SQL grouping 解决 OLAP 场景总计与小计问题,其语法分为几类,但要解决的是同一个问题:
ROLLUP 与 CUBE 是封装了规则的 GROUPING SETS,而 GROUPING SETS 则是最原始的规则。
为了方便理解,让我们从一个问题入手,层层递进吧。
## 底表
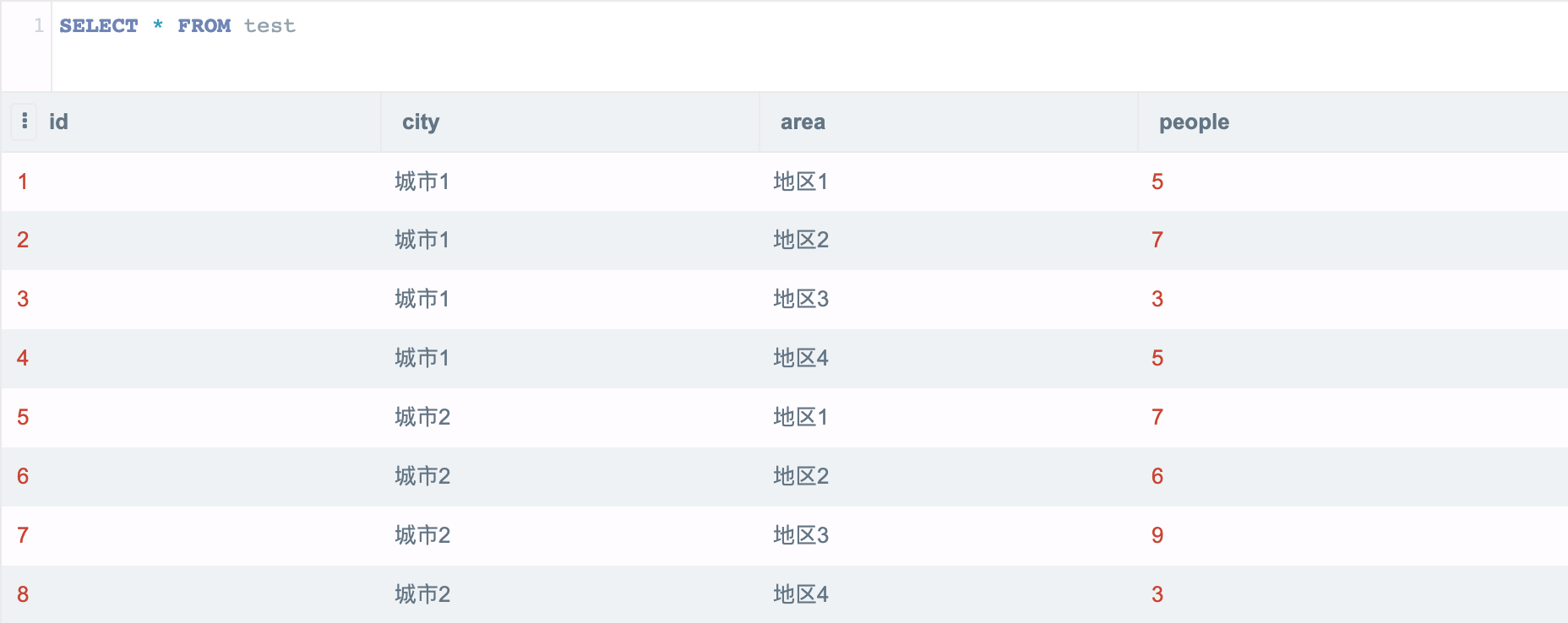 以上是示例底表,共有 8 条数据,城市1、城市2 两个城市,下面各有地区1~4,每条数据都有该数据的人口数。
现在想计算人口总计,以及各城市人口小计。在没有掌握 grouping 语法前,我们只能通过两个 select 语句 union 后得到:
```sql
SELECT city, sum(people) FROM test GROUP BY city
union
SELECT '合计' as city, sum(people) FROM test
```
以上是示例底表,共有 8 条数据,城市1、城市2 两个城市,下面各有地区1~4,每条数据都有该数据的人口数。
现在想计算人口总计,以及各城市人口小计。在没有掌握 grouping 语法前,我们只能通过两个 select 语句 union 后得到:
```sql
SELECT city, sum(people) FROM test GROUP BY city
union
SELECT '合计' as city, sum(people) FROM test
```
 但两条 select 语句聚合了两次,性能是一个不小的开销,因此 SQL 提供了 GROUPING SETS 语法解决这个问题。
## GROUPING SETS
GROUP BY GROUPING SETS 可以指定任意聚合项,比如我们要同时计算总计与分组合计,就要按照空内容进行 GROUP BY 进行一次 sum,再按照 city 进行 GROUP BY 再进行一次 sum,换成 GROUPING SETS 描述就是:
```sql
SELECT
city, area,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
其中 `GROUPING SETS((), (city, area))` 表示分别按照 `()`、`(city, area)` 聚合计算总计。返回结果是:
但两条 select 语句聚合了两次,性能是一个不小的开销,因此 SQL 提供了 GROUPING SETS 语法解决这个问题。
## GROUPING SETS
GROUP BY GROUPING SETS 可以指定任意聚合项,比如我们要同时计算总计与分组合计,就要按照空内容进行 GROUP BY 进行一次 sum,再按照 city 进行 GROUP BY 再进行一次 sum,换成 GROUPING SETS 描述就是:
```sql
SELECT
city, area,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
其中 `GROUPING SETS((), (city, area))` 表示分别按照 `()`、`(city, area)` 聚合计算总计。返回结果是:
 可以看到,值为 NULL 的行就是我们要的总计,其值是没有任何 GROUP BY 限制算出来的。
类似的,我们还可以写 `GROUPING SETS((), (city), (city, area), (area))` 等任意数量、任意组合的 GROUP BY 条件。
通过这种规则计算的数据我们称为 “超级分组记录”。我们发现 “超级分组记录” 产生的 NULL 值很容易和真正的 NULL 值弄混,所以 SQL 提供了 GROUPING 函数解决这个问题。
## 函数 GROUPING
对于超级分组记录产生的 NULL,是可以被 `GROUPING()` 函数识别为 1 的:
```sql
SELECT
GROUPING(city),
GROUPING(area),
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
具体效果见下图:
可以看到,值为 NULL 的行就是我们要的总计,其值是没有任何 GROUP BY 限制算出来的。
类似的,我们还可以写 `GROUPING SETS((), (city), (city, area), (area))` 等任意数量、任意组合的 GROUP BY 条件。
通过这种规则计算的数据我们称为 “超级分组记录”。我们发现 “超级分组记录” 产生的 NULL 值很容易和真正的 NULL 值弄混,所以 SQL 提供了 GROUPING 函数解决这个问题。
## 函数 GROUPING
对于超级分组记录产生的 NULL,是可以被 `GROUPING()` 函数识别为 1 的:
```sql
SELECT
GROUPING(city),
GROUPING(area),
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
具体效果见下图:
 可以看到,但凡是超级分组计算出来的字段都会识别为 1,我们利用之前学习的 [SQL CASE 表达式](https://github.com/ascoders/weekly/blob/master/SQL/234.SQL%20CASE%20%E8%A1%A8%E8%BE%BE%E5%BC%8F.md) 将其转换为总计、小计字样,就可以得出一张数据分析表了:
```sql
SELECT
CASE WHEN GROUPING(city) = 1 THEN '总计' ELSE city END,
CASE WHEN GROUPING(area) = 1 THEN '小计' ELSE area END,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
可以看到,但凡是超级分组计算出来的字段都会识别为 1,我们利用之前学习的 [SQL CASE 表达式](https://github.com/ascoders/weekly/blob/master/SQL/234.SQL%20CASE%20%E8%A1%A8%E8%BE%BE%E5%BC%8F.md) 将其转换为总计、小计字样,就可以得出一张数据分析表了:
```sql
SELECT
CASE WHEN GROUPING(city) = 1 THEN '总计' ELSE city END,
CASE WHEN GROUPING(area) = 1 THEN '小计' ELSE area END,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
 然后前端表格展示时,将第一行 “总计”、“小计” 单元格合并为 “总计”,就完成了总计这个 BI 可视化分析功能。
## ROLLUP
ROLLUP 是卷起的意思,是一种特定规则的 GROUPING SETS,以下两种写法是等价的:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
再看一组等价描述:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (city, area))
```
发现规律了吗?ROLLUP 会按顺序把 GROUP BY 内容 “一个个卷起来”。用 GROUPING 函数判断超级分组记录对 ROLLUP 同样适用。
## CUBE
CUBE 又有所不同,它对内容进行了所有可能性展开(所以叫 CUBE)。
类比上面的例子,我们再写两组等价的展开:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
上面的例子因为只有一项还看不出来,下面两项分组就能看出来了:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (area), (city, area))
```
所谓 CUBE,是一种多维形状的描述,二维时有 2^1 种展开,三维时有 2^2 种展开,四维、五维依此类推。可以想象,如果用 CUBE 描述了很多组合,复杂度会爆炸。
## 总结
学习了 GROUPING 语法,以后前端同学的你不会再纠结这个问题了吧:
> 产品开启了总计、小计,我们是额外取一次数还是放到一起获取啊?
这个问题的标准答案和原理都在这篇文章里了。PS:对于不支持 GROUPING 语法数据库,要想办法屏蔽,就像前端 polyfill 一样,是一种降级方案。至于如何屏蔽,参考文章开头提到的两个 SELECT + UNION。
> 讨论地址是:[精读《SQL grouping》· Issue #406 · ascoders/weekly](https://github.com/ascoders/weekly/issues/406)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
然后前端表格展示时,将第一行 “总计”、“小计” 单元格合并为 “总计”,就完成了总计这个 BI 可视化分析功能。
## ROLLUP
ROLLUP 是卷起的意思,是一种特定规则的 GROUPING SETS,以下两种写法是等价的:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
再看一组等价描述:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (city, area))
```
发现规律了吗?ROLLUP 会按顺序把 GROUP BY 内容 “一个个卷起来”。用 GROUPING 函数判断超级分组记录对 ROLLUP 同样适用。
## CUBE
CUBE 又有所不同,它对内容进行了所有可能性展开(所以叫 CUBE)。
类比上面的例子,我们再写两组等价的展开:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
上面的例子因为只有一项还看不出来,下面两项分组就能看出来了:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (area), (city, area))
```
所谓 CUBE,是一种多维形状的描述,二维时有 2^1 种展开,三维时有 2^2 种展开,四维、五维依此类推。可以想象,如果用 CUBE 描述了很多组合,复杂度会爆炸。
## 总结
学习了 GROUPING 语法,以后前端同学的你不会再纠结这个问题了吧:
> 产品开启了总计、小计,我们是额外取一次数还是放到一起获取啊?
这个问题的标准答案和原理都在这篇文章里了。PS:对于不支持 GROUPING 语法数据库,要想办法屏蔽,就像前端 polyfill 一样,是一种降级方案。至于如何屏蔽,参考文章开头提到的两个 SELECT + UNION。
> 讨论地址是:[精读《SQL grouping》· Issue #406 · ascoders/weekly](https://github.com/ascoders/weekly/issues/406)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
 > 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))