Cloud Resume Challenge Part 3
AWS Cloud Resumé Challenge: Part 3¶
Introduction¶
This is part three of the AWS Cloud Resumé Challenge, in which I productize the creation of the AWS Cloud configuration that I previously created by clicking around in the AWS Console, like a demented Click Monkey.
Having the AWS setup as a code file, then allows it to be placed under configuration control: Configuration as Code.
I found a few wrinkles and gotchas that I will go through below.
To Recap¶
The design that I will be creating by configuration code is that below (figure from a previous post).

The Browser client has embedded Javascript code that calls the endpoint of an API Gateway instance. The API Gateway instance calls a AWS Lambda function, that reads, increments, and writes back a counter held in a DynamoDB datatable.
Design Choices¶
Play it again, Sam¶
The configuration language I could have used is called AWS CloudFormation, which is the more general purpose configuration language. However, Amazon (and the general AWS Cloud community) heavily push the AWS Serverless Application Model (SAM) option. Configurations in SAM are build into CloudFormation specifications, but are much more concise, and a lot of the "best-practice" work is done for you.
Downsides¶
One gotcha I encountered in dealing with AWS SAM is that it is much better to do everything through SAM. Performing AWS Cloud operations (like deleting a DynamoDB datatable) in the AWS Console can confuse SAM when it comes time to build the configuration again. The official AWS advice for this case is "re-create every thing you deleted, and try again!".
You do have to become familiar with CloudFormation terminology (as it is SAM terminolgy too). The key concept is a Stack; a set of AWS capabilities that operate, and are linked, to achieve some task.
SAM Configuration Walkthrough¶
I found that it was best to incrementally learn SAM by creating parts of the processing chain in isolation. First the DynamoDB database table, then the Lambda Function. I won't go through all my interim steps, but just walk through my final result.
Because I am a Windows user, I went very old-school, and have a .bat file to run my builds.
Excluding the header comments, it looks like:
ECHO ON
ECHO Deleting previous stack
call aws cloudformation delete-stack --stack-name loadcounter01
call aws cloudformation wait stack-delete-complete --stack-name loadcounter01
REM -----------------------------
ECHO ON
ECHO Starting SAM Build
call sam build
ECHO Starting SAM Deploy
call sam deploy --guided
ECHO Loading initial data
call aws dynamodb batch-write-item --request-items file://initialloaddata.json
Note that I am hard-coding the name of my stack in this script (loadcounter01).
To walk through each command:
aws cloudformation delete-stack --stack-name loadcounter01
I expect to be running this script repeatably. For this application I am happy to trash whatever state is stored in the database (the API Gateway instance, and the Lambda Function, have no state, by definition). If I was concerned with maintaining my load-count across build, I would have to read the DynamoDB database, store the data, and reload it into the newly re-created database at the end of the script.
It turns out that the delete-stack command doesn't actually delete the CloudFormation stack, it only initiates the delete operation. You have to wait to is is complete, via:
aws cloudformation wait stack-delete-complete --stack-name loadcounter01
So now we have a clean slate. We build the CloudFormation configuration via the
sam build
Then we deploy it. I have chosen to use the --guided option so I could see what was happening, but if you added the appropriate command line options, this could be completely automated.
sam deploy --guided
Finally, I load an initial dataset into the DynamoDB datatable
aws dynamodb batch-write-item --request-items file://initialloaddata.json
Script Outputs¶
SAM Build¶
The results (in part) of running the script above are:
(ac5-py37) D:\AWS-SAM-Working\loadcounter01>call sam build
Building function 'ManageCounterFunction'
Running PythonPipBuilder:ResolveDependencies
Running PythonPipBuilder:CopySource
Build Succeeded
Built Artifacts : .aws-sam\build
Built Template : .aws-sam\build\template.yaml
Commands you can use next
=========================
[*] Invoke Function: sam local invoke
[*] Deploy: sam deploy --guided
SAM Deploy¶
The output from the SAM deployment looks in part like:
Configuring SAM deploy
======================
Looking for samconfig.toml : Found
Reading default arguments : Success
Setting default arguments for 'sam deploy'
=========================================
Stack Name [loadcounter01]:
AWS Region [ap-southeast-2]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [Y/n]: y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: y
ManageCounterFunction may not have authorization defined, Is this okay? [y/N]: y
Save arguments to samconfig.toml [Y/n]: y
Looking for resources needed for deployment: Found!
Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-1dgbnny6g7a0
A different default S3 bucket can be set in samconfig.toml
Saved arguments to config file
Running 'sam deploy' for future deployments will use the parameters saved above.
Note that I had run this SAM configuration file many time in my debugging / development effort, and the deployment process had remembered some state. First, the .toml file that remembered my previous choices for the guided deployment. Second, the S3 Bucket used for deployment already existed, and so didn't need to be rebuilt. Now I think about it, I wonder why it didn't get deleted in the delete-stack operation? One thing to consider in the cleanup process if you decide to not use a CloudFormation Stack ever again.
Once the desired configuration is known, SAM works out what needs changing (in my case, everything)
| Operation | LogicalResourceId | ResourceType |
|---|---|---|
| + Add | LoadCounterTable | AWS::DynamoDB::Table |
| + Add | ManageCounterFunctionCounterAccessApiPermissionProd | AWS::Lambda::Permission |
| + Add | ManageCounterFunctionRole | AWS::IAM::Role |
| + Add | ManageCounterFunction | AWS::Lambda::Function |
| + Add | ServerlessRestApiDeployment4b9917be34 | AWS::ApiGateway::Deployment |
| + Add | ServerlessRestApiProdStage | AWS::ApiGateway::Stage |
| + Add | ServerlessRestApi | AWS::ApiGateway::RestApi |
You then get (because of --guided) to decide whether to proceed
Changeset created successfully. arn:aws:cloudformation:ap-southeast-2:261204630592:changeSet/samcli-deploy1598338401/94778c3f-f4cd-45c4-993a-21e4cd31b500
Previewing CloudFormation changeset before deployment
======================================================
Deploy this changeset? [y/N]: y
2020-08-25 16:53:39 - Waiting for stack create/update to complete
You then get a number of CREATE_IN_PROGRESS and CREATE_COMPLETE messages, and finally:
Successfully created/updated stack - loadcounter01 in ap-southeast-2
The final DynamoDB batch-write is silent, but I guess would complain if the expected data table was not present.
Now, in order for our soon-to-be-constructed webpage to be able to use this Stack, we have to know the
endpoint by which we can access the API Gateway instance. In my SAM configuration (described below), I create a Stack Output, that gives this endpoint.
So by running a command as below, we can get this endpoint.
(ac5-py37) D:\AWS-SAM-Working\loadcounter01>aws cloudformation describe-stacks --stack-name loadcounter01 --query Stacks[0].Outputs[?OutputKey==`CounterAccessApi`].OutputValue --output text
https://byhpjqrzn9.execute-api.ap-southeast-2.amazonaws.com/Prod/counter/
This says:
get the first Stack in the list I am processing (and because I specified the stackname explicitly, there is only one Stack)
get the Output with the OutputKey equal to a key we have defined in the configuration file
get the OutputValue
show it as text (could be JSON, etc)
Now I have an endpoint (https://byhpjqrzn9.execute-api.ap-southeast-2.amazonaws.com/Prod/counter/) that I can use in my Javascript in my webpage.
I cheated: I manually edited the webpage Javascript in resume.html, and reloaded it into the S3 Bucket that AWS CloudFront is using as the source of my webpage. But I could have automated this process, honest.
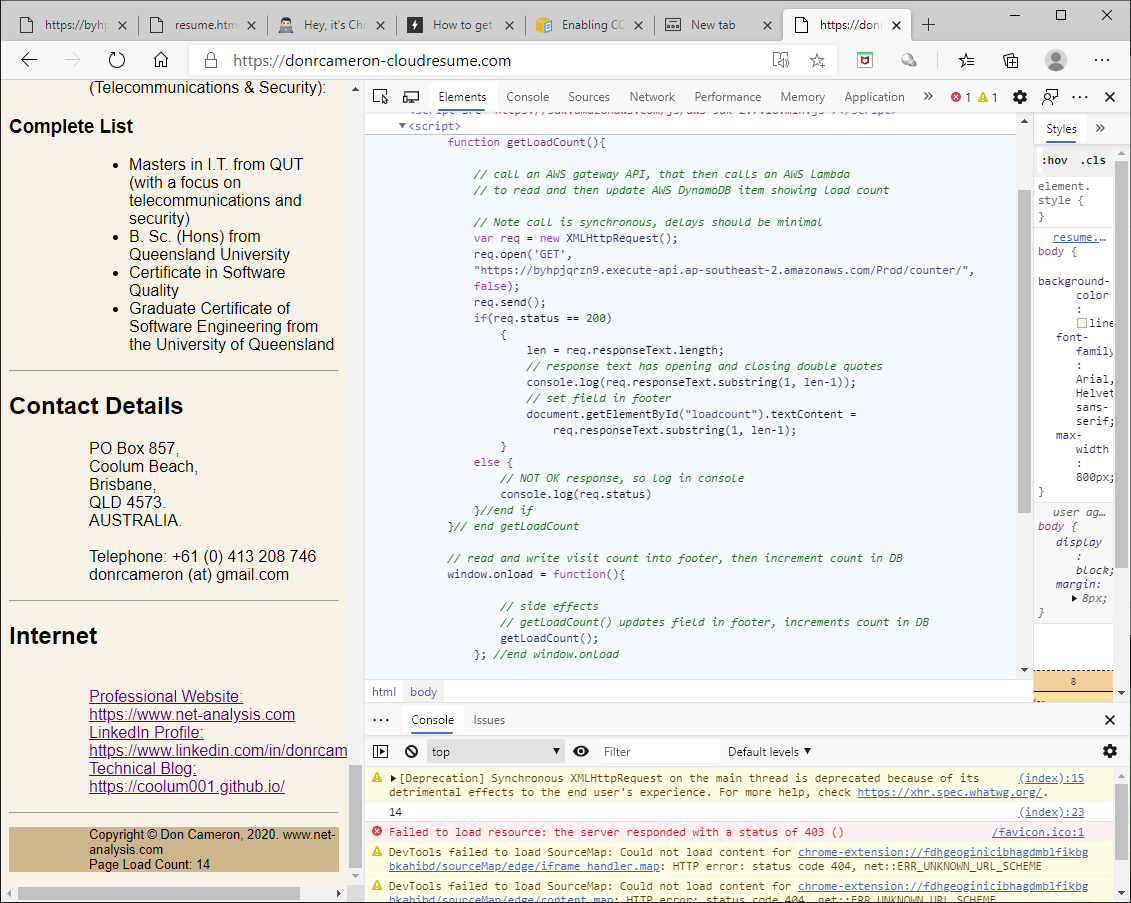
Note again the warning about my (mis)use of the Synchronous XMLHttpRequest. I have decided that it is acceptable in my circumstances, where back-end processing is minimal, and minimising page-load times are not a significant design issue.
Header comments¶
# ----------------------------------------
# ASW SAM YAML Template
#
# Purpose:
# To create:
# a DynamoDB database, for page load count statistics
# a AWS Lambda function with HTTP endpoint
#
# Lambda function will read and increment a counter, and update
# counter in database
#
# The API endpoint will be called via Javascript from a HTML page
#
# Notes:
# - DynamoDB table name must match that used in the Lambda Function Python
# - DynamoDB table primary key must match that used in Lambda Function Python
# - The Lambda API endpoint must match that used in the Javascript of the Resume Web Page
# - Initial data load script must define a secondary attribute 'loadcount'
# initialized to an integer value
# - Initial data load must create row with 'appname'== 'ResumeApp'
#
# - The Lambda function is granted full access to DynamoDB - may be excessive?
#
# Author - D Cameron donrcameron@gmail.com
# Date - 2020-08-24
#
I was not able to find any SAM header comment standards or guidelines, so I invented my own. In this header, I tried to define all the moving parts that had to mesh (and, of course, should be automated).
For example, I could have defined the DynamoDB table name externally, and automatically ensured that it was the same the in the Lambda Python and in this configuration file
The next two lines are mandatory (I don't know if there are any other Transforms defined by Amazon or third parties)
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
I elected to have place-holders for all the SAM top-level sections I don't use. The Description section briefly states the purpose of the SAM for display in the AWS Console
Description: Creates a HTTP API Function and DynamoDB datatable
# end Description
# Globals:
# No Globals defined
# Metadata:
# No Metadata defined
# Parameters:
# No Parameters defined
# Mappings:
# No mappings defined
# Conditions:
# No Conditions defined
The main meat of the SAM is in the Resources section
Resources:
Database Specification¶
The first resource we define is the DynamoDB table. As an aside, I find it hard to track levels of indentation, so I like to show explicitly where sub-sections begin and end. I usually choose to have all name and identifiers used across boundaries to be all lowercase, to reduce possible sources of error.
# --------------------------------------
# define a DynamoDB table resource
LoadCounterTable:
Type: AWS::Serverless::SimpleTable
Properties:
# Creates a DynamoDB table with a single attribute
# primary key. It is useful when data only needs to be
# accessed via a primary key.
TableName: loadcounter2
PrimaryKey:
Name: appname
Type: String
ProvisionedThroughput:
# 5 reads/writes per second before throttling should be ample
# expect access to be in 5 reads/writes a day
ReadCapacityUnits: 5
WriteCapacityUnits: 5
# Tags:
# No Tags defined
# SSESpecification
# No Server Side Encryption defined
#end LoadCounterTable:
Lambda Function¶
The second resource is our Lambda Function. We specify that our Lambda code is in Python 3.7, and is held in a file app.py held in the directory Lambda, and the function to be called to handle events is lambda_handler. We know our Lambda function needs access to DynamoDB, so we define a policy (predefined by AWS) that allows this.
About the only wrinkle here (and the main difference between this solution, and the previous AWS Console solutions), is that the API Gateway instance we create is implicit in the definition of the Events that will trigger this Lambda.
This means that the Cross-Origin Resource Sharing (CORS) configuration to allow general browser access has to be done at run-time, in our Python Lamda code. This will be shown below.
# --------------------------------------
# Define an HTTP API Lambda Function
ManageCounterFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: Lambda/
Handler: app.lambda_handler
Runtime: python3.7
Policies:
# Give DynamoDB Full Access to the Lambda Function
AmazonDynamoDBFullAccess
Events:
CounterAccessApi:
Type: Api
Properties:
Path: /counter
Method: get
# end ManageCounterFunction
# --------------------------------------
Finally we define an output for our Stack, that actually exposes the endpoint for the API Gateway instance. In AWS SAM, the Stage used seems to be hardcoded to Prod, and the internal AWS documentation says "This API defaults to a StageName called "Prod" that cannot be configured"
The two expressions enclosed in { and } are either:
- CloudFormation resources generated By SAM (AWS::ApiGateway::RestApi -> ServerlessRestApi), or
- Pseudo parameters, that are parameters predefined by AWS CloudFormation (AWS::Region returns a string representing the AWS Region)
Outputs:
# --------------------------------------
# Define a AWS CloudFormation Stack Output,
# that will show the HTTP URL to access function
#
# This can be accessed by
# aws cloudformation describe-stacks \
# --stack-name loadcounter01 \
# --query Stacks[0].Outputs[?OutputKey==`CounterAccessApi`].OutputValue \
# --output text
CounterAccessApi:
Description: "endpoint for api to python "
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/counter/"
# end CounterAccessApi
# end Outputs -----------------------------
Python Business Logic¶
The Python code is fairly simple:
- get current load count, held as string in DynamoDB
- increment value
- store updated counter back into DynamoDB
- return value to caller
Note:
- there are two API's to write to the DynamoDB; I used the newer, preferred call (but it is slightly more complicated)
- in order for browser access to this function, I need CORS enabled. This is done by explicitly writing back the HTTP
headers that says we are prepared to accepts requests from any DNS domain.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('loadcounter2')
def lambda_handler(event, context):
response = table.get_item(Key={'appname': 'ResumeApp'})
count = response["Item"]["loadcount"]
# increment string version of visit count
new_count = str(int(count) + 1)
response = table.update_item(
Key={'appname': 'ResumeApp'},
UpdateExpression='set loadcount = :c',
ExpressionAttributeValues={':c': new_count},
ReturnValues='UPDATED_NEW',
)
return {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Headers": "Content-Type",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "OPTIONS,POST,GET",
},
"body": json.dumps(new_count),
}
# end lambda_handler
Javascript Presentation Logic¶
The presentation logic is straightforward. When the resume page has loaded, make a XMLHttpRequest, extract the current counter, and store in a predefined field in the page.
function getLoadCount(){
// call an AWS gateway API, that then calls an AWS Lambda
// to read and then update AWS DynamoDB item showing load count
// Note call is synchronous, delays should be minimal
var req = new XMLHttpRequest();
req.open('GET',
"https://byhpjqrzn9.execute-api.ap-southeast-2.amazonaws.com/Prod/counter/",
false);
req.send();
if(req.status == 200)
{
len = req.responseText.length;
// response text has opening and closing double quotes
console.log(req.responseText.substring(1, len-1));
// set field in footer
document.getElementById("loadcount").textContent =
req.responseText.substring(1, len-1);
}
else {
// NOT OK response, so log in console
console.log(req.status)
}//end if
}// end getLoadCount
// read and write visit count into footer, then increment count in DB
window.onload = function(){
// side effects
// getLoadCount() updates field in footer, increments count in DB
getLoadCount();
}; //end window.onload
AWS Console View¶
We can view the results of the Stack deployment in the AWS Console.
First the Stack we have created and deployed.
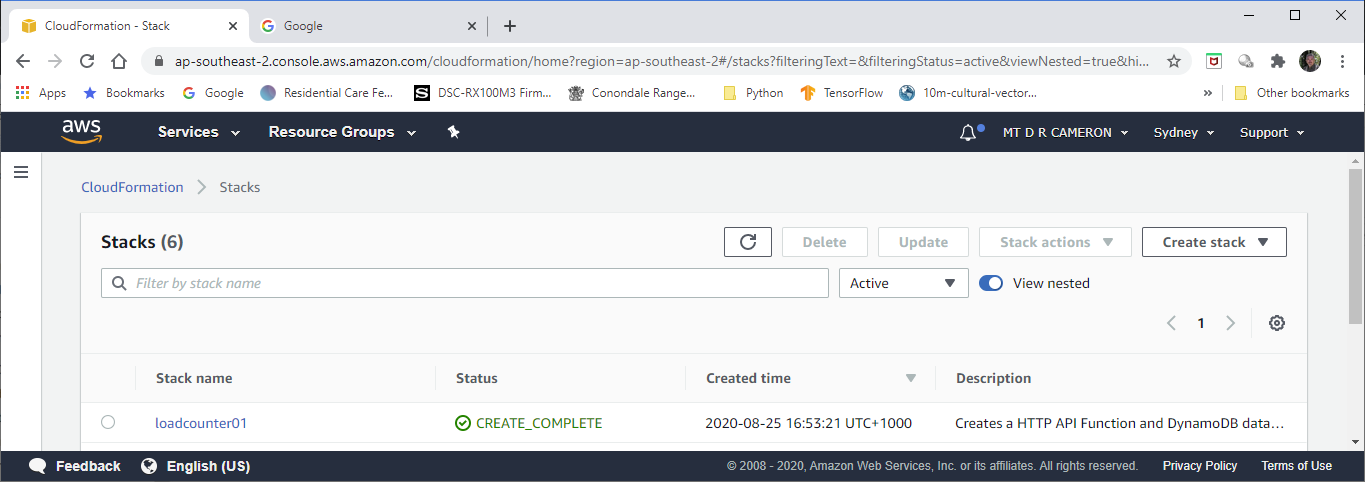
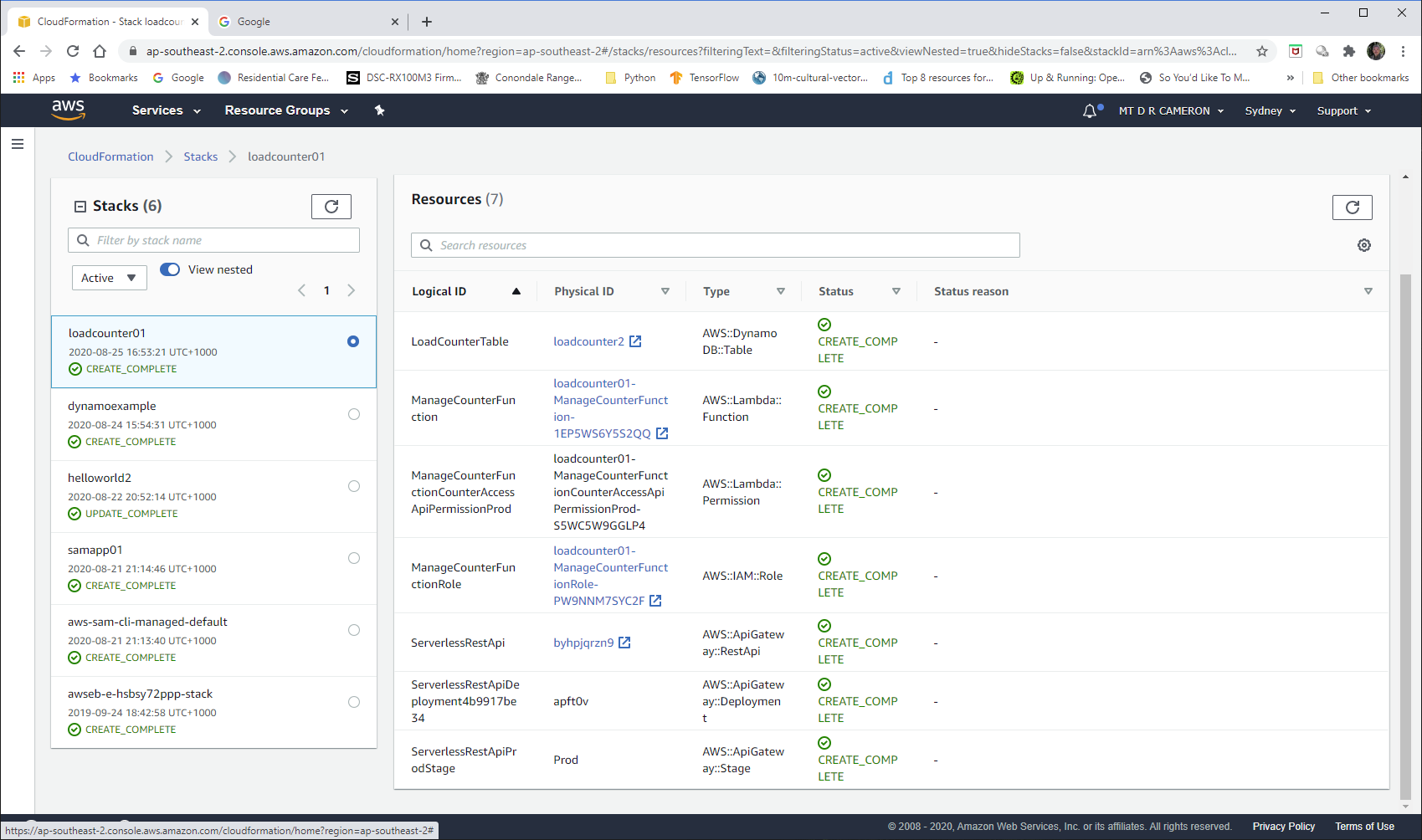
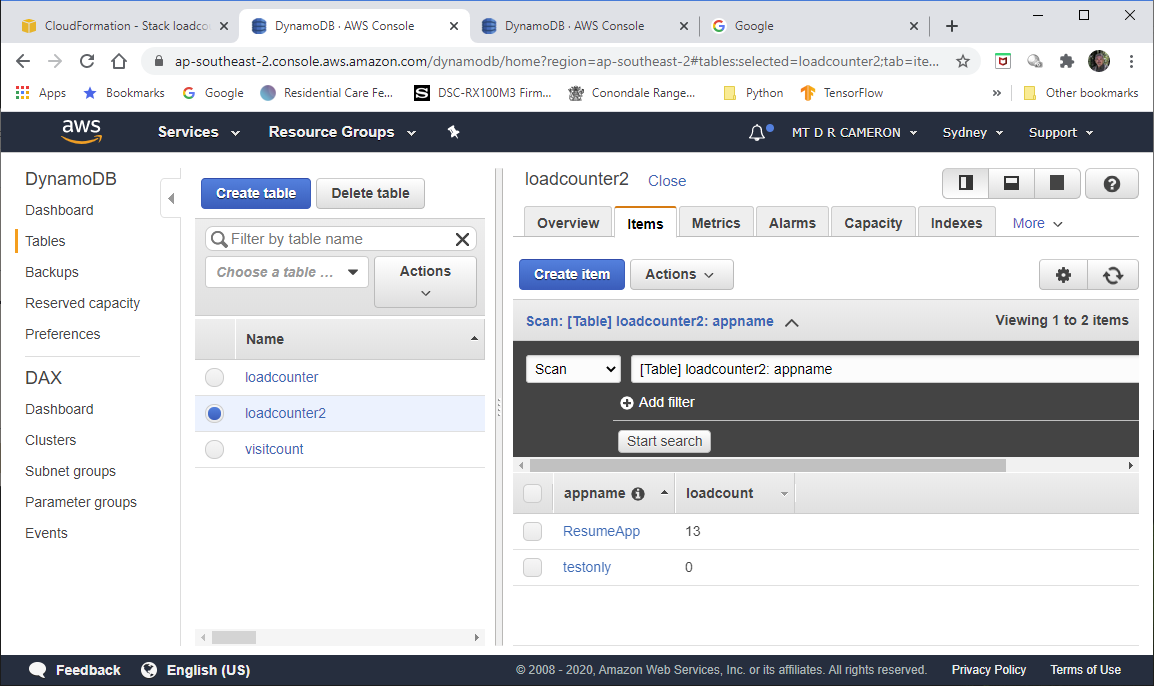
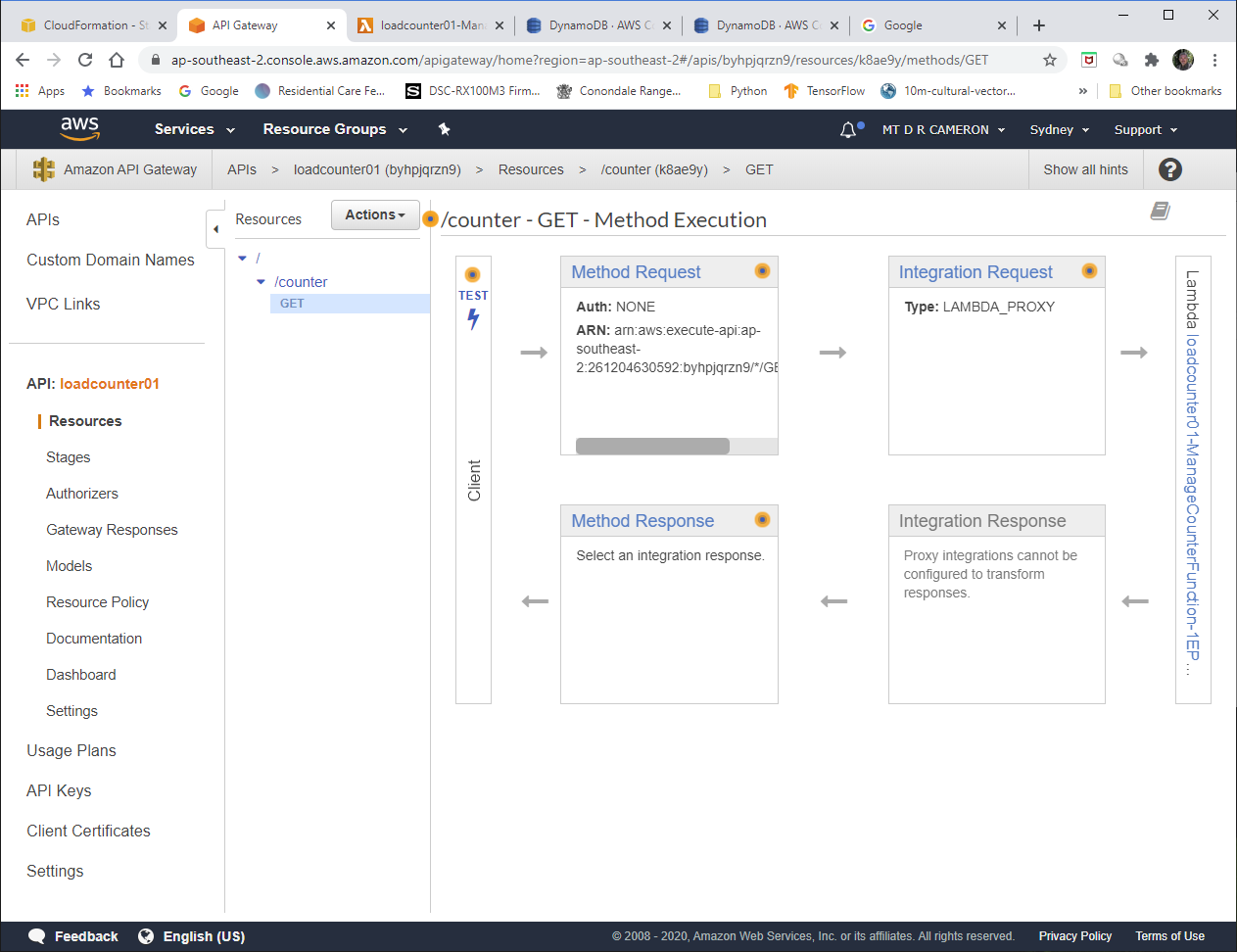
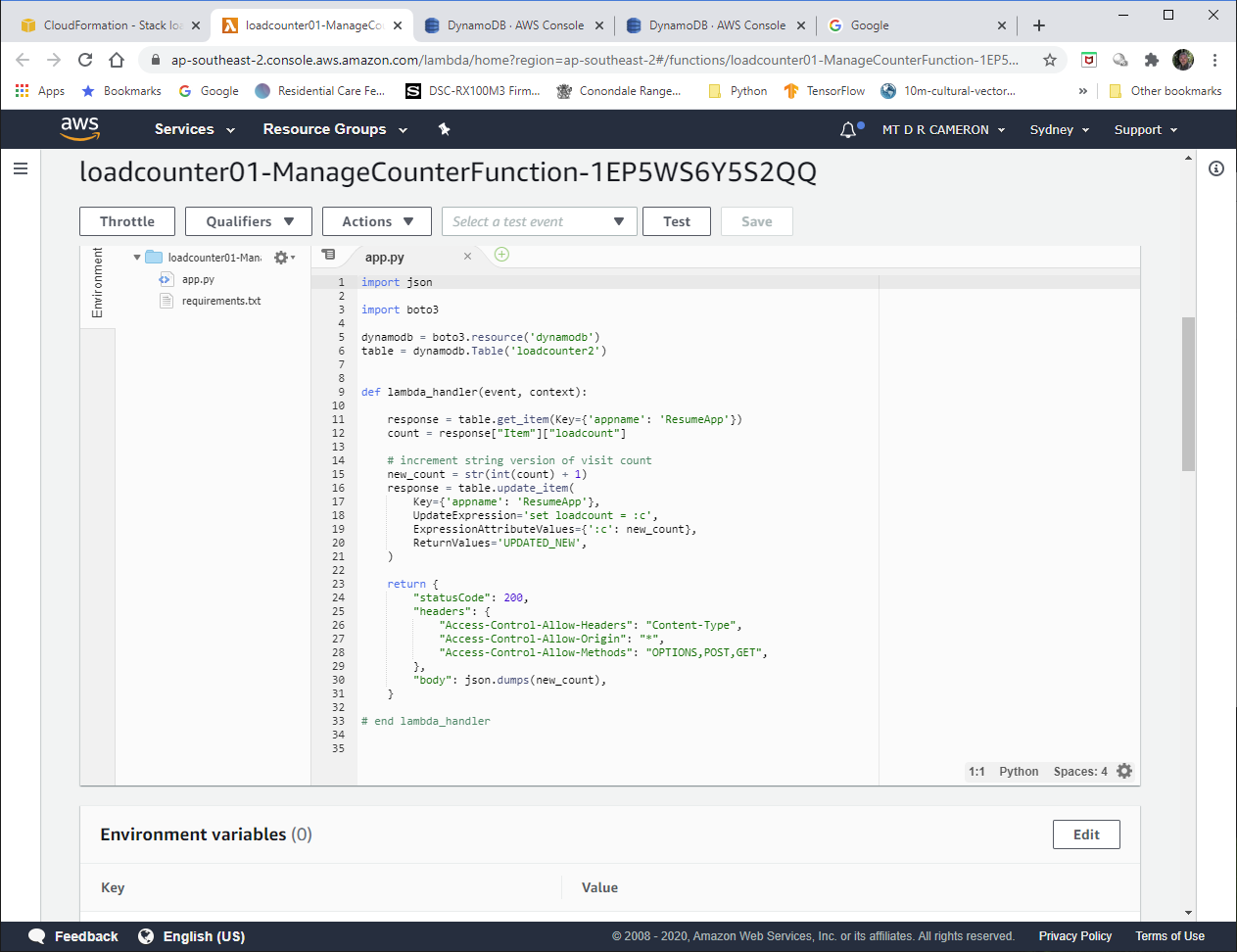
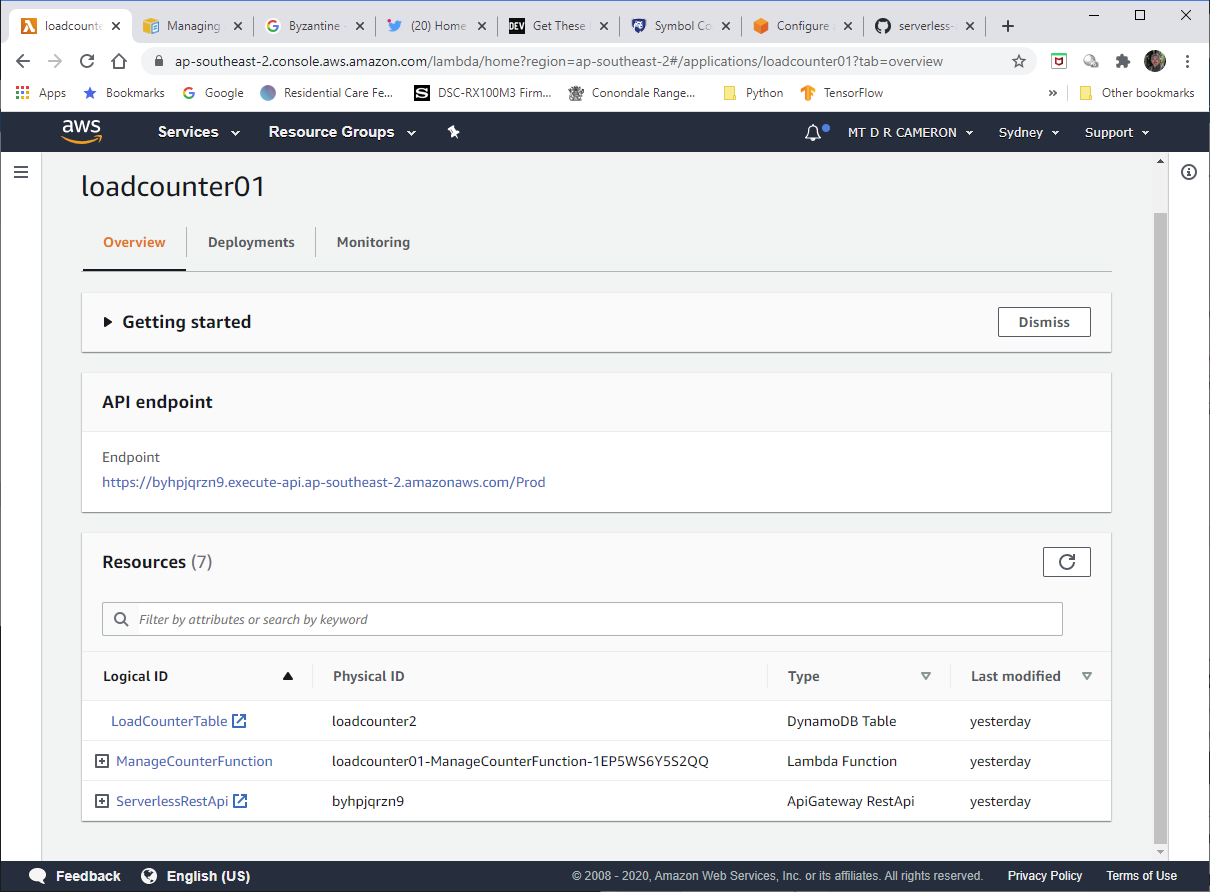
Conclusions¶
I must say that I feel very unsatisfied with my solution, for a number of reasons. I feel like someone who has scratched out a "Hello World" app, but who knows there is much more to software engineering that that.
First, I didn't explore any other approaches. For example, I might have defined a Lambda Function that was triggered by down-loads from my S3 Bucket holding my HTML, to update the database, and another Function for the browser to call to read from the database. As I said initially, I just wanted to automatically re-create a manually crafted solution.
More importantly, I feel there are significant design questions that this toy example ignores. For example:
If I want to avoid Denial-of-Wallet attacks, how to I stop a malicious agent from running up huge bills for me? I have attempted to control this by limiting database access, but I don't know if this works, or is best practice. There is a "Throttle" button in the Lambda Console UI, but it seems to be a last-resort kill-switch.
What am I supposed to do with the Roles that have automatically been created? I dimly suspect that I am supposed to use these to define Privilege Boundaries, and apply them to the Roles. For example, the Lambda Function has access to all the database; I would like to limit it to one table, in case of code-injecting into my Lambda Function.
What security issues have I ignored? For example, if a end-user disables Javascript, their download will not increment the download counter - in this case I don't care. I suspect that I should have payed a lot more care in defining AWS Roles, and profiles to use in running SAM commands.
The full support for Staging (Development -> Test -> Production Beta -> Full Production) doesn't seem to be supported by SAM. I don't know how to achieve this.
Now clearly the questions (and many more) might be answered by a (years long) structured study of AWS (rather than by my hobbyist Google / StackOverflow antics).
Overall, I learned a lot about how AWS thinks you should compose applications, but I have a lot more to learn!