Getting data from the web: writing API queries
library(tidyverse)
library(stringr)
library(curl)
library(jsonlite)
library(XML)
library(httr)
theme_set(theme_minimal())What happens if someone has not already written a package for the API from which we want to obtain data? We have to write our own function! Fortunately you know how to write functions - now we need to use them to query an API to obtain data.
First we’re going to examine the structure of API requests via the Open Movie Database. OMDb is very similar to IMDB, except it has a nice, simple API. We can go to the website, input some search parameters, and obtain both the XML query and the response from it.
Determining the shape of an API request
You can play around with the parameters on the OMDB website, and look at the resulting API call and the query you get back:
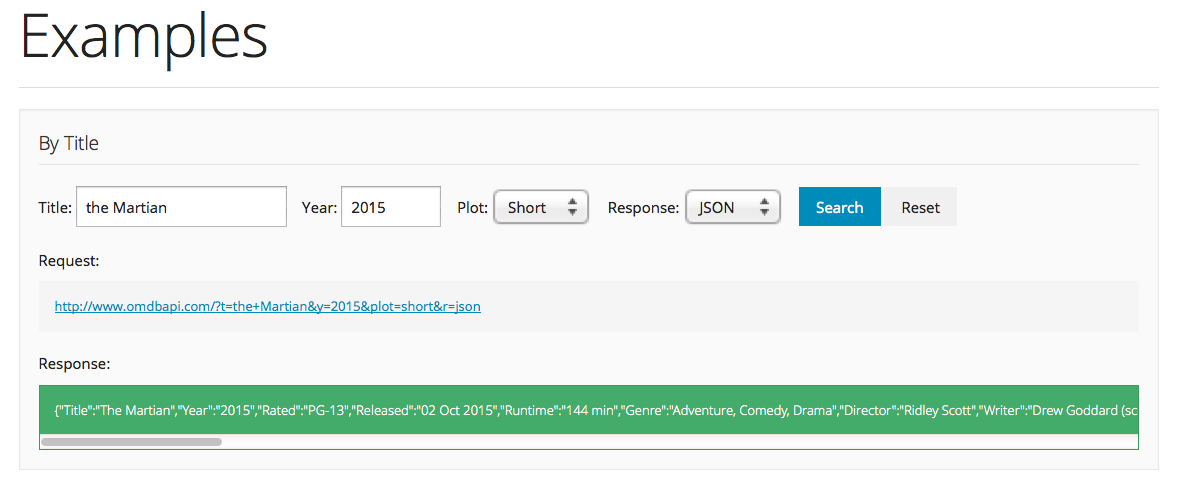
Let’s experiment with different values of the title and year fields. Notice the pattern in the request. For example for Title = Sharknado and Year = 2013, we get:
http://www.omdbapi.com/?apikey=[apikey]&t=Sharknado&y=2013&plot=short&r=xmlTry pasting this link into the browser. Also experiment with json and xml.
The OMDB API used to be free, however in the past year shifted to a private API key due to overwhelming traffic. See in class for a demo API key you can use.
How can we create this request in R?
# retrieve API key from .RProfile
omdb_key <- getOption("omdb_key")
# create url
request <- str_c("http://www.omdbapi.com/?apikey=", omdb_key, "&", "t=", "Sharknado", "&", "y=", "2013", "&", "plot=", "short", "&", "r=", "xml")
request## [1] "http://www.omdbapi.com/?apikey=775e324f&t=Sharknado&y=2013&plot=short&r=xml"It works, but it’s a bit ungainly. Lets try to abstract that into a function:
omdb <- function(Key, Title, Year, Plot, Format){
baseurl <- "http://www.omdbapi.com/?"
params <- c("apikey=", "t=", "y=", "plot=", "r=")
values <- c(Key, Title, Year, Plot, Format)
param_values <- map2_chr(params, values, str_c)
args <- str_c(param_values, collapse = "&")
str_c(baseurl, args)
}
omdb("omdb_key", "Sharknado", "2013", "short", "xml")## [1] "http://www.omdbapi.com/?apikey=omdb_key&t=Sharknado&y=2013&plot=short&r=xml"Now we have a handy function that returns the API query. We can paste in the link, but we can also obtain data from within R:
request_sharknado <- omdb(omdb_key, "Sharknado", "2013", "short", "xml")
con <- curl(request_sharknado)
answer_xml <- readLines(con)## Warning in readLines(con): incomplete final line found on 'http://
## www.omdbapi.com/?apikey=775e324f&t=Sharknado&y=2013&plot=short&r=xml'close(con)
answer_xml## [1] "<?xml version=\"1.0\" encoding=\"UTF-8\"?><root response=\"True\"><movie title=\"Sharknado\" year=\"2013\" rated=\"TV-14\" released=\"11 Jul 2013\" runtime=\"86 min\" genre=\"Comedy, Horror, Sci-Fi\" director=\"Anthony C. Ferrante\" writer=\"Thunder Levin\" actors=\"Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo\" plot=\"When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace.\" language=\"English\" country=\"USA\" awards=\"1 win & 2 nominations.\" poster=\"https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg\" metascore=\"N/A\" imdbRating=\"3.3\" imdbVotes=\"38,247\" imdbID=\"tt2724064\" type=\"movie\"/></root>"request_sharknado <- omdb(omdb_key, "Sharknado", "2013", "short", "json")
con <- curl(request_sharknado)
answer_json <- readLines(con)
close(con)
answer_json %>%
prettify()## {
## "Title": "Sharknado",
## "Year": "2013",
## "Rated": "TV-14",
## "Released": "11 Jul 2013",
## "Runtime": "86 min",
## "Genre": "Comedy, Horror, Sci-Fi",
## "Director": "Anthony C. Ferrante",
## "Writer": "Thunder Levin",
## "Actors": "Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo",
## "Plot": "When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace.",
## "Language": "English",
## "Country": "USA",
## "Awards": "1 win & 2 nominations.",
## "Poster": "https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg",
## "Ratings": [
## {
## "Source": "Internet Movie Database",
## "Value": "3.3/10"
## },
## {
## "Source": "Rotten Tomatoes",
## "Value": "82%"
## }
## ],
## "Metascore": "N/A",
## "imdbRating": "3.3",
## "imdbVotes": "38,247",
## "imdbID": "tt2724064",
## "Type": "movie",
## "DVD": "03 Sep 2013",
## "BoxOffice": "N/A",
## "Production": "NCM Fathom",
## "Website": "http://www.mtivideo.com/TitleView.aspx?TITLE_ID=728",
## "Response": "True"
## }
## We have a form of data that is obviously structured. What is it?
Intro to JSON and XML
These are the two common languages of web services: JavaScript Object Notation and eXtensible Markup Language.
Here’s an example of JSON: from this wonderful site
{
"crust": "original",
"toppings": ["cheese", "pepperoni", "garlic"],
"status": "cooking",
"customer": {
"name": "Brian",
"phone": "573-111-1111"
}
}And here is XML:
<order>
<crust>original</crust>
<toppings>
<topping>cheese</topping>
<topping>pepperoni</topping>
<topping>garlic</topping>
</toppings>
<status>cooking</status>
</order>You can see that both of these data structures are quite easy to read. They are “self-describing”. In other words, they tell you how they are meant to be read.
There are easy means of taking these data types and creating R objects. Our JSON response above can be parsed using jsonlite::fromJSON():
answer_json %>%
fromJSON()## $Title
## [1] "Sharknado"
##
## $Year
## [1] "2013"
##
## $Rated
## [1] "TV-14"
##
## $Released
## [1] "11 Jul 2013"
##
## $Runtime
## [1] "86 min"
##
## $Genre
## [1] "Comedy, Horror, Sci-Fi"
##
## $Director
## [1] "Anthony C. Ferrante"
##
## $Writer
## [1] "Thunder Levin"
##
## $Actors
## [1] "Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo"
##
## $Plot
## [1] "When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA"
##
## $Awards
## [1] "1 win & 2 nominations."
##
## $Poster
## [1] "https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg"
##
## $Ratings
## Source Value
## 1 Internet Movie Database 3.3/10
## 2 Rotten Tomatoes 82%
##
## $Metascore
## [1] "N/A"
##
## $imdbRating
## [1] "3.3"
##
## $imdbVotes
## [1] "38,247"
##
## $imdbID
## [1] "tt2724064"
##
## $Type
## [1] "movie"
##
## $DVD
## [1] "03 Sep 2013"
##
## $BoxOffice
## [1] "N/A"
##
## $Production
## [1] "NCM Fathom"
##
## $Website
## [1] "http://www.mtivideo.com/TitleView.aspx?TITLE_ID=728"
##
## $Response
## [1] "True"The output is a named list! A familiar and friendly R structure. Because data frames are lists, and because this list has no nested lists-within-lists,1 we can coerce it very simply:
answer_json %>%
fromJSON() %>%
# remove ratings element for now
list_modify(Ratings = NULL) %>%
as_tibble()## # A tibble: 1 x 24
## Title Year Rated Released Runtime Genre
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Sharknado 2013 TV-14 11 Jul 2013 86 min Comedy, Horror, Sci-Fi
## # ... with 18 more variables: Director <chr>, Writer <chr>, Actors <chr>,
## # Plot <chr>, Language <chr>, Country <chr>, Awards <chr>, Poster <chr>,
## # Metascore <chr>, imdbRating <chr>, imdbVotes <chr>, imdbID <chr>,
## # Type <chr>, DVD <chr>, BoxOffice <chr>, Production <chr>,
## # Website <chr>, Response <chr>A similar process exists for XML formats:
ans_xml_parsed <- xmlParse(answer_xml)
ans_xml_parsed## <?xml version="1.0" encoding="UTF-8"?>
## <root response="True">
## <movie title="Sharknado" year="2013" rated="TV-14" released="11 Jul 2013" runtime="86 min" genre="Comedy, Horror, Sci-Fi" director="Anthony C. Ferrante" writer="Thunder Levin" actors="Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo" plot="When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace." language="English" country="USA" awards="1 win & 2 nominations." poster="https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg" metascore="N/A" imdbRating="3.3" imdbVotes="38,247" imdbID="tt2724064" type="movie"/>
## </root>
## Not exactly the response we were hoping for! This shows us some of the XML document’s structure:
- a
<root>node with a single child,<movie>. - the information we want is all stored as attributes
From Nolan and Lang 2014:
The
xmlRoot()function returns an object of classXMLInternalElementNode. This is a regular XML node and not specific to the root node, i.e., all XML nodes will appear in R with this class or a more specific class. An object of class XMLInternalElementNode has four fields: name, attributes, children and value, which we access with the methods xmlName(), xmlAttrs(), xmlChildren(), and xmlValue()
| field | method |
|---|---|
| name | xmlName() |
| attributes | xmlAttrs() |
| children | xmlChildren() |
| value | xmlValue() |
ans_xml_parsed_root <- xmlRoot(ans_xml_parsed)[["movie"]] # could also use [[1]]
ans_xml_parsed_root## <movie title="Sharknado" year="2013" rated="TV-14" released="11 Jul 2013" runtime="86 min" genre="Comedy, Horror, Sci-Fi" director="Anthony C. Ferrante" writer="Thunder Levin" actors="Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo" plot="When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace." language="English" country="USA" awards="1 win & 2 nominations." poster="https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg" metascore="N/A" imdbRating="3.3" imdbVotes="38,247" imdbID="tt2724064" type="movie"/>ans_xml_attrs <- xmlAttrs(ans_xml_parsed_root)
ans_xml_attrs## title
## "Sharknado"
## year
## "2013"
## rated
## "TV-14"
## released
## "11 Jul 2013"
## runtime
## "86 min"
## genre
## "Comedy, Horror, Sci-Fi"
## director
## "Anthony C. Ferrante"
## writer
## "Thunder Levin"
## actors
## "Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo"
## plot
## "When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace."
## language
## "English"
## country
## "USA"
## awards
## "1 win & 2 nominations."
## poster
## "https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg"
## metascore
## "N/A"
## imdbRating
## "3.3"
## imdbVotes
## "38,247"
## imdbID
## "tt2724064"
## type
## "movie"ans_xml_attrs %>%
t() %>%
as_tibble()## # A tibble: 1 x 19
## title year rated released runtime genre
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Sharknado 2013 TV-14 11 Jul 2013 86 min Comedy, Horror, Sci-Fi
## # ... with 13 more variables: director <chr>, writer <chr>, actors <chr>,
## # plot <chr>, language <chr>, country <chr>, awards <chr>, poster <chr>,
## # metascore <chr>, imdbRating <chr>, imdbVotes <chr>, imdbID <chr>,
## # type <chr>Introducing the easy way: httr
httr is yet another star in the tidyverse, this one designed to facilitate all things HTTP from within R. This includes the major HTTP verbs, which are:2
- GET: fetch an existing resource. The URL contains all the necessary information the server needs to locate and return the resource.
- POST: create a new resource. POST requests usually carry a payload that specifies the data for the new resource.
- PUT: update an existing resource. The payload may contain the updated data for the resource.
- DELETE: delete an existing resource.
HTTP is the foundation for APIs; understanding how it works is the key to interacting with all the diverse APIs out there. An excellent beginning resource for APIs (including HTTP basics) is this simple guide.
httr contains one function for every HTTP verb. The functions have the same names as the verbs (e.g. GET(), POST()). They have more informative outputs than simply using curl, and come with some nice convenience functions for working with the output:
sharknado_json <- omdb(omdb_key, "Sharknado", "2013", "short", "json")
response_json <- GET(sharknado_json)
content(response_json, as = "parsed", type = "application/json")## $Title
## [1] "Sharknado"
##
## $Year
## [1] "2013"
##
## $Rated
## [1] "TV-14"
##
## $Released
## [1] "11 Jul 2013"
##
## $Runtime
## [1] "86 min"
##
## $Genre
## [1] "Comedy, Horror, Sci-Fi"
##
## $Director
## [1] "Anthony C. Ferrante"
##
## $Writer
## [1] "Thunder Levin"
##
## $Actors
## [1] "Ian Ziering, Tara Reid, John Heard, Cassandra Scerbo"
##
## $Plot
## [1] "When a freak hurricane swamps Los Angeles, nature's deadliest killer rules sea, land, and air as thousands of sharks terrorize the waterlogged populace."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA"
##
## $Awards
## [1] "1 win & 2 nominations."
##
## $Poster
## [1] "https://images-na.ssl-images-amazon.com/images/M/MV5BOTE2OTk4MTQzNV5BMl5BanBnXkFtZTcwODUxOTM3OQ@@._V1_SX300.jpg"
##
## $Ratings
## $Ratings[[1]]
## $Ratings[[1]]$Source
## [1] "Internet Movie Database"
##
## $Ratings[[1]]$Value
## [1] "3.3/10"
##
##
## $Ratings[[2]]
## $Ratings[[2]]$Source
## [1] "Rotten Tomatoes"
##
## $Ratings[[2]]$Value
## [1] "82%"
##
##
##
## $Metascore
## [1] "N/A"
##
## $imdbRating
## [1] "3.3"
##
## $imdbVotes
## [1] "38,247"
##
## $imdbID
## [1] "tt2724064"
##
## $Type
## [1] "movie"
##
## $DVD
## [1] "03 Sep 2013"
##
## $BoxOffice
## [1] "N/A"
##
## $Production
## [1] "NCM Fathom"
##
## $Website
## [1] "http://www.mtivideo.com/TitleView.aspx?TITLE_ID=728"
##
## $Response
## [1] "True"sharknado_xml <- omdb(omdb_key, "Sharknado", "2013", "short", "xml")
response_xml <- GET(sharknado_xml)
content(response_xml, as = "parsed")## {xml_document}
## <root response="True">
## [1] <movie title="Sharknado" year="2013" rated="TV-14" released="11 Jul ...In addition, httr gives us access to lots of useful information about the quality of our response. For example, the header:
headers(response_xml)## $date
## [1] "Tue, 22 Aug 2017 18:55:14 GMT"
##
## $`content-type`
## [1] "text/xml; charset=utf-8"
##
## $`transfer-encoding`
## [1] "chunked"
##
## $connection
## [1] "keep-alive"
##
## $`cache-control`
## [1] "public, max-age=86400"
##
## $expires
## [1] "Wed, 23 Aug 2017 18:55:14 GMT"
##
## $`last-modified`
## [1] "Tue, 22 Aug 2017 18:50:07 GMT"
##
## $vary
## [1] "Accept-Encoding"
##
## $`x-aspnet-version`
## [1] "4.0.30319"
##
## $`x-powered-by`
## [1] "ASP.NET"
##
## $`access-control-allow-origin`
## [1] "*"
##
## $`cf-cache-status`
## [1] "HIT"
##
## $server
## [1] "cloudflare-nginx"
##
## $`cf-ray`
## [1] "39280b9606c12579-ORD"
##
## $`content-encoding`
## [1] "gzip"
##
## attr(,"class")
## [1] "insensitive" "list"And also a handy means to extract specifically the HTTP status code:
status_code(response_xml)## [1] 200| Code3 | Status |
|---|---|
| 1xx | Informational |
| 2xx | Success |
| 3xx | Redirection |
| 4xx | Client error (you did something wrong) |
| 5xx | Server error (server did something wrong) |
(Perhaps a more intuitive, cat-based explanation of error codes).
In fact, we didn’t need to create omdb() at all! httr provides a straightforward means of making an http request:
sharknado_2 <- GET("http://www.omdbapi.com/?", query = list(t = "Sharknado 2: The Second One", y = 2014, plot = "short", r = "json", apikey = omdb_key))
content(sharknado_2)## $Title
## [1] "Sharknado 2: The Second One"
##
## $Year
## [1] "2014"
##
## $Rated
## [1] "TV-14"
##
## $Released
## [1] "30 Jul 2014"
##
## $Runtime
## [1] "95 min"
##
## $Genre
## [1] "Comedy, Horror, Sci-Fi"
##
## $Director
## [1] "Anthony C. Ferrante"
##
## $Writer
## [1] "Thunder Levin"
##
## $Actors
## [1] "Ian Ziering, Tara Reid, Vivica A. Fox, Mark McGrath"
##
## $Plot
## [1] "Fin and April are on their way to New York, until a Category 7 Hurricane spawns heavy rain, storm surges and deadly Sharknadoes."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA"
##
## $Awards
## [1] "N/A"
##
## $Poster
## [1] "https://images-na.ssl-images-amazon.com/images/M/MV5BMjA0MTIxMDEwNF5BMl5BanBnXkFtZTgwMDk3ODIxMjE@._V1_SX300.jpg"
##
## $Ratings
## $Ratings[[1]]
## $Ratings[[1]]$Source
## [1] "Internet Movie Database"
##
## $Ratings[[1]]$Value
## [1] "4.1/10"
##
##
## $Ratings[[2]]
## $Ratings[[2]]$Source
## [1] "Rotten Tomatoes"
##
## $Ratings[[2]]$Value
## [1] "61%"
##
##
##
## $Metascore
## [1] "N/A"
##
## $imdbRating
## [1] "4.1"
##
## $imdbVotes
## [1] "14,133"
##
## $imdbID
## [1] "tt3062074"
##
## $Type
## [1] "movie"
##
## $DVD
## [1] "07 Oct 2014"
##
## $BoxOffice
## [1] "N/A"
##
## $Production
## [1] "NCM Fathom"
##
## $Website
## [1] "N/A"
##
## $Response
## [1] "True"We get the same answer as before! With httr, we are able to pass in the named arguments to the API call as a named list. We are also able to use spaces in movie names - httr encodes these in the URL before making the GET request.
The documentation for httr includes two useful vignettes:
httrquickstart guide - summarizes all the basichttrfunctions like above- Best practices for writing an API package - document outlining the key issues involved in writing API wrappers in R
Applying httr to the Microsoft Emotion API
APIs can be used in conjunction with cloud computing and deep learning platforms that cannot be deployed on a local machine. Consider the Microsoft Emotion API:
The Emotion API takes a facial expression in an image as an input, and returns the confidence across a set of emotions for each face in the image, as well as bounding box for the face, using the Face API. If a user has already called the Face API, they can submit the face rectangle as an optional input. The emotions detected are anger, contempt, disgust, fear, happiness, neutral, sadness, and surprise. These emotions are understood to be cross-culturally and universally communicated with particular facial expressions.
Here is how we can use R and the httr package to send a request to the Microsoft Emotion API to analyze a video and retrieve the results.4 As our sample video, we’ll use a sample five minute video clip from the third 2016 U.S. presidential debate between Donald J. Trump and Hillary Clinton.
# Set an endpoint for Emotion in Video API with "perFrame" output
apiUrl <- "https://api.projectoxford.ai/emotion/v1.0/recognizeInVideo?outputStyle=perFrame"
# Set URL for accessing the video
urlVideo <- "https://www.dropbox.com/s/zfmaswf8s9c58om/blog2.mp4?dl=1"
# Request Microsoft AI start processing the video via POST
faceEMO <- httr::POST(
url = apiUrl,
content_type("application/json"),
add_headers(.headers = c("Ocp-Apim-Subscription-Key" = getOption("emotion_api"))),
body = list(url = urlVideo),
encode = "json"
)
# url to access the operation
operationLocation <- headers(faceEMO)[["operation-location"]]
# it can take awhile to process a long video
# use a while loop to wait for the processing to finish
# and retrieve the results
while(TRUE){
# retrieve results and extract content
ret <- GET(operationLocation,
add_headers(.headers = c("Ocp-Apim-Subscription-Key" = getOption("emotion_api"))))
con <- content(ret)
# if the process is still running, print the progress and continue waiting
if(is.null(con$status)){
warning("Connection Error, retry after 1 minute")
Sys.sleep(60)
} else if (con$status == "Running" | con$status == "Uploading"){
cat(paste0("status ", con$status, "\n"))
cat(paste0("progress ", con$progress, "\n"))
Sys.sleep(60)
} else {
# once the process is done, exit the loop
cat(paste0("status ", con$status, "\n"))
break()
}
}
# extract data from the results
data <- (con$processingResult %>%
fromJSON())$fragments
# data$events is list of events that has a data.frame column,
# so it has to be flattened using a series of map functions
data$events <- map(data$events, ~ .x %>%
map(flatten) %>%
bind_rows()
)
# print results
data
# clean up and save
emotion <- data %>%
as_tibble %>%
# unnest the list of data frames
unnest(events) %>%
# remove the moderator
filter(id != 2) %>%
# create a row id variable, use same row id for each set of speakers
mutate(row_id = ceiling(row_number() / 2)) %>%
# convert from wide to long, one row for each id-emotion
gather(key, value, starts_with("scores")) %>%
mutate(key = str_replace(key, "scores.", ""),
id = recode(id, `0` = "Trump",
`1` = "Clinton")) %>%
# remove neutral expressions and write to disk
filter(key != "neutral") %>%
write_rds("data/debate_emotion.rds")This script requires you to create your own API key for the Microsoft Emotion API and would take about an hour to process the video and retrieve the results. Instead, you can just use the prepped data frame stored in the rcfss package.
# already ran the API and stored the data frame in the rcfss package
data("emotion", package = "rcfss")
emotion## # A tibble: 128,688 x 11
## start duration interval id x y width height
## <int> <int> <int> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 0 60060 1001 Trump 0.185417 0.218519 0.153125 0.272222
## 2 0 60060 1001 Clinton 0.717708 0.296296 0.138542 0.246296
## 3 0 60060 1001 Trump 0.184375 0.216667 0.155208 0.275926
## 4 0 60060 1001 Clinton 0.714583 0.283333 0.139583 0.248148
## 5 0 60060 1001 Trump 0.184375 0.216667 0.155208 0.275926
## 6 0 60060 1001 Clinton 0.712500 0.275926 0.139583 0.248148
## 7 0 60060 1001 Trump 0.184375 0.216667 0.155208 0.275926
## 8 0 60060 1001 Clinton 0.711458 0.274074 0.139583 0.248148
## 9 0 60060 1001 Trump 0.184375 0.216667 0.155208 0.275926
## 10 0 60060 1001 Clinton 0.708333 0.264815 0.141667 0.251852
## # ... with 128,678 more rows, and 3 more variables: row_id <dbl>,
## # key <chr>, value <dbl>See
?emotionfor more documentation on the variables.
What could we do with this information? A simple analysis would be to visualize the emotions of each candidate over time:
ggplot(emotion, aes(row_id, value, color = key)) +
facet_wrap(~ id, nrow = 2) +
geom_smooth(se = FALSE) +
scale_color_brewer(type = "qual") +
labs(title = "Candidate emotions during final 2016 U.S. presidential debate",
subtitle = "Five-minute sample",
x = "Frame",
y = "Probability of emotion",
color = "Emotion")## `geom_smooth()` using method = 'gam'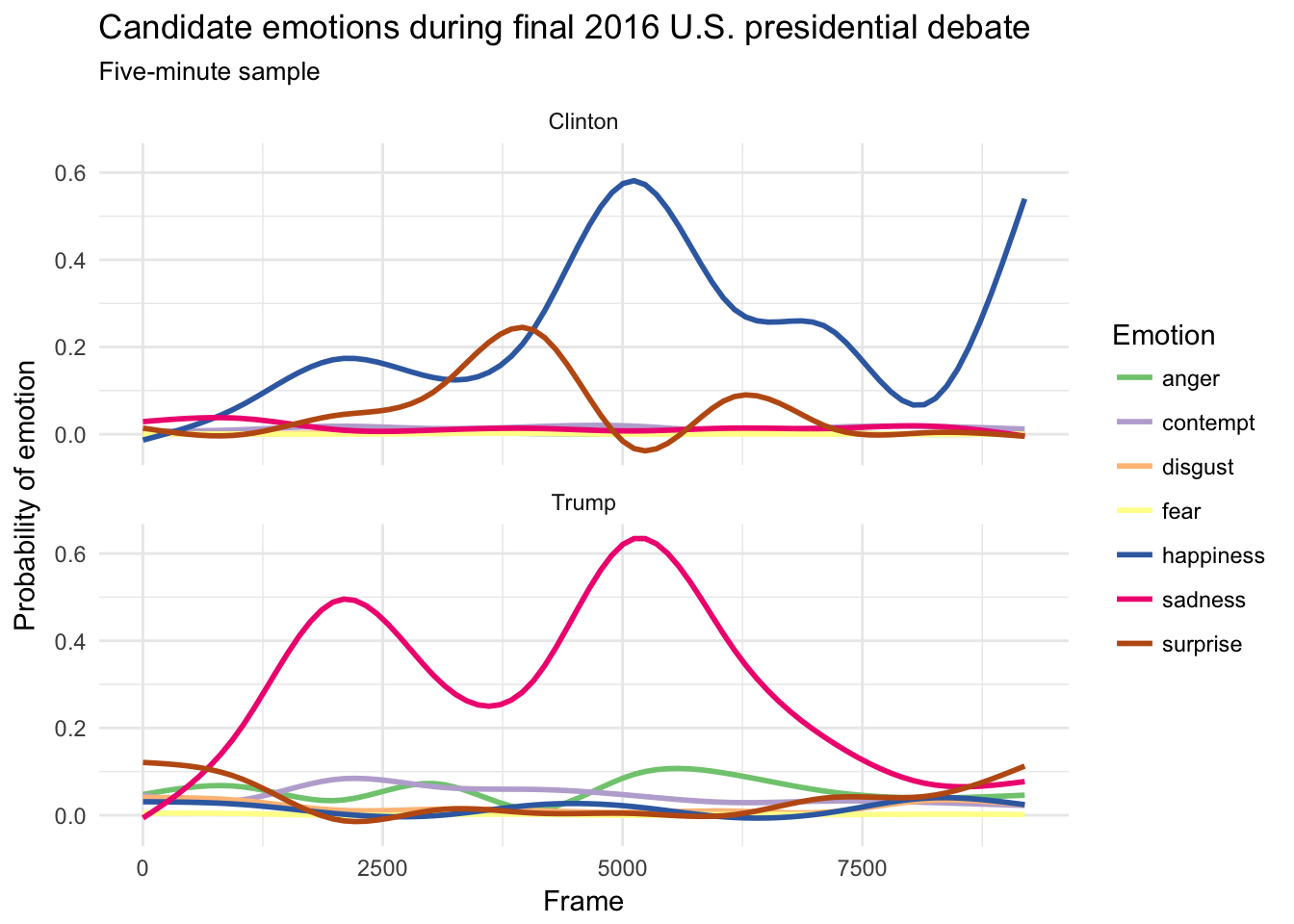
Hillary Clinton’s facial expressions are marked predominantly by happiness, whereas Donald Trump’s facial expressions are mostly sad.5
Acknowledgments
- This page is derived in part from “UBC STAT 545A and 547M”, licensed under the CC BY-NC 3.0 Creative Commons License.
- Microsoft Emotion API example drawn from Analyzing Emotions using Facial Expressions in Video with Microsoft AI and R
Session Info
devtools::session_info()## Session info -------------------------------------------------------------## setting value
## version R version 3.4.1 (2017-06-30)
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## tz America/Chicago
## date 2017-11-13## Packages -----------------------------------------------------------------## package * version date source
## assertthat 0.2.0 2017-04-11 CRAN (R 3.4.0)
## backports 1.1.0 2017-05-22 CRAN (R 3.4.0)
## base * 3.4.1 2017-07-07 local
## bindr 0.1 2016-11-13 CRAN (R 3.4.0)
## bindrcpp 0.2 2017-06-17 CRAN (R 3.4.0)
## boxes 0.0.0.9000 2017-07-19 Github (r-pkgs/boxes@03098dc)
## broom 0.4.2 2017-08-09 local
## cellranger 1.1.0 2016-07-27 CRAN (R 3.4.0)
## clisymbols 1.2.0 2017-05-21 cran (@1.2.0)
## colorspace 1.3-2 2016-12-14 CRAN (R 3.4.0)
## compiler 3.4.1 2017-07-07 local
## crayon 1.3.4 2017-10-03 Github (gaborcsardi/crayon@b5221ab)
## curl * 2.8.1 2017-07-21 CRAN (R 3.4.1)
## datasets * 3.4.1 2017-07-07 local
## devtools 1.13.3 2017-08-02 CRAN (R 3.4.1)
## digest 0.6.12 2017-01-27 CRAN (R 3.4.0)
## dplyr * 0.7.4.9000 2017-10-03 Github (tidyverse/dplyr@1a0730a)
## evaluate 0.10.1 2017-06-24 CRAN (R 3.4.1)
## forcats * 0.2.0 2017-01-23 CRAN (R 3.4.0)
## foreign 0.8-69 2017-06-22 CRAN (R 3.4.1)
## ggplot2 * 2.2.1 2016-12-30 CRAN (R 3.4.0)
## glue 1.1.1 2017-06-21 CRAN (R 3.4.1)
## graphics * 3.4.1 2017-07-07 local
## grDevices * 3.4.1 2017-07-07 local
## grid 3.4.1 2017-07-07 local
## gtable 0.2.0 2016-02-26 CRAN (R 3.4.0)
## haven 1.1.0 2017-07-09 CRAN (R 3.4.1)
## hms 0.3 2016-11-22 CRAN (R 3.4.0)
## htmltools 0.3.6 2017-04-28 CRAN (R 3.4.0)
## httr * 1.3.1 2017-08-20 CRAN (R 3.4.1)
## jsonlite * 1.5 2017-06-01 CRAN (R 3.4.0)
## knitr 1.17 2017-08-10 cran (@1.17)
## lattice 0.20-35 2017-03-25 CRAN (R 3.4.1)
## lazyeval 0.2.0 2016-06-12 CRAN (R 3.4.0)
## lubridate 1.6.0 2016-09-13 CRAN (R 3.4.0)
## magrittr 1.5 2014-11-22 CRAN (R 3.4.0)
## memoise 1.1.0 2017-04-21 CRAN (R 3.4.0)
## methods * 3.4.1 2017-07-07 local
## mnormt 1.5-5 2016-10-15 CRAN (R 3.4.0)
## modelr 0.1.1 2017-08-10 local
## munsell 0.4.3 2016-02-13 CRAN (R 3.4.0)
## nlme 3.1-131 2017-02-06 CRAN (R 3.4.1)
## parallel 3.4.1 2017-07-07 local
## pkgconfig 2.0.1 2017-03-21 CRAN (R 3.4.0)
## plyr 1.8.4 2016-06-08 CRAN (R 3.4.0)
## psych 1.7.5 2017-05-03 CRAN (R 3.4.1)
## purrr * 0.2.3 2017-08-02 CRAN (R 3.4.1)
## R6 2.2.2 2017-06-17 CRAN (R 3.4.0)
## Rcpp 0.12.13 2017-09-28 cran (@0.12.13)
## readr * 1.1.1 2017-05-16 CRAN (R 3.4.0)
## readxl 1.0.0 2017-04-18 CRAN (R 3.4.0)
## reshape2 1.4.2 2016-10-22 CRAN (R 3.4.0)
## rlang 0.1.2 2017-08-09 CRAN (R 3.4.1)
## rmarkdown 1.6 2017-06-15 CRAN (R 3.4.0)
## rprojroot 1.2 2017-01-16 CRAN (R 3.4.0)
## rstudioapi 0.6 2016-06-27 CRAN (R 3.4.0)
## rvest 0.3.2 2016-06-17 CRAN (R 3.4.0)
## scales 0.4.1 2016-11-09 CRAN (R 3.4.0)
## stats * 3.4.1 2017-07-07 local
## stringi 1.1.5 2017-04-07 CRAN (R 3.4.0)
## stringr * 1.2.0 2017-02-18 CRAN (R 3.4.0)
## tibble * 1.3.4 2017-08-22 CRAN (R 3.4.1)
## tidyr * 0.7.0 2017-08-16 CRAN (R 3.4.1)
## tidyverse * 1.1.1.9000 2017-07-19 Github (tidyverse/tidyverse@a028619)
## tools 3.4.1 2017-07-07 local
## utils * 3.4.1 2017-07-07 local
## withr 2.0.0 2017-07-28 CRAN (R 3.4.1)
## XML * 3.98-1.9 2017-06-19 CRAN (R 3.4.1)
## xml2 1.1.1 2017-01-24 CRAN (R 3.4.0)
## yaml 2.1.14 2016-11-12 CRAN (R 3.4.0)Because I strip it out. We’ll see shortly how to handle nested lists-within-lists.↩
Based on Analyzing Emotions using Facial Expressions in Video with Microsoft AI and R, which is itself based on the original post How to apply face recognition API technology to data journalism with R and python, which served as the basis for The many debate faces of Donald Trump and Hillary Clinton.↩
Not exactly predictive of the election results.↩
This work is licensed under the CC BY-NC 4.0 Creative Commons License.