Getting data from the web: API access
library(tidyverse)
library(forcats)
library(broom)
library(wordcloud)
library(tidytext)
set.seed(1234)
theme_set(theme_minimal())Methods for obtaining data online
There are many ways to obtain data from the Internet. Four major categories are:
- click-and-download on the internet as a “flat” file, such as .csv, .xls
- install-and-play an API for which someone has written a handy R package
- API-query published with an unwrapped API
- Scraping implicit in an html website
Click-and-Download
In the simplest case, the data you need is already on the internet in a tabular format. There are a couple of strategies here:
- Use
read.csvorreadr::read_csvto read the data straight into R - Use the
downloaderpackage orcurlfrom the shell to download the file and store a local copy, then useread_csvor something similar to read the data into R- Even if the file disappears from the internet, you have a local copy cached
Even in this instance, files may need cleaning and transformation when you bring them into R.
Data supplied on the web
Many times, the data that you want is not already organized into one or a few tables that you can read directly into R. More frequently, you find this data is given in the form of an API. Application Programming Interfaces (APIs) are descriptions of the kind of requests that can be made of a certain piece of software, and descriptions of the kind of answers that are returned. Many sources of data - databases, websites, services - have made all (or part) of their data available via APIs over the internet. Computer programs (“clients”) can make requests of the server, and the server will respond by sending data (or an error message). This client can be many kinds of other programs or websites, including R running from your laptop.
Install and play packages
Many common web services and APIs have been “wrapped”, i.e. R functions have been written around them which send your query to the server and format the response.
Why do we want this?
- provenance
- reproducible
- updating
- ease
- scaling
Sightings of birds: rebird
rebird is an R interface for the ebird database. e-Bird lets birders upload sightings of birds, and allows everyone access to those data.
install.packages("rebird")library(rebird)Search birds by geography
The ebird website categorizes some popular locations as “Hotspots”. These are areas where there are both lots of birds and lots of birders. Once such location is at Lincoln Park Zoo in Chicago. You can see data for this site at http://ebird.org/ebird/hotspot/L1573785
At that link, you can see a page like this:
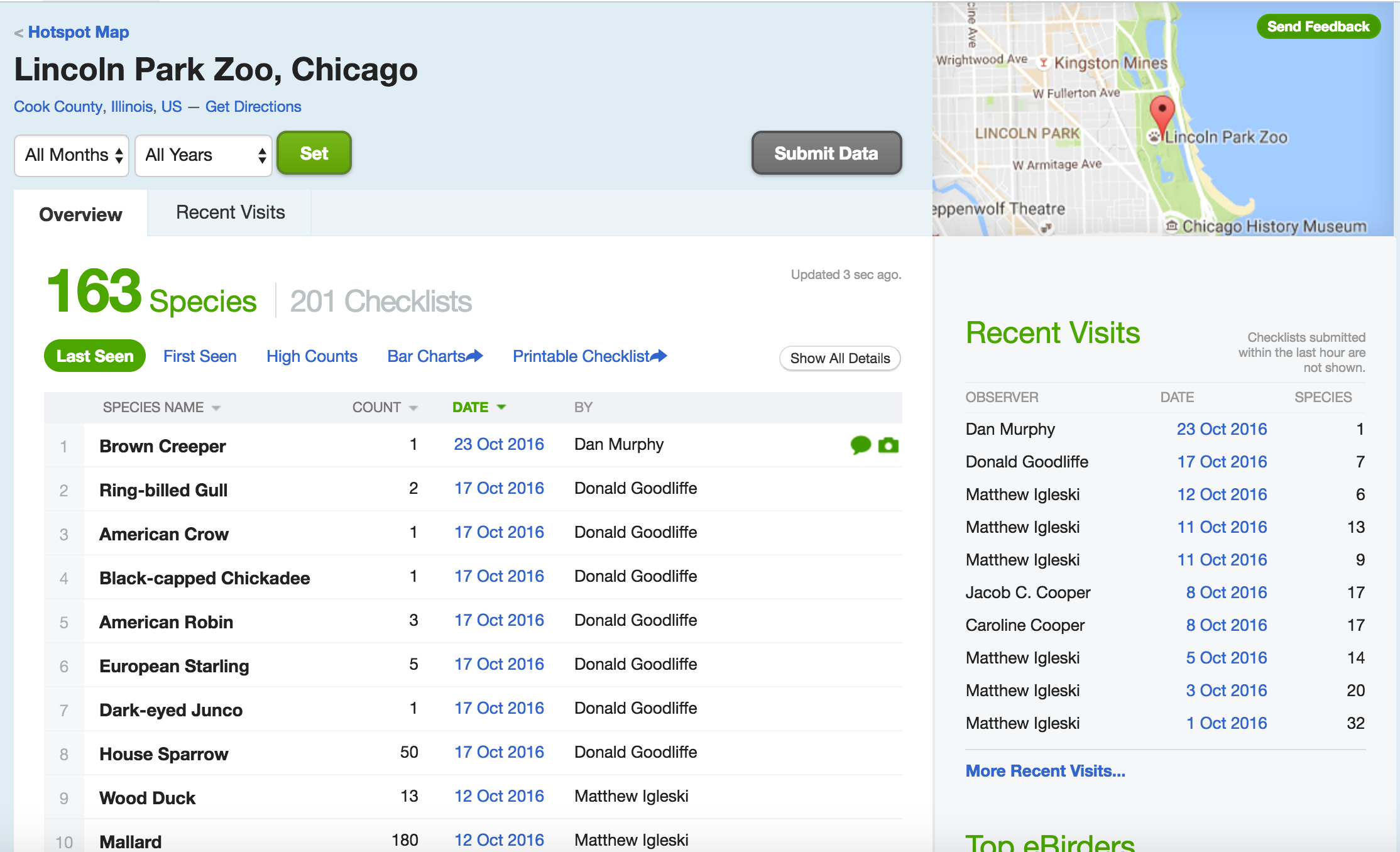
Lincoln Park Zoo
The data already look to be organized in a data frame! rebird allows us to read these data directly into R.
The ID code for Lincoln Park Zoo is L1573785
ebirdhotspot(locID = "L1573785") %>%
as_tibble()## # A tibble: 24 x 11
## lng locName howMany sciName
## <dbl> <chr> <int> <chr>
## 1 -87.63272 Lincoln Park Zoo, Chicago 2 Nycticorax nycticorax
## 2 -87.63272 Lincoln Park Zoo, Chicago 15 Larus delawarensis
## 3 -87.63272 Lincoln Park Zoo, Chicago 15 Hirundo rustica
## 4 -87.63272 Lincoln Park Zoo, Chicago 2 Poecile atricapillus
## 5 -87.63272 Lincoln Park Zoo, Chicago 1 Sitta carolinensis
## 6 -87.63272 Lincoln Park Zoo, Chicago 15 Sturnus vulgaris
## 7 -87.63272 Lincoln Park Zoo, Chicago 13 Agelaius phoeniceus
## 8 -87.63272 Lincoln Park Zoo, Chicago 8 Quiscalus quiscula
## 9 -87.63272 Lincoln Park Zoo, Chicago 3 Spinus tristis
## 10 -87.63272 Lincoln Park Zoo, Chicago 35 Passer domesticus
## # ... with 14 more rows, and 7 more variables: obsValid <lgl>,
## # locationPrivate <lgl>, obsDt <chr>, obsReviewed <lgl>, comName <chr>,
## # lat <dbl>, locID <chr>We can use the function ebirdgeo to get a list for an area. (Note that South and West are negative):
chibirds <- ebirdgeo(lat = 41.8781, lng = -87.6298)
chibirds %>%
as_tibble() %>%
str()## Classes 'tbl_df', 'tbl' and 'data.frame': 137 obs. of 11 variables:
## $ lng : num -87.6 -87.6 -87.6 -87.6 -87.6 ...
## $ locName : chr "U. of Chicago-University Ave. from 61st to 58th" "U. of Chicago-University Ave. from 61st to 58th" "U. of Chicago-University Ave. from 61st to 58th" "U. of Chicago-University Ave. from 61st to 58th" ...
## $ howMany : int 5 2 2 3 1 3 4 3 7 1 ...
## $ sciName : chr "Corvus brachyrhynchos" "Passer domesticus" "Chaetura pelagica" "Spizella passerina" ...
## $ obsValid : logi TRUE TRUE TRUE TRUE TRUE TRUE ...
## $ locationPrivate: logi TRUE TRUE TRUE TRUE TRUE TRUE ...
## $ obsDt : chr "2017-07-12 08:40" "2017-07-12 08:40" "2017-07-12 08:40" "2017-07-12 08:40" ...
## $ obsReviewed : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ comName : chr "American Crow" "House Sparrow" "Chimney Swift" "Chipping Sparrow" ...
## $ lat : num 41.8 41.8 41.8 41.8 41.8 ...
## $ locID : chr "L1242933" "L1242933" "L1242933" "L1242933" ...Note: Check the defaults on this function. e.g. radius of circle, time of year.
We can also search by “region”, which refers to short codes which serve as common shorthands for different political units. For example, France is represented by the letters FR
frenchbirds <- ebirdregion("FR")
frenchbirds %>%
as_tibble() %>%
str()## Classes 'tbl_df', 'tbl' and 'data.frame': 267 obs. of 11 variables:
## $ lng : num 7.75 -1.17 -1.17 -1.17 -1.17 ...
## $ locName : chr "Strasbourg (cité)" "Sainte-Eulalie-en-Born " "Sainte-Eulalie-en-Born " "Sainte-Eulalie-en-Born " ...
## $ howMany : int 1 8 1 3 5 2 3 25 1 2 ...
## $ sciName : chr "Fulica atra" "Hirundo rustica" "Troglodytes troglodytes" "Motacilla alba" ...
## $ obsValid : logi TRUE TRUE TRUE TRUE TRUE TRUE ...
## $ locationPrivate: logi FALSE TRUE TRUE TRUE TRUE TRUE ...
## $ obsDt : chr "2017-07-12 12:27" "2017-07-12 07:00" "2017-07-12 07:00" "2017-07-12 07:00" ...
## $ obsReviewed : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ comName : chr "Eurasian Coot" "Barn Swallow" "Eurasian Wren" "White Wagtail" ...
## $ lat : num 48.6 44.3 44.3 44.3 44.3 ...
## $ locID : chr "L3737750" "L6072426" "L6072426" "L6072426" ...Find out WHEN a bird has been seen in a certain place! Choosing a name from chibirds above (the Bald Eagle):
warbler <- ebirdgeo(species = 'Setophaga coronata', lat = 41.8781, lng = -87.6298)
warbler %>%
as_tibble() %>%
str()## Classes 'tbl_df', 'tbl' and 'data.frame': 0 obs. of 0 variablesrebird knows where you are:
ebirdgeo(species = 'Setophaga coronata') %>%
as_tibble() %>%
knitr::kable()## Warning: As a complete lat/long pair was not provided, your location was
## determined using your computer's public-facing IP address. This will likely
## not reflect your physical location if you are using a remote server or
## proxy.Searching geographic info: geonames
# install.packages(geonames)
library(geonames)API authentication
Many APIs require you to register for access. This allows them to track which users are submitting queries and manage demand - if you submit too many queries too quickly, you might be rate-limited and your requests de-prioritized or blocked. Always check the API access policy of the web site to determine what these limits are.
There are a few things we need to do to be able to use this package to access the geonames API:
- go to the geonames site and register an account.
- click here to enable the free web service
- Tell R your geonames username. You could run the line
options(geonamesUsername = "my_user_name")in R. However this is insecure. We don’t want to risk committing this line and pushing it to our public GitHub page! Instead, you should create a file in the same place as your .Rproj file. Name this file .Rprofile, and add
options(geonamesUsername = "my_user_name")to that file.
Important
- Make sure your
.Rprofileends with a blank line - Make sure
.Rprofileis included in your.gitignorefile, otherwise it will be synced with Github - Restart RStudio after modifying
.Rprofilein order to load any new keys into memory - Spelling is important when you set the option in your
.Rprofile - You can do a similar process for an arbitrary package or key. For example:
# in .Rprofile
options("this_is_my_key" = XXXX)
# later, in the R script:
key <- getOption("this_is_my_key")This is a simple means to keep your keys private, especially if you are sharing the same authentication across several projects. Remember that using .Rprofile makes your code un-reproducible. In this case, that is exactly what we want!
Using Geonames
What can we do? Get access to lots of geographical information via the various “web services”
countryInfo <- GNcountryInfo()countryInfo %>%
as_tibble() %>%
str()## Classes 'tbl_df', 'tbl' and 'data.frame': 250 obs. of 17 variables:
## $ continent : chr "EU" "AS" "AS" "NA" ...
## $ capital : chr "Andorra la Vella" "Abu Dhabi" "Kabul" "Saint John’s" ...
## $ languages : chr "ca" "ar-AE,fa,en,hi,ur" "fa-AF,ps,uz-AF,tk" "en-AG" ...
## $ geonameId : chr "3041565" "290557" "1149361" "3576396" ...
## $ south : chr "42.4284925987684" "22.6333293914795" "29.377472" "16.996979" ...
## $ isoAlpha3 : chr "AND" "ARE" "AFG" "ATG" ...
## $ north : chr "42.6560438963" "26.0841598510742" "38.483418" "17.729387" ...
## $ fipsCode : chr "AN" "AE" "AF" "AC" ...
## $ population : chr "84000" "4975593" "29121286" "86754" ...
## $ east : chr "1.78654277783198" "56.3816604614258" "74.879448" "-61.672421" ...
## $ isoNumeric : chr "020" "784" "004" "028" ...
## $ areaInSqKm : chr "468.0" "82880.0" "647500.0" "443.0" ...
## $ countryCode : chr "AD" "AE" "AF" "AG" ...
## $ west : chr "1.40718671411128" "51.5833282470703" "60.478443" "-61.906425" ...
## $ countryName : chr "Principality of Andorra" "United Arab Emirates" "Islamic Republic of Afghanistan" "Antigua and Barbuda" ...
## $ continentName: chr "Europe" "Asia" "Asia" "North America" ...
## $ currencyCode : chr "EUR" "AED" "AFN" "XCD" ...This country info dataset is very helpful for accessing the rest of the data, because it gives us the standardized codes for country and language.
The Manifesto Project: manifestoR
The Manifesto Project collects and organizes political party manifestos from around the world. It currently covers over 1000 parties from 1945 until today in over 50 countries on five continents. We can use the manifestoR package to access the API and download those manifestos for analysis in R.
Load library and set API key
Accessing data from the Manifesto Project API requires an authentication key. You can create an account and key here. Here I store my key in .Rprofile and retrieve it using mp_setapikey().
library(manifestoR)
# retrieve API key stored in .Rprofile
mp_setapikey(key = getOption("manifesto_key"))Retrieve the database
(mpds <- mp_maindataset())## Connecting to Manifesto Project DB API...
## Connecting to Manifesto Project DB API... corpus version: 2016-6## # A tibble: 4,121 x 173
## country countryname oecdmember eumember edate date party
## <dbl> <chr> <dbl> <dbl> <date> <dbl> <dbl>
## 1 11 Sweden 0 0 1944-09-17 194409 11220
## 2 11 Sweden 0 0 1944-09-17 194409 11320
## 3 11 Sweden 0 0 1944-09-17 194409 11420
## 4 11 Sweden 0 0 1944-09-17 194409 11620
## 5 11 Sweden 0 0 1944-09-17 194409 11810
## 6 11 Sweden 0 0 1948-09-19 194809 11220
## 7 11 Sweden 0 0 1948-09-19 194809 11320
## 8 11 Sweden 0 0 1948-09-19 194809 11420
## 9 11 Sweden 0 0 1948-09-19 194809 11620
## 10 11 Sweden 0 0 1948-09-19 194809 11810
## # ... with 4,111 more rows, and 166 more variables: partyname <chr>,
## # partyabbrev <chr>, parfam <dbl>, coderid <dbl>, manual <dbl>,
## # coderyear <dbl>, testresult <dbl>, testeditsim <dbl>, pervote <dbl>,
## # voteest <dbl>, presvote <dbl>, absseat <dbl>, totseats <dbl>,
## # progtype <dbl>, datasetorigin <dbl>, corpusversion <chr>, total <dbl>,
## # peruncod <dbl>, per101 <dbl>, per102 <dbl>, per103 <dbl>,
## # per104 <dbl>, per105 <dbl>, per106 <dbl>, per107 <dbl>, per108 <dbl>,
## # per109 <dbl>, per110 <dbl>, per201 <dbl>, per202 <dbl>, per203 <dbl>,
## # per204 <dbl>, per301 <dbl>, per302 <dbl>, per303 <dbl>, per304 <dbl>,
## # per305 <dbl>, per401 <dbl>, per402 <dbl>, per403 <dbl>, per404 <dbl>,
## # per405 <dbl>, per406 <dbl>, per407 <dbl>, per408 <dbl>, per409 <dbl>,
## # per410 <dbl>, per411 <dbl>, per412 <dbl>, per413 <dbl>, per414 <dbl>,
## # per415 <dbl>, per416 <dbl>, per501 <dbl>, per502 <dbl>, per503 <dbl>,
## # per504 <dbl>, per505 <dbl>, per506 <dbl>, per507 <dbl>, per601 <dbl>,
## # per602 <dbl>, per603 <dbl>, per604 <dbl>, per605 <dbl>, per606 <dbl>,
## # per607 <dbl>, per608 <dbl>, per701 <dbl>, per702 <dbl>, per703 <dbl>,
## # per704 <dbl>, per705 <dbl>, per706 <dbl>, per1011 <dbl>,
## # per1012 <dbl>, per1013 <dbl>, per1014 <dbl>, per1015 <dbl>,
## # per1016 <dbl>, per1021 <dbl>, per1022 <dbl>, per1023 <dbl>,
## # per1024 <dbl>, per1025 <dbl>, per1026 <dbl>, per1031 <dbl>,
## # per1032 <dbl>, per1033 <dbl>, per2021 <dbl>, per2022 <dbl>,
## # per2023 <dbl>, per2031 <dbl>, per2032 <dbl>, per2033 <dbl>,
## # per2041 <dbl>, per3011 <dbl>, per3051 <dbl>, per3052 <dbl>,
## # per3053 <dbl>, ...mp_maindataset() includes a data frame describing each manifesto included in the database. You can use this database for some exploratory data analysis. For instance, how many manifestos have been published by each political party in Sweden?
mpds %>%
filter(countryname == "Sweden") %>%
count(partyname) %>%
ggplot(aes(fct_reorder(partyname, n), n)) +
geom_col() +
labs(title = "Political manifestos published in Sweden",
x = NULL,
y = "Total (1948-present)") +
coord_flip()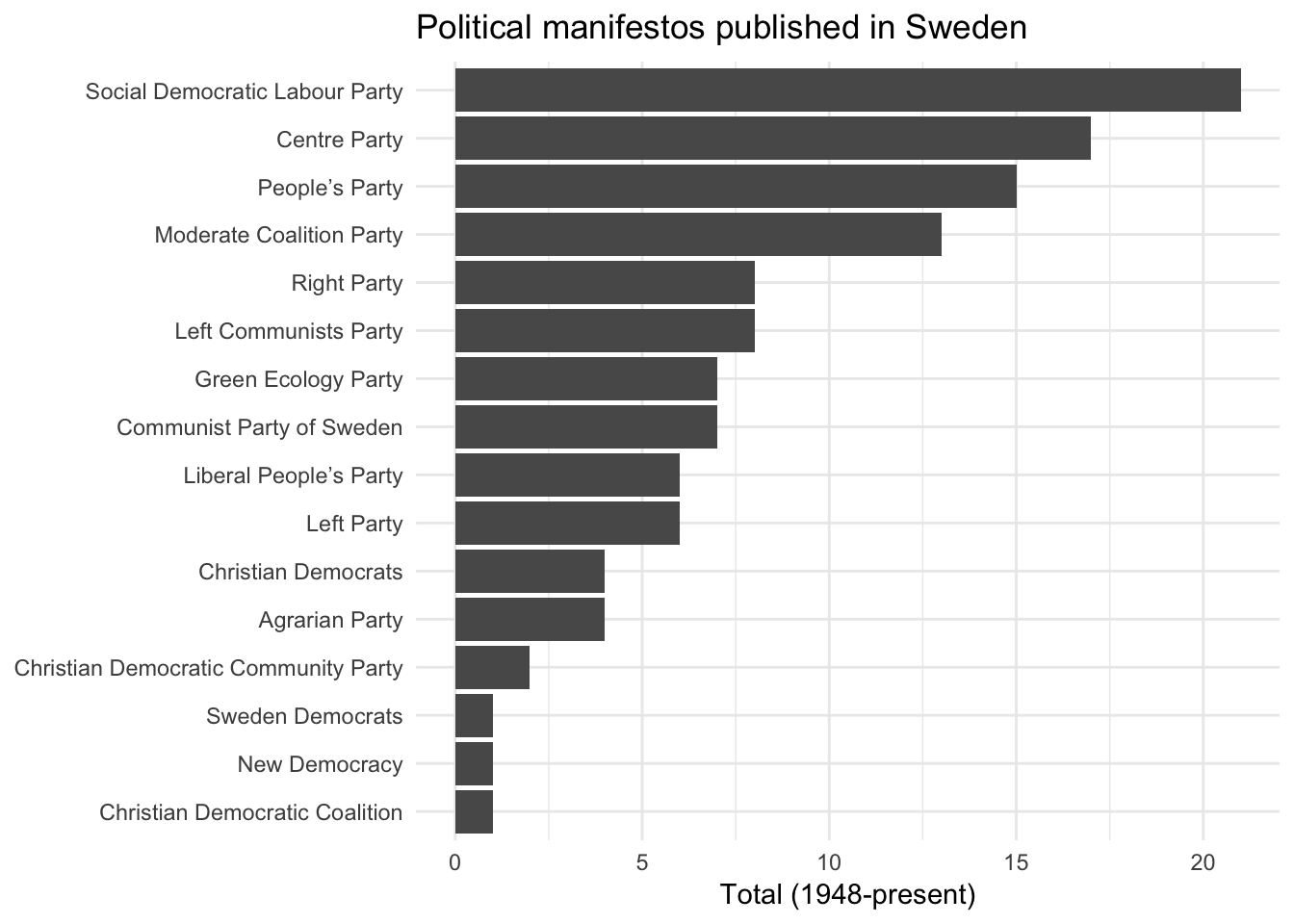
Or we can use scaling functions to identify each party manifesto on an ideological dimension. For example, how have the Democratic and Republican Party manifestos in the United States changed over time?
mpds %>%
filter(party == 61320 | party == 61620) %>%
mutate(ideo = mp_scale(.)) %>%
select(partyname, edate, ideo) %>%
ggplot(aes(edate, ideo, color = partyname)) +
geom_line() +
scale_color_manual(values = c("blue", "red")) +
labs(title = "Ideological scaling of major US political parties",
x = "Year",
y = "Ideological position",
color = NULL) +
theme(legend.position = "bottom")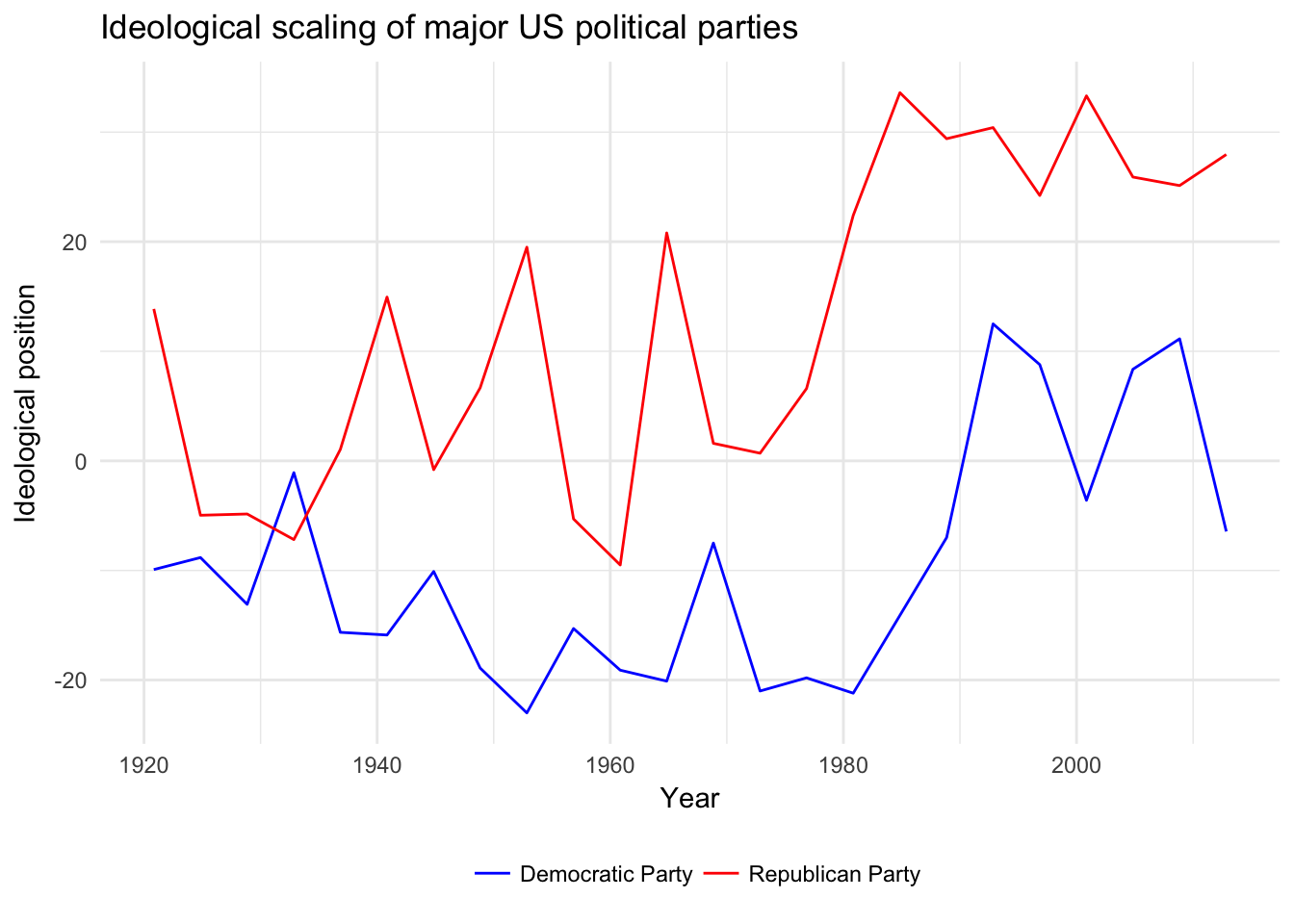
Download manifestos
mp_corpus() can be used to download the original manifestos as full text documents stored as a corpus. Once you obtain the corpus, you can perform text analysis. As an example, let’s compare the most common words in the Democratic and Republican Party manifestos from the 2012 U.S. presidential election:
# download documents
(docs <- mp_corpus(countryname == "United States" & edate > as.Date("2012-01-01")))## Connecting to Manifesto Project DB API...
## Connecting to Manifesto Project DB API... corpus version: 2017-1
## Connecting to Manifesto Project DB API...
## Connecting to Manifesto Project DB API... corpus version: 2017-1
## Connecting to Manifesto Project DB API... corpus version: 2017-1
## Connecting to Manifesto Project DB API... corpus version: 2017-1## <<ManifestoCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 2# generate wordcloud of most common terms
docs %>%
tidy() %>%
mutate(party = factor(party, levels = c(61320, 61620),
labels = c("Democratic Party", "Republican Party"))) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(party, word, sort = TRUE) %>%
na.omit() %>%
reshape2::acast(word ~ party, value.var = "n", fill = 0) %>%
comparison.cloud(max.words = 200)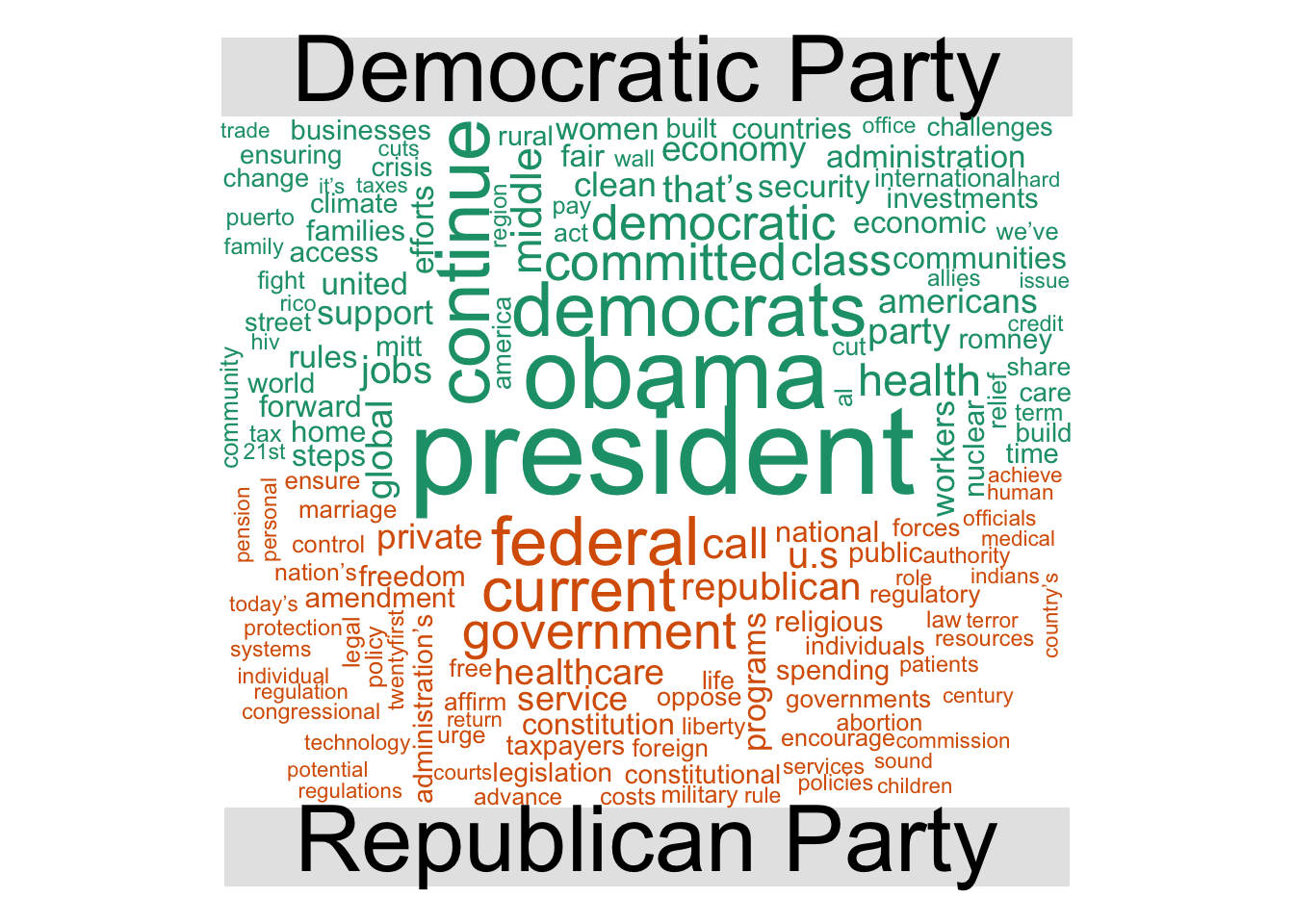
Acknowledgments
- This page is derived in part from “UBC STAT 545A and 547M”, licensed under the CC BY-NC 3.0 Creative Commons License.
Session Info
devtools::session_info()## Session info -------------------------------------------------------------## setting value
## version R version 3.4.1 (2017-06-30)
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## tz America/Chicago
## date 2017-11-10## Packages -----------------------------------------------------------------## package * version date source
## assertthat 0.2.0 2017-04-11 CRAN (R 3.4.0)
## backports 1.1.0 2017-05-22 CRAN (R 3.4.0)
## base * 3.4.1 2017-07-07 local
## base64enc 0.1-3 2015-07-28 CRAN (R 3.4.0)
## bindr 0.1 2016-11-13 CRAN (R 3.4.0)
## bindrcpp * 0.2 2017-06-17 CRAN (R 3.4.0)
## bit 1.1-12 2014-04-09 CRAN (R 3.4.0)
## bit64 0.9-7 2017-05-08 CRAN (R 3.4.0)
## boxes 0.0.0.9000 2017-07-19 Github (r-pkgs/boxes@03098dc)
## broom * 0.4.2 2017-08-09 local
## cellranger 1.1.0 2016-07-27 CRAN (R 3.4.0)
## clisymbols 1.2.0 2017-05-21 cran (@1.2.0)
## codetools 0.2-15 2016-10-05 CRAN (R 3.4.1)
## colorspace 1.3-2 2016-12-14 CRAN (R 3.4.0)
## compiler 3.4.1 2017-07-07 local
## crayon 1.3.4 2017-10-03 Github (gaborcsardi/crayon@b5221ab)
## curl 2.8.1 2017-07-21 CRAN (R 3.4.1)
## datasets * 3.4.1 2017-07-07 local
## DBI 0.7 2017-06-18 CRAN (R 3.4.0)
## devtools 1.13.3 2017-08-02 CRAN (R 3.4.1)
## digest 0.6.12 2017-01-27 CRAN (R 3.4.0)
## dplyr * 0.7.4.9000 2017-10-03 Github (tidyverse/dplyr@1a0730a)
## evaluate 0.10.1 2017-06-24 CRAN (R 3.4.1)
## forcats * 0.2.0 2017-01-23 CRAN (R 3.4.0)
## foreign 0.8-69 2017-06-22 CRAN (R 3.4.1)
## functional 0.6 2014-07-16 CRAN (R 3.4.0)
## geonames * 0.998 2014-12-19 CRAN (R 3.4.0)
## ggplot2 * 2.2.1 2016-12-30 CRAN (R 3.4.0)
## glue 1.1.1 2017-06-21 CRAN (R 3.4.1)
## graphics * 3.4.1 2017-07-07 local
## grDevices * 3.4.1 2017-07-07 local
## grid 3.4.1 2017-07-07 local
## gtable 0.2.0 2016-02-26 CRAN (R 3.4.0)
## haven 1.1.0 2017-07-09 CRAN (R 3.4.1)
## hms 0.3 2016-11-22 CRAN (R 3.4.0)
## htmltools 0.3.6 2017-04-28 CRAN (R 3.4.0)
## httr 1.3.1 2017-08-20 CRAN (R 3.4.1)
## janeaustenr 0.1.5 2017-06-10 CRAN (R 3.4.0)
## jsonlite 1.5 2017-06-01 CRAN (R 3.4.0)
## knitr * 1.17 2017-08-10 cran (@1.17)
## lattice 0.20-35 2017-03-25 CRAN (R 3.4.1)
## lazyeval 0.2.0 2016-06-12 CRAN (R 3.4.0)
## lubridate 1.6.0 2016-09-13 CRAN (R 3.4.0)
## magrittr 1.5 2014-11-22 CRAN (R 3.4.0)
## manifestoR * 1.2.4 2017-05-10 CRAN (R 3.4.0)
## Matrix 1.2-11 2017-08-16 CRAN (R 3.4.1)
## memoise 1.1.0 2017-04-21 CRAN (R 3.4.0)
## methods * 3.4.1 2017-07-07 local
## mnormt 1.5-5 2016-10-15 CRAN (R 3.4.0)
## modelr 0.1.1 2017-08-10 local
## munsell 0.4.3 2016-02-13 CRAN (R 3.4.0)
## nlme 3.1-131 2017-02-06 CRAN (R 3.4.1)
## NLP * 0.1-11 2017-08-15 CRAN (R 3.4.1)
## parallel 3.4.1 2017-07-07 local
## pkgconfig 2.0.1 2017-03-21 CRAN (R 3.4.0)
## plyr 1.8.4 2016-06-08 CRAN (R 3.4.0)
## psych 1.7.5 2017-05-03 CRAN (R 3.4.1)
## purrr * 0.2.3 2017-08-02 CRAN (R 3.4.1)
## R6 2.2.2 2017-06-17 CRAN (R 3.4.0)
## RColorBrewer * 1.1-2 2014-12-07 CRAN (R 3.4.0)
## Rcpp 0.12.13 2017-09-28 cran (@0.12.13)
## readr * 1.1.1 2017-05-16 CRAN (R 3.4.0)
## readxl 1.0.0 2017-04-18 CRAN (R 3.4.0)
## rebird * 0.4.0 2017-04-26 CRAN (R 3.4.0)
## reshape2 1.4.2 2016-10-22 CRAN (R 3.4.0)
## rjson 0.2.15 2014-11-03 CRAN (R 3.4.0)
## rlang 0.1.2 2017-08-09 CRAN (R 3.4.1)
## rmarkdown 1.6 2017-06-15 CRAN (R 3.4.0)
## rplos * 0.6.4 2016-11-24 CRAN (R 3.4.0)
## rprojroot 1.2 2017-01-16 CRAN (R 3.4.0)
## rstudioapi 0.6 2016-06-27 CRAN (R 3.4.0)
## rvest 0.3.2 2016-06-17 CRAN (R 3.4.0)
## scales 0.4.1 2016-11-09 CRAN (R 3.4.0)
## slam 0.1-40 2016-12-01 CRAN (R 3.4.0)
## SnowballC 0.5.1 2014-08-09 CRAN (R 3.4.0)
## solr 0.1.6 2015-09-17 CRAN (R 3.4.0)
## stats * 3.4.1 2017-07-07 local
## stringi 1.1.5 2017-04-07 CRAN (R 3.4.0)
## stringr * 1.2.0 2017-02-18 CRAN (R 3.4.0)
## tibble * 1.3.4 2017-08-22 CRAN (R 3.4.1)
## tidyr * 0.7.0 2017-08-16 CRAN (R 3.4.1)
## tidytext * 0.1.3 2017-06-19 CRAN (R 3.4.1)
## tidyverse * 1.1.1.9000 2017-07-19 Github (tidyverse/tidyverse@a028619)
## tm * 0.7-1 2017-03-02 CRAN (R 3.4.0)
## tokenizers 0.1.4 2016-08-29 CRAN (R 3.4.0)
## tools 3.4.1 2017-07-07 local
## twitteR * 1.1.9 2015-07-29 CRAN (R 3.4.0)
## utils * 3.4.1 2017-07-07 local
## whisker 0.3-2 2013-04-28 CRAN (R 3.4.0)
## withr 2.0.0 2017-07-28 CRAN (R 3.4.1)
## wordcloud * 2.5 2014-06-13 CRAN (R 3.4.0)
## XML 3.98-1.9 2017-06-19 CRAN (R 3.4.1)
## xml2 1.1.1 2017-01-24 CRAN (R 3.4.0)
## yaml 2.1.14 2016-11-12 CRAN (R 3.4.0)
## zoo 1.8-0 2017-04-12 CRAN (R 3.4.0)This work is licensed under the CC BY-NC 4.0 Creative Commons License.