---
title: "Confidence Intervals and Hypothesis Testing"
subtitle: "FMB819: R을 이용한 데이터분석"
author: "고려대학교 경영대학 정지웅"
format:
revealjs:
theme: simple
transition: fade
transition-speed: fast
scrollable: true
chalkboard: true
slide-number: true
revealjs-plugins:
- revealjs-text-resizer
---
```{r setup, include=FALSE,warning=FALSE,message=FALSE}
options(htmltools.dir.version = FALSE)
knitr::opts_chunk$set(
message = FALSE,
warning = FALSE,
dev = "svg",
cache = TRUE,
fig.align = "center"
)
om = par("mar")
lowtop = c(om[1],om[2],0.1,om[4])
library(magrittr)
library(moderndive)
library(dplyr)
library(tidyverse)
library(infer)
library(cowplot) # plot_grid() 사용을 위해 추가
library(countdown)
library(showtext)
font_add_google("Nanum Gothic", "nanumgothic")
showtext_auto() # 모든 그래픽 디바이스에 자동 적용
theme_set(
theme_bw(base_size = 14) +
theme(text = element_text(family = "nanumgothic"))
)
countdown(
color_border = "#d90502",
color_text = "black",
color_running_background = "#d90502",
color_running_text = "white",
color_finished_background = "white",
color_finished_text = "#d90502",
color_finished_border = "#d90502"
)
overwrite = FALSE
```
------------------------------------------------------------------------
## Today's Agenda
**Part 1 — 신뢰 구간 (Confidence Intervals)**
- 점 추정치의 한계: 왜 범위가 필요한가?
- 부트스트랩(Bootstrap)을 이용한 신뢰 구간 구축
- 신뢰 구간의 정확한 해석
**Part 2 — 가설 검정 (Hypothesis Testing)**
- 귀무가설과 대립가설
- 순열 검정(Permutation Test)을 이용한 귀무분포 생성
- p-값과 유의수준: 언제 귀무가설을 기각하는가?
- 검정 오류(Type I / II Error)
> **핵심 질문**: 표본에서 얻은 숫자를 얼마나 믿을 수 있는가? 그리고 두 그룹 간 차이가 "진짜" 차이인가?
------------------------------------------------------------------------
## 표본이 하나뿐이라면?
- 지난 시간: 표본을 ***1,000번*** 반복 추출하여 표본 분포를 시뮬레이션했음.
- **현실**: 모집단에서 단 ***하나의 표본***만 얻을 수 있음. 비용과 시간 때문.
- 또한, 모집단의 ***진짜 모수***는 알 수 없음.
> **그렇다면 지난 시간에 한 것은 의미가 없었나?**
- 아니다. 관찰할 수는 없지만 ***표본 분포는 실제로 존재***하며,
우리는 CLT 덕분에 그것이 어떻게 행동하는지 알고 있음.
- 이제 이 지식을 ***단 하나의 표본***에서 활용하는 방법을 배움.
- **신뢰 구간**: 추정값의 불확실성을 범위로 표현
- **가설 검정**: "이 차이가 우연인가?"를 확률로 판단
# Confidence Intervals
------------------------------------------------------------------------
## 점 추정에서 신뢰 구간으로
- 지금까지 표본에서 ***점 추정치***만 계산했음: 표본 평균, 표본 비율, 회귀 계수 등.
- 이 ***표본 통계량***은 ***표본 변동성*** 때문에 진짜 모집단 모수와 다를 수 있음.
- 점 추정치 대신, 모집단 모수에 대한 ***가능한 값의 범위***를 제공할 수 있음.
- 이것이 바로 ***신뢰 구간 (Confidence Interval)*** 이 하는 일.
**비유 — 낚시**
| 방법 | 도구 | 비유 |
|:---|:---:|:---|
| 점 추정 | 작살 | 한 점을 정확히 겨냥 — 맞으면 좋지만 빗나가면 끝 |
| 신뢰 구간 | 그물 | 범위를 감싸서 잡음 — 더 믿을 수 있음 |
> 여기서 "물고기"는 모집단의 참값 $(p)$
------------------------------------------------------------------------
## 신뢰 구간 구축 방법
신뢰 구간을 구축하는 두 가지 주요 접근법:
| 방법 | 원리 | 특징 |
|:---|:---|:---|
| **이론적 접근** | CLT + 수학 공식 | R이 기본으로 사용하는 방식 |
| **시뮬레이션 접근** | 부트스트래핑 (Bootstrapping) | 직관적, 가정이 적음 |
- 오늘은 **시뮬레이션 접근(부트스트랩)** 에 집중하여 개념을 직관적으로 이해.
------------------------------------------------------------------------
## 다시 파스타로: 단 하나의 표본
- 파스타 그릇에서 ***단 하나의 랜덤 표본*** $(n=50)$ 만 얻을 수 있다고 가정.
- 단일 표본으로 표본 변동성을 어떻게 분석할 수 있을까?
`👉` ***Bootstrap Resampling*** 사용!
```{r, echo = FALSE}
bowl <- read.csv("https://www.dropbox.com/s/qpjsk0rfgc0gx80/pasta.csv?dl=1")
set.seed(1234)
sample_size = 50
my_sample = bowl %>%
mutate(color = as.factor(ifelse(color == "green","green","non-green"))) %>%
rep_sample_n(size = sample_size) %>%
ungroup() %>%
select(pasta_ID, color) %>%
arrange(pasta_ID)
```
```{r, echo=TRUE, eval = FALSE}
library(tidyverse)
bowl <- read.csv("https://www.dropbox.com/s/qpjsk0rfgc0gx80/pasta.csv?dl=1")
my_sample = bowl %>%
mutate(color = ifelse(color == "green","green","non-green")) %>%
rep_sample_n(size = 50) %>%
ungroup() %>%
select(pasta_ID, color)
```
::::: columns
::: {.column width="50%"}
```{r, echo=TRUE}
head(my_sample, 3)
```
:::
::: {.column width="50%"}
```{r, echo=TRUE}
p_hat = mean(my_sample$color == "green")
p_hat
```
이 표본에서 녹색 파스타의 비율: $\hat{p} = `r p_hat`$.
이것이 최선의 추정값이지만, 얼마나 불확실한가?
:::
:::::
------------------------------------------------------------------------
## 부트스트랩 아이디어: 표본에서 표본 만들기
**핵심 아이디어**: 모집단이 없으면, 내 표본을 "모집단처럼" 쓰면 된다.
::::: columns
::: {.column width="50%"}
**부트스트랩 표본 추출 절차**
1. 표본에서 파스타 1개를 무작위 선택 → 색상 기록
2. 선택한 파스타를 표본에 **다시 넣음** (복원추출)
3. 1–2를 반복 → 원래 표본 크기($n=50$)와 동일한 새 표본
4. 새 표본에서 $\hat{p}$ 계산
5. 이 과정을 1,000번 반복 → **부트스트랩 분포**
:::
::: {.column width="50%"}
**왜 복원추출인가?**
- 복원 없이 뽑으면 항상 같은 표본 → 변동성 없음
- 복원 추출이어야 표본마다 조금씩 다른 $\hat{p}$가 생성됨
- 이 변동성이 ***표본 변동성을 근사***함
> 핵심: 부트스트랩은 "단 하나의 표본"으로 표본 분포를 *흉내낸다*.
:::
:::::
------------------------------------------------------------------------
## 표본 재추출(Resampling)하기
::::: columns
::: {.column width="50%"}
- 하나의 부트스트랩 표본 예시
```{r echo=TRUE}
one_bootstrap = my_sample %>%
rep_sample_n(size = 50, replace = TRUE) %>%
arrange(pasta_ID)
head(one_bootstrap, 8)
nrow(one_bootstrap)
```
:::
::: {.column width="50%"}
- 같은 `pasta_ID`가 여러 번 등장함 → 복원추출의 특징
```{r echo=TRUE}
mean(one_bootstrap$color == "green")
```
- 원래 표본의 $\hat{p} = `r p_hat`$ 과 조금 다름.
- 이 과정을 1,000번 반복하면 → 매번 조금씩 다른 $\hat{p}$ 를 얻음.
- 이 1,000개의 $\hat{p}$ 분포 = ***부트스트랩 분포***.
:::
:::::
------------------------------------------------------------------------
## 부트스트랩 분포 생성하기
::::: columns
::: {.column width="50%"}
`infer` 패키지로 부트스트랩 수행
```{r, echo=FALSE}
bootstrap_distrib = my_sample %>%
specify(response = color, success = "green") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
percentile_95ci = get_confidence_interval(bootstrap_distrib, level = 0.95, type = "percentile")
percentile_95lb = percentile_95ci[[1]]
percentile_95ub = percentile_95ci[[2]]
```
```{r, echo=TRUE, eval = FALSE}
library(infer)
bootstrap_distrib = my_sample %>%
# 관심 변수와 성공 수준 지정
specify(response = color, success = "green") %>%
# 부트스트랩 표본 1,000개 생성
generate(reps = 1000, type = "bootstrap") %>%
# 각 표본에서 녹색 파스타 비율 계산
calculate(stat = "prop")
```
:::
::: {.column width="50%"}
부트스트랩 결과 확인
```{r}
head(bootstrap_distrib)
nrow(bootstrap_distrib)
```
1,000개의 $\hat{p}$ 값이 생성됨.\
이 분포를 시각화하면?
:::
:::::
------------------------------------------------------------------------
## 부트스트랩 분포
```{r, echo = FALSE, fig.height = 4.75, fig.width = 8}
boot_distrib_plot = bootstrap_distrib %>%
ggplot(aes(x = stat)) +
geom_histogram(boundary = 0.39, binwidth = 0.02, col = "white", fill = "darkgreen") +
labs(x = "Proportion of green pasta",
y = "Frequency") +
theme_bw(base_size = 14)
boot_distrib_plot
```
- ***부트스트랩 분포***는 ***표본 분포***를 근사하는 역할을 함.
- 분포의 중심은 원래 표본 $\hat{p}$에 가깝고, 퍼짐 정도가 추정의 불확실성을 나타냄.
------------------------------------------------------------------------
## 부트스트랩 분포와 평균
```{r, echo = FALSE, fig.height = 4.75, fig.width = 8}
boot_distrib_plot +
geom_vline(xintercept = mean(bootstrap_distrib$stat), linetype = "dashed", linewidth = 1) +
annotate("text", x = 0.375, y = 127, label = "bootstrap distribution mean", size = 4)
```
- 부트스트랩 분포의 평균은 원래 표본 비율 $\hat{p} = `r p_hat`$과 매우 가까움.
- 이제 이 분포에서 ***중앙 95%의 범위***를 신뢰 구간으로 사용하자.
------------------------------------------------------------------------
## 백분위수 방법: 95% 신뢰 구간
- 부트스트랩 분포에서 **중앙 95%**의 값을 사용하여 신뢰 구간 생성.
- 2.5% 및 97.5% 백분위수를 계산:
::::: columns
::: {.column width="50%"}
```{r, echo=TRUE}
quantile(bootstrap_distrib$stat, 0.025)
```
:::
::: {.column width="50%"}
```{r, echo=TRUE}
quantile(bootstrap_distrib$stat, 0.975)
```
:::
:::::
- **95% 신뢰 구간**: $[`r round(percentile_95lb, 2)`,\; `r round(percentile_95ub, 2)`]$
**`infer` 패키지로 한 번에 계산**
```{r, echo=TRUE}
ci_95 <- get_confidence_interval(bootstrap_distrib, level = 0.95, type = "percentile")
ci_95
```
------------------------------------------------------------------------
## 95% 신뢰 구간 시각화: 참값 포함 여부
```{r, echo = FALSE, fig.height = 4.75, fig.width = 8}
percentile_95lb = quantile(bootstrap_distrib$stat, 0.025)
percentile_95ub = quantile(bootstrap_distrib$stat, 0.975)
p = mean(bowl$color == "green")
boot_distrib_plot_ci = boot_distrib_plot +
geom_vline(xintercept = percentile_95lb, linetype = "dashed", linewidth = 1.5) +
geom_vline(xintercept = percentile_95ub, linetype = "dashed", linewidth = 1.5) +
annotate("rect", xmin=percentile_95lb, xmax=percentile_95ub, ymin=0, ymax=Inf, fill = "#d90502", alpha=0.4)
boot_distrib_plot_ci +
geom_vline(xintercept = p, col = "black", linewidth = 1.25) +
annotate("text", x = 0.56, y = 125, label = "population proportion (p)", size = 4)
```
- 붉은 영역이 95% 신뢰 구간. 실제 모집단 비율 $p$가 구간 내에 포함됨.
- 항상 포함될까? 다음 슬라이드에서 확인.
------------------------------------------------------------------------
## 신뢰 구간의 올바른 해석
```{r, echo=FALSE, fig.width=10, fig.height = 4}
library(purrr)
library(tidyr)
if(!file.exists("../rds/pasta_percentile_cis.rds")){
set.seed(5)
bootstrap_pipeline <- function(sample_data){
sample_data %>%
specify(formula = color ~ NULL, success = "green") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
}
pasta_percentile_cis <- bowl %>%
mutate(color = as.factor(ifelse(color == "green","green","non-green"))) %>%
rep_sample_n(size = 40, reps = 100, replace = FALSE) %>%
group_by(replicate) %>%
nest() %>%
mutate(sample_prop = map_dbl(data, ~mean(.x$color == "green"))) %>%
mutate(bootstraps = map(data, bootstrap_pipeline)) %>%
group_by(replicate) %>%
mutate(percentile_ci = map(bootstraps, get_ci, type = "percentile", level = 0.95))
saveRDS(object = pasta_percentile_cis, "../rds/pasta_percentile_cis.rds")
} else {
pasta_percentile_cis <- readRDS("../rds/pasta_percentile_cis.rds")
}
percentile_cis <- pasta_percentile_cis %>%
unnest(percentile_ci) %>%
mutate(captured = `2.5%` <= p & p <= `97.5%`)
ggplot(percentile_cis) +
geom_segment(aes(
y = replicate, yend = replicate, x = `2.5%`, xend = `97.5%`,
alpha = factor(captured, levels = c("TRUE", "FALSE"))
)) +
labs(x = "Proportion of green pasta", y = "Confidence interval number",
alpha = "Contains Truth") +
geom_vline(xintercept = p, color = "#d90502", linewidth = 1, linetype = "dashed") +
annotate("text", x = 0.47, y = 5, label = "population proportion", col = "#d90502") +
geom_point(aes(y = replicate, x = sample_prop,
alpha = factor(captured, levels = c("TRUE", "FALSE")))) +
coord_cartesian(xlim = c(0.2, 0.8)) +
coord_flip() +
theme_bw(base_size = 14) +
theme(panel.grid.major.y = element_blank(), panel.grid.minor.y = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = "top")
```
100개의 신뢰 구간 중 ***약 95개***가 실제 모수 $p$를 포함함.
------------------------------------------------------------------------
## 신뢰 구간 해석
> *해석**: 동일한 방법으로 신뢰 구간을 반복 생성하면, 그 중 **약 95%가 모집단 모수를 포함**할 것으로 기대된다.
**신뢰 구간의 폭에 영향을 주는 요인**
| 변화 | 구간 폭 | 이유 |
|:---|:---:|:---|
| 신뢰수준 ↑ (95% → 99%) | 넓어짐 | 더 많이 포함해야 하므로 |
| 표본 크기 ↑ | 좁아짐 | 표본 변동성 감소 → $SE$ 감소 |
------------------------------------------------------------------------
## 신뢰구간에서 가설검정으로
- 신뢰 구간은 **"모집단 모수가 어떤 범위에 있을까?"** 라는 질문에 답함.
- 그런데 경영 현장의 질문은 종종 이런 형태:
- 남성과 여성의 평균 임금 차이가 **통계적으로 유의미**한가?
- 신제품 출시 후 고객 전환율이 **실제로 올랐는가**, 아니면 우연인가?
- A안과 B안 중 어느 쪽이 **진짜 더 효과적**인가?
- 이런 질문에 답하는 도구: ***가설 검정 (Hypothesis Testing)***
| | 신뢰 구간 | 가설 검정 |
|:---|:---|:---|
| 질문 | 모수의 범위는? | 이 차이가 우연인가? |
| 결과 | 값의 범위 | 기각 / 기각 불가 |
| 활용 | 추정, 불확실성 정량화 | 의사결정, 차이 검증 |
# Hypothesis Testing
------------------------------------------------------------------------
## 은행 승진에서 성차별이 존재하는가?
- 1974년 *Journal of Applied Psychology* 연구: 은행 여직원 차별 여부 조사.
- 48명의 (남성) 관리자에게 **동일한 이력서** 제공, 지원자 이름만 남성/여성으로 구분.
- 이력서: *"지점장 승진 여부를 결정하는 요청 메모"* 형식.
- **검증하고자 하는 가설**: 승진에서 성차별이 존재하는가?
::::: columns
::: {.column width="50%"}
실험 데이터: `moderndive` 패키지의 `promotions` 데이터셋
```{r, echo=TRUE}
library(moderndive)
head(promotions)
```
:::
::: {.column width="50%"}
**이 실험이 중요한 이유**
- 이력서 내용이 **동일** → 성별 외 다른 변수 통제
- 즉, 승진 결정의 차이는 오직 **성별 때문**이어야 함
- 오늘날에도 A/B 테스트, 임금 감사 등 동일한 논리 적용
:::
:::::
------------------------------------------------------------------------
## 차별의 증거가 있는가?
::::: columns
::: {.column width="50%"}
성별별 승진 결정 집계
```{r, echo=FALSE}
promotions %>%
group_by(gender, decision) %>%
tally() %>%
mutate(percentage = 100 * n / sum(n))
```
- 남성 승진율: **87.5%**, 여성 승진율: **58.3%**
- 차이: **29.2%포인트**
:::
::: {.column width="50%"}
```{r, echo=FALSE, fig.height=8}
ggplot(promotions, aes(x = gender, fill = decision)) +
geom_bar(width = 0.75) +
labs(x = "Gender of name on resume",
y = "Frequency",
title = "Promotion decision by gender") +
theme_bw(base_size = 20) +
theme(legend.position = "top")
```
:::
:::::
> ***핵심 질문***: 이 29.2%p 차이가 성차별의 증거인가, 아니면 **우연**히 발생한 것인가?
------------------------------------------------------------------------
## 가상의 세계: 성차별이 없다면?
- 만약 성차별이 **존재하지 않는** 세상이라면, 승진 결정은 성별과 ***완전히 독립적***이어야 함.
- 이를 시뮬레이션하는 방법: `gender` 변수를 **무작위로 섞어** 재할당.
::::: columns
::: {.column width="50%"}
```{r, echo = TRUE}
promotions %>%
left_join(promotions_shuffled %>%
rename(shuffled_gender = gender)) %>%
head()
```
:::
::: {.column width="50%"}
```{r}
promotions_shuffled %>%
group_by(gender, decision) %>%
tally() %>%
mutate(percentage = 100 * n / sum(n))
```
- 무작위로 섞은 후 차이: **4.2%포인트** (원래 29.2%p → 대폭 감소)
:::
:::::
------------------------------------------------------------------------
## 표본 변동성을 고려해야 한다
- "성차별 없는 세계"에서 한 번 섞었을 때 4.2%p가 나왔음.
- 그런데 **다시 섞으면** 4.2%p가 또 나올까? 아니면 다른 값?
- 표본 변동성 때문에 매번 다른 값이 나옴 → 한 번의 결과만으로 판단 불가.
**우리가 알아야 할 것**:
> 성차별이 **없는** 세계에서, "무작위로 섞었을 때 29.2%p 이상의 차이가 나올 가능성"이 얼마나 되는가?
**방법**: 무작위 재배열을 **1,000번** 반복 → 각 번마다 차이 계산 → 분포 생성.
- 이것이 ***귀무분포 (Null Distribution)*** 임.
------------------------------------------------------------------------
## 가설 검정의 표기법 정의
**두 개의 경쟁 가설**
- ***귀무가설*** $H_0$: 기본 가설. 일반적으로 "차이 없음", "효과 없음".
- ***대립가설*** $H_A$: 연구자가 주장하는 가설.
**승진 실험의 가설**
$$H_0: p_m - p_f = 0 \quad \text{(성별 간 승진율 차이 없음)}$$
$$H_A: p_m - p_f > 0 \quad \text{(남성의 승진율이 더 높음)}$$
여기서 $p_m$ = 남성 승진 비율, $p_f$ = 여성 승진 비율.
- 위의 $H_A$는 ***단측 검정 (one-sided test)***: 방향이 있음 ($p_m > p_f$).
- ***양측 검정 (two-sided test)***: $H_A: p_m - p_f \neq 0$ (방향 무관, 차이만 검정).
------------------------------------------------------------------------
## 핵심 용어 정의
| 용어 | 정의 | 이 예시에서 |
|:---|:---|:---|
| **검정 통계량** (Test statistic) | 가설 검정에 사용되는 표본 통계량 | $\hat{p}_m - \hat{p}_f$ |
| **관측된 검정 통계량** (Observed test statistic) | 실제 데이터에서 관측된 값 | $0.292$ (29.2%p) |
| **귀무분포** (Null distribution) | $H_0$이 참일 때 검정 통계량의 분포 | 1,000번 섞어서 얻은 차이의 분포 |
| **p-값** (p-value) | $H_0$이 참일 때, 관측값이 나올 확률 | 아래에서 계산 |
| **유의수준** (Significance level, $\alpha$) | 귀무가설 기각의 컷오프 기준 | 통상 0.05 |
------------------------------------------------------------------------
## 귀무분포 생성: 1,000번의 무작위 재배열
```{r, echo = FALSE, fig.height = 4.75, fig.width = 8}
set.seed(2)
null_distribution <- promotions %>%
specify(formula = decision ~ gender, success = "promoted") %>%
hypothesize(null = "independence") %>%
generate(reps = 1000, type = "permute") %>%
calculate(stat = "diff in props", order = c("male", "female"))
visualize(null_distribution, bins = 10, fill = "darkred") +
geom_vline(xintercept = 0.292, linewidth = 1.25) +
labs(x = "Difference in promotion rates (male - female)",
y = "Frequency") +
xlim(-0.4, 0.4) +
annotate("text", x = 0.17, y = 485, label = "observed statistic (0.292)", size = 4) +
theme_bw(base_size = 14)
```
- 분포의 중심은 **0** 근처: 성차별이 없으면 차이가 0에 가까워야 함.
- 실제 관측값 **0.292**는 분포의 오른쪽 끝에 위치 → 매우 드문 값.
------------------------------------------------------------------------
## p-값 시각화
```{r, fig.height = 4.75, fig.width = 8, echo = FALSE}
obs_diff_prop <- promotions %>%
specify(decision ~ gender, success = "promoted") %>%
calculate(stat = "diff in props", order = c("male", "female"))
visualize(null_distribution, bins = 10, fill = "#d90502") +
shade_p_value(obs_stat = obs_diff_prop,
size = 0.5,
direction = "right",
fill = "blue") +
labs(x = "Differences in sample proportions (male - female)",
y = "Frequency") +
xlim(-0.4, 0.4) +
theme_bw(base_size = 14) +
geom_vline(xintercept = 0.292, linewidth = 1.25) +
annotate("text", x = 0.19, y = 485, label = "observed test statistic (0.292)", size = 4)
```
- **파란 영역** = p-값: $H_0$ 하에서 0.292 이상의 차이가 나올 확률.
------------------------------------------------------------------------
## p-값 계산 및 의사 결정
> ***p-값***: $H_0$이 참일 때, 관측된 검정 통계량과 **같거나 더 극단적인** 값을 관측할 확률.
```{r, echo=TRUE}
p_value <- mean(null_distribution$stat >= 0.292)
p_value
```
- 성차별이 없는 세계에서 $\hat{p}_m - \hat{p}_f \geq 0.292$ 일 확률: **`r 100*p_value`%**
**의사 결정** (유의수준 $\alpha = 0.05$)
| 비교 | 판단 |
|:---|:---|
| p-값 $(`r p_value`)$ $<$ $\alpha$ $(0.05)$ | $H_0$ **기각** |
| 해석 | 29.2%p 차이는 우연이 아닐 가능성이 높음 → 성차별의 통계적 증거 존재 |
> **만약 $\alpha = 0.01$로 설정했다면?** p-값이 0.01보다 작은지 확인 후 동일하게 판단.
------------------------------------------------------------------------
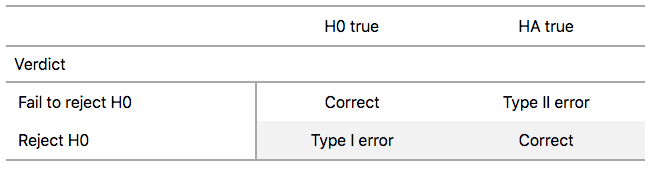
## 검정 오류 (Testing Errors)
- 확률을 다루기 때문에 **오류**를 피할 수 없음.
- 0.292의 차이는 $H_0$ 하에서 *드물지만* **불가능하지는 않음**.
::::: columns
::: {.column width="50%"}
:::
::: {.column width="50%"}
**제1종 오류 (Type I Error)**\
$H_0$이 *참인데* 기각 → **False Positive**\
*예: 실제로 차별이 없는데 "있다"고 결론*
유의수준 $\alpha$로 제어: $\alpha = 0.05$이면\
5% 이하의 확률로만 이 오류를 범함.
**제2종 오류 (Type II Error)**\
$H_0$이 *거짓인데* 기각 못함 → **False Negative**\
*예: 실제 차별이 있는데 "없다"고 결론*
:::
:::::
------------------------------------------------------------------------
## 통계적 추론과 회귀 분석의 연결
- 지금까지 배운 신뢰 구간·가설 검정 = ***통계적 추론 (Statistical Inference)***의 핵심 도구.
- 회귀 분석도 **표본 데이터**를 기반으로 하므로, 동일한 논리가 적용됨:
| 회귀 분석 출력값 | 통계적 추론 연결 |
|:---|:---|
| 회귀 계수 $\hat{\beta}_1$ | 점 추정량 — 표본 변동성에 영향받음 |
| 표준 오차 (Std. Error) | $\hat{\beta}_1$의 표본분포의 표준편차 |
| p-값 (Pr(>\|t\|)) | $H_0: \beta_1 = 0$ 하에서의 p-값 |
| 95% 신뢰 구간 | $\hat{\beta}_1 \pm 1.96 \times SE$ |
| t-값 (t-statistic) | 검정 통계량: $t = \hat{\beta}_1 / SE$ |
> **핵심**: 회귀 계수가 "유의미하다" = p-값 $< \alpha$ = 해당 변수가 결과에 **실제 영향을 미칠 가능성이 높음**.
# THE END!
------------------------------------------------------------------------
## Appendix: `infer` 파이프라인 전체 코드
::::: columns
::: {.column width="50%"}
```{r, echo=TRUE, eval = FALSE}
# 귀무분포 생성
null_distribution <- promotions %>%
# 변수와 성공 기준 지정
specify(formula = decision ~ gender,
success = "promoted") %>%
# 귀무가설: 성별과 승진 독립
hypothesize(null = "independence") %>%
# 1,000번 무작위 재배열
generate(reps = 1000, type = "permute") %>%
# 각 재배열에서 p_m - p_f 계산
calculate(stat = "diff in props",
order = c("male", "female"))
# 귀무분포 시각화
visualize(null_distribution,
bins = 10,
fill = "#d90502") +
labs(x = "Difference in promotion rates (male - female)",
y = "Frequency") +
xlim(-0.4, 0.4) +
theme_bw(base_size = 14)
```
:::
::: {.column width="50%"}
```{r, echo = FALSE, fig.height=6}
visualize(null_distribution, bins = 10, fill = "#d90502") +
labs(x = "Difference in promotion rates (male - female)",
y = "Frequency") +
xlim(-0.4, 0.4) +
theme_bw(base_size = 14)
```
:::
:::::