{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "ILsAojF_nXzT"
},
"source": [
"# Link to the lab\n",
"\n",
"https://tinyurl.com/inlplab5"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "KVkKP3mNWP4c"
},
"source": [
"# Setup\n",
"\n",
"We'll use fasttext wiki embeddings in our embedding layer"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"collapsed": true,
"id": "shI-n-rp8nU2",
"jupyter": {
"outputs_hidden": true
},
"outputId": "077dc499-179c-488b-fa2d-d79c881c5d56",
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Requirement already satisfied: fasttext in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (0.9.2)\n",
"Requirement already satisfied: pybind11>=2.2 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from fasttext) (2.10.0)\n",
"Requirement already satisfied: numpy in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from fasttext) (1.23.0)\n",
"Requirement already satisfied: setuptools>=0.7.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from fasttext) (61.2.0)\n",
"Requirement already satisfied: pytorch-crf in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (0.7.2)\n",
"Requirement already satisfied: datasets in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (2.4.0)\n",
"Requirement already satisfied: responses<0.19 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (0.18.0)\n",
"Requirement already satisfied: dill<0.3.6 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (0.3.5.1)\n",
"Requirement already satisfied: numpy>=1.17 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (1.23.0)\n",
"Requirement already satisfied: pyarrow>=6.0.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (9.0.0)\n",
"Requirement already satisfied: tqdm>=4.62.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (4.64.0)\n",
"Requirement already satisfied: aiohttp in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (3.8.1)\n",
"Requirement already satisfied: multiprocess in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (0.70.13)\n",
"Requirement already satisfied: requests>=2.19.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (2.28.1)\n",
"Requirement already satisfied: pandas in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (1.4.3)\n",
"Requirement already satisfied: xxhash in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (3.0.0)\n",
"Requirement already satisfied: fsspec[http]>=2021.11.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (2022.7.1)\n",
"Requirement already satisfied: huggingface-hub<1.0.0,>=0.1.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (0.9.1)\n",
"Requirement already satisfied: packaging in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from datasets) (21.3)\n",
"Requirement already satisfied: pyyaml>=5.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from huggingface-hub<1.0.0,>=0.1.0->datasets) (6.0)\n",
"Requirement already satisfied: filelock in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from huggingface-hub<1.0.0,>=0.1.0->datasets) (3.8.0)\n",
"Requirement already satisfied: typing-extensions>=3.7.4.3 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from huggingface-hub<1.0.0,>=0.1.0->datasets) (4.3.0)\n",
"Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from packaging->datasets) (3.0.9)\n",
"Requirement already satisfied: urllib3<1.27,>=1.21.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from requests>=2.19.0->datasets) (1.26.9)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from requests>=2.19.0->datasets) (2022.6.15)\n",
"Requirement already satisfied: charset-normalizer<3,>=2 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from requests>=2.19.0->datasets) (2.1.0)\n",
"Requirement already satisfied: idna<4,>=2.5 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from requests>=2.19.0->datasets) (3.3)\n",
"Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (4.0.2)\n",
"Requirement already satisfied: aiosignal>=1.1.2 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (1.2.0)\n",
"Requirement already satisfied: multidict<7.0,>=4.5 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (6.0.2)\n",
"Requirement already satisfied: attrs>=17.3.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (21.4.0)\n",
"Requirement already satisfied: yarl<2.0,>=1.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (1.8.1)\n",
"Requirement already satisfied: frozenlist>=1.1.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from aiohttp->datasets) (1.3.1)\n",
"Requirement already satisfied: pytz>=2020.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from pandas->datasets) (2022.1)\n",
"Requirement already satisfied: python-dateutil>=2.8.1 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from pandas->datasets) (2.8.2)\n",
"Requirement already satisfied: six>=1.5 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from python-dateutil>=2.8.1->pandas->datasets) (1.16.0)\n",
"Collecting sklearn\n",
" Using cached sklearn-0.0-py2.py3-none-any.whl\n",
"Collecting scikit-learn\n",
" Using cached scikit_learn-1.1.2-cp310-cp310-macosx_10_9_x86_64.whl (8.7 MB)\n",
"Collecting threadpoolctl>=2.0.0\n",
" Using cached threadpoolctl-3.1.0-py3-none-any.whl (14 kB)\n",
"Requirement already satisfied: scipy>=1.3.2 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from scikit-learn->sklearn) (1.9.0)\n",
"Requirement already satisfied: numpy>=1.17.3 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from scikit-learn->sklearn) (1.23.0)\n",
"Requirement already satisfied: joblib>=1.0.0 in /Users/knf792/miniconda3/envs/nlp-course/lib/python3.10/site-packages (from scikit-learn->sklearn) (1.1.0)\n",
"Installing collected packages: threadpoolctl, scikit-learn, sklearn\n",
"Successfully installed scikit-learn-1.1.2 sklearn-0.0 threadpoolctl-3.1.0\n"
]
}
],
"source": [
"!pip install fasttext\n",
"!pip install datasets\n",
"!pip install sklearn"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"id": "qTxj2GUD86Mt"
},
"outputs": [],
"source": [
"%reload_ext autoreload\n",
"%autoreload 2\n",
"%matplotlib inline"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"id": "K23XIfU19JC6"
},
"outputs": [],
"source": [
"import io\n",
"from math import log\n",
"from numpy import array\n",
"from numpy import argmax\n",
"import torch\n",
"import random\n",
"from math import log\n",
"from numpy import array\n",
"from numpy import argmax\n",
"import numpy as np\n",
"from torch.utils.data import Dataset, DataLoader\n",
"from torch import nn\n",
"from torch.optim import Adam\n",
"from torch.optim.lr_scheduler import ExponentialLR, CyclicLR\n",
"from typing import List, Tuple, AnyStr\n",
"from tqdm.notebook import tqdm\n",
"from sklearn.metrics import precision_recall_fscore_support\n",
"import matplotlib.pyplot as plt\n",
"from copy import deepcopy\n",
"from datasets import load_dataset\n",
"from sklearn.metrics import confusion_matrix\n",
"import torch.nn.functional as F\n",
"import heapq"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"id": "1WG_TMG29Jkh"
},
"outputs": [],
"source": [
"def enforce_reproducibility(seed=42):\n",
" # Sets seed manually for both CPU and CUDA\n",
" torch.manual_seed(seed)\n",
" torch.cuda.manual_seed_all(seed)\n",
" # For atomic operations there is currently \n",
" # no simple way to enforce determinism, as\n",
" # the order of parallel operations is not known.\n",
" # CUDNN\n",
" torch.backends.cudnn.deterministic = True\n",
" torch.backends.cudnn.benchmark = False\n",
" # System based\n",
" random.seed(seed)\n",
" np.random.seed(seed)\n",
"\n",
"enforce_reproducibility()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Y0-F6_Wb9Ams"
},
"source": [
"# Sequence Classification - recap\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kk7Nm4aD1Le_"
},
"source": [
"\n",
"Sequence classification is the task of \n",
"- predicting a class (e.g., POS tag) for each separate token in a textual input\n",
"- label tokens as beginning (B), inside (I), or outside (O) \n",
"- predicting which tokens from the input belong to a span, e.g.:\n",
" - which tokens from a document answer a given question (extractive QA)\n",
"\n",
" - which tokens in a news article contain propagandistic techniques\n",
"\n",
" - the spans can be of different types, e.g. type of a Named Entity (NE) -- Person, Location, Organisation\n",
" - ([More datasets for structured prediction](https://huggingface.co/datasets?languages=languages:en&task_categories=task_categories:structure-prediction&sort=downloads))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "OHp8Z6Pc89h7"
},
"source": [
"## Named entity recognition"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "viwPhyqMaQhi"
},
"source": [
"\n",
"\n",
"- identify the **entities** that appear in a document and their types\n",
"- e.g., extract from the following sentence all names of the people, locations, and organizations:\n",
"\n",
"\n",
"
\n",
"\n",
"
\n",
"
Sundar
\n",
"
Pichai
\n",
"
is
\n",
"
the
\n",
"
CEO
\n",
"
of
\n",
"
Alphabet
\n",
"
,
\n",
"
located
\n",
"
in
\n",
"
Mountain
\n",
"
View
\n",
"
,
\n",
"
CA
\n",
"
\n",
"
\n",
"
PER
\n",
"
PER
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
ORG
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
LOC
\n",
"
LOC
\n",
"
LOC
\n",
"
LOC
\n",
"
\n",
"\n",
"
\n",
"\n",
"- we have labelled all of the tokens associate with their classes as the given type (PER: Person, ORG: Organization, LOC: Location, O: Outside). **Question: What are some issues that could arise as a result of this tagging?"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bG7fTfhRdulS"
},
"source": [
"In practice, we will also want to denote which tokens are the beginning of an entity, and which tokens are inside the full entity span, giving the following tagging:\n",
"\n",
"\n",
"
\n",
"\n",
"
\n",
"
Sundar
\n",
"
Pichai
\n",
"
is
\n",
"
the
\n",
"
CEO
\n",
"
of
\n",
"
Alphabet
\n",
"
,
\n",
"
located
\n",
"
in
\n",
"
Mountain
\n",
"
View
\n",
"
,
\n",
"
CA
\n",
"
\n",
"
\n",
"
B-PER
\n",
"
I-PER
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
B-ORG
\n",
"
O
\n",
"
O
\n",
"
O
\n",
"
B-LOC
\n",
"
I-LOC
\n",
"
I-LOC
\n",
"
I-LOC
\n",
"
\n",
"\n",
"
\n",
"\n",
"**Question: What are some other tagging schemes that you think could be good?**\n",
"\n",
"Modeling the dependencies between the predictions can be useful: for example knowing that the previous tag was `B-PER` influences whether or not the current tag will be `I-PER` or `O` or `I-LOC`."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uOi3HWggedf9"
},
"source": [
"## Download and prepare the data\n",
"\n",
"We'll use a small set of Wikipedia data labelled with people, locations, organizations, and \"miscellaneous\" entities."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 569,
"referenced_widgets": [
"378fa5d2ca2d4005a0824d512c74bab9",
"054c24038d3e46559503463d23ddc389",
"d835d9ae913b4b8aa79195bbb65c67a2",
"100fee07db9a428ca681de6261a83220",
"878b7dbe92304f56be3f6cd519318522",
"d7fdc539d31c456498d6db7558c984fb",
"ab7ed4ca77bf4370820cdd932267885d",
"85b3a26f64e74fb299bea1ff292ec8c3",
"c537cce1751b48d482cfbcfc6611e64e",
"2b5d33ab96a746edbefa19cbbd3f28d8",
"7db97d142d2844fdb9b785cc7d9648f7",
"c7c6f6a5c86543f898e9598387d61437",
"8f4c1790ec104d208484a5e0b300d7bd",
"4373ceede55c499c9203d3fde6b31082",
"d12355d50fdc46f691212830c5510648",
"66fdff54c9fb4054b20461f69befb50a",
"e781457369704f12b9808104bcd8821f",
"f90f4b96b9c34ee79bf9db54d9376086",
"272da6e0838841a4a7107392d6e29f41",
"33640913b31b41a2a3e705cdee4e3324",
"f692ec41d40240508e620cc561355166",
"6ea12b0213b34770b91671d3ff7c90c9",
"8014b553c7214e85a760bdfdb56d20d5",
"bd909e355e85410683c23061f9e07518",
"ee98e3dec8e74ccda89c58ba82ad4f87",
"f01e0f0622a8403698d736e175cabd0f",
"a99fb612b1564315903fc6cac33259fb",
"520d60e185c7447f93e23c9accc27258",
"6b70e5760c6243248cb3c6d81723416c",
"58ee651ead9a408aae427ff74958ea4d",
"757d72ff8d77442687874f18efd8a31d",
"f3b08eaf8c754d5683a6442c29084d36",
"1c5b754a90354f739cb3e5660e1eeadf",
"be289fccdfa64228839b0b60774b29d9",
"aedc1a90c62f4385af8827f7203aaeba",
"eca645bca6f54b0580ad1d6fc3c02780",
"8f1fcc4069d34ac39fa705730cc62a3a",
"99f713f428d24c89a309b447bdc2cdf1",
"704acba671124ede9f4bcedfaa2217ed",
"9b55e7f888934a8cbb94e15946fd6653",
"d4052b6974ac4068a470650ce3863f94",
"4aa399acdf824ddc8f98d49ea633821e",
"d373c5ded26447bfb1a3ad0e86bb3720",
"76ce4bf8d41a4b51af901000791dbb76"
]
},
"id": "BoEPDmb6QTw5",
"outputId": "b4e2e71c-63f8-46f2-ae37-f4a3957850a1"
},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "90bc7b241ead44cb8b21bd98f95149dc",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Downloading builder script: 0%| | 0.00/2.58k [00:00] 650,22M 11,9MB/s in 49s \n",
"\n",
"2022-10-06 09:19:30 (13,3 MB/s) - ‘wiki-news-300d-1M.vec.zip’ saved [681808098/681808098]\n",
"\n",
"Archive: wiki-news-300d-1M.vec.zip\n",
" inflating: wiki-news-300d-1M.vec \n"
]
}
],
"source": [
"!wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip\n",
"!unzip wiki-news-300d-1M.vec.zip"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"id": "AU1ldp1VArxU"
},
"outputs": [],
"source": [
"# Reduce down to our vocabulary and word embeddings\n",
"def load_vectors(fname, vocabulary):\n",
" fin = io.open(fname, 'r', encoding='utf-8', newline='\\n', errors='ignore')\n",
" n, d = map(int, fin.readline().split())\n",
" tag_names = datasets[\"train\"].features[f\"ner_tags\"].feature.names\n",
" final_vocab = tag_names + ['[PAD]', '[UNK]', '[BOS]', '[EOS]']\n",
" final_vectors = [np.random.normal(size=(300,)) for _ in range(len(final_vocab))]\n",
" for j,line in enumerate(fin):\n",
" tokens = line.rstrip().split(' ')\n",
" if tokens[0] in vocabulary or len(final_vocab) < 30000:\n",
" final_vocab.append(tokens[0])\n",
" final_vectors.append(np.array(list(map(float, tokens[1:]))))\n",
" return final_vocab, np.vstack(final_vectors)\n",
"\n",
"class FasttextTokenizer:\n",
" def __init__(self, vocabulary):\n",
" self.vocab = {}\n",
" for j,l in enumerate(vocabulary):\n",
" self.vocab[l.strip()] = j\n",
"\n",
" def encode(self, text):\n",
" # Text is assumed to be tokenized\n",
" return [self.vocab[t] if t in self.vocab else self.vocab['[UNK]'] for t in text]"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "4OgHYnqV-CzF",
"outputId": "cead7528-df83-4a52-8261-ba9f26ff78c3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"size of vocabulary: 40630\n"
]
}
],
"source": [
"vocabulary = (set([t for s in datasets['train'] for t in s['tokens']]) | set([t for s in datasets['validation'] for t in s['tokens']]))\n",
"vocabulary, pretrained_embeddings = load_vectors('wiki-news-300d-1M.vec', vocabulary)\n",
"print('size of vocabulary: ', len(vocabulary))\n",
"tokenizer = FasttextTokenizer(vocabulary)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "03GlNGdjffvJ"
},
"source": [
"The main difference in the dataset reading and collation functions is that we now return a sequence of labels instead of a single label as in text classification."
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"id": "DDNdg8kNCYxa"
},
"outputs": [],
"source": [
"def collate_batch_bilstm(input_data: Tuple) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:\n",
" input_ids = [tokenizer.encode(i['tokens']) for i in input_data]\n",
" seq_lens = [len(i) for i in input_ids]\n",
" labels = [i['ner_tags'] for i in input_data]\n",
"\n",
" max_length = max([len(i) for i in input_ids])\n",
"\n",
" input_ids = [(i + [0] * (max_length - len(i))) for i in input_ids]\n",
" labels = [(i + [0] * (max_length - len(i))) for i in labels] # 0 is the id of the O tag\n",
"\n",
" assert (all(len(i) == max_length for i in input_ids))\n",
" assert (all(len(i) == max_length for i in labels))\n",
" return torch.tensor(input_ids), torch.tensor(seq_lens), torch.tensor(labels)"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "EAJsgXF_IZUQ",
"outputId": "b25fbeae-e7f8-4794-89a0-72b2f9bb8063"
},
"outputs": [
{
"data": {
"text/plain": [
"(tensor([[36231, 48, 10, 33561, 30770, 8120, 31121, 21803, 10, 36750,\n",
" 15]]),\n",
" tensor([11]),\n",
" tensor([[0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0]]))"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dev_dl = DataLoader(datasets['validation'], batch_size=1, shuffle=False, collate_fn=collate_batch_bilstm, num_workers=0)\n",
"next(iter(dev_dl))"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "AIHamPlSIgS5",
"outputId": "549bf33b-8cc7-4720-c255-5a877992f3d3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'id': '0', 'tokens': ['CRICKET', '-', 'LEICESTERSHIRE', 'TAKE', 'OVER', 'AT', 'TOP', 'AFTER', 'INNINGS', 'VICTORY', '.'], 'pos_tags': [22, 8, 22, 22, 15, 22, 22, 22, 22, 21, 7], 'chunk_tags': [11, 0, 11, 12, 13, 11, 12, 12, 12, 12, 0], 'ner_tags': [0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0]}\n",
"(tensor([[36231, 48, 10, 33561, 30770, 8120, 31121, 21803, 10, 36750,\n",
" 15]]), tensor([11]), tensor([[0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0]]))\n"
]
}
],
"source": [
"print(datasets['validation'][0])\n",
"print(collate_batch_bilstm([datasets['validation'][0]]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oo6sp4It9Txz"
},
"source": [
"# Creating the model"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cQIYJ0Q_gILv"
},
"source": [
"## LSTM model for sequence classification\n",
"\n",
"You'll notice that the BiLSTM model is mostly the same from the text classification and language modeling labs. "
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"id": "nVsVJgToVrdz"
},
"outputs": [],
"source": [
"# Define the model\n",
"class BiLSTM(nn.Module):\n",
" \"\"\"\n",
" Basic BiLSTM-CRF network\n",
" \"\"\"\n",
" def __init__(\n",
" self,\n",
" pretrained_embeddings: torch.tensor,\n",
" lstm_dim: int,\n",
" dropout_prob: float = 0.1,\n",
" n_classes: int = 2\n",
" ):\n",
" \"\"\"\n",
" Initializer for basic BiLSTM network\n",
" :param pretrained_embeddings: A tensor containing the pretrained BPE embeddings\n",
" :param lstm_dim: The dimensionality of the BiLSTM network\n",
" :param dropout_prob: Dropout probability\n",
" :param n_classes: The number of output classes\n",
" \"\"\"\n",
"\n",
" # First thing is to call the superclass initializer\n",
" super(BiLSTM, self).__init__()\n",
"\n",
" # We'll define the network in a ModuleDict, which makes organizing the model a bit nicer\n",
" # The components are an embedding layer, a 2 layer BiLSTM, and a feed-forward output layer\n",
" self.model = nn.ModuleDict({\n",
" 'embeddings': nn.Embedding.from_pretrained(pretrained_embeddings, padding_idx=pretrained_embeddings.shape[0] - 1),\n",
" 'bilstm': nn.LSTM(\n",
" pretrained_embeddings.shape[1], # input size\n",
" lstm_dim, # hidden size\n",
" 2, # number of layers\n",
" batch_first=True,\n",
" dropout=dropout_prob,\n",
" bidirectional=True),\n",
" 'ff': nn.Linear(2*lstm_dim, n_classes),\n",
" })\n",
" self.n_classes = n_classes\n",
" self.loss = nn.CrossEntropyLoss()\n",
" # Initialize the weights of the model\n",
" self._init_weights()\n",
"\n",
" def _init_weights(self):\n",
" all_params = list(self.model['bilstm'].named_parameters()) + \\\n",
" list(self.model['ff'].named_parameters())\n",
" for n,p in all_params:\n",
" if 'weight' in n:\n",
" nn.init.xavier_normal_(p)\n",
" elif 'bias' in n:\n",
" nn.init.zeros_(p)\n",
"\n",
" def forward(self, inputs, input_lens, hidden_states = None, labels = None):\n",
" \"\"\"\n",
" Defines how tensors flow through the model\n",
" :param inputs: (b x sl) The IDs into the vocabulary of the input samples\n",
" :param input_lens: (b) The length of each input sequence\n",
" :param labels: (b) The label of each sample\n",
" :return: (loss, logits) if `labels` is not None, otherwise just (logits,)\n",
" \"\"\"\n",
"\n",
" # Get embeddings (b x sl x edim)\n",
" embeds = self.model['embeddings'](inputs)\n",
"\n",
" # Pack padded: This is necessary for padded batches input to an RNN - https://stackoverflow.com/questions/51030782/why-do-we-pack-the-sequences-in-pytorch\n",
" lstm_in = nn.utils.rnn.pack_padded_sequence(\n",
" embeds,\n",
" input_lens.cpu(),\n",
" batch_first=True,\n",
" enforce_sorted=False\n",
" )\n",
"\n",
" # Pass the packed sequence through the BiLSTM\n",
" if hidden_states:\n",
" lstm_out, hidden = self.model['bilstm'](lstm_in, hidden_states)\n",
" else:\n",
" lstm_out, hidden = self.model['bilstm'](lstm_in)\n",
"\n",
" # Unpack the packed sequence --> (b x sl x 2*lstm_dim)\n",
" lstm_out, lengths = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)\n",
"\n",
" # Get logits (b x seq_len x n_classes)\n",
" logits = self.model['ff'](lstm_out)\n",
" outputs = (logits, lengths)\n",
" if labels is not None:\n",
" loss = self.loss(logits.reshape(-1, self.n_classes), labels.reshape(-1))\n",
" outputs = outputs + (loss,)\n",
"\n",
" return outputs"
]
},
{
"cell_type": "code",
"execution_count": 75,
"metadata": {
"id": "oH_92rb8VvEd"
},
"outputs": [],
"source": [
"def train(\n",
" model: nn.Module, \n",
" train_dl: DataLoader, \n",
" valid_dl: DataLoader, \n",
" optimizer: torch.optim.Optimizer, \n",
" n_epochs: int, \n",
" device: torch.device,\n",
" scheduler=None,\n",
"):\n",
" \"\"\"\n",
" The main training loop which will optimize a given model on a given dataset\n",
" :param model: The model being optimized\n",
" :param train_dl: The training dataset\n",
" :param valid_dl: A validation dataset\n",
" :param optimizer: The optimizer used to update the model parameters\n",
" :param n_epochs: Number of epochs to train for\n",
" :param device: The device to train on\n",
" :return: (model, losses) The best model and the losses per iteration\n",
" \"\"\"\n",
"\n",
" # Keep track of the loss and best accuracy\n",
" losses = []\n",
" learning_rates = []\n",
" best_f1 = 0.0\n",
"\n",
" # Iterate through epochs\n",
" for ep in range(n_epochs):\n",
"\n",
" loss_epoch = []\n",
"\n",
" #Iterate through each batch in the dataloader\n",
" for batch in tqdm(train_dl):\n",
" # VERY IMPORTANT: Make sure the model is in training mode, which turns on \n",
" # things like dropout and layer normalization\n",
" model.train()\n",
"\n",
" # VERY IMPORTANT: zero out all of the gradients on each iteration -- PyTorch\n",
" # keeps track of these dynamically in its computation graph so you need to explicitly\n",
" # zero them out\n",
" optimizer.zero_grad()\n",
"\n",
" # Place each tensor on the GPU\n",
" batch = tuple(t.to(device) for t in batch)\n",
" input_ids = batch[0]\n",
" seq_lens = batch[1]\n",
" labels = batch[2]\n",
"\n",
" # Pass the inputs through the model, get the current loss and logits\n",
" logits, lengths, loss = model(input_ids, seq_lens, labels=labels)\n",
" losses.append(loss.item())\n",
" loss_epoch.append(loss.item())\n",
"\n",
" # Calculate all of the gradients and weight updates for the model\n",
" loss.backward()\n",
"\n",
" # Optional: clip gradients\n",
" #torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)\n",
"\n",
" # Finally, update the weights of the model\n",
" optimizer.step()\n",
" if scheduler != None:\n",
" scheduler.step()\n",
" learning_rates.append(scheduler.get_last_lr()[0])\n",
"\n",
" # Perform inline evaluation at the end of the epoch\n",
" f1 = evaluate(model, valid_dl)\n",
" print(f'Validation F1: {f1}, train loss: {sum(loss_epoch) / len(loss_epoch)}')\n",
"\n",
" # Keep track of the best model based on the accuracy\n",
" if f1 > best_f1:\n",
" torch.save(model.state_dict(), 'best_model')\n",
" best_f1 = f1\n",
"\n",
" return losses, learning_rates"
]
},
{
"cell_type": "code",
"execution_count": 76,
"metadata": {
"id": "LQkyUeyhV1D3"
},
"outputs": [],
"source": [
"def evaluate(model: nn.Module, valid_dl: DataLoader):\n",
" \"\"\"\n",
" Evaluates the model on the given dataset\n",
" :param model: The model under evaluation\n",
" :param valid_dl: A `DataLoader` reading validation data\n",
" :return: The accuracy of the model on the dataset\n",
" \"\"\"\n",
" # VERY IMPORTANT: Put your model in \"eval\" mode -- this disables things like \n",
" # layer normalization and dropout\n",
" model.eval()\n",
" labels_all = []\n",
" preds_all = []\n",
"\n",
" # ALSO IMPORTANT: Don't accumulate gradients during this process\n",
" with torch.no_grad():\n",
" for batch in tqdm(valid_dl, desc='Evaluation'):\n",
" batch = tuple(t.to(device) for t in batch)\n",
" input_ids = batch[0]\n",
" seq_lens = batch[1]\n",
" labels = batch[2]\n",
" hidden_states = None\n",
"\n",
" logits, _, _ = model(input_ids, seq_lens, hidden_states=hidden_states, labels=labels)\n",
" preds_all.extend(torch.argmax(logits, dim=-1).reshape(-1).detach().cpu().numpy())\n",
" labels_all.extend(labels.reshape(-1).detach().cpu().numpy())\n",
"\n",
" P, R, F1, _ = precision_recall_fscore_support(labels_all, preds_all, average='macro')\n",
" print(confusion_matrix(labels_all, preds_all))\n",
" return F1"
]
},
{
"cell_type": "code",
"execution_count": 77,
"metadata": {
"id": "ycIjTfhBZGNJ"
},
"outputs": [],
"source": [
"lstm_dim = 128\n",
"dropout_prob = 0.1\n",
"batch_size = 8\n",
"lr = 1e-2\n",
"n_epochs = 10\n",
"n_workers = 0 # set to a larger number if you run your code in colab\n",
"\n",
"device = torch.device(\"cpu\")\n",
"if torch.cuda.is_available():\n",
" device = torch.device(\"cuda\")\n",
"\n",
"# Create the model\n",
"model = BiLSTM(\n",
" pretrained_embeddings=torch.FloatTensor(pretrained_embeddings), \n",
" lstm_dim=lstm_dim, \n",
" dropout_prob=dropout_prob, \n",
" n_classes=len(datasets[\"train\"].features[f\"ner_tags\"].feature.names)\n",
" ).to(device)"
]
},
{
"cell_type": "code",
"execution_count": 78,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 1000,
"referenced_widgets": [
"afc43fa359df4352ba07ba5e5d00054d",
"95164b73146c4484873e302a514db3cb",
"00fdcbd96cb94d3eb4ebce2dd65453df",
"69dac05df03a4505bf57ddee27c052c7",
"5230116d8f9d40fbb22be74eb6bddba8",
"04e7a1a51fc843a28998e9c233eb6b53",
"ed85ba97e4db4aa4870c97fb5dae9320",
"032c119a998a43efa68e584df3832d19",
"7afee097ce0d4179a71382e1a770347d",
"bba4178aa4d44e9d91190d821d05b7ee",
"2614645b079b49bea5d51d1f8d99a38f",
"f01071efe73b4151a3b75e73dd249c48",
"b314e1ca91b1434e951253e9bebf6b0b",
"0258bc4f1039499f8d27f95ea6881d4b",
"470e65e908714a76a9a1aaeb9b889b62",
"ca708c2a421b4dd9a744970e3d9ae610",
"70a96efaef804fd8ad5ce058b130a5d8",
"0dedc3af2f79435a8f866cd47b0258ff",
"47d6e470ee324f50aa0b2ff7539a5308",
"1d004bcd0131429296f108282d445751",
"5e341b1c7e5346caad69ba22a54ec4dc",
"dc5d256cae234801877fb9ce3ca792cf",
"8ce8e901bde44dd6bf7de4ca40f35a5b",
"e1c62c4d464b451ebf33b77b2e8dbba6",
"931f034c69de4c379d851d93eb1a9084",
"ddd1301e94394e62bacf916ad4880292",
"bfcbe3d471ad412ca4161ee4fbb4125d",
"485299f0fd8e4f5ba78bd3d109366717",
"a6d38f7eb3cf43b58c5335f3b5557ff6",
"969beef0e2184558a1c741abc45e021b"
]
},
"id": "xOdf3IBNV4hx",
"outputId": "5b93d989-a102-4195-d7ec-88af05f514a9"
},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "5f809429d2864a5583df712280a659ae",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/1756 [00:00"
]
},
"execution_count": 78,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)\n",
"valid_dl = DataLoader(datasets['validation'], batch_size=len(datasets['validation']), collate_fn=collate_batch_bilstm, num_workers=n_workers)\n",
"\n",
"# Create the optimizer\n",
"optimizer = Adam(model.parameters(), lr=lr)\n",
"scheduler = CyclicLR(optimizer, base_lr=0., max_lr=lr, step_size_up=1, step_size_down=len(train_dl)*n_epochs, cycle_momentum=False)\n",
"\n",
"# Train\n",
"losses, learning_rates = train(model, train_dl, valid_dl, optimizer, n_epochs, device, scheduler)\n",
"model.load_state_dict(torch.load('best_model'))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Learning rate schedules"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Motivation: \n",
"- speed up training\n",
"- to train a better model\n",
"\n",
"With Pytorch:\n",
"- choose a learning rate schedulers form `torch.optim.lr_schedule`\n",
"- add a line in your training loop which calls the `step()` function of your scheduler\n",
"- this will automatically change your learning rate! \n",
"- **Note**: be aware of when to call `step()`; some schedulers change the learning rate after every epoch, and some change after every training step (batch). The one we will use here changes the learning rate after every training step. We'll define the scheduler in the cell that calls the `train()` function. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set up hyperparameters and create the model. Note the high learning rate -- this is partially due to the learning rate scheduler we will use."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Above we have used the `CyclicLR` scheduler. The cyclic learning rate schedule in general looks like this:\n",
"\n",
"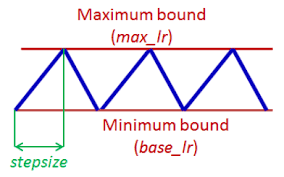 [Source](https://arxiv.org/pdf/1506.01186.pdf)\n",
"\n",
"We are using it here to linearly decay the learning rate from a starting max learning rate (here 1e-2) down to 0 over the entire course of training (essentially one cycle that starts at the max and ends at 0). \n",
"\n",
"\" Allowing the learning rate to rise and fall is beneficial overall\n",
"even though it might temporarily harm the network’s performance\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAXQAAAD4CAYAAAD8Zh1EAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAe8ElEQVR4nO3deZwU9Z3/8deHQzDxFjYSPFAX9aHrESSK2ejPJB6IBzGJ12a9kl03UX+rcXNgvIjJqokbk3giiTcqeKDgiiKeiOEahuEWGK5hLhhmYJhhGOb67h9d3dPdU33MTPdMV/t+Ph7zsLuqpvrTNfLu6k99q8qcc4iISPD16e0CREQkMxToIiJ5QoEuIpInFOgiInlCgS4ikif69dYLDxo0yA0bNqy3Xl5EJJAWLVq0zTk32G9erwX6sGHDKCgo6K2XFxEJJDPblGieWi4iInlCgS4ikicU6CIieUKBLiKSJxToIiJ5QoEuIpInFOgiInkicIG+urKO/5m5mppdTb1diohITglcoK+rqufRj4rZsrOxt0sREckpgQv0PmYA6L4cIiKxAhfoIiLiT4EuIpInAhvoDvVcRESiBS7QvRa6iIjECVygi4iIPwW6iEieCGyga9iiiEiswAW6WugiIv4CF+giIuJPgS4ikidSBrqZHWZmH5nZSjNbYWa3+CxjZvawmRWb2VIzG5GdckVEJJF+aSzTAvyXc67QzPYFFpnZLOfcyqhlLgCGez+nA094/80400B0ERFfKffQnXMVzrlC73EdsAoYGrfYWOB5FzIPOMDMhmS8WhERSahTPXQzGwZ8DZgfN2sosDnqeSkdQx8zu8HMCsysoKqqqnOViohIUmkHupntA7wO3Oqc29mVF3POTXTOjXTOjRw8eHBXVhG1rm79uohI3kkr0M2sP6Ewf9E5N9VnkTLgsKjnh3rTMk4ddBERf+mMcjHgKWCVc+6hBItNB67xRruMAmqdcxUZrFNERFJIZ5TLPwNXA8vMrMib9mvgcADn3ARgBjAGKAYagOszX6qIiCSTMtCdc3NI0elwzjngpkwVlQ5dD11EJFbgzhTVMHQREX+BC3QREfGnQBcRyROBDXSNQxcRiRXYQBcRkViBC3QdFBUR8Re4QBcREX8KdBGRPBHYQNcxURGRWIELdNPluUREfAUu0EVExJ8CXUQkTwQ20J3OLBIRiRG8QFcLXUTEV/ACXUREfCnQRUTyRGADXR10EZFYgQt0tdBFRPwFLtBFRMSfAl1EJE8ENtA1DF1EJFbgAt10QXQREV+BC3QREfGnQBcRyRMBDnQ10UVEogUu0NVBFxHxF7hAFxERfwp0EZE8EdhA1zh0EZFYgQt0DUMXEfEXuEAXERF/CnQRkTwR2EBXC11EJFbgAt00El1ExFfgAl1ERPwp0EVE8kRgA13j0EVEYqUMdDN72sy2mtnyBPPPNrNaMyvyfu7OfJnRr5fNtYuIBFe/NJZ5FngUeD7JMp865y7KSEUiItIlKffQnXOzgZoeqEVERLohUz30M8xsiZm9Y2YnJFrIzG4wswIzK6iqqurWCzo10UVEYmQi0AuBI5xzJwOPAG8mWtA5N9E5N9I5N3Lw4MFdejG10EVE/HU70J1zO51z9d7jGUB/MxvU7cpERKRTuh3oZnaIWWjsiZmd5q2zurvrFRGRzkk5ysXMXgbOBgaZWSlwD9AfwDk3AfgB8FMzawF2A1e6Hmhwq4MuIhIrZaA7565KMf9RQsMae4aa6CIivgJ7pqiIiMRSoIuI5InABrqGoYuIxApcoOt66CIi/gIX6CIi4k+BLiKSJxToIiJ5IrCB7nRqkYhIjMAFum5wISLiL3CBLiIi/hToIiJ5IriBrha6iEiMwAW6WugiIv4CF+giIuJPgS4ikicCG+hqoYuIxApcoHt3u2Nb/Z5erkREJLcELtBrdzcDcMvkol6uREQktwQu0Fvb2nq7BBGRnBS4QBcREX8BDHSNRBcR8RPAQNf4FhERPwEMdBER8RPAQFfLRUTET+ACvX5PS2+XICKSkwIX6IUl23u7BBGRnBS4QBcREX+BC3R10EVE/AUu0PvopqIiIr4CF+giIuJPgS4ikicCF+jquIiI+AtcoKuHLiLiL3CBLiIi/hToIiJ5QoEuIpInUga6mT1tZlvNbHmC+WZmD5tZsZktNbMRmS+z3Yefb83m6kVEAiudPfRngdFJ5l8ADPd+bgCe6H5ZidXsasrm6kVEAitloDvnZgM1SRYZCzzvQuYBB5jZkEwVGE9jXERE/GWihz4U2Bz1vNSblh1KdBERXz16UNTMbjCzAjMrqKqq6smXFhHJe5kI9DLgsKjnh3rTOnDOTXTOjXTOjRw8eHAGXlpERMIyEejTgWu80S6jgFrnXEUG1utLHRcREX/9Ui1gZi8DZwODzKwUuAfoD+CcmwDMAMYAxUADcH22igXYb+/+7GzUbehEROKlDHTn3FUp5jvgpoxVlML3vjaUhz8s7qmXExEJjMCdKdqnj5ouIiJ+AhfoIiLiL3CBrsvnioj4C1ygK85FRPwFLtBFRMRf4AJdHRcREX8BDHQluoiIn8AF+r4DUw6dFxH5QgpcoA/eZ0BvlyAikpMCF+giIuIvcIGuFrqIiL/ABbqIiPgLYKBrF11ExE8AA11ERPwELtDVQxcR8Re4QBcREX8KdBGRPBG4QNflc0VE/AUu0BXnIiL+Ahfo0VrbXG+XICKSMwId6NX1e3q7BBGRnBG4QFcLXUTEnwJdRCRPBC7QRUTEnwJdRCRPBC7QTQMXRUR8BS7QYyjbRUQigh3oGoYuIhIR7EAXEZGI4AW62iwiIr6CF+giIuJLgS4ikieCHehqv4iIRAQu0KMz/LT//oAdDU29VouISC4JXKDH27BtV2+XICKSEwIX6Karc4mI+ApeoMc/V8CLiABpBrqZjTaz1WZWbGbjfOZfZ2ZVZlbk/fxb5kv1d+OkRdTubu6plxMRyVkpA93M+gKPARcAxwNXmdnxPotOcc6d4v38LcN1JlRe28hL80t66uVERHJWOnvopwHFzrn1zrkmYDIwNrtliYhIZ6UT6EOBzVHPS71p8b5vZkvN7DUzO8xvRWZ2g5kVmFlBVVVVF8rVHYtERBLJ1EHRt4BhzrmTgFnAc34LOecmOudGOudGDh48OEMvnV2zVm5h+y6NdReR3JdOoJcB0Xvch3rTIpxz1c65Pd7TvwGnZqa8rpu/vpqfTSnCua5fY3f7rib+/fkC/v35ggxWJiKSHekE+kJguJkdaWZ7AVcC06MXMLMhUU8vAVZlrsSuufqpBbyxuIym1rYur6PZ+91NNQ2ZKktEJGv6pVrAOddiZjcDM4G+wNPOuRVmdi9Q4JybDvynmV0CtAA1wHXZKli3oBMR8Zcy0AGcczOAGXHT7o56fDtwe2ZLyx3d6NqIiPSYwJ0p6sd18150y0praWvzWYe+DIhIgAQu0DM9bLFgYw0XPzqHJ2evz+yKRUR6WOACvbNeml/Cwo01CeeX7dgNwKqKnUnWop6LiOS+vAj0P7y7OuG837y1kssmzE04P1l/XAdgRSRI8iLQ/aTbVw8v59fK6W5vXkSkJwUu0DO9zxzeQ0++Xu2pi0juC1ygZ1ok0JMebdWeuojkvrwM9G31e1IvFMcvztVDF5EgSevEolwy/Cv7+k53zmFmLNq0ne8/8fe016d9bxHJF4HbQx+87wDf6a8UhK7wuzLp8MOOXBpN9J2NLcxbX92p9SbS1uaYVlRGq9+JTCIi3RC4QE/krjdXJJ1/0viZkdCPFo5Vv/ZKuK3e1NLGlRPnUdvgf6u7I29/m9teKUqrztcKS7llchHPfLYhreVFRNKVN4Ge6qqKOxtbGD+9PfT3tLQyc0UlE70zRH2HLcbtRCd6DedgamGZ77x41fWha6tX1XW+zy8ikkzgeuippHMYc8GGGi5/MvZko546/LmjIRTo1bpphohkWN7soQMp+9J9vN1wv3643x56V64b09zaRkuSbwvha8a8tqiUleWd6/eLiCSTV4H+j3fMYG6Sg5fJ8jmdIYrpBPzxd7/LNx74MPWCQHFVfVrLiYikI68C3Tl4e2lFwvl1e1pYXVlHY3Nrl1+jaPMO/vz+moTzm1sdWzPYH3/kg7VMK2rvz3+6toqmlq7fhSmZ5WW1TJq3KSvrFpHsy7seeirn/3m27/Q+Ph9t8TvkTS1tfPexzwC49ZxjMlyZvz/OCn14jD1lKIUl27n6qQX82zeP5M6Ljs/Ya/zh3c95f9UW1mwJfWP411FHZGzdItJz8moPvXtS91OiL8N7eZIrOIa1tLYxad4mWtscK8preWl+SbcqrPFGyGzYtivy31PufY/S7d275+njH6+LhLmIBNcXbg89ke27mphWVMaJQ/fnqMH7+C5zy+T2seYLfK6xvmtPS8zzZz7byH/PWMVri0op2ryj0zXNXlOVdP7kBSXsaGjmrSUV/PTsozu9fhHJLwp0z7srKnl3RSUAj/9wBGcOH8Tf5nTu5J8/vhfbW9+xO7RHnSjMXZKLsVfU7uaapxf4ztvuDX2MnBTVjTGXd765rOu/nAXXPbOAbxx9MDecpQ8okc5SoPu48cXCLv3e7riDralGztwyuYjR/3QIA/r17TCvoanjgdtwgBeWhD4gwh8I3RlDP2le99pAmfbx6io+Xl2lQBfpAvXQMyh+TzmdPeeGPa0Ub61nccn2Tr9e+6V/O/2rGbejocn3RturK+s47q53KPdu9Sci2aNA74ZfvLqEUfd9EHleENdXTzdnz3noEy59PPYKkTt3+183xk+ybwIrymt9LzMwtbCUT9cm79Gna1v9Hk65d5bvcM4X5m2ksbmN91dtSbqOBRtq+Lzyi3ui1eaahsjBbpGuUsulG15dVBrzPHqkSHNrG9u6cXp/fD8eYOLsdTHPU/X4a3Y1ceHDc9h/7/4suee8mHm3vbKky7XFC19/fuaKLdx23rEx89K7IxQdLsXwRXPmHz4CYOMDF/ZyJdlVv6eFfn2Mgf07thml+7SHniW3T13W6WGKK8t3ctNLhUycvY6WttiTh4q31rFwY3tbJrq94ddyKdhYw4jfzgKgNm5vP509wU3Vuzp9ApbfPVjbD9yGipw0b1O39kQXl2xPejBZcs/WukYWbQr9v/tP98zk2//zce8WlMcU6FnyzrLEZ6wmMubhT3l7aQX3zficeetj2zfb6mP39udv6Dhs8hevLuGv3rVilpfVJnydVAd9W1rb+H8PfsxNaRwcnr++moU+tYRF9/mdc9z55nLGPjon5Xr9zFxRyaWP/50pC9svg7y5poFHP1wbE/Iry3eydktdl15DMu+ih+fE3HSmvLaxF6vJb4FsuRxx8JfYVN29k2myLfk9StstL08cvNEammLHuF/113kxr3XC3e+yyxsZc/4Jh1CwqfMHWcPC0fhJknHwy8tqOeLgL3HFxHkJl4ldW3u418WN109XeM9+fdQe/nXPLGBd1S4uHXEoe/fvy4Ff6s+Yhz8FOte+2L6rifLa3bxaUMrN3/5HBu3jfyMV6bxMXgpDkgtkoE/68emRnmOuqk8ztK5+yn+sebwfPVuQcJ5BJMwBznqw47apa2xm34H9WbuljtUpDj5OLyoHoC1Ba6OtzXHRI3P4+rADE65j7ZY6zv3TbI71bhloWGR9faI+7NZuqWPq4o7Xkm9qaWOvfrFfIP1+Pzy8s3zHbi6bMJdfnB/bww8r3lpHwcbtXHjSEPYd2D9mXl1jMxc9MocybyTOtvo9PPovIxK+N5FcFciWy35790+90BfIA+98nnKZu95czsZtuzj3T7NJdfe7/3o1dMA0erl3l1cyZWGJNz00I7qnD7E3BHmtMHTAeLXX+jBrX18fC4VmwcYarpg4jyc+jj3YC3DMne8wY1lFzHDH8HGDPlFffsKvWel9jf8gajRNRW3od99bUck5D81m3NRl3PzSYgCufXoBJ42fyZuLyzhx/HuRMIfUl2EWyVWBDPSB/QNZdtakulsTwJtF5ZzdjYNRP5m0iF+9Hjqr9OTfvJdwuVUVO1ldWceTn6yPmW60fxCYGRc9PIcfTJhLTZKRQDe+WMglXr+9qaWNusbQt56+UYkeXucK79ry0Vl8xv2hyxg/NKt9xNDS0h2s2VLHJ2uq2NnY4ttWiv5genH+prRvL5gJbW2Oos07OrTYwvOmLCxJ+2qbM5ZVUNeYePjr9CXlPKtbIWbEQ7PWMGzc277nYvQkJaN02i6fs1gB1m6t54K/fOp7RctxU5dx9oMfA6FwrtyZ3oGx8MHgUfd/ELk5SHTLJfzPZ8Inob38+DbR/e+sinm+vaGZkqjjL763Hozq+9/xxnKmFpbFjPhpbXM889kG9rR07TLM89dXc8vkxbS0tjFlYQn3TFsembekdAfffewzbp3c8UNk2pIyfvX6Mh7/uDhm+u6mVlbF3Ry9eGs9N75YyM9fTTw89T9fXsz4t1Z26T1IrMc+Cv1NWnt5BFYgA12j1nrOKwWbk15jvjPSDXE/0Xvy4UDfXNPQ4aSp+HbJk5+s7zDtraXlkcd9fRK9tc2xvqo+5ho8x931buTx64Wl/OatlTz2UcdWEcAbi0s7nGQW7YqJ85hWVM5v3lrJr15fxnNz269Bv9v7sHxv5RbueGMZjc2t7PT2ssPfUMLj/sNunbKYC/7yaWRvfGdjM1u8bV26vWfP0J04ex3Dxr2d9K5d+SgTl+HIhEAeFJWe88vXlvZ2Cfz/lxfHPO9j8MTH6/j9ux2PHfh94w0HYVh0m6WPT6C/v2or76/a6ltLSXVDZJs89el6zhw+iK8POyhmmZ9NCe0VR4+y+WRNFTsamhh7ytDItBd8biYSXf6L80t40TuXYeMDF0ZGTsW/x/AQ1pZWx56WVk4a394Sy8bOz+uLSrlvxioW3HEOffsYK8t3MmVhCeMvOSHS3mpqbaNf30DuL3ZJruxjfnG2uGTEz6b0XD857K0l5THP/zhrjW+YAx1aD9Dxm8GOhva+8pSCzfGLJ/Xz19pbGLuaWrlswtyEfer566sj9Vz79AJumVzEsHFvJ11/sgAOHzp4aX5JZD2tbS7yfpaW1XLC3TNjfmdlxU6mFZVR29DMtKIyRt33AS2tbWkdSI+3rX4PCzbUcOeby6ne1RRpOf3rU/N5bu6mmBuf1zW28OnaKrYm+Vb23N83Rk446q4nP1nHcXe9k5F1dUWudA0CuYfer09vf7H54nrDZ4jhF8Wna6t8d8X+5a/z+eXoY5mxrJLzjv9KZHrqMfod+Z1tG+bXHloQdVLXtQkut3xLXD++YNP2yDGHeMPGvc33Rgzl4pO+CsC3jvuHyLzLJsxlw7Zd7B132n64KuegsTnUahn959lsb2hmyP4DI8vVNsR+8N0zfQWQ+HyBppY2+vUx+iT4916/p4XirfWcctgB3J/kA6pmVxP7DezXI98Y4v96La1t1O5u5uAeOq8hkHvo/fr24YSv7tfbZcgXzNVPLfC9scmyslqufmoBLy8o4fpnF3b7Nfy8s6yCSfNjWzSXPzk3cm38znh+7sak86cWlnH9sws7vJfwiV2N3p75Kws38+7yisie+ZaovfHtXnhXRJ0VevK9/qOjlpfVxtwcprXN8d6KSo658x1ueKGAsh27cc5x1cR5zFxRGXMZge8+9lnMiKD4y0KUVDcw4rezGP/Wisi0Rz5Ym/SbUmVtI9X1e1hZ3rWLxUXXc/vUZZz6u/ezdh/geIHcQwd48AcnR84IFMl3P/W5DMOCDTUxe+jpmrGsMub5b/93JXdddHzSG4RvrmkfGRTOzPFvrWTfge0RclfUaJ3OuOiR0NDUST8+nW8OH8Qzn23gd2+HRieFjmd8yJrfXcDc9dXMXV8NwLSb/jny+4tL2g9et7Y5mlpbuXvaCm479xj+Y9Ki0LrnlXDyoQcw9pShkfv0Oud8z+gedX/7FVSfvm4kjc1tVNY2ctVph7O4ZDulO3Zz4YlD+PKA0HsPj3CB0M1sLpswlx+efnjk+AeELtYXf6JcNlg6Fzoys9HAX4C+wN+ccw/EzR8APA+cClQDVzjnNiZb58iRI11BQeKzH1Mp37GbbzzwYZd/X0TanXHUwZGw7E3r7xvDUb+e0WH6IfsNTGuU1MFf3iuml5/K/nv3p+jucznq1zM49fADufjkr0ZaQfFGHH5A5OYyAPddeiKLNm3n9cL2q64O2mdAh1FIAHv168PXhx3I0AP2ZuO2Bl75yRlp1xjPzBY550b6zksV6GbWF1gDnAuUAguBq5xzK6OWuRE4yTn3EzO7ErjUOXdFsvV2N9CBlAeYRERy0ayfncVw77IYnZUs0NP5DnAaUOycW++cawImA2PjlhkLPOc9fg34jqV7dapu2PjAhay7bwy/Gn0cf7riZL4adQBGRCRXnfunjiffZUI6PfShQPTYrlLg9ETLOOdazKwWOBjYFr2Qmd0A3ABw+OGHd7HkWH37WOSO92NOHEJdYwv7792fvuZ/dLyxuZXFJTso37Gbg/bZi211e9hU3cCN3zqaOWu3sd/e/Snx+oW/fG0p3znuH6hrbGHYoC/xwaqtHb7O7d2/b4d7iWbat44dzEerM3N3IRHpffdcfHxW1tujB0WdcxOBiRBquWR6/QP69WXAPsnvhDKwf1/OOPpg33nnnXAIAKOOCs2/fORhmS1QRCSL0mm5lAHRyXaoN813GTPrB+xP6OCoiIj0kHQCfSEw3MyONLO9gCuB6XHLTAeu9R7/APjQ6T5hIiI9KmXLxeuJ3wzMJDRs8Wnn3AozuxcocM5NB54CXjCzYqCGUOiLiEgPSquH7pybAcyIm3Z31ONG4LLMliYiIp0RyFP/RUSkIwW6iEieUKCLiOQJBbqISJ5I6+JcWXlhsyog8eXdkhtE3FmoOS5I9arW7AlSvao1e7pb7xHOucF+M3ot0LvDzAoSXZwmFwWpXtWaPUGqV7VmTzbrVctFRCRPKNBFRPJEUAN9Ym8X0ElBqle1Zk+Q6lWt2ZO1egPZQxcRkY6CuocuIiJxFOgiInkicIFuZqPNbLWZFZvZuF6q4TAz+8jMVprZCjO7xZs+3szKzKzI+xkT9Tu3ezWvNrPze/L9mNlGM1vm1VTgTTvIzGaZ2Vrvvwd6083MHvbqWWpmI6LWc623/FozuzbR63Wz1mOjtl+Rme00s1tzZdua2dNmttXMlkdNy9i2NLNTvb9Vsfe7Xb6VY4JaHzSzz7163jCzA7zpw8xsd9T2nZCqpkTvO8P1ZuzvbqFLgM/3pk+x0OXAM1nrlKg6N5pZkTe957atcy4wP4Qu37sOOArYC1gCHN8LdQwBRniP9yV0E+3jgfHAz32WP96rdQBwpPce+vbU+wE2AoPipv0BGOc9Hgf83ns8BngHMGAUMN+bfhCw3vvvgd7jA3vg710JHJEr2xY4CxgBLM/GtgQWeMua97sXZLjW84B+3uPfR9U6LHq5uPX41pTofWe43oz93YFXgCu9xxOAn2ay1rj5fwTu7ultG7Q99HRuWJ11zrkK51yh97gOWEXovqqJjAUmO+f2OOc2AMWE3ktvvp/oG3s/B3w3avrzLmQecICZDQHOB2Y552qcc9uBWcDoLNf4HWCdcy7ZGcU9um2dc7MJXfM/voZub0tv3n7OuXku9C/5+ah1ZaRW59x7zrkW7+k8QncgSyhFTYned8bqTaJTf3dvz/fbhG5i3+16k9XqvdblwMvJ1pGNbRu0QPe7YXWyIM06MxsGfA2Y70262fs6+3TU16REdffU+3HAe2a2yEI36gb4inOuwntcCXwlR2qNdiWx/yhycdtC5rblUO9x/PRs+RGhvcKwI81ssZl9YmZnetOS1ZTofWdaJv7uBwM7oj7MsrltzwS2OOfWRk3rkW0btEDPKWa2D/A6cKtzbifwBHA0cApQQehrVy74pnNuBHABcJOZnRU909s7yKnxq15/8xLgVW9Srm7bGLm4Lf2Y2R1AC/CiN6kCONw59zXgNuAlM9sv3fVl8X0H4u8e5ypid0R6bNsGLdDTuWF1jzCz/oTC/EXn3FQA59wW51yrc64N+Cuhr3+QuO4eeT/OuTLvv1uBN7y6tnhf+cJf/bbmQq1RLgAKnXNbvNpzctt6MrUty4htgWSlZjO7DrgI+KEXFniti2rv8SJCfehjUtSU6H1nTAb/7tWEWl794qZnlLf+7wFTot5Dj23boAV6OjeszjqvR/YUsMo591DU9CFRi10KhI+ATweuNLMBZnYkMJzQwZCsvx8z+7KZ7Rt+TOig2HJib+x9LTAtqtZrLGQUUOt99ZsJnGdmB3pfe8/zpmVLzF5OLm7bKBnZlt68nWY2yvt/7JqodWWEmY0Gfglc4pxriJo+2Mz6eo+PIrQd16eoKdH7zmS9Gfm7ex9cHxG6iX3W6gXOAT53zkVaKT26bdM9qpsrP4RGDqwh9Cl3Ry/V8E1CX4GWAkXezxjgBWCZN306MCTqd+7wal5N1MiFbL8fQkf7l3g/K8KvQain+AGwFngfOMibbsBjXj3LgJFR6/oRoYNPxcD1Wdy+Xya0R7V/1LSc2LaEPmQqgGZCPc8fZ3JbAiMJhdY64FG8s7kzWGsxoR5z+P/bCd6y3/f+/ygCCoGLU9WU6H1nuN6M/d29fwsLvG3wKjAgk7V6058FfhK3bI9tW536LyKSJ4LWchERkQQU6CIieUKBLiKSJxToIiJ5QoEuIpInFOgiInlCgS4ikif+D1RPiPE6XsNjAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.plot(losses)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYAAAAD4CAYAAADlwTGnAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO3dd3hUdfr+8feTSg8tItJCVYOAYChSklU6Kiiigl0RLCAl6+7KusWvu6vruhuagIKoWAERNTaaugkgLTTpEooUKaFIr/L5/THH/WWzAQJMMpPM/bquXJz5nDLPOQlz55wzecacc4iISOgJC3QBIiISGAoAEZEQpQAQEQlRCgARkRClABARCVERgS7gQlSsWNHFxcUFugwRkUJj8eLFe5xzsbnNK1QBEBcXR0ZGRqDLEBEpNMzsh7PN0yUgEZEQpQAQEQlRCgARkRClABARCVEKABGREJWnADCzTma2zswyzezpXOZHm9kkb/4CM4vzxiuY2TdmdtjMXs6xznVmtsJbZ4SZmT92SERE8ua8AWBm4cAooDMQD/Qys/gci/UG9jvn6gBDgRe98ePAH4Gnctn0GKAPUNf76nQxOyAiIhcnL2cAzYBM59xG59xJYCLQLccy3YAJ3vQUoK2ZmXPuiHNuDr4g+A8zqwyUcc7Nd75+1G8Bt17KjpzLiK/Ws3zrT/m1eRGRQikvAVAF2Jrt8TZvLNdlnHOngQNAhfNsc9t5tgmAmfU1swwzy8jKyspDuf/tp6MneW/BFm4bPZfnv1jDsZM/X/A2RESKoqC/CeycG+ucS3DOJcTG5vrXzOdUtkQUM5ITuatpdcamb6Tz8HTmbdibD5WKiBQueQmA7UC1bI+remO5LmNmEUAMcK5X2e3eds61Tb8pUyySF7o34L0+zXFAr3Hz+f1HKzh4/FR+PaWISNDLSwAsAuqaWU0ziwJ6Aqk5lkkFHvCmewBfu3N81qRzbgdw0MxaeO/+uR/45IKrv0Ata1dk2sBE+rSpycSFW+iQks5Xa3bl99OKiASl8waAd02/PzAdWANMds6tMrPnzKyrt9h4oIKZZQLJwH/eKmpmm4EU4EEz25btHURPAK8BmcAG4Ev/7NK5FY8K55mb4pn6RCtiikfSe0IGA95fyt7DJwri6UVEgoYVpg+FT0hIcP7sBnry9BlG/zuTUd9kUrpYJH++JZ6uja5Af5IgIkWFmS12ziXkNi/obwLnp6iIMAa1q8dnT7ahWvkSDJy4jEcmZLDjwLFAlyYiku9COgB+ceXlpZn6eEv+cNPVzN2whw4p6by3YAtnzhSesyMRkQulAPCEhxmPtKnF9EGJXFMlht9/tIK7X5vP5j1HAl2aiEi+UADkUKNCSd7r05y/d2/Aqu0H6TgsnbHpGzj985lAlyYi4lcKgFyYGT2bVWdmchJt6lbk+S/WcvuYb1m782CgSxMR8RsFwDlcHlOMcfcnMLJXY7btP8bNI+aQMvN7TpxWOwkRKfwUAOdhZtzS6ApmJidxc8PKjPhqPbeMnMPSLfsDXZqIyCVRAORR+ZJRDOvZmNcfTODQ8dN0H/Mtf/lsNUdPng50aSIiF0UBcIFuvKoSMwYnck/z6oyfs4mOw9KZm7kn0GWJiFwwBcBFKF0skr/e2oCJfVsQbsY9ry3g6Q+/48AxNZcTkcJDAXAJWtSqwLRBiTyaVIvJGVtpn5LGjFU7A12WiEieKAAuUbHIcIZ0vpqP+7WifMko+r69mP7vLWGPmsuJSJBTAPhJw6plSe3fml+3r8eMVbtol5LGR0u3UZia7YlIaFEA+FFURBhPtq3L5wNaU7NiSQZPWs7Dby7ix5/UXE5Ego8CIB/UrVSaKY+15E83xzN/4z7ap6Tx9vwf1FxORIKKAiCfhIcZD7euyYzBiTSuXo4/frySnmPnszHrcKBLExEBFAD5rlr5Erzduxn/uL0ha3YepPPw2bySpuZyIhJ4CoACYGbc2bQas5KTSKoXy9+/XMuto+ey+kc1lxORwFEAFKBKZYrx6n3XMfqeJuw8cJyuL8/hXzPWqbmciASEAqCAmRldGlRm5uAkul57BSO/zuSmEXNY/MO+QJcmIiFGARAg5UpGkXLntbz5UFOOnfyZHq/M49nUVRw5oeZyIlIwFAAB9qsrL2P64ETua1GDN7/dTMdh6cxenxXoskQkBCgAgkCp6Aie63YNkx+9nqjwMO4bv5DffLCcA0fVXE5E8o8CIIg0q1meLwa24Ylf1Wbq0u20G5rGtJVqLici+UMBEGSKRYbz205X8Um/VsSWiuaxdxbzxLuL2X3oeKBLE5EiRgEQpK6pEsMn/Vvxm45XMmvNbtqnpDNlsZrLiYj/KACCWGR4GP1uqMMXA9pQ57JSPPXBch54YxHb9h8NdGkiUgQoAAqBOpeV4oNHr+f/utYnY/M+OgxNZ8K3m9VcTkQuiQKgkAgLMx5oGceMwYkkxJXnz6mruPPVeWxQczkRuUgKgEKmarkSTHioKf+8oxHrdx+m8/DZjPomk1NqLiciF0gBUAiZGT2uq8rM5ETaXX0ZL01fR7eX57Jy+4FAlyYihUieAsDMOpnZOjPLNLOnc5kfbWaTvPkLzCwu27wh3vg6M+uYbXywma0ys5Vm9r6ZFfPHDoWSy0oXY/Q91/HKvU3YfegE3UbN5cVpazl+Ss3lROT8zhsAZhYOjAI6A/FALzOLz7FYb2C/c64OMBR40Vs3HugJ1Ac6AaPNLNzMqgADgATn3DVAuLecXIRO11Tmq+Qkujeuwph/b6DL8Nks2qzmciJybnk5A2gGZDrnNjrnTgITgW45lukGTPCmpwBtzcy88YnOuRPOuU1Aprc9gAiguJlFACWAHy9tV0JbTIlIXrqjEW893IwTp89wxyvz+NMnKzms5nIichZ5CYAqwNZsj7d5Y7ku45w7DRwAKpxtXefcduCfwBZgB3DAOTcjtyc3s75mlmFmGVlZapJ2Pon1YpkxOJEHW8bx9vwf6Dg0nbTvddxE5H8F5CawmZXDd3ZQE7gCKGlm9+a2rHNurHMuwTmXEBsbW5BlFloloyN4tmt9pjx2PcUiw3jg9YUkT17GT0dPBro0EQkieQmA7UC1bI+remO5LuNd0okB9p5j3XbAJudclnPuFDAVaHkxOyBnd12N8nw+oA39b6hD6rIfaZeSxhcrdqidhIgAeQuARUBdM6tpZlH4btam5lgmFXjAm+4BfO18rzKpQE/vXUI1gbrAQnyXflqYWQnvXkFbYM2l747kVCwynKc6Xskn/VtxeUwxnnh3CY+9s5jdB9VcTiTUnTcAvGv6/YHp+F6kJzvnVpnZc2bW1VtsPFDBzDKBZOBpb91VwGRgNTAN6Oec+9k5twDfzeIlwAqvjrF+3TP5L/WviOHjJ1rxu05X8c26LNqlpDE5Y6vOBkRCmBWmF4CEhASXkZER6DIKvY1Zh3n6wxUs3LyP1nUq8kL3BlQrXyLQZYlIPjCzxc65hNzm6S+BQ1Ct2FJM7NuCv9x6DUu37KfD0HTemLuJn9VcTiSkKABCVFiYcV+LGsxITqJ5rfL836erueOVb8ncfSjQpYlIAVEAhLgqZYvzxoNNGXpXIzbuOUKX4XMY+dV6NZcTCQEKAMHMuK1xVWYlJ9G+fiX+NfN7bhk5hxXb1FxOpChTAMh/VCwVzai7m/Dqfdex78hJuo2awwtfrlFzOZEiSgEg/6Nj/cuZmZzEnQnVeDVtI52Hz2bBxr2BLktE/EwBILmKKR7J329vyLuPNOf0mTPcNXY+f/h4BYeOnwp0aSLiJwoAOadWdSoyfVAivVvX5N0FW+g4NJ1v1u4OdFki4gcKADmvElER/PHmeD58vCUloyN46M1FDJ60jH1H1FxOpDBTAEieNalejs8GtGZA27p8uvxH2qek8enyH9VOQqSQUgDIBYmOCCe5fT0+fbI1VcoV58n3l9LnrcXsUnM5kUJHASAX5erKZZj6eEt+3+UqZq/3NZebuHCLzgZEChEFgFy0iPAw+ibWZvqgROIrl+HpqSu457UFbNl7NNCliUgeKADkksVVLMn7fVrw/G0N+G7bAToMS+O12RvVXE4kyCkAxC/Cwoy7m1dnZnIiLWtX5K+fr6H7mG9Zt1PN5USClQJA/KpyTHHGP5DA8J7XsnXfUW4eOZths77n5Gk1lxMJNgoA8Tszo9u1VZg5OJEuDSozbNZ6bhk5h+Vbfwp0aSKSjQJA8k2FUtEM79mY1+5P4MCxU9w2ei5/+3w1x06quZxIMFAASL5rF1+JGcmJ9GxWnXGzN9FpeDrzNqi5nEigKQCkQJQpFsnztzXgvT7NAeg1bj5Dpq7goJrLiQSMAkAKVMvaFZk2MJG+ibWYtGgL7VPSmLV6V6DLEglJCgApcMWjwvl9l6uZ+kQryhaP4pG3Mhjw/lL2Hj4R6NJEQooCQALm2mpl+fTJ1gxuV48vV+6gXUoanyzbrnYSIgVEASABFRURxsB2dfl8QBtqVCjJwInLeGRCBjsOHAt0aSJFngJAgkK9SqX58PGW/OGmq5m7YQ/tU9J5d8EPnFE7CZF8owCQoBEeZjzSphYzBiXRsGoMz3y0krtfm8/mPUcCXZpIkaQAkKBTvUIJ3n2kOX/v3oBV2w/ScVg6Y9M3cPpntZMQ8ScFgAQlM6Nns+rMTE6iTd1Ynv9iLd3HfMuaHQcDXZpIkaEAkKB2eUwxxt1/HS/f3Zjt+49xy8g5pMz8nhOn1U5C5FIpACTomRk3N7yCWclJ3NLoCkZ8tZ6bR8xhyZb9gS5NpFDLUwCYWSczW2dmmWb2dC7zo81skjd/gZnFZZs3xBtfZ2Yds42XNbMpZrbWzNaY2fX+2CEpusqVjGLoXdfyxoNNOXziNLeP+Za/fLaaoydPB7o0kULpvAFgZuHAKKAzEA/0MrP4HIv1BvY75+oAQ4EXvXXjgZ5AfaATMNrbHsBwYJpz7iqgEbDm0ndHQsENV13GjMGJ3NO8OuPnbKLjsHTmZu4JdFkihU5ezgCaAZnOuY3OuZPARKBbjmW6ARO86SlAWzMzb3yic+6Ec24TkAk0M7MYIBEYD+CcO+mcU7N4ybPSxSL5660NmNS3BRFhYdzz2gJ+N+U7DhxTczmRvMpLAFQBtmZ7vM0by3UZ59xp4ABQ4Rzr1gSygDfMbKmZvWZmJXN7cjPra2YZZpaRlZWVh3IllDSvVYEvB7bhsaTaTFmyjfYpacxYtTPQZYkUCoG6CRwBNAHGOOcaA0eA/7m3AOCcG+ucS3DOJcTGxhZkjVJIFIsM5+nOV/HxE62oUCqavm8vpt97S8g6pOZyIueSlwDYDlTL9riqN5brMmYWAcQAe8+x7jZgm3NugTc+BV8giFy0BlVjSO3fiqc61GPmql20H5rGR0u3qbmcyFnkJQAWAXXNrKaZReG7qZuaY5lU4AFvugfwtfP9r0sFenrvEqoJ1AUWOud2AlvN7EpvnbbA6kvcFxEiw8Pof2NdvhjYmloVSzJ40nIeenMR239SczmRnM4bAN41/f7AdHzv1JnsnFtlZs+ZWVdvsfFABTPLBJLxLuc451YBk/G9uE8D+jnnfvkLnieBd83sO+Ba4Hn/7ZaEujqXleaDx1ry51viWbBxHx1S0nh73mY1lxPJxgrT6XFCQoLLyMgIdBlSyGzdd5Tff7SC2ev30CyuPH+/vQG1YksFuiyRAmFmi51zCbnN018CS5FXrXwJ3nq4GS/1aMjanQfpNHw2Y/6t5nIiCgAJCWbGHQnVmJWcxA1XxvLitLXcOnouq39UczkJXQoACSmXlSnGq/clMOaeJuw8cIKuL8/hn9PXcfyUmstJ6FEASEjq3KAys5IT6XZtFV7+JpObRsxm8Q/7Al2WSIFSAEjIKlsiin/d2YgJDzfj+Kkz9HhlHs+mruLICTWXk9CgAJCQl1QvlumDE7m/RQ0mzNtMh6HppH+vtiNS9CkARIBS0RH8X7drmPzo9URHhnH/6wt56oPlHDiq5nJSdCkARLJpGleeLwa04Ylf1eajpdtpNzSNaSt3BLoskXyhABDJoVhkOL/tdBWf9GtFbKloHntnCY+/s5jdh44HujQRv1IAiJzFNVVi+KR/K37T8Uq+Wrub9inpTFms5nJSdCgARM4hMjyMfjfU4YsBbah7WSme+mA597++kK37jga6NJFLpgAQyYM6l5Vi8qPX81y3+iz5YT8dh6Xz5txNai4nhZoCQCSPwsKM+6+PY/rgRBLiyvPsp6u589V5ZO4+HOjSRC6KAkDkAlUtV4IJDzXlX3c0Yv3uw3QZPptR32RySs3lpJBRAIhcBDPj9uuqMis5iXbxl/HS9HV0e3kuK7cfCHRpInmmABC5BLGloxl9z3W8cm8Tsg6foNuoubw4ba2ay0mhoAAQ8YNO11Rm1uAkbm9ShTH/3kCX4bNZtFnN5SS4KQBE/CSmRCT/6NGId3o35+TPZ7jjlXn86ZOVHFZzOQlSCgARP2tdtyLTByXyUKs43p7/Ax2HpvPvdbsDXZbI/1AAiOSDktER/PmW+kx5rCXFo8J58I1FJE9exv4jJwNdmsh/KABE8tF1Ncrx+YDWPHljHVKX/Uj7oWl8/t0OtZOQoKAAEMln0RHh/LrDlaT2b03lmOL0e28Jj769mN0H1VxOAksBIFJA4q8ow0dPtGRI56tI+z6LtilpTF60VWcDEjAKAJECFBEexqNJtflyYBuurlyG3374HfeNV3M5CQwFgEgA1IotxcQ+LfjrrdewbOtPdBiazutzNvGzmstJAVIAiARIWJhxb4sazBicSPNa5Xnus9Xc8cq3rN91KNClSYhQAIgE2BVli/PGg00Zdte1bNpzhJtGzGHkV+s5eVrN5SR/KQBEgoCZcWvjKsxMTqLjNZfzr5nf0/XlOXy37adAlyZFmAJAJIhULBXNyF6NGXd/AvuPnuTWUXN54Ys1ai4n+UIBIBKE2sdXYsbgJO5qWo1X0zfSaVg68zfuDXRZUsQoAESCVEzxSF7o3pD3HmnOGQc9x87nmY9WcOj4qUCXJkVEngLAzDqZ2TozyzSzp3OZH21mk7z5C8wsLtu8Id74OjPrmGO9cDNbamafXeqOiBRVLetUZNqgNjzSuibvL9xCh6HpfLNWzeXk0p03AMwsHBgFdAbigV5mFp9jsd7AfudcHWAo8KK3bjzQE6gPdAJGe9v7xUBgzaXuhEhRVyIqgj/cHM+Hj7ekVHQED725iEETl7JPzeXkEuTlDKAZkOmc2+icOwlMBLrlWKYbMMGbngK0NTPzxic650445zYBmd72MLOqwE3Aa5e+GyKhoXH1cnw2oDUD29bl8xU7aJeSRuryH9VOQi5KXgKgCrA12+Nt3liuyzjnTgMHgArnWXcY8FvgnG92NrO+ZpZhZhlZWVl5KFekaIuOCGdw+3p8+mRrqpUrzoD3l9LnrcXsPKDmcnJhAnIT2MxuBnY75xafb1nn3FjnXIJzLiE2NrYAqhMpHK66vAxTn2jFM12uZk5mFu1T0nh/4RadDUie5SUAtgPVsj2u6o3luoyZRQAxwN5zrNsK6Gpmm/FdUrrRzN65iPpFQlp4mNEnsRbTBiZSv0oZhkxdwd3jFvDD3iOBLk0KgbwEwCKgrpnVNLMofDd1U3Mskwo84E33AL52vl9DUoGe3ruEagJ1gYXOuSHOuarOuThve1875+71w/6IhKS4iiV575EWPH9bA1ZuP0DHYem8NnujmsvJOZ03ALxr+v2B6fjesTPZObfKzJ4zs67eYuOBCmaWCSQDT3vrrgImA6uBaUA/55z+pFEkH4SFGXc3r86M5ERa1a7IXz9fQ/cx37Jup5rLSe6sMF0vTEhIcBkZGYEuQyToOef49LsdPJu6ikPHT9Hvhjo88as6REXobz9DjZktds4l5DZPPw0iRZCZ0bXRFcxKTqJLg8oMm7WeW0bOYdlWNZeT/08BIFKElS8ZxfCejRn/QAIHjp2i++i5/O3z1Rw7qSuxogAQCQltr67EjOREejarzrjZm+g4LJ1vN+wJdFkSYAoAkRBRplgkz9/WgPf7tMAM7h63gCFTV3BQzeVClgJAJMRcX7sC0wYm8mhiLSYt2kL7lDRmrd4V6LIkABQAIiGoeFQ4Q7pczcf9WlGuRBSPvJXBk+8vZe/hE4EuTQqQAkAkhDWsWpbU/q1Jbl+PaSt9zeU+WbZd7SRChAJAJMRFRYQxoG1dPh/QhhoVSjJw4jJ6T8jgx5+OBbo0yWcKABEBoF6l0nz4eEv+eHM88zbspcPQdN5d8ANn1E6iyFIAiMh/hIcZvVvXZPqgRBpVi+GZj1bSa9x8Nu1Rc7miSAEgIv+jeoUSvNO7OS/e3oDVOw7SaVg6r6Zt4PTP5/z4DilkFAAikisz466m1ZmVnERivVhe+HIt3cd8y5odBwNdmviJAkBEzqlSmWKMve86Rt3dhB9/OsYtI+eQMmMdJ06rnURhpwAQkfMyM25qWJmZg5Po2ugKRnydyc0j5rBky/5AlyaXQAEgInlWrmQUKXddyxsPNeXIidPcPuZbnvt0NUdPng50aXIRFAAicsFuuPIypg9O5N7mNXh9rq+53Jz1ai5X2CgAROSilC4WyV9uvYbJj15PRFgY945fwG+nLOfAMTWXKywUACJySZrVLM+XA9vw+K9q8+GS7bRPSWP6qp2BLkvyQAEgIpesWGQ4v+t0FR8/0YoKpaJ59O3F9Ht3CVmH1FwumCkARMRvGlSNIbV/K37T8Upmrt5F+6FpTF2yTc3lgpQCQET8KjI8jH431OGLga2pVbEkyZOX8+Abi9iu5nJBRwEgIvmizmWl+eCxljx7SzyLNu+jQ0oab83brOZyQUQBICL5JjzMeLCVr7lckxrl+NMnq7hr7Dw2ZB0OdGmCAkBECkC18iV46+FmvNSjIet2HqLz8NmM/nemmssFmAJARAqEmXFHQjVm/TqJG6+8jH9MW8eto+ey6scDgS4tZCkARKRAXVa6GK/cdx1j7mnCzgMn6PryXF6avpbjp9RcrqApAEQkIDo3qMys5ERua1yFUd9s4KYRs8nYvC/QZYUUBYCIBEzZElH8845GvPVwM46fOsMdr87j2dRVHDmh5nIFQQEgIgGXWC+WGYMTeeD6OCbM20yHoemkf58V6LKKPAWAiASFktERPNu1Ph88ej3RkWHc//pCnvpgOT8dPRno0oqsPAWAmXUys3VmlmlmT+cyP9rMJnnzF5hZXLZ5Q7zxdWbW0RurZmbfmNlqM1tlZgP9tUMiUrglxJXniwFt6HdDbT5aup12Kel8uWJHoMsqks4bAGYWDowCOgPxQC8zi8+xWG9gv3OuDjAUeNFbNx7oCdQHOgGjve2dBn7tnIsHWgD9ctmmiISoYpHh/KbjVaT2b0WlMtE8/u4SHn9nMbsPHQ90aUVKXs4AmgGZzrmNzrmTwESgW45lugETvOkpQFszM298onPuhHNuE5AJNHPO7XDOLQFwzh0C1gBVLn13RKQoqX9FDB/3a8XvOl3FV2t30z4lnQ8ytqq5nJ/kJQCqAFuzPd7G/75Y/2cZ59xp4ABQIS/repeLGgMLcntyM+trZhlmlpGVpZtCIqEmMjyMx39Vmy8HtqFepVL8Zsp33P/6QrbuOxro0gq9gN4ENrNSwIfAIOfcwdyWcc6Ndc4lOOcSYmNjC7ZAEQkatWNLManv9fylW32W/LCfjsPSeXPuJjWXuwR5CYDtQLVsj6t6Y7kuY2YRQAyw91zrmlkkvhf/d51zUy+meBEJLWFhxn3XxzF9cCJN48rz7KeruePVeWTuPhTo0gqlvATAIqCumdU0syh8N3VTcyyTCjzgTfcAvna+i3SpQE/vXUI1gbrAQu/+wHhgjXMuxR87IiKho2q5Erz5UFNS7mzEhqzDdBk+h1HfZHJKzeUuyHkDwLum3x+Yju9m7WTn3Coze87MunqLjQcqmFkmkAw87a27CpgMrAamAf2ccz8DrYD7gBvNbJn31cXP+yYiRZiZ0b1JVWYOTqJ9/Uq8NH0d3V6ey8rtai6XV1aY7qYnJCS4jIyMQJchIkFo+qqd/OHjlew7cpK+ibUY2LYuxSLDA11WwJnZYudcQm7z9JfAIlIkdKx/ObMGJ9GjSVXG/HsDXYbPZuEmNZc7FwWAiBQZMSUiebFHQ97p3ZyTP5/hzlfn8cePV3JYzeVypQAQkSKndd2KzBicyMOtavLOgh/okJLGN+t2B7qsoKMAEJEiqURUBH+6JZ4pj7WkRHQED72xiORJy9h/RM3lfqEAEJEi7boa5fh8QGsG3FiH1OU/0n5oGp9/t0PtJFAAiEgIiI4IJ7nDlXz6ZGsqxxSn33tLePTtxew6GNrN5RQAIhIyrq5cho+eaMmQzleR9n0W7VLSmLRoS8ieDSgARCSkRISH8WhSbaYNSuTqymX43YcruHf8ArbsDb3mcgoAEQlJNSuWZGKfFvz11mtYvvUAHYelM37OJn4OoeZyCgARCVlhYca9LWowY3AiLWqV5y+frabHK9+yfldoNJdTAIhIyLuibHFef7Apw3tey+Y9R7hpxBxGfLWek6eLdnM5BYCICL7mct2urcKs5CQ6XnM5KTO/p+vLc1i+9adAl5ZvFAAiItlUKBXNyF6NGXd/AvuPnuS20XN54Ys1HDv5c6BL8zsFgIhILtrHV2JmchJ3Na3Gq+kb6Tw8nfkb9wa6LL9SAIiInEWZYpG80L0h7z3SnDMOeo6dzzMfreDQ8VOBLs0vFAAiIufRsk5Fpg9KpE+bmry/cAsdhqbz9dpdgS7rkikARETyoHhUOM/cFM/UJ1pRplgkD7+ZwcCJS9l7+ESgS7toCgARkQtwbbWyfPpkawa1q8sXK3bQfmg6qct/LJTtJBQAIiIXKCoijEHt6vHZk22oVr4EA95fSp+3Mth5oHA1l1MAiIhcpCsvL83Ux1vyh5uuZk7mHtqnpPH+wsLTXE4BICJyCcLDjEfa1GL6oESuqRLDkKkruHvcAn7YeyTQpZ2XAkBExA9qVCjJe32a80L3Bqzc7msuNy59Y1A3l1MAiIj4iZnRq1l1ZiYn0bpORf72xRq6j57Lup3B2VxOASAi4meXxxRj3P0JjOzVmG37j1M1W90AAAhBSURBVHHzyNkMnfl90DWXUwCIiOQDM+OWRlcwMzmJmxpUZvhX67l55GyWBVFzOQWAiEg+Kl8yimE9G/P6gwkcOn6a7qPn8tfPVgdFczkFgIhIAbjxqkrMGJxIr2bVeW3OJjoOS+fbDXsCWpMCQESkgJQuFsnfbmvAxL4tCDO4e9wChkz9jgPHAtNcTgEgIlLAWtSqwLRBiTyaVItJi7bSYWgaM1cXfHM5BYCISAAUiwxnSOer+bhfK8qViKLPWxn0f28JewqwuZwCQEQkgBpWLUtq/9b8un09ZqzaRfuUND5eur1A2knkKQDMrJOZrTOzTDN7Opf50WY2yZu/wMziss0b4o2vM7OOed2miEioiIoI48m2dfl8QGviKpZk0KRl9J6QwY8/HcvX5z1vAJhZODAK6AzEA73MLD7HYr2B/c65OsBQ4EVv3XigJ1Af6ASMNrPwPG5TRCSk1K1UmimPteRPN8czb8NeOgxN5535P3Amn9pJ5OUMoBmQ6Zzb6Jw7CUwEuuVYphswwZueArQ1M/PGJzrnTjjnNgGZ3vbysk0RkZATHmY83LomMwYncm21svzh45X0HDefoydP+/258hIAVYCt2R5v88ZyXcY5dxo4AFQ4x7p52SYAZtbXzDLMLCMrKysP5YqIFH7Vypfg7d7N+MftDalZoSQloiL8/hxBfxPYOTfWOZfgnEuIjY0NdDkiIgXGzLizaTVe7NEwX7aflwDYDlTL9riqN5brMmYWAcQAe8+xbl62KSIi+SgvAbAIqGtmNc0sCt9N3dQcy6QCD3jTPYCvne89TKlAT+9dQjWBusDCPG5TRETy0XkvKjnnTptZf2A6EA687pxbZWbPARnOuVRgPPC2mWUC+/C9oOMtNxlYDZwG+jnnfgbIbZv+3z0RETkbKyyfXQmQkJDgMjIyAl2GiEihYWaLnXMJuc0L+pvAIiKSPxQAIiIhSgEgIhKiFAAiIiGqUN0ENrMs4IeLXL0iENiP38k71Zp/ClO9qjX/FKZ6L7XWGs65XP+KtlAFwKUws4yz3QkPNqo1/xSmelVr/ilM9eZnrboEJCISohQAIiIhKpQCYGygC7gAqjX/FKZ6VWv+KUz15lutIXMPQERE/lsonQGIiEg2CgARkRBV5AMgGD583syqmdk3ZrbazFaZ2UBv/Fkz225my7yvLtnWGeLVvM7MOhb0/pjZZjNb4dWV4Y2VN7OZZrbe+7ecN25mNsKr6Tsza5JtOw94y683swfO9nyXUOeV2Y7fMjM7aGaDgunYmtnrZrbbzFZmG/PbsTSz67zvVaa3rvm51pfMbK1Xz0dmVtYbjzOzY9mO8Svnq+ls++3HWv32fTdfu/oF3vgk87Wu92etk7LVudnMlnnjBXdcnXNF9gtfq+kNQC0gClgOxAegjspAE2+6NPA9EA88CzyVy/LxXq3RQE1vH8ILcn+AzUDFHGP/AJ72pp8GXvSmuwBfAga0ABZ44+WBjd6/5bzpcvn8/d4J1AimYwskAk2AlflxLPF9xkYLb50vgc5+rrUDEOFNv5it1rjsy+XYTq41nW2//Vir377vwGSgpzf9CvC4P2vNMf9fwJ8K+rgW9TOAoPjweefcDufcEm/6ELCGs3wGsqcbMNE5d8I5twnIxLcvgd6fbsAEb3oCcGu28becz3ygrJlVBjoCM51z+5xz+4GZQKd8rK8tsME5d66/Fi/wY+ucS8f3ORk567jkY+nNK+Ocm+98//vfyrYtv9TqnJvhfJ/1DTAf3yf4ndV5ajrbfvul1nO4oO+795v1jcCU/K7Ve647gffPtY38OK5FPQDy/OHzBcXM4oDGwAJvqL93av16ttO2s9VdkPvjgBlmttjM+npjlZxzO7zpnUClIKoXfB9ElP0/UbAeW/DfsaziTecczy8P4/vN8xc1zWypmaWZWRtv7Fw1nW2//ckf3/cKwE/Zgi8/j2sbYJdzbn22sQI5rkU9AIKKmZUCPgQGOecOAmOA2sC1wA58p4HBorVzrgnQGehnZonZZ3q/gQTNe4i967NdgQ+8oWA+tv8l2I7l2ZjZM/g+2e9db2gHUN051xhIBt4zszJ53V4+7Xeh+b5n04v//sWlwI5rUQ+AoPnweTOLxPfi/65zbiqAc26Xc+5n59wZYBy+01E4e90Ftj/Oue3ev7uBj7zadnmnob+cju4OlnrxBdUS59wur+6gPbYefx3L7fz3JZl8qdvMHgRuBu7xXmDwLqfs9aYX47uWXu88NZ1tv/3Cj9/3vfguv0XkGPcrb/vdgUnZ9qHAjmtRD4Cg+PB57xrfeGCNcy4l23jlbIvdBvzyDoFUoKeZRZtZTaAuvps/BbI/ZlbSzEr/Mo3vJuBK77l+effJA8An2eq933xaAAe809HpQAczK+edinfwxvLDf/0WFazHNhu/HEtv3kEza+H9nN2fbVt+YWadgN8CXZ1zR7ONx5pZuDddC9+x3Hiems623/6q1S/fdy/kvgF65FetnnbAWufcfy7tFOhxzetd7ML6he9dFd/jS9FnAlRDa3ynZN8By7yvLsDbwApvPBWonG2dZ7ya15HtXR0FsT/43hGx3Pta9cvz4Lsu+hWwHpgFlPfGDRjl1bQCSMi2rYfx3XDLBB7Kp3pL4vuNLSbbWNAcW3zBtAM4he+6bW9/HksgAd8L3QbgZby/8PdjrZn4rpP/8rP7irfs7d7PxzJgCXDL+Wo62377sVa/fd+9/wcLvf3/AIj2Z63e+JvAYzmWLbDjqlYQIiIhqqhfAhIRkbNQAIiIhCgFgIhIiFIAiIiEKAWAiEiIUgCIiIQoBYCISIj6f3x0Oxh6UrCwAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.plot(learning_rates)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Evaluate"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 328,
"referenced_widgets": [
"6cdc774b00ab477d956c98d936c2a422"
]
},
"id": "RWxwYR7KV-RA",
"outputId": "15ce76cc-1373-4dde-88ed-bca45b3bd1b9"
},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "7af82e38e7e94395b38173cdb0084ba9",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Evaluation: 0%| | 0/1 [00:00 best_f1:\n",
" torch.save(model.state_dict(), 'best_model')\n",
" best_f1 = f1\n",
"\n",
" return losses"
]
},
{
"cell_type": "code",
"execution_count": 84,
"metadata": {
"id": "OykuF5dURSd5"
},
"outputs": [],
"source": [
"softmax = nn.Softmax(dim=-1)\n",
"\n",
"def decode(model, inputs, input_lens, labels=None, beam_size=2):\n",
" \"\"\"\n",
" Decoding/predicting the labels for an input text by running beam search.\n",
"\n",
" :param inputs: (b x sl) The IDs into the vocabulary of the input samples\n",
" :param input_lens: (b) The length of each input sequence\n",
" :param labels: (b) The label of each sample\n",
" :param beam_size: the size of the beam \n",
" :return: predicted sequence of labels\n",
" \"\"\"\n",
"\n",
" assert inputs.shape[0] == 1\n",
" # first, encode the input text\n",
" encoder_output, encoder_hidden = model.model['encoder'](inputs, input_lens)\n",
" decoder_hidden = encoder_hidden\n",
"\n",
" # the decoder starts generating after the Begining of Sentence (BOS) token\n",
" decoder_input = torch.tensor([tokenizer.encode(['[BOS]',]),], device=device)\n",
" target_length = labels.shape[1]\n",
" \n",
" # we will use heapq to keep top best sequences so far sorted in heap_queue \n",
" # these will be sorted by the first item in the tuple\n",
" heap_queue = []\n",
" heap_queue.append((torch.tensor(0), tokenizer.encode(['[BOS]']), decoder_input, decoder_hidden))\n",
"\n",
" # Beam Decoding\n",
" for _ in range(target_length):\n",
" # print(\"next len\")\n",
" new_items = []\n",
" # for each item on the beam\n",
" for j in range(len(heap_queue)): \n",
" # 1. remove from heap\n",
" score, tokens, decoder_input, decoder_hidden = heapq.heappop(heap_queue)\n",
" # 2. decode one more step\n",
" decoder_output, decoder_hidden = model.model['decoder'](\n",
" decoder_input, decoder_hidden, torch.tensor([1]))\n",
" decoder_output = softmax(decoder_output)\n",
" # 3. get top-k predictions\n",
" best_idx = torch.argsort(decoder_output[0], descending=True)[0]\n",
" # print(decoder_output)\n",
" # print(best_idx)\n",
" for i in range(beam_size):\n",
" decoder_input = torch.tensor([[best_idx[i]]], device=device)\n",
" \n",
" new_items.append((score + decoder_output[0,0, best_idx[i]],\n",
" tokens + [best_idx[i].item()], \n",
" decoder_input, \n",
" decoder_hidden))\n",
" # add new sequences to the heap\n",
" for item in new_items:\n",
" # print(item)\n",
" heapq.heappush(heap_queue, item)\n",
" # remove sequences with lowest score (items are sorted in descending order)\n",
" while len(heap_queue) > beam_size:\n",
" heapq.heappop(heap_queue)\n",
" \n",
" final_sequence = heapq.nlargest(1, heap_queue)[0]\n",
" assert labels.shape[1] == len(final_sequence[1][1:])\n",
" return final_sequence"
]
},
{
"cell_type": "code",
"execution_count": 85,
"metadata": {
"id": "9tV1Sdlze9eO"
},
"outputs": [],
"source": [
"def evaluate(model: nn.Module, valid_dl: DataLoader, beam_size:int = 1):\n",
" \"\"\"\n",
" Evaluates the model on the given dataset\n",
" :param model: The model under evaluation\n",
" :param valid_dl: A `DataLoader` reading validation data\n",
" :return: The accuracy of the model on the dataset\n",
" \"\"\"\n",
" # VERY IMPORTANT: Put your model in \"eval\" mode -- this disables things like \n",
" # layer normalization and dropout\n",
" model.eval()\n",
" labels_all = []\n",
" logits_all = []\n",
" tags_all = []\n",
"\n",
" # ALSO IMPORTANT: Don't accumulate gradients during this process\n",
" with torch.no_grad():\n",
" for batch in tqdm(valid_dl, desc='Evaluation'):\n",
" batch = tuple(t.to(device) for t in batch)\n",
" input_ids = batch[0]\n",
" input_lens = batch[1]\n",
" labels = batch[2]\n",
"\n",
" best_seq = decode(model, input_ids, input_lens, labels=labels, beam_size=beam_size)\n",
" mask = (input_ids != 0)\n",
" labels_all.extend([l for seq,samp in zip(list(labels.detach().cpu().numpy()), input_ids) for l,i in zip(seq,samp) if i != 0])\n",
" tags_all += best_seq[1][1:]\n",
" # print(best_seq[1][1:], labels)\n",
" P, R, F1, _ = precision_recall_fscore_support(labels_all, tags_all, average='macro')\n",
" print(confusion_matrix(labels_all, tags_all))\n",
" return F1"
]
},
{
"cell_type": "code",
"execution_count": 88,
"metadata": {
"id": "4KjDoQkl8Omy"
},
"outputs": [],
"source": [
"lstm_dim = 300\n",
"dropout_prob = 0.1\n",
"batch_size = 64\n",
"lr = 1e-3\n",
"n_epochs = 20\n",
"n_workers = 0\n",
"\n",
"device = torch.device(\"cpu\")\n",
"if torch.cuda.is_available():\n",
" device = torch.device(\"cuda\")\n",
"\n",
"# Create the model\n",
"model = Seq2Seq(\n",
" pretrained_embeddings=torch.FloatTensor(pretrained_embeddings), \n",
" lstm_dim=lstm_dim, \n",
" dropout_prob=dropout_prob, \n",
" n_classes=len(datasets[\"train\"].features[f\"ner_tags\"].feature.names)\n",
" ).to(device)"
]
},
{
"cell_type": "code",
"execution_count": 90,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 1000,
"referenced_widgets": [
"e69a0f48b8104bd29adfab7a1409d1d4",
"ce96995f8d93445a93d4cb357ec3c72c",
"a86d9662ed444599a707f383ef9293ad",
"7ec12acc502c4bafa871a289054204b2",
"927b8def881c449abcfb01750074aaef",
"79da7ceb7e17457aaea7dd19ec96c0a2",
"8d6f82061cee47aca199947061c51514",
"66098eb69aaf4486bb2eddf5de1be7f4",
"f2944271cf214122a7cbea8952d9b6ba",
"b09a25113e134475b06d53d60538dbd0",
"24d8f5b9572049f9aa34c0a91142473b"
]
},
"id": "iHvNb7nm6kLI",
"outputId": "0436841f-d3a3-44aa-bc76-b9eda50f2fac"
},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "13dd97cb90cf43cfb2de15168cf9e933",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/220 [00:00"
]
},
"execution_count": 90,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)\n",
"valid_dl = DataLoader(datasets['validation'], batch_size=1, collate_fn=collate_batch_bilstm, num_workers=n_workers)\n",
"\n",
"# Create the optimizer\n",
"optimizer = Adam(model.parameters(), lr=lr)\n",
"\n",
"# Train\n",
"losses = train(model, train_dl, valid_dl, optimizer, n_epochs, device)\n",
"model.load_state_dict(torch.load('best_model'))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R80wA-upBHDD"
},
"source": [
"**Question: Do you have ideas how to improve the model?**\n",
"How about adding attention mechanism for the decoder to attend to the separate hidden states of the separate token steps in the encoder? (see the resources)\n"
]
},
{
"cell_type": "code",
"execution_count": 68,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 311
},
"id": "o1yYPFe5wKC5",
"outputId": "95db2ec2-2fdf-444b-9dad-42c2d7615094"
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:481: UserWarning: This DataLoader will create 8 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.\n",
" cpuset_checked))\n",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:17: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0\n",
"Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "a8d16dfe21b74ea98e7853171b8c66a1",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Evaluation: 0%| | 0/3453 [00:00