{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Learning Strategies\n",
"\n",
"_git:_ https://github.com/JuliaML/LearningStrategies.jl\n",
"\n",
"## Index\n",
"\n",
" - Summary of package and functionalities
\n",
" - How a _learning strategy_ works
\n",
" - Combining _learning strategies_
\n",
" - How data is handled in the default structure
\n",
" __Examples:__\n",
" \n",
" - Building a simple maximum finder (model with no data)
\n",
" - Building a K-means algorithm (model with data)
\n",
" - Making a custom meta-strategy
\n",
" - List and examples of built-in functions
\n",
"
\n",
"
\n",
"\n",
"\n",
"\n",
"## Summary\n",
"\n",
"Through the JuliaML _Learn.jl_ and _LearningStrategies.jl_, a framework was built allowing the simple implementation of new algorithms and learning strategies, and making it extremely simple to combine multiple strategies together.\n",
"\n",
"A strategy here is simply defined as a way for the user to tell how a model (stored as a _struct_) is setup, trained and updated. This idea stems from the very similar pseudocode most learning algorithms operate with, which is:\n",
"\n",
"```julia\n",
"# Learning a model involves a model, a strategy and (not necessary) some data \n",
"function learn!(model, strat::LearningStrategy, data) \n",
" # We set up the model, can be preparing arrays for training, doing some preprocessing\n",
" setup!(strat, model[, data]) \n",
" \n",
" # Using the \"repeated\" function on your data allows it to replicate it infinitely\n",
" for (i, item) in enumerate(data) \n",
" \n",
" # Update the model according to the strategy(-ies) and the data \n",
" update!(model, strat[, i], item) \n",
" \n",
" # Allows to record information or generally \"hook in\" the process. Should NOT modify in place\n",
" hook(strat, model[, data], i) \n",
" \n",
" # Checks if the finishing condition has been reached\n",
" finished(strat, model[, data], i) && break \n",
" end\n",
" \n",
" # Clean up after yourself\n",
" cleanup!(strat, model) \n",
" \n",
" # Return the trained model\n",
" model \n",
"end\n",
"```\n",
"\n",
"Which can be translated as setup, iterate over data until some end condition is met, and clean up.\n",
"In addition, a conventional extra function which can (and should) be defined if your model is predictive, is _predict()_, which should be imported from StatsBase. The pseudocode is as follows\n",
"\n",
"```julia\n",
"function predict(model, data)\n",
" # Make predictions\n",
"end\n",
"```\n",
"\n",
"\n",
"## LearningStrategy\n",
"\n",
"A LearningStrategy is simply a struct which extends _LearningStrategy_. A strategy needs not contain any variable, all that is required is that at least one of the following functions is defined:\n",
"\n",
"- `setup!(strat, model, data)`\n",
"- `cleanup!(strat, model)`\n",
"- `hook(strat, model, i)`\n",
"- `finished(strat, model, data, i)`\n",
"- `update!(model, strat, item)`\n",
"\n",
"Keep in mind of course that if only the `hook` function is defined for a generic strategy _StrategyA_, and this is the only strategy given for learning, the model will.. not learn anything!\n",
"\n",
"\n",
"This architecture makes it extremely simple for user wanting to write his own learning algorithm to add methods as they come without need further planning. For instance, suppose one strats off by just implementing and `SGD()` optimizer, then all that would be required is to define the structure\n",
"\n",
"```julia\n",
"struct SGD() <:LearningStrategy end\n",
"```\n",
"\n",
"and then implement the actual optimization by defining a function `update!(model, strategy::SGD)`. Later on, if the same user or another wants to implement _AdaProx_ optimizer, they can simply add a new function `update!(model, strategy::AdaProx)`.\n",
"\n",
"It is not even required to explicitely wirte a `learn!` function if all you need is the `update!`, simply use the call\n",
"```julia\n",
"learn!(model, SGD(), data)\n",
"```\n",
"and Julia will handle the \"missing\" functions (by simply skipping them) and will make the call to the update you defined.\n",
"\n",
"**Note:** the _data_ (and _i_)parameter is not actually required, all the base functions are defined with both data and no data argument\n",
"\n",
"\n",
"## Meta-Strategy\n",
"\n",
"One extremely powerful feature that this framework offers is the combination of strategies. For instance, while only one strategy will tell the model how to train and update for each iteration, extra strategies which only give side indications can be very easily used. For instance, one of the built-in strategies is `MaxIter(n=100)` which, if given in conjuction to a laerning strategy for any model, will overload the _finished_ function, and will do its own check as to whether the algorithm is indeed over. A simple use would be:\n",
"\n",
"```julia\n",
"learn!(MyModel(), strategies( MyLearningStrategy(), MaxIter(20) ), MyData )\n",
"```\n",
"\n",
"In this way, the learning process will end after 20 iterations, even if the conditions for _finished()_ given by the _MyLearningStrategy_ are not met (only one _finished_ condition needs to be met for the learning to stop)\n",
"\n",
"This means that if you develop your own learning model, you do not need to also add all this \"side functionalities\"! How great is that!\n",
"\n",
"\n",
"## Passing data\n",
"\n",
"Different algorithms use data differently. Some iterate over each element, while other take batches and so on. \n",
"\n",
"The base code uses this loop: `for (i, item) in enumerate(data)`. This implies the data supplied for training is an iterable. This is often not really the case, for instance a matrix, although technically iterable, will be enumerated by element, instead of by row or column which is the more natural way.\n",
"\n",
"Two solutions are therefore proposed;\n",
"\n",
"The first is to pass a _repeated_ matrix using Base.Iterators.repeated, which will basically make every \"item\" a copy of the initial matrix. This is simply used as `repeated(matrix)`.\n",
"\n",
"The other is to do some preprocessing, possibly using the `setup!` function or in some other way. It would be, for example, possible to make a row iterator, in the case of a row-majored matrix."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"____\n",
"## Sample Codes\n",
"\n",
"\n",
"\n",
"### Making a simple maximum finder (No data)\n",
"\n",
"Below I will show a and explain a code to make a simple (and not very good..) maximum finder!\n",
"The idea is this: the model will simply include a starting point (2D space), and a _heuristic function_ that is being maximised by a (bad) strategy.\n",
"\n",
"First thing first, since we're going to be implementing `learn!, update!` and `finished`, we need to export them from the base package"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"using Plots\n",
"using LearningStrategies\n",
"import LearningStrategies: setup!, learn!, update!, finished, hook\n",
"\n",
"import StatsBase: predict\n",
"import Base.Iterators: repeated"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we define the model. It contains 4 attributes, one of which is a generic function. x & y are the starting points, and z will just keep track of the current \"height\" (i.e. score) in the solution space. The _heuristic_ is the function to be optimised"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"mutable struct HillClimber\n",
" x::Float64\n",
" y::Float64\n",
" z::Float64\n",
" heuristic::Function\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then, we define our learning strategy structure. Since this strategy doesn't require any attributes, its definition is trivial."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"struct SillyOptimizer <: LearningStrategy end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally we start the actual strategy building."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"finished (generic function with 13 methods)"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"function update!(model::HillClimber, s::SillyOptimizer)\n",
" # Generate 4 random direction vectors\n",
" choices = rand((4,2))-0.5\n",
"\n",
" # Normalizes to unit step size\n",
" choices ./= abs.(sum(choices,2))\n",
"\n",
" # Test the locations\n",
" heights = [heuristic(choices[i,:]+[model.x,model.y]) for i in 1:size(choices,1)]\n",
" \n",
" # Keep the best\n",
" (model.z, best) = findmax(heights)\n",
" \n",
" # Change current coordinates\n",
" model.x += choices[best,1]\n",
" model.y += choices[best,2]\n",
"end\n",
"\n",
"# Stop after first iteration\n",
"finished(s::SillyOptimizer, model) = true"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You may have noticed that the `learn!` did not actually need to be defined since there is no need to override the default learning structure. The _finished_ function simply returns true, hence the learning will complete after one iteration. Let's give it a try:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"HillClimber(-1.042851726399331, -0.4571482736006689, 0.6740519892971322, heuristic)"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Gaussian with max at (0,1)\n",
"function heuristic(x)\n",
" arg = (x[1])^2 /5 + (x[2]-1)^2 /12\n",
" h = exp(-arg)\n",
" h\n",
"end\n",
"\n",
"# Create the model, giving the attributes in order of definition\n",
"model = HillClimber(1.5, -2, 0, heuristic)\n",
"\n",
"# Learn!\n",
"learn!(model, SillyOptimizer() )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So given that it's a pretty bad optimiser and that we only allowed for one iteration, it didn't perform very well..\n",
"Now it's quite hard for such an optimizer to decide when to stop and building a finished function. Therefore, what I will do is intead use meta-learning to decide when to finish. \n",
"\n",
"To do this, I first need to redefine `finished` so that it doesn't return true, and then use a convergence strategy, such as MaxIter or TimeLimit.\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"HillClimber(0.3349619985744343, -0.8349619985744344, 0.73857666586363, heuristic)"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Redefine to never finish (careful here! #infiniteloop)\n",
"finished(s::SillyOptimizer, model) = false\n",
"\n",
"# Create the model, giving the attributes in order of definition\n",
"model = HillClimber(1.5, -2, 0, heuristic)\n",
"\n",
"# Use MaxIter to decide when to end learning\n",
"learn!(model, strategy( SillyOptimizer(), MaxIter(20) ) )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Building a K-means learner \n",
"\n",
"_TODO: rewrite this terrible description_ \n",
"\n",
"K-means is an unsupervised-learning algorithm which attempts to find the set of _k_ clusters which separates the data the best.\n",
"\n",
"The model itself doesn't require anything more than the number _K_ of clusters that the user expects, and an array of means which can be initialised in the setup. Here we are writing an algorithm for the case of 2D points."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"mutable struct KMeans\n",
" k::Int32\n",
" means::Array{Float64,2}\n",
"\n",
" # Constructor requires the number k of clusters to calculate\n",
" KMeans(k) = new( k, zeros((0,2)) )\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The strategy requires a few more variables, an array of distances of each point to the means, and an array of the assigned mean for that iteration.\n",
"\n",
"Note that these would not necessarily be required as structure variables, since they could be reallocated continuously in the update function."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"mutable struct Lloyds <:LearningStrategy \n",
" n_obs::Int32\n",
" distances::Array{Float64}\n",
" choices::Array{Int64}\n",
" Lloyds() = new(0,[],[])\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now for the actual learning, two functions are defined. _setup!_ is used to, as expected, setup and allocate the model and strategy variables. \n",
"\n",
"The means are randomly initialised with coordinates close to the origin, and the strategy variables are allocated. \n",
"\n",
"The _update!_ simply follows the _Lloyds_ algorithm, which is the basic K-means algorithm."
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"update! (generic function with 6 methods)"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"function setup!(s::Lloyds, model::KMeans, repeated_points::Base.Iterators.Repeated{Array{Float64,2}})\n",
" model.means = randn(model.k,2)*0.1\n",
" s.n_obs = size(repeated_points.x,1)\n",
" s.distances = zeros(model.k)\n",
" s.choices = zeros(Int64, s.n_obs)\n",
"end\n",
"\n",
"function update!(model::KMeans, s::Lloyds, points::Array{Float64,2})\n",
" # Assign step\n",
" for i in 1:s.n_obs \n",
" # Get distance from means\n",
" for j in 1:model.k\n",
" s.distances[j] = sum((points[i,:]-model.means[j,:]).^2)\n",
" end\n",
" # Assign to closest mean\n",
" s.choices[i] = findmin(s.distances)[2]\n",
"\n",
" end\n",
" \n",
" # Update k-means\n",
" for i in 1:model.k\n",
" # Get list of points assigned to i-th mean\n",
" in_cluster = (s.choices .== i)\n",
"\n",
" # Calculate new mean (average)\n",
" mean = sum(points[in_cluster,:],1)\n",
" mean /= sum(in_cluster.==true)\n",
" \n",
" model.means[i,:] = mean\n",
" end\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"_predict_ is imported from StatsBase. We notice that the \"assigning\" step in the update is really just a prediction, and therefore it could have simply be replaced with a call to the predict function. This was not done out of clarity of the example."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"predict (generic function with 2 methods)"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Imported from StatsBase\n",
"function predict(model::KMeans, points::Array{Float64})\n",
" n_obs = size(points,1)\n",
" distances = zeros(model.k)\n",
" predictions = zeros(Int64, n_obs)\n",
"\n",
" for i in 1:n_obs \n",
" # Get distance from means\n",
" for j in 1:model.k\n",
" distances[j] = sum((points[i,:]-model.means[j,:]).^2)\n",
" end\n",
" \n",
" # Assign to closest mean\n",
" predictions[i] = findmin(distances)[2]\n",
" end\n",
" predictions\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then we simply train the model. We set K=3, points generated from normals withs differents variances and means.\n",
"\n",
"Note that the data is given as a _repeated_ iterator, which is simply an iterator of the same data. This structure is the preferred for the framework since it fits better with the basic _learn!_, although one could jsut overload the latter and have a normal array be sent, or similarly transform it in the _setup!_."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Instantiate a KMeans model with k=3\n",
"model = KMeans(3)\n",
"# Points are generated from three normals with different stds\n",
"points = vcat( randn(100,2)*0.2 .+ [1.0 1.0], randn(100,2)*0.5 .+ [-1.0 0.0], randn(100,2)*0.35 .+ [2.0 -1.0] )\n",
"learn!(model, strategy(Lloyds(), MaxIter(10)), Base.Iterators.repeated(points))\n",
"\n",
"# How prediction would work\n",
"predict(model, points);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"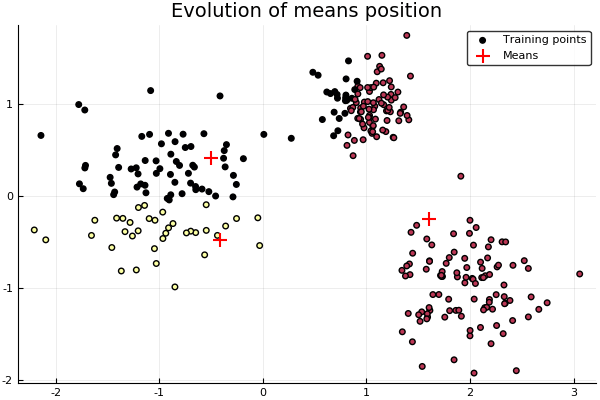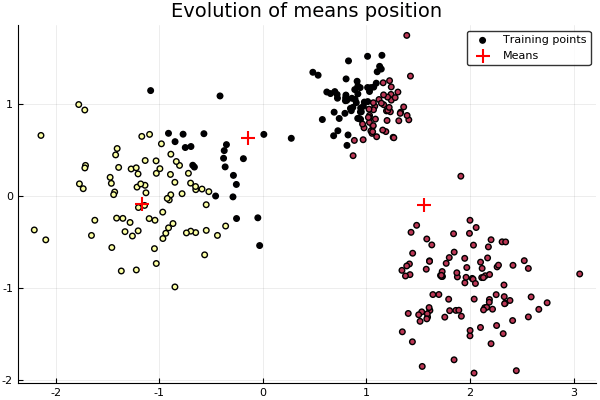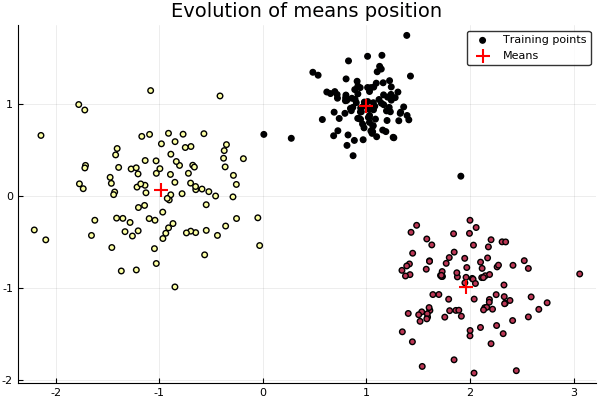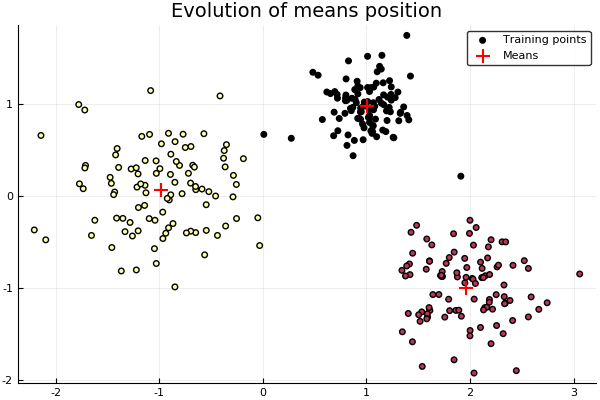\n",
"[Source](resources/snippets/LearningStrategies.ipynb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Making a helper strategy (using hook function)\n",
"\n",
"Now it's quite hard to tell whether it's actually working any good given the optimizer is quite bad and will keep moving even when it reaches a maximum, therefore I'd like to be able to visualise.. \n",
"\n",
"Why not build a path tracing strategy!\n",
"\n",
"For this, one could either write and `update!` function which would update the strategy, but because we're just recording a trace, if makes more sense to use the `hook` function, which is another function allowed in the framework, used for printing or logging; one can think of it as a function meant to _observe_ the process, without interfering with it."
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"hook (generic function with 7 methods)"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# One array for each coordinate to keep track of positions\n",
"mutable struct PathTracer <: LearningStrategy\n",
" x::Array{Float64}\n",
" y::Array{Float64}\n",
" z::Array{Float64}\n",
"end\n",
"\n",
"# The constructor (for any argument) is simply to initialise the arrays\n",
"PathTracer() = PathTracer([],[],[])\n",
"\n",
"# On setup, save initial position\n",
"function setup!(s::PathTracer, model::HillClimber)\n",
" update!(model, s) \n",
"end\n",
"\n",
"# Save current position in helper strategy\n",
"function hook(s::PathTracer, model::HillClimber)\n",
" push!(s.x, model.x)\n",
" push!(s.y, model.y)\n",
" push!(s.z, model.z)\n",
"end"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"HillClimber(0.0948636718479543, 1.1051363281520459, 0.997282737919177, heuristic)"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Run the model again, this time adding the path tracer strategy\n",
"model = HillClimber(2.0, -4.8, 0.0, heuristic)\n",
"tracer = PathTracer()\n",
"learn!(model, strategy(SillyOptimizer(), MaxIter(30), tracer) )"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Plots.Animation(\"/tmp/tmpxkTZbH\", String[])"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
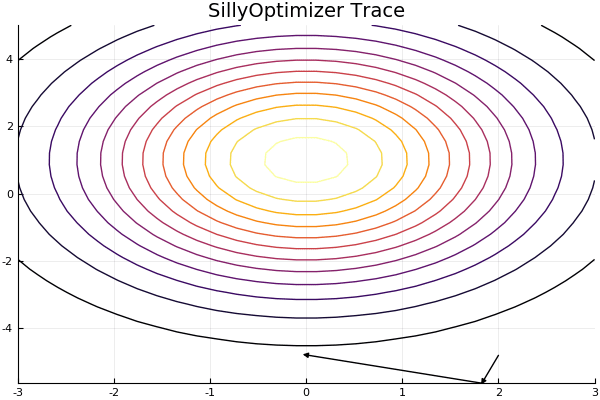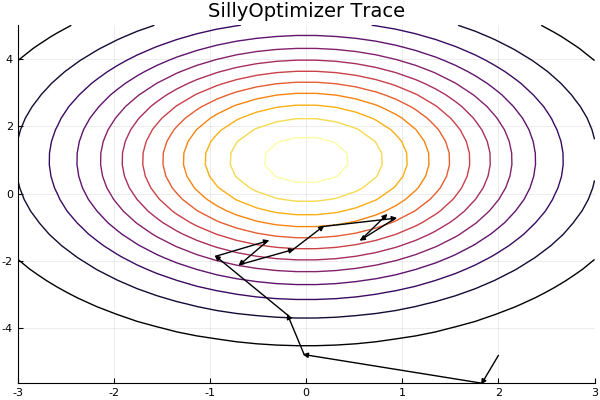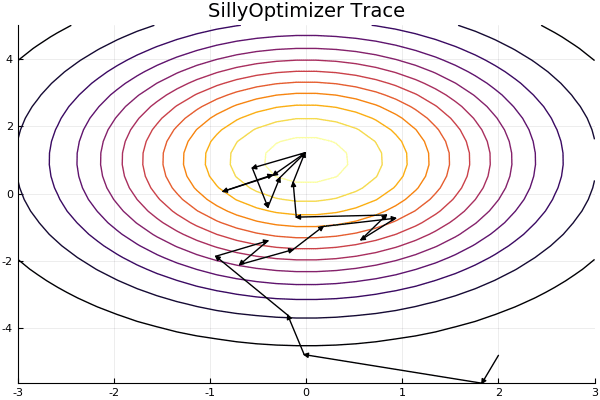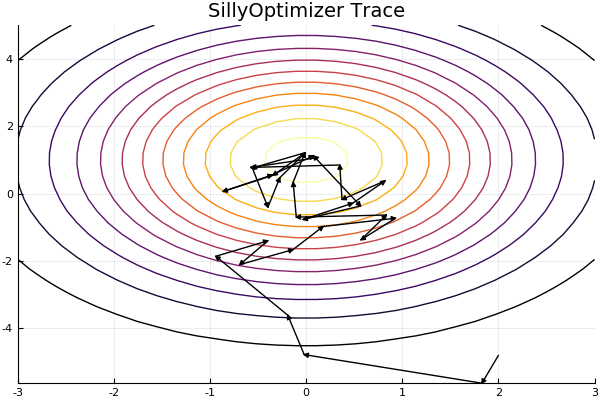
"# Plot\n",
"using Plots\n",
"pyplot()\n",
"xs = linspace(-3,3,30)\n",
"ys = linspace(-5,5,30)\n",
"z = [heuristic([x, y]) for x=xs, y=ys]'\n",
"\n",
"anim = @animate for max_length = 2:length(tracer.x)-1\n",
" plot(xs, ys, z)\n",
" for i in 1:max_length\n",
" plot!([tracer.x[i], tracer.x[i+1]], [tracer.y[i], tracer.y[i+1]], arrow = true, color=\"black\")\n",
" end\n",
" plot!(legend=false, cb=false, title=\"SillyOptimizer Trace\")\n",
"end"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Built-in functions\n",
"\n",
"We've already looked at `MaxIter`, here's a list of other built-in functions from LearningStrategy that will be discussed below:\n",
"\n",
"- TimeLimit\n",
"- Converged\n",
"- ConvergedTo\n",
"- IterFunction\n",
"- Tracer\n",
"- Breaker\n",
"\n",
"\n",
"#### TimeLimit\n",
"Allows to set a maximal time (in seconds) for the process to run."
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Time elapsed: 1.053900964\n"
]
}
],
"source": [
"model = HillClimber(2.0, -4.8, 0.0, heuristic)\n",
"tic()\n",
"learn!(model, strategy(SillyOptimizer(), TimeLimit(1.0)) )\n",
"t = toq()\n",
"println(\"Time elapsed: $t\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Converged\n",
"\n",
"Allows to check if the model has converged by looking at whether it is changing by enough of a margin. From the source code\n",
"```\n",
" Converged(f; tol = 1e-6, every = 1)\n",
" Stop learning when `norm(f(model) - lastf) ≦ tol`. `f` must return a `Vector{Float64}`.\n",
"```\n",
"f should be a function that takes as argument the model. In the case of our optimizer, this is not a great strategy since we know the optimizer takes pretty big steps and moves a lot even when near a maximum. Nevertheless, we can sort of test convergence by checking whether the heuristic has changed by less than a tolerance $\\epsilon$.\n"
]
},
{
"cell_type": "code",
"execution_count": 103,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"HillClimber(0.38183295191069544, -0.18183295191069537, 0.8645437442655263, heuristic)"
]
},
"execution_count": 103,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model = HillClimber(2.0, -4.8, 0.0, heuristic)\n",
"\n",
"θ(m::HillClimber) = [m.heuristic([m.x m.y])]\n",
"ϵ=0.01\n",
"\n",
"learn!(model, strategy( SillyOptimizer(), Converged(θ, tol=ϵ) ) )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Similarly, on the KMeans example (which is more adapted to this convergence strategy)"
]
},
{
"cell_type": "code",
"execution_count": 102,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"KMeans(3, [2.03591 -1.01121; 0.992619 1.02625; -1.08733 -0.0182533])"
]
},
"execution_count": 102,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model = KMeans(3)\n",
"points = vcat( randn(100,2)*0.2 .+ [1.0 1.0], randn(100,2)*0.5 .+ [-1.0 0.0], randn(100,2)*0.35 .+ [2.0 -1.0] )\n",
"\n",
"ϵ=0.01\n",
"θ(m::KMeans) = m.means[:]\n",
"\n",
"learn!(model, strategy(Lloyds(), Converged(θ,tol=ϵ)), Base.Iterators.repeated(points))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### ConvergedTo\n",
"\n",
"Allows to check whether the model has converged to a goal value.\n",
"```julia\n",
" ConvergedTo(f, goal; tol=1e-6, every=1)\n",
" Stop learning when `‖f(model) - goal‖ ≦ tol`.\n",
"```\n",
"The user must provide a function taking the model as argument and returning a float. The latter should be some sort of score of the model to check for convergence to the goal\n",
"\n",
"In our case, this will simply check if we're close to the actual maximum (which we know given the heuristic is a gaussian)"
]
},
{
"cell_type": "code",
"execution_count": 134,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"\u001b[1m\u001b[36mINFO: \u001b[39m\u001b[22m\u001b[36mConverged after 3 iterations: 0.9627098842147999\n",
"\u001b[39m"
]
},
{
"data": {
"text/plain": [
"HillClimber(-0.27074663336744964, 0.4707466333674494, 0.9627098842147999, heuristic)"
]
},
"execution_count": 134,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model = HillClimber(2.0, -4.8, 0.0, heuristic)\n",
"\n",
"θ(m::HillClimber) = m.heuristic( [m.x m.y] )\n",
"ϵ=0.05\n",
"goal = model.heuristic( [0.0 1.0] )\n",
"\n",
"learn!(model, strategy(SillyOptimizer(), ConvergedTo(θ,ϵ, goal, 1) ) )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Tracer\n",
"\n",
"Earlier, I demonstrated a helper strategy, `PathTracer`, which allowed to record the movement. This actually already exists as a built-in function, `Tracer` which allows for much more operations.\n",
"```\n",
"Tracer{T}(::Type{T}, f, b=1)\n",
"Store `f(model, i)` every `b` iterations.\n",
"```\n",
"Let us record our means for the KMeans example. We're recording the means, stored as rows in a matrix, therefore the `::Type{T}` will be `Array{Float64}`. Additionally, a requirement on the function is that it accepts two arguments, `model` and `i`, the latter being the iteration number. In this case we just ignore it. "
]
},
{
"cell_type": "code",
"execution_count": 107,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"KMeans(3, Array{Float64}(0,2))"
]
},
"execution_count": 107,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model = KMeans(3)\n",
"points = vcat( randn(100,2)*0.2 .+ [1.0 1.0], randn(100,2)*0.5 .+ [-1.0 0.0], randn(100,2)*0.35 .+ [2.0 -1.0] )\n",
"\n",
"θ(m::KMeans, i) = m.means\n",
"t = Tracer(Array{Float64,2}, θ)\n",
"\n",
"learn!(model, strategy(SillyOptimizer(), t, MaxIter(5) ) )\n",
"\n",
"# Records are stored in\n",
"t.storage "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Breaker\n",
"\n",
"Allows to add a condition to break out of the learning, by defining a boolean function acting on the model and the iteration number:\n",
"```\n",
" Breaker(f)\n",
" Stop learning when `f(model, i)` returns true.\n",
"```\n",
"As a meaningless example, we will simply break when the `y` value of the hill climbing model is larger than 0."
]
},
{
"cell_type": "code",
"execution_count": 117,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"HillClimber(-1.3979701578860708, 1.5979701578860714, 0.6566123457082915, heuristic)"
]
},
"execution_count": 117,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model = HillClimber(2.0, -4.8, 0.0, heuristic)\n",
"\n",
"θ(m::HillClimber, ..) = m.y > 0.0\n",
"\n",
"learn!(model, strategy(SillyOptimizer(), Breaker(θ) ) )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### IterFunction\n",
"```\n",
" IterFunction(f)\n",
" IterFunction(f, b)\n",
" IterFunction(b, f)\n",
"\n",
" Call `f(model, i)` every `b` iterations at `hook` call.\n",
" Default value of `b` is 1.\n",
"```\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Julia 0.6.2",
"language": "julia",
"name": "julia-0.6"
},
"language_info": {
"file_extension": ".jl",
"mimetype": "application/julia",
"name": "julia",
"version": "0.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}