 # Deploying Deep Learning
Welcome to our instructional guide for inference and realtime vision [DNN library](#api-reference) for **[NVIDIA Jetson](https://developer.nvidia.com/embedded-computing)** devices. This project uses **[TensorRT](https://developer.nvidia.com/tensorrt)** to run optimized networks on GPUs from C++ or Python, and PyTorch for training models.
Supported DNN vision primitives include [`imageNet`](docs/imagenet-console-2.md) for image classification, [`detectNet`](docs/detectnet-console-2.md) for object detection, [`segNet`](docs/segnet-console-2.md) for semantic segmentation, [`poseNet`](docs/posenet.md) for pose estimation, and [`actionNet`](docs/actionnet.md) for action recognition. Examples are provided for streaming from live camera feeds, making webapps with WebRTC, and support for ROS/ROS2.
# Deploying Deep Learning
Welcome to our instructional guide for inference and realtime vision [DNN library](#api-reference) for **[NVIDIA Jetson](https://developer.nvidia.com/embedded-computing)** devices. This project uses **[TensorRT](https://developer.nvidia.com/tensorrt)** to run optimized networks on GPUs from C++ or Python, and PyTorch for training models.
Supported DNN vision primitives include [`imageNet`](docs/imagenet-console-2.md) for image classification, [`detectNet`](docs/detectnet-console-2.md) for object detection, [`segNet`](docs/segnet-console-2.md) for semantic segmentation, [`poseNet`](docs/posenet.md) for pose estimation, and [`actionNet`](docs/actionnet.md) for action recognition. Examples are provided for streaming from live camera feeds, making webapps with WebRTC, and support for ROS/ROS2.
 Follow the **[Hello AI World](#hello-ai-world)** tutorial for running inference and transfer learning onboard your Jetson, including collecting your own datasets, training your own models with PyTorch, and deploying them with TensorRT.
### Table of Contents
* [Hello AI World](#hello-ai-world)
* [Jetson AI Lab](#jetson-ai-lab)
* [Video Walkthroughs](#video-walkthroughs)
* [API Reference](#api-reference)
* [Code Examples](#code-examples)
* [Pre-Trained Models](#pre-trained-models)
* [System Requirements](#recommended-system-requirements)
* [Change Log](CHANGELOG.md)
> > JetPack 6 is now supported on Orin devices ([developer.nvidia.com/jetpack](https://developer.nvidia.com/embedded/jetpack))
Follow the **[Hello AI World](#hello-ai-world)** tutorial for running inference and transfer learning onboard your Jetson, including collecting your own datasets, training your own models with PyTorch, and deploying them with TensorRT.
### Table of Contents
* [Hello AI World](#hello-ai-world)
* [Jetson AI Lab](#jetson-ai-lab)
* [Video Walkthroughs](#video-walkthroughs)
* [API Reference](#api-reference)
* [Code Examples](#code-examples)
* [Pre-Trained Models](#pre-trained-models)
* [System Requirements](#recommended-system-requirements)
* [Change Log](CHANGELOG.md)
> > JetPack 6 is now supported on Orin devices ([developer.nvidia.com/jetpack](https://developer.nvidia.com/embedded/jetpack))
> > Check out the Generative AI and LLM tutorials on [Jetson AI Lab](https://www.jetson-ai-lab.com/)!
> > See the [Change Log](CHANGELOG.md) for the latest updates and new features.
## Hello AI World
Hello AI World can be run completely onboard your Jetson, including live inferencing with TensorRT and transfer learning with PyTorch. For installation instructions, see [System Setup](#system-setup). It's then recommended to start with the [Inference](#inference) section to familiarize yourself with the concepts, before diving into [Training](#training) your own models.
#### System Setup
* [Setting up Jetson with JetPack](docs/jetpack-setup-2.md)
* [Running the Docker Container](docs/aux-docker.md)
* [Building the Project from Source](docs/building-repo-2.md)
#### Inference
* [Image Classification](docs/imagenet-console-2.md)
* [Using the ImageNet Program on Jetson](docs/imagenet-console-2.md)
* [Coding Your Own Image Recognition Program (Python)](docs/imagenet-example-python-2.md)
* [Coding Your Own Image Recognition Program (C++)](docs/imagenet-example-2.md)
* [Running the Live Camera Recognition Demo](docs/imagenet-camera-2.md)
* [Multi-Label Classification for Image Tagging](docs/imagenet-tagging.md)
* [Object Detection](docs/detectnet-console-2.md)
* [Detecting Objects from Images](docs/detectnet-console-2.md#detecting-objects-from-the-command-line)
* [Running the Live Camera Detection Demo](docs/detectnet-camera-2.md)
* [Coding Your Own Object Detection Program](docs/detectnet-example-2.md)
* [Using TAO Detection Models](docs/detectnet-tao.md)
* [Object Tracking on Video](docs/detectnet-tracking.md)
* [Semantic Segmentation](docs/segnet-console-2.md)
* [Segmenting Images from the Command Line](docs/segnet-console-2.md#segmenting-images-from-the-command-line)
* [Running the Live Camera Segmentation Demo](docs/segnet-camera-2.md)
* [Pose Estimation](docs/posenet.md)
* [Action Recognition](docs/actionnet.md)
* [Background Removal](docs/backgroundnet.md)
* [Monocular Depth](docs/depthnet.md)
#### Training
* [Transfer Learning with PyTorch](docs/pytorch-transfer-learning.md)
* Classification/Recognition (ResNet-18)
* [Re-training on the Cat/Dog Dataset](docs/pytorch-cat-dog.md)
* [Re-training on the PlantCLEF Dataset](docs/pytorch-plants.md)
* [Collecting your own Classification Datasets](docs/pytorch-collect.md)
* Object Detection (SSD-Mobilenet)
* [Re-training SSD-Mobilenet](docs/pytorch-ssd.md)
* [Collecting your own Detection Datasets](docs/pytorch-collect-detection.md)
#### WebApp Frameworks
* [WebRTC Server](docs/webrtc-server.md)
* [HTML / JavaScript](docs/webrtc-html.md)
* [Flask + REST](docs/webrtc-flask.md)
* [Plotly Dashboard](docs/webrtc-dash.md)
* [Recognizer (Interactive Training)](docs/webrtc-recognizer.md)
#### Appendix
* [Camera Streaming and Multimedia](docs/aux-streaming.md)
* [Image Manipulation with CUDA](docs/aux-image.md)
* [DNN Inference Nodes for ROS/ROS2](https://github.com/dusty-nv/ros_deep_learning)
## Jetson AI Lab
 The [**Jetson AI Lab**](https://www.jetson-ai-lab.com) has additional tutorials on LLMs, Vision Transformers (ViT), and Vision Language Models (VLM) that run on Orin (and in some cases Xavier). Check out some of these:
The [**Jetson AI Lab**](https://www.jetson-ai-lab.com) has additional tutorials on LLMs, Vision Transformers (ViT), and Vision Language Models (VLM) that run on Orin (and in some cases Xavier). Check out some of these:
 > [NanoOWL - Open Vocabulary Object Detection ViT](https://www.jetson-ai-lab.com/tutorial_nanoowl.html) (container: [`nanoowl`](/packages/vit/nanoowl))
> [NanoOWL - Open Vocabulary Object Detection ViT](https://www.jetson-ai-lab.com/tutorial_nanoowl.html) (container: [`nanoowl`](/packages/vit/nanoowl))
 > [Live Llava on Jetson AGX Orin](https://youtu.be/X-OXxPiUTuU) (container: [`local_llm`](/packages/llm/local_llm#live-llava))
> [Live Llava on Jetson AGX Orin](https://youtu.be/X-OXxPiUTuU) (container: [`local_llm`](/packages/llm/local_llm#live-llava))
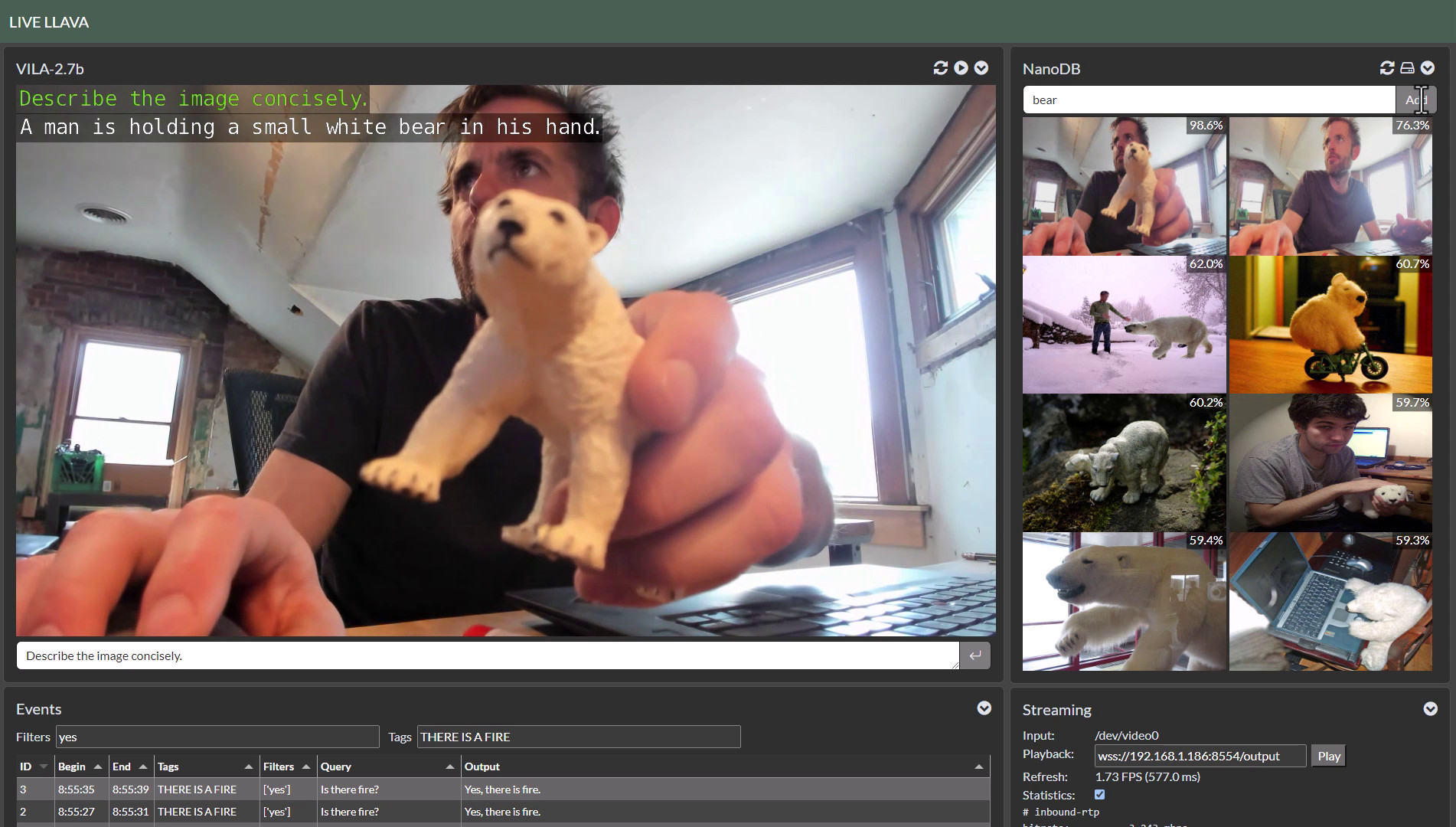 > [Live Llava 2.0 - VILA + Multimodal NanoDB on Jetson Orin](https://youtu.be/X-OXxPiUTuU) (container: [`local_llm`](/packages/llm/local_llm#live-llava))
> [Live Llava 2.0 - VILA + Multimodal NanoDB on Jetson Orin](https://youtu.be/X-OXxPiUTuU) (container: [`local_llm`](/packages/llm/local_llm#live-llava))
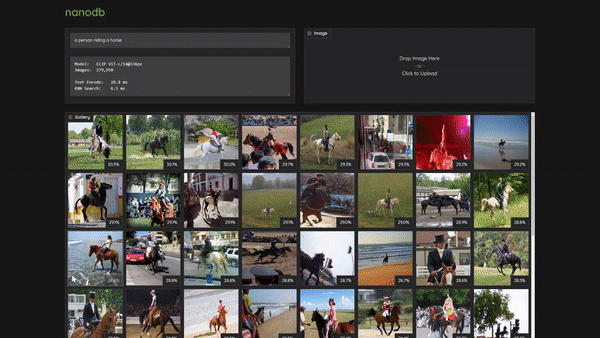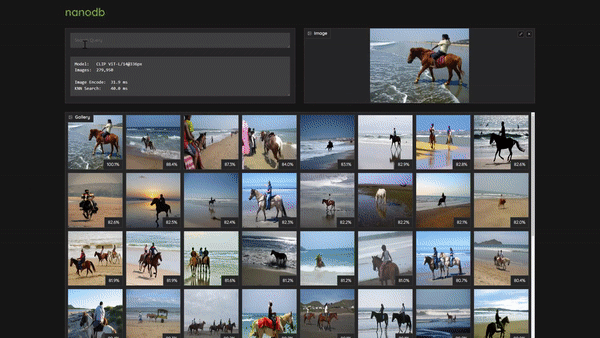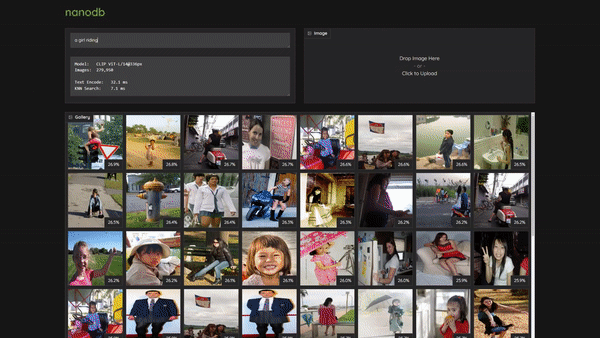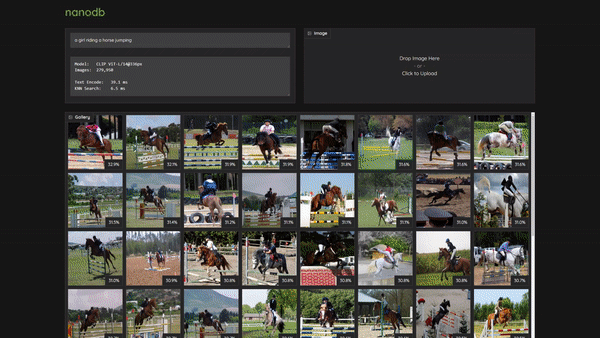 > [Realtime Multimodal VectorDB on NVIDIA Jetson](https://www.youtube.com/watch?v=wzLHAgDxMjQ) (container: [`nanodb`](/packages/vectordb/nanodb))
## Video Walkthroughs
Below are screencasts of Hello AI World that were recorded for the [Jetson AI Certification](https://developer.nvidia.com/embedded/learn/jetson-ai-certification-programs) course:
| Description | Video |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| **Hello AI World Setup**
> [Realtime Multimodal VectorDB on NVIDIA Jetson](https://www.youtube.com/watch?v=wzLHAgDxMjQ) (container: [`nanodb`](/packages/vectordb/nanodb))
## Video Walkthroughs
Below are screencasts of Hello AI World that were recorded for the [Jetson AI Certification](https://developer.nvidia.com/embedded/learn/jetson-ai-certification-programs) course:
| Description | Video |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| **Hello AI World Setup**
Download and run the Hello AI World container on Jetson Nano, test your camera feed, and see how to stream it over the network via RTP. |  |
| **Image Classification Inference**
|
| **Image Classification Inference**
Code your own Python program for image classification using Jetson Nano and deep learning, then experiment with realtime classification on a live camera stream. |  |
| **Training Image Classification Models**
|
| **Training Image Classification Models**
Learn how to train image classification models with PyTorch onboard Jetson Nano, and collect your own classification datasets to create custom models. |  |
| **Object Detection Inference**
|
| **Object Detection Inference**
Code your own Python program for object detection using Jetson Nano and deep learning, then experiment with realtime detection on a live camera stream. |  |
| **Training Object Detection Models**
|
| **Training Object Detection Models**
Learn how to train object detection models with PyTorch onboard Jetson Nano, and collect your own detection datasets to create custom models. |  |
| **Semantic Segmentation**
|
| **Semantic Segmentation**
Experiment with fully-convolutional semantic segmentation networks on Jetson Nano, and run realtime segmentation on a live camera stream. |  |
## API Reference
Below are links to reference documentation for the [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/index.html) and [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.html) libraries from the repo:
#### jetson-inference
| | [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__deepVision.html) | [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html) |
|--------------------|--------------|--------------|
| Image Recognition | [`imageNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__imageNet.html#classimageNet) | [`imageNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#imageNet) |
| Object Detection | [`detectNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__detectNet.html#classdetectNet) | [`detectNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#detectNet)
| Segmentation | [`segNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__segNet.html#classsegNet) | [`segNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#segNet) |
| Pose Estimation | [`poseNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__poseNet.html#classposeNet) | [`poseNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#poseNet) |
| Action Recognition | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__actionNet.html#classactionNet) | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#actionNet) |
| Background Removal | [`backgroundNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__backgroundNet.html#classbackgroundNet) | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#backgroundNet) |
| Monocular Depth | [`depthNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__depthNet.html#classdepthNet) | [`depthNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#depthNet) |
#### jetson-utils
* [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__util.html)
* [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.utils.html)
These libraries are able to be used in external projects by linking to `libjetson-inference` and `libjetson-utils`.
## Code Examples
Introductory code walkthroughs of using the library are covered during these steps of the Hello AI World tutorial:
* [Coding Your Own Image Recognition Program (Python)](docs/imagenet-example-python-2.md)
* [Coding Your Own Image Recognition Program (C++)](docs/imagenet-example-2.md)
Additional C++ and Python samples for running the networks on images and live camera streams can be found here:
| | C++ | Python |
|-------------------|---------------------|---------------------|
| Image Recognition | [`imagenet.cpp`](examples/imagenet/imagenet.cpp) | [`imagenet.py`](python/examples/imagenet.py) |
| Object Detection | [`detectnet.cpp`](examples/detectnet/detectnet.cpp) | [`detectnet.py`](python/examples/detectnet.py) |
| Segmentation | [`segnet.cpp`](examples/segnet/segnet.cpp) | [`segnet.py`](python/examples/segnet.py) |
| Pose Estimation | [`posenet.cpp`](examples/posenet/posenet.cpp) | [`posenet.py`](python/examples/posenet.py) |
| Action Recognition | [`actionnet.cpp`](examples/actionnet/actionnet.cpp) | [`actionnet.py`](python/examples/actionnet.py) |
| Background Removal | [`backgroundnet.cpp`](examples/backgroundnet/backgroundnet.cpp) | [`backgroundnet.py`](python/examples/backgroundnet.py) |
| Monocular Depth | [`depthnet.cpp`](examples/depthnet/segnet.cpp) | [`depthnet.py`](python/examples/depthnet.py) |
> **note**: see the [Array Interfaces](docs/aux-image.md#array-interfaces) section for using memory with other Python libraries (like Numpy, PyTorch, ect)
These examples will automatically be compiled while [Building the Project from Source](docs/building-repo-2.md), and are able to run the pre-trained models listed below in addition to custom models provided by the user. Launch each example with `--help` for usage info.
## Pre-Trained Models
The project comes with a number of pre-trained models that are available to use and will be automatically downloaded:
#### Image Recognition
| Network | CLI argument | NetworkType enum |
| --------------|----------------|------------------|
| AlexNet | `alexnet` | `ALEXNET` |
| GoogleNet | `googlenet` | `GOOGLENET` |
| GoogleNet-12 | `googlenet-12` | `GOOGLENET_12` |
| ResNet-18 | `resnet-18` | `RESNET_18` |
| ResNet-50 | `resnet-50` | `RESNET_50` |
| ResNet-101 | `resnet-101` | `RESNET_101` |
| ResNet-152 | `resnet-152` | `RESNET_152` |
| VGG-16 | `vgg-16` | `VGG-16` |
| VGG-19 | `vgg-19` | `VGG-19` |
| Inception-v4 | `inception-v4` | `INCEPTION_V4` |
#### Object Detection
| Model | CLI argument | NetworkType enum | Object classes |
| ------------------------|--------------------|--------------------|----------------------|
| SSD-Mobilenet-v1 | `ssd-mobilenet-v1` | `SSD_MOBILENET_V1` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| SSD-Mobilenet-v2 | `ssd-mobilenet-v2` | `SSD_MOBILENET_V2` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| SSD-Inception-v2 | `ssd-inception-v2` | `SSD_INCEPTION_V2` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| TAO PeopleNet | `peoplenet` | `PEOPLENET` | person, bag, face |
| TAO PeopleNet (pruned) | `peoplenet-pruned` | `PEOPLENET_PRUNED` | person, bag, face |
| TAO DashCamNet | `dashcamnet` | `DASHCAMNET` | person, car, bike, sign |
| TAO TrafficCamNet | `trafficcamnet` | `TRAFFICCAMNET` | person, car, bike, sign |
| TAO FaceDetect | `facedetect` | `FACEDETECT` | face |
|
## API Reference
Below are links to reference documentation for the [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/index.html) and [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.html) libraries from the repo:
#### jetson-inference
| | [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__deepVision.html) | [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html) |
|--------------------|--------------|--------------|
| Image Recognition | [`imageNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__imageNet.html#classimageNet) | [`imageNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#imageNet) |
| Object Detection | [`detectNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__detectNet.html#classdetectNet) | [`detectNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#detectNet)
| Segmentation | [`segNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__segNet.html#classsegNet) | [`segNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#segNet) |
| Pose Estimation | [`poseNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__poseNet.html#classposeNet) | [`poseNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#poseNet) |
| Action Recognition | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__actionNet.html#classactionNet) | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#actionNet) |
| Background Removal | [`backgroundNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__backgroundNet.html#classbackgroundNet) | [`actionNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#backgroundNet) |
| Monocular Depth | [`depthNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__depthNet.html#classdepthNet) | [`depthNet`](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.inference.html#depthNet) |
#### jetson-utils
* [C++](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/group__util.html)
* [Python](https://rawgit.com/dusty-nv/jetson-inference/master/docs/html/python/jetson.utils.html)
These libraries are able to be used in external projects by linking to `libjetson-inference` and `libjetson-utils`.
## Code Examples
Introductory code walkthroughs of using the library are covered during these steps of the Hello AI World tutorial:
* [Coding Your Own Image Recognition Program (Python)](docs/imagenet-example-python-2.md)
* [Coding Your Own Image Recognition Program (C++)](docs/imagenet-example-2.md)
Additional C++ and Python samples for running the networks on images and live camera streams can be found here:
| | C++ | Python |
|-------------------|---------------------|---------------------|
| Image Recognition | [`imagenet.cpp`](examples/imagenet/imagenet.cpp) | [`imagenet.py`](python/examples/imagenet.py) |
| Object Detection | [`detectnet.cpp`](examples/detectnet/detectnet.cpp) | [`detectnet.py`](python/examples/detectnet.py) |
| Segmentation | [`segnet.cpp`](examples/segnet/segnet.cpp) | [`segnet.py`](python/examples/segnet.py) |
| Pose Estimation | [`posenet.cpp`](examples/posenet/posenet.cpp) | [`posenet.py`](python/examples/posenet.py) |
| Action Recognition | [`actionnet.cpp`](examples/actionnet/actionnet.cpp) | [`actionnet.py`](python/examples/actionnet.py) |
| Background Removal | [`backgroundnet.cpp`](examples/backgroundnet/backgroundnet.cpp) | [`backgroundnet.py`](python/examples/backgroundnet.py) |
| Monocular Depth | [`depthnet.cpp`](examples/depthnet/segnet.cpp) | [`depthnet.py`](python/examples/depthnet.py) |
> **note**: see the [Array Interfaces](docs/aux-image.md#array-interfaces) section for using memory with other Python libraries (like Numpy, PyTorch, ect)
These examples will automatically be compiled while [Building the Project from Source](docs/building-repo-2.md), and are able to run the pre-trained models listed below in addition to custom models provided by the user. Launch each example with `--help` for usage info.
## Pre-Trained Models
The project comes with a number of pre-trained models that are available to use and will be automatically downloaded:
#### Image Recognition
| Network | CLI argument | NetworkType enum |
| --------------|----------------|------------------|
| AlexNet | `alexnet` | `ALEXNET` |
| GoogleNet | `googlenet` | `GOOGLENET` |
| GoogleNet-12 | `googlenet-12` | `GOOGLENET_12` |
| ResNet-18 | `resnet-18` | `RESNET_18` |
| ResNet-50 | `resnet-50` | `RESNET_50` |
| ResNet-101 | `resnet-101` | `RESNET_101` |
| ResNet-152 | `resnet-152` | `RESNET_152` |
| VGG-16 | `vgg-16` | `VGG-16` |
| VGG-19 | `vgg-19` | `VGG-19` |
| Inception-v4 | `inception-v4` | `INCEPTION_V4` |
#### Object Detection
| Model | CLI argument | NetworkType enum | Object classes |
| ------------------------|--------------------|--------------------|----------------------|
| SSD-Mobilenet-v1 | `ssd-mobilenet-v1` | `SSD_MOBILENET_V1` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| SSD-Mobilenet-v2 | `ssd-mobilenet-v2` | `SSD_MOBILENET_V2` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| SSD-Inception-v2 | `ssd-inception-v2` | `SSD_INCEPTION_V2` | 91 ([COCO classes](../data/networks/ssd_coco_labels.txt)) |
| TAO PeopleNet | `peoplenet` | `PEOPLENET` | person, bag, face |
| TAO PeopleNet (pruned) | `peoplenet-pruned` | `PEOPLENET_PRUNED` | person, bag, face |
| TAO DashCamNet | `dashcamnet` | `DASHCAMNET` | person, car, bike, sign |
| TAO TrafficCamNet | `trafficcamnet` | `TRAFFICCAMNET` | person, car, bike, sign |
| TAO FaceDetect | `facedetect` | `FACEDETECT` | face |
Legacy Detection Models
| Model | CLI argument | NetworkType enum | Object classes |
| ------------------------|--------------------|--------------------|----------------------|
| DetectNet-COCO-Dog | `coco-dog` | `COCO_DOG` | dogs |
| DetectNet-COCO-Bottle | `coco-bottle` | `COCO_BOTTLE` | bottles |
| DetectNet-COCO-Chair | `coco-chair` | `COCO_CHAIR` | chairs |
| DetectNet-COCO-Airplane | `coco-airplane` | `COCO_AIRPLANE` | airplanes |
| ped-100 | `pednet` | `PEDNET` | pedestrians |
| multiped-500 | `multiped` | `PEDNET_MULTI` | pedestrians, luggage |
| facenet-120 | `facenet` | `FACENET` | faces |
#### Semantic Segmentation
| Dataset | Resolution | CLI Argument | Accuracy | Jetson Nano | Jetson Xavier |
|:------------:|:----------:|--------------|:--------:|:-----------:|:-------------:|
| [Cityscapes](https://www.cityscapes-dataset.com/) | 512x256 | `fcn-resnet18-cityscapes-512x256` | 83.3% | 48 FPS | 480 FPS |
| [Cityscapes](https://www.cityscapes-dataset.com/) | 1024x512 | `fcn-resnet18-cityscapes-1024x512` | 87.3% | 12 FPS | 175 FPS |
| [Cityscapes](https://www.cityscapes-dataset.com/) | 2048x1024 | `fcn-resnet18-cityscapes-2048x1024` | 89.6% | 3 FPS | 47 FPS |
| [DeepScene](http://deepscene.cs.uni-freiburg.de/) | 576x320 | `fcn-resnet18-deepscene-576x320` | 96.4% | 26 FPS | 360 FPS |
| [DeepScene](http://deepscene.cs.uni-freiburg.de/) | 864x480 | `fcn-resnet18-deepscene-864x480` | 96.9% | 14 FPS | 190 FPS |
| [Multi-Human](https://lv-mhp.github.io/) | 512x320 | `fcn-resnet18-mhp-512x320` | 86.5% | 34 FPS | 370 FPS |
| [Multi-Human](https://lv-mhp.github.io/) | 640x360 | `fcn-resnet18-mhp-512x320` | 87.1% | 23 FPS | 325 FPS |
| [Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC/) | 320x320 | `fcn-resnet18-voc-320x320` | 85.9% | 45 FPS | 508 FPS |
| [Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC/) | 512x320 | `fcn-resnet18-voc-512x320` | 88.5% | 34 FPS | 375 FPS |
| [SUN RGB-D](http://rgbd.cs.princeton.edu/) | 512x400 | `fcn-resnet18-sun-512x400` | 64.3% | 28 FPS | 340 FPS |
| [SUN RGB-D](http://rgbd.cs.princeton.edu/) | 640x512 | `fcn-resnet18-sun-640x512` | 65.1% | 17 FPS | 224 FPS |
* If the resolution is omitted from the CLI argument, the lowest resolution model is loaded
* Accuracy indicates the pixel classification accuracy across the model's validation dataset
* Performance is measured for GPU FP16 mode with JetPack 4.2.1, `nvpmodel 0` (MAX-N)
Legacy Segmentation Models
| Network | CLI Argument | NetworkType enum | Classes |
| ------------------------|---------------------------------|---------------------------------|---------|
| Cityscapes (2048x2048) | `fcn-alexnet-cityscapes-hd` | `FCN_ALEXNET_CITYSCAPES_HD` | 21 |
| Cityscapes (1024x1024) | `fcn-alexnet-cityscapes-sd` | `FCN_ALEXNET_CITYSCAPES_SD` | 21 |
| Pascal VOC (500x356) | `fcn-alexnet-pascal-voc` | `FCN_ALEXNET_PASCAL_VOC` | 21 |
| Synthia (CVPR16) | `fcn-alexnet-synthia-cvpr` | `FCN_ALEXNET_SYNTHIA_CVPR` | 14 |
| Synthia (Summer-HD) | `fcn-alexnet-synthia-summer-hd` | `FCN_ALEXNET_SYNTHIA_SUMMER_HD` | 14 |
| Synthia (Summer-SD) | `fcn-alexnet-synthia-summer-sd` | `FCN_ALEXNET_SYNTHIA_SUMMER_SD` | 14 |
| Aerial-FPV (1280x720) | `fcn-alexnet-aerial-fpv-720p` | `FCN_ALEXNET_AERIAL_FPV_720p` | 2 |
#### Pose Estimation
| Model | CLI argument | NetworkType enum | Keypoints |
| ------------------------|--------------------|--------------------|-----------|
| Pose-ResNet18-Body | `resnet18-body` | `RESNET18_BODY` | 18 |
| Pose-ResNet18-Hand | `resnet18-hand` | `RESNET18_HAND` | 21 |
| Pose-DenseNet121-Body | `densenet121-body` | `DENSENET121_BODY` | 18 |
#### Action Recognition
| Model | CLI argument | Classes |
| -------------------------|--------------|---------|
| Action-ResNet18-Kinetics | `resnet18` | 1040 |
| Action-ResNet34-Kinetics | `resnet34` | 1040 |
## Recommended System Requirements
* Jetson Nano Developer Kit with JetPack 4.2 or newer (Ubuntu 18.04 aarch64).
* Jetson Nano 2GB Developer Kit with JetPack 4.4.1 or newer (Ubuntu 18.04 aarch64).
* Jetson Orin Nano Developer Kit with JetPack 5.0 or newer (Ubuntu 20.04 aarch64).
* Jetson Xavier NX Developer Kit with JetPack 4.4 or newer (Ubuntu 18.04 aarch64).
* Jetson AGX Xavier Developer Kit with JetPack 4.0 or newer (Ubuntu 18.04 aarch64).
* Jetson AGX Orin Developer Kit with JetPack 5.0 or newer (Ubuntu 20.04 aarch64).
* Jetson TX2 Developer Kit with JetPack 3.0 or newer (Ubuntu 16.04 aarch64).
* Jetson TX1 Developer Kit with JetPack 2.3 or newer (Ubuntu 16.04 aarch64).
The [Transfer Learning with PyTorch](#training) section of the tutorial speaks from the perspective of running PyTorch onboard Jetson for training DNNs, however the same PyTorch code can be used on a PC, server, or cloud instance with an NVIDIA discrete GPU for faster training.
## Extra Resources
In this area, links and resources for deep learning are listed:
* [ros_deep_learning](http://www.github.com/dusty-nv/ros_deep_learning) - TensorRT inference ROS nodes
* [NVIDIA AI IoT](https://github.com/NVIDIA-AI-IOT) - NVIDIA Jetson GitHub repositories
* [Jetson eLinux Wiki](https://www.eLinux.org/Jetson) - Jetson eLinux Wiki
## Two Days to a Demo (DIGITS)
> **note:** the DIGITS/Caffe tutorial from below is deprecated. It's recommended to follow the [Transfer Learning with PyTorch](#training) tutorial from Hello AI World.
Expand this section to see original DIGITS tutorial (deprecated)
The DIGITS tutorial includes training DNN's in the cloud or PC, and inference on the Jetson with TensorRT, and can take roughly two days or more depending on system setup, downloading the datasets, and the training speed of your GPU.
* [DIGITS Workflow](docs/digits-workflow.md)
* [DIGITS System Setup](docs/digits-setup.md)
* [Setting up Jetson with JetPack](docs/jetpack-setup.md)
* [Building the Project from Source](docs/building-repo.md)
* [Classifying Images with ImageNet](docs/imagenet-console.md)
* [Using the Console Program on Jetson](docs/imagenet-console.md#using-the-console-program-on-jetson)
* [Coding Your Own Image Recognition Program](docs/imagenet-example.md)
* [Running the Live Camera Recognition Demo](docs/imagenet-camera.md)
* [Re-Training the Network with DIGITS](docs/imagenet-training.md)
* [Downloading Image Recognition Dataset](docs/imagenet-training.md#downloading-image-recognition-dataset)
* [Customizing the Object Classes](docs/imagenet-training.md#customizing-the-object-classes)
* [Importing Classification Dataset into DIGITS](docs/imagenet-training.md#importing-classification-dataset-into-digits)
* [Creating Image Classification Model with DIGITS](docs/imagenet-training.md#creating-image-classification-model-with-digits)
* [Testing Classification Model in DIGITS](docs/imagenet-training.md#testing-classification-model-in-digits)
* [Downloading Model Snapshot to Jetson](docs/imagenet-snapshot.md)
* [Loading Custom Models on Jetson](docs/imagenet-custom.md)
* [Locating Objects with DetectNet](docs/detectnet-training.md)
* [Detection Data Formatting in DIGITS](docs/detectnet-training.md#detection-data-formatting-in-digits)
* [Downloading the Detection Dataset](docs/detectnet-training.md#downloading-the-detection-dataset)
* [Importing the Detection Dataset into DIGITS](docs/detectnet-training.md#importing-the-detection-dataset-into-digits)
* [Creating DetectNet Model with DIGITS](docs/detectnet-training.md#creating-detectnet-model-with-digits)
* [Testing DetectNet Model Inference in DIGITS](docs/detectnet-training.md#testing-detectnet-model-inference-in-digits)
* [Downloading the Detection Model to Jetson](docs/detectnet-snapshot.md)
* [DetectNet Patches for TensorRT](docs/detectnet-snapshot.md#detectnet-patches-for-tensorrt)
* [Detecting Objects from the Command Line](docs/detectnet-console.md)
* [Multi-class Object Detection Models](docs/detectnet-console.md#multi-class-object-detection-models)
* [Running the Live Camera Detection Demo on Jetson](docs/detectnet-camera.md)
* [Semantic Segmentation with SegNet](docs/segnet-dataset.md)
* [Downloading Aerial Drone Dataset](docs/segnet-dataset.md#downloading-aerial-drone-dataset)
* [Importing the Aerial Dataset into DIGITS](docs/segnet-dataset.md#importing-the-aerial-dataset-into-digits)
* [Generating Pretrained FCN-Alexnet](docs/segnet-pretrained.md)
* [Training FCN-Alexnet with DIGITS](docs/segnet-training.md)
* [Testing Inference Model in DIGITS](docs/segnet-training.md#testing-inference-model-in-digits)
* [FCN-Alexnet Patches for TensorRT](docs/segnet-patches.md)
* [Running Segmentation Models on Jetson](docs/segnet-console.md)
##
© 2016-2019 NVIDIA | Table of Contents