 \n",
"\n",
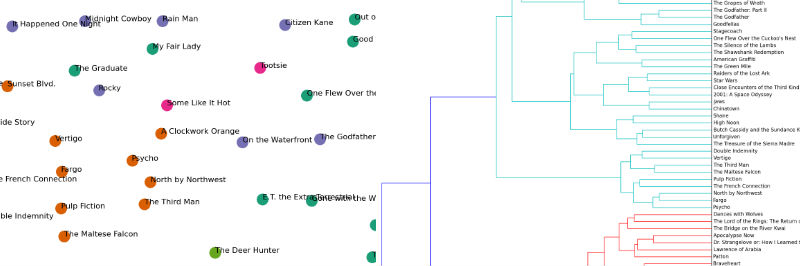
"In this guide, I will explain how to cluster a set of documents using Python. My motivating example is to identify the latent structures within the synopses of the top 100 films of all time (per an IMDB list). See [the original post](http://www.brandonrose.org/top100) for a more detailed discussion on the example. This guide covers:\n",
"\n",
"
\n",
"\n",
"In this guide, I will explain how to cluster a set of documents using Python. My motivating example is to identify the latent structures within the synopses of the top 100 films of all time (per an IMDB list). See [the original post](http://www.brandonrose.org/top100) for a more detailed discussion on the example. This guide covers:\n",
"\n",
"" ] }, { "cell_type": "heading", "level": 1, "metadata": {}, "source": [ "Latent Dirichlet Allocation" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "This section focuses on using [Latent Dirichlet Allocation (LDA)](http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation) to learn yet more about the hidden structure within the top 100 film synopses. LDA is a probabilistic topic model that assumes documents are a mixture of topics and that each word in the document is attributable to the document's topics. There is quite a good high-level overview of probabilistic topic models by one of the big names in the field, David Blei, available in the [Communications of the ACM here](http://delivery.acm.org/10.1145/2140000/2133826/p77-blei.pdf?ip=68.48.185.120&id=2133826&acc=OPEN&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E6D218144511F3437&CFID=612398453&CFTOKEN=48760790&__acm__=1419436704_2d47aefe0700e44f81eb822df659a341). Incidentally, Blei was one of the authors of the seminal paper on LDA.\n", "\n", "For my implementaiton of LDA, I use the [Gensim pacakage](https://radimrehurek.com/gensim/). I'm going to preprocess the synopses a bit differently here, and first I define a function to remove any proper noun." ] }, { "cell_type": "code", "collapsed": false, "input": [ "#strip any proper names from a text...unfortunately right now this is yanking the first word from a sentence too.\n", "import string\n", "def strip_proppers(text):\n", " # first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token\n", " tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent) if word.islower()]\n", " return \"\".join([\" \"+i if not i.startswith(\"'\") and i not in string.punctuation else i for i in tokens]).strip()" ], "language": "python", "metadata": {}, "outputs": [], "prompt_number": 82 }, { "cell_type": "markdown", "metadata": {}, "source": [ "Since the above function is just based on capitalization, it is prone to remove words at the beginning of sentences. So, I wrote the below function using NLTK's part of speech tagger. However, it took way too long to run across all synopses, so I stuck with the above." ] }, { "cell_type": "code", "collapsed": false, "input": [ "#strip any proper nouns (NNP) or plural proper nouns (NNPS) from a text\n", "from nltk.tag import pos_tag\n", "\n", "def strip_proppers_POS(text):\n", " tagged = pos_tag(text.split()) #use NLTK's part of speech tagger\n", " non_propernouns = [word for word,pos in tagged if pos != 'NNP' and pos != 'NNPS']\n", " return non_propernouns" ], "language": "python", "metadata": {}, "outputs": [], "prompt_number": 80 }, { "cell_type": "markdown", "metadata": {}, "source": [ "Here I run the actual text processing (removing of proper nouns, tokenization, removal of stop words)" ] }, { "cell_type": "code", "collapsed": false, "input": [ "from gensim import corpora, models, similarities \n", "\n", "#remove proper names\n", "%time preprocess = [strip_proppers(doc) for doc in synopses]\n", "\n", "#tokenize\n", "%time tokenized_text = [tokenize_and_stem(text) for text in preprocess]\n", "\n", "#remove stop words\n", "%time texts = [[word for word in text if word not in stopwords] for text in tokenized_text]" ], "language": "python", "metadata": {}, "outputs": [ { "output_type": "stream", "stream": "stdout", "text": [ "CPU times: user 12.9 s, sys: 148 ms, total: 13 s\n", "Wall time: 15.9 s\n", "CPU times: user 15.1 s, sys: 172 ms, total: 15.3 s" ] }, { "output_type": "stream", "stream": "stdout", "text": [ "\n", "Wall time: 19.3 s\n", "CPU times: user 4.56 s, sys: 39.2 ms, total: 4.6 s" ] }, { "output_type": "stream", "stream": "stdout", "text": [ "\n", "Wall time: 5.95 s\n" ] } ], "prompt_number": 83 }, { "cell_type": "markdown", "metadata": {}, "source": [ "Below are some Gensim specific conversions; I also filter out extreme words (see inline comment)" ] }, { "cell_type": "code", "collapsed": false, "input": [ "#create a Gensim dictionary from the texts\n", "dictionary = corpora.Dictionary(texts)\n", "\n", "#remove extremes (similar to the min/max df step used when creating the tf-idf matrix)\n", "dictionary.filter_extremes(no_below=1, no_above=0.8)\n", "\n", "#convert the dictionary to a bag of words corpus for reference\n", "corpus = [dictionary.doc2bow(text) for text in texts]" ], "language": "python", "metadata": {}, "outputs": [], "prompt_number": 84 }, { "cell_type": "markdown", "metadata": {}, "source": [ "The actual model runs below. I took 100 passes to ensure convergence, but you can see that it took my machine 13 minutes to run. My chunksize is larger than the corpus so basically all synopses are used per pass. I should optimize this, and Gensim has the capacity to run in parallel. I'll likely explore this further as I use the implementation on larger corpora." ] }, { "cell_type": "code", "collapsed": false, "input": [ "%time lda = models.LdaModel(corpus, num_topics=5, \n", " id2word=dictionary, \n", " update_every=5, \n", " chunksize=10000, \n", " passes=100)" ], "language": "python", "metadata": {}, "outputs": [ { "output_type": "stream", "stream": "stdout", "text": [ "CPU times: user 9min 53s, sys: 5.87 s, total: 9min 59s\n", "Wall time: 13min 1s\n" ] } ], "prompt_number": 85 }, { "cell_type": "markdown", "metadata": {}, "source": [ "Each topic has a set of words that defines it, along with a certain probability." ] }, { "cell_type": "code", "collapsed": false, "input": [ "lda.show_topics()" ], "language": "python", "metadata": {}, "outputs": [ { "metadata": {}, "output_type": "pyout", "prompt_number": 87, "text": [ "[u'0.006*men + 0.005*kill + 0.004*soldier + 0.004*order + 0.004*patient + 0.004*night + 0.003*priest + 0.003*becom + 0.003*new + 0.003*speech',\n", " u\"0.006*n't + 0.005*go + 0.005*fight + 0.004*doe + 0.004*home + 0.004*famili + 0.004*car + 0.004*night + 0.004*say + 0.004*next\",\n", " u\"0.005*ask + 0.005*meet + 0.005*kill + 0.004*say + 0.004*friend + 0.004*car + 0.004*love + 0.004*famili + 0.004*arriv + 0.004*n't\",\n", " u'0.009*kill + 0.006*soldier + 0.005*order + 0.005*men + 0.005*shark + 0.004*attempt + 0.004*offic + 0.004*son + 0.004*command + 0.004*attack',\n", " u'0.004*kill + 0.004*water + 0.004*two + 0.003*plan + 0.003*away + 0.003*set + 0.003*boat + 0.003*vote + 0.003*way + 0.003*home']" ] } ], "prompt_number": 87 }, { "cell_type": "markdown", "metadata": {}, "source": [ "Here, I convert the topics into just a list of the top 20 words in each topic. You can see a similar breakdown of topics as I identified using k-means including a war/family topic and a more clearly war/epic topic." ] }, { "cell_type": "code", "collapsed": false, "input": [ "topics_matrix = lda.show_topics(formatted=False, num_words=20)\n", "topics_matrix = np.array(topics_matrix)\n", "\n", "topic_words = topics_matrix[:,:,1]\n", "for i in topic_words:\n", " print([str(word) for word in i])\n", " print()" ], "language": "python", "metadata": {}, "outputs": [ { "output_type": "stream", "stream": "stdout", "text": [ "['men', 'kill', 'soldier', 'order', 'patient', 'night', 'priest', 'becom', 'new', 'speech', 'friend', 'decid', 'young', 'ward', 'state', 'front', 'would', 'home', 'two', 'father']\n", "\n", "[\"n't\", 'go', 'fight', 'doe', 'home', 'famili', 'car', 'night', 'say', 'next', 'ask', 'day', 'want', 'show', 'goe', 'friend', 'two', 'polic', 'name', 'meet']\n", "\n", "['ask', 'meet', 'kill', 'say', 'friend', 'car', 'love', 'famili', 'arriv', \"n't\", 'home', 'two', 'go', 'father', 'money', 'call', 'polic', 'apart', 'night', 'hous']\n", "\n", "['kill', 'soldier', 'order', 'men', 'shark', 'attempt', 'offic', 'son', 'command', 'attack', 'water', 'friend', 'ask', 'fire', 'arriv', 'wound', 'die', 'battl', 'death', 'fight']\n", "\n", "['kill', 'water', 'two', 'plan', 'away', 'set', 'boat', 'vote', 'way', 'home', 'run', 'ship', 'would', 'destroy', 'guilti', 'first', 'attack', 'go', 'use', 'forc']\n", "\n" ] } ], "prompt_number": 86 } ], "metadata": {} } ] }