一种用于图数据存储和读取的开源标准数据文件格式。
[](https://github.com/apache/incubator-graphar/actions) [](https://github.com/apache/incubator-graphar/actions) [](https://graphar.apache.org/docs/) [](https://github.com/apache/incubator-graphar/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) [](README.md) ## GraphAr 项目简介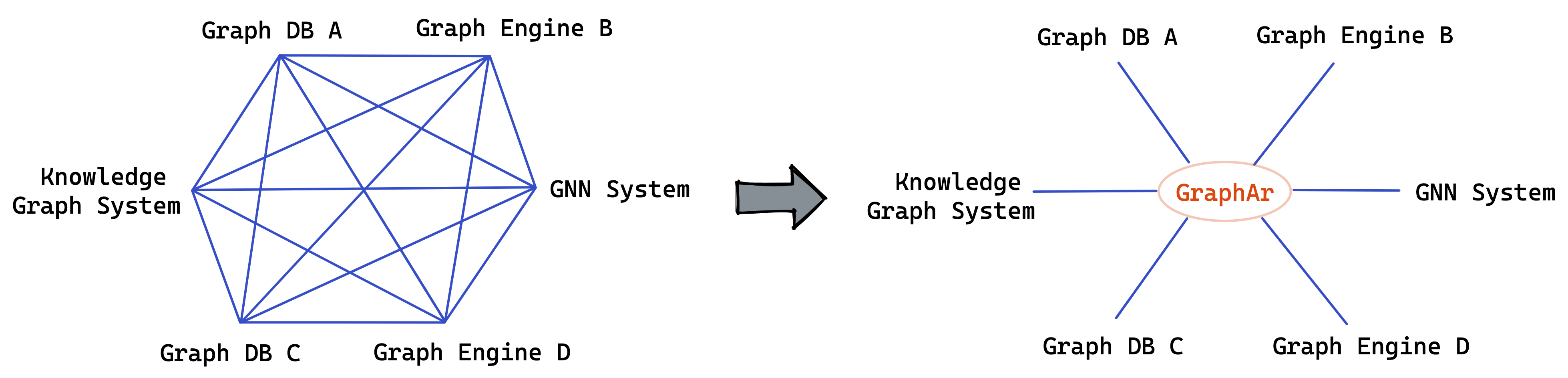 图计算是大数据中的一种常见计算类型,例如社交网络分析、数据挖掘、网络路由和科学计算等。
GraphAr(全称为“Graph Archive”,直译为图的归档)项目旨在使各种应用程序和系统(包括内存和外存中的存储、数据库、图计算系统和交互式图查询框架)能够方便高效地构建和访问图数据。
它可以用于图数据的导入/导出和持久化存储,进行系统间高效的数据交换,从而减轻系统协作时的负担。此外,它还可以直接作为图计算应用的数据源。
为实现这一目标,GraphAr 项目提供了:
- GraphAr 格式:一种标准化的、与系统无关的图数据存储格式;
- 各种语言的开发库:一组各种语言下用于读取、写入和转换 GraphAr 格式数据的开发库;
通过使用 GraphAr 项目,用户可以:
- 使用 GraphAr 格式以系统无关的方式存储和持久化图数据;
- 通过开发库轻松访问和生成 GraphAr 格式的数据;
- 利用 Apache Spark 快速操作和转换 GraphAr 格式的数据
## The GraphAr Format
GraphAr 格式专为属性图而设计。它使用元数据记录图的所有必要信息,并以分区的方式维护实际数据。
属性图由顶点和边组成,每个顶点包含一个唯一标识符,并且包括:
- 描述顶点类型的文本标签;
- 一组属性,每个属性可以用键值对表示。
每条边包含一个唯一标识符,并且包括:
- 出边顶点(边的起点);
- 入边顶点(边的终点);
- 描述两个顶点之间关系的文本标签;
- 一组属性。
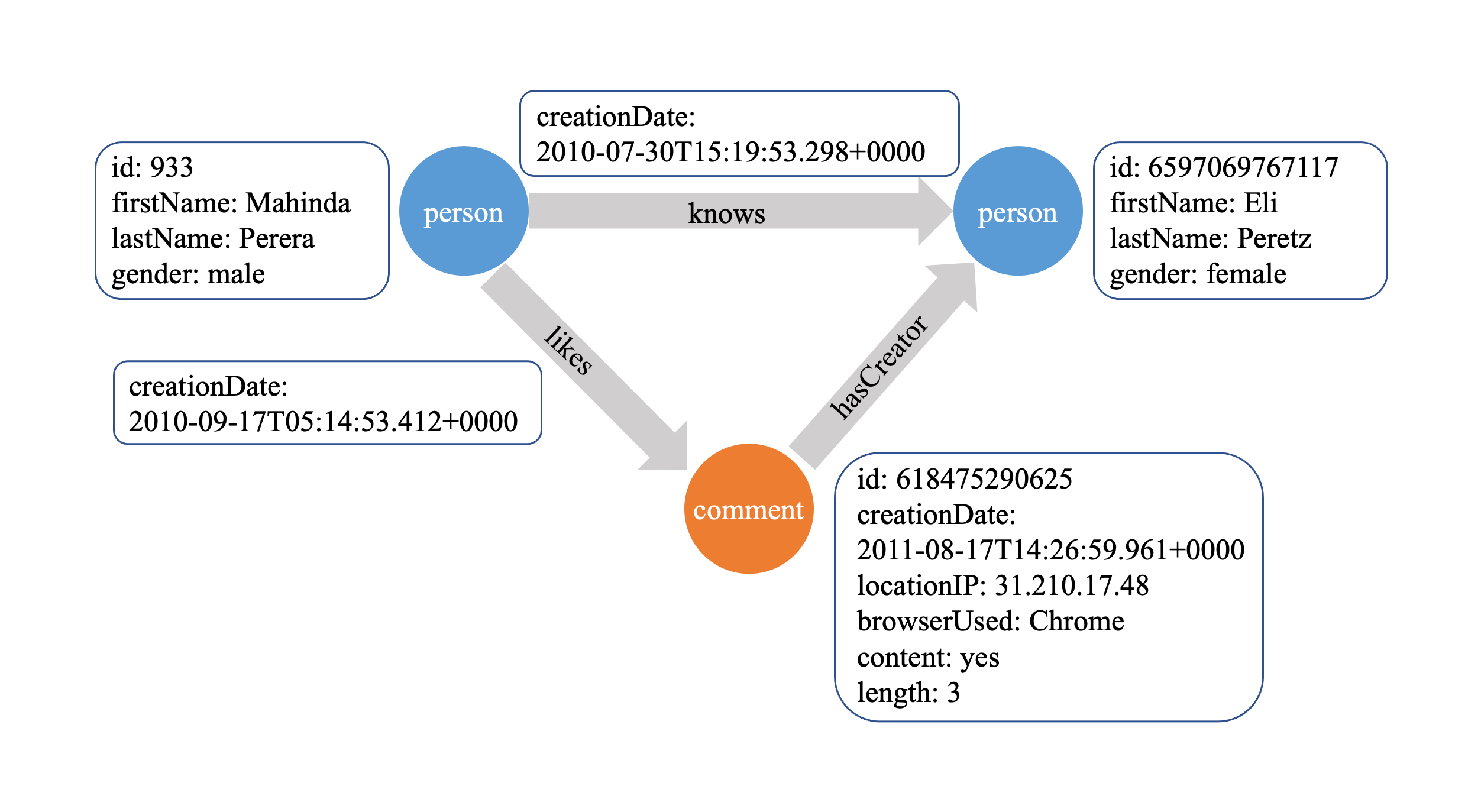
以下是一个属性图的示例,包含两种类型的顶点(“person” 和 “comment”)以及三种类型(“likes”, “knows” 和 “hasCreator”)的边。
图计算是大数据中的一种常见计算类型,例如社交网络分析、数据挖掘、网络路由和科学计算等。
GraphAr(全称为“Graph Archive”,直译为图的归档)项目旨在使各种应用程序和系统(包括内存和外存中的存储、数据库、图计算系统和交互式图查询框架)能够方便高效地构建和访问图数据。
它可以用于图数据的导入/导出和持久化存储,进行系统间高效的数据交换,从而减轻系统协作时的负担。此外,它还可以直接作为图计算应用的数据源。
为实现这一目标,GraphAr 项目提供了:
- GraphAr 格式:一种标准化的、与系统无关的图数据存储格式;
- 各种语言的开发库:一组各种语言下用于读取、写入和转换 GraphAr 格式数据的开发库;
通过使用 GraphAr 项目,用户可以:
- 使用 GraphAr 格式以系统无关的方式存储和持久化图数据;
- 通过开发库轻松访问和生成 GraphAr 格式的数据;
- 利用 Apache Spark 快速操作和转换 GraphAr 格式的数据
## The GraphAr Format
GraphAr 格式专为属性图而设计。它使用元数据记录图的所有必要信息,并以分区的方式维护实际数据。
属性图由顶点和边组成,每个顶点包含一个唯一标识符,并且包括:
- 描述顶点类型的文本标签;
- 一组属性,每个属性可以用键值对表示。
每条边包含一个唯一标识符,并且包括:
- 出边顶点(边的起点);
- 入边顶点(边的终点);
- 描述两个顶点之间关系的文本标签;
- 一组属性。
以下是一个属性图的示例,包含两种类型的顶点(“person” 和 “comment”)以及三种类型(“likes”, “knows” 和 “hasCreator”)的边。
 ### GraphAr 的顶点
#### 顶点的逻辑表
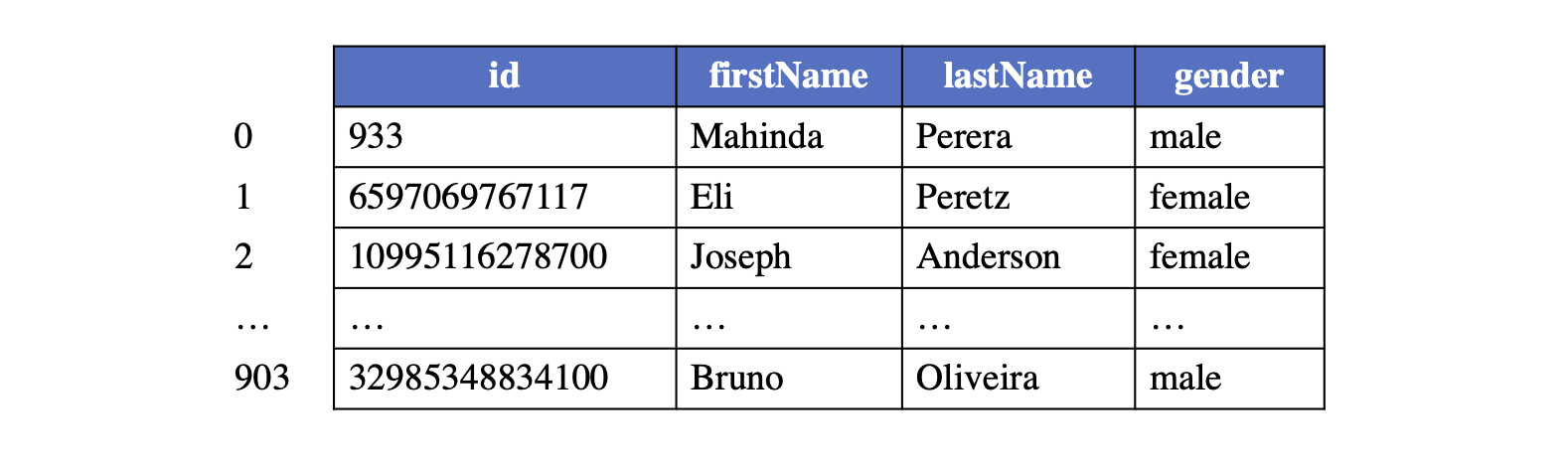
每种类型的顶点(即具有相同标签的顶点)构成一个逻辑顶点表,每个顶点在此类型内被分配一个全局索引(称为内部顶点 ID),从 0 开始,对应于逻辑顶点表中顶点的行号。下图中提供了标签为 “person” 的顶点逻辑表的示例布局供参考。
通过内部顶点 ID 和顶点标签,可以唯一标识一个顶点,并且可以从该表中访问其相应的属性。内部顶点 ID 还用于在维护图的拓扑结构时标识边的起始顶点和终止顶点。
### GraphAr 的顶点
#### 顶点的逻辑表
每种类型的顶点(即具有相同标签的顶点)构成一个逻辑顶点表,每个顶点在此类型内被分配一个全局索引(称为内部顶点 ID),从 0 开始,对应于逻辑顶点表中顶点的行号。下图中提供了标签为 “person” 的顶点逻辑表的示例布局供参考。
通过内部顶点 ID 和顶点标签,可以唯一标识一个顶点,并且可以从该表中访问其相应的属性。内部顶点 ID 还用于在维护图的拓扑结构时标识边的起始顶点和终止顶点。
 #### 顶点的物理表
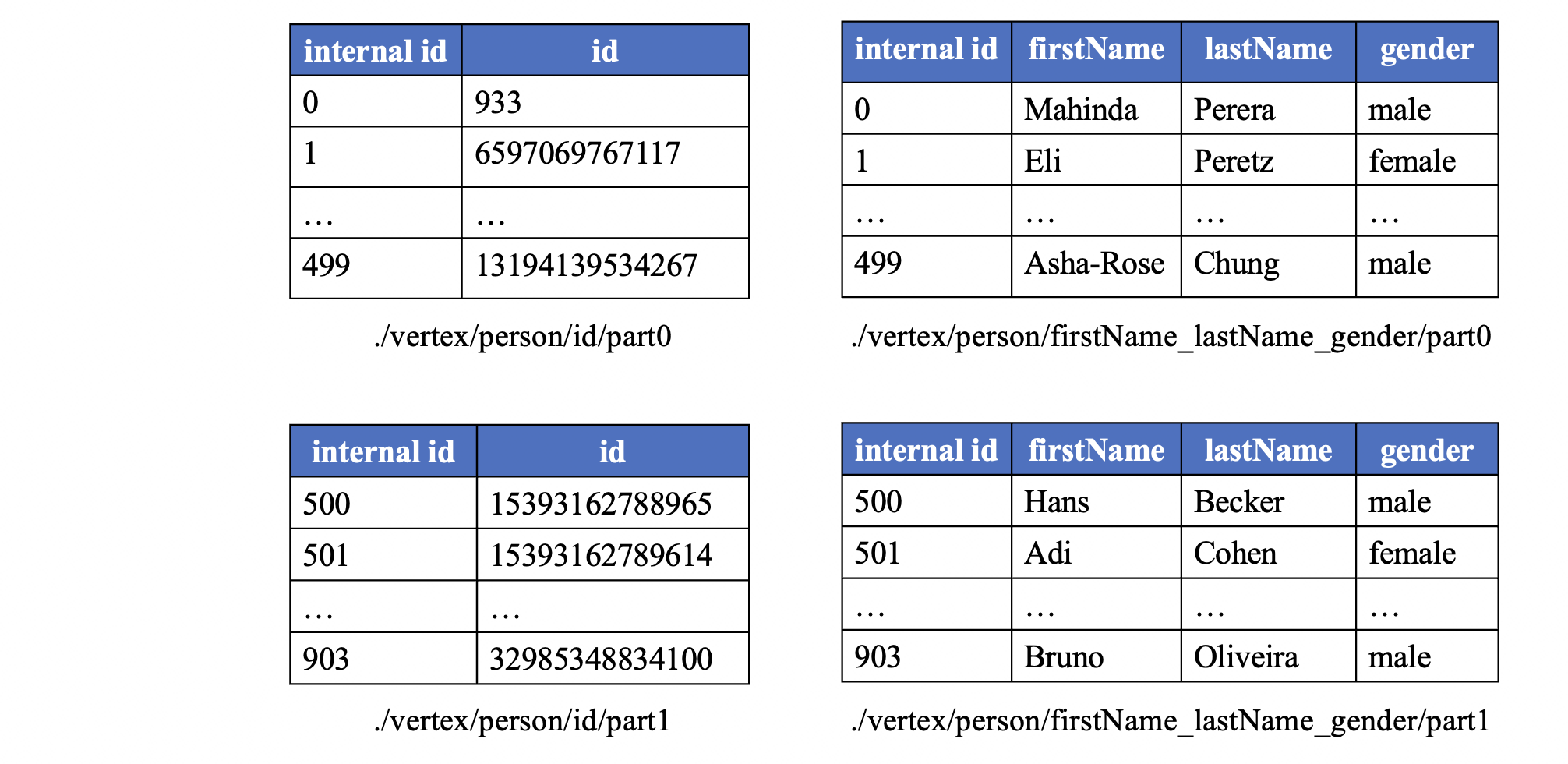
为了提高读写效率,逻辑顶点表将被分割成多个连续的顶点块。为了保持随机访问的能力,相同标签的顶点块大小是固定的。为了支持访问所需属性而无需从文件中读取所有属性,并且能够在不修改现有文件的情况下为顶点添加属性,逻辑表的列将被分为多个列组。
以 person 顶点表为例,如果块大小设置为 500,那么逻辑表将被分成每个 500 行的子逻辑表,最后一个子逻辑表可能少于 500 行。用于维护属性的列也将被分成不同的组(例如,在我们的示例中为 2 个组)。因此,总共创建了 4 个物理顶点表来存储该示例逻辑表,如下图所示。
#### 顶点的物理表
为了提高读写效率,逻辑顶点表将被分割成多个连续的顶点块。为了保持随机访问的能力,相同标签的顶点块大小是固定的。为了支持访问所需属性而无需从文件中读取所有属性,并且能够在不修改现有文件的情况下为顶点添加属性,逻辑表的列将被分为多个列组。
以 person 顶点表为例,如果块大小设置为 500,那么逻辑表将被分成每个 500 行的子逻辑表,最后一个子逻辑表可能少于 500 行。用于维护属性的列也将被分成不同的组(例如,在我们的示例中为 2 个组)。因此,总共创建了 4 个物理顶点表来存储该示例逻辑表,如下图所示。
 > [!NOTE]
> 为了有效利用诸如 Parquet 之类 payload 文件格式的过滤下推功能,内部顶点 ID 作为一列存储在 payload 文件中。由于内部顶点 ID 是连续的,payload 文件格式可以对内部顶点 ID 列使用增量编码,这不会给存储带来太多的开销。
### GraphAr 的边
#### 边的逻辑表
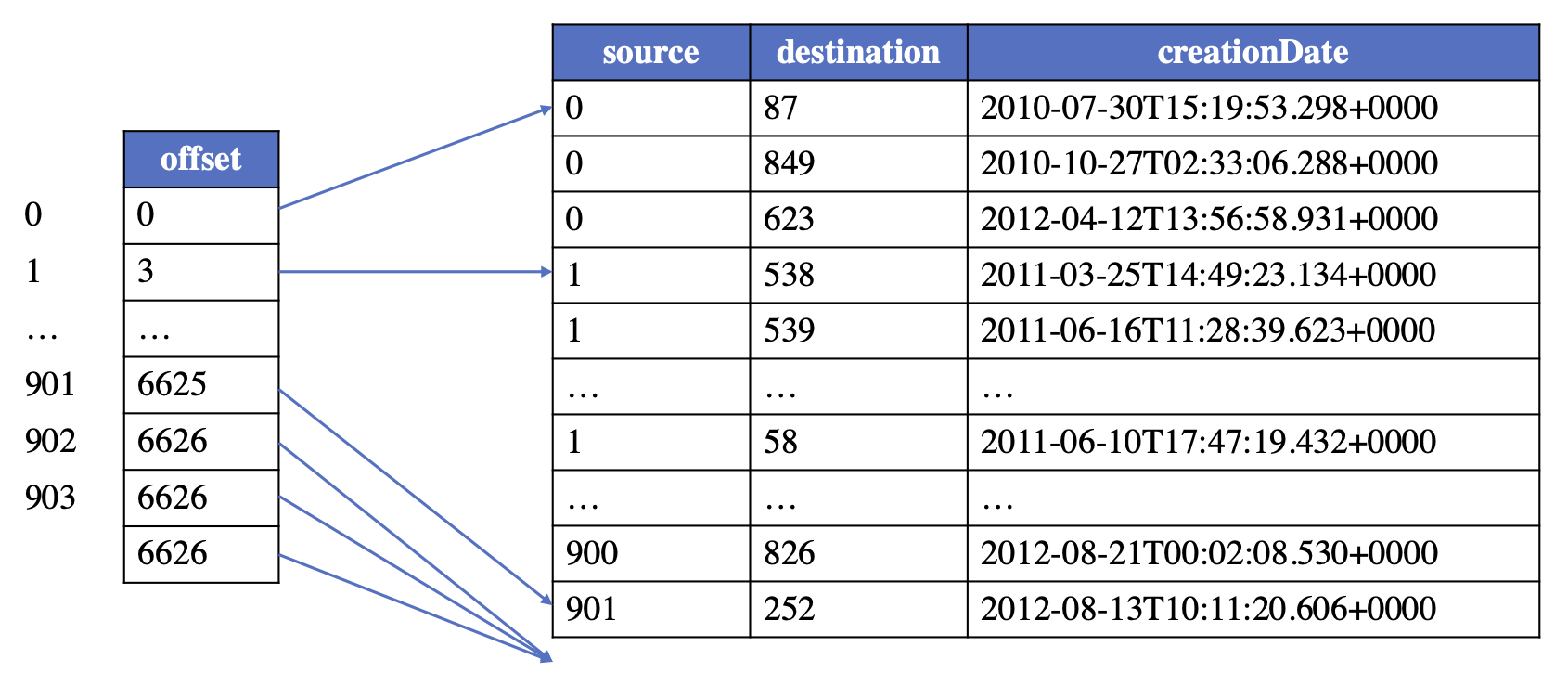
为了维护一种类型的边(具有相同的源标签、边标签和目标标签),会建立一个逻辑边表。为了支持从图存储文件中快速创建图,逻辑边表可以以类似于 [CSR/CSC](https://en.wikipedia.org/wiki/Sparse_matrix) 的方式维护拓扑信息,即边按照源或目标的内部顶点 ID 排序。通过这种方式,需要一个偏移表来存储每个顶点的边的起始偏移量,并且具有相同源/目标的边将连续存储在逻辑表中。
以 person knows person 边的逻辑表为例,逻辑边表看起来如下所示:
> [!NOTE]
> 为了有效利用诸如 Parquet 之类 payload 文件格式的过滤下推功能,内部顶点 ID 作为一列存储在 payload 文件中。由于内部顶点 ID 是连续的,payload 文件格式可以对内部顶点 ID 列使用增量编码,这不会给存储带来太多的开销。
### GraphAr 的边
#### 边的逻辑表
为了维护一种类型的边(具有相同的源标签、边标签和目标标签),会建立一个逻辑边表。为了支持从图存储文件中快速创建图,逻辑边表可以以类似于 [CSR/CSC](https://en.wikipedia.org/wiki/Sparse_matrix) 的方式维护拓扑信息,即边按照源或目标的内部顶点 ID 排序。通过这种方式,需要一个偏移表来存储每个顶点的边的起始偏移量,并且具有相同源/目标的边将连续存储在逻辑表中。
以 person knows person 边的逻辑表为例,逻辑边表看起来如下所示:
 #### 边的物理表
与顶点表相同,逻辑边表也被分割为一些子逻辑表,每个子逻辑表包含源(或目标)顶点在相同顶点块中的边。根据分区策略和边的顺序,边可以按照以下四种类型之一存储在 GraphAr 中:
- **ordered_by_source**:逻辑表中的所有边按照源的内部顶点 ID 排序,并进一步按源顶点 ID 进行分区,这可以看作是 CSR 格式。
- **ordered_by_dest**:逻辑表中的所有边按照目标的内部顶点 ID 排序,并进一步按目标顶点 ID 进行分区,这可以看作是 CSC 格式。
- **unordered_by_source**:使用源顶点的内部 ID 作为分区键,将边分割成不同的子逻辑表,并且每个子逻辑表中的边是无序的,这可以看作是 COO 格式。
- **unordered_by_dest**:使用目标顶点的内部 ID 作为分区键,将边分割成不同的子逻辑表,并且每个子逻辑表中的边是无序的,这也可以看作是 COO 格式。
之后,一个子逻辑表会进一步被划分为具有预定义固定行数的边块(称为边块大小)。最终,一个边块会按照以下方式分离为物理表:
- 一个 `adjList` 表(仅包含两列:源和目标的内部顶点 ID)。
- 0 个或多个边属性表,每个表包含一组属性。
此外,对于 **ordered_by_source** 或 **ordered_by_dest** 类型的边,还会有一个偏移表。偏移表用于记录每个顶点的边的起始点。偏移表的分区应与相应的顶点表的分区保持一致。每个偏移块的第一行总是 0,表示对应子逻辑边表的起始点。
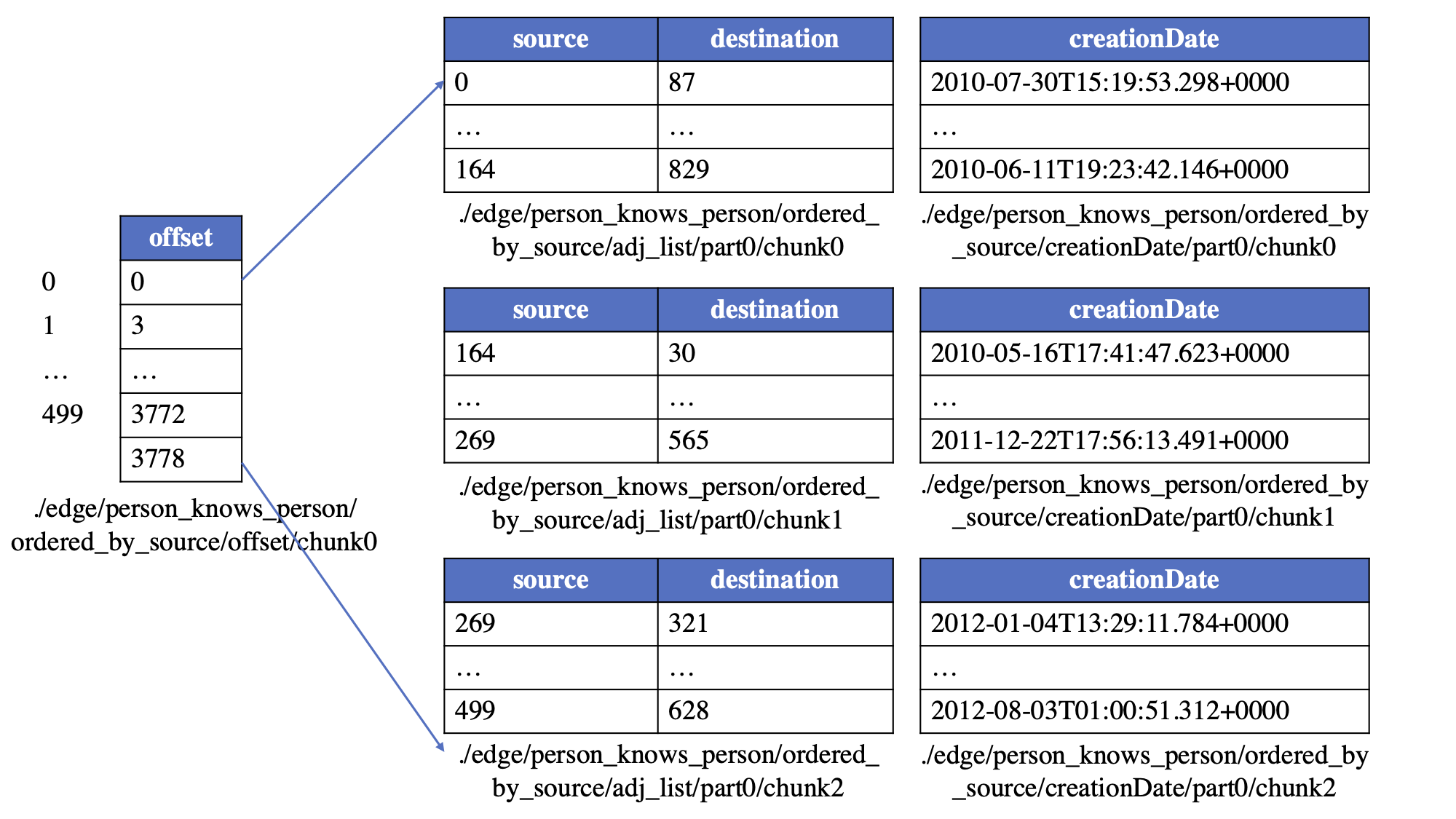
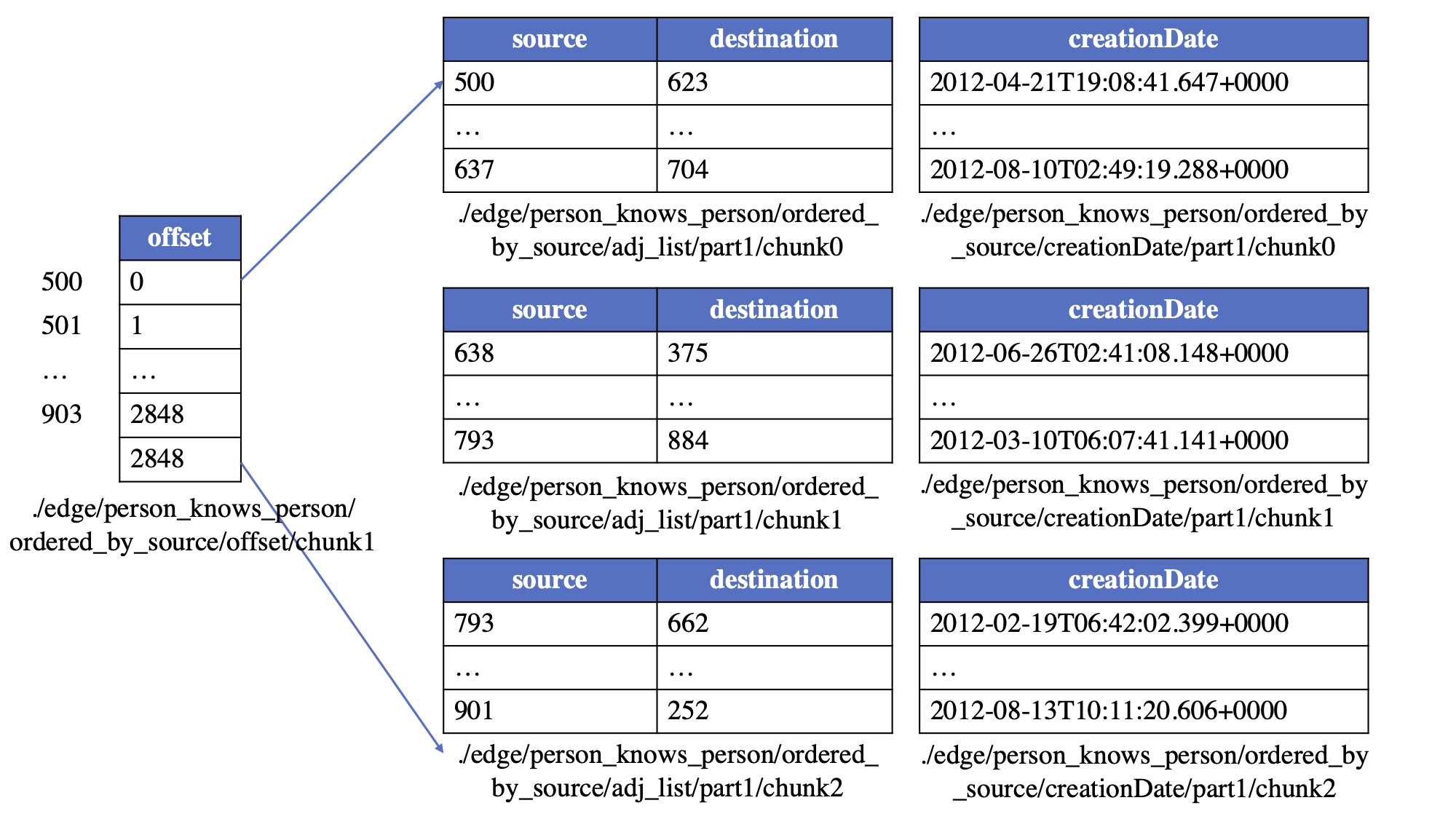
以 `person--knows->person` 边为例来说明。假设顶点块大小设置为 500,边块大小为 1024,并且边是 **ordered_by_source** 类型的,那么这些边可以存储在以下物理表中:
#### 边的物理表
与顶点表相同,逻辑边表也被分割为一些子逻辑表,每个子逻辑表包含源(或目标)顶点在相同顶点块中的边。根据分区策略和边的顺序,边可以按照以下四种类型之一存储在 GraphAr 中:
- **ordered_by_source**:逻辑表中的所有边按照源的内部顶点 ID 排序,并进一步按源顶点 ID 进行分区,这可以看作是 CSR 格式。
- **ordered_by_dest**:逻辑表中的所有边按照目标的内部顶点 ID 排序,并进一步按目标顶点 ID 进行分区,这可以看作是 CSC 格式。
- **unordered_by_source**:使用源顶点的内部 ID 作为分区键,将边分割成不同的子逻辑表,并且每个子逻辑表中的边是无序的,这可以看作是 COO 格式。
- **unordered_by_dest**:使用目标顶点的内部 ID 作为分区键,将边分割成不同的子逻辑表,并且每个子逻辑表中的边是无序的,这也可以看作是 COO 格式。
之后,一个子逻辑表会进一步被划分为具有预定义固定行数的边块(称为边块大小)。最终,一个边块会按照以下方式分离为物理表:
- 一个 `adjList` 表(仅包含两列:源和目标的内部顶点 ID)。
- 0 个或多个边属性表,每个表包含一组属性。
此外,对于 **ordered_by_source** 或 **ordered_by_dest** 类型的边,还会有一个偏移表。偏移表用于记录每个顶点的边的起始点。偏移表的分区应与相应的顶点表的分区保持一致。每个偏移块的第一行总是 0,表示对应子逻辑边表的起始点。
以 `person--knows->person` 边为例来说明。假设顶点块大小设置为 500,边块大小为 1024,并且边是 **ordered_by_source** 类型的,那么这些边可以存储在以下物理表中:
 ## 基准测试(Benchmark)
我们的实验在阿里云 r6.6xlarge 实例上进行,该实例配备了 24 核 Intel(R) Xeon(R) Platinum 8269CY CPU(主频 2.50GHz)、192GB 内存,运行 64 位 Ubuntu 20.04 LTS 系统。数据存储在一块容量为 200GB 的 PL0 ESSD 上,最大 I/O 吞吐量为 180MB/s。我们在其他平台和类 S3 存储上的附加测试也得到了相似的结果。
### 数据集
我们使用了来自 [Graph500](https://graph500.org/) 和 [LDBC](https://doi.org/10.1145/2723372.2742786) 的大规模图数据集,包含数亿个顶点。其他实验中涉及的数据集可在论文 [GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes](https://arxiv.org/abs/2312.09577) 中查阅。
## 基准测试(Benchmark)
我们的实验在阿里云 r6.6xlarge 实例上进行,该实例配备了 24 核 Intel(R) Xeon(R) Platinum 8269CY CPU(主频 2.50GHz)、192GB 内存,运行 64 位 Ubuntu 20.04 LTS 系统。数据存储在一块容量为 200GB 的 PL0 ESSD 上,最大 I/O 吞吐量为 180MB/s。我们在其他平台和类 S3 存储上的附加测试也得到了相似的结果。
### 数据集
我们使用了来自 [Graph500](https://graph500.org/) 和 [LDBC](https://doi.org/10.1145/2723372.2742786) 的大规模图数据集,包含数亿个顶点。其他实验中涉及的数据集可在论文 [GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes](https://arxiv.org/abs/2312.09577) 中查阅。
| Abbr. | Graph | |V| | |E| |
|---|---|---|---|
| G8 | Graph500-28 | 268M | 4.29B |
| G9 | Graph500-29 | 537M | 8.59B |
| SF30 | SNB Interactive SF-30 | 99.4M | 655M |
| SF100 | SNB Interactive SF-100 | 318M | 2.15B |
| SF300 | SNB Interactive SF-300 | 908M | 6.29B |
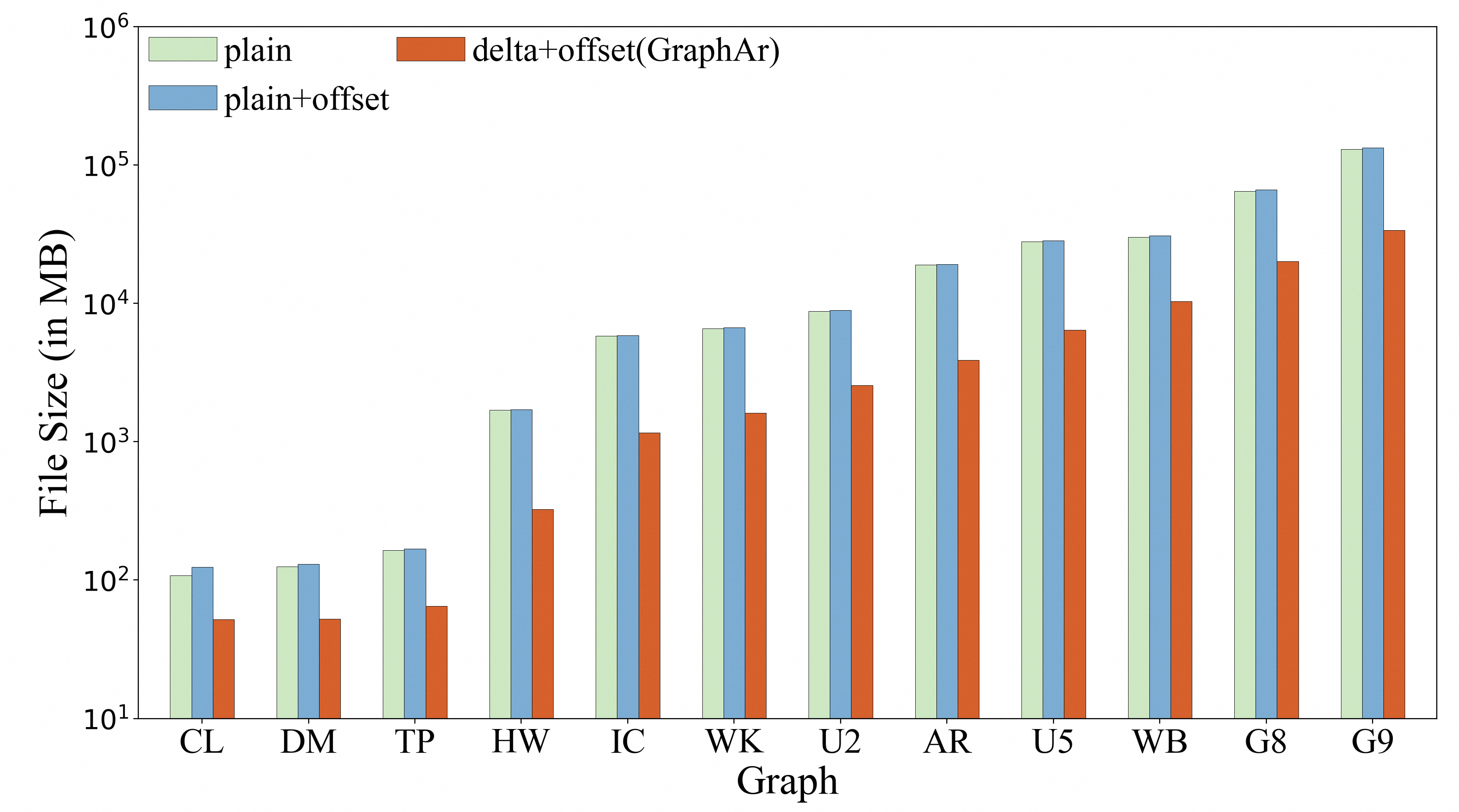 我们对比了两种基线方法:
1. **“plain”**:对源节点和目标节点列使用普通编码;
2. **“plain + offset”**:在 “plain” 方法基础上,对边排序并添加偏移列以标记每个顶点起始边的位置。
结果表明,GraphAr 在存储方面具有显著优势:平均仅需 “plain + offset” 所需存储空间的 **27.3%**,这主要得益于 delta 编码的应用。
### I/O 速度
我们对比了两种基线方法:
1. **“plain”**:对源节点和目标节点列使用普通编码;
2. **“plain + offset”**:在 “plain” 方法基础上,对边排序并添加偏移列以标记每个顶点起始边的位置。
结果表明,GraphAr 在存储方面具有显著优势:平均仅需 “plain + offset” 所需存储空间的 **27.3%**,这主要得益于 delta 编码的应用。
### I/O 速度
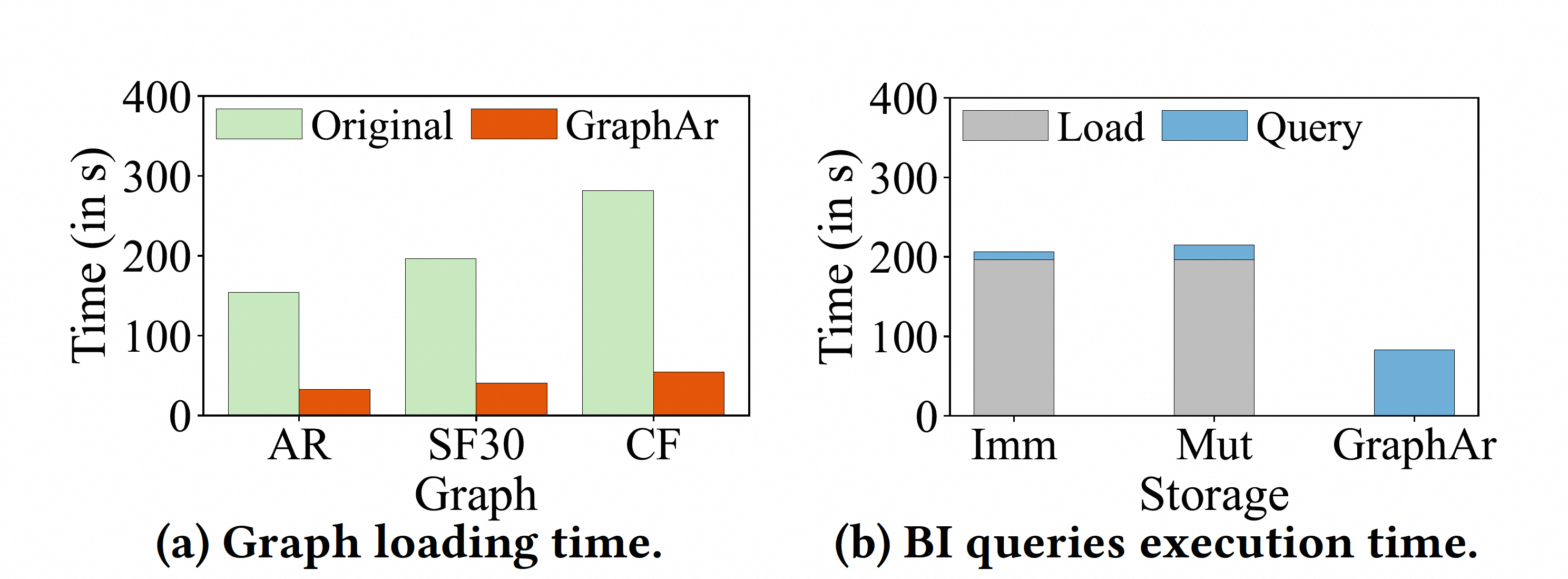 图 (a) 显示 GraphAr 明显优于基线方法(CSV),平均性能提升达 **4.9 倍**。图 (b) 中,“Imm”(不可变)和 “Mut”(可变)是 GraphScope 的本地内存存储形式。尽管 GraphAr 的查询时间略高于内存存储方式,这是由于固有的 I/O 开销所致,但它仍显著优于先加载再执行查询的方式,在两个变体下分别提升了 **2.4 倍** 和 **2.5 倍**。这表明 GraphAr 是处理低频查询的有效选择。
### 标签过滤(Label Filtering)
图 (a) 显示 GraphAr 明显优于基线方法(CSV),平均性能提升达 **4.9 倍**。图 (b) 中,“Imm”(不可变)和 “Mut”(可变)是 GraphScope 的本地内存存储形式。尽管 GraphAr 的查询时间略高于内存存储方式,这是由于固有的 I/O 开销所致,但它仍显著优于先加载再执行查询的方式,在两个变体下分别提升了 **2.4 倍** 和 **2.5 倍**。这表明 GraphAr 是处理低频查询的有效选择。
### 标签过滤(Label Filtering)
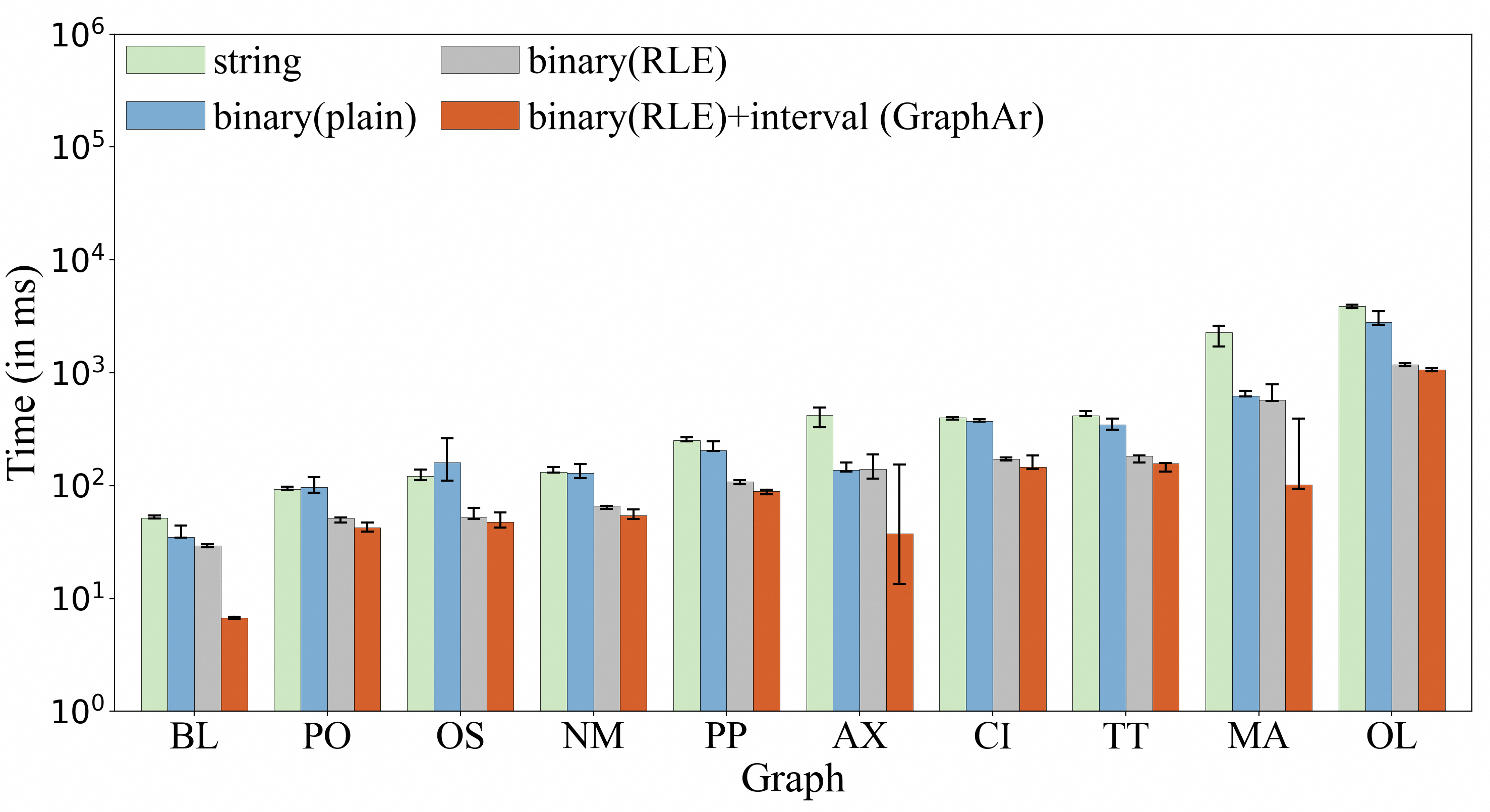 **简单条件下的标签过滤性能**
对于每个图,我们分别将每个标签作为目标标签进行过滤实验。GraphAr 持续优于所有基线方法。平均来看,相比 “string” 方法,性能提升了 **14.8 倍**;相比 “binary (plain)” 方法,性能提升了 **8.9 倍**;相比 “binary (RLE)” 方法,性能提升了 **7.4 倍**。
**简单条件下的标签过滤性能**
对于每个图,我们分别将每个标签作为目标标签进行过滤实验。GraphAr 持续优于所有基线方法。平均来看,相比 “string” 方法,性能提升了 **14.8 倍**;相比 “binary (plain)” 方法,性能提升了 **8.9 倍**;相比 “binary (RLE)” 方法,性能提升了 **7.4 倍**。
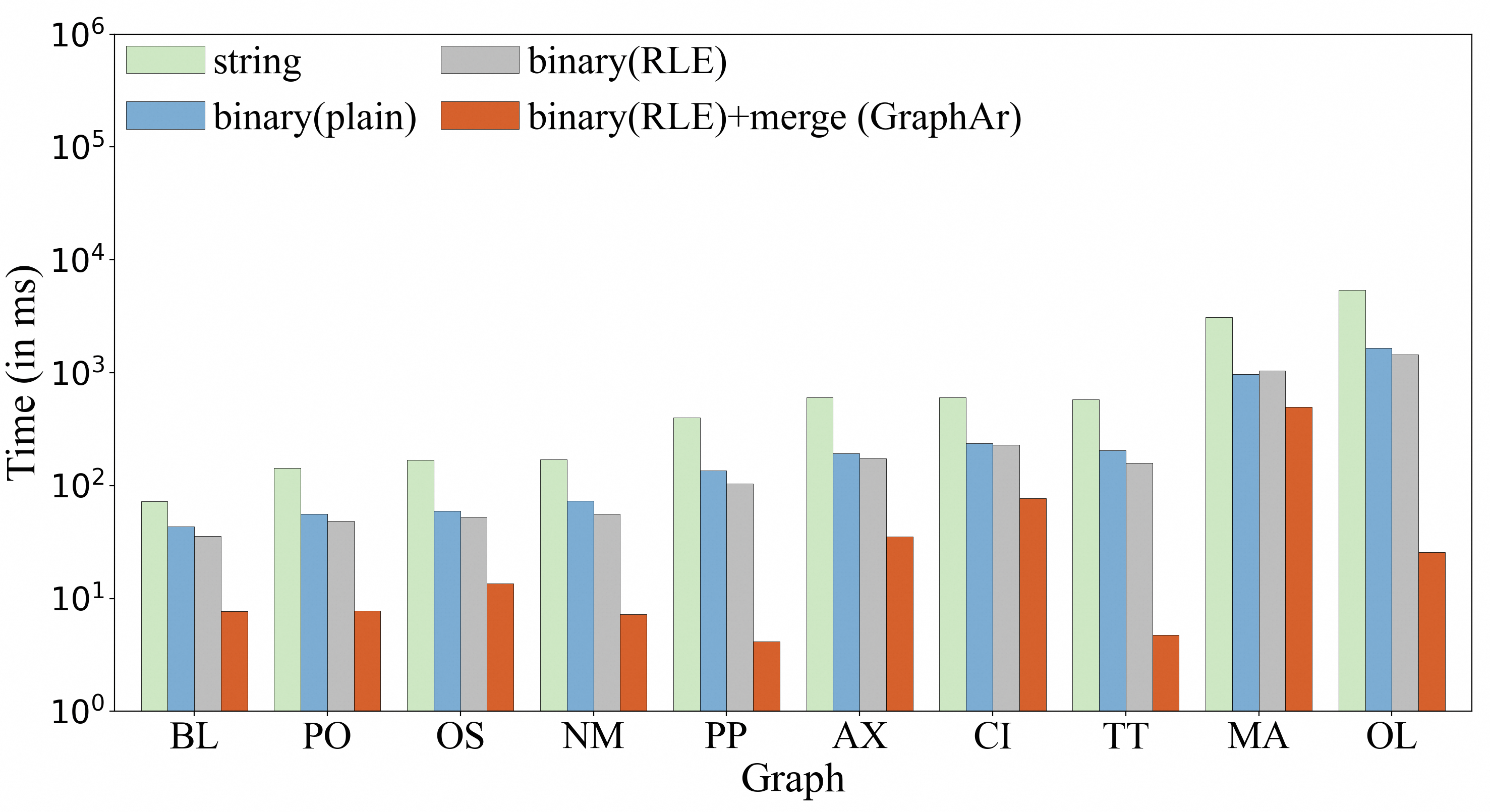 **复杂条件下的标签过滤性能**
在每个图中,我们通过 AND 或 OR 组合两个标签作为过滤条件。“基于合并解码”的方法表现最佳,其中 “binary (RLE) + merge” 相比 “binary (RLE)” 方法最高提升了 **60.5 倍**。
## 开发库
GraphAr 提供了一组用于读取、写入和转换文件的库。目前,以下库已经可用,并计划扩展对其他编程语言的支持。
### C++ 库
有关 C++ 库构建的详细信息,请参阅 [GraphAr C++库](./cpp)。
### Spark(Scala)库
有关 Scala 与 Spark 库的详细信息,请参阅 [GraphAr Spark库](./maven-projects/spark)。
### Java (FFI) 库
> [!WARNING]
> Java (FFI) 库已不再更新,最后版本依赖于 C++ 库 v0.12.0。
GraphAr Java 库是通过绑定到 C++ 库(当前版本为v0.12.0)创建的,使用 [Alibaba-FastFFI](https://github.com/alibaba/fastFFI) 进行实现。有关 Java 库构建的详细信息,请参阅 [GraphAr Java库](./maven-projects/java)。
### Java 库
> [!NOTE]
> Java 库正在开发中.
java 库将由纯java开发,他将会包括下面的模块:
- **[Java-Info](./maven-projects/info)**:负责从yaml文件中解析Graphinfo(schema)
- **Java-io-XXX**:负责从不同存储格式读取图形数据(待实现)
- **Java-Api-XXX**:为图形操作提供高级API(待实现)
### Python(PySpark)库
> [!NOTE]
> Python 与 PySpark 库正在开发中。
PySpark 库是作为 GraphAr Spark 库的绑定进行开发的。有关 PySpark 库的详细信息,请参阅 [GraphAr PySpark库](./pyspark)。
## 参与本项目
- 请参阅 [贡献指南](https://github.com/apache/incubator-graphar/blob/main/CONTRIBUTING.md)。
- 提交 [Github Issue](https://github.com/apache/incubator-graphar/issues) 以报告错误或提出功能请求。
- 在 [开发者邮件列表](mailto:dev@graphar.apache.org)上讨论([订阅](mailto:dev-subscribe@graphar.apache.org?subject=(send%20this%20email%20to%20subscribe)) / [取消订阅](mailto:dev-unsubscribe@graphar.apache.org?subject=(send%20this%20email%20to%20unsubscribe)) / [归档](https://lists.apache.org/list.html?dev@graphar.apache.org))。
- 在 [GitHub Discussion](https://github.com/apache/graphar/discussions/new?category=q-a) 中提出问题。
## 开源协议
**GraphAr** 遵循 [Apache License 2.0](https://github.com/apache/incubator-graphar/blob/main/LICENSE) 开源协议分发。同时请注意,某些依赖的第三方库可能采用了与 GraphAr 不同的开源许可协议。
## 论文
- Xue Li, Weibin Zeng, Zhibin Wang, Diwen Zhu, Jingbo Xu, Wenyuan Yu, Jingren Zhou. GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes. PVLDB, 18(3): 530 - 543, 2024.
```bibtex
@article{li2024graphar,
author = {Xue Li and Weibin Zeng and Zhibin Wang and Diwen Zhu and Jingbo Xu and Wenyuan Yu and Jingren Zhou},
title = {GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes},
journal = {Proceedings of the VLDB Endowment},
year = {2024},
volume = {18},
number = {3},
pages = {530--543},
publisher = {VLDB Endowment},
}
```
论文的源代码、数据和其他相关文档已在[Research 分支](https://github.com/apache/incubator-graphar/tree/research)中提供。
**复杂条件下的标签过滤性能**
在每个图中,我们通过 AND 或 OR 组合两个标签作为过滤条件。“基于合并解码”的方法表现最佳,其中 “binary (RLE) + merge” 相比 “binary (RLE)” 方法最高提升了 **60.5 倍**。
## 开发库
GraphAr 提供了一组用于读取、写入和转换文件的库。目前,以下库已经可用,并计划扩展对其他编程语言的支持。
### C++ 库
有关 C++ 库构建的详细信息,请参阅 [GraphAr C++库](./cpp)。
### Spark(Scala)库
有关 Scala 与 Spark 库的详细信息,请参阅 [GraphAr Spark库](./maven-projects/spark)。
### Java (FFI) 库
> [!WARNING]
> Java (FFI) 库已不再更新,最后版本依赖于 C++ 库 v0.12.0。
GraphAr Java 库是通过绑定到 C++ 库(当前版本为v0.12.0)创建的,使用 [Alibaba-FastFFI](https://github.com/alibaba/fastFFI) 进行实现。有关 Java 库构建的详细信息,请参阅 [GraphAr Java库](./maven-projects/java)。
### Java 库
> [!NOTE]
> Java 库正在开发中.
java 库将由纯java开发,他将会包括下面的模块:
- **[Java-Info](./maven-projects/info)**:负责从yaml文件中解析Graphinfo(schema)
- **Java-io-XXX**:负责从不同存储格式读取图形数据(待实现)
- **Java-Api-XXX**:为图形操作提供高级API(待实现)
### Python(PySpark)库
> [!NOTE]
> Python 与 PySpark 库正在开发中。
PySpark 库是作为 GraphAr Spark 库的绑定进行开发的。有关 PySpark 库的详细信息,请参阅 [GraphAr PySpark库](./pyspark)。
## 参与本项目
- 请参阅 [贡献指南](https://github.com/apache/incubator-graphar/blob/main/CONTRIBUTING.md)。
- 提交 [Github Issue](https://github.com/apache/incubator-graphar/issues) 以报告错误或提出功能请求。
- 在 [开发者邮件列表](mailto:dev@graphar.apache.org)上讨论([订阅](mailto:dev-subscribe@graphar.apache.org?subject=(send%20this%20email%20to%20subscribe)) / [取消订阅](mailto:dev-unsubscribe@graphar.apache.org?subject=(send%20this%20email%20to%20unsubscribe)) / [归档](https://lists.apache.org/list.html?dev@graphar.apache.org))。
- 在 [GitHub Discussion](https://github.com/apache/graphar/discussions/new?category=q-a) 中提出问题。
## 开源协议
**GraphAr** 遵循 [Apache License 2.0](https://github.com/apache/incubator-graphar/blob/main/LICENSE) 开源协议分发。同时请注意,某些依赖的第三方库可能采用了与 GraphAr 不同的开源许可协议。
## 论文
- Xue Li, Weibin Zeng, Zhibin Wang, Diwen Zhu, Jingbo Xu, Wenyuan Yu, Jingren Zhou. GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes. PVLDB, 18(3): 530 - 543, 2024.
```bibtex
@article{li2024graphar,
author = {Xue Li and Weibin Zeng and Zhibin Wang and Diwen Zhu and Jingbo Xu and Wenyuan Yu and Jingren Zhou},
title = {GraphAr: An Efficient Storage Scheme for Graph Data in Data Lakes},
journal = {Proceedings of the VLDB Endowment},
year = {2024},
volume = {18},
number = {3},
pages = {530--543},
publisher = {VLDB Endowment},
}
```
论文的源代码、数据和其他相关文档已在[Research 分支](https://github.com/apache/incubator-graphar/tree/research)中提供。