{
"cells": [
{
"cell_type": "markdown",
"source": [
"# Keywords Analysis\n",
"\n",
"In this notebook, you will use the KeywordsAnalysis tool to analyse words in a collection of texts (in a corpus) and identify whether certain words are over- or under-represented in a particular corpus (the study corpus) compared to their frequency in the other corpus (the reference corpus). \n",
"\n",
"**Note:** the statistical calculations used in this tool (Log Likelihood, %Diff, Bayes Factor, Effect Size for Log Likelihood, Relative Risk, Log Ratio, Odds Ratio) are the python implementation of the statistical calculations on this [website](https://ucrel.lancs.ac.uk/llwizard.html), and are explained there with relevant attribution and links.\n",
"\n",
"\n",
"User guide to using a Jupyter Notebook \n",
"\n",
"If you are new to Jupyter Notebook, feel free to take a quick look at [this user guide](https://github.com/Australian-Text-Analytics-Platform/semantic-tagger/blob/main/documents/jupyter-notebook-guide.pdf) for basic information on how to use a notebook.\n",
"
\n",
"\n",
"### Keyword Analysis User Guide\n",
"\n",
"For instructions on how to use the Document Similarity tool, please refer to the [Keyword Analysis User Guide](documents/keywords_help_pages.pdf)."
],
"metadata": {
"collapsed": false
},
"id": "09ff3725"
},
{
"cell_type": "markdown",
"id": "feedfad4-e1d7-4662-aa31-7c6bd428b732",
"metadata": {},
"source": [
"## Acknowledgements\n",
"We would like to acknowledge the Statistical Consulting Service provided by Stanislaus Stadlmann from the Sydney Informatics Hub, a Core Research Facility of the University of Sydney."
]
},
{
"cell_type": "markdown",
"id": "2c08e975",
"metadata": {},
"source": [
"## 1. Setup\n",
"Before you begin, you need to import the KeywordsAnalysis package and the necessary libraries and initiate them to run in this notebook."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "045c5ce2",
"metadata": {},
"outputs": [],
"source": [
"# import the KeywordsAnalysis tool\n",
"print('Loading KeywordsAnalysis...')\n",
"from keywords_analysis import KeywordsAnalysis, DownloadFileLink\n",
"\n",
"# initialize the KeywordsAnalysis\n",
"ka = KeywordsAnalysis()\n",
"print('Finished loading.')"
]
},
{
"cell_type": "markdown",
"id": "e631321b",
"metadata": {},
"source": [
"## 2. Load the data\n",
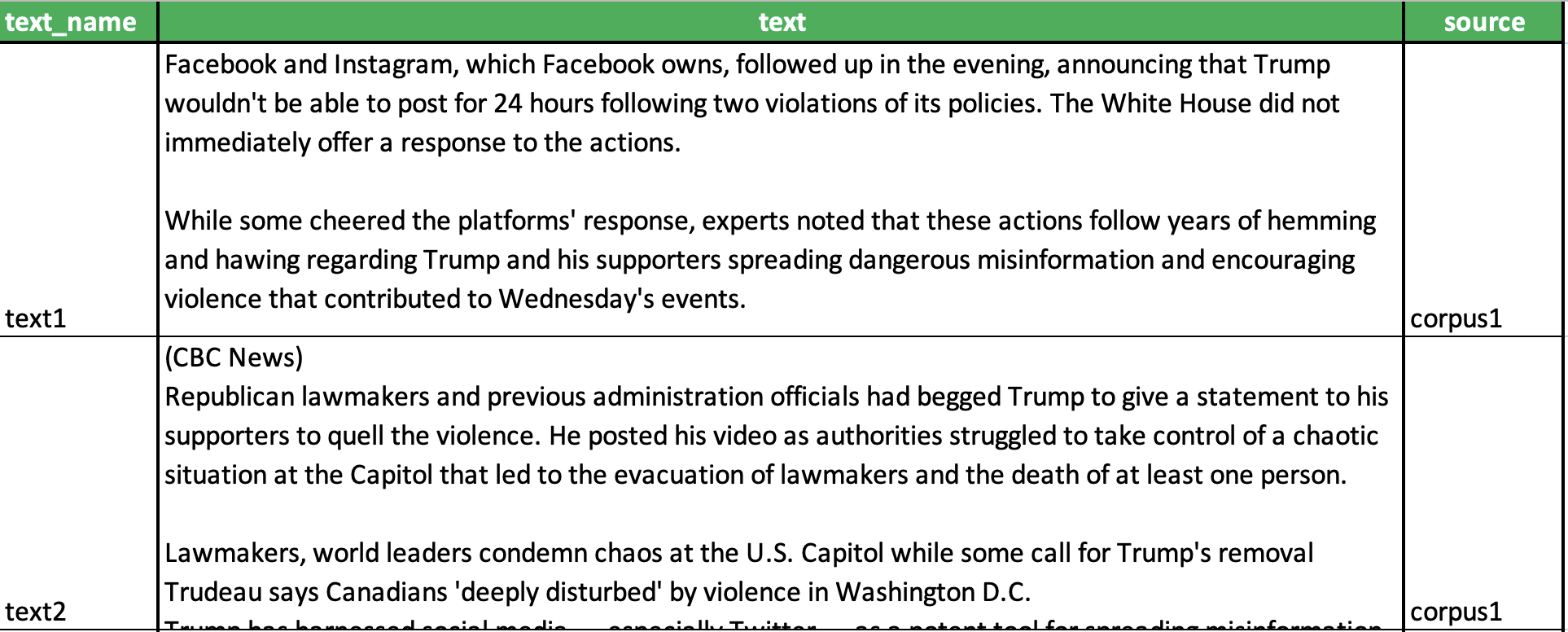
"This notebook will allow you to upload text data in a text/corpus file (or a number of text/corpus files). You upload each file/corpus in turn and then compare them. For instance, you could identify keywords in four different corpora that you have uploaded one after the other as separate zip files. Alternatively, you could upload your corpora all at once by specifying the source/corpus name in an excel spreadsheet (see below example). \n",
"\n",
"\n",
"  | \n",
"  | \n",
"  | \n",
"  | \n",
"
\n",
"\n",
"\n",
"  | \n",
"
\n",
"\n",
"\n",
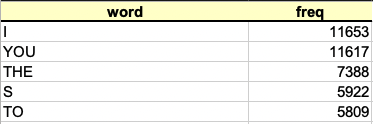
"Uploading word frequency list \n",
" \n",
"There may be times where you only have the word frequencies without having access to the actual corpus. In this case, you can store the word frequencies in an excel spreadsheet (the first column should contain the words and the second column the word frequencies - see below example) and upload it here. Please ensure to give a corpus name for each uploaded spreadsheet and tick the 'Uploading word frequency list' box. \n",
"
\n",
"\n",
"\n",
"  | \n",
"
\n",
"\n",
"\n",
"Tokens in the word frequency list \n",
"\n",
"This tool uses scikit learn's CountVectorizer to tokenize the texts (a token is identified as one or more alphanumeric characters in the texts, and punctuation is ignored and treated as a token separator, e.g., \"high-school\" will be tokenized as two tokens \"high\" and \"school\"). We suggest to follow the same token format when uploading your own word frequency list. For more information about the CountVectorizer, please visit [this page](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "875739d0",
"metadata": {},
"outputs": [],
"source": [
"# upload the text files and/or excel spreadsheets onto the system\n",
"ka.upload_file_widget()"
]
},
{
"cell_type": "markdown",
"id": "9bd637bd",
"metadata": {},
"source": [
"\n",
"Large file upload \n",
" \n",
"If you have ongoing issues with the file upload, please re-launch the notebook. If the issue persists, consider restarting your computer.\n",
"
"
]
},
{
"cell_type": "markdown",
"id": "b6cdc7da",
"metadata": {},
"source": [
"## 3. Calculate word statistics\n",
"Once your texts have been uploaded, you can begin to calculate the statistics for the words in the corpus. \n",
"\n",
"\n",
"Tools: \n",
"\n",
"- scikit learn's CountVectorizer: used to tokenize the texts. \n",
"\n",
"Note: a token is identified as one or more alphanumeric characters in the texts. Here, punctuation is completely ignored and always treated as a token separator. For further information about the CountVectorizer, please visit [this page](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html).\n",
"
\n",
"\n",
"\n",
"Memory limitation in Binder \n",
" \n",
"The free Binder deployment is only guaranteed a maximum of 2GB memory. Processing very large text files may cause the session (kernel) to re-start due to insufficient memory. Check [the user guide](https://github.com/Australian-Text-Analytics-Platform/semantic-tagger/blob/main/documents/jupyter-notebook-guide.pdf) for more info. \n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "cbf368ed",
"metadata": {},
"outputs": [],
"source": [
"# begin the process of calculating word statistics\n",
"ka.calculate_word_statistics()"
]
},
{
"cell_type": "markdown",
"id": "7c5f8eec",
"metadata": {},
"source": [
"## 4. Analyse word statistics\n",
"Once the tool has finished calculating the statistics, you can begin to analyse the outcome. \n",
"\n",
"\n",
"Pairwise analysis \n",
" \n",
"Below, you can analyse keyword statistics between pairs of datasets (study corpus vs reference corpus). When you have more than two datasets to compare (e.g., corpus 1, corpus 2 and corpus 3), you can either choose to compare one corpus to another (e.g., study corpus 1 vs reference corpus 2), or one corpus with the rest of the data (e.g., study corpus: corpus 2 vs reference corpus: rest of corpus, which includes corpus 1 and 3). \n",
"\n",
"By default, the graph displays the first 30 positive (overuse) keywords in the study corpus (the x-axis) and the log-likelihood for each word (the y-axis), sorted in descending order. However, you can use the below widgets to select different words/statistics: \n",
"- Select statistic(s) to display: press and hold the Ctrl button to select multiple statistics using the left-click button on your mouse. \n",
"- Sorted by: to sort based on the selected statistic value (from highest to lowest) or in alphabetical order. \n",
"- Keywords to display: to display positive (overuse), negative (underuse) or all keywords in the study corpus vs the reference corpus.\n",
"- Select index: move the index up/down by 10 using the up/down arrow to display subsequent words, or enter your own index number and press 'Tab' to select any index number. \n",
"- Display chart: to display the selected statistics in the chart. \n",
"- Save data to excel: to save the data to an excel spreadsheet and download it to your local computer. \n",
" \n",
"Finally, once you generate the graph, you can save and download it to your computer using the 'save' icon on the right-hand side of the graph. \n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5309d3a2",
"metadata": {},
"outputs": [],
"source": [
"# generate pair-wise corpus analysis\n",
"ka.analyse_stats(right_padding=0.9) # adjust the 'right_padding' to move the legend box left/right"
]
},
{
"cell_type": "markdown",
"id": "c511eefa",
"metadata": {},
"source": [
"\n",
"What information is included in the above chart? \n",
"\n",
"**normalised_wc/normalised_reference_corpus_wc:** the normalised count of the word in the study corpus vs the reference corpus. Here, the normalised word count is calculated by dividing the total words for each word in the corpus by the total words in that corpus.\n",
" \n",
"**log-likelihood$^{1}$:** the log-likelihood that a word is statistically different in the study corpus vs the reference corpus. \n",
" \n",
"**percent-diff$^{2}$:** the percentage difference between the use of a word in the study corpus vs the reference corpus. \n",
" \n",
"**bayes factor BIC$^{3}$:** the degree of evidence that a word is statistically different in the study corpus vs the reference corpus. \n",
" \n",
"**effect size for log-likelihood (ELL)$^{4}$:** the proportion of the maximum departure between the log-likelihood of a word and its expected frequency. \n",
" \n",
"**relative risk$^{5}$:** the relative frequency of (how many times more frequent) a particular word in the study corpus vs the reference corpus.\n",
" \n",
"**log ratio$^{2}$:** the doubling size (2^n) of a particular word in the study corpus vs the reference corpus. \n",
" \n",
"**odd ratio$^{5}$:** the odd that a particular word is used in the study corpus vs the reference corpus. \n",
" \n",
"**Notes:** \n",
"$^{1}$A large value (>=3.84 at 95% confidence interval) indicates that the use of the word is statistically different in the study corpus vs the reference corpus. \n",
"$^{2}$A positive value indicates overuse of that word in the study corpus vs the reference corpus, and vice versa. \n",
"$^{3}$A large positive value (>=2) indicates higher degree of evidence that a word is statistically different in the study corpus vs the reference corpus. \n",
"$^{4}$The ELL typically ranges from 0-1. But if two corpora are compared and one of the expected frequencies < 1, the ELL will be negative. In this case, the ELL should not be compared to ELL’s of different words, or interpreted by itself. \n",
"$^{5}$A large value indicates overuse of the word in the study corpus vs the reference corpus, and vice versa. \n",
"\n",
"For more information on the above statistics, please visit this [website](https://ucrel.lancs.ac.uk/llwizard.html). \n",
"
"
]
},
{
"cell_type": "markdown",
"id": "5671f463",
"metadata": {},
"source": [
"\n",
"
Multi-corpora analysis \n",
" \n",
"Below, you can analyse the overall statistics at the multi-corpora level, for cases where you explore more than two corpora. This option is only available for some of the statistics, because the other statistics are only applicable to pairwise comparisons. \n",
" \n",
"By default, the graph displays the first 30 keywords in the multi-corpora (the x-axis) and the log-likelihood for each word (the y-axis), sorted in descending order. However, similar to the above, you can use the below widgets to select different words/statistics."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2f79fb65",
"metadata": {},
"outputs": [],
"source": [
"# generate multi-corpus analysis\n",
"ka.analyse_stats(right_padding=0.5, multi=True)"
]
},
{
"cell_type": "markdown",
"id": "8db56f6f",
"metadata": {},
"source": [
"
\n",
"What information is included in the above chart? \n",
" \n",
"For the multi-corpus comparison, the statistics are calculated across the whole set in one go. In other words, an adjusted/expected average is calculated for each corpus and actual/observed frequencies are compared to this average.\n",
"\n",
"**log-likelihood$^{1}$:** the log-likelihood that the observed frequencies of a word are different from their adjusted/expected average frequencies. \n",
" \n",
"**bayes factor BIC$^{2}$:** the degree of evidence that the observed frequencies of a word are different from their adjusted/expected average frequencies. \n",
" \n",
"**effect size for log-likelihood (ELL)$^{3}$:** the proportion of the maximum departure between the observed frequencies of a word and their adjusted/expected average frequencies. \n",
" \n",
"**Notes:** \n",
"$^{1}$A larger value (>=3.84 at 95% confidence interval) means the observed frequencies are very different from their expected/average frequencies. The higher the LL value of a word, the more variable the frequencies are from the adjusted/expected average. For words with high LL values, there will be a lot of variation in how they are used across the multi-corpora. \n",
"$^{2}$A larger value (>=2) means higher degree of evidence that the observed frequencies are very different from their adjusted/expected average frequencies. Higher BIC value shows more evidence that there is more variation in how the word is used across the multi-corpora. \n",
"$^{3}$A larger value indicates larger variation between the observed and their adjusted/expected average frequencies, but this calculation is very sensitive to the size of the corpora included in the multi-corpus comparison. The ELL value would also change depending on whether a word with a small expected frequency is included/excluded (because the scaling is along the logarithm of the minimum of all expected frequencies that are compared). We recommend using the LL or BIC values instead.\n",
"For more information on the above statistics, please visit this [website](https://ucrel.lancs.ac.uk/llwizard.html). The website also includes an explanation of how raw/absolute frequencies of zero are handled. We recommend users inspect results and have caution when zero raw/frequencies are involved.\n",
"
"
]
},
{
"cell_type": "markdown",
"id": "883a2047",
"metadata": {},
"source": [
"## 5. Welch t-test and Fisher permutation test\n",
"In this section, you will be able to use statistical tests to investigate if the use of a certain word in a corpus is statistically different to the use of that same word in a different corpus. All you need to do is enter the 'word' you wish to analyse, the two corpora you wish to compare, perform data transformation if needed (optional) and select the statistical test to perform using the below tool.\n",
"\n",
"
\n",
"Tools: \n",
" \n",
"- scipy: collection of math algorithms and functions built on the NumPy extension of Python\n",
"- nltk: natural language processing toolkit\n",
"
\n",
"\n",
"
\n",
"Welch t-test \n",
"\n",
"The Welch t-test is used to test if two populations have equal means. In this context, the Welch t-test will be used to test if the mean (average) frequency of a word in one corpus is the same as the mean frequency of that word in a different corpus. If the mean frequencies in the two corpora being compared are significantly different, then it can be said that the difference is statistically significant. \n",
" \n",
"**Note:** for more information about the Welch t-test, please visit this [website](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html#r3566833beaa2-2).\n",
"
\n",
"\n",
"
\n",
"Fisher permutation test \n",
"\n",
"The Fisher permutation test is used to test if all observations in the data are sampled from the same distribution. In this context, the Fisher permutation test will be used to test if the frequencies of a word in a corpus and the frequencies of that word in another corpus are the same. If not, and the difference is significant, then it can be said that the use of that word in one corpus is statistically different to that in the other corpus. \n",
" \n",
"**Note:** for more information about the Fisher permutation test, please visit this [website](https://docs.scipy.org/doc//scipy/reference/generated/scipy.stats.permutation_test.html).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c34fc29a",
"metadata": {},
"outputs": [],
"source": [
"ka.word_usage_analysis()"
]
},
{
"cell_type": "markdown",
"id": "74d0e1bb",
"metadata": {},
"source": [
"
\n",
"Data transformation \n",
"\n",
"Statistical tests often assume that data is normally distributed (bell-shaped distribution). However, real world data can be messy and often are not normally distributed. Whilst it is not always possible to do so, you can always try to transform your data to more closely match a normal distirbution. In the above tool, you have the option to apply (1) log tranformation, or (2) square root transformation to your data if you wish. \n",
"
\n",
"\n",
"
\n",
"Word frequency list \n",
" \n",
"You are unable to perform these statistical tests if you only upload the word frequency list as the analysis are conducted on the number of words in each text within the corpus. Please upload the actual text files to do this section. \n",
"
"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.6"
}
},
"nbformat": 4,
"nbformat_minor": 5
}