KNN, SVM, Data Preprocessing, and Scikit-learn Pipeline ¶
Fall 2017
from IPython.display import Image
from IPython.display import display
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# inline plotting instead of popping out
%matplotlib inline
# load utility classes/functions that has been taught in previous labs
# e.g., plot_decision_regions()
import os, sys
module_path = os.path.abspath(os.path.join('.'))
sys.path.append(module_path)
from lib import *
In this lab, we will classify nonlinearly separable data using the KNN and SVM classifiers. Then, we discuss how to handle data with missing values and categorical data. Finally, we will show how to pack multiple data preprocessing steps into into a single Pipeline in Scikit-learn to simplify the training workflow.
Nonlinearly Separable Classes¶
Sometimes, the classes in a dataset may be nonlinearly separable. A famous synthetic dataset in this category, called the two-moon dataset, can be illustrated in 2-D:
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.15, random_state=0)
plt.scatter(X[y == 0, 0], X[y == 0, 1],
c='r', marker='o', label='Class 0')
plt.scatter(X[y == 1, 0], X[y == 1, 1],
c='b', marker='s', label='Class 1')
plt.xlim(X[:, 0].min()-1, X[:, 0].max()+1)
plt.ylim(X[:, 1].min()-1, X[:, 1].max()+1)
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='best')
plt.tight_layout()
plt.savefig('./output/fig-two-moon.png', dpi=300)
plt.show()

If we apply linear classifiers such as Perceptron or Logistic Regression to this dataset, it is not possible to get a reasonable decision boundary:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Perceptron
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=1)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
ppn = Perceptron(max_iter=1000, eta0=0.1, random_state=0)
ppn.fit(X_train_std, y_train)
y_pred = ppn.predict(X_test_std)
print('[Perceptron]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# plot decision regions for Perceptron
plot_decision_regions(X_combined_std, y_combined,
classifier=ppn,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/fig-two-moon-perceptron-boundray.png', dpi=300)
plt.show()
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(X_train_std, y_train)
y_pred = lr.predict(X_test_std)
print('[Logistic regression]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# plot decision regions for LogisticRegression
plot_decision_regions(X_combined_std, y_combined,
classifier=lr,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/fig-two-moon-logistic-regression-boundray.png', dpi=300)
plt.show()


As we can see, neither of the classifiers can separate the two classes well due to underfitting. In other words, the models are too simple to capture the shape of true boundary, introducing a large bias. It is better to use nonlinear classifiers for this dataset.
K-Nearest Neighbors Classifier¶
The KNN algorithm itself is fairly straightforward and can be summarized by the following steps:
- Choose $K$ (the number of neighbors), and a distance metric;
- Find the $K$ nearest neighbors of the data point that we want to classify;
- Assign the class label by majority vote.
KNN is a typical example of a lazy learner. It is called lazy because it simply memorizes the training dataset in the training phase and learns a discriminative function $f$ only before making a prediction.
By executing the following code, we will now implement a KNN model in scikit-learn using a Euclidean distance metric:
from sklearn.neighbors import KNeighborsClassifier
# p=2 and metric='minkowski' means the Euclidean Distance
knn = KNeighborsClassifier(n_neighbors=11, p=2, metric='minkowski')
knn.fit(X_train_std, y_train)
y_pred = knn.predict(X_test_std)
print('[KNN]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# plot decision regions for knn classifier
plot_decision_regions(X_combined_std, y_combined,
classifier=knn,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/fig-two-moon-knn-boundray.png', dpi=300)
plt.show()

The KNN classifier achieves 95% accuracy. That's pretty good! Another advantage of such a memory-based approach is that the classifier immediately adapts as we collect new training data.
However, the downside is that the computational complexity for classifying new points grows linearly with the number of samples in the training dataset in the worst-case scenario, unless the dataset has very few dimensions (features) and the algorithm has been implemented using efficient data structures such as KD-trees, an algorithm for finding best matches in logarithmic expected time. Furthermore, we can't discard training samples since no training step is involved. Thus, storage space can become a challenge if we are working with large datasets.
Support Vector Classifier¶
Another powerful and widely used memory-based classifier is the nonlinear support vector classifier (SVC). Like KNN, nonlinear SVC makes predictions by the weighted average of the labels of similar examples (measured by a kernel function). However, only the support vectors, i.e., examples falling onto or inside the margin, can have positive weights and need to be remembered. In practice, SVC usually remembers much fewer examples than KNN does. Another difference is that SVC is not an lazy learner---the weights are trained eagerly in the training phase.
Let's make predictions using SVCs:
from sklearn.svm import SVC
# kernel: the kernel function, can be 'linear', 'poly', 'rbf', ...etc
# C is the hyperparameter for the error penalty term
svm_linear = SVC(kernel='linear', C=1000.0, random_state=0)
svm_linear.fit(X_train_std, y_train)
y_pred = svm_linear.predict(X_test_std)
print('[Linear SVC]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# plot decision regions for linear svm
plot_decision_regions(X_combined_std, y_combined,
classifier=svm_linear,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/figtwo-moon-svm-linear-boundray.png', dpi=300)
plt.show()
# C is the hyperparameter for the error penalty term
# gamma is the hyperparameter for the rbf kernel
svm_rbf = SVC(kernel='rbf', random_state=0, gamma=0.2, C=10.0)
svm_rbf.fit(X_train_std, y_train)
y_pred = svm_rbf.predict(X_test_std)
print('[Nonlinear SVC]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# plot decision regions for rbf svm
plot_decision_regions(X_combined_std, y_combined,
classifier=svm_rbf,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/fig-two-moon-svm-rbf-boundray.png', dpi=300)
plt.show()


As we can see, non-linear SVC achieves 95% accuracy as KNN does. However, we haven't tuned its hyperparameters to get the best performance yet. Let's try other values:
print('[Nonlinear SVC: C=1000, gamma=0.01]')
svm = SVC(kernel='rbf', random_state=0, gamma=0.01, C=1000.0)
svm.fit(X_train_std, y_train)
y_pred = svm.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
print('\n[Nonlinear SVC: C=1, gamma=1]')
svm = SVC(kernel='rbf', random_state=0, gamma=0.0001, C=10.0)
svm.fit(X_train_std, y_train)
y_pred = svm.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
From the above example, we can see that tuning the hyperparameters is very important to nonlinear SVM. Different parameter setting will make huge performance difference.
Tuning Hyperparameters via Grid Search¶
Tuning the hyperparameters of SVC is not as straightforward as we see in Polynomial Regression, where we can simply increase the polynomial degree from 1 and stop if the validation performance does not improve anymore. In SVC, there is no simple way to relate a particular hyperparameter combination $(C,\gamma)$ to the model complexity. So, we have to try out all possible (or specified) combinations exhaustively in order to pick the best one. This procedure is called grid search:
from sklearn.model_selection import GridSearchCV
param_C = [0.1, 1.0, 10.0, 100.0, 1000.0, 10000.0]
param_gamma = [0.00001, 0.0001, 0.001, 0.01, 0.1, 1.0]
svm = SVC(random_state=0)
# set the param_grid parameter of GridSearchCV to a list of dictionaries
param_grid = [{'C': param_C,
'gamma': param_gamma,
'kernel': ['rbf']}]
gs = GridSearchCV(estimator=svm,
param_grid=param_grid,
scoring='accuracy')
gs = gs.fit(X_train_std, y_train)
print(gs.best_score_)
print(gs.best_params_)
After finding the best parameter, we can then use it to evaluate on test data:
clf = gs.best_estimator_
clf.fit(X_train_std, y_train)
print('\n[Nonlinear SVC: grid search]')
print('Test accuracy: %.2f' % clf.score(X_test_std, y_test))
# plot decision regions for rbf svm
plot_decision_regions(X_combined_std, y_combined,
classifier=gs.best_estimator_,
test_idx=range(y_train.size,
y_train.size + y_test.size))
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.legend(loc='upper left')
plt.tight_layout()
plt.savefig('./output/fig-two-moon-svm-rbf-gs-boundray.png', dpi=300)
plt.show()

We have perfect test accuracy. That's great!
NOTE: grid search may consume a lot of time when the dataset is large. A practical way is to use coarse grids initially, narrow down into some grids that gives relatively good performance, and then perform more fine-grained grid searches within those grids recursively.
Data Preprocessing¶
Now we have hands-on experience of many machine learning models. It's time to apply them to a more realistic dataset that have quality issues. The quality of the data and the amount of useful information that it contains are key factors that determine how well a machine learning algorithm can learn. Therefore, it is critical that we make sure to examine and preprocess a dataset before we feed it to a learning algorithm. The dataset we use on next section is the Adult dataset.
The Adult dataset¶
The Adult dataset from UCI repository collects information about people (attributes) for determining whether a person makes over 50K a year (label). Following are the attributes:
1. age continuous.
2. workclass Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov,
Without-pay, Never-worked.
3. fnlwgt continuous.
4. education Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc,
9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
5. education-num continuous.
6. marital-status Married-civ-spouse, Divorced, Never-married, Separated, Widowed,
Married-spouse-absent, Married-AF-spouse.
7. occupation Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty,
Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving,
Priv-house-serv, Protective-serv, Armed-Forces.
8. relationship Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
9. race White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
10. sex Female, Male.
11. capital-gain continuous.
12. capital-loss continuous.
13. hours-per-week continuous.
14. native-country United-States, Cambodia, England, Puerto-Rico, Canada, Germany,
Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran,
Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal,
Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia,
Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador,
Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
15. label >50K, <=50K
You can see more details about the dataset here. Let's load the data:
import pandas as pd
import numpy as np
# we set sep=', ' since this dataset is not a regular csv file
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'adult/adult.data', header=None, sep=', ', engine='python')
df.columns = ['age', 'workclass', 'fnlwgt', 'education',
'education-num', 'marital-status', 'occupation',
'relationship', 'race', 'sex', 'capital-gain',
'capital-loss', 'hours-per-week', 'native-country',
'label']
display(df.head(15))
We can observe two things in this dataset:
- Many attributes are not numeric but categorical;
- There are missing values. For example, data point No.14 has a missing value on native-country.
Since most machine learning algorithms can only take datasets with numeric features and without missing values. We have to preprocess this dataset.
Handling Categorical Data¶
Real-world datasets usually contain one or more categorical features. When we are talking about categorical data, we have to further distinguish between nominal and ordinal features. Ordinal features can be understood as categorical values that can be sorted or ordered. For example, T-shirt size would be an ordinal feature, because we can define an order XL > L > M. In contrast, nominal features don't imply any order. For example, we could think of T-shirt color as a nominal feature since it typically doesn't make sense to say that, for example, red is larger than blue.
In the Adult dataset, there is no obvious feature that is ordinal. So we will only focus on nominal ones in this lab. We can use the LabelEncoder in scikit-learn to help us encode categorical values into numerical values.
import numpy as np
from sklearn.preprocessing import LabelEncoder
# encode label first
label_le = LabelEncoder()
df['label'] = label_le.fit_transform(df['label'].values)
# encode categorical features
catego_features = ['workclass', 'education', 'marital-status', 'occupation',
'relationship', 'race', 'sex', 'native-country']
catego_le = LabelEncoder()
# transform categorical values into numerical values
# be careful that '?' will also be encoded
# we have to replace it to NaN in numerical
num_values = []
for i in catego_features:
df[i] = catego_le.fit_transform(df[i].values)
classes_list = catego_le.classes_.tolist()
# store the total number of values
num_values.append(len(classes_list))
# replace '?' with 'NaN'
if '?' in classes_list:
idx = classes_list.index('?')
df[i] = df[i].replace(idx, np.nan)
display(df.head(15))
After executing the code, we successfully replaced the categorical values into numerical values.
Dealing with Missing Data¶
It is common in real-world applications that our samples have missing values for various reasons in one or more attributes for various reasons. For example, there could have been an error in the data collection process, or certain measurements are not applicable, or particular fields could have been left blank intentionally in a survey, etc. We typically see missing values as the blank spaces, NaN, or question mark in our datasets.
Unfortunately, most computational tools are unable to handle such missing values or would produce unpredictable results if we simply ignored them. Therefore, it is crucial that we take care of those missing values before we proceed with further analyses.
First, we can use isnull() method in Panda's Dataframe to see how many missing values we have in Adult dataset:
# count the number of missing values per column
display(df.isnull().sum())
For a larger dataset, it can be tedious to look for missing values manually; in this case, we can use the isnull() method to return a DataFrame with Boolean values that indicate whether a cell contains a numeric value (False) or if data is missing (True). Using the sum() method, we can then return the number of missing values per column.
Next, we discuss some different strategies to handle missing data.
Eliminating Samples or Features with Missing Values¶
One of the easiest ways to deal with missing data is to simply remove the corresponding features (columns) or samples (rows) from the dataset entirely. We can call the dropna() method of Dataframe to eliminate rows or columns:
print(df.shape)
# drop rows with missing values
df_drop_row = df.dropna()
print(df_drop_row.shape)
The dropna method supports several additional parameters that can come in handy:
print('Original: {}'.format(df.shape))
# drop columns with missing values
df_drop_col = df.dropna(axis=1)
print('Drop column: {}'.format(df_drop_col.shape))
# only drop rows where all columns are NaN
df_drop_row_all = df.dropna(how='all')
print('Drop row all: {}'.format(df_drop_row_all.shape))
# drop rows that have not at least 14 non-NaN values
df_drop_row_thresh = df.dropna(thresh=14)
print('Drop row 14: {}'.format(df_drop_row_thresh.shape))
# only drop rows where NaN appear in specific columns (here: 'occupation')
df_drop_row_occupation = df.dropna(subset=['occupation'])
print('Drop row occupation: {}'.format(df_drop_row_occupation.shape))
Although the removal of missing data seems to be a convenient approach, it comes with certain disadvantages; for example, we may end up removing too many samples and have a small dataset, resulting in overfitting. Or, if we remove too many feature columns, we will run the risk of losing valuable relationship between features that our classifier needs to discriminate between classes.
Imputing Missing Values¶
If we do not have a large dataset, the removal of samples or dropping of entire feature columns may not be feasible, because we could lose too much valuable information. An alternative way is to use interpolation techniques to estimate the missing values from other training samples in the same dataset. There are some common interpolation techniques we can use, such as mean imputation, median imputation, and most frequent imputation.
The Imputer class from scikit-learn provides a convenient way for imputation. Next, we use it to perform the most frequent imputation since the missing values in the Adult dataset are all categorical features:
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imr = imr.fit(df.values)
imputed_data = imr.transform(df.values)
df_impute = pd.DataFrame(imputed_data)
df_impute.columns = df.columns
display(df.head(15))
display(df_impute.head(15))
# check if there are still missing values
display(df_impute.isnull().sum())
After executing the code, we successfully replace the missing values into most frequent values.
One-Hot Encoding¶
If we stop at this point and feed the array to our classifier, we will make one of the most common mistakes in dealing with categorical data. Take the 'workclass' for example, we will assume that 'State-gov' is larger than 'Self-emp-not-inc', and 'Self-emp-not-inc' is larger than 'Private'. This incorrect assumption can lead to degraded performance. For example, if a model uses weight decay for regularization, it may prefer categorical values that are encoded closer to $0$.
A common workaround for this problem is to use a technique called one-hot encoding. The idea behind this approach is to create a new dummy feature column for each unique value in the nominal feature. To perform this transformation, we can use the OneHotEncoder from Scikit-learn:
from sklearn.preprocessing import OneHotEncoder
# we perform one-hot encoding on both impute data and drop-row data
impute_data = df_impute.values
drop_row_data = df_drop_row.values
# find the index of the categorical feature
catego_features_idx = []
for str in catego_features:
catego_features_idx.append(df.columns.tolist().index(str))
# give the column index you want to do one-hot encoding
ohe = OneHotEncoder(categorical_features = catego_features_idx, sparse=False)
print('Impute: {}'.format(impute_data.shape))
impute_onehot_data = ohe.fit_transform(impute_data)
print('Impute one-hot: {}'.format(impute_onehot_data.shape))
print('Drop row: {}'.format(drop_row_data.shape))
drop_row_onehot_data = ohe.fit_transform(drop_row_data)
print('Drop row one-hot: {}'.format(drop_row_onehot_data.shape))
Here, we can see that the numbers of column on both dataset increase significantly. Note that the number of columns between impute_onehot_data and drop_row_onehot_data are different, which implies that the drop-row method makes a value in a column disappear, resulting in loss of information.
NOTE: by default, the OneHotEncoder returns a sparse matrix when we use the transform() method. Sparse matrices save space to store entries with a lot of zeros.
The get_dummies() Method in Pandas¶
An alternative, but more convenient way to create dummy features via one-hot encoding is to use the get_dummies() method implemented in Pandas.
NOTE: the get_dummies() method will only convert string columns and leave all other columns unchanged. If you want to use this method, you have to ensure that the categorical data are all string. Otherwise it will not perform encoding.
df_dummy = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'adult/adult.data',
header=None, sep=', ', engine='python')
df_dummy.columns = ['age', 'workclass', 'fnlwgt', 'education',
'education-num', 'marital-status', 'occupation',
'relationship', 'race', 'sex', 'capital-gain',
'capital-loss', 'hours-per-week', 'native-country',
'label']
# encode label first
label_le = LabelEncoder()
df_dummy['label'] = label_le.fit_transform(df_dummy['label'].values)
# remove rows with missing data
df_dummy = df_dummy.replace('?', np.nan)
df_dummy_drop_row = df_dummy.dropna()
# here we cannot use sklearn.Imputer, since it only accepts numerical values
# one-hot encoding
df_dummy_drop_row = pd.get_dummies(df_dummy_drop_row)
display(df_dummy_drop_row.head())
Scikit-learn Pipeline¶
When we applied different preprocessing techniques in the previous labs, such as standardization, data preprocessing, or PCA, you learned that we have to reuse the parameters that were obtained during the fitting of the training data to scale and compress any new data, for example, the samples in the separate test dataset. Scikit-learn Pipeline allows us to fit a model including an arbitrary number of transformation steps and apply it to make predictions about new data. The following summarizes how a Pipeline works:
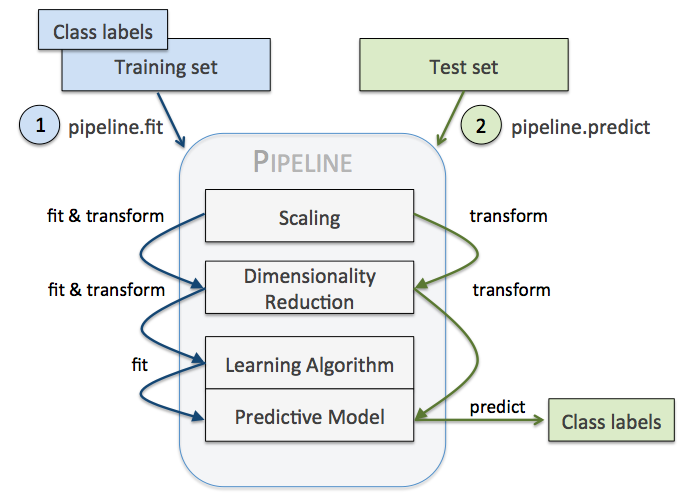
Here, we give an example on how to combine Imputer and OneHotEncoder with KNN or SVM:
from sklearn.pipeline import Pipeline
df_small = df.sample(n=4000, random_state=0)
X = df_small.drop('label', 1).values
y = df_small['label'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0)
# define pipeline with an arbitrary number of transformer in a tuple array
pipe_knn = Pipeline([('imr', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('ohe', OneHotEncoder(categorical_features=catego_features_idx,
n_values=num_values, sparse=False)),
('scl', StandardScaler()),
('clf', KNeighborsClassifier(n_neighbors=10, p=2, metric='minkowski'))])
pipe_svm = Pipeline([('imr', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('ohe', OneHotEncoder(categorical_features=catego_features_idx,
n_values=num_values, sparse=False)),
('scl', StandardScaler()),
('clf', SVC(kernel='rbf', random_state=0, gamma=0.001, C=100.0))])
# use the pipeline model to train
pipe_knn.fit(X_train, y_train)
y_pred = pipe_knn.predict(X_test)
print('[KNN]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
pipe_svm.fit(X_train, y_train)
y_pred = pipe_svm.predict(X_test)
print('\n[SVC]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
We can check whether one-hot encoding is useful or not:
pipe_knn = Pipeline([('imr', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('scl', StandardScaler()),
('clf', KNeighborsClassifier(n_neighbors=10, p=2, metric='minkowski'))])
pipe_svm = Pipeline([('imr', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('scl', StandardScaler()),
('clf', SVC(kernel='rbf', random_state=0, gamma=0.001, C=100.0))])
pipe_knn.fit(X_train, y_train)
y_pred = pipe_knn.predict(X_test)
print('[KNN: no one-hot]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
pipe_svm.fit(X_train, y_train)
y_pred = pipe_svm.predict(X_test)
print('\n[SVC: no one-hot]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
As we can see, the performance of KNN does not change much because the model does not prefer specific numerical values. On the other hand, the performance of SVC dropped because it has a weight decay term in the cost function that can be misled when the categorical features are not encoded as one-hot vectors.
We can also compare the performance between imputation and dropping rows:
# keep only data points without NaN features
idx = np.isnan(X_train).sum(1) == 0
X_train = X_train[idx]
y_train = y_train[idx]
idx = np.isnan(X_test).sum(1) == 0
X_test = X_test[idx]
y_test = y_test[idx]
pipe_knn = Pipeline([('ohe', OneHotEncoder(categorical_features = catego_features_idx,
n_values = num_values, sparse=False)),
('scl', StandardScaler()),
('clf', KNeighborsClassifier(n_neighbors=10, p=2, metric='minkowski'))])
pipe_svm = Pipeline([('ohe', OneHotEncoder(categorical_features = catego_features_idx,
n_values = num_values, sparse=False)),
('scl', StandardScaler()),
('clf', SVC(kernel='rbf', random_state=0, gamma=0.001, C=100.0))])
# use the pipeline model to train
pipe_knn.fit(X_train, y_train)
y_pred = pipe_knn.predict(X_test)
print('[KNN: drop row]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
pipe_svm.fit(X_train, y_train)
y_pred = pipe_svm.predict(X_test)
print('\n[SVC: drop row]')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
We get slightly worse results than imputation, but not much since we have a large enough dataset.
Finally, let's combine SVC pipeline with grid search:
pipe_svm = Pipeline([('ohe', OneHotEncoder(categorical_features = catego_features_idx,
n_values = num_values, sparse=False)),
('scl', StandardScaler()),
('clf', SVC(random_state=0))])
param_gamma = [0.0001, 0.001, 0.01, 0.1, 1.0]
param_C = [0.1, 1.0, 10.0, 100.0]
# here you can set parameter for different steps
# by adding two underlines (__) between step name and parameter name
param_grid = [{'clf__C': param_C,
'clf__kernel': ['linear']},
{'clf__C': param_C,
'clf__gamma': param_gamma,
'clf__kernel': ['rbf']}]
# set pipe_svm as the estimator
gs = GridSearchCV(estimator=pipe_svm,
param_grid=param_grid,
scoring='accuracy')
gs = gs.fit(X_train, y_train)
print('[SVC: grid search]')
print('Validation accuracy: %.3f' % gs.best_score_)
print(gs.best_params_)
clf = gs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))
Assignment¶
In this assignment, a dataset called Mushroom dataset will be used. This data includes descriptions of hypothetical samples corresponding to 22 features of gilled mushrooms. Please refer to the website for more information about this dataset.
Goal¶
Given the dataset, predict whether a mushroom is poisonous or edible. The dataset can be downloaded here.
Requirements¶
- Use Mushroom dataset and sample 2000 rows from it.
- Do some data preprocessing.
- Train models using KNN and/or SVM. Note that you need to use train_test_split and set test_size = 0.2. Also, it is up to you which features to use – you can either use all or select a few depending on how you see fit.
- Show the accuracy scores of the models.
- Among the models that you tried, choose the best model and show its accuracy score.
Submit your ipynb (make sure we can rerun it successfully) to iLMS. The ipynb file should contain:
- Your code
- What you have done for data preprocessing
- Your code and accuracy by using KNN and/or SVM
- Anything you want to tell us.