---
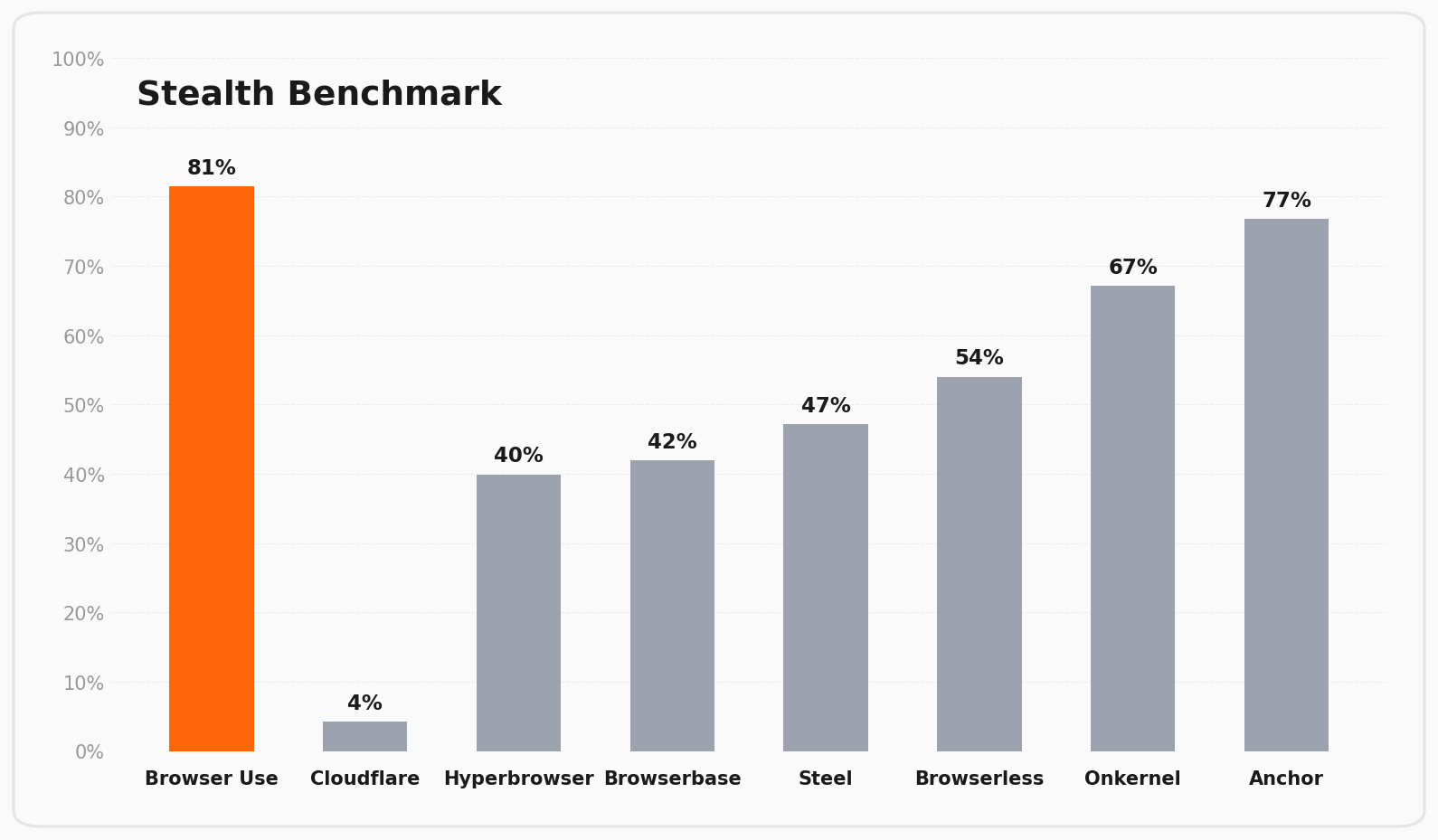
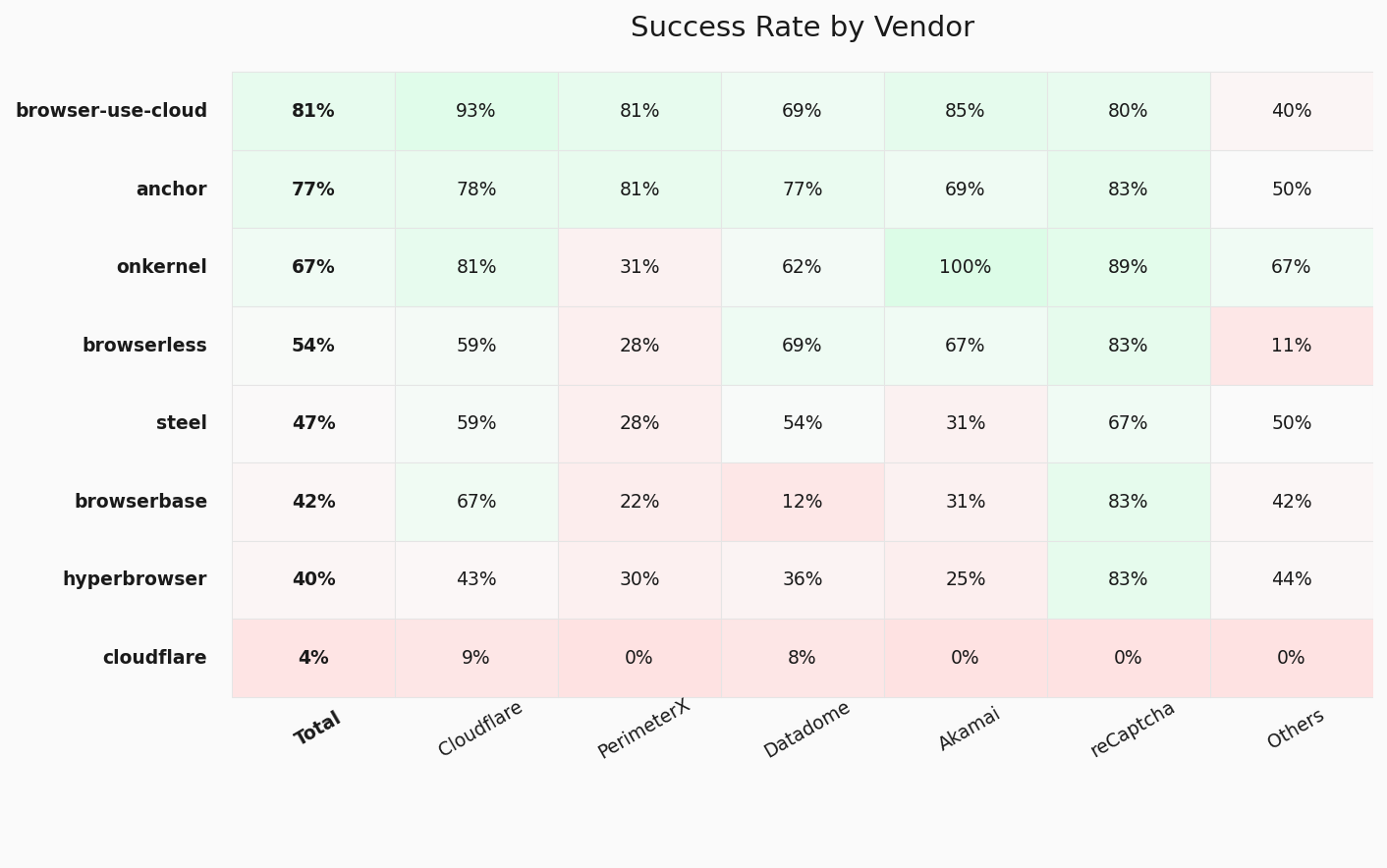
## Stealth Bench V1
**71 tasks for evaluating browser stealth across anti-bot protections**
Read more in our [blog post](https://browser-use.com/posts/stealth-benchmark).
### Running the Stealth Benchmark
**1. Install dependencies**
```bash
pip install uv
uv sync
```
**2. Set up your `.env`** (see [`.env.example`](.env.example))
```bash
cp .env.example .env
# Fill in GOOGLE_API_KEY (required for the judge LLM)
# Fill in the API key for the browser provider you want to test
```
**3. Decrypt the task set**
```bash
python -c "
import base64, hashlib, json
from cryptography.fernet import Fernet
key = base64.urlsafe_b64encode(hashlib.sha256(b'Stealth_Bench_V1').digest())
tasks = json.loads(Fernet(key).decrypt(base64.b64decode(open('Stealth_Bench_V1.enc').read())))
print(f'Loaded {len(tasks)} tasks')
json.dump(tasks, open('Stealth_Bench_V1.json', 'w'), indent=2)
"
```
**4. Run the evaluation**
```bash
uv run python run_eval.py --browser
```
Available providers: `browser-use-cloud`, `anchor`, `browserbase`, `browserless`, `hyperbrowser`, `onkernel`, `steel`, `local_headful`, `local_headless`
**Results and official data:** [`stealth_bench/`](stealth_bench/)
---
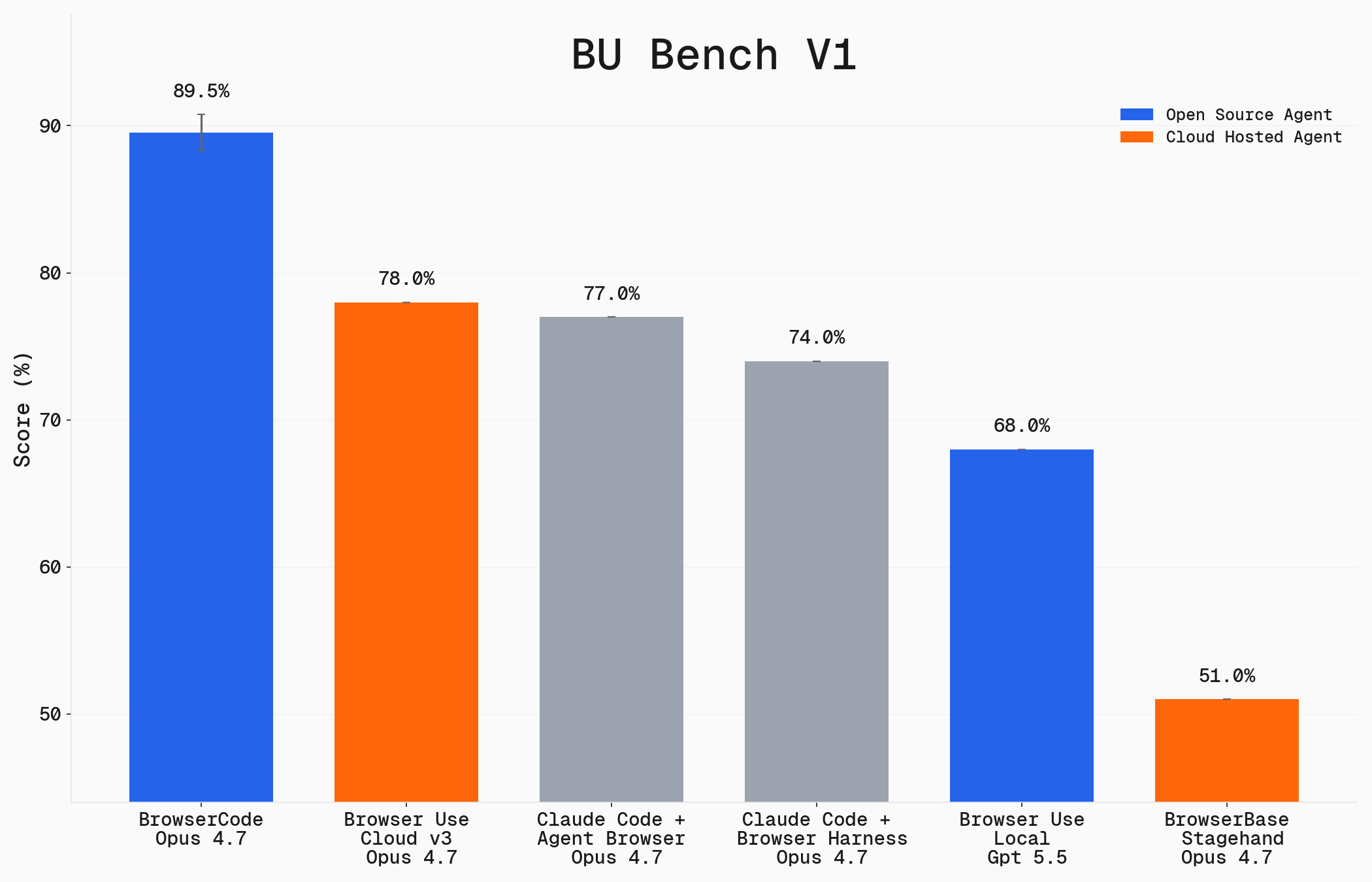
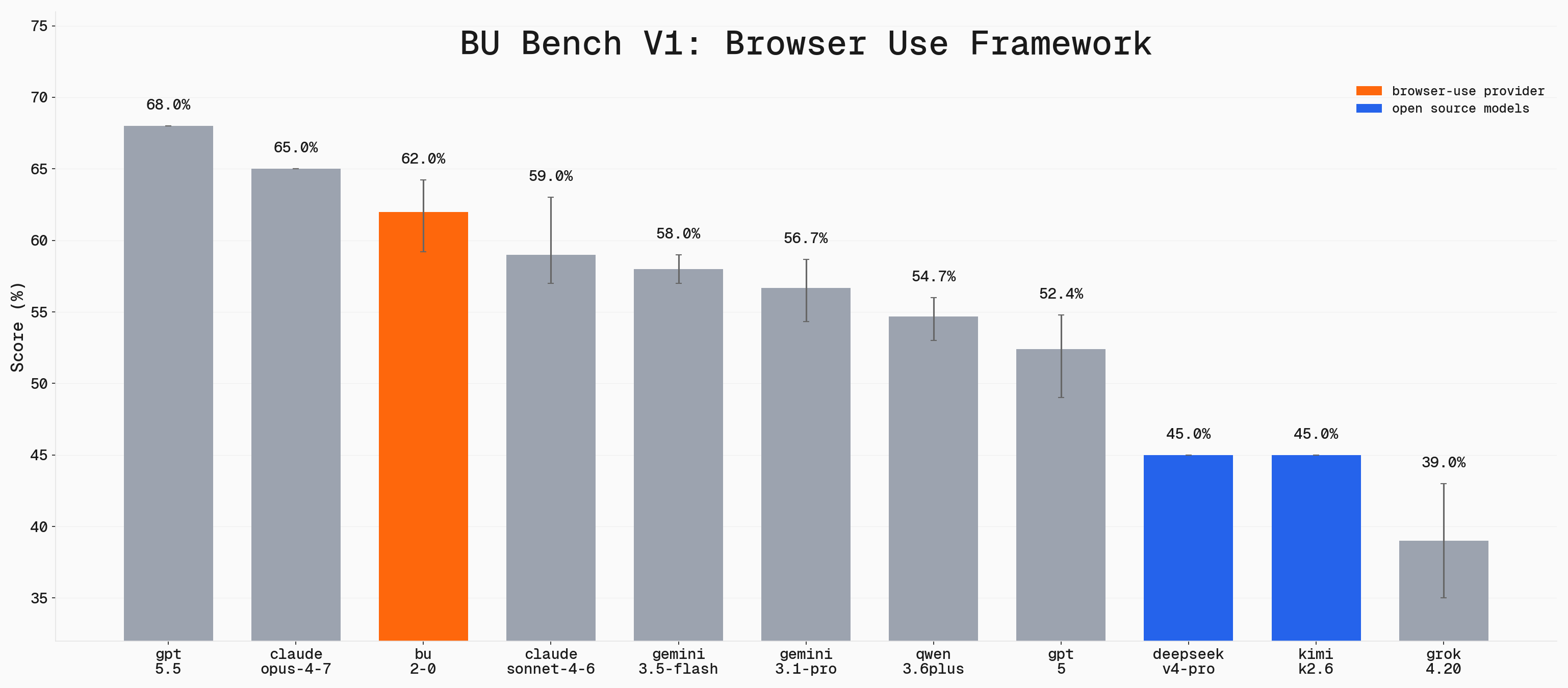
## BU Bench V1
**100 hand-selected tasks for evaluating browser automation agents**
### Comparing Agent Frameworks
### Comparing Models for Browser Use
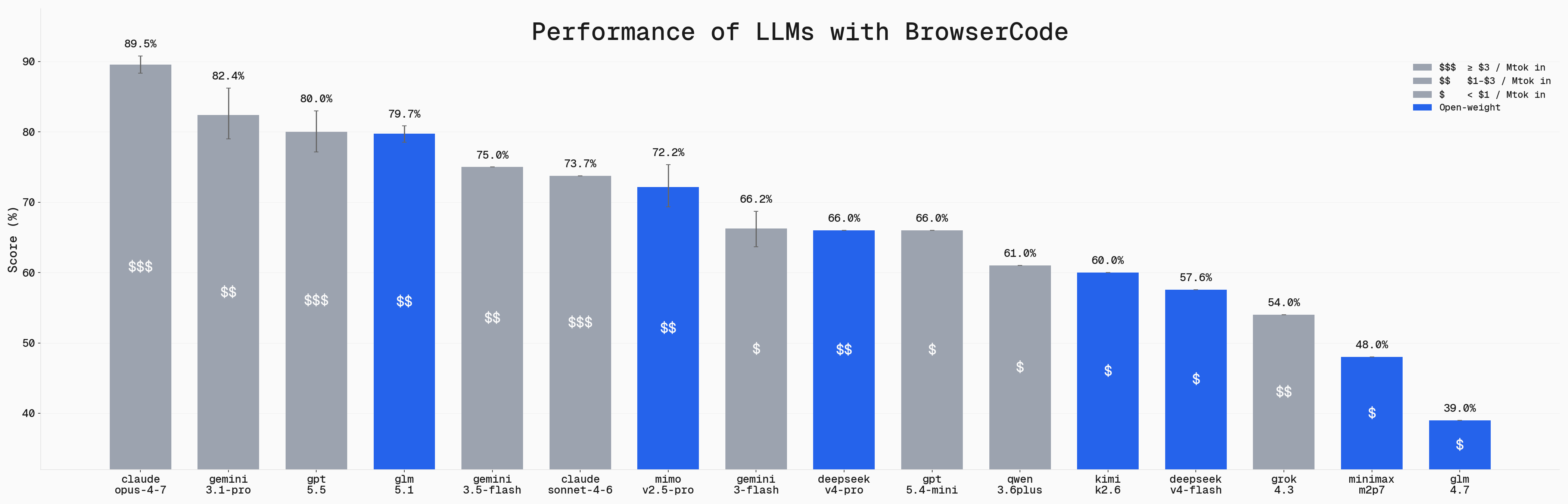
### Comparing Models for BrowserCode
### Running BU Bench
**1. Install dependencies**
```bash
pip install uv
uv sync
```
**2. Set up your `.env`** (see [`.env.example`](.env.example))
```bash
cp .env.example .env
# Fill in BROWSER_USE_API_KEY (required for ChatBrowserUse and cloud browsers)
# Fill in GOOGLE_API_KEY (required for judge LLM)
```
**3. Run evaluation**
```bash
uv run python run_eval.py
```
Results are saved to `results/` and detailed traces to `run_data/`.
### Re-verifying Framework Results
Use `run_framework_eval.py` to rerun BU_Bench_V1 through a framework adapter.
It decrypts `BU_Bench_V1.enc` in memory and writes local outputs to ignored
`results/` and `run_data/`.
```bash
uv run python run_framework_eval.py --list-frameworks
uv run python run_framework_eval.py --framework browser-use --browser browser-use-cloud --model bu-2-0
```
See the comment at the top of `run_framework_eval.py` for framework-specific
setup, options, and examples.
Important: `run_data/` traces include decrypted task text, ground truth, model
outputs, and screenshots. They are gitignored for local verification only. Do
not publish or commit them.
### Swapping Models
Edit `run_eval.py` to change the model:
```python
# Default: ChatBrowserUse (recommended)
agent = Agent(task=task["confirmed_task"], llm=ChatBrowserUse(), browser=browser)
# OpenAI
agent = Agent(task=task["confirmed_task"], llm=ChatOpenAI(model="gpt-4.1"), browser=browser)
# Anthropic
agent = Agent(task=task["confirmed_task"], llm=ChatAnthropic(model="claude-sonnet-4-5"), browser=browser)
# Google
agent = Agent(task=task["confirmed_task"], llm=ChatGoogle(model="gemini-2.5-flash"), browser=browser)
```
### About BU Bench
100 tasks drawn from established benchmarks and custom challenges:
| Source | Tasks | Description |
|--------|-------|-------------|
| Custom | 20 | Page interaction challenges |
| WebBench | 20 | Web browsing tasks |
| Mind2Web 2 | 20 | Multi-step web navigation |
| GAIA | 20 | General AI assistant tasks (web-based) |
| BrowseComp | 20 | Browser comprehension tasks |
WebBench, Mind2Web 2, and BrowseComp are released under the MIT license. GAIA has no explicit license; to comply with its data policies, we only include tasks from the "fully public" validation split, and all tasks are base64 encoded and encrypted to prevent data contamination.
Tasks were hand-selected for difficulty and verified to be achievable. Each task has been validated to confirm it can be completed successfully.
Important: The task set is stored in base64 encoding to prevent data contamination in LLM training. Please do not publish the tasks in plaintext or use them in model training data.
#### Task Format
| Field | Description |
|-------|-------------|
| `task_id` | Unique identifier |
| `confirmed_task` | Task instruction |
| `category` | Source benchmark |
| `answer` | Ground truth (if applicable) |
---
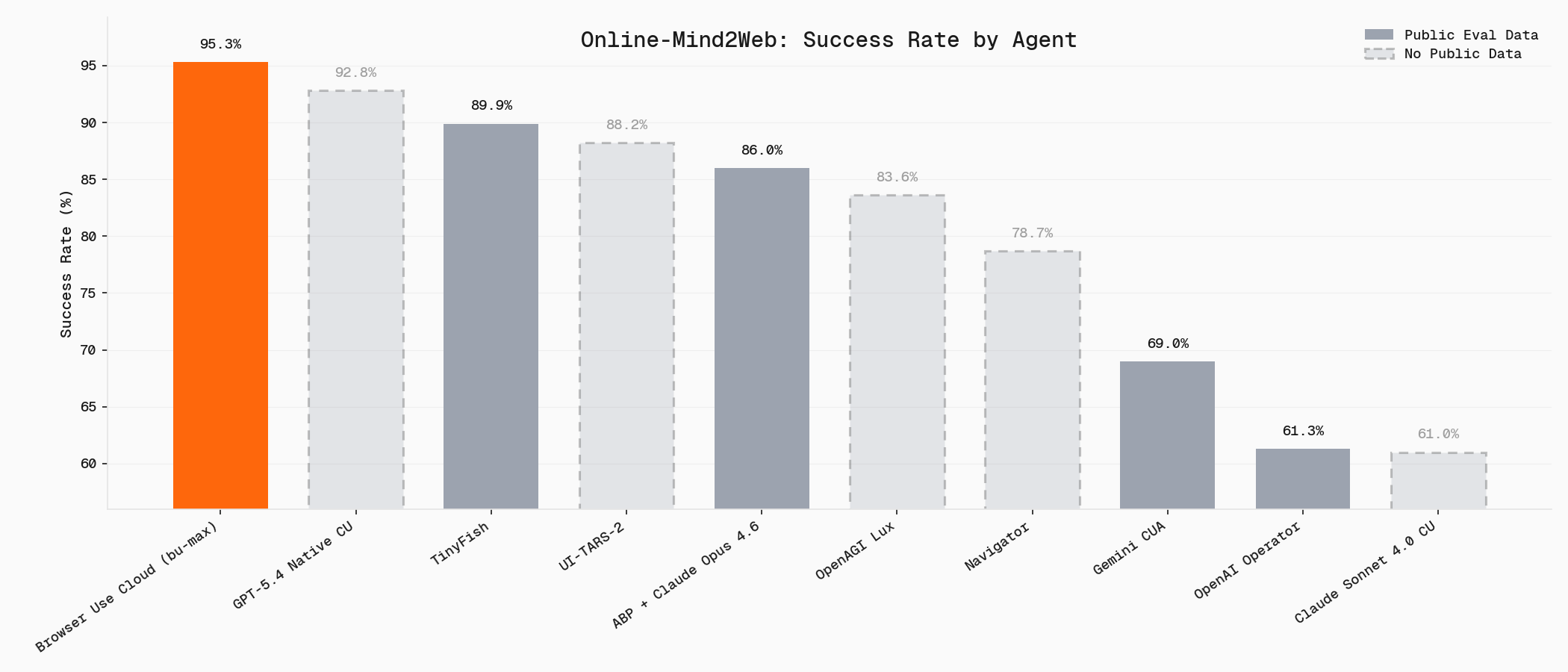
## Online-Mind2Web
The [Online-Mind2Web](https://github.com/OSU-NLP-Group/Online-Mind2Web) benchmark is evaluated across agent frameworks.
---
## Attributions
### WebBench
MIT License | https://webbench.ai/
```bibtex
@misc{webbench2025,
title = {WebBench: AI Web Browsing Agent Benchmark},
author = {{Halluminate and Skyvern}},
year = {2025},
note = {\url{https://webbench.ai/}},
}
```
### Mind2Web 2 (OMI2W-2)
MIT License | https://openreview.net/forum?id=AUaW6DS9si
```bibtex
@inproceedings{
gou2025mind2web2,
title={Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge},
author={Boyu Gou and Zanming Huang and Yuting Ning and Yu Gu and Michael Lin and Botao Yu and Andrei Kopanev and Weijian Qi and Yiheng Shu and Jiaman Wu and Chan Hee Song and Bernal Jimenez Gutierrez and Yifei Li and Zeyi Liao and Hanane Nour Moussa and TIANSHU ZHANG and Jian Xie and Tianci Xue and Shijie Chen and Boyuan Zheng and Kai Zhang and Zhaowei Cai and Viktor Rozgic and Morteza Ziyadi and Huan Sun and Yu Su},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2025},
url={https://openreview.net/forum?id=AUaW6DS9si}
}
```
### BrowseComp
MIT License | https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf
```bibtex
@techreport{wei2025browsecomp,
author = {Jason Wei and Zhiqing Sun and Spencer Papay and Scott McKinney and Jeffrey Han and Isa Fulford and Hyung Won Chung and Alex Tachard Passos and William Fedus and Amelia Glaese},
title = {BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents},
institution = {OpenAI},
year = {2025},
url = {https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf},
}
```
### GAIA
No license (public validation split only) | https://huggingface.co/datasets/gaia-benchmark/GAIA
```bibtex
@misc{mialon2023gaia,
title={GAIA: a benchmark for General AI Assistants},
author={Gregoire Mialon and Clementine Fourrier and Craig Swift and Thomas Wolf and Yann LeCun and Thomas Scialom},
year={2023},
eprint={2311.12983},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```