Next: Experimental Setup Up: Machine Learning Methods Previous: The Maximum Entropy Classifier
Support Vector Machines (SVMs) operate by separating points in a d-dimensional space using a (d-1)-dimensional hyperplane, unlike Max-Ent and Naive Bayes classifiers, which use probabilistic measures to classify points. Given a set of training data, the SVM classifier finds a hyperplane with the largest possible margin; that is, it tries finds the hyperplane such that each training point is correctly classified and the hyperplane is as far as possible from the points closest to it. In practice, it is usually not possible to find a hyperplane that separates the classes perfectly, so points are permitted to be inside the margin or on the wrong side of the hyperplane. Any point on or inside the margin is referred to as a support vector, and the hyperplane, given by
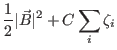
For this paper, we use the PyML implementation of SVMs [1], which uses the liblinear optimizer to actually find the separating hyperplane. Of the three classifiers, this was the slowest to train, as it suffers from the curse of dimensionalit
Pranjal Vachaspati 2012-02-05