### 1. Data Policies
The Quartet Multi-omics reference materials and raw datasets are publicly available and accessible. Researchers are encouraged to access and analyze the datasets. The recipients of the Reference Materials are highly encouraged to share their data with Fudan University through the Quartet Data Portal in order for us to improve the reference datasets and to better serve the community.
More details on the data policies can be found in [the document](../policies/data_request_policy.md).
### 2. How to bulk download the omics data files with browser?
- Filter and select your expected files
- Add them into file cart
- Go to file cart by clicking `Cart Files` button
- Click `Download Files` to downloading all files in cart.
### 3. How to bulk download the omics data files with file transfer tool?
- Download a metadata table from multi-omics data page.(such as genomics data in Multiomics Data -> Genomics Data)
- Get the md5sum of files which you want to download from the metadata table.
- Follow the following docs to download your expected files.
#### 3.1 Download `file transfer tool - biominer-aget`
Click the link to download `BioMiner Aget`:
- [Linux (CentOS, Debian/Ubuntu or Others)](https://www.indexd.org/biominer-aget/biominer-aget-x86_64-linux)
- [Mac (Intel, not m1 & m2 version)](https://www.indexd.org/biominer-aget/biominer-aget-x86_64-mac)
- [Mac ARM64](https://www.indexd.org/biominer-aget/biominer-aget-x86_64-mac-arm64)
- [Windows](https://www.indexd.org/biominer-aget/biominer-aget-x86_64-windows)
Copy the biominer-aget_xxx binary into /usr/bin/biominer-aget_xxx or any other directory which in PATH variable.
!!!note Please note that
1. The `chunk_size` and `concurrency` parameters are related with the download speed. **There may be tens or hundreds of times the difference, so it's worth taking some time to find the best one.**
2. Not each file can be found in all these repos, so you need to specify a repo name when you downloading expected file.
#### 3.2 Download a data file with biominer-aget
e.g. you want to download the file with UUID `0023a688-6569-44d7-a2cf-b031f4af8cdd` or Hash (such as md5sum, sha128...) `d4e50c8edbf5215fbe2afa1540f7c968` from the repository biominer.fudan-pgx, you can run the following command:
##### For Mac (Intel) Users
```bash
biominer-aget-x86_64-mac --guid biominer.fudan-pgx/0023a688-6569-44d7-a2cf-b031f4af8cdd --output-dir ~/Downloads/ --repo http --chunk_size 1m --concurrency 1000
## or
biominer-aget-x86_64-mac --hash d4e50c8edbf5215fbe2afa1540f7c968 --output-dir ~/Downloads/ --repo http --chunk_size 1m --concurrency 1000
## NODE repo doesn't support http range, so the --chunk_size and --concurrency arguments don't work for it.
biominer-aget-x86_64-mac --hash d4e50c8edbf5215fbe2afa1540f7c968 --output-dir ~/Downloads/ --repo node
```
##### For Linux Users
```bash
biominer-aget-x86_64-linux --guid biominer.fudan-pgx/0023a688-6569-44d7-a2cf-b031f4af8cdd --output-dir ~/Downloads/ --repo gsa --chunk_size 1m --concurrency 1000
## or
biominer-aget-x86_64-linux --hash d4e50c8edbf5215fbe2afa1540f7c968 --output-dir ~/Downloads/ --repo http --chunk_size 1m --concurrency 1000
## NODE repo doesn't support http range, so the --chunk_size and --concurrency arguments don't work for it.
biominer-aget-x86_64-linux --hash d4e50c8edbf5215fbe2afa1540f7c968 --output-dir ~/Downloads/ --repo node
```
##### For Windows Users
If you download the biominer-aget_xxx binary into C://Users/xxx/Desktop, you can use the following command to download data file from QDP.
```cmd
cmd /c C:\Users\xxx\Desktop\biominer-aget-x86_64-windows --hash d4e50c8edbf5215fbe2afa1540f7c968 --repo http
## or
cmd /c C:\Users\xxx\Desktop\biominer-aget-x86_64-windows --guid biominer.fudan-pgx/0023a688-6569-44d7-a2cf-b031f4af8cdd --repo http --chunk_size 1m --concurrency 1000
## NODE repo doesn't support http range, so the --chunk_size and --concurrency arguments don't work for it.
cmd /c C:\Users\xxx\Desktop\biominer-aget-x86_64-windows --hash d4e50c8edbf5215fbe2afa1540f7c968 --repo node
```
```bash
$ biominer-aget --help
Biominer Aget 0.3.7
Jingcheng Yang
An Index Engine for Omics Data Files
USAGE:
biominer-aget [FLAGS] [OPTIONS]
FLAGS:
-D, --debug Activate debug mode
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-a, --api-server The api server address
-k, --chunk_size The number of interval length of each concurrent request [default: '50m']
-c, --concurrency The number of concurrency request [default: 10]
--dns-timeout DNS Timeout(seconds) of request [default: 10]
-g, --guid The guid of the file you want to download, e.g. biominer.fudan-pgx/00006134-c655-
4bbe-9144-0ee86da83902
-H, --hash The hash of the file you want to download, e.g. b47ee06cdf62847f6d4c11bb12ac1ae0
-o, --output-dir Output directory [default: ./]
-p, --password Password for the biominer api server [default: anonymous]
-r, --repo Which data repository you want to download from [default: node] [possible
values: node, gsa, s3, oss, minio, http]
--retries The maximum times of retring [default: 0]
--retry-wait The seconds between retries [default: 0]
-t, --timeout Timeout(seconds) of request [default: 60]
-u, --username Username for the biominer-indexd api server [default: anonymous]
```
### 4. How do you know a file is stored at which repo?
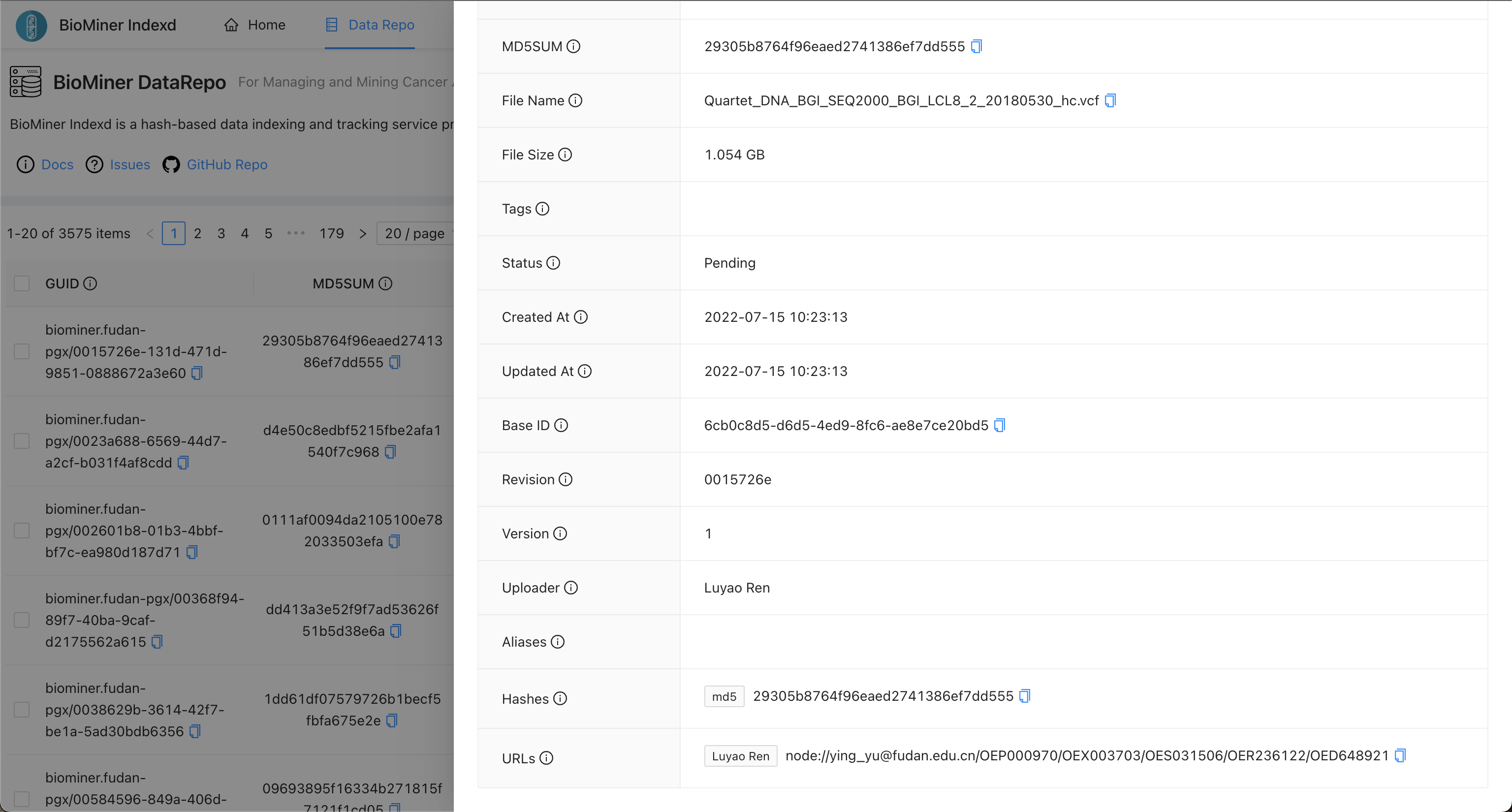
Please access [the BioMiner Indexd service](http://www.indexd.org/index) and query file by md5sum, filename, or other metadata.
When you find the record of a file, you can see more information as the following picture.
In the picture, you can see the URLs field, it can tell you the file is stored at which repos.
### 5. Why BioMiner Indexd?
We will release our data to multiple repos (such as [NODE](https://www.biosino.org/node/), [GSA](https://ngdc.cncb.ac.cn/gsa/), [SRA](https://www.ncbi.nlm.nih.gov/sra), [ENA](https://www.ebi.ac.uk/ena/browser/) etc.), for your convenience, we provide the BioMiner Indexd service for aggregating all these repos.
BioMiner Indexd is a hash-based data indexing and tracking service providing globally unique identifiers.
### 6. What multi-omics data do we provide?
#### Genomics
Quartet DNA reference materials have been extensively sequenced by short-read and long-read technologies. Short-read WGS datasets were generated with depth ranging from 30-60, by employing PCR-free and PCR libraries on multiple short-read sequencing platforms, including Illumina Hiseq XTen, Illumina Novaseq, MGISEQ-2000 and DNBSEQ-T7. We have sequenced 180 WGS libraries, 248 WES libraries in total. Long-read sequencing datasets have been generated using 10X genomics, Oxford Nanopore Technologies, BioNano Genomics, and Pacific Biosciences Sequel and Sequel II with CLR and CCS HiFi modes.
#### Transcriptomics
RNA-seq datasets from reference materials were then obtained, consisting of 252 RNA-seq libraries from 21 batches which were generated by eight laboratories using two library construction protocols (poly(A) selection and rRNA depletion) and two sequencing platforms (Illumina NovaSeq and BGI DNBseq). Here, a batch of RNA-seq experiments was defined as libraries from a standard sample set, consisting of 12 tubes with each representing one of the triplicates of the four RNA reference sample groups, which were conducted library construction and sequencing experiments concurrently.
#### Proteomics
Currently we sent 6 units of Quartet Protein Reference Materials to 6 labs, in which 6 batches of raw datasets and profiled datasets were generated in their in-house LC-MS/MS systems by label-free quantitation (both DDA and DIA). Our Cooperators also extracted human proteins (labeled as “Lot1” in our metadata) from the immortalized B-lymphoblastoid cell lines and have generated 26 batches of DDA-based profiled datasets since 2017.
#### Metabolomics
We dispensed three biological replicates of each unit of the Quartet Metabolite Reference Materials to six laboratory platforms of five companies. These six laboratories produced a total of 204 metabolic quantitative profiles in 17 datasets (batches) using targeted or un-targeted metabolomics strategies. Furthermore, based on the large amount of copies of Quartet metabolite reference materials, we regularly generated targeted metabolomics data with three technical replicates for each unit of the Quartet Metabolite Reference Materials for up to one year in Metabo-Profile (L4).