Getting data from the web: scraping
library(tidyverse)
library(rvest)
theme_set(theme_minimal())Web scraping
What if data is present on a website, but isn’t provided in an API at all? It is possible to grab that information too. How easy that is to do depends a lot on the quality of the website that we are using.
HTML
HTML is a structured way of displaying information. It is very similar in structure to XML (in fact many modern html sites are actually XHTML5, which is also valid XML)

Process
HyperText Markup Language (HTML) is the basic building block of the World Wide Web. It defines the structure and format of content on web pages. The HTML code is stored on a server and retrieved by your computer when you visit a web page.
- The web browser sends a request to the server that hosts the website.
- The server sends the browser an HTML document.
- The browser uses instructions in the HTML to render the website.
Components of HTML code
HTML code looks something like this:
<html>
<head>
<title>Title</title>
<link rel="icon" type="icon" href="http://a" />
<link rel="icon" type="icon" href="http://b" />
<script src="https://c.js"></script>
</head>
<body>
<div>
<p>Click <b>here</b> now.</p>
<span>Frozen</span>
</div>
<table style="width:100%">
<tr>
<td>Kristen</td>
<td>Bell</td>
</tr>
<tr>
<td>Idina</td>
<td>Menzel</td>
</tr>
</table>
<img src="http://ia.media-imdb.com/images.png"/>
</body>
</html>HTML code consists of markup code used to annotate text, images, and other content for display in a web browswer. As you can see, the code above consists of HTML elements which are created by a tag <>. Elements can also have attributes that configure the elements or adjust their behavior.
You can think of elements as R functions, and attributes are the arguments to functions. Not all functions require arguments, or they use default arguments.
<a href="http://github.com">GitHub</a><a></a>- tag namehref- attribute (name)"http://github.com"- attribute (value)GitHub- content
HTML code utilizes a nested structure. The above tags can be represented as:
htmlheadtitlelinklinkscript
bodydivpb
span
tabletrtdtd
trtdtd
img
Let’s say we want to find the content “here”. Which tag in our sample HTML code contains that content?
htmlheadtitlelinklinkscript
bodydivpb
span
tabletrtdtd
trtdtd
img
Find the source code
Navigate to the IMDB page for Frozen and open the source code. Locate the piece of HTML that inserts “Kristen Bell” into the cast section. Which HTML tag surrounds her name?
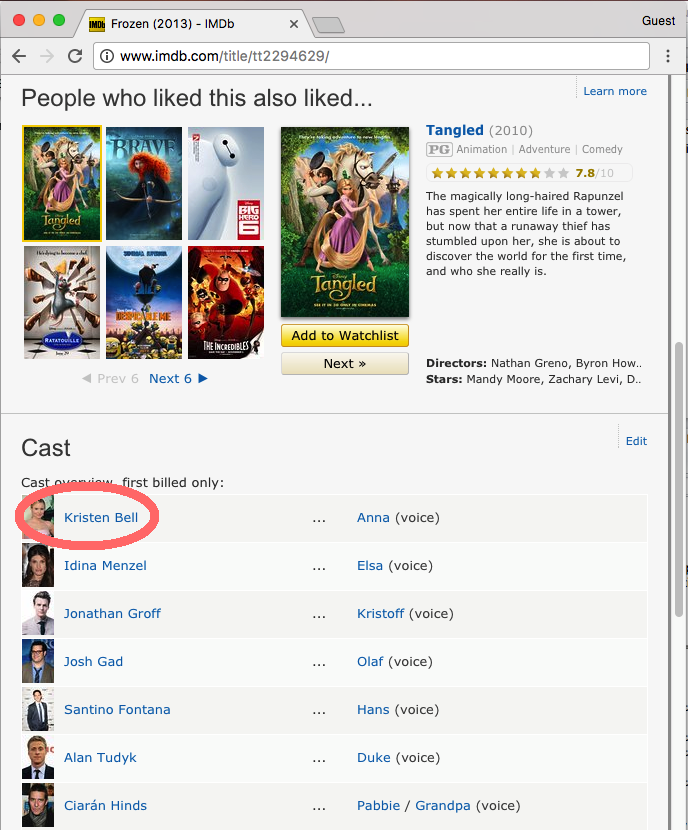
IMDB page for Frozen
Click for the solution
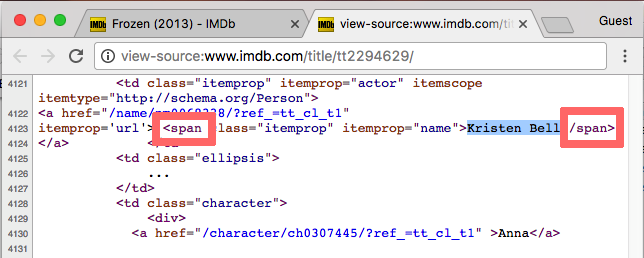
HTML tag for “Kristen Bell”
“Kristen Bell” is enclosed in the span tag. But look through the some of the other source code. span is used many times throughout the page. How can we select just the element containing “Kristen Bell”, or all the cast member names but nothing else?
CSS selectors
Cascading Style Sheets (CSS) are a flexible framework for customizing the appearance of elements in a web page. They work in conjunction with HTML to format the appearance of content on the web.
HTML
HTML only
HTML + CSS
HTML + CSS
CSS code
span {
color: #ffffff;
}
.num {
color: #a8660d;
}
table.data {
width: auto;
}
#firstname {
background-color: yellow;
}CSS uses selectors and styles. Selectors define to which elements of the HTML code the styles apply. A CSS script describes an element by its tag, class, and/or ID. Class and ID are defined in the HTML code as attributes of the element.
<span class="bigname" id="shiny">Shiny</span><span></span>- tag namebigname- class (optional)shiny- id (optional)
So a CSS selector of
spanwould select all elements with the span tag. Likewise, a CSS selector of
.bignameselects all elements with the bigname class (note the use of a . to select based on class). A CSS selector of
span.bignameselects all elements with the span tag and the bigname class. Finally,
#shinyselects all elements with the shiny id.
| Prefix | Matches |
|---|---|
| none | tag |
| . | class |
| # | id |
CSS diner is a JavaScript-based interactive game for learning and practicing CSS selectors. Take some time to play and learn more about CSS selector combinations.
Find the CSS selector
Which CSS identifiers are associated with Kristen Bell’s name in the Frozen page? Write a CSS selector that targets them.
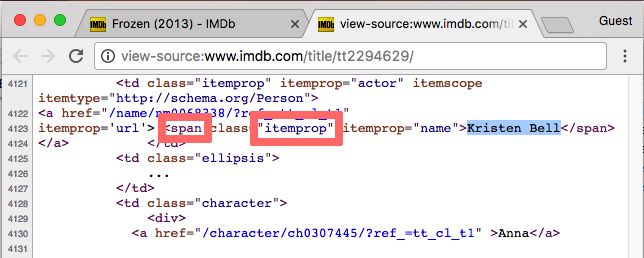
Click for the solution
span- the elementitemprop- the class
Therefore the CSS selector would be span.itemprop.
rvest
rvest is a package that contains functions to easily extract information from a webpage. The basic workflow is:
- Download the HTML and turn it into an XML file with
read_html() - Extract specific nodes with
html_nodes() - Extract content from nodes with various functions
Download the HTML
library(rvest)
frozen <- read_html("http://www.imdb.com/title/tt2294629/")
frozen## {xml_document}
## <html xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset= ...
## [2] <body id="styleguide-v2" class="fixed">\n<script>\n if (typeof ue ...It is always a good practice when web scraping to store the output of
read_html()in an object immediately, then apply further functions to the stored HTML file. Otherwise you send a request to the server every time you extract information from the HTML. For longer-term projects, you can storeread_html()objects locally on your computer usingreadr::write_rds()and retrieve them usingreadr::read_rds(). This caches a local copy of the file so you always have a copy preserved, in case the webpage’s underlying HTML code is modified (or the website is taken offline).
Extract nodes
itals <- html_nodes(frozen, "em")
itals## {xml_nodeset (1)}
## [1] <em class="nobr">Written by\n<a href="/search/title?plot_author=DeAl ...- The first argument to
html_nodes()is the HTML document or a node previously extracted from the document - The second argument is a CSS selector to identify which nodes to select
Extract content from nodes
itals## {xml_nodeset (1)}
## [1] <em class="nobr">Written by\n<a href="/search/title?plot_author=DeAl ...html_text(itals)## [1] "Written by\nDeAlan Wilson for ComedyE.com"html_name(itals)## [1] "em"html_children(itals)## {xml_nodeset (1)}
## [1] <a href="/search/title?plot_author=DeAlan%20Wilson%20for%20ComedyE.c ...html_attr(itals, "class")## [1] "nobr"html_attrs(itals)## [[1]]
## class
## "nobr"Extract content
Now it’s your turn to practice.
- Read in the Frozen HTML
- Select the nodes that are both
spans andclass = "itemprop" - Extract the text from the nodes
Click for the solution
library(rvest)
frozen <- read_html("http://www.imdb.com/title/tt2294629/")
cast <- html_nodes(frozen, "span.itemprop")
html_text(cast)## [1] "Animation" "Adventure"
## [3] "Comedy" "Chris Buck"
## [5] "Jennifer Lee" "Jennifer Lee"
## [7] "Hans Christian Andersen" "Kristen Bell"
## [9] "Idina Menzel" "Jonathan Groff"
## [11] "Kristen Bell" "Idina Menzel"
## [13] "Jonathan Groff" "Josh Gad"
## [15] "Santino Fontana" "Alan Tudyk"
## [17] "Ciarán Hinds" "Chris Williams"
## [19] "Stephen J. Anderson" "Maia Wilson"
## [21] "Edie McClurg" "Robert Pine"
## [23] "Maurice LaMarche" "Livvy Stubenrauch"
## [25] "Eva Bella" "female protagonist"
## [27] "snowman" "sister sister relationship"
## [29] "magic" "sister love"
## [31] "Walt Disney Animation Studios" "Walt Disney Pictures"Do you collect the cast names and only the cast names? We’ve scraped too much. The problem is that our CSS selector is not specific enough for our needs. We need an easy way to identify CSS selector combinations to extract only the content we want, and nothing more.
SelectorGadget
SelectorGadget is a GUI tool used to identify CSS selector combinations from a webpage.
Install SelectorGadget
- Run
vignette("selectorgadget") - Drag SelectorGadget link into your browser’s bookmark bar
Using SelectorGadget
- Navigate to a webpage
- Open the SelectorGadget bookmark
- Click on the item to scrape
- Click on yellow items you do not want to scrape
- Click on additional items that you do want to scrape
- Rinse and repeat until only the items you want to scrape are highlighted in yellow
- Copy the selector to use with
html_nodes()
When using SelectorGadget, always make sure to scroll up and down the web page to make sure you have properly selected only the content you want.
Practice using SelectorGadget
- Install SelectorGadget in your browser
- Use SelectorGadget to find a CSS selector combination that identifies just the cast member names
Click for the solution
cast2 <- html_nodes(frozen, "#titleCast span.itemprop")
html_text(cast2)## [1] "Kristen Bell" "Idina Menzel" "Jonathan Groff"
## [4] "Josh Gad" "Santino Fontana" "Alan Tudyk"
## [7] "Ciarán Hinds" "Chris Williams" "Stephen J. Anderson"
## [10] "Maia Wilson" "Edie McClurg" "Robert Pine"
## [13] "Maurice LaMarche" "Livvy Stubenrauch" "Eva Bella"cast3 <- html_nodes(frozen, ".itemprop .itemprop")
html_text(cast3)## [1] "Kristen Bell" "Idina Menzel" "Jonathan Groff"
## [4] "Josh Gad" "Santino Fontana" "Alan Tudyk"
## [7] "Ciarán Hinds" "Chris Williams" "Stephen J. Anderson"
## [10] "Maia Wilson" "Edie McClurg" "Robert Pine"
## [13] "Maurice LaMarche" "Livvy Stubenrauch" "Eva Bella"Practice scraping data
Look up the cost of living for your hometown on Sperling’s Best Places. Then extract it with html_nodes() and html_text().
Click for the solution
For me, this means I need to obtain information on Sterling, Virginia.
sterling <- read_html("http://www.bestplaces.net/cost_of_living/city/virginia/sterling")
col <- html_nodes(sterling, css = "#mainContent_dgCostOfLiving tr:nth-child(2) td:nth-child(2)")
html_text(col)## [1] "136"# or use a piped operation
sterling %>%
html_nodes(css = "#mainContent_dgCostOfLiving tr:nth-child(2) td:nth-child(2)") %>%
html_text()## [1] "136"Tables
Use html_table() to scrape whole tables of data as a data frame.
tables <- html_nodes(sterling, css = "table")
tables %>%
# get the second table
nth(2) %>%
# convert to data frame
html_table(header = TRUE)## COST OF LIVING Sterling, Virginia United States
## 1 Overall 136.0 100
## 2 Grocery 113.9 100
## 3 Health 101.0 100
## 4 Housing 203.0 100
## 5 Utilities 107.0 100
## 6 Transportation 108.0 100
## 7 Miscellaneous 98.0 100Extract climate statistics
Visit the climate tab for your home town. Extract the climate statistics of your hometown as a data frame with useful column names.
Click for the solution
For me, this means I need to obtain information on Sterling, Virginia.
sterling_climate <- read_html("http://www.bestplaces.net/climate/city/virginia/sterling")
climate <- html_nodes(sterling_climate, css = "table")
html_table(climate, header = TRUE, fill = TRUE)[[2]]## CLIMATE Sterling, Virginia United States
## 1 Rainfall (in.) 42.0447 39.2
## 2 Snowfall (in.) 21.5351 25.8
## 3 Precipitation Days 74.1000 102
## 4 Sunny Days 197.0000 205
## 5 Avg. July High 87.4170 86.1
## 6 Avg. Jan. Low 23.9660 22.6
## 7 Comfort Index (higher=better) 47.0000 54
## 8 UV Index 4.0000 4.3
## 9 Elevation ft. 457.0000 1,443sterling_climate %>%
html_nodes(css = "table") %>%
nth(2) %>%
html_table(header = TRUE)## CLIMATE Sterling, Virginia United States
## 1 Rainfall (in.) 42.0447 39.2
## 2 Snowfall (in.) 21.5351 25.8
## 3 Precipitation Days 74.1000 102
## 4 Sunny Days 197.0000 205
## 5 Avg. July High 87.4170 86.1
## 6 Avg. Jan. Low 23.9660 22.6
## 7 Comfort Index (higher=better) 47.0000 54
## 8 UV Index 4.0000 4.3
## 9 Elevation ft. 457.0000 1,443Acknowledgments
- Web scraping lesson drawn from Extracting data from the web APIs and beyond
- HTML| Mozilla Developer Network
- CSS | Mozilla Developer Network
Session Info
devtools::session_info()## Session info -------------------------------------------------------------## setting value
## version R version 3.4.1 (2017-06-30)
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## tz America/Chicago
## date 2017-11-14## Packages -----------------------------------------------------------------## package * version date source
## assertthat 0.2.0 2017-04-11 CRAN (R 3.4.0)
## backports 1.1.0 2017-05-22 CRAN (R 3.4.0)
## base * 3.4.1 2017-07-07 local
## bindr 0.1 2016-11-13 CRAN (R 3.4.0)
## bindrcpp 0.2 2017-06-17 CRAN (R 3.4.0)
## boxes 0.0.0.9000 2017-07-19 Github (r-pkgs/boxes@03098dc)
## broom 0.4.2 2017-08-09 local
## cellranger 1.1.0 2016-07-27 CRAN (R 3.4.0)
## clisymbols 1.2.0 2017-05-21 cran (@1.2.0)
## colorspace 1.3-2 2016-12-14 CRAN (R 3.4.0)
## compiler 3.4.1 2017-07-07 local
## crayon 1.3.4 2017-10-03 Github (gaborcsardi/crayon@b5221ab)
## datasets * 3.4.1 2017-07-07 local
## devtools 1.13.3 2017-08-02 CRAN (R 3.4.1)
## digest 0.6.12 2017-01-27 CRAN (R 3.4.0)
## dplyr * 0.7.4.9000 2017-10-03 Github (tidyverse/dplyr@1a0730a)
## evaluate 0.10.1 2017-06-24 CRAN (R 3.4.1)
## forcats * 0.2.0 2017-01-23 CRAN (R 3.4.0)
## foreign 0.8-69 2017-06-22 CRAN (R 3.4.1)
## ggplot2 * 2.2.1 2016-12-30 CRAN (R 3.4.0)
## glue 1.1.1 2017-06-21 CRAN (R 3.4.1)
## graphics * 3.4.1 2017-07-07 local
## grDevices * 3.4.1 2017-07-07 local
## grid 3.4.1 2017-07-07 local
## gtable 0.2.0 2016-02-26 CRAN (R 3.4.0)
## haven 1.1.0 2017-07-09 CRAN (R 3.4.1)
## hms 0.3 2016-11-22 CRAN (R 3.4.0)
## htmltools 0.3.6 2017-04-28 CRAN (R 3.4.0)
## httr 1.3.1 2017-08-20 CRAN (R 3.4.1)
## jsonlite 1.5 2017-06-01 CRAN (R 3.4.0)
## knitr 1.17 2017-08-10 cran (@1.17)
## lattice 0.20-35 2017-03-25 CRAN (R 3.4.1)
## lazyeval 0.2.0 2016-06-12 CRAN (R 3.4.0)
## lubridate 1.6.0 2016-09-13 CRAN (R 3.4.0)
## magrittr 1.5 2014-11-22 CRAN (R 3.4.0)
## memoise 1.1.0 2017-04-21 CRAN (R 3.4.0)
## methods * 3.4.1 2017-07-07 local
## mnormt 1.5-5 2016-10-15 CRAN (R 3.4.0)
## modelr 0.1.1 2017-08-10 local
## munsell 0.4.3 2016-02-13 CRAN (R 3.4.0)
## nlme 3.1-131 2017-02-06 CRAN (R 3.4.1)
## parallel 3.4.1 2017-07-07 local
## pkgconfig 2.0.1 2017-03-21 CRAN (R 3.4.0)
## plyr 1.8.4 2016-06-08 CRAN (R 3.4.0)
## psych 1.7.5 2017-05-03 CRAN (R 3.4.1)
## purrr * 0.2.3 2017-08-02 CRAN (R 3.4.1)
## R6 2.2.2 2017-06-17 CRAN (R 3.4.0)
## Rcpp 0.12.13 2017-09-28 cran (@0.12.13)
## readr * 1.1.1 2017-05-16 CRAN (R 3.4.0)
## readxl 1.0.0 2017-04-18 CRAN (R 3.4.0)
## reshape2 1.4.2 2016-10-22 CRAN (R 3.4.0)
## rlang 0.1.2 2017-08-09 CRAN (R 3.4.1)
## rmarkdown 1.6 2017-06-15 CRAN (R 3.4.0)
## rprojroot 1.2 2017-01-16 CRAN (R 3.4.0)
## rstudioapi 0.6 2016-06-27 CRAN (R 3.4.0)
## rvest * 0.3.2 2016-06-17 CRAN (R 3.4.0)
## scales 0.4.1 2016-11-09 CRAN (R 3.4.0)
## stats * 3.4.1 2017-07-07 local
## stringi 1.1.5 2017-04-07 CRAN (R 3.4.0)
## stringr * 1.2.0 2017-02-18 CRAN (R 3.4.0)
## tibble * 1.3.4 2017-08-22 CRAN (R 3.4.1)
## tidyr * 0.7.0 2017-08-16 CRAN (R 3.4.1)
## tidyverse * 1.1.1.9000 2017-07-19 Github (tidyverse/tidyverse@a028619)
## tools 3.4.1 2017-07-07 local
## utils * 3.4.1 2017-07-07 local
## withr 2.0.0 2017-07-28 CRAN (R 3.4.1)
## xml2 * 1.1.1 2017-01-24 CRAN (R 3.4.0)
## yaml 2.1.14 2016-11-12 CRAN (R 3.4.0)This work is licensed under the CC BY-NC 4.0 Creative Commons License.