---
title: 计算机组成原理
date: 9997-12-29
tags: [计算机,计算机基础,计算机组成]
---
计算机组成原理笔记
## 0.1. 计算机系统的层次结构
应用软件、系统软件、硬件构成了计算机系统的三个层次结构。
```
软件
系统软件
操作系统
语言处理程序
标准库程序
服务性程序
数据库管理系统
计算机网络软件
应用软件
硬件
CPU(运算器、控制器、Cache)
运算器是处理数据的:数据加工。主要功能
算术运算,逻辑运算
所有的运算功能由一个被称为ALU(算术逻辑单元)的电路完成
功能强的ALU还能执行:定点运算、浮点运算,向量运算
暂放参加运算的数据和中间结果。(由多个通用寄存器来完成)
控制器是执行程序的
按规定管理 指挥(人的大脑)。处理指令的
功能:
正确执行每条指令(单个指令): 取⇒分析⇒执行
保证指令按规定序列自动连续执行(多个指令)
对异常情况和请求及时响应和处理
存储器是存储数据和程序的
三级存储系统
高速缓冲存储器
主存储器
辅助存储器
存储系统(高速缓存、主存储器、外存设备)
输入/ 输出设备等主要组成部分
系统总线
```
```
系统软件管理应用软件,直接管理硬件资源
TODO:它们[?谁]总是通过总线和接口连接在一起,构成一台完整的计算机
这三级存储器存储介质(半导体材料,磁性材料),工作原理和特性各不相同
```
计算机硬件的三个主要性能指标

借助系统总线的连接,计算机在各系统部件之间实现【地址信号、数据信号、控制信号】的传送
```
机器字长:CPU一次能处理数据的位数,通常与CPU的寄存器位数有关
指令字长:机器指令中二进制代码的总位数
存储字长:一个存储单元能存放的二进制数字位数
```
## 0.2. 计算机发展简史
```
冯.诺依曼体制特点:
【二进制】表示指令和数据
【存储程序】概念。(计算机不仅可以存储数据也可以存储程序)
计算机系统由【运算器、控制器、存储器、输入设备、输出设备】五大部件组成
运算器为核心
指令由操作码和地址码组成
指令在计算机中是顺序执行的,并受控制器的统一控制
```
```
现在的计算机结构(冯.诺依曼结构)
不改变的:存储程序(冯.诺依曼思想精华)
典型【冯.诺依曼】计算机结构以【运算器】为中心
改变的是:以【存储器】为中心,总线结构,分散控制
```
电子管计算机⇒晶体管计算机⇒中小规模集成电路计算机⇒超大规模集成电路计算机
```
计算机中【控制单元】负责指令译码。(控制器)
存储字是指存放在一个存储单元中的二进制【代码组合】
把汇编程序变成机器语言程序的过程是汇编(编译、编辑、链接)
计算机系统中算术逻辑单元和控制单元合称为【CPU】
存取速度:寄存器>cache>内存>外存
【兼容】是指计算机软件或硬件的通用性
```
https://blog.csdn.net/qq_41523096/article/details/86688528
## 0.3. 系统总线
### 0.3.1. 概念
```
总线不仅是指一组传输线,还包括相应的总线接口和总线控制器
分时共享是总线的主要特征
共享:是指总线所连接的各部件都通过共享它传递信号
分时:是指在某一时刻只允许有一个部件将信号发送上总线
```
总线所连的各个部件都应有三态门电路,这是最基本的总线接口逻辑电路
```
总线的基本结构
一组传输线总线接口(三态门)
总线接口寄存器(缓冲作用)
总线控制器(维护总线协议)
```
### 0.3.2. 分类
```
系统总线包括:数据总线、地址总线、控制总线和电源线
单向总线:地址总线
双向总线:数据总线、控制总线
都是并行总线
```
### 0.3.3. 结构
以存储器为中心的双总线结构(当前广泛使用),减轻了系统总线的负担
```
大多数计算机采用了分层次的多总线结构
速度差异较大的设备分享不同速度的总线,
速度相近的设备共享同一速度总线
```
### 0.3.4. 控制
总线的控制主要解决通信双方如何获知数据传输开始和传输结束,以及通信双方如何协调配合
```
线传输周期(总线周期)
一次总线操作所需要的时间。(分四个阶段:申请、寻址、传输、结束)
申请分配阶段:主设备提出申请,总线仲裁机构决定授予总线使用权
寻址阶段:主设备取得了总线使用权后,通过总线发出访问从设备的存储地址或设备地址及有关命令,启动传输
传输阶段:主设备和从设备之间进行数据交换
结束阶段:主设备从系统总线上撤出,并让出总线使用权
```
```
同步通信:
设置统一的时钟信号,数据传送时,收发双方严格遵循这个时钟信号。(和最慢的部件同步!!)
应用范围:总线上各部件间工作速度差异较小,其控制较简单,但时间利用率可能不高
异步通信:
没有统一的时钟信号,数据传送时,采用应答方式工作
应用范围:总线上各部件工作速度差异较大,传输时间可根据需要而定,时间利用率高,控制复杂
异步分为:不互锁、半互锁、全互锁
半同步通信:
将同步与异步相结合。既有公共时钟控制又允许不同速度部件谐和工作(插入等待周期。)
分离式通信:
充分挖掘系统总线每个瞬间的潜力
将一个总线传输周期分成两个子周期分给主从部件
```
### 0.3.5. 仲裁
```
连接到总线上的功能部件有主和从两种形态
如:CPU在不同的时间可以主动,也可以被动,但是存储器只能被动
【主设备】可以启动一个总线周期,【从设备】只能响应主部件的请求
每次总线操作,只能有一个【主设备】占用【总线控制权】,但同一时间里可以有一个或多个从设备
为了解决多个主设备同时竞争总线控制权,必须具有【总线仲裁部件】,以某种方式选择其中一个主设备作为总线的下一次主方
对多个主设备提出的总线请求,一般采用【优先级】或【公平】策略进行仲裁
除CPU外,输入输出设备也可以提出总线请求
对输入输出设备的总线请求采用【优先级】策略。
```
```
按照总线仲裁【电路的位置】不同,仲裁分为集中式和分布式仲裁两类。
集中式仲裁总线控制:总线控制逻辑电路基本集中在一起
分布式仲裁总线控制:总线控制逻辑基本分散在总线各个部件中
```
```
集中式仲裁
集中式仲裁中每个总线上的部件有两条线连仲裁器
一条是送往仲裁器的总线请求信号线BR
一条是仲裁器送出的总线授权信号线BG。
(1)链式查询方式
离仲裁器最近的设备具有最高优先级,通过接口的优先级排队电路来实现。
(2)计数器定时查询方式
(3)独立请求方式
```
https://blog.csdn.net/qq_41523096/article/details/86688682
## 0.4. 存储器
```
内存
在计算机中,存储正在运行的(部分)程序和数据的部件。
通过地址总线、数据总线、控制总线与CPU等其他部件相连
内存功能:存放程序和数据部件,并满足在计算机执行的过程中,能够随机访问这些程序和数据
①存(存放)
②取(访问)
```
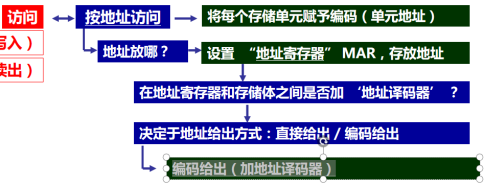
### 0.4.1. 存储器基本结构
```
存储体
地址寄存器
地址译码器
数据缓冲寄存器
读写控制线路
先送地址后读写数据
```
### 0.4.2. 存储器的分类
```
一个触发器能存储一位二进制代码。
一个触发器电路称为一个存储元(存储位),是存储器中的最小单位。
```
```
随机读写存储器(RAM):在程序执行过程中可读可写。
静态的和动态的RAM
SRAM 静态 作为cache
DRAM 动态 做内存 (因为需要刷新)
只读存储器(ROM):在程序执行过程中只读。
```
```
存储器的层次结构(三级存储系统):由系统统一调度、统一管理。
高速缓冲存储器(Cache)
高速缓冲存储器也有两神:
一是在CPU内(一级 CACHE、二级 CACHE)。CPU通过内部总线对其进行读/写操作
一是在CPU外(主板上)。CPU通过存储器总线对其进行读/写操作
主存储器(内存,Main memory)
围绕主存储器(内存)来组织和运行的。
SRAM存储器: 存取速度快、集成度低、位平均功耗高,小容量主存。
DRAM存储器: 存取速度慢、集成度高、位平均功耗低,大容量主存。(定时通电刷新)
性能指标:存储容量、存取时间、存储周期、存储器带宽。
辅助存储器(外存)
三个要点: 速度 容量 费用
离CPU越近的速度越快,越远容量越大
多级存储系统可以实现的前提: 程序运行时的局部性。
```
主存储器性能指标

CPU不能直接访问辅助存储器(外存),程序与数据从辅助存储器调入内存后,再从内存调入CACHE, CPU访问CACHE,读写程序和数据。
### 0.4.3. 存储单元(地址译码)
```
通过地址译码寻找存储单元,需要有译码器
地址译码器:把地址信号翻译成,对应存储单元的选择信号。
单译码器。
双译码器。
双译码比单译码使用的选择线少,可以减少芯片的引脚
```
### 0.4.4. 存储器(芯片封装)
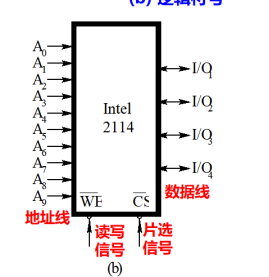
要会画芯片的封装
```
地址线,数据线(i/o),读写信号线(WE),片选信号线(CS)
```
## 0.5. 主存储器

### 0.5.1. 主存储器扩展
内存条是由多个存储芯片扩展而成。扩展后需要选芯片。扩展方法选择标准:片选信号越少越好
位扩展(数据线扩充)

字扩展(地址线扩充)

位字扩展(先位后字)

存储芯片无论位扩展还是字扩展,各芯片的片内地址线条条相并联。
即所有A0连在一起,所有A1连在一起,所有A2连在一起为什么?
各片內的存储单元地址相同,解决了地址线的扩充问题
### 0.5.2. 主存储器与CPU的连接
CPU对內存进行读写操作时,要给出**内存单元的地址信号**,给出**对内存单元进行操作的读写控制信号**,然后通过**数据总线**传输数据**信号**。
```
连接方法
CPU的地址总线:连接内存全部地址信号线;
CPU的控制总线:连接内存的读/写控制信号线;
CPU的数据总线:连接内存的数据线。
1)各扩展芯片的片内地址线、数据线、控制信号线:条条并连。
2)扩展后的产生的高位地址线:经译码,产生片选信号。
```
TODO:译码器的输出端和片选信号怎么连
存储器与CPU链接举例:

### 0.5.3. 主存读写周期与CPU的配合
```
在读过程中,地址信号不能变
在写过程中,地址信号、数据信号都不能变
```

### 0.5.4. 主存储器的刷新
**刷新周期**,DRAM 所有存储单元都被刷新一次的时间。一般为2ms。
整个主存中,各芯片可同时刷新,芯片内逐行刷新,每次刷新一行。
几种刷新方式:
```
1)集中式刷新
在2ms内按存储容量集中安排刷新时间(刷新期间停止读/写操作)
2)分散式刷新
把存取周期分成两部分。一半读写一半刷新,一个周期刷一行。
(如果CPU存取周期是主存存取周期的二倍,使用此方法好)
3)异步式刷新
在2ms内,分散式地对128行逐行刷新一遍,每一行平均刷新的时间
间隔为 2ms / 128 = 15.625us,即每隔15.6us提出一次刷新请求。
这样,每行之间的刷新间隔仍为2ms。
相对于分散式刷新,它减少了刷新次数;
相对于集中式刷新,它的主机“死区”缩短了很多
```
### 0.5.5. 主存储器的性能提高
```
提高主存制造技术
改进存储器结构
单体多字存储器
单体双端口存储器
多体交叉存储器(重点)
```


## 0.6. 高速缓冲存储器(Cache)
为了弥补主存速度的不足


`系统效率 = (Cache存取时间/平均存取时间)`
```
Cache 的全部功能都是由硬件完成的
内存地址 转 Cache地址)
先有内存的地址,然后再有cache的地址
```
## 地址映象
Cache与主存中存储单元地址映象关系
```
映象
物理意义:位置的对应关系
将主存地址变成Cache地址。
```
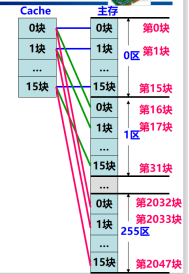
```
直接映象
方式:多对一映射
主存中的一块只能映象到Cache某一个固定的块中
特点:Cache的利用率不高
全相联映象
主存中任一块都可以映象到Cache中任一块上。
必须采用相联存储器
```

TODO:内存地址如何换成cache地址 4-04
## 替换算法
当未命中而将新的主存块调入Cache中,而它的位置已被占满,就会产生替换问题。
```
替换算法目的:获得最高命中率
先进先出算法 FIFO
最近最少使用算法 LRU
平均命中率 LRU>FIFO
LRU替换算法反映了程序的局部性特点
```