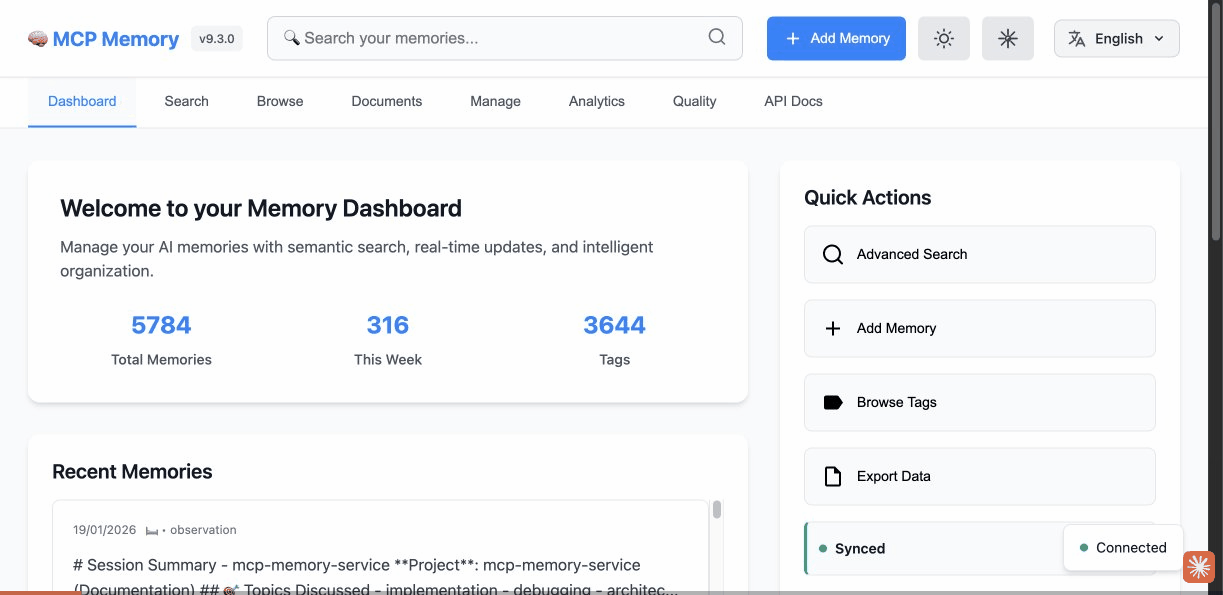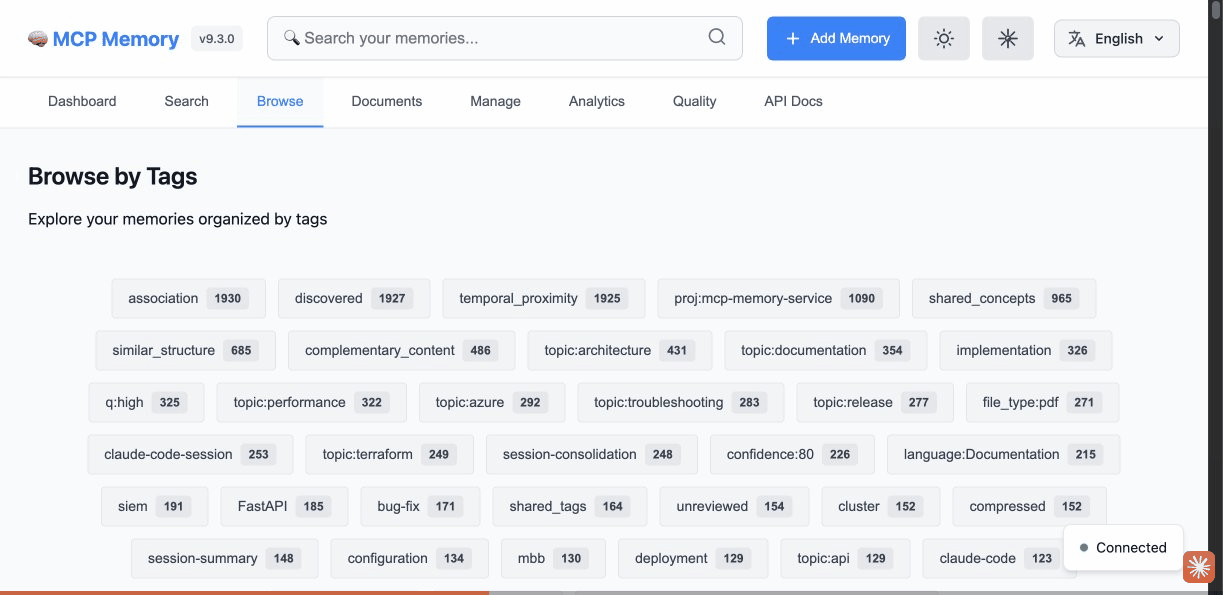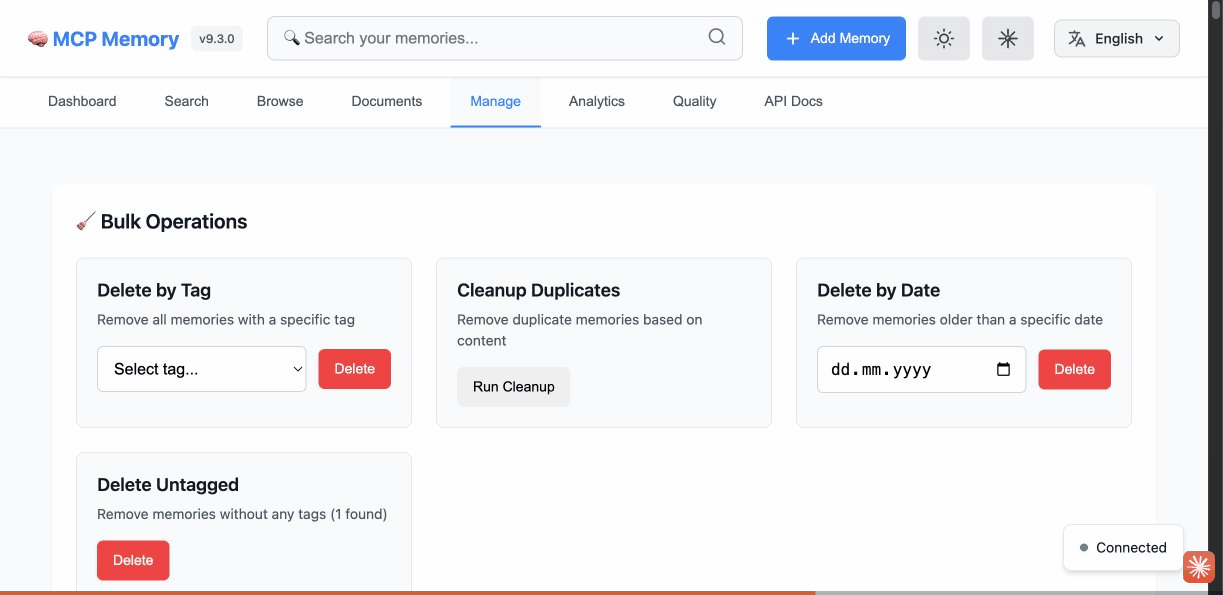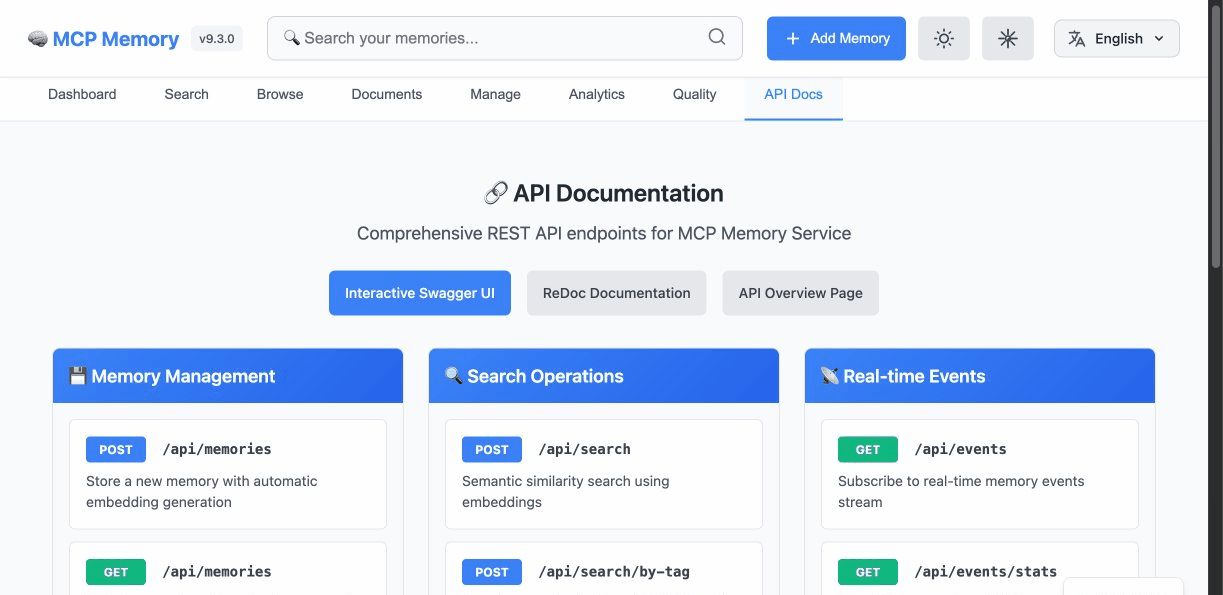
Technical showcase: Performance, Architecture, AI/ML Intelligence & Developer Experience
### ⚡ Works With Your Favorite AI Tools
#### 🤖 Agent Frameworks (REST API)
**LangGraph** · **CrewAI** · **AutoGen** · **Any HTTP Client** · **OpenClaw/Nanobot** · **Custom Pipelines**
#### 🖥️ CLI & Terminal AI (MCP)
**Claude Code** · **Gemini CLI** · **Gemini Code Assist** · **OpenCode** · **Codex CLI** · **Goose** · **Aider** · **GitHub Copilot CLI** · **Amp** · **Continue** · **Zed** · **Cody**
#### 🎨 Desktop & IDE (MCP)
**Claude Desktop** · **VS Code** · **Cursor** · **Windsurf** · **Kilo Code** · **Raycast** · **JetBrains** · **Replit** · **Sourcegraph** · **Qodo**
#### 💬 Chat Interfaces (MCP)
**ChatGPT** (Developer Mode) · **claude.ai** (Remote MCP via HTTPS)
**Works seamlessly with any MCP-compatible client or HTTP client** - whether you're building agent pipelines, coding in the terminal, IDE, or browser.
> **💡 NEW**: ChatGPT now supports MCP! Enable Developer Mode to connect your memory service directly. [See setup guide →](https://github.com/doobidoo/mcp-memory-service/discussions/377#discussioncomment-15605174)
---
## 🚀 Get Started in 60 Seconds
> Not sure which setup fits your needs? See the **[Setup Guide](docs/setup-guide.md)** — a decision tree walks you to the right path in under a minute.
**1. Install:**
```bash
pip install mcp-memory-service
```
**2. Configure your AI client:**