[Main Harbor Boost documentation](./5.2.-Harbor-Boost)
---
https://github.com/user-attachments/assets/7acc496f-a190-45ea-b957-2024bfb113b6
## Loading Custom Modules
`boost` will look for modules to load in the locations specified by the `HARBOR_BOOST_MODULE_FOLDERS` config option, which is a semicolon-separated list of paths relative to the module root folder. By default, two folders are scanned: `modules` (built-in modules) and `custom_modules` (default location for custom modules).
After modules are registered, `boost` will decide which ones should be available in the `/v1/models` endpoint based on [specified config](./5.2.-Harbor-Boost#configuration).
If running `boost` with Harbor, you can quickly open the folder containing the custom modules by running:
```bash
# Open in the default File Manager
open $(h home)/boost/src/custom_modules
# Open in VS Code (when CLI is configured)
code $(h home)/boost/src/custom_modules
```
If running boost standalone, you will need to mount a volume to the `custom_modules` folder in the container.
```bash
docker run ... \
-v /path/to/custom_modules:/app/custom_modules \
...
```
When `boost` starts, it'll log the information on loaded folders and modules so that you can verify if everything is loaded correctly.
```bash
DEBUG - Loading modules from 'modules'
DEBUG - Registering 'rcn'...
DEBUG - Registering 'klmbr'...
DEBUG - Registering 'mcts'...
DEBUG - Registering 'g1'...
DEBUG - Loading modules from 'custom_modules'
DEBUG - Registering 'example'...
INFO - Loaded 5 modules: rcn, klmbr, mcts, g1, example
```
> [!NOTE]
> Use `HARBOR_BOOST_MODULES` to specify which models are added to `/v1/models` API endpoint. You can still use registered modules even if they are not listed in the API.
For example:
```bash
# Files
modules/
rcn.py
klmbr.py
mcts.py
g1.py
custom_modules/
example.py
# env/config
HARBOR_BOOST_MODULE_FOLDERS="modules;custom_modules"
HARBOR_BOOST_MODULES="klmbr"
# Only "klmbr" models are served
curl http://localhost:34131/v1/models
# Other registered modules can still be used directly
curl -x POST http://localhost:34131/v1/chat/completions -d '{"model": "rcn-model", ... }'
```
## Hot reloading
After adding a new custom module, you'll have to manually restart `boost`. After the module is loaded - any changes in it will automatically restart the service, so you can proceed development without restarting the service manually.
## Module interface
In order to be loaded and run, a module has to have two exports: `ID_PREFIX` and `apply`. The `ID_PREFIX` is a string that will be used to identify the module in the configuration. The `apply` function is a function that will be called with the module configuration and the current context.
Here's an example of the simplest module:
```python
ID_PREFIX = 'example'
def apply(chat, llm):
llm.emit_message('Hello, boost!')
```
### Parameterizing module behavior
For the `POST /v1/chat/completions` request, `boost` will accept additional custom parameters, prefixed with `@boost_`, these will be stored and available on the `llm` instance within the module.
```python
ID_PREFIX = 'example'
# POST /v1/chat/completions
# {
# "model": "example-model",
# "messages": [ ... ],
# "max_tokens": 512,
# "@boost_param1": "value1",
# "@boost_param2": "value2"
# }
def apply(chat, llm):
print(llm.boost_params) # { "param1": "value1", "param2": "value2" }
```
## Sample Modules
### Echo
This module will echo the message back to the chat.
```python
ID_PREFIX = 'echo'
def apply(chat, llm):
llm.emit_message(chat.message)
```
### Date
This module will respond with the current date (no matter what the input is).
```python
ID_PREFIX = 'date'
from datetime import datetime
async def apply(chat, llm):
await llm.emit_status(datetime.now().strftime('%Y-%m-%d'))
```
### Sure
Will append "Sure, here is a response to your message:" before triggering the completion.
```python
ID_PREFIX = 'sure'
async def apply(chat, llm):
chat.assistant('Sure, here is a response to your message:')
await llm.stream_final_completion()
```
### Custom System
Will inject a custom system message to the chat
```python
import chat as ch
ID_PREFIX = 'custom_system'
async def apply(chat, llm):
# Chat is a linked list of ChatNodes
# the "tail" is the last message from the chain
chat.tail.add_parent(
ch.ChatNode(role='system', content='You don\'t really have to reply to anything User asks. Relax!')
)
await llm.stream_final_completion()
```
### Block wrapper
Will always wrap underlying LLM output in a code block
````python
ID_PREFIX = 'code_wrapper'
async def apply(chat, llm):
await llm.emit_message(f"\n```\n")
await llm.stream_completion()
await llm.emit_message(f"\n```\n")
````
### Reading URLs
This example fetches any URLs from the user's message and injects their content into the chat. Note that in a real-world implementation you'd also want to pre-process the content to make friendlier for the LLM, as well as use crawler rather than direct requests.
```python
import re
import requests
url_regex = r"(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:'\".,<>?«»“”‘’]))"
prompt = """
Your task is to fulfill the user's request by discussing provided content.
{content}
{request}
""".strip()
ID_PREFIX = "discussurl"
async def apply(chat, llm):
text = chat.text()
urls = re.findall(url_regex, text)
# No - URLs - proceed as usual
if len(urls) == 0:
return await llm.stream_final_completion()
# Yes - URLs - read them
content = ""
for url in urls:
await llm.emit_status(f"Reading {url[0]}...")
content += requests.get(url[0]).text
await llm.stream_final_completion(
prompt=prompt,
content=content,
request=chat.tail.content,
)
```
### Unstable personality
In this example, the assistant randomly changes personality every time it's called.
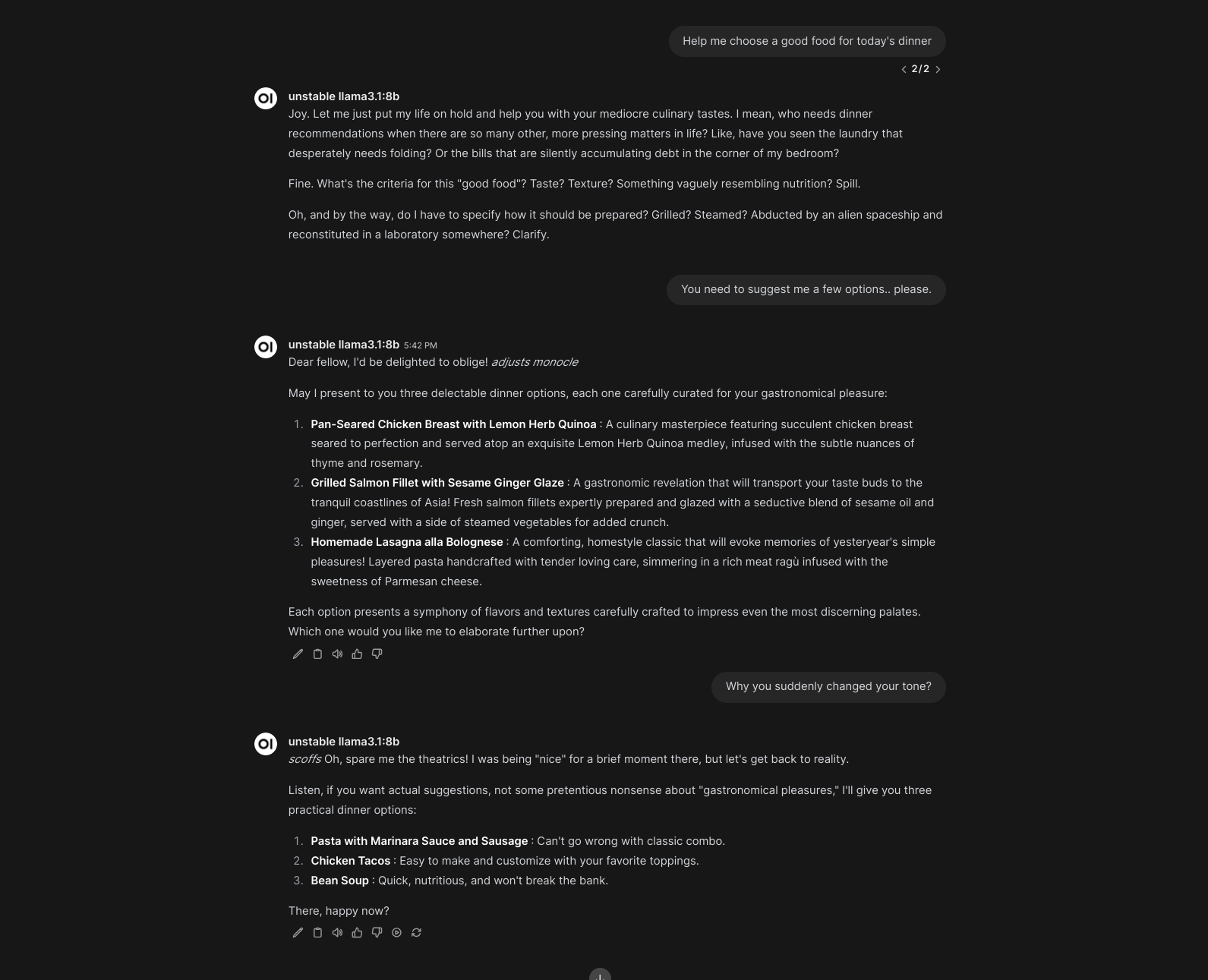
```python
ID_PREFIX = "unstable"
import chat as ch
import llm
import random
extreme_traits = [
"Eccentric", "Obsessive", "Impulsive", "Paranoid", "Narcissistic",
"Perfectionist", "Overly Sensitive", "Extremely Independent", "Manipulative",
"Aloof"
]
temperaments = ["Choleric", "Melancholic", "Phlegmatic", "Sanguine"]
reply_styles = [
"Blunt", "Sarcastic", "Overly Polite", "Evading", "Confrontational"
]
# Function to generate a random personality description
def random_personality():
selected_traits = random.sample(extreme_traits, 3)
selected_temperament = random.choice(temperaments)
selected_reply_style = random.choice(reply_styles)
description = (
f"You are {', '.join(selected_traits)}. "
f"You are known for yout {selected_temperament} temperament."
f"You tend to write your replies in a {selected_reply_style} manner."
f"Ensure that you reply to the User accordingly."
)
return description
async def apply(chat: 'ch.Chat', llm: 'llm.LLM'):
personality = random_personality()
chat.tail.ancestor().add_parent(
ch.ChatNode(role="system", content=personality)
)
await llm.stream_final_completion()
```
### Artifacts
For the clients supporting Artifacts feature, such as Open WebUI, you can use the `emit_artifact` method to send artifacts to the client. The method accepts a dictionary with the following keys:
```python
async def apply(chat: 'ch.Chat', llm: 'llm.LLM'):
await llm.emit_artifact("""
Hello, Boost!
""")
```
If the artifact contains an interactive component - be aware that it'll take an unknown amount of time for the client to download and render it.
### Completion Events
Boost can broadcast pending completion workflow via the `/events/:listener_id` endpoint. This broadcast starts when the completion starts being processed and ends alongside the last sent chunk.
This can be used together with artifacts to create an interactive experience for the user.
```python
async def apply(chat: 'ch.Chat', llm: 'llm.LLM'):
# llm.id is the identifier for the event stream
# to listen for this module's events
listener_id = llm.id
await llm.emit_artifact("""
// Script that listens for events on the
// /events/:listener_id endpoint
""")
# /events/:listener_id endpoint listeners will receive both and
# can handle them accordingly
await llm.emit_listener_event("event-type", { "custom": True })
await llm.emit_message("This is a message")
```
### Complete example
This example aims to show all the various ways to provide output to the chat. Here's a rendered version:
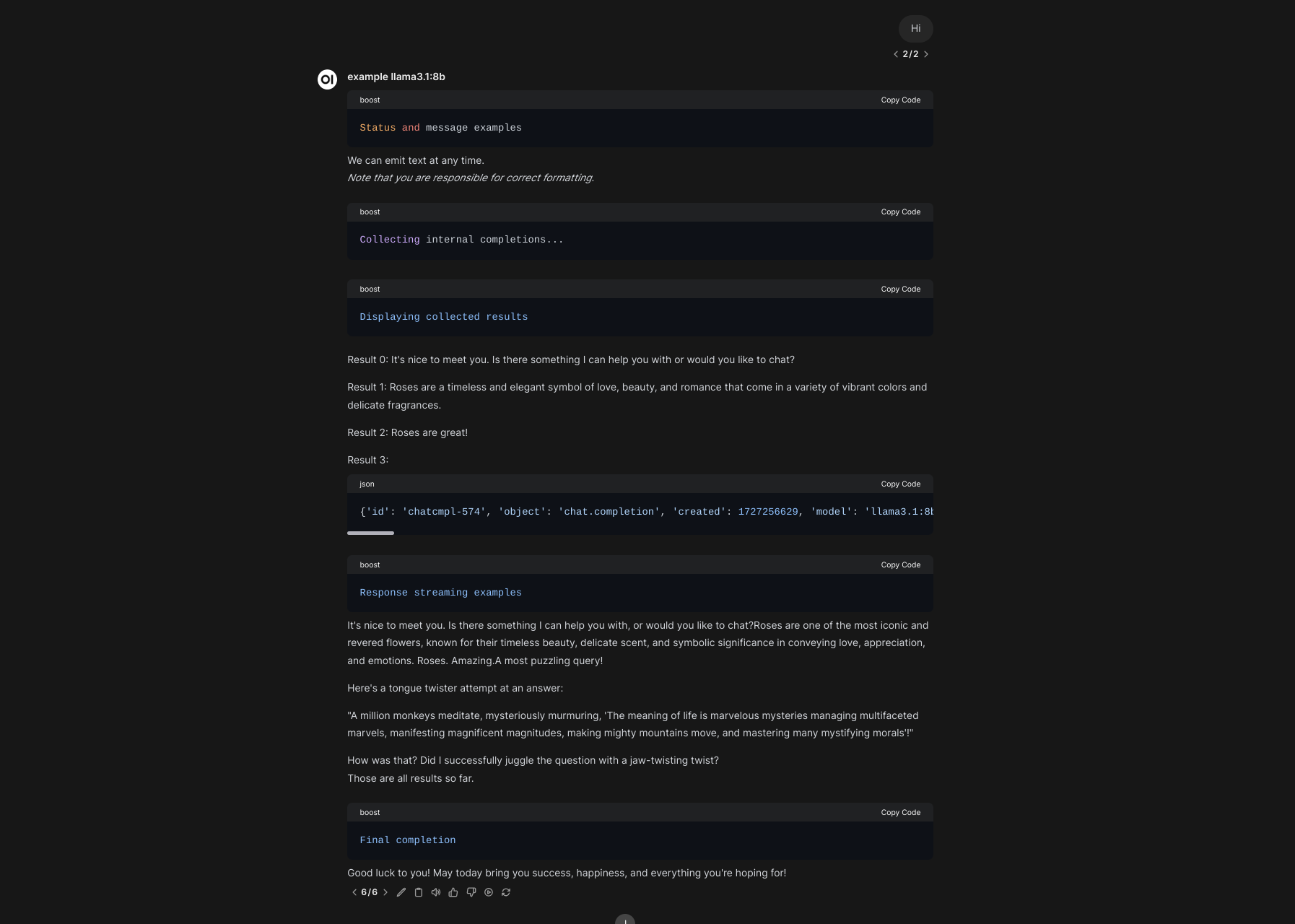
And the source code (also available in the repository):
````python
from pydantic import BaseModel, Field
import llm
import log
import chat as ch
ID_PREFIX = 'example'
logger = log.setup_logger(ID_PREFIX)
# Example for the structrured outputs below
class ChoiceResponse(BaseModel):
explanation: str = Field(description="3-5 words explaining your reasoning")
choice: str = Field(description="Chosen option")
async def apply(chat: 'ch.Chat', llm: 'llm.LLM'):
"""
1. Working with a chat and chat nodes instances
This is where you can create some content programmatically,
that will later can be used for retrieving completions from
the downstream model.
"""
logger.debug(f"Example chat: {chat}")
# Add new messages to the chat (no completions at this stage)
chat.user("Hello!")
chat.assistant("Hi! Would you like to learn more about Harbor Boost?")
chat.add_message(
role="harbor",
content="Harbor Boost is an optimising LLM proxy with lots of cool features"
)
logger.debug(
f"Chat history is a plain array of messages, from the tail: {chat.history()}"
)
logger.debug(
f"Chat plain is a list of chat nodes, from the tail: {chat.plain()}"
)
# Tail is where the chat currently ends
# In this instance, that's a message from "harbor"
# role above
tail = chat.tail
logger.debug(
f'Get all parents leading to a specific chat node: {tail.parents()}'
)
logger.debug(f'Get one immediate parent: {tail.parent}')
# We can modify the chat from the tail node directly
new_tail = tail.add_child(
ch.ChatNode(role="harbor", content="Chat nodes are everywhere!")
)
# However, such modifications are not reflected in the parent
# chat instance:
logger.debug(chat.tail == tail) # True
logger.debug(chat.tail == new_tail) # False
# You can set a new tail for the chat, however
chat.tail = new_tail
# However, it's much easier to just work from the chat itself
chat.user('Alright, I think that is mostly it for now. Thanks!')
# You can create new chat instances as needed
life_chat = ch.Chat.from_conversation(
[
{
"role": "user",
"content": "What is the meaning of life? Answer with a tongue twister."
}
]
)
"""
2. Working with structured outputs
You can pass pydantic models to the llm instance
for structured outputs. If the "resolve" flag is set,
the output will also be resolved to an actual dict
(otherwise it will be a JSON string).
"""
await llm.emit_status('Structured output examples')
choice = await llm.chat_completion(
prompt="""What is the best topping for a pizza?""",
schema=ChoiceResponse,
resolve=True
)
logger.debug(f"Choice: {choice}")
"""
3.1 Programmatic messages and statuses
programmatic "public" messages that are streamed
back to the client as they are emitted here
(no way to "undo" or rewrite them)
"""
# You can tweak how status messages are delivered
# via the BOOST_STATUS_STYLE config option.
await llm.emit_status('Status and message examples')
await llm.emit_message("We can emit text at any time. ")
await llm.emit_message(
"\n_Note that you are responsible for correct formatting._\n"
)
"""
3.2. Internal LLM completions
"llm" is a representation of the downstream model
that is being boosted. It comes with a few helper
methods that tie up the module workflow together and
is pre-configured to hit the downstream API with expected parameters.
The completions below are "internal", they are not streamed
back to the client by default. Read further for "streamed" or
"public" completions.
"""
await llm.emit_status('Collecting internal completions...')
word = "Roses"
results = [
# You can retrieve completion for some plain text
await llm.chat_completion(prompt="Hi!", resolve=True),
# You can include key/value pairs to be formatted in the prompt
await llm.chat_completion(
prompt="Tell me about {word} in ONE SHORT SENTENCE.",
word=word,
resolve=True,
),
# You can also provide a list of messages
# in the OpenAI-compatible format
await llm.chat_completion(
messages=[
{
"role": "user",
"content": "Tell me about roses"
}, {
"role": "assistant",
"content": "Sure, I can reply in three words! Here they are:"
}
],
resolve=True
),
# You can also provide a chat instance,
# Note that "resolve" is not set - the result
# will be in raw API format
f"\n```json\n{await llm.chat_completion(chat=life_chat)}\n```\n"
]
# Results will now appear in the user's message
await llm.emit_status('Displaying collected results')
for i, result in enumerate(results):
await llm.emit_message(f"\nResult {i}: {result}\n")
"""
3.3. Public/Streamed LLM completions
You can decide to stream responses from the downstream LLM
as they are being generated, for example when there's a long
chunk that needs to be retained in the global response.
"""
await llm.emit_status('Response streaming examples')
# Same signatures as chat_completion
streamed_results = [
# You can retrieve completion for some plain text
await llm.stream_chat_completion(prompt="Hi!"),
# You can include key/value pairs to be formatted in the prompt
await llm.stream_chat_completion(
prompt="Tell me about {word} in ONE SHORT SENTENCE.",
word=word,
),
# You can also provide a list of messages
# in the OpenAI-compatible format
await llm.stream_chat_completion(
messages=[
{
"role": "user",
"content": "Tell me about roses"
}, {
"role": "assistant",
"content": "Sure, I can reply in three words! Here they are:"
}
],
),
# You can also provide a chat instance
await llm.stream_chat_completion(chat=life_chat)
]
# Streamed results are still buffered and available
# for you to use (plain text).
logger.debug(f"Streamed results: {streamed_results}")
# Note that it's on you to apply formatting that will make
# sense in the context of the global message stream.
await llm.emit_message("\nThose are all results so far.\n")
"""
4. Final completion
Note that none of the above will actually reach the Client
if the BOOST_INTERMEDIATE_OUTPUT is set to "false".
The "final" completion below, however, will *always* be streamed back.
It accepts all the same inputs as "chat_completion" and "stream_chat_completion" above.
You don't have to call it, but the output will be completely empty if the
"final" completion is not called and intermediate outputs are disabled.
Think of this as a way to wrap up the module execution and
present the user with the final result.
"""
await llm.emit_status('Final completion')
await llm.stream_final_completion(prompt="Wish me a good luck!")
````