
# pi-autoresearch
### Autonomous experiment loop for pi
**[Install](#install)** · **[Usage](#usage)** · **[How it works](#how-it-works)**
*Try an idea, measure it, keep what works, discard what doesn't, repeat forever.*
An extension for **[pi](https://pi.dev/)** — an AI coding agent that runs in your terminal. pi-autoresearch gives pi the tools and workflow to run autonomous optimization loops: try an idea, benchmark it, keep improvements, revert regressions, repeat.
Inspired by [karpathy/autoresearch](https://github.com/karpathy/autoresearch). Works for any optimization target: test speed, bundle size, LLM training, build times, Lighthouse scores.
---
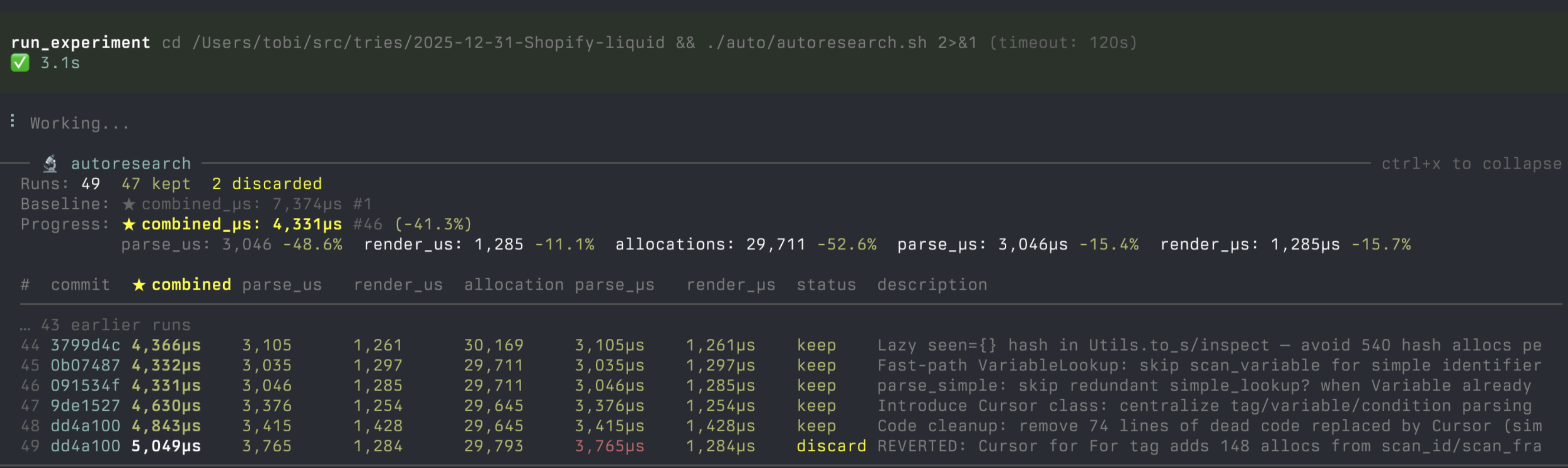
---
## Quick start
```bash
pi install https://github.com/davebcn87/pi-autoresearch
```
## What's included
| | |
|---|---|
| **Extension** | Tools + live widget + `/autoresearch` dashboard |
| **Skill** | Gathers what to optimize, writes session files, starts the loop |
### Extension tools
| Tool | Description |
|------|-------------|
| `init_experiment` | One-time session config — name, metric, unit, direction |
| `run_experiment` | Runs any command, times wall-clock duration, captures output |
| `log_experiment` | Records result, auto-commits, updates widget and dashboard |
### `/autoresearch` command
| Subcommand | Description |
|------------|-------------|
| `/autoresearch