






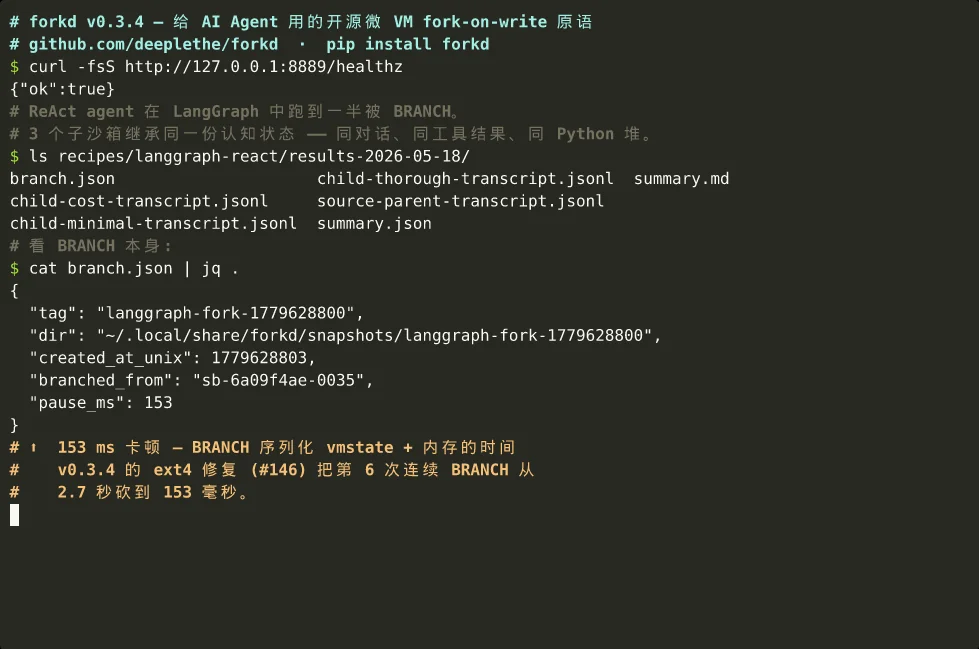
## 101 毫秒 fork 100 个 microVM,56 毫秒 BRANCH 一个运行中的 VM(v0.4 live 模式)。
面向 **AI Agent 扇出**(fan-out)场景的 microVM 沙箱运行时。子 VM
从一个已"暖启动"的父快照 fork 而来,通过写时复制(CoW)继承
父进程的地址空间,而不是冷启动一个新内核。
forkd 基于 Firecracker 构建。父 VM 启动一次,把运行时(Python +
依赖,JIT 已暖的 JVM,已加载的 ML 模型)导入内存,然后暂停并落盘。
每个子 VM 是一个独立的 Firecracker 进程,通过 `MAP_PRIVATE`
方式 `mmap` 父快照的内存镜像;内核在页面级别实现写时复制,因此
在子 VM 发生写入分歧之前,它们共享父 VM 的常驻内存。
由此同时获得两个特性:**每个子 VM 都是独立的 KVM 隔离**,
同时**单个子 VM 的启动成本接近 `fork(2)`,而非冷启动 VM**。
forkd 同时支持 **BRANCH**:把正在运行的沙箱暂停,把它当下的
in-flight 状态做成快照,再恢复 —— 整套 ~150 ms —— 让 agent
能在"思考过程中"叉出多条路径,而不只在暖启动时刻 fork。
v0.3.4 修复了一个慢路径回归:在同一个父 VM 上反复 BRANCH 时,
pause 时间会从 150 ms 涨到 2.7 s
([#146](https://github.com/deeplethe/forkd/issues/146));修复后
连续 BRANCH 保持平直(第 6 次 BRANCH 快了 17.6×)。
**v0.4 live BRANCH** 把源 VM 卡顿窗口从 ~200 ms(Diff)压到
**56 ms p50 / 64 ms p90**(1.5 GiB 源 VM,实测,
[`bench/live-fork-pause-window/RESULTS-v0.4.md`](./bench/live-fork-pause-window/RESULTS-v0.4.md))。
p50 比 v0.3 Diff 快 **3.6 倍**,而且在慢盘上这个比值**变得更大**——
因为 Live 的 pause 是 disk-independent 的(内存拷贝跑在 resume 之
后,不占临界区)。加 `wait: false` 让调用方 ~70 ms 就返回,背景
拷贝异步完成——对于 agent 代码的 fire-and-forget BRANCH 是 **200×**
的 RT 改进。CLI 用 `--live` / `--no-wait`,REST 用 `mode: "live"` /
`wait: false`,Python / TypeScript / MCP SDK 同名。
```python
from forkd import Controller
c = Controller()
# 源 VM 必须用 live_fork=True 启动(memfd 后端 RAM,UFFD_WP 看到
# 运行中父 VM 写的前提条件)。
parent = c.spawn_sandboxes("pyagent", n=1, live_fork=True)[0]
# ... 驱动 parent ... 然后 live BRANCH + fire-and-forget:
branch = c.branch_sandbox(parent["id"], mode="live", wait=False)
# ~10 ms 返回,status="writing";poll list_snapshots 等到
# status="ready" 即背景拷贝完成。
```
```bash
# CLI:本地 fork live-fork-capable 子 VM,然后对 daemon 追踪的那个
# 做 live BRANCH。两条路径暂时还不组合 ——daemon 侧 spawn 走 CLI
# 是下一个缺口(状态见 issue #209)。
sudo -E forkd fork --tag pyagent -n 1 --per-child-netns --live-fork
sudo -E forkd snapshot --from-sandbox --live --no-wait
```
需要 Linux ≥ 5.7、`vm.unprivileged_userfaultfd=1`(或
`CAP_SYS_PTRACE`),以及 vendored Firecracker 分支
[deeplethe/firecracker:forkd-v0.4-mem-backend-shared-v1.12](https://github.com/deeplethe/firecracker/tree/forkd-v0.4-mem-backend-shared-v1.12)
——`forkd doctor` 会探测这两项。完整设计:
[`DESIGN-v0.4.md`](./DESIGN-v0.4.md)。PoC 实证数据:
[`experiments/v0.4-*-poc/`](./experiments/)。跟踪 issue
[#101](https://github.com/deeplethe/forkd/issues/101)。
## Demo:让一个思考中的 agent 分裂
一个 24 秒的演示 —— 源 agent 在 LangGraph ReAct loop 中跑到一半,
被 BRANCH,3 个子沙箱继承同一份认知状态,各自收到不同的引导
("深度文化派"、"极简派"、"省钱派"),输出三条**显著不同的**
第一天行程。
最关键的分裂证据:源 agent(无引导)第一天下午选 Nishiki Market
(锦市场,$$);3 个被引导的子沙箱**各自独立地都换成了 Arashiyama
Bamboo Grove**(岚山竹林,free);"省钱派" 还在 $$ 餐厅那里加上了
"may be pricey" 的警告语,其他两个没有。**模型并没有被告知"换景点"**
—— 是 hint 影响了下一次 LLM 调用,前置推理整套都没变。
完整机制 + 数据 + 原始 transcript 在
[`recipes/langgraph-react/`](./recipes/langgraph-react/) 和
[`recipes/langgraph-react/DEMO.md`](./recipes/langgraph-react/DEMO.md)。
### 不仅是推理状态,文件系统状态也继承
针对"难道你不能直接并行调 3 次 LLM 吗"这个常见反驳,看
[`recipes/coding-agent-fork/`](./recipes/coding-agent-fork/) ——
50 MiB 的二进制 blob 通过一次 BRANCH 字节完全一致地传到 4 个
沙箱里。3 个孙沙箱各自对同一个有 bug 的 Python 包应用不同的修复;
它们的 `__pycache__/` 和编辑互不影响,但那 50 MiB 的继承是共享的。
字节是塞不进 prompt 的。**BRANCH 操作的 pause 时间 3.3 秒。**
## 关键特性
- **硬件级隔离。** 每个子 VM 都是独立的 Firecracker microVM,
基于 KVM。要逃逸出来需要 hypervisor 或内核漏洞,而不是
`runc` 的一个回归 bug。
- **暖启动的运行时免费继承。** 导入、JIT 编译、模型权重、预取的
缓存——只要父 VM 做过的事,子 VM 直接拿到。
- **每个子 VM 都是真 Linux。** 多 vCPU、完整 TCP 网络、`apt
install`、出站 HTTPS。和那些为了极致启动速度牺牲掉
单 vCPU + 串行 I/O 的函数级快照运行时不同,forkd 的子 VM
可以跑真实的 Python 服务、模型推理或任何需要完整内核的负载。
- **从设计上就是多租户。** 每个子 VM 独立 network namespace、
独立 cgroup v2 内存限制、独立 `/dev/urandom`(Linux 5.20+
通过 `vmgenid` 重新播种)。
- **为 Agent 扇出而生。** 单次请求扇出到大量短生命周期沙箱的
AI Agent 负载——代码解释器、工具调用、评估 rollout——是
设计目标。暖启动的父 VM 把每次请求的 `import numpy` /
`import torch` 开销在整个 cohort 间分摊到接近零。
- **可运维。** 守护进程持有状态、REST API(Unix 或 TCP)、
Prometheus `/metrics`、append-only JSON 审计日志、systemd 单元。
- **开源。** Apache 2.0,没有厂商 SDK 锁定。
## 基准测试
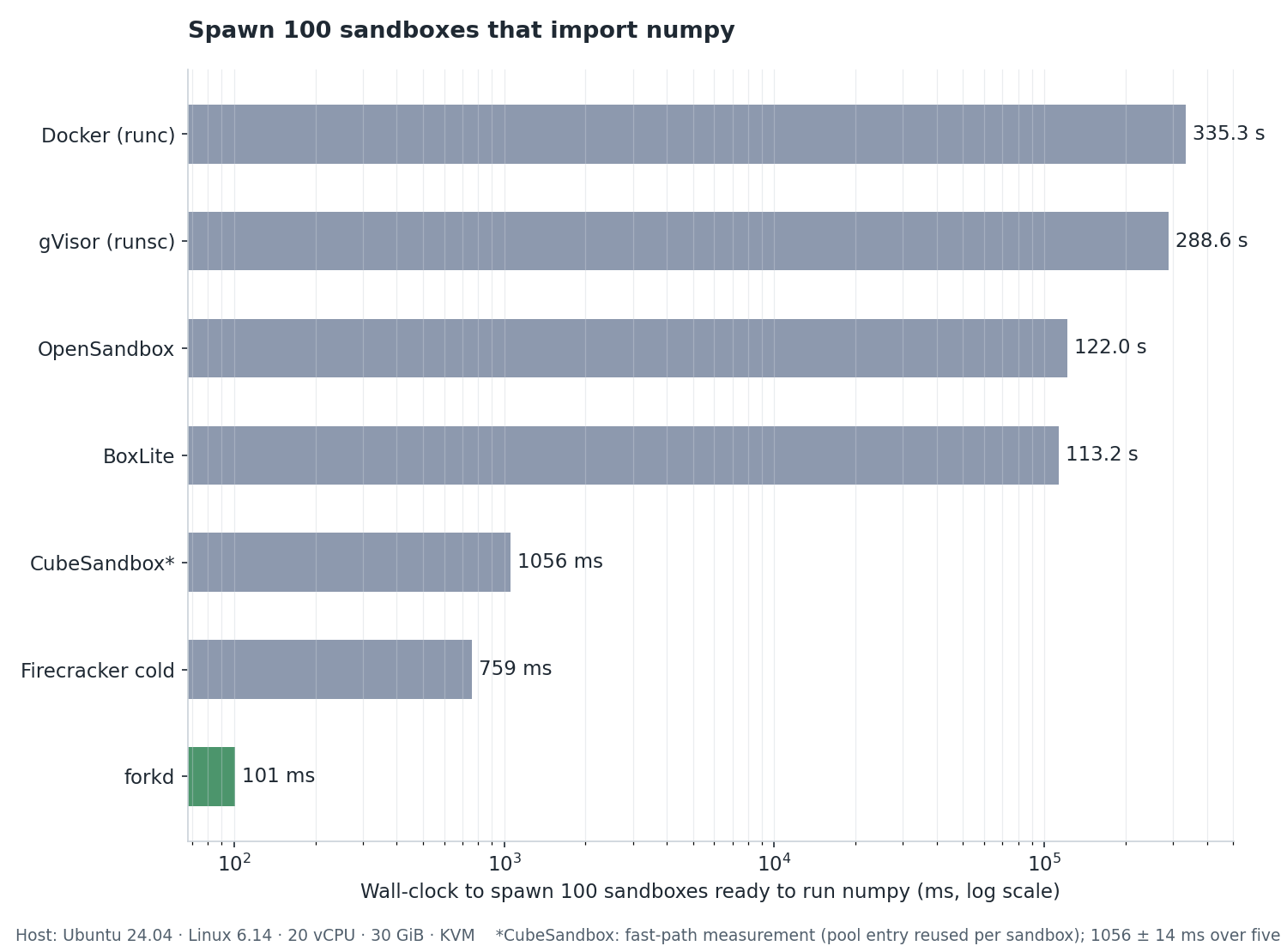
同一台 Linux 主机(Ubuntu 24.04,Linux 6.14,20 vCPU,30 GiB,KVM)。
负载:启动 100 个沙箱,每个执行 `import numpy;
numpy.zeros(5).tolist()`。
| 后端 | N=100 总耗时 | 每个沙箱内存增量 | 说明 |
|---|---:|---:|---|
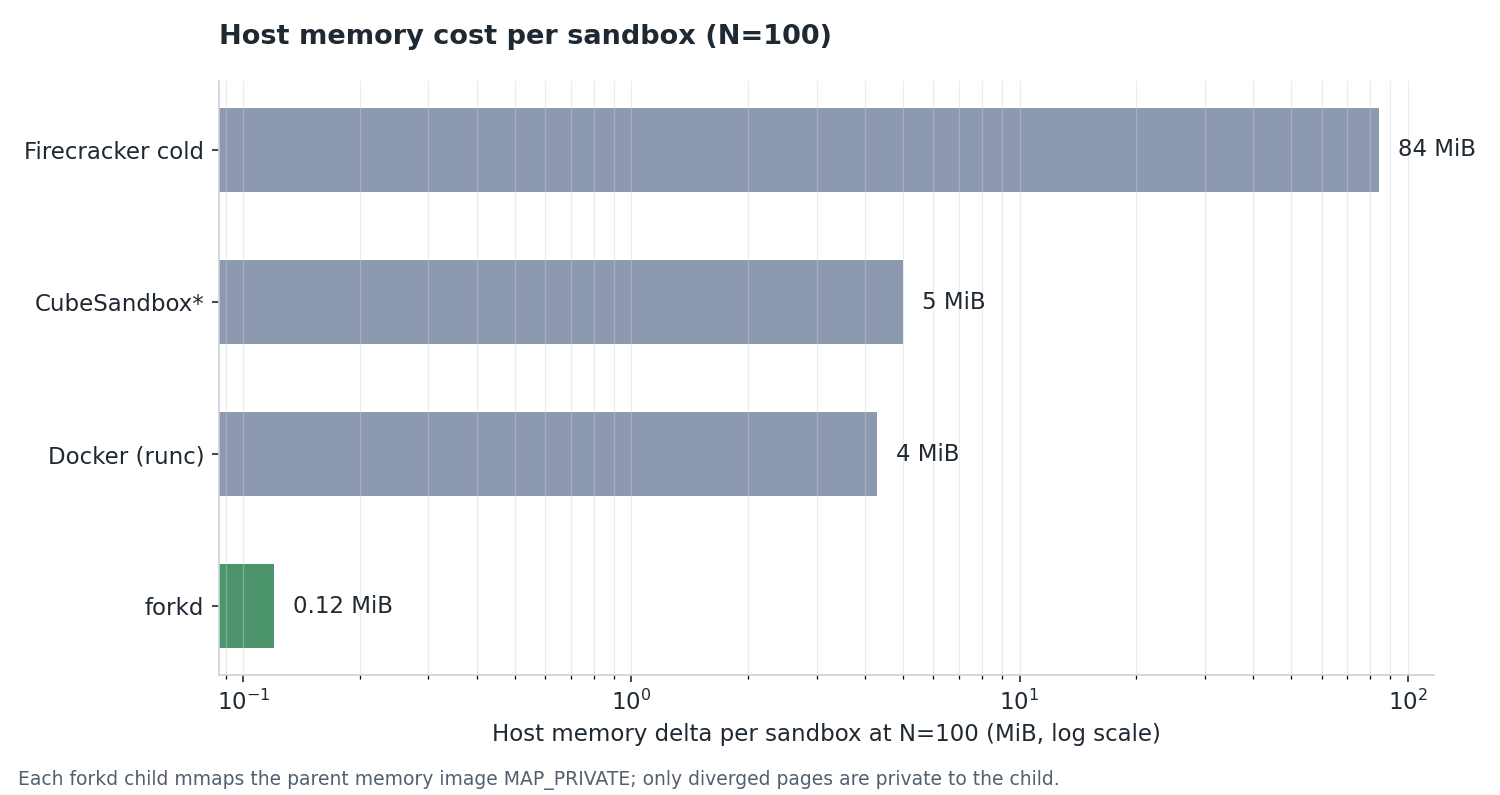
| **forkd** | **101 ms** | **0.12 MiB** | 从暖启动快照 CoW fork |
| CubeSandbox¹ | 1.06 s | 5 MiB | RustVMM microVM,冷启动(池 fast path) |
| BoxLite² | 113.2 s | — | KVM microVM,冷启动 OCI rootfs |
| OpenSandbox³ | 122.0 s | — | 经抽象层调用 Docker 运行时 |
| Firecracker 冷启动 | 759 ms | 84 MiB | 裸 VM 启动,无编排 |
| gVisor (runsc) | 288.6 s | — | 用户态内核容器 |
| Docker (runc) | 335.3 s | 4 MiB | 标准容器运行时 |
¹ CubeSandbox:1.06 s 是本机的 **fast-path** N=100 数字(1056 ± 14 ms,
五次连跑,每次 100 % 成功),用 pre-warm Python `ThreadPoolExecutor`
的改进 bench 脚本测,避免 client 侧懒初始化污染测量。之前在同一台
机器上跑的 slow-path 是 20.3 s / 77 成功 —— 那次模板的 writable
layer 是 2 GiB,与默认 1 GiB 池不匹配,每个沙箱都走了一遍
`mkfs.ext4 + reflink-copy`;维护者在
[#235](https://github.com/TencentCloud/CubeSandbox/issues/235)
澄清后,我们把 `2Gi` 加进 `pool_default_format_size_list` 重测。
机器跑的是 cube **v0.2.0**,这版有一个 ~50 ms 延迟回归,
[PR #234](https://github.com/TencentCloud/CubeSandbox/pull/234)
在 v0.2.1 中修复 —— 上面的数字是 v0.2.0 baseline。CubeSandbox
公布单实例冷启动 **<60 ms**(96 vCPU 主机,N=100 并发 P99 200 ms),
我们没在此处复测那个形态。详见
[`bench/CUBESANDBOX.md`](./bench/CUBESANDBOX.md)、以及两个上游 PR
[#236](https://github.com/TencentCloud/CubeSandbox/pull/236) /
[#237](https://github.com/TencentCloud/CubeSandbox/pull/237)。
² BoxLite 的设计目标是每个负载一个长生命周期、有状态的 Box,
而不是 100 个并发的全新 microVM。冷启动扇出数据放在这里仅为
直接对比。详见 [`bench/BOXLITE.md`](./bench/BOXLITE.md)。
³ OpenSandbox 是 Docker / K8s / gVisor / Kata / Firecracker 上层的
抽象层;此处数字是它默认的 Docker 运行时。详见
[`bench/OPENSANDBOX.md`](./bench/OPENSANDBOX.md)。
复现:`bench/bench-spawn-100.sh` 然后 `bench/generate_charts.py`。
对单个沙箱执行同一个 numpy 表达式的两种方式:
| 调用 | 耗时 | 做了什么 |
|---|---:|---|
| `sandbox.eval("numpy.zeros(5).tolist()")` | 1 ms | 复用 PID 1 里已暖的 Python |
| `sandbox.commands.run("python3 -c '...'")` | 96 ms | 冷子进程重新 import numpy |
## 工作原理
```mermaid
flowchart TB
%% ─── parent ───────────────────────────────────────────────
subgraph PARENT["父 VM(启动一次并暖启动)"]
direction TB
runtime["PID 1
Python + numpy + 你的依赖
已导入 RAM"]
end
PARENT -- "暂停 + 快照" --> SNAP["磁盘上的快照
memory.bin(CoW 源)
vmstate(vCPU + 设备)"]
%% ─── controller ───────────────────────────────────────────
CLIENT["客户端(CLI / Python SDK)"] -- "POST /v1/sandboxes n=100" --> CTL["forkd-controller
REST · 鉴权 · 审计 · /metrics"]
CTL -- "restore_many_with(...)" --> SNAP
%% ─── children ─────────────────────────────────────────────
subgraph CHILDREN["100 个子 Firecracker 进程(内核每页 CoW)"]
direction LR
subgraph NS1["netns forkd-child-1"]
C1["子 VM 1
mmap MAP_PRIVATE
cgroup memory.max"]
end
subgraph NS2["netns forkd-child-2"]
C2["子 VM 2
mmap MAP_PRIVATE
cgroup memory.max"]
end
subgraph NSN["netns forkd-child-100"]
CN["子 VM 100
mmap MAP_PRIVATE
cgroup memory.max"]
end
end
SNAP -. "共享文件
(基本只读)" .-> C1
SNAP -. "共享文件" .-> C2
SNAP -. "共享文件" .-> CN
%% ─── network ──────────────────────────────────────────────
C1 -- "veth" --> BR["宿主机桥 forkd-br0
MASQUERADE"]
C2 -- "veth" --> BR
CN -- "veth" --> BR
BR --> UPLINK(("uplink → 公网"))
%% styling
classDef parent fill:#e8f3ec,stroke:#4c956c,color:#1f2933;
classDef snap fill:#fff3df,stroke:#d4a259,color:#1f2933;
classDef ctl fill:#e6efff,stroke:#5b7dba,color:#1f2933;
classDef child fill:#ffffff,stroke:#52606d,color:#1f2933;
classDef net fill:#f1f3f5,stroke:#8d99ae,color:#1f2933;
class PARENT,runtime parent;
class SNAP snap;
class CTL,CLIENT ctl;
class NS1,NS2,NSN,C1,C2,CN child;
class BR,UPLINK net;
```
完整设计、以及当前架构留下的开放问题,见
[`DESIGN.md`](./DESIGN.md)。
## forkd 与其他方案对比
沙箱运行时这个领域的设计差异很大。下表把 forkd 和最常被提及的
开源项目放在一起对比。引号内的数字是**上游项目自己公布的数字**,
除非已经在上面我们的基准图里。forkd 不会去测别的项目在它们
本来就不为之设计的负载形态。
| 项目 | 隔离原语 | 冷启动 (N=100) | Fork 自暖快照 | 配额 | 鉴权 / TLS | 协议 |
|---|---|---|:---:|---|---|---|
| **forkd** | Firecracker + 快照 CoW | **101 ms** | ✓ | cgroup `memory.max` | bearer + rustls | Apache 2.0 |
| [CubeSandbox][cs] | RustVMM + KVM microVM | 1.06 s¹ | "coming soon" | <5 MiB / 实例 | 闭源不开放 | Apache 2.0 |
| [Daytona][dy] | OCI workspace | <90 ms² | ✗ | 每 workspace | 平台 API key | **AGPL-3.0** |
| [OpenSandbox][os] | Docker / K8s + gVisor / Kata / FC | 122 s | ✗ | 取决于底层 | k8s 网关 | Apache 2.0 |
| [E2B][e2b] | Firecracker(在 [infra][e2b-infra] 中) | 开源不含 | ✗ | 平台侧 | 云 API key | Apache 2.0 |
| [BoxLite][bl] | KVM / Hypervisor.framework + OCI | 113 s | ✗ 有状态 Box | KVM + seccomp | 仅出站策略 | Apache 2.0 |
| Modal | 闭源快照 fork | 不公开 | ✓ | ✓ | ✓ | 闭源 |
| Firecracker 裸用 | 只有 microVM | 759 ms | 手工 | n/a | n/a | Apache 2.0 |
| Docker (runc) | OCI 容器 | 335 s | ✗ | cgroups | n/a | Apache 2.0 |
| gVisor (runsc) | 用户态内核 | 289 s | ✗ | cgroups | n/a | Apache 2.0 |
¹ N=100 并发,本机裸金属(`systemd-detect-virt: none`,i7-12700,
20 vCPU,无嵌套虚拟化)。这是 **fast path** 的数字 ——
`pool_default_format_size_list` 已包含模板的 writable-layer 尺寸,
每个沙箱复用预格式化的池条目,不走 `mkfs.ext4 + reflink-copy`。
五次连跑均值 1056 ± 14 ms,每次 100 % 成功,bench 脚本会先 pre-warm
Python 的 `ThreadPoolExecutor`,把 client 侧懒初始化排除在测量外。
机器跑的是 cube **v0.2.0**,这版有 ~50 ms 延迟回归,
[PR #234](https://github.com/TencentCloud/CubeSandbox/pull/234) 在
v0.2.1 修 —— 上面的数字是 v0.2.0 baseline。之前在同一台机器上的
slow-path 测得 20.3 s / 77 成功 —— 那是我们模板配错的结果,维护者
在 [#235](https://github.com/TencentCloud/CubeSandbox/issues/235)
指出后修正。Cube 自称单实例冷启动 **<60 ms**(96 vCPU 主机,
N=100 并发 P99 200 ms),我们没复测。注意这行是把 **forkd 的
fork-from-warm** 跟其他项目的 **冷启动** 放在一起 —— 它们是不同
的工作点,不是等价原语。详见
[bench/CUBESANDBOX.md](./bench/CUBESANDBOX.md),以及为上游 cmdTimeout
race 提的两个 PR
[#236](https://github.com/TencentCloud/CubeSandbox/pull/236) /
[#237](https://github.com/TencentCloud/CubeSandbox/pull/237)。
² Daytona 自己公布的数字,我们没测它(workspace 运行时,不属于
可对比的扇出形态)。
[cs]: https://github.com/TencentCloud/CubeSandbox
[dy]: https://github.com/daytonaio/daytona
[os]: https://github.com/alibaba/OpenSandbox
[e2b]: https://github.com/e2b-dev/E2B
[e2b-infra]: https://github.com/e2b-dev/infra
[bl]: https://github.com/boxlite-ai/boxlite
**forkd 适合什么场景。**
- **代码解释器和 Jupyter kernel 沙箱。** 每一次对话或工具调用
都开一个全新 kernel;暖启动的父 VM 带着 SciPy / ML 运行时,
所以每次请求的 `import numpy` / `import torch` 直接降到零开销。
这就是设计目标——Anthropic / OpenAI / Modal 的代码解释器
产品全是这种负载形态。
- **评估测试集 harness。** 几百个仓库 checkout 或测试 rollout
并行跑——SWE-bench 那种形状——又不用每个 task 付 Docker
冷启动的代价。
- **大规模扇出的多用户代码执行。** 大量短生命周期沙箱共享
同一个暖启动父 VM,每个子 VM 都是 KVM 隔离。
- **CI 里执行不可信代码。** `git clone`、`pip install`、
`pytest` 跑在真实的 Linux VM 里,而不是一个容器 namespace。
- **托管沙箱 SaaS 的自托管替代品。** 一台 Linux + KVM,单二进制
守护进程,Apache 2.0——没有按秒计费的云账单,也没有厂商锁定。
**别的项目更合适什么。** CubeSandbox:更快的纯冷启动(自称
<60 ms)。Daytona:每个用户拥有一个长生命周期沙箱的 workspace
形态。OpenSandbox:用一套编排 API 适配多种隔离后端。BoxLite:
可嵌入、不需要守护进程、跨平台(macOS 走 Hypervisor.framework)。
Modal:同一种原语的闭源托管版本。
**forkd 的不适用场景。** 函数级快照运行时为了极致启动速度
放弃了真实 Linux(单 vCPU、只有串行 I/O),它们能在 forkd 的
~100 ms 基础上再快一个数量级——代价是跑不了真实的 Python
服务、`apt install`、出站 HTTPS。
## 企业部署 FAQ
给平台 / 采购团队的速查答案:
**能直接上 Kubernetes 吗?** 可以——**一个 forkd-controller Pod 承载 N 个沙箱子 VM**,K8s 调度器只在 Pod 创建时跑**一次**,跟扇出数量无关(对比 Kata / Firecracker-on-K8s 那种"每个沙箱一个 Pod"的设计)。起步 manifest 在 [`packaging/k8s/`](./packaging/k8s/)。节点要有 `/dev/kvm` + cgroup v2;托管 K8s(GKE / EKS / AKS)通常得选裸金属 SKU 或显式开嵌套虚拟化才行。
**一个 Pod 能塞多少沙箱?** 用 512 MiB 暖好的 Python+numpy 父 VM,大致定容:
- **每 vCPU 跑 ~1 个**活跃 agent(算力瓶颈)
- **每 8 GiB Pod RAM 装 ~50 个**空闲池里的 agent(进程状态瓶颈,**不是**内存)
N=100 实测 CoW 开销是 **每个 child 0.12 MiB**(详见 [bench/](./bench/)),内存几乎从来不是扇出的天花板,真正卡住的是 vCPU 和进程数。父 VM 更重的负载(浏览器、ML 推理)更快撞顶,具体定容请用自家父 VM 实测。
**现有 agent 怎么接入?**
- **REST** —— `POST /v1/sandboxes n=100`,跟语言无关,bearer-token 鉴权
- **Python SDK** —— `pip install forkd`(`from forkd import Sandbox` 可替 `from e2b import Sandbox`)
- **TypeScript SDK** —— `npm install @deeplethe/forkd`,Node.js 18+,与 Python SDK surface 对齐
- **LangGraph / AutoGen / CrewAI / Swarm** —— 通过 SDK,无需特殊适配。完整示例见 [`recipes/`](./recipes/) 下的 `crewai-fanout/`、`autogen-branch/`、`openai-swarm/`
- **MCP** —— `pip install forkd-mcp` 提供 MCP server,可接入 Claude Desktop / Claude Code / Cursor / Cline,详见 [`sdk/mcp/`](./sdk/mcp/)
**生产场景形态(对应仓内 recipe):**
- **AI 代码解释器** —— 一个暖好的父 VM(SciPy / torch 已 import),每个对话回合 fork 一个 child。Recipe:[`e2b-codeinterpreter/`](./recipes/e2b-codeinterpreter/)
- **SWE-bench 风格并行评测** —— N 个并行 repo checkout,每个 child 独立跑 `pytest`。Recipe:[`coding-agent/`](./recipes/coding-agent/)
- **多用户代码执行规模化** —— 共享暖父 VM,每个用户的 child 由 KVM 隔离
- **CI 跑不可信代码** —— `git clone + pip install + pytest` 在真 Linux VM 里跑,不是容器 namespace
- **每测试隔离数据库** —— Recipe:[`postgres-fixture/`](./recipes/postgres-fixture/) —— 每个 child ~10 ms 拿到 ready-to-query postgres,跳过 ~2 s 的 fresh `initdb`
## 快速开始
要求:x86_64 Linux,带 KVM,Ubuntu 22.04 或更新。两步跑出一个真 fork:主机准备(一次性),然后 `forkd pull` + fork(~30 秒)。下面再后面的章节是不在 Hub 上的自定义 recipe 的备选路径。
### 一. 确认主机环境就绪
```bash
# 1. CLI + 守护进程二进制(预编译 tarball,不需要 Rust 工具链):
curl -sSL https://github.com/deeplethe/forkd/releases/download/v0.3.4/forkd-v0.3.4-x86_64-linux.tar.gz \
| sudo tar -xz -C /usr/local/bin/
# 2. 主机初始化:
sudo bash scripts/setup-host.sh # KVM + tap 设备,一次性
sudo bash scripts/netns-setup.sh 3 # 每子 VM 的网络 namespace
# 3. 一键自检:
forkd doctor # 检查上面这些是否到位
# 4. (可选)给程序用的语言客户端:
pip install forkd # Python SDK —— 通过 HTTP 调守护进程
npm install @deeplethe/forkd # TypeScript SDK
```
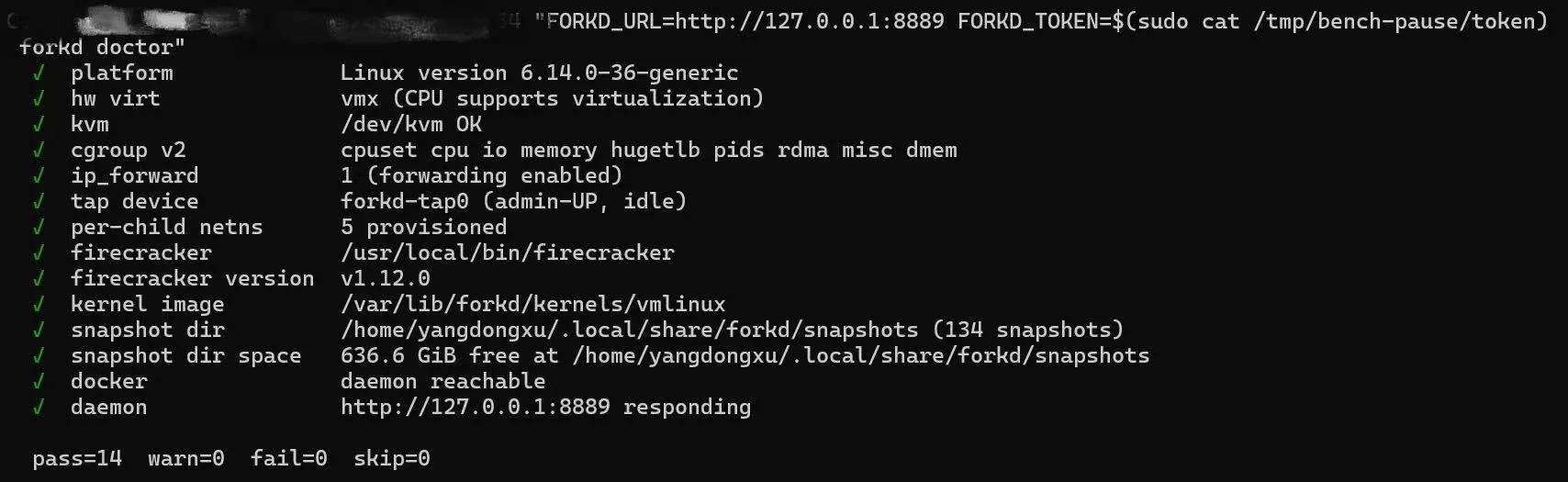
`forkd doctor` 跑 16 项检查(KVM、硬件虚拟化、cgroup v2、IP 转发、
tap、netns、Firecracker 二进制 + 版本、Docker daemon、快照目录 +
磁盘空间、内核镜像、controller 可达性、平台,以及 v0.4 live-fork
所需的 `uffd_wp` 和 `memfd_create`),每一项不通过都附带具体修复
提示。任何东西觉得不对就先跑它。
### 二. 第一次 fork(推荐)
```bash
# 14.5 MiB 的预热快照(Python 3.12 + LangGraph) → ~15 秒下载,自动 sha256 校验。
forkd pull deeplethe/langgraph-react
# 3 个共享父 VM 内存的子 VM,每个 ~10 ms。
sudo -E forkd fork --tag langgraph -n 3 --per-child-netns
```
参见 [`docs/HUB.md`](./docs/HUB.md) 了解 registry 模型 + 如何发布自己的
snapshot pack。
### 三. 备选:从 Docker 镜像构建
`forkd from-image` 把 Docker pull → ext4 → 启动 + 暖启动 → pause →
注册 tag 串成一条命令。Hub 里还没有的 recipe 用这个:
```bash
sudo -E forkd from-image python:3.12-slim \
--tag py-numpy \
--extra python3-numpy
# 第一次 2-3 分钟(Docker pull + ext4 + warmup),之后走缓存。
sudo -E forkd fork --tag py-numpy -n 5 --per-child-netns
```
### 四. 探测你装的 forkd 实际有多快
```bash
forkd bench --tag py-numpy --n 5
# forkd bench against snapshot py-numpy
# spawn (n=1) 61 ms
# exec round-trip 22 ms
# branch (diff=true) 287 ms pause_ms=234 ...
# fanout (n=5) 65 ms 13ms/child
# cleanup 136 ms
# -----
# total 571 ms
```
screenshot 友好,跑一遍能知道 v0.3 在你机器上是不是真有那个速度。
### 五. 备选:从源码构建你自己的暖启动父 VM(进阶)
```bash
# 1. 主机准备:KVM、Firecracker、Rust、KSM、大页、tap 设备。
sudo bash scripts/setup-host.sh
sudo bash scripts/host-tap.sh
cargo build --release
sudo install -m 0755 target/release/{forkd,forkd-controller} /usr/local/bin/
# 2. 从一个 Docker 镜像构建暖启动 rootfs。
sudo bash scripts/build-rootfs.sh python:3.12-slim python-rootfs.ext4 1536 python3-numpy
# 3. 拉一个内核。
curl -O https://s3.amazonaws.com/spec.ccfc.min/firecracker-ci/v1.10/x86_64/vmlinux-6.1.141
# 4. 跑一个一次性沙箱。
sudo -E forkd run --image python:3.12-slim --kernel ./vmlinux-6.1.141 \
-- python3 -c "import numpy; print(numpy.zeros(5).sum())"
# 0.0
```
### 多子 VM 扇出
```bash
# 一次性给 N 个子 VM 准备好网络 namespace。
sudo bash scripts/netns-setup.sh 100
# 创建一个带 tag 的父快照。
sudo forkd snapshot --tag pyagent \
--kernel ./vmlinux-6.1.141 \
--rootfs ./python-rootfs.ext4 \
--tap forkd-tap0
# Fork 100 个共享父 VM 内存的子 VM。
sudo -E forkd fork --tag pyagent -n 100 --per-child-netns --memory-limit-mib 256
# 和其中一个子 VM 通信。
sudo forkd eval --child forkd-child-42 -- "numpy.zeros(100).sum()"
```
### Python SDK
```python
from forkd import Sandbox # 可直接替换 `from e2b import Sandbox`
with Sandbox() as sb:
print(sb.commands.run("uname -a").stdout)
print(sb.eval("numpy.zeros(5).tolist()")) # 复用暖启动的 PID 1
```
### TypeScript SDK
给 Node.js 18+ 的 agent 用(LangChain.js、agent-twins、任何 JS 侧的工具):
```bash
npm install @deeplethe/forkd
```
```ts
import { Controller } from '@deeplethe/forkd';
const ctrl = new Controller(); // 从 env 读 FORKD_URL、FORKD_TOKEN
const [parent] = await ctrl.spawnSandboxes({
snapshotTag: 'pyagent', n: 1, perChildNetns: true,
liveFork: true, // v0.4:打开后,后续 BRANCH 可以用 mode: 'live'
});
// ... 驱动 parent ...
// `mode: 'live'` + `wait: false` 让源 VM 卡顿 sub-50 ms,~10 ms 返回。
// 背景内存拷贝异步完成,完成后快照 status 从 "writing" 变 "ready"。
const branch = await ctrl.branchSandbox(parent.id, { mode: 'live', wait: false });
const kids = await ctrl.spawnSandboxes({ snapshotTag: branch.tag, n: 5, perChildNetns: true });
```
Surface 与 Python SDK 对齐:`spawnSandboxes` / `branchSandbox` 都接受
`prewarm` / `liveFork` / `mode` / `wait` / `measure_diff`。详见
[`sdk/typescript/`](./sdk/typescript/)。
### MCP server
用 Claude Desktop / Claude Code / Cursor 等任意
[MCP](https://modelcontextprotocol.io/) 客户端接入:
```bash
pip install forkd-mcp
# 然后在 claude_desktop_config.json 里加:
# "mcpServers": { "forkd": { "command": "forkd-mcp" } }
```
Server 暴露 `spawn_sandboxes`、`exec_command`、`eval_code` 等 8 个
工具,agent 可以直接驱动 forkd 微 VM。详见
[`sdk/mcp/README.md`](./sdk/mcp/README.md)。
### Framework 集成 recipe(宿主机侧,不需要 rootfs 构建)
四个最常被问到的 agent framework 的接入示例。每个 ~150-250 行 Python,
带 `--dry-run` 跑 forkd 链路不需要 LLM key:
| Recipe | 驱动 | forkd 特有动作 |
|---|---|---|
| [`mcp-agent/`](./recipes/mcp-agent/) | Claude Desktop / Cursor / Cline (MCP) | 端到端验证 MCP 协议链路 |
| [`crewai-fanout/`](./recipes/crewai-fanout/) | CrewAI | N 个 agent 跑在 N 个 microVM 上(同一父快照)——每个 agent 真正隔离,~24ms/child 启动 |
| [`autogen-branch/`](./recipes/autogen-branch/) | AutoGen | forkd-backed `CodeExecutor` + 对话进行中 BRANCH 出 N 条平行延续 |
| [`openai-swarm/`](./recipes/openai-swarm/) | OpenAI Swarm / Agents SDK | handoff = BRANCH:agent B 继承 agent A 的完整 VM 状态(文件系统、import、env) |
### 预构建 rootfs recipe
不想自己设计 rootfs?直接从 [`recipes/`](./recipes/) 选一个,
跑它的 `build.sh`:
| Recipe | 适合什么 |
|---|---|
| [`python-numpy/`](./recipes/python-numpy/) | 复现基准测试;最轻量的 Python + numpy |
| [`e2b-codeinterpreter/`](./recipes/e2b-codeinterpreter/) | AI 代码解释器 agent(E2B SDK 兼容) |
| [`jupyter-kernel/`](./recipes/jupyter-kernel/) | 预导入 notebook / SciPy 栈;每个 kernel ~1 ms |
| [`coding-agent/`](./recipes/coding-agent/) | SWE-bench / 编码 agent,带 `git` + 开发工具 |
| [`nodejs/`](./recipes/nodejs/) | JS / TS 负载,Playwright 扇出 |
| [`playwright-browser/`](./recipes/playwright-browser/) | 驱动浏览器的 agent(computer-use / 网页研究 / UI 测试生成),fork 出已暖好的 Chromium ≈10 ms |
| [`agent-workbench/`](./recipes/agent-workbench/) | 全家桶——浏览器 + VSCode + Jupyter + MCP |
| [`postgres-fixture/`](./recipes/postgres-fixture/) | fork-per-test 隔离数据库,每个 child ~10 ms 拿到 ready-to-query postgres,跳过 ~2 s fresh initdb |
## 守护进程模式部署
Controller 守护进程持有快照和活跃沙箱的注册表,对外暴露 REST API,
并写结构化审计日志。除了本地开发,推荐都用这种模式部署。
```bash
sudo install -m 0644 packaging/systemd/forkd-controller.service /etc/systemd/system/
sudo mkdir -p /etc/forkd
sudo bash -c 'head -c 32 /dev/urandom | base64 > /etc/forkd/token'
sudo chmod 600 /etc/forkd/token
sudo systemctl enable --now forkd-controller
```
然后用 HTTP 驱动它:
```bash
TOKEN=$(sudo cat /etc/forkd/token)
curl -H "Authorization: Bearer $TOKEN" -X POST http://127.0.0.1:8889/v1/sandboxes \
-H 'Content-Type: application/json' \
-d '{"snapshot_tag":"pyagent","n":5,"per_child_netns":true,"memory_limit_mib":256}'
# [{"id":"sb-67a1b3-0000","pid":...,...}, ...]
curl -H "Authorization: Bearer $TOKEN" http://127.0.0.1:8889/metrics
# forkd_sandboxes_active 5
```
完整 API 参考:[`docs/API.md`](./docs/API.md)。
运维手册:[`docs/RUNBOOK.md`](./docs/RUNBOOK.md)。
安全姿态:[`docs/SECURITY.md`](./docs/SECURITY.md)。
## 仓库结构
```
crates/
forkd-vmm/ Firecracker 封装:BootConfig、Vm、Snapshot、cgroup
forkd-cli/ `forkd` 二进制(snapshot、fork、run、exec、eval)
forkd-controller/ `forkd-controller` 守护进程:REST、注册表、审计
rootfs-init/
forkd-init.sh guest 内的 PID 1;挂载伪文件系统,启动 agent
forkd-agent.py guest 内 :8888 上的 TCP server(ping/exec/eval)
sdk/python/ E2B 兼容的 Python SDK
sdk/typescript/ `@deeplethe/forkd` —— TypeScript / Node.js SDK
sdk/mcp/ MCP server(`forkd-mcp`)—— 从 Claude
Desktop / Claude Code / 任何 MCP 客户端驱动 forkd
scripts/ 宿主机侧的辅助脚本(KVM、Firecracker、netns、rootfs)
packaging/systemd/ Controller 的 systemd unit
packaging/k8s/ forkd-controller 的 Kubernetes starter manifest
recipes/ Framework 集成 recipe(mcp-agent、crewai-fanout、
autogen-branch、openai-swarm)+ 预构建 rootfs
recipe(python-numpy、e2b-codeinterpreter、
jupyter-kernel、coding-agent、nodejs、
playwright-browser、agent-workbench、
postgres-fixture)。详见 recipes/README.md。
bench/ 基准测试 harness、图表生成器、结果
docs/ API.md、SECURITY.md、RUNBOOK.md
```
## 状态
Alpha。fork-on-write 原语、controller 守护进程、REST API、
鉴权、审计日志、cgroup 内存限制、Prometheus metrics、
Python + TypeScript SDK 都已就绪,并由 CI 里的 25 个单元 + 集成测试
覆盖。1.0 之前,磁盘格式和 API 形态可能还会有变化。
本版本暂未达到生产可用的项:
- 多节点调度(目前 一个守护进程 = 一台主机)。
- 子 VM netns 的默认拒绝出站(目前是共享 MASQUERADE 规则;
想要 allow-list 策略的用户需要自己给每个 netns 加 `iptables` 规则)。
- `memory.max` 之外的 `cpu.max`、`io.max`、`pids.max` 配额。
- 第三方安全审计。
Roadmap 和正在追踪的工作都在 [GitHub issues](https://github.com/deeplethe/forkd/issues)。
版本变更记录:[CHANGELOG.md](./CHANGELOG.md)。
安全策略与历史漏洞通告:[docs/SECURITY.md](./docs/SECURITY.md)。
**v0.3 phase 1 已 ship (v0.3.0 → v0.3.4)** —— diff-snapshot BRANCH
把源 VM 暂停时间从 **29.3 秒砍到 205 毫秒(143x)**(4 GiB SSD 源,
空闲); 典型 agent 工作负载(30-300 MiB 脏页)**6-15x**。v0.3.1
支持同一 sandbox 上**多次** diff BRANCH —— 5 次连续 diff BRANCH
聚合下来 **14x** 总暂停时间减少。v0.3.2 把 Python SDK 的
`spawn_sandboxes(prewarm=...)` 和 `branch_sandbox(diff=..., measure_diff=...)`
补齐,跟 REST 和 TypeScript SDK 对齐。v0.3.4 通过 `posix_fallocate`
绕过 ext4 mballoc/wbt_wait,关掉了多 BRANCH 暂停异常 (#146)——
第 6 次连续 BRANCH 从 2.7 秒砍到 153 毫秒,BRANCH 3-10 中位数加速
**8.5x**。完整表格和诚实 caveat 见
[`bench/pause-window/RESULTS-v0.3.md`](./bench/pause-window/RESULTS-v0.3.md);
75 个 trial 的 sweep 原始数据在 `bench/pause-window/*-sweep-*.csv`。
通过 `POST /v1/sandboxes/:id/branch` 请求体加 `"diff": true` 开启,
或用 `forkd snapshot --from-sandbox --diff` 的 CLI flag。
胜的是源 VM 的**停机时间**,不是 BRANCH API 的总延迟:source
的 memory.bin cp 在后台和 source 并行跑,然后 diff 窗口关闭、
source 恢复、diff 合到事先 cp 出来的输出上。源 VM 的 TCP 连接、
kvmclock、定时器只看到 ~200ms 的 gap 而不是 29 秒。BRANCH API
本身的总时间还是被 cp 带宽限制——这个 trade-off 对"长跑 agent
的 live BRANCH"是甜区。
v0.3.1 的多 BRANCH 用**上一次 BRANCH 的输出当 chain head**——
没有 separate shadow file,零额外存储。用户 `DELETE` 中间快照时,
chain 检测到文件缺失自动 fall back 到 source-tag (带 warning)。
完整设计:
[`docs/design/diff-snapshots.md`](./docs/design/diff-snapshots.md)。
**v0.4 live BRANCH** 已经把用户接口全部接通(REST `mode: "live"`、
CLI `--live`、Python / TypeScript / MCP SDK;PR
[#204](https://github.com/deeplethe/forkd/pull/204)–[#207](https://github.com/deeplethe/forkd/pull/207))。
机制:spawn 时带 `live_fork: true`,guest RAM 用 memfd 后端(被
Firecracker 和 controller 共享),BRANCH 时用 UFFD_WP 异步抓脏页,
源 VM 在 vCPU 状态 dump 完立刻恢复(sub-50 ms),内存拷贝异步
完成。原本想留在 vanilla FC,但 `mem_backend.backend_type:
"Shared"` 配 `shared: true`(`mmap MAP_SHARED`)是绕不开的
upstream gap,因此 fork 了:
[deeplethe/firecracker:forkd-v0.4-mem-backend-shared-v1.12](https://github.com/deeplethe/firecracker/tree/forkd-v0.4-mem-backend-shared-v1.12)。
我们已经向 upstream 提了
[`FIRECRACKER-UPSTREAM-PROPOSAL.md`](./FIRECRACKER-UPSTREAM-PROPOSAL.md),
合并后 vendor 要求即可去掉。跟踪:
[issue #101](https://github.com/deeplethe/forkd/issues/101)。在
干净父快照上的 bench 数字(`bench/live-fork-pause-window.md`)
正在跑——Phase 6 E2E 早期数据是 pause_ms = 41-48 ms,但那个
parent 带着 17 个已经 baked-in 的 guest Oopses,会污染测量。
> **0.1.4 包含 daemon 侧安全修复**。`POST /v1/sandboxes` 的
> `snapshot_tag` 校验缺失(任意路径 → 控制 grandchild VM
> volumes)和 K8s manifest 接受字面占位符 bearer token —— 两个 HIGH
> 影响 0.1.0–0.1.3,请升级。完整公告见
> [docs/SECURITY.md#past-advisories](./docs/SECURITY.md#past-advisories)。
> 0.1.3 此前还修复了 CLI `--tag` path-traversal(影响 0.1.0–0.1.2)。
## 贡献
欢迎 Pull Request。开 PR 之前请:
1. 先开 issue 描述你想改什么。API 还在动,我们更愿意提前对齐
而不是让你重写补丁。
2. 本地跑过 `cargo fmt --all && cargo clippy --all-targets -- -D warnings && cargo test --all`。
3. 提交带 sign-off(`git commit -s`)。
## Star 历史

## License
Apache 2.0。详见 [LICENSE](./LICENSE) 与 [NOTICE](./NOTICE)。