlie all human language. In addition to basic cognitive capacity, language must be learned early in childhood and is also deeply entwined with culture and convention.\n",
"\n",
"Because it is inherently social, language use is variable -- crossing social boundaries, conventional use across media, and over time. In fact, language changes very quickly - and especially where different cultures contact one another. Because language is so variable, it poses particular challenges for language processing."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Language in the Brain\n",
"[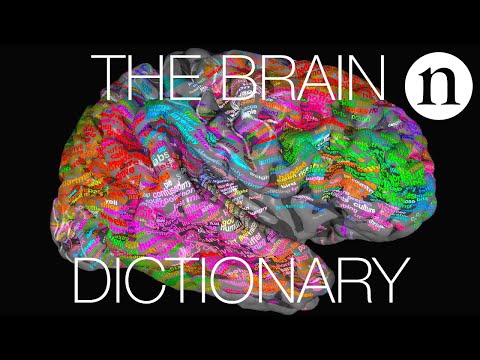](https://youtu.be/k61nJkx5aDQ)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"## The Brain Dictionary\n",
"It turns out the language is distributed across the entire cortex. But they cluster together by meaning. This was an enormous discovery. https://www.theguardian.com/science/2016/apr/27/brain-atlas-showing-how-words-are-organised-neuroscience\n",
"\n",
"\n",
"This image depicts a person's right cerebral hemisphere. The overlaid words, when heard in context, are predicted to evoke strong responses near the corresponding location. Green words are mostly visual and tactile, red words are mostly social.\n",
"\n",
" This view intimates that linguistic capacity is distributed across your entire cerebral cortex. A single location in the brain is associated with a number of words and one word may activate multiple regions of the brain. Thus, semantic concepts are activated by priming or stimulating neural networks.\n",
"\n",
"The original scientific article is found here:\n",
"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4852309/pdf/nihms765514.pdf\n",
"\n",
"If this interests you, play around with semantic maps in an [Interactive 3D viewer](https://gallantlab.org/huth2016/)"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"What we know about human language in the brain has largely come from studying people with damaged people and more recently from brain imaging. Anatomical studies indicate that certain regions of the brain play a role in linguistic processes.\n",
"\n",
"For example, Broca's area, once thought to be a center in speech production and syntactic processing is probably not the center of such functionality, but participating as a node in broader neural processes (e.g., motor processes, computational processes).\n",
"\n",
"That said, neuroscience has tools that give deeper insight into linguistic processing that also inform approaches to processing language.\n",
"\n",
"The study of language is highly inter-disciplinary including not just linguists but neuroscientists, psychologists, anthropologists, sociologists, computer scientists, and others."
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Dual Processing\n",
"**The** fast-thinking part **of your** brain creates **the** basic structure **of the** sentence (**the** words **here** marked **in** bold). **The** other words require **the** slower, more calculating part **of your** brain."
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0,
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Example from: https://www.technologyreview.com/s/611640/data-mining-reveals-fundamental-pattern-of-human-thinking/\n",
"\n",
"There is a difference between \"function words\" such as the articles, prepositions, pronouns, and other \"closed class\" words, and \"content words\".\n",
"\n",
"\"In English, the most popular word is the, which makes up about 7 percent of all words, followed by and, which occurs 3.5 percent of the time, and so on. Indeed, about 135 words account for half of all word appearances. So a few words appear often, while most hardly ever appear.\"\n",
"\n",
"Other languages follow the same sort of distributional pattern.\n",
"\n",
"A possible explanation for this distribution is accounted for by dual process theory, as described by [Kahneman (2011)](https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow). There may be two ways in which we process words (or phrases) in the brain. Dual process theory provides an account for thought arising from both the unconscious (fast) and controlled (slow). The multiplication of two three digit numbers in one's head involves the use of working memory and planning circuitry. But estimating whether a car looks cheap or expensive involves a more heuristic process and judgement is largely formed through unconscious processes.\n",
"\n",
"The same may be true of language. Function words are largely grammaticalized information accessible via unconscious processes. Indeed, when you first learn a new language it is effortful to form utterances and later becomes much easier as unconscious processes assimilate patterns at different levels of analysis. Yet, you still make conscious choices about the words you might use to frame your thoughts, depending on the audience. And despite this, you would not expend much energy thinking about whether to insert smaller, grammaticalized pieces of information. Your ability to use such information is largely driven by unconscious processes. In fact, our brains are quite efficient in the use of language using as little effort as possible."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Categories, Concepts, and Objects\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"One of the first things we learn as infants is how to communicate by connecting objects to concepts and concepts to words (or symbols). Our sound system is itself perceptually categorical - though with learned variation across cultures. (For example, in English we distinguish between voiceless \"p\" and voiced \"b\" in a categorical sense such that \"pig\" and \"big\" are perceived as different words.)\n",
"\n",
"Indeed, language use in general seems oriented toward categories. Think about your perception of color. While colors are clearly gradational, we make distinction along the visible, electromagnetic spectrum and communicate with discrete color names, accordingly.\n",
"\n",
"That said, we also use 'intensifiers' to indicate more/less, as well as other sorts of expressive strategies."
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Symbolic Processing\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: https://searocraeft.wordpress.com\n",
"\n",
"The structure of language has also been analyzed as symbolic. Formal languages and models were adapted for language analysis at least back as far as the early 1950's when [Bar-Hillel suggested the possibility of universal syntactic categories](http://www.mt-archive.info/Bar-Hillel-1953.pdf) and potential ramification for machine translation.\n",
"\n",
"Noam Chomsky went on to compose a treatise on syntactic structures to show that a limited set of rules and symbols could generate all well-formed (i.e., valid) grammatical sentences for a language. (And excluding those that are not.)\n",
"\n",
"That said... purely symbolic approaches to language processing have been problematic. One large problem, for example, is the problem of ambiguity. We often don't even notice ambiguity because we are so good at making use of surrounding context.\n",
"\n",
"Example, \"He saw the girl with the telescope.\"\"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Symbols as Continuous\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: Christopher Manning 2017. \n",
"\n",
"For more about this talk, visit https://simons.berkeley.edu/talks/christopher-manning-2017-3-27 or watch directly in YouTube at https://youtu.be/nFCxTtBqF5U.\n",
"\n",
"As Christopher Manning and others have noted, symbols are not only categorical in nature, but continuous! And, in fact, the brain encodes information in a continuous pattern of activation. Deep Learning methods take advantage of this dual-natured representational system.\n",
"\n",
"Though Manning notes particularly sound, gesture, and writing as perceptually continuous in nature, even syntactic categories are less absolutely categorical as we might imagine."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Symbolic to Distributed\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image from: https://nlp.stanford.edu/manning/talks/Simons-Institute-Manning-2017.pdf\n",
"\n",
"A key idea from distributional semantics has had tremendous impact on modern methods in language processing. The distributional hypothesis posits linguistic items with similar distributions have similar meanings.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 2,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Language is Social\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Adding to the complexity of language as a communication system is that it is inherently social. The way we talk depends not only on intent (let alone cooperative intent!) but also who we are talking with, who may be listening, and what we think our interlocutors understand.\n",
"\n",
"Not only does language change - but we use different strategies for communication depending on the social context.\n",
"\n",
"Fundamentally, language understanding is achieved by joint action. People participate in joint activities to achieve goals.\n",
"\n",
"In most joint activities, people pursue multiple goals - public and private goals. Business goal (transaction), procedural goals (doing this quickly and efficiently), interpersonal goals (remaining polite), private agendas.\n",
"\n",
"Joint activities require coordination and we use conventional procedures and language as a part of coordinating actions."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Spoken Language\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"*Humans are inherently wired for conversation -- and conversation is a kind of joint action.*\n",
"- Understanding is incremental\n",
"- We ground understanding\n",
"- We use sequences\n",
"- We signal shifts (e.g., stance, topics)\n",
"Most conversational actions aren't sequential but over-lapping in time. They may not be so discrete but continuous, as well. Timing is important to understanding meaning -- not just the sequence.\n",
"\n",
"Humans are really good at dialogue. The capacity is built into us. This contrasts from the use of formal or written language which must be explicitly learned.\n",
"\n",
"We'll talk about dialog in the last class of this course. If anything, we may predict that 2019 or 2020 will be the \"year of dialog in NLP.\" Dialog is extremely difficult, but there is also great excitement in tackling it using Deep Learning architectures."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Written Language\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image source (screen shot): https://corpling.uis.georgetown.edu/rstweb/info/\n",
"\n",
"In some sense, the structure in written language is more obvious.\n",
"\n",
"The image on the left is an academic paper. The structure is conventionalized and familiar. Easily recognizable are document title, headers, authors. etc. Slightly less obvious sorts of chunking are paragraph sections, sentences, footnotes, and abbreviations. These conventions are learned.\n",
"\n",
"The image on the right is a screenshot of a tool called RSTweb. It is designed for the study of discourse structure. In particular, it was designed for relating structural elements in text used in text generation. But because annotators can related segments of text, it can also support the creation of corpora for the purpose of showing relations between other elements in text such as relating pronouns to person mentions or demonstratives (e.g., this, that) to clauses.\n",
"\n",
"While abstract structural elements such as rhetorical structure - structure created by an author to persuade or inform - has strong links to textual analysis. Discourse structure - structural elements that extend beyond a sentence - remains a significant challenge to NLP. What you will likely notice is that NLP tools do very well at the sentence level and less well with discourse. That said, this is an intense area of research."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Linguistic Abstractions\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"The study of language is a huge field. Language is often the best view into thought and intension - though increasingly we have the need to focus on other signals, such as eye movement or other behavior.\n",
"\n",
"Linguistics is an empirical tradition and is driven by observation. Linguists strive to find patterns in language use, not to explain behavior as a psychologist might, but to better understand how we think and communicate as a species.\n",
"\n",
"Linguistics is such a broad field, that it is broken into multiple categories as shown below.\n",
"\n",
"\n",
"How does computational linguistics differ from NLP? [Jason Eisner gives an excellent answer on Quora](https://www.quora.com/How-is-computational-linguistics-different-from-natural-language-processing). He makes the distinction in terms of research goals. **Computational linguists** strive to answer questions about language and how humans compute it. NLP practitioners are focused on the engineering side of the house - how do we analyze text to answer questions. **Data scientists**, in particular, care about how they can best answer some sort of \"business\" question.\n",
"\n",
"Another way to look at this is, computational linguists are often engaged in pushing the research, while data scientists strive to improve the practice.\n",
"\n",
"If you find this course interesting, you may want to learn more about computational linguistics."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"# Language Processing Examples\n",
"These are just some examples.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Corpus Linguistics\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"A parallel tradition in the study of language has been the study of language *as it exists in the real world.*\n",
"\n",
"In fact, there had been a long tension between those that studied actual \"language use\" and those that introspected on theory.\n",
"\n",
"The screenshot above shows a tool typical for corpus linguistics. In essence, corpus linguists use digitized texts to study language at a relatively fine-grained level by using patterns derived from large amounts of text.\n",
"\n",
"How is corpus linguistics related to NLP?\n",
"\n",
"They overlap heavily. Corpus linguistics embodies statistics and methods that linguists and linguistic practitioners use to study language use, while NLP focuses on engineering tasks using similar statistics and methods.\n",
"\n",
"Typical tools include:\n",
"- Word frequencies\n",
"- Associational measures (collocation analysis - what terms are associated with any particular word?)\n",
"- Concordances (key words and words that occur around them)\n",
"- Word clusters\n",
"\n",
"Research gains in NLP have relied heavily upon the development of structured corpora for training and testing. For example, the Brown Corpus (1967) was a carefully compiled selection of American English texts of about a million words. The American Heritage Dictionary was the first compiled using corpus linguistics - how English is actually used vice how society thinks it should be used (prescriptive use).\n",
"\n",
"Corpora can be intensely resource consuming to produce since often human annotations and judgements are required. For some corpora, theoretical frameworks are needed (e.g., parts-of-speech) and, therefore, annotations require expert intervention.\n",
"\n",
"Corpora are inherently biased. (\"Bias\" means a systematic pattern.) Linguistic data itself contains cultural bias and thus imparts these biases via derived models."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP Tasks\n",
"- **Text Processing tasks**: tokenization, sentence segmentation, stemming/lemmatization, etc.\n",
"- **Sentential level processing**: POS, parsing, Named Entity Recognition, semantic roles, etc.\n",
"- **Discourse processing**: co-reference, relationship extraction, entailment, etc.\n",
"- **Application areas**: MT, sentiment, text classification, Q&A, Dialog, etc."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"NLP tasks are, in effect, categories based on processing challenges. And, to some extent, they line up with different levels of linguistic abstraction. Some tasks involve yet more fine-grained sub-tasks.\n",
"\n",
"The categories provided in this slide are intended only as a rough framework by which you think about NLP tasks. There are many ways to lump and split processing tasks and you will not see a definitive list.\n",
"\n",
"One important development in NLP in the last couple of years is that it is now possible to do multi-task modeling!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Rules\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"While we know that language is a context-sensitive system, many NLP tools were originally developed as context-free, finite state automota. Indeed, rules are still a very powerful tool and you already use them when you creating regular expressions.\n",
"\n",
"Often, if you have little data or time, this is the most productive approach to take."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Statistical \n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Deep Learning\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"We are all learning new schools by adopting deep learning. There is a reduced focus on explicit pipelines, perhaps, but a larger focus on neural network architectures.\n",
"\n",
"Domain expertise is still critical for developing and tuning very good models. The ability to closely examine errors or problems is key - and remains quite challenging."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Why is this science?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"Image credit: https://towardsdatascience.com/is-data-science-really-a-science-9c2249ee2ce4\n",
"\n",
"What is data science without science?\n",
"You could characterize data exploration as a part of data engineering. But data science is not just the extraction of knowledge from data nor data exploration.\n",
"\n",
"So why is “science” in data science so important?\n",
"Much of what you are doing in NLP involves prediction. To produce meaningful results, we use empirical methods to validate the output of algorithms and models, since we can’t always determine validity through direct inspection of every bit of data.\n",
"\n",
"What is empiricism? \n",
"Emperial knowledge is based on evidence from observation and experimentation. This idea contrasts with the idea that knowledge is based on reason (or argument). \n",
"\n",
"Noah Smith notes that hand-crafted knowledge sources are an example of information we might use as a resource. And in fact, theories in linguistic are largely driven by rationalist thinking - though informed by evidence from data. Knowledge from data itself (via text corpora) have come to play a crucial role in the computational analysis of language. Indeed, this empirical manner of thinking drives science and how we as (data) scientists work. \n",
"\n",
"What is the scientific process you will typically follow when you are assessing data that involves inferencing?\n",
"\n",
"- Clearly identify a business question\n",
"- Transform it to a data science question (or set of questions)\n",
"- Create a hypotheses around questions that can be examined statistically (so you must also define the test and assess validity)\n",
"- Design an experiment to test this hypothesis\n",
"- Draw conclusions through experimental results\n",
"\n",
"In all of this, you are not proving the correctness of your hypothesis, but rather creating supportive evidence for your conclusion.\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP in Data Science\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Only a few years ago, NLP required the domain expertise of a computational linguist. This was because either 1) linguists constructed rules using knowledge-based approaches and/or 2) machine learning techniques often required explicit determination of features.\n",
"\n",
"Deep Learning has turned NLP on its head. While neural nets have been around for a long time and also used in NLP, they were neither powerful enough (remember Moore's law?) nor was the sufficient data to drive them.\n",
"\n",
"NLTK was the first package that \"data scientists\" have been able to use to do any sort of NLP. But it was not designed as an industrial tool, rather as a teaching tool. Only recently, have industrial APIs become available and accessible to data scientists.\n",
"\n",
"Another exciting development is that, through efforts such as Jeremy Howard's fast.ai course, deep learning is accessible directly to domain experts who are not expert programmers or statisticians.\n",
"\n",
"These developments are most definitely alarming to computational linguists and also machine learning experts. But at the same time exciting!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP Pipelines\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: https://spacy.io/usage/processing-pipelines\n",
"\n",
"NLP tasks generally require processing in multiple steps. This processing is known as an NLP pipeline. At the very least, there is a step to tokenize text - to process text as a string. In the SpaCy pipeline illustrated, other processing steps take a document and return a document. The order in which you organize NLP steps depends on what you are trying to accomplish and what the models entail as input. For example, if you have a parser that requires part-of-speech tags, then you will need to provide tagged input into the parser.\n",
"\n",
"We're going to go through SpaCy tutorials later in the class and you will be building your own NLP pipelines."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# What is a word?\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Your reading on \"What is a word\" (Grefenstette & Tapanainen, 1994) focuses on the practical challenge of tokenizing text - it raises a basic question about how to break apart text into discrete units *using surface (or orthographic) form.* If this is not so straightforward in English, imagine how challenging it must be with languages that do not use conventions such as whitespace."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"# The Brown Corpus\n",
"The Brown Corpus was an achievement in the late 1960s containing 500 samples of English language text across a broad range of sources and more than 1M words. Kucera and Francis used this corpus as the basis for a computational analysis - and it later became the base for the first dictionary (American Heritage) to use statistical information about word use.\n",
"\n",
"NLTK includes the part-of-speech tagged version of the Brown Corpus which includes about 80 parts of speech. More information on the tag set and basic structure (data description can be found here: http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/index.html)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"The question of \"what is a word\" is fundamental to text processing. There is no \"right\" answer. That said, tokens have structure.\n",
"- For example, some structure is textual and can be extracted using regular expressions.\n",
" - Some structure is linguistic (e.g., morphological where parts of words have meaning. The text representation may be affected by context)\n",
"\n",
"- Tokenization is a pre-processing step. It requires making many decisions that affect downstream processes.\n"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1161192\n"
]
}
],
"source": [
"# Code\n",
"import nltk\n",
"from nltk.corpus import brown\n",
"#from nltk.text import Text\n",
"\n",
"brown_words = brown.words()\n",
"print(len(brown_words))\n",
" \n",
"# Some things to try...\n",
"\n",
"# How large is the total vocabulary?\n",
"# What is the relative frequency of the word \"the\"?\n",
"# How much of the vocabulary are Hapax Legomena (word that occur only once)?\n",
"# Can you create a graph that shows rank vs frequency?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Word Features\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: http://jalammar.github.io/illustrated-word2vec/\n",
"\n",
"In \"Contextual word representations\" (Noah Smith, 2019) goes further to talk about how we can represent words in a useful way from a computational perspective and to support downstream NLP tasks. Intuitively, we'd like to be able to use surface attributes to relate similar word types, but we'd also relate those that have similar meanings or share other characteristics but are not similar orthographically."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Words Encode Context?\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: http://jalammar.github.io/illustrated-bert/\n",
"\n",
"\"Contextualized word-embeddings can give words different embeddings based on the meaning they carry in the context of the sentence.\" Jay Alammar\n",
"\n",
"Elmo word embeddings look at the entire sentence."
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Inference in NLP\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: [Zellers et al. 2018](https://arxiv.org/abs/1811.10830)\n",
"\n",
"To understand language requires making inferences about what is meant. And, in fact, you do all sorts of inferencing without even realizing it.\n",
"\n",
"For example, in the previous sentence you had to make sense of the meaning of the word \"it\" . If asked, you would probably say \"it\" refers to \"you doing all sorts of inferencing\". Language processing is concerned with more complex tasks around how they combine syntactactically, semantically, and pragmatically. This will matter a great deal for tasks such as question-answering and dialog interaction.\n",
"\n",
"Check out this 10-minute [interview with Yann LeCun on whether neural networks can reason](https://www.youtube.com/watch?v=YAfwNEY826I). In short, he thinks so. There are some outstanding questions in this area. For example, how do you structure and represent knowledge in order to support reasoning? How do you deal with the fact that logic-based reasoning is very discrete (versus continuous) and our reliance on gradience-based learing?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Problems and Challenges\n",
"- Natural Language Understanding\n",
"\t- Includes representation and coding of linguistic and world knowledge\n",
"- Low Resource Languages (data scarcity)\n",
"- Discourse (dialog, multi- and large documents)\n",
"- More datasets!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"See more on problems and challenges at:\n",
"http://ruder.io/4-biggest-open-problems-in-nlp/"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# SOTA\n",
"- https://github.com/sebastianruder/NLP-progress\n",
"- https://paperswithcode.com/area/natural-language-processing"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"A great resource to follow is at https://nlpprogress.com or the GitHub link above.\n",
"Note... there is no state-of-the-art tokenization. Because there is no agreed-upon standard... nor should their be. Decisions about tokenization are pragmatic and driven by your end goals. That said... tokenization matters in your pipeline. If you tokenize one way, and then use a pre-trained model that has made different decisions in tokenization, your performance may suffer. We'll have some examples later in the course around this."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"- [NLTK](https://www.nltk.org) - first few weeks; material from chapters 2-3\n",
"- [Scikit-learn](https://scikit-learn.org/stable/) - text classification\n",
"- [Gensim](https://radimrehurek.com/gensim/index.html)- topic modeling\n",
"- [SpaCy](https://spacy.io) - pipeline, neural models\n",
"- [AllenNLP](https://allennlp.org) - inferencing"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"The most industrial tool on the list for general purpose NLP is SpaCy.\n",
"\n",
"NLTK, StanfordNLP, and AllenNLP are all research grade software and very useful!\n",
"\n",
"https://luckytoilet.wordpress.com/2018/12/29/deep-learning-for-nlp-spacy-vs-pytorch-vs-allennlp/"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# More Course NLP Resources\n",
"\n",
"- [Lecture 1 Supplement](https://anyl580.github.io/syllabus/1-overview.html) and other supplemental material at https://anyl580.github.io"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Next Week\n",
"- Short lecture\n",
"- Tools practicum in class\n",
"- J&M Chapter 2"
]
}
],
"metadata": {
"celltoolbar": "Slideshow",
"jupytext": {
"cell_metadata_filter": "slideshow,-all",
"comment_magics": false,
"notebook_metadata_filter": "-all"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Adding to the complexity of language as a communication system is that it is inherently social. The way we talk depends not only on intent (let alone cooperative intent!) but also who we are talking with, who may be listening, and what we think our interlocutors understand.\n",
"\n",
"Not only does language change - but we use different strategies for communication depending on the social context.\n",
"\n",
"Fundamentally, language understanding is achieved by joint action. People participate in joint activities to achieve goals.\n",
"\n",
"In most joint activities, people pursue multiple goals - public and private goals. Business goal (transaction), procedural goals (doing this quickly and efficiently), interpersonal goals (remaining polite), private agendas.\n",
"\n",
"Joint activities require coordination and we use conventional procedures and language as a part of coordinating actions."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Spoken Language\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"*Humans are inherently wired for conversation -- and conversation is a kind of joint action.*\n",
"- Understanding is incremental\n",
"- We ground understanding\n",
"- We use sequences\n",
"- We signal shifts (e.g., stance, topics)\n",
"Most conversational actions aren't sequential but over-lapping in time. They may not be so discrete but continuous, as well. Timing is important to understanding meaning -- not just the sequence.\n",
"\n",
"Humans are really good at dialogue. The capacity is built into us. This contrasts from the use of formal or written language which must be explicitly learned.\n",
"\n",
"We'll talk about dialog in the last class of this course. If anything, we may predict that 2019 or 2020 will be the \"year of dialog in NLP.\" Dialog is extremely difficult, but there is also great excitement in tackling it using Deep Learning architectures."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Written Language\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image source (screen shot): https://corpling.uis.georgetown.edu/rstweb/info/\n",
"\n",
"In some sense, the structure in written language is more obvious.\n",
"\n",
"The image on the left is an academic paper. The structure is conventionalized and familiar. Easily recognizable are document title, headers, authors. etc. Slightly less obvious sorts of chunking are paragraph sections, sentences, footnotes, and abbreviations. These conventions are learned.\n",
"\n",
"The image on the right is a screenshot of a tool called RSTweb. It is designed for the study of discourse structure. In particular, it was designed for relating structural elements in text used in text generation. But because annotators can related segments of text, it can also support the creation of corpora for the purpose of showing relations between other elements in text such as relating pronouns to person mentions or demonstratives (e.g., this, that) to clauses.\n",
"\n",
"While abstract structural elements such as rhetorical structure - structure created by an author to persuade or inform - has strong links to textual analysis. Discourse structure - structural elements that extend beyond a sentence - remains a significant challenge to NLP. What you will likely notice is that NLP tools do very well at the sentence level and less well with discourse. That said, this is an intense area of research."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Linguistic Abstractions\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"The study of language is a huge field. Language is often the best view into thought and intension - though increasingly we have the need to focus on other signals, such as eye movement or other behavior.\n",
"\n",
"Linguistics is an empirical tradition and is driven by observation. Linguists strive to find patterns in language use, not to explain behavior as a psychologist might, but to better understand how we think and communicate as a species.\n",
"\n",
"Linguistics is such a broad field, that it is broken into multiple categories as shown below.\n",
"\n",
"\n",
"How does computational linguistics differ from NLP? [Jason Eisner gives an excellent answer on Quora](https://www.quora.com/How-is-computational-linguistics-different-from-natural-language-processing). He makes the distinction in terms of research goals. **Computational linguists** strive to answer questions about language and how humans compute it. NLP practitioners are focused on the engineering side of the house - how do we analyze text to answer questions. **Data scientists**, in particular, care about how they can best answer some sort of \"business\" question.\n",
"\n",
"Another way to look at this is, computational linguists are often engaged in pushing the research, while data scientists strive to improve the practice.\n",
"\n",
"If you find this course interesting, you may want to learn more about computational linguistics."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"# Language Processing Examples\n",
"These are just some examples.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Corpus Linguistics\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"A parallel tradition in the study of language has been the study of language *as it exists in the real world.*\n",
"\n",
"In fact, there had been a long tension between those that studied actual \"language use\" and those that introspected on theory.\n",
"\n",
"The screenshot above shows a tool typical for corpus linguistics. In essence, corpus linguists use digitized texts to study language at a relatively fine-grained level by using patterns derived from large amounts of text.\n",
"\n",
"How is corpus linguistics related to NLP?\n",
"\n",
"They overlap heavily. Corpus linguistics embodies statistics and methods that linguists and linguistic practitioners use to study language use, while NLP focuses on engineering tasks using similar statistics and methods.\n",
"\n",
"Typical tools include:\n",
"- Word frequencies\n",
"- Associational measures (collocation analysis - what terms are associated with any particular word?)\n",
"- Concordances (key words and words that occur around them)\n",
"- Word clusters\n",
"\n",
"Research gains in NLP have relied heavily upon the development of structured corpora for training and testing. For example, the Brown Corpus (1967) was a carefully compiled selection of American English texts of about a million words. The American Heritage Dictionary was the first compiled using corpus linguistics - how English is actually used vice how society thinks it should be used (prescriptive use).\n",
"\n",
"Corpora can be intensely resource consuming to produce since often human annotations and judgements are required. For some corpora, theoretical frameworks are needed (e.g., parts-of-speech) and, therefore, annotations require expert intervention.\n",
"\n",
"Corpora are inherently biased. (\"Bias\" means a systematic pattern.) Linguistic data itself contains cultural bias and thus imparts these biases via derived models."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP Tasks\n",
"- **Text Processing tasks**: tokenization, sentence segmentation, stemming/lemmatization, etc.\n",
"- **Sentential level processing**: POS, parsing, Named Entity Recognition, semantic roles, etc.\n",
"- **Discourse processing**: co-reference, relationship extraction, entailment, etc.\n",
"- **Application areas**: MT, sentiment, text classification, Q&A, Dialog, etc."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"NLP tasks are, in effect, categories based on processing challenges. And, to some extent, they line up with different levels of linguistic abstraction. Some tasks involve yet more fine-grained sub-tasks.\n",
"\n",
"The categories provided in this slide are intended only as a rough framework by which you think about NLP tasks. There are many ways to lump and split processing tasks and you will not see a definitive list.\n",
"\n",
"One important development in NLP in the last couple of years is that it is now possible to do multi-task modeling!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Rules\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"While we know that language is a context-sensitive system, many NLP tools were originally developed as context-free, finite state automota. Indeed, rules are still a very powerful tool and you already use them when you creating regular expressions.\n",
"\n",
"Often, if you have little data or time, this is the most productive approach to take."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Statistical \n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Deep Learning\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"We are all learning new schools by adopting deep learning. There is a reduced focus on explicit pipelines, perhaps, but a larger focus on neural network architectures.\n",
"\n",
"Domain expertise is still critical for developing and tuning very good models. The ability to closely examine errors or problems is key - and remains quite challenging."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Why is this science?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"Image credit: https://towardsdatascience.com/is-data-science-really-a-science-9c2249ee2ce4\n",
"\n",
"What is data science without science?\n",
"You could characterize data exploration as a part of data engineering. But data science is not just the extraction of knowledge from data nor data exploration.\n",
"\n",
"So why is “science” in data science so important?\n",
"Much of what you are doing in NLP involves prediction. To produce meaningful results, we use empirical methods to validate the output of algorithms and models, since we can’t always determine validity through direct inspection of every bit of data.\n",
"\n",
"What is empiricism? \n",
"Emperial knowledge is based on evidence from observation and experimentation. This idea contrasts with the idea that knowledge is based on reason (or argument). \n",
"\n",
"Noah Smith notes that hand-crafted knowledge sources are an example of information we might use as a resource. And in fact, theories in linguistic are largely driven by rationalist thinking - though informed by evidence from data. Knowledge from data itself (via text corpora) have come to play a crucial role in the computational analysis of language. Indeed, this empirical manner of thinking drives science and how we as (data) scientists work. \n",
"\n",
"What is the scientific process you will typically follow when you are assessing data that involves inferencing?\n",
"\n",
"- Clearly identify a business question\n",
"- Transform it to a data science question (or set of questions)\n",
"- Create a hypotheses around questions that can be examined statistically (so you must also define the test and assess validity)\n",
"- Design an experiment to test this hypothesis\n",
"- Draw conclusions through experimental results\n",
"\n",
"In all of this, you are not proving the correctness of your hypothesis, but rather creating supportive evidence for your conclusion.\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP in Data Science\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Only a few years ago, NLP required the domain expertise of a computational linguist. This was because either 1) linguists constructed rules using knowledge-based approaches and/or 2) machine learning techniques often required explicit determination of features.\n",
"\n",
"Deep Learning has turned NLP on its head. While neural nets have been around for a long time and also used in NLP, they were neither powerful enough (remember Moore's law?) nor was the sufficient data to drive them.\n",
"\n",
"NLTK was the first package that \"data scientists\" have been able to use to do any sort of NLP. But it was not designed as an industrial tool, rather as a teaching tool. Only recently, have industrial APIs become available and accessible to data scientists.\n",
"\n",
"Another exciting development is that, through efforts such as Jeremy Howard's fast.ai course, deep learning is accessible directly to domain experts who are not expert programmers or statisticians.\n",
"\n",
"These developments are most definitely alarming to computational linguists and also machine learning experts. But at the same time exciting!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# NLP Pipelines\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: https://spacy.io/usage/processing-pipelines\n",
"\n",
"NLP tasks generally require processing in multiple steps. This processing is known as an NLP pipeline. At the very least, there is a step to tokenize text - to process text as a string. In the SpaCy pipeline illustrated, other processing steps take a document and return a document. The order in which you organize NLP steps depends on what you are trying to accomplish and what the models entail as input. For example, if you have a parser that requires part-of-speech tags, then you will need to provide tagged input into the parser.\n",
"\n",
"We're going to go through SpaCy tutorials later in the class and you will be building your own NLP pipelines."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# What is a word?\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Your reading on \"What is a word\" (Grefenstette & Tapanainen, 1994) focuses on the practical challenge of tokenizing text - it raises a basic question about how to break apart text into discrete units *using surface (or orthographic) form.* If this is not so straightforward in English, imagine how challenging it must be with languages that do not use conventions such as whitespace."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"# The Brown Corpus\n",
"The Brown Corpus was an achievement in the late 1960s containing 500 samples of English language text across a broad range of sources and more than 1M words. Kucera and Francis used this corpus as the basis for a computational analysis - and it later became the base for the first dictionary (American Heritage) to use statistical information about word use.\n",
"\n",
"NLTK includes the part-of-speech tagged version of the Brown Corpus which includes about 80 parts of speech. More information on the tag set and basic structure (data description can be found here: http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/index.html)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"\n",
"The question of \"what is a word\" is fundamental to text processing. There is no \"right\" answer. That said, tokens have structure.\n",
"- For example, some structure is textual and can be extracted using regular expressions.\n",
" - Some structure is linguistic (e.g., morphological where parts of words have meaning. The text representation may be affected by context)\n",
"\n",
"- Tokenization is a pre-processing step. It requires making many decisions that affect downstream processes.\n"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1161192\n"
]
}
],
"source": [
"# Code\n",
"import nltk\n",
"from nltk.corpus import brown\n",
"#from nltk.text import Text\n",
"\n",
"brown_words = brown.words()\n",
"print(len(brown_words))\n",
" \n",
"# Some things to try...\n",
"\n",
"# How large is the total vocabulary?\n",
"# What is the relative frequency of the word \"the\"?\n",
"# How much of the vocabulary are Hapax Legomena (word that occur only once)?\n",
"# Can you create a graph that shows rank vs frequency?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Word Features\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: http://jalammar.github.io/illustrated-word2vec/\n",
"\n",
"In \"Contextual word representations\" (Noah Smith, 2019) goes further to talk about how we can represent words in a useful way from a computational perspective and to support downstream NLP tasks. Intuitively, we'd like to be able to use surface attributes to relate similar word types, but we'd also relate those that have similar meanings or share other characteristics but are not similar orthographically."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Words Encode Context?\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: http://jalammar.github.io/illustrated-bert/\n",
"\n",
"\"Contextualized word-embeddings can give words different embeddings based on the meaning they carry in the context of the sentence.\" Jay Alammar\n",
"\n",
"Elmo word embeddings look at the entire sentence."
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Inference in NLP\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"Image credit: [Zellers et al. 2018](https://arxiv.org/abs/1811.10830)\n",
"\n",
"To understand language requires making inferences about what is meant. And, in fact, you do all sorts of inferencing without even realizing it.\n",
"\n",
"For example, in the previous sentence you had to make sense of the meaning of the word \"it\" . If asked, you would probably say \"it\" refers to \"you doing all sorts of inferencing\". Language processing is concerned with more complex tasks around how they combine syntactactically, semantically, and pragmatically. This will matter a great deal for tasks such as question-answering and dialog interaction.\n",
"\n",
"Check out this 10-minute [interview with Yann LeCun on whether neural networks can reason](https://www.youtube.com/watch?v=YAfwNEY826I). In short, he thinks so. There are some outstanding questions in this area. For example, how do you structure and represent knowledge in order to support reasoning? How do you deal with the fact that logic-based reasoning is very discrete (versus continuous) and our reliance on gradience-based learing?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Problems and Challenges\n",
"- Natural Language Understanding\n",
"\t- Includes representation and coding of linguistic and world knowledge\n",
"- Low Resource Languages (data scarcity)\n",
"- Discourse (dialog, multi- and large documents)\n",
"- More datasets!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"See more on problems and challenges at:\n",
"http://ruder.io/4-biggest-open-problems-in-nlp/"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# SOTA\n",
"- https://github.com/sebastianruder/NLP-progress\n",
"- https://paperswithcode.com/area/natural-language-processing"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"A great resource to follow is at https://nlpprogress.com or the GitHub link above.\n",
"Note... there is no state-of-the-art tokenization. Because there is no agreed-upon standard... nor should their be. Decisions about tokenization are pragmatic and driven by your end goals. That said... tokenization matters in your pipeline. If you tokenize one way, and then use a pre-trained model that has made different decisions in tokenization, your performance may suffer. We'll have some examples later in the course around this."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"- [NLTK](https://www.nltk.org) - first few weeks; material from chapters 2-3\n",
"- [Scikit-learn](https://scikit-learn.org/stable/) - text classification\n",
"- [Gensim](https://radimrehurek.com/gensim/index.html)- topic modeling\n",
"- [SpaCy](https://spacy.io) - pipeline, neural models\n",
"- [AllenNLP](https://allennlp.org) - inferencing"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "notes"
}
},
"source": [
"The most industrial tool on the list for general purpose NLP is SpaCy.\n",
"\n",
"NLTK, StanfordNLP, and AllenNLP are all research grade software and very useful!\n",
"\n",
"https://luckytoilet.wordpress.com/2018/12/29/deep-learning-for-nlp-spacy-vs-pytorch-vs-allennlp/"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# More Course NLP Resources\n",
"\n",
"- [Lecture 1 Supplement](https://anyl580.github.io/syllabus/1-overview.html) and other supplemental material at https://anyl580.github.io"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Next Week\n",
"- Short lecture\n",
"- Tools practicum in class\n",
"- J&M Chapter 2"
]
}
],
"metadata": {
"celltoolbar": "Slideshow",
"jupytext": {
"cell_metadata_filter": "slideshow,-all",
"comment_magics": false,
"notebook_metadata_filter": "-all"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}