{
"metadata" : {
"config" : {
"dependencies" : {
"scala" : [
"be.botkop:numsca_2.12:0.1.5"
]
},
"exclusions" : [
],
"repositories" : [
],
"sparkConfig" : {
},
"env" : {
"OMP_NUM_THREADS" : "1"
}
},
"language_info" : {
"name" : "scala"
}
},
"nbformat" : 4,
"nbformat_minor" : 0,
"cells" : [
{
"cell_type" : "markdown",
"execution_count" : 0,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"# Neural networks from scratch in Scala!\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 1,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
" \n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 2,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"This PolyNotebook explains how to implement a simple neural network in Scala.\n",
"\n",
"\n",
"PolyNote is the polyglot notebook from Netflix. Check it out at [https://polynote.org/](https://polynote.org/).\n",
"\n",
"\n",
"First some jargon.\n",
"\n",
"\n",
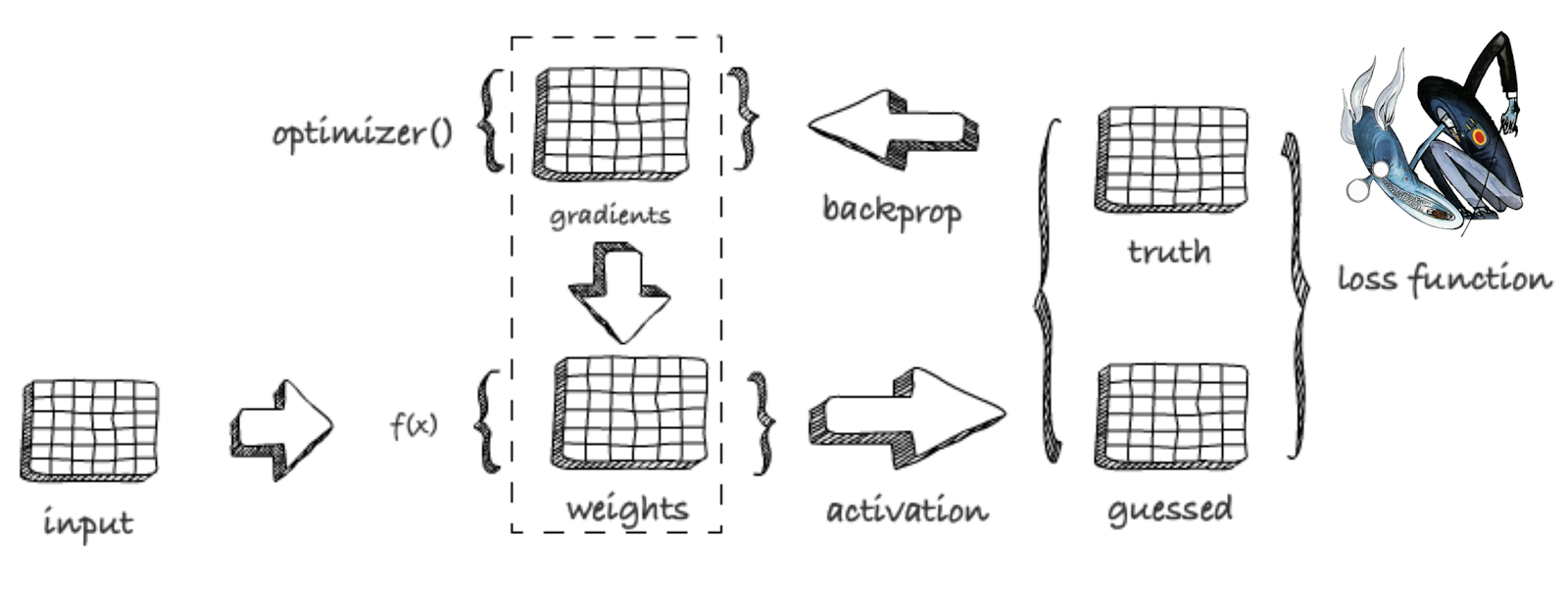
"In its simplest form, a neural net is a sequence of linear transformations (read matrix multiplications) glued together by **activation** functions. The task of the activation function is to introduce a non-linearity (such as setting the negative values to 0) between these transformations. The reason this works can be traced back to the Universal Approximation Theorem. The matrices are called **weights,** or **parameters.** The linear transformation together with the activation function is called a **layer**. Layers can be stacked together to form **modules**. The complete set of modules that compose the neural net is often called a **model**.\n",
"\n",
"\n",
"The neural net we'll be discussing is part of the supervised domain of machine learning. In supervised learning there is a learning, or **training** phase, and an **inference** phase.\n",
"\n",
"\n",
"In the training phase, a **dataloader** pushes **labeled** input in the form of a matrix (input) and a vector (expected outcome) to the model, where the multiplications and activations ensue. The dataloader is responsible for transforming the semantic units of both input (a picture of a cat) and output (the label 'cat') into resp. a matrix and a vector of numbers. Data is usually loaded in multiples (eg. 64 images, together with their labels). These multiples are called **minibatches**.\n",
"\n",
"\n",
"A **loss function** compares the prediction of the network on each sample with the ground truth, ie. the label. It notifies the network of the errors it made, in the form of **gradients,** by a process called **backpropagation**. Subsequently an **optimizer** uses the gradients to nudge the weights into the direction of the correct outcome, by subtracting a fraction of the gradients from the weights. This fraction is called the **learning rate**.\n",
"\n",
"\n",
"This is repeated on every minibatch of the training data set. A complete processing on the training set in this way is called an **epoch**. The model is trained as many epochs as needed, ie. until the loss is sufficiently low, and the accuracy (or another metric) is satisfactory. The **validation set** is a special part of the training set, that was set aside beforehand. It is not used as input for the training, but only to assess how well or how bad we are doing on data the model has never seen before. The loss and accuracy metrics are also computed on the validation set, and these are an important source for adjusting the **hyperparameters** of the model, such as the learning rate.\n",
"\n",
"\n",
"In the inference phase, we use the trained model to make predictions on unseen, unlabeled data. In this phase there is no loss, no backprop, and no optimizer. \n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 3,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"## Using a numerical library\n",
"\n",
"\n",
"In order to build anything similar to the above design, we need a numerical library. Numsca is a library for the Scala programming language, inspired by NumPy, with\n",
"\n",
"\n",
"* support for matrices and tensors (multi-dimensional arrays)\n",
"* a collection of high-level mathematical functions to operate on these tensors\n",
"* broadcasting and fancy indexing, just like NumPy.\n",
"\n",
"\n",
"Numsca can be found at [https://github.com/botkop/numsca](https://github.com/botkop/numsca)\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 4,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866251190,
"endTs" : 1612866251797
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"import botkop.{numsca => ns}\r\n",
"import ns.Tensor\r\n",
"import scala.language.implicitConversions"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 5,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"## Implementing Backpropagation\n",
"\n",
"\n",
" \n",
"\n",
"\n",
"The circuit diagram above shows a computation graph which allows to relate the value and gradient of the variables to the functions that produced them. In order to achieve this we will make 2 constructs that are defined in terms of each other: \n",
"\n",
"\n",
"* \n",
" a Variable, which is a wrapper around a tensor. It also stores the originating Function of this Variable, if any. For example, the function of Variable x will be None if `x = Variable(ns.zeros(3, 3,))`, but will be `Mul` if `x = a * b`, where a and b are also Variables.\n",
" \n",
" \n",
" \n",
"* \n",
" a Function, which has a `forward()` method that produces the standard result of a computation, and a `backward(g)` method where g is a tensor that represents the upstream gradient. The gradient is distributed among the composing Variables according to the rules of calculus, and passed on to the `backward(g)` methods of these Variables.\n",
" \n",
" \n",
" \n",
"\n",
"\n",
"### Variables & Functions\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 6,
"metadata" : {
"jupyter.outputs_hidden" : true,
"cell.metadata.exec_info" : {
"startTs" : 1612866262487,
"endTs" : 1612866264354
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"/**\r\n",
" * Wrapper around a tensor.\r\n",
" * Keeps track of the computation graph by storing the originating function of this variable, if any.\r\n",
" * The function will be None if the variable is the result of simple wrapping around a tensor.\r\n",
" * If the variable is the result of a computation, then f will be set to the function behind this computation.\r\n",
" * For example, f will be None if x = Variable(ns.zeros(3, 3,)), but f will be Mul if x = a * b,\r\n",
" * where a and b are also Variables.\r\n",
" *\r\n",
" * @param data the tensor\r\n",
" * @param f function that produced this variable, if any.\r\n",
" */\r\n",
"case class Variable(data: Tensor, f: Option[Function] = None) {\r\n",
"\r\n",
" /* the local gradient */\r\n",
" lazy val g: Tensor = ns.zerosLike(data)\r\n",
"\r\n",
" /**\r\n",
" * Accumulates the incoming gradient in the local gradient.\r\n",
" * Pushes the incoming gradient back through the network,\r\n",
" * by means of the originating function, if any.\r\n",
" * The gradient defaults to 1, as per the Calculus definition.\r\n",
" * @param gradOutput the gradient that is being pushed back through the network\r\n",
" */\r\n",
" def backward(gradOutput: Tensor = ns.ones(data.shape)): Unit = {\r\n",
" // gradients may have been broadcasted\r\n",
" // squash the dimensions to fit the original shape\r\n",
" val ug = unbroadcast(gradOutput)\r\n",
"\r\n",
" // Gradients add up at forks.\r\n",
" // If the forward expression involves the variables x,y multiple times,\r\n",
" // then when we perform backpropagation we must be careful to use += instead of =\r\n",
" // to accumulate the gradient on these variables (otherwise we would overwrite it).\r\n",
" // This follows the multivariable chain rule in Calculus,\r\n",
" // which states that if a variable branches out to different parts of the circuit,\r\n",
" // then the gradients that flow back to it will add.\r\n",
" // http://cs231n.github.io/optimization-2/#staged\r\n",
" g += ug\r\n",
"\r\n",
" // backprop thru the function that generated this variable, if any\r\n",
" for (gf <- f) gf.backward(ug)\r\n",
" }\r\n",
"\r\n",
" def +(other: Variable): Variable = Add(this, other).forward()\r\n",
" def *(other: Variable): Variable = Mul(this, other).forward()\r\n",
" def dot(other: Variable): Variable = Dot(this, other).forward()\r\n",
" def t(): Variable = Transpose(this).forward()\r\n",
"\r\n",
" // chain operator, allows to attach variables to functions without using call syntax\r\n",
" def ~>(f: Variable => Variable): Variable = f(this)\r\n",
" def shape: List[Int] = data.shape.toList\r\n",
"\r\n",
" def unbroadcast(t: Tensor): Tensor =\r\n",
" if (t.shape.sameElements(data.shape)) t\r\n",
" else data.shape.zip(t.shape).zipWithIndex.foldLeft(t) {\r\n",
" case (d: Tensor, ((oi, ni), i)) if oi == ni => \r\n",
" d\r\n",
" case (d: Tensor, ((oi, ni), i)) if oi == 1 => \r\n",
" ns.sum(d, axis = i)\r\n",
" case _ =>\r\n",
" throw new Exception(\r\n",
" s\"unable to reduce broadcasted shape ${t.shape.toList} as ${data.shape.toList}\")\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"object Variable {\r\n",
" // turn a sequence of numbers directly into a Variable\r\n",
" def apply(ds: Double*): Variable = Variable(Tensor(ds:_*))\r\n",
"}\r\n",
"\r\n",
"/**\r\n",
" * The Function is the 2nd required component in keeping track of a computation graph.\r\n",
" * It defines 2 methods: \r\n",
" * forward(): produces the traditional result of a computation\r\n",
" * backward(g): takes a gradient and distributes it to the composing \r\n",
" * Variables of the Function by calling their backward(g) method.\r\n",
" */\r\n",
"trait Function {\r\n",
" def forward(): Variable\r\n",
" def backward(g: Tensor): Unit\r\n",
"}\r\n",
"\r\n",
"/* Elementwise addition of 2 tensors */\r\n",
"case class Add(v1: Variable, v2: Variable) extends Function {\r\n",
" def forward(): Variable = Variable(v1.data + v2.data, f = Some(this))\r\n",
" /* The Add function distributes its gradient equally to all the inputs */\r\n",
" def backward(g: Tensor): Unit = {\r\n",
" v1.backward(g)\r\n",
" v2.backward(g)\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"/* Elementwise multiplication of 2 tensors */\r\n",
"case class Mul(v1: Variable, v2: Variable) extends Function {\r\n",
" override def forward(): Variable = Variable(v1.data * v2.data, f = Some(this))\r\n",
" /* The Mul function swaps the input activations, and multiplies them with the gradient */\r\n",
" override def backward(g: Tensor): Unit = {\r\n",
" val dv2 = v2.data * g\r\n",
" val dv1 = v1.data * g\r\n",
" v1.backward(dv2)\r\n",
" v2.backward(dv1)\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"/* Dot product of 2 tensors */\r\n",
"case class Dot(v1: Variable, v2: Variable) extends Function {\r\n",
" val w: Tensor = v1.data\r\n",
" val x: Tensor = v2.data\r\n",
" override def forward(): Variable = Variable(w dot x, f = Some(this))\r\n",
" override def backward(g: Tensor): Unit = {\r\n",
" val dw = g dot x.T\r\n",
" val dx = w.T dot g\r\n",
" v1.backward(dw)\r\n",
" v2.backward(dx)\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"/* Transpose a tensor */\r\n",
"case class Transpose(v: Variable) extends Function {\r\n",
" override def forward(): Variable = Variable(v.data.transpose, Some(this))\r\n",
" override def backward(gradOutput: Tensor): Unit =\r\n",
" v.backward(gradOutput.transpose)\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 7,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Activation\n",
"\n",
"\n",
"Activation functions are element-wise functions that introduce a non-linearity in the network. RELU is the most commonly used activation. In the forward pass, it simply sets all negative values in a tensor equal to zero. In the backward pass, it routes the gradient to the input higher than 0.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 8,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866271086,
"endTs" : 1612866271362
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"case class Threshold(x: Variable, d: Double) extends Function {\n",
" override def forward(): Variable = Variable(ns.maximum(x.data, d), Some(this))\n",
" override def backward(gradOutput: Tensor): Unit = {\n",
" x.backward(gradOutput * (x.data > d))\n",
" }\n",
"}\n",
"\n",
"def relu(x: Variable): Variable = Threshold(x, 0.0).forward()"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 9,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Module\n",
"\n",
"\n",
"A module is a wrapper around a set of Variables, here called parameters because they constitute the layers of a network. When layers are stacked on top of each other, the encompassing module allows to dynamically pull up the parameters of its layers. This can be done by calling the `parameters` method. In the same way the gradients of all the layers can be pulled up through method `gradients`. The `zeroGrad` method allows to set all gradients of the parameters equal to 0. The Module behaves like a Function through the abstract methods `forward()` and `apply() `.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 10,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866276001,
"endTs" : 1612866276434
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"abstract class Module(localParameters: Seq[Variable] = Nil) {\r\n",
" // by default, obtain submodules through introspection\r\n",
" lazy val subModules: Seq[Module] =\r\n",
" this.getClass.getDeclaredFields.flatMap { f =>\r\n",
" f setAccessible true\r\n",
" f.get(this) match {\r\n",
" case module: Module => Some(module)\r\n",
" case _ => None\r\n",
" }\r\n",
" }\r\n",
"\r\n",
" def parameters: Seq[Variable] = localParameters ++ subModules.flatMap(_.parameters)\r\n",
" def gradients: Seq[Tensor] = parameters.map(_.g)\r\n",
" def zeroGrad(): Unit = parameters.foreach(p => p.g := 0)\r\n",
"\r\n",
" def forward(x: Variable): Variable\r\n",
" def apply(x: Variable): Variable = forward(x)\r\n",
"}\r\n",
"\r\n",
"/* extend module to act like a Function/Variable */\r\n",
"implicit def moduleApply[T <: Module](m: T): (Variable) => Variable = m.forward"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 11,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"#### Linear Module\n",
"\n",
"\n",
"Applies a linear transformation (dot product) to its input.\n",
"\n",
" \n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 12,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866283367,
"endTs" : 1612866283638
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"case class Linear(weights: Variable, bias: Variable)\r\n",
" extends Module(Seq(weights, bias)) {\r\n",
" override def forward(x: Variable): Variable = {\r\n",
" (x dot weights.t()) + bias\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"object Linear {\r\n",
" def apply(inFeatures: Int, outFeatures: Int): Linear = {\r\n",
" /* He initialization */\r\n",
" val w = ns.randn(outFeatures, inFeatures) * math.sqrt(2.0 / (inFeatures + outFeatures))\r\n",
" val weights = Variable(w)\r\n",
" val b = ns.zeros(1, outFeatures)\r\n",
" val bias = Variable(b)\r\n",
" Linear(weights, bias)\r\n",
" }\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 13,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Optimizer\n",
"\n",
"The task of an Optimizer is to nudge the parameters into the direction of the expected outcome of the model. At each step (epoch) it will be called to perform a function on the parameters, using their gradients, in order to achieve this. The Optimizer also provides a method to reset the gradients to 0, which should be called after each update of the parameters.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 14,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866289517,
"endTs" : 1612866289662
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"abstract class Optimizer(parameters: Seq[Variable]) {\r\n",
" def step(epoch: Int)\r\n",
" def zeroGrad(): Unit = parameters.foreach(p => p.g := 0)\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 15,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"#### Stochastic Gradient Descent\n",
"\n",
"SGD is a type of Optimizer, that implements a simple yet very efficient approach to discriminative learning of a linear classifier. It subtracts a fraction of the gradient of a parameter from the parameter itself. This fraction is called the learning rate.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 16,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866293382,
"endTs" : 1612866293671
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"case class SGD(parameters: Seq[Variable], learningRate: Double) extends Optimizer(parameters) {\r\n",
" override def step(epoch: Int): Unit =\r\n",
" parameters.foreach { p =>\r\n",
" p.data -= learningRate * p.g\r\n",
" } \r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 17,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Softmax Loss function\n",
"\n",
"\n",
"The loss function quantifies our unhappiness with the score of the network. It measures the error between the predicted and the expected value. Intuitively, the loss will be high if we’re doing a poor job of classifying the training data, and it will be low if we’re doing well.\n",
"\n",
"\n",
"The goal of the network is to find parameters that minimize the loss over all samples. \n",
"\n",
"\n",
"For a classification task, SoftMax Loss is often used used. It is a combination of a Softmax activation and a Cross Entropy Loss function. Usually they are combined into one function.\n",
"\n",
"\n",
"Softmax squashes the raw class scores into normalized positive values that sum to one. See also [http://neuralnetworksanddeeplearning.com/chap3.html#softmax](http://neuralnetworksanddeeplearning.com/chap3.html#softmax)\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 18,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866298526,
"endTs" : 1612866299401
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"case class SoftmaxLoss(actual: Variable, target: Variable) extends Function {\r\n",
" val x: Tensor = actual.data\r\n",
" val y: Tensor = target.data.T\r\n",
"\r\n",
" val shiftedLogits: Tensor = x - ns.max(x, axis = 1)\r\n",
" val z: Tensor = ns.sum(ns.exp(shiftedLogits), axis = 1)\r\n",
" val logProbs: Tensor = shiftedLogits - ns.log(z)\r\n",
" val n: Int = x.shape.head\r\n",
" val loss: Double = -ns.sum(logProbs(ns.arange(n), y)) / n\r\n",
"\r\n",
" override def forward(): Variable = Variable(Tensor(loss), Some(this))\r\n",
"\r\n",
" override def backward(gradOutput: Tensor /* not used */ ): Unit = {\r\n",
" val dx = ns.exp(logProbs)\r\n",
" dx(ns.arange(n), y) -= 1\r\n",
" dx /= n\r\n",
"\r\n",
" actual.backward(dx)\r\n",
" }\r\n",
"}\r\n",
"\r\n",
"type LossFunction = (Variable, Variable) => Variable\r\n",
"\r\n",
"val softmaxLoss: LossFunction = (yHat: Variable, y: Variable) => SoftmaxLoss(yHat, y).forward"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 19,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Data Loader\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 20,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866309794,
"endTs" : 1612866309939
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"trait DataLoader extends Iterable[(Variable, Variable)] {\r\n",
" def numSamples: Int\r\n",
" def numBatches: Int\r\n",
" def mode: String\r\n",
" def iterator: Iterator[(Variable, Variable)]\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 21,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"#### Fashion MNIST data loader\n",
"\n",
"\n",
"This dataloader reads the Fashion MNIST dataset from Zalando: [https://github.com/zalandoresearch/fashion-mnist](https://github.com/zalandoresearch/fashion-mnist). The dataset in CSV format can be downloaded from Kaggle : [https://www.kaggle.com/zalando-research/fashionmnist](https://www.kaggle.com/zalando-research/fashionmnist). In the cell below, I have defined a variable `baseFolder` which points to the download folder. Note that I also assume that the files have been gzipped.\n",
"\n",
"Each line in the file represents an image and its label. There are 10 classes: t-shirt, trousers, pullover, dress, coat, sandal, shirt, sneaker, bag and ankle boot. It is a dataset with 60K training images and 10K validation images.\n",
"\n",
"\n",
" \n",
"\n",
"\n",
"Each image consists of 28x28 grayscale pixels. The values of the pixels in the files are all integers between 0 and 255.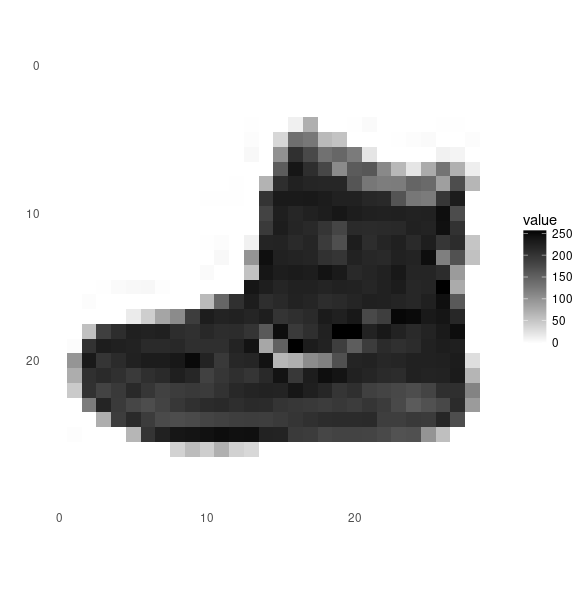\n",
"\n",
"\n",
"The dataloader turns the values into floats between 0 and 1 by dividing the values for the pixels by 255.0. It also applies zero centering: subtract the mean across every individual feature in the data. The geometric interpretation for this is to center the data around the origin along every dimension.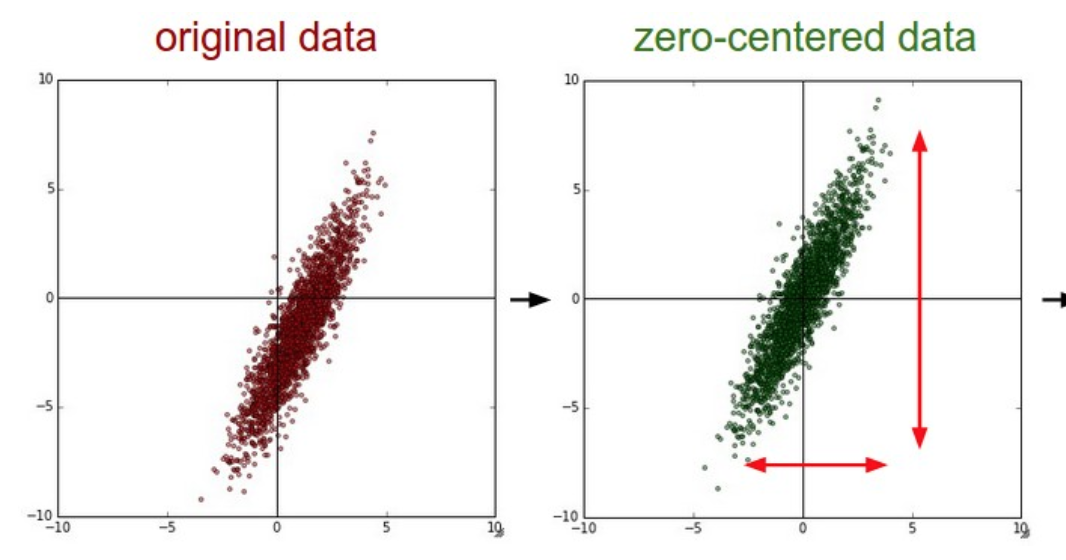\n",
"\n",
"\n",
"Caveat: when zero-centering test data, the mean of the training data must be subtracted from the test data.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 22,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866316137,
"endTs" : 1612866316985
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"import scala.io.Source\r\n",
"import scala.language.postfixOps\r\n",
"import scala.util.Random\r\n",
"import java.util.zip.GZIPInputStream\r\n",
"import java.io._\r\n",
"\r\n",
"val baseFolder =\"dl-from-scratch-polynb/data/fashionmnist\"\r\n",
"\r\n",
"class FashionMnistDataLoader(val mode: String,\r\n",
" miniBatchSize: Int,\r\n",
" take: Option[Int] = None,\r\n",
" seed: Long = 231)\r\n",
" extends DataLoader {\r\n",
"\r\n",
" Random.setSeed(seed)\r\n",
"\r\n",
" val file: String = mode match {\r\n",
" case \"train\" => s\"$baseFolder/fashion-mnist_train.csv.gz\"\r\n",
" case \"valid\" => s\"$baseFolder/fashion-mnist_test.csv.gz\"\r\n",
" }\r\n",
"\r\n",
" def gis(f: String) = Source.fromInputStream(\r\n",
" new GZIPInputStream(new BufferedInputStream(new FileInputStream(f))))\r\n",
"\r\n",
" val lines: List[String] = {\r\n",
" val src = gis(file)\r\n",
" val lines = src.getLines().toList\r\n",
" src.close()\r\n",
" Random.shuffle(lines.tail) // skip header\r\n",
" }\r\n",
"\r\n",
" val numFeatures = 784\r\n",
" val numEntries: Int = lines.length\r\n",
"\r\n",
" val numSamples: Int = take match {\r\n",
" case Some(n) => math.min(n, numEntries)\r\n",
" case None => numEntries\r\n",
" }\r\n",
"\r\n",
" val numBatches: Int =\r\n",
" (numSamples / miniBatchSize) +\r\n",
" (if (numSamples % miniBatchSize == 0) 0 else 1)\r\n",
"\r\n",
" val data: Seq[(Variable, Variable)] = lines\r\n",
" .take(take.getOrElse(numSamples))\r\n",
" .sliding(miniBatchSize, miniBatchSize)\r\n",
" .map { lines =>\r\n",
" val batchSize = lines.length\r\n",
"\r\n",
" val xs = Array.fill[Float](numFeatures * batchSize)(elem = 0)\r\n",
" val ys = Array.fill[Float](batchSize)(elem = 0)\r\n",
"\r\n",
" lines.zipWithIndex.foreach {\r\n",
" case (line, lnr) =>\r\n",
" val tokens = line.split(\",\")\r\n",
" ys(lnr) = tokens.head.toFloat\r\n",
" tokens.tail.zipWithIndex.foreach {\r\n",
" case (sx, i) =>\r\n",
" xs(lnr * numFeatures + i) = sx.toFloat / 255.0f\r\n",
" }\r\n",
" }\r\n",
"\r\n",
" val x = Variable(Tensor(xs).reshape(batchSize, numFeatures))\r\n",
" val y = Variable(Tensor(ys).reshape(batchSize, 1))\r\n",
" (x, y)\r\n",
" }\r\n",
" .toSeq\r\n",
"\r\n",
" lazy val meanImage: Tensor = {\r\n",
" val m = ns.zeros(1, numFeatures)\r\n",
" data.foreach {\r\n",
" case (x, _) =>\r\n",
" m += ns.sum(x.data, axis = 0)\r\n",
" }\r\n",
" m /= numSamples\r\n",
" m\r\n",
" }\r\n",
"\r\n",
" if (mode == \"train\") zeroCenter(meanImage)\r\n",
"\r\n",
" def zeroCenter(meanImage: Tensor): Unit = {\r\n",
" val bcm = broadcastTo(meanImage, miniBatchSize, numFeatures)\r\n",
"\r\n",
" data.foreach {\r\n",
" case (x, _) =>\r\n",
" if (x.data.shape.head == miniBatchSize)\r\n",
" x.data -= bcm\r\n",
" else\r\n",
" x.data -= meanImage\r\n",
" }\r\n",
" }\r\n",
"\r\n",
" def iterator: Iterator[(Variable, Variable)] =\r\n",
" Random.shuffle(data.toIterator)\r\n",
"\r\n",
" def broadcastTo(t: Tensor, shape: Int*): Tensor =\r\n",
" new Tensor(t.array.broadcast(shape: _*))\r\n",
"\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 23,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Evaluator\n",
"\n",
"\n",
"After each epoch we want to evaluate the model, so that we can follow how good or how bad it is doing.\n",
"\n",
"\n",
"The metrics we're computing in the evaluator below are the loss (which we want to be low) and the accuracy (which we want to be high). We will collect the metrics of all minibatches of the training and validation data set. This will allow us to visualize the performance of the model.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 24,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866323494,
"endTs" : 1612866323871
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"trait Evaluator {\r\n",
" def evaluate(epoch: Int, startTime: Long, endTime: Long, net: Module, loss: LossFunction): Unit\r\n",
"}\r\n",
"\r\n",
"case class MetricsCollector(trainDataLoader: DataLoader,\r\n",
" validDataLoader: DataLoader,\r\n",
" loss: LossFunction) extends Evaluator {\r\n",
" import scala.collection.mutable.ArrayBuffer\r\n",
" val trnLossMetrics = ArrayBuffer[Float]()\r\n",
" val valLossMetrics = ArrayBuffer[Float]()\r\n",
" val trnAccuracyMetrics = ArrayBuffer[Float]()\r\n",
" val valAccuracyMetrics = ArrayBuffer[Float]()\r\n",
"\r\n",
" def metrics = (\r\n",
" trnLossMetrics.toArray,\r\n",
" valLossMetrics.toArray,\r\n",
" trnAccuracyMetrics.toArray,\r\n",
" valAccuracyMetrics.toArray)\r\n",
"\r\n",
" def evaluate(epoch: Int, t0: Long, t1: Long, net: Module, loss: LossFunction): Unit = {\r\n",
" val dur = (t1 - t0) / 1000000\r\n",
" val (ltrn, atrn) = evaluate(trainDataLoader, net, trnLossMetrics, trnAccuracyMetrics)\r\n",
" val (lval, aval) = evaluate(validDataLoader, net, valLossMetrics, valAccuracyMetrics)\r\n",
" println(\r\n",
" f\"epoch: $epoch%2d duration: $dur%4dms loss: $lval%1.4f / $ltrn%1.4f\\taccuracy: $aval%1.4f / $atrn%1.4f\")\r\n",
" }\r\n",
"\r\n",
" def evaluate(dl: DataLoader,\r\n",
" net: Module,\r\n",
" lossMetrics: ArrayBuffer[Float],\r\n",
" accuracyMetrics: ArrayBuffer[Float]): (Double, Double) = {\r\n",
" val (l, a) =\r\n",
" dl.foldLeft(0.0, 0.0) {\r\n",
" case ((lossAcc, accuracyAcc), (x, y)) =>\r\n",
" val output = net(x)\r\n",
" val guessed = ns.argmax(output.data, axis = 1)\r\n",
" val accuracy = ns.sum(guessed == y.data) / x.shape.head\r\n",
" val cost = loss(output, y).data.squeeze()\r\n",
" lossMetrics += cost.toFloat\r\n",
" accuracyMetrics += accuracy.toFloat\r\n",
" (lossAcc + cost, accuracyAcc + accuracy)\r\n",
" }\r\n",
" (l / dl.numBatches, a / dl.numBatches)\r\n",
" }\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 25,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Learner\n",
"\n",
"\n",
"Convenience class around the learning process. You provide it with the training datasets, the model layout to train, an optimizer, a loss function, and an evaluator.\n",
"\n",
"\n",
"The class provides a `fit` method, that will train the model for the required number of epochs.\n",
"\n",
"\n",
"For a given epoch, the `fit` method will loop through all the minibatches of the training set, and for each minibatch will perform the following operations:\n",
"\n",
"\n",
"* set the gradients of all parameters of the network to 0\n",
"* perform a forward pass on the input\n",
"* perform the loss function on the outcome of the forward pass\n",
"* perform the backward pass on the outcome of the loss function\n",
"* perform an optimization step\n",
"\n",
"\n",
"The model is evaluated after each epoch.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 26,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866328634,
"endTs" : 1612866328906
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"case class Learner(trainingDataLoader: DataLoader,\r\n",
" net: Module,\r\n",
" optimizer: Optimizer,\r\n",
" loss: LossFunction,\r\n",
" evaluator: Evaluator) {\r\n",
" var epochs = 0\r\n",
" def fit(numEpochs: Int): Unit = {\r\n",
" (0 until numEpochs) foreach { _ =>\r\n",
" val t0 = System.nanoTime()\r\n",
" trainingDataLoader.foreach { // for each mini batch\r\n",
" case (x, y) =>\r\n",
" optimizer.zeroGrad()\r\n",
" val yh = net(x)\r\n",
" val l = loss(yh, y)\r\n",
" l.backward()\r\n",
" optimizer.step(epochs) // update parameters using their gradient\r\n",
" }\r\n",
" val t1 = System.nanoTime()\r\n",
" evaluator.evaluate(epochs, t0, t1, net, loss)\r\n",
" epochs += 1\r\n",
" }\r\n",
" }\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 27,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Train a network\n",
"\n",
"\n",
"Create the data loaders for the training and validation data sets. Zero-center the validation set with the mean image of the training set. \n",
"\n",
"The instantiation of the dataloaders may take some time.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 28,
"metadata" : {
"jupyter.outputs_hidden" : true,
"cell.metadata.exec_info" : {
"startTs" : 1612866343169,
"endTs" : 1612866432956
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"val batchSize = 256\r\n",
"val trainDl = new FashionMnistDataLoader(\"train\", batchSize)\r\n",
"val validDl = new FashionMnistDataLoader(\"valid\", batchSize)\r\n",
"validDl.zeroCenter(trainDl.meanImage)"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 29,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"In the next cell we define the layout of our network: 2 linear transformations with a RELU activation in between. \n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 30,
"metadata" : {
"jupyter.outputs_hidden" : true,
"cell.metadata.exec_info" : {
"startTs" : 1612866456227,
"endTs" : 1612866456477
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"val nn: Module = new Module() {\r\n",
" val fc1 = Linear(784, 100)\r\n",
" val fc2 = Linear(100, 10)\r\n",
" override def forward(x: Variable): Variable = \r\n",
" x ~> fc1 ~> relu ~> fc2\r\n",
"}"
],
"outputs" : [
]
},
{
"cell_type" : "markdown",
"execution_count" : 31,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"Next, we define the optimizer for the given learning rate, and the number of epochs we want to train the model. Then start the training.\n",
"\n",
"\n",
"You should not expect state-of-the-art results with this simple network. It just proves that the model can learn.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 32,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866469534,
"endTs" : 1612866710871
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"val learningRate = .1\n",
"val sgd = SGD(nn.parameters, learningRate)\n",
"val eval = MetricsCollector(trainDl, validDl, softmaxLoss)\n",
"val learner = Learner(trainDl, nn, sgd, softmaxLoss, eval)"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 33,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866796973,
"endTs" : 1612866877953
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"val numEpochs = 10\n",
"learner.fit(numEpochs)"
],
"outputs" : [
{
"name" : "stdout",
"text" : [
"epoch: 0 duration: 5052ms loss: 0.5210 / 0.5223\taccuracy: 0.8193 / 0.8170\n",
"epoch: 1 duration: 4401ms loss: 0.4506 / 0.4510\taccuracy: 0.8443 / 0.8413\n",
"epoch: 2 duration: 4308ms loss: 0.4212 / 0.4174\taccuracy: 0.8530 / 0.8526\n",
"epoch: 3 duration: 4302ms loss: 0.4033 / 0.3985\taccuracy: 0.8590 / 0.8594\n",
"epoch: 4 duration: 4239ms loss: 0.3876 / 0.3803\taccuracy: 0.8642 / 0.8661\n",
"epoch: 5 duration: 4267ms loss: 0.3748 / 0.3663\taccuracy: 0.8665 / 0.8699\n",
"epoch: 6 duration: 4251ms loss: 0.3682 / 0.3557\taccuracy: 0.8669 / 0.8740\n",
"epoch: 7 duration: 4252ms loss: 0.3592 / 0.3458\taccuracy: 0.8706 / 0.8778\n",
"epoch: 8 duration: 4273ms loss: 0.3546 / 0.3392\taccuracy: 0.8714 / 0.8787\n",
"epoch: 9 duration: 4375ms loss: 0.3514 / 0.3310\taccuracy: 0.8740 / 0.8832\n"
],
"output_type" : "stream"
}
]
},
{
"cell_type" : "markdown",
"execution_count" : 34,
"metadata" : {
"language" : "text"
},
"language" : "text",
"source" : [
"### Visualize loss and accuracy\n",
"\n",
"\n",
"In the next cells we will make use of a unique feature of polynote, which, as its name suggests, provides the possibility to mix languages in the same notebook, and what is really interesting, to use variables created in one cell in another cell of a different language. We will prepare the Scala variables in the cell below, and then use them for visualization by matplotlib in the following Python cell.\n",
"\n",
"\n"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 35,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866882013,
"endTs" : 1612866882145
},
"language" : "scala"
},
"language" : "scala",
"source" : [
"val (tl, vl, ta, va) = eval.metrics"
],
"outputs" : [
]
},
{
"cell_type" : "code",
"execution_count" : 36,
"metadata" : {
"cell.metadata.exec_info" : {
"startTs" : 1612866883445,
"endTs" : 1612866884740
},
"language" : "python"
},
"language" : "python",
"source" : [
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"\n",
"plt.close()\n",
"\n",
"def plot_metrics(metrics, label):\n",
" fig, ax = plt.subplots()\n",
" ax.plot(metrics, 'b')\n",
" ax.set(xlabel='minibatch', ylabel=label, title=label)\n",
" ax.grid()\n",
" plt.plot(np.arange(len(metrics)), metrics)\n",
"\n",
"plot_metrics(tl, 'training loss')\n",
"plot_metrics(vl, 'validation loss')\n",
"plot_metrics(ta, 'training accuracy')\n",
"plot_metrics(va, 'validation accuracy')\n",
" \n",
"plt.show()\n"
],
"outputs" : [
{
"data" : {
"text/html" : [
"