 \n",
"\n",
"## The data\n",
"\n",
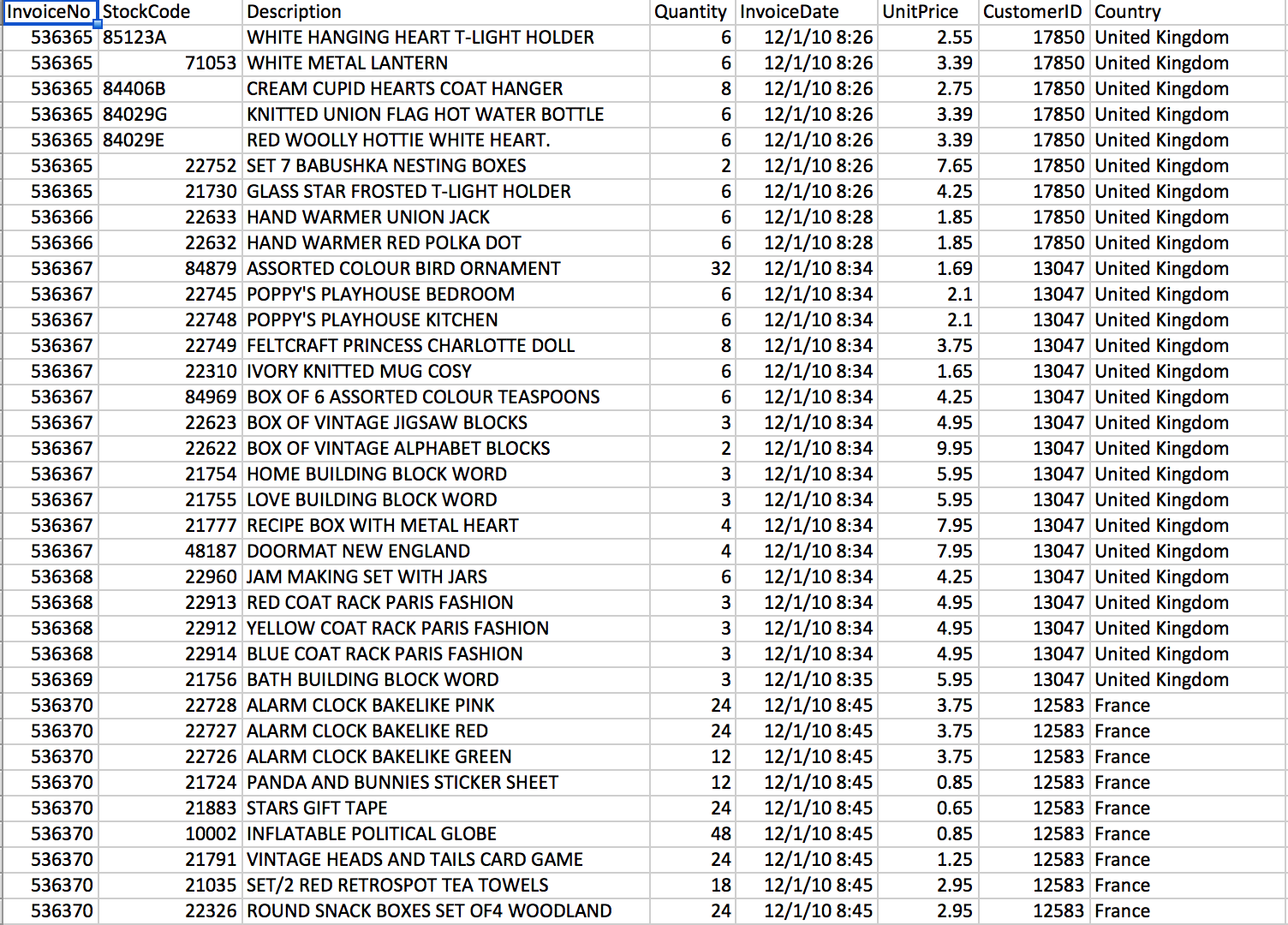
"This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. The company mainly sells unique all-occasion gifts. Many customers of the company are wholesalers.\n",
"\n",
"http://archive.ics.uci.edu/ml/datasets/Online+Retail\n",
"\n",
"
\n",
"\n",
"## The data\n",
"\n",
"This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. The company mainly sells unique all-occasion gifts. Many customers of the company are wholesalers.\n",
"\n",
"http://archive.ics.uci.edu/ml/datasets/Online+Retail\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Step 1 - Create an RDD from the CSV File \n",
"### 1.1 - Download the data"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false,
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"--2016-10-17 17:01:52-- https://raw.githubusercontent.com/rosswlewis/RecommendationPoT/master/OnlineRetail.csv.gz\n",
"Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.48.133\n",
"Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.48.133|:443... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 7483128 (7.1M) [application/octet-stream]\n",
"Saving to: 'OnlineRetail.csv.gz'\n",
"\n",
"100%[======================================>] 7,483,128 --.-K/s in 0.1s \n",
"\n",
"2016-10-17 17:01:54 (69.4 MB/s) - 'OnlineRetail.csv.gz' saved [7483128/7483128]\n",
"\n"
]
}
],
"source": [
"#Download the data from github to the local directory\n",
"!rm 'OnlineRetail.csv.gz' -f\n",
"!wget https://raw.githubusercontent.com/rosswlewis/RecommendationPoT/master/OnlineRetail.csv.gz"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
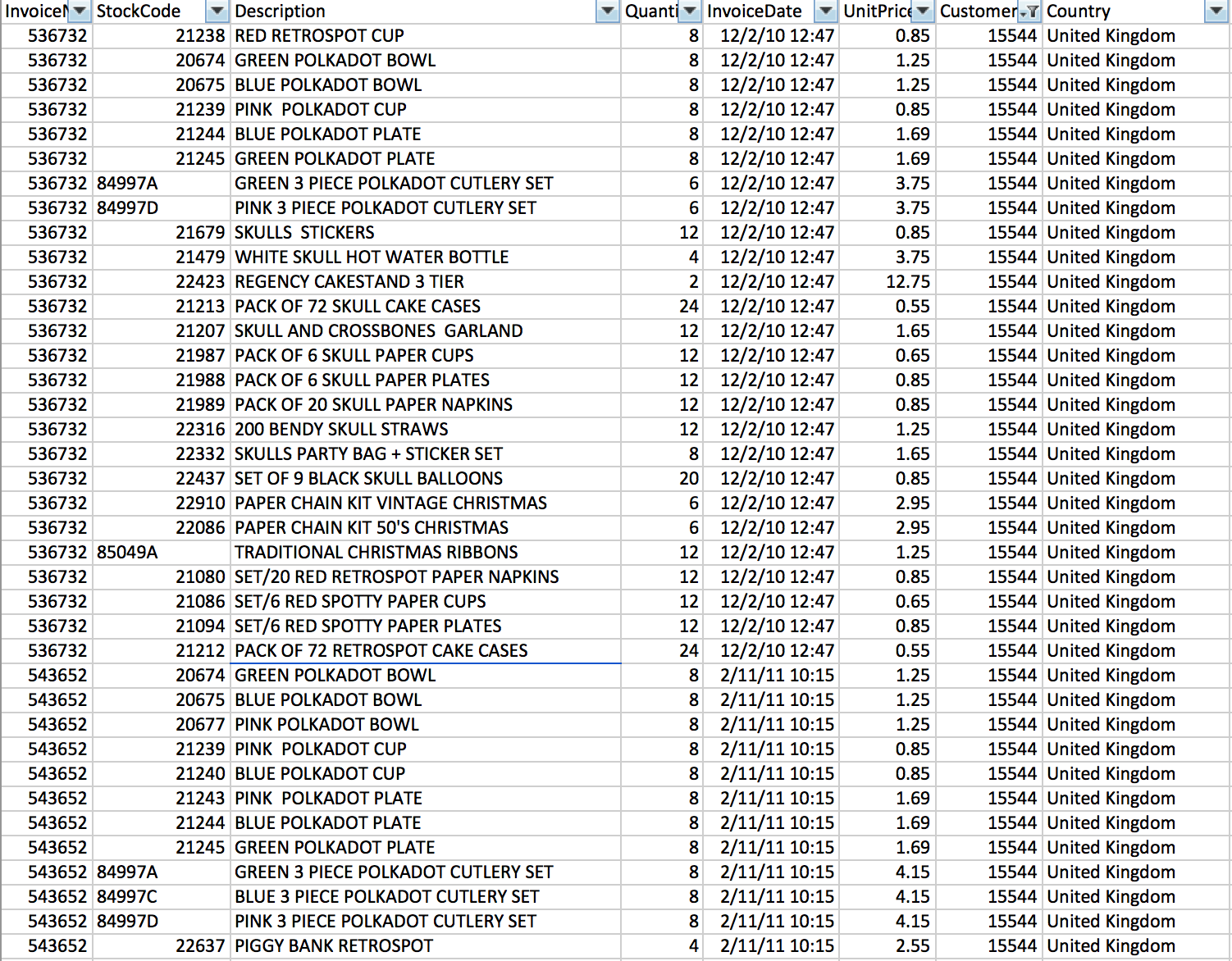
"### 1.2 - Put the csv into an RDD (at first, each row in the RDD is a string which correlates to a line in the csv) and show the first three lines.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Step 1 - Create an RDD from the CSV File \n",
"### 1.1 - Download the data"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false,
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"--2016-10-17 17:01:52-- https://raw.githubusercontent.com/rosswlewis/RecommendationPoT/master/OnlineRetail.csv.gz\n",
"Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.48.133\n",
"Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.48.133|:443... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 7483128 (7.1M) [application/octet-stream]\n",
"Saving to: 'OnlineRetail.csv.gz'\n",
"\n",
"100%[======================================>] 7,483,128 --.-K/s in 0.1s \n",
"\n",
"2016-10-17 17:01:54 (69.4 MB/s) - 'OnlineRetail.csv.gz' saved [7483128/7483128]\n",
"\n"
]
}
],
"source": [
"#Download the data from github to the local directory\n",
"!rm 'OnlineRetail.csv.gz' -f\n",
"!wget https://raw.githubusercontent.com/rosswlewis/RecommendationPoT/master/OnlineRetail.csv.gz"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.2 - Put the csv into an RDD (at first, each row in the RDD is a string which correlates to a line in the csv) and show the first three lines.\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"This user seems to have purchased a lot of childrens gifts and some holiday items. The recommendation engine we created suggested some items along these lines\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Citation\n",
"Daqing Chen, Sai Liang Sain, and Kun Guo, Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, Vol. 19, No. 3, pp. 197–208, 2012 (Published online before print: 27 August 2012. doi: 10.1057/dbm.2012.17)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2 with Spark 1.6",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.11"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"This user seems to have purchased a lot of childrens gifts and some holiday items. The recommendation engine we created suggested some items along these lines\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Citation\n",
"Daqing Chen, Sai Liang Sain, and Kun Guo, Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, Vol. 19, No. 3, pp. 197–208, 2012 (Published online before print: 27 August 2012. doi: 10.1057/dbm.2012.17)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2 with Spark 1.6",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.11"
}
},
"nbformat": 4,
"nbformat_minor": 0
}