Data analysis on Movies Dataset¶
by Deepak Das¶
The main aim of the project is to find insights about the datset containing information about particular movies. This project uses the movie dataset avaliable form Movie lens.This dataset contains just 1000 movies for analysis. We have used libraries present in Python such as Matplotlib,Seaborn,Pandas for reading and visualization of the dataset.

We import the packages required for visualization¶
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Data description¶
The data is in csv format.In computing, a comma-separated values (CSV) file stores tabular data (numbers and text) in plain text. Each line of the file is a data record. Each record consists of one or more fields, separated by commas. Data are collected on 12 different informations of a movie,with rating being in the order of 1 (worst) and 10 (best) and the metascore being in the order from 1 (worst) and 100 (best).
df = pd.read_csv('Documents//movie.csv')
Attributes¶
- Rank
- Title
- Genre
- Description
- Director
- Actors
- Year
- Runtime
- Rating
- Votes
- Revenue
- Metascore
Here we call the head function and print the first 5 rows of the data¶
df.head()
Here we see the total size of the dataset¶
df.size
Here we see the shape of the dataset¶
df.shape
Here we see all the mathematical aspects of the data¶
df.describe(include = 'all')
We check for the missing values in the dataset¶
We find there are missing values present in the dataset so we will remove the missing values¶
df.isnull().sum()
We fill the null values with the mean values in the dataset¶
df.mean()
Filling the Null values of the Revenue column with mean values¶
df['Revenue (Millions)'] = df['Revenue (Millions)'].fillna(df['Revenue (Millions)'].mean())
Filling the Null values of the Metascore column with mean values¶
df['Metascore'] = df['Metascore'].fillna(df['Metascore'].mean())
df.isnull().sum()
We drop the columns which are not required for analysis and for the Recommendation engine¶
df1 = df.drop(columns = ['Description' ,'Director','Actors'])
df1.head()
Exploratory Data Analysis¶

Univariate Analysis¶
Univariate analysis is the simplest form of analyzing data. “Uni” means “one”, so in other words your data has only one variable. It doesn't deal with causes or relationships (unlike regression) and it's major purpose is to describe it takes data, summarizes that data and finds patterns in the data.The key pointers to the Univaraite analysis are to find out the outliers present in the data. We also tend to find the disitribution of the data on the dataset which can further help us for the Bivaraite/Multivariate analysis.
Rating¶
x = df1['Rating']
sns.distplot(x)
sns.despine()

sns.boxplot(df1['Rating'])
sns.despine()

Inferences :-¶
- We observe that the plot is left skewed.
- There are almost no outliers present in the plot
- The ratings given are between 6-8 out of 10
- So the users have been generous with their ratings
Runtime (Minutes)¶
x = df1['Runtime (Minutes)']
sns.distplot(x)
sns.despine()

sns.boxplot(df1['Runtime (Minutes)'])
sns.despine()

Inferences :-¶
- The plot is little right-skewed
- Here also the number of outliers present are less
- The average runtime of movies is somewhere between 100-120 minutes
- Movies with a runtime of more than 140 minutes are quite less in number
Metascore¶
x = df1['Metascore']
sns.distplot(x,);

sns.boxplot(df1['Metascore'])
sns.despine()

Inferences :-¶
- The plot follows a normal distribution
- The outliers for the plot are almost negligible
- The average Metascore here is 60
Bivariate Analysis¶
Bivariate analysis is the simultaneous analysis of two variables (attributes). It explores the concept of relationship between two variables, whether there exists an association and the strength of this association, or whether there are differences between two variables and the significance of these differences.
Co-relation¶
plt.figure(figsize =(15,15))
sns.heatmap(df.corr(),annot=True)
plt.show()

Year vs Rating¶
sns.regplot(x = 'Year',y = 'Rating',data = df1 , x_jitter=0.2, scatter_kws={'alpha':0.1})
sns.despine()

sns.jointplot(x='Year', y='Rating', data=df1, kind="kde")
sns.despine()

Inferences :-¶
- We observe a decreasing trend from the plot
- We have maximum data from the year 2016
- We can also say that as years passed by people became more conscious about watching movies because of the decrease in the ratings
Year vs Metascore¶
sns.regplot(x = 'Year',y = 'Metascore',data = df1 , x_jitter=0.2, scatter_kws={'alpha':0.1})
sns.despine()

sns.jointplot(x='Year', y='Metascore', data=df1, kind="kde")
sns.despine()

Inferences :-¶
- Here also we can see that there is a slight decreasing trend
- Again the data for 2016 is maximum
- The critics have been a little generous over the years so there is a very slight decrease in the Metascore
Year vs Runtime (Minutes)¶
sns.regplot(x = 'Year',y = 'Runtime (Minutes)',data = df1 , x_jitter=0.2, scatter_kws={'alpha':0.1})
sns.despine()

sns.jointplot(x="Year", y='Runtime (Minutes)', data=df1, kind="kde")
sns.despine()

Inferences :-¶
- We observe a slight decreasing trend in the plot
- The average runtime has been around 120 mins over the years
Multi-Variate Analysis¶
Multivariate analysis (MVA) is based on the statistical principle of multivariate statistics, which involves observation and analysis of more than one statistical outcome variable at a time.
Inferences from Runtime vs Rating in terms of Year¶
- From the plots below we can say that the dataset contains maximum number of movies from 2016 and over the years the runtime of movies has been around 100-125 minutes
grid = sns.FacetGrid(df1, col='Year',col_wrap = 4)
grid.map(plt.scatter,'Runtime (Minutes)','Rating',alpha = 0.5)
sns.despine()

WordCloud¶
What are Word Clouds?¶
Word clouds (also known as text clouds or tag clouds) work in a simple way: the more a specific word appears in a source of textual data (such as a speech, blog post, or database), the bigger and bolder it appears in the word cloud.
We get to see the most common words used for a movie title in the dataset¶
import wordcloud
from wordcloud import WordCloud, STOPWORDS
# Create a wordcloud of the movie titles
df1['Title'] = df1['Title'].fillna("").astype('str')
title_corpus = ' '.join(df1['Title'])
title_wordcloud = WordCloud(stopwords=STOPWORDS,background_color='black', height=1500, width=4000).generate(title_corpus)
# Plot the wordcloud
plt.figure(figsize=(16,8))
plt.imshow(title_wordcloud)
plt.axis('off')
plt.show()

We get to see the most common Genres of the Movie dataset¶
# Create a wordcloud of the movie Genres
df['Genre'] = df1['Genre'].fillna("").astype('str')
title_corpus = ' '.join(df1['Genre'])
title_wordcloud = WordCloud(stopwords=STOPWORDS,background_color='black', height=1500, width=4000).generate(title_corpus)
# Plot the wordcloud
plt.figure(figsize=(16,8))
plt.imshow(title_wordcloud)
plt.axis('off')
plt.show()

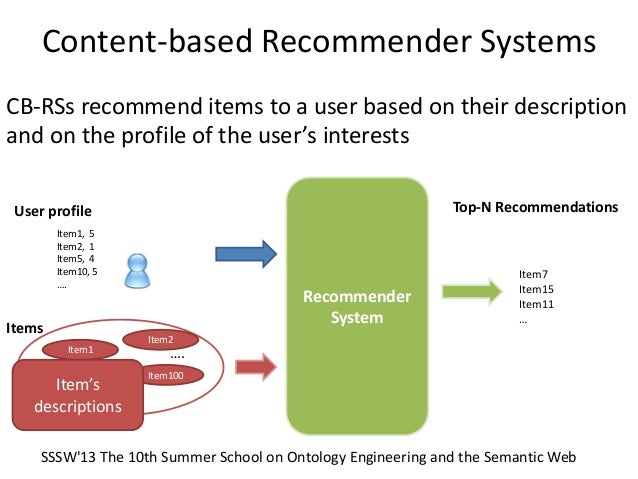
Recommendation Systems¶
Content Based Recommendation¶
from sklearn.feature_extraction.text import TfidfVectorizer
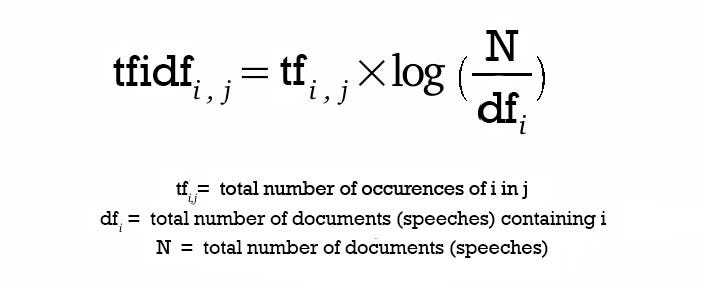
tf = TfidfVectorizer()
tfidf_matrix = tf.fit_transform(df1['Genre'])
print(tfidf_matrix.todense().shape)
a = pd.DataFrame(tfidf_matrix.todense())
a
from sklearn.metrics.pairwise import cosine_similarity
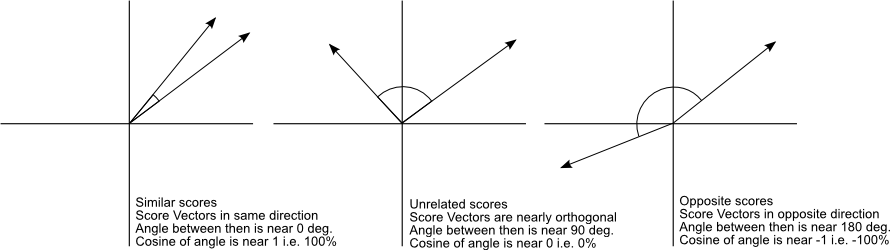
Building a matrix with cosine similarity scores¶
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print(cosine_sim)
Build a 1-dimensional array with movie titles¶
titles = df1['Title']
indices = pd.Series(df.index, index=df1['Title'])
print(indices.head(10))
Function that get movie recommendations based on the cosine similarity score of movie genres¶
def genre_recommendations(title):
sim_scores = list(enumerate(cosine_sim[indices[title]]))
# Sorting the recommendation list according to cosine similarity
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Printing the top 30 recommendations in desencding order of similarity score
sim_scores = sim_scores[1:30]
# Indexing with Integer Location and returning the values
movie_indices = [i[0] for i in sim_scores]
return titles.iloc[movie_indices]
Recommendation Based on the cosine simialrity and sorted according to similarity scores¶
genre_recommendations('Guardians of the Galaxy')
Summary¶
From the above given dataset we built a content based Recommendation system or Personalized recommendation system.First we had to clean the datset as there were some missing values then we had to drop the columns which didn't seem necessary for out Analysis. After that we did some Exploratory Data Analysis on the movie dataset and found some trends and observations from the plots.
Then we used the concept of TF-IDF vector to convert our texts into a matrix form and find the cosine similarity so that we can predict the similar movies present in the dataset. At last we were sucessfull in building a very small version of a personalized recommendation system.