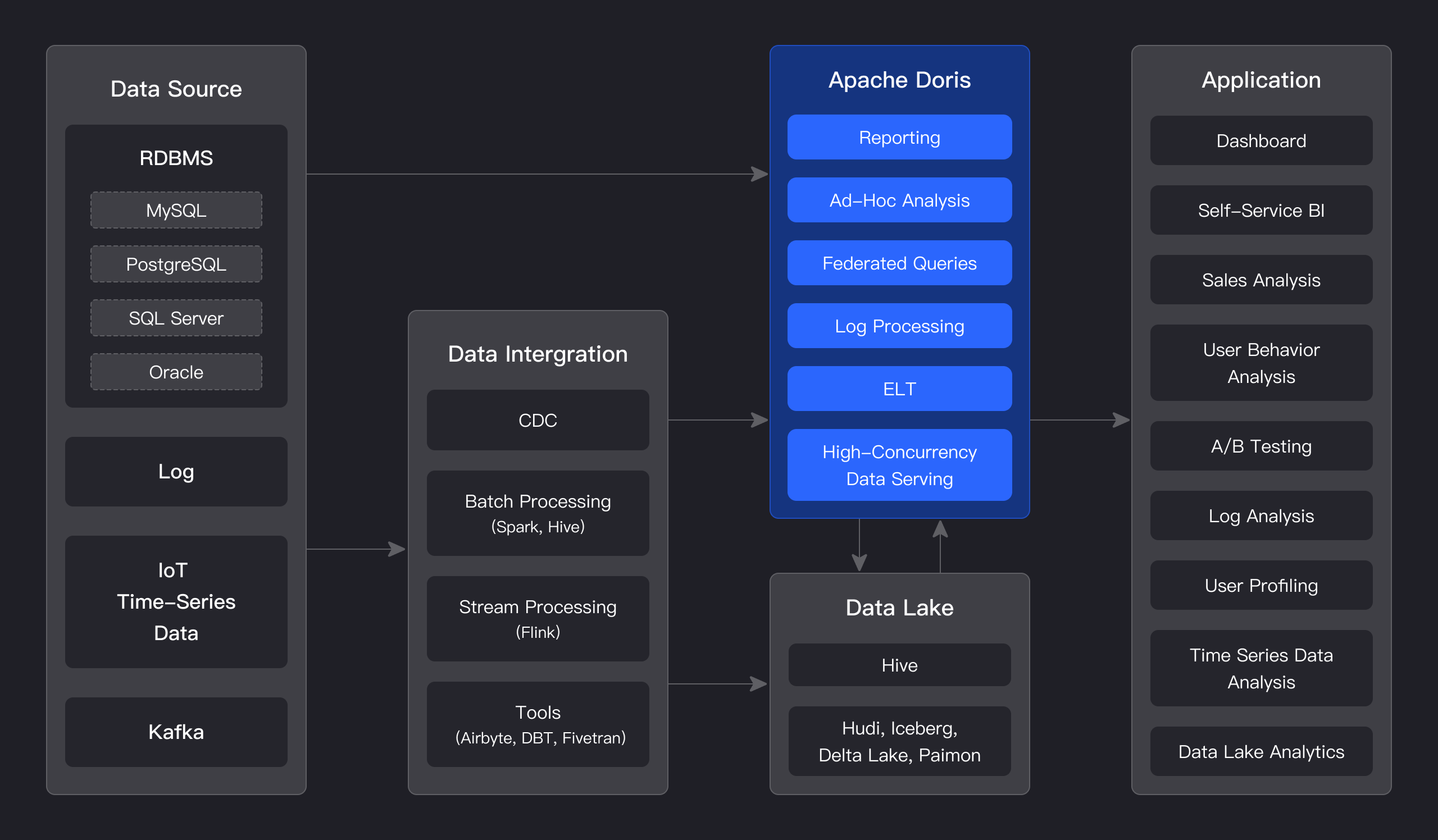
# Apache Doris
[](https://www.apache.org/licenses/LICENSE-2.0.html)
[](https://github.com/apache/doris/releases)
[](https://ossrank.com/p/516)
[](https://github.com/apache/doris/commits/master/)
[](https://doris.apache.org/docs/gettingStarted/what-is-apache-doris)
[](https://doris.apache.org/zh-CN/docs/gettingStarted/what-is-apache-doris)
[![Official Website]()](https://doris.apache.org/)
[![Quick Download]()](https://doris.apache.org/download)