{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Programming Exercise 5:\n",
"# Regularized Linear Regression and Bias vs Variance\n",
"\n",
"## Introduction\n",
"\n",
"In this exercise, you will implement regularized linear regression and use it to study models with different bias-variance properties. Before starting on the programming exercise, we strongly recommend watching the video lectures and completing the review questions for the associated topics.\n",
"\n",
"All the information you need for solving this assignment is in this notebook, and all the code you will be implementing will take place within this notebook. The assignment can be promptly submitted to the coursera grader directly from this notebook (code and instructions are included below).\n",
"\n",
"Before we begin with the exercises, we need to import all libraries required for this programming exercise. Throughout the course, we will be using [`numpy`](http://www.numpy.org/) for all arrays and matrix operations, [`matplotlib`](https://matplotlib.org/) for plotting, and [`scipy`](https://docs.scipy.org/doc/scipy/reference/) for scientific and numerical computation functions and tools. You can find instructions on how to install required libraries in the README file in the [github repository](https://github.com/dibgerge/ml-coursera-python-assignments)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# used for manipulating directory paths\n",
"import os\n",
"\n",
"# Scientific and vector computation for python\n",
"import numpy as np\n",
"\n",
"# Plotting library\n",
"from matplotlib import pyplot\n",
"\n",
"# Optimization module in scipy\n",
"from scipy import optimize\n",
"\n",
"# will be used to load MATLAB mat datafile format\n",
"from scipy.io import loadmat\n",
"\n",
"# library written for this exercise providing additional functions for assignment submission, and others\n",
"import utils\n",
"\n",
"# define the submission/grader object for this exercise\n",
"grader = utils.Grader()\n",
"\n",
"# tells matplotlib to embed plots within the notebook\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submission and Grading\n",
"\n",
"\n",
"After completing each part of the assignment, be sure to submit your solutions to the grader. The following is a breakdown of how each part of this exercise is scored.\n",
"\n",
"\n",
"| Section | Part | Submitted Function | Points |\n",
"| :- |:- |:- | :-: |\n",
"| 1 | [Regularized Linear Regression Cost Function](#section1) | [`linearRegCostFunction`](#linearRegCostFunction) | 25 |\n",
"| 2 | [Regularized Linear Regression Gradient](#section2) | [`linearRegCostFunction`](#linearRegCostFunction) |25 |\n",
"| 3 | [Learning Curve](#section3) | [`learningCurve`](#func2) | 20 |\n",
"| 4 | [Polynomial Feature Mapping](#section4) | [`polyFeatures`](#polyFeatures) | 10 |\n",
"| 5 | [Cross Validation Curve](#section5) | [`validationCurve`](#validationCurve) | 20 |\n",
"| | Total Points | |100 |\n",
"\n",
"\n",
"You are allowed to submit your solutions multiple times, and we will take only the highest score into consideration.\n",
"\n",
"\n",
"At the end of each section in this notebook, we have a cell which contains code for submitting the solutions thus far to the grader. Execute the cell to see your score up to the current section. For all your work to be submitted properly, you must execute those cells at least once.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## 1 Regularized Linear Regression\n",
"\n",
"In the first half of the exercise, you will implement regularized linear regression to predict the amount of water flowing out of a dam using the change of water level in a reservoir. In the next half, you will go through some diagnostics of debugging learning algorithms and examine the effects of bias v.s.\n",
"variance. \n",
"\n",
"### 1.1 Visualizing the dataset\n",
"\n",
"We will begin by visualizing the dataset containing historical records on the change in the water level, $x$, and the amount of water flowing out of the dam, $y$. This dataset is divided into three parts:\n",
"\n",
"- A **training** set that your model will learn on: `X`, `y`\n",
"- A **cross validation** set for determining the regularization parameter: `Xval`, `yval`\n",
"- A **test** set for evaluating performance. These are “unseen” examples which your model did not see during training: `Xtest`, `ytest`\n",
"\n",
"Run the next cell to plot the training data. In the following parts, you will implement linear regression and use that to fit a straight line to the data and plot learning curves. Following that, you will implement polynomial regression to find a better fit to the data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Load from ex5data1.mat, where all variables will be store in a dictionary\n",
"data = loadmat(os.path.join('Data', 'ex5data1.mat'))\n",
"\n",
"# Extract train, test, validation data from dictionary\n",
"# and also convert y's form 2-D matrix (MATLAB format) to a numpy vector\n",
"X, y = data['X'], data['y'][:, 0]\n",
"Xtest, ytest = data['Xtest'], data['ytest'][:, 0]\n",
"Xval, yval = data['Xval'], data['yval'][:, 0]\n",
"\n",
"# m = Number of examples\n",
"m = y.size\n",
"\n",
"# Plot training data\n",
"pyplot.plot(X, y, 'ro', ms=10, mec='k', mew=1)\n",
"pyplot.xlabel('Change in water level (x)')\n",
"pyplot.ylabel('Water flowing out of the dam (y)');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.2 Regularized linear regression cost function\n",
"\n",
"Recall that regularized linear regression has the following cost function:\n",
"\n",
"$$ J(\\theta) = \\frac{1}{2m} \\left( \\sum_{i=1}^m \\left( h_\\theta\\left( x^{(i)} \\right) - y^{(i)} \\right)^2 \\right) + \\frac{\\lambda}{2m} \\left( \\sum_{j=1}^n \\theta_j^2 \\right)$$\n",
"\n",
"where $\\lambda$ is a regularization parameter which controls the degree of regularization (thus, help preventing overfitting). The regularization term puts a penalty on the overall cost J. As the magnitudes of the model parameters $\\theta_j$ increase, the penalty increases as well. Note that you should not regularize\n",
"the $\\theta_0$ term.\n",
"\n",
"You should now complete the code in the function `linearRegCostFunction` in the next cell. Your task is to calculate the regularized linear regression cost function. If possible, try to vectorize your code and avoid writing loops.\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def linearRegCostFunction(X, y, theta, lambda_=0.0):\n",
" \"\"\"\n",
" Compute cost and gradient for regularized linear regression \n",
" with multiple variables. Computes the cost of using theta as\n",
" the parameter for linear regression to fit the data points in X and y. \n",
" \n",
" Parameters\n",
" ----------\n",
" X : array_like\n",
" The dataset. Matrix with shape (m x n + 1) where m is the \n",
" total number of examples, and n is the number of features \n",
" before adding the bias term.\n",
" \n",
" y : array_like\n",
" The functions values at each datapoint. A vector of\n",
" shape (m, ).\n",
" \n",
" theta : array_like\n",
" The parameters for linear regression. A vector of shape (n+1,).\n",
" \n",
" lambda_ : float, optional\n",
" The regularization parameter.\n",
" \n",
" Returns\n",
" -------\n",
" J : float\n",
" The computed cost function. \n",
" \n",
" grad : array_like\n",
" The value of the cost function gradient w.r.t theta. \n",
" A vector of shape (n+1, ).\n",
" \n",
" Instructions\n",
" ------------\n",
" Compute the cost and gradient of regularized linear regression for\n",
" a particular choice of theta.\n",
" You should set J to the cost and grad to the gradient.\n",
" \"\"\"\n",
" # Initialize some useful values\n",
" m = y.size # number of training examples\n",
"\n",
" # You need to return the following variables correctly \n",
" J = 0\n",
" grad = np.zeros(theta.shape)\n",
"\n",
" # ====================== YOUR CODE HERE ======================\n",
"\n",
"\n",
"\n",
" # ============================================================\n",
" return J, grad"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"When you are finished, the next cell will run your cost function using `theta` initialized at `[1, 1]`. You should expect to see an output of 303.993."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"theta = np.array([1, 1])\n",
"J, _ = linearRegCostFunction(np.concatenate([np.ones((m, 1)), X], axis=1), y, theta, 1)\n",
"\n",
"print('Cost at theta = [1, 1]:\\t %f ' % J)\n",
"print('This value should be about 303.993192)\\n' % J)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After completing a part of the exercise, you can submit your solutions for grading by first adding the function you modified to the submission object, and then sending your function to Coursera for grading. \n",
"\n",
"The submission script will prompt you for your login e-mail and submission token. You can obtain a submission token from the web page for the assignment. You are allowed to submit your solutions multiple times, and we will take only the highest score into consideration.\n",
"\n",
"*Execute the following cell to grade your solution to the first part of this exercise.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"grader[1] = linearRegCostFunction\n",
"grader.grade()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### 1.3 Regularized linear regression gradient\n",
"\n",
"Correspondingly, the partial derivative of the cost function for regularized linear regression is defined as:\n",
"\n",
"$$\n",
"\\begin{align}\n",
"& \\frac{\\partial J(\\theta)}{\\partial \\theta_0} = \\frac{1}{m} \\sum_{i=1}^m \\left( h_\\theta \\left(x^{(i)} \\right) - y^{(i)} \\right) x_j^{(i)} & \\qquad \\text{for } j = 0 \\\\\n",
"& \\frac{\\partial J(\\theta)}{\\partial \\theta_j} = \\left( \\frac{1}{m} \\sum_{i=1}^m \\left( h_\\theta \\left( x^{(i)} \\right) - y^{(i)} \\right) x_j^{(i)} \\right) + \\frac{\\lambda}{m} \\theta_j & \\qquad \\text{for } j \\ge 1\n",
"\\end{align}\n",
"$$\n",
"\n",
"In the function [`linearRegCostFunction`](#linearRegCostFunction) above, add code to calculate the gradient, returning it in the variable `grad`. Do not forget to re-execute the cell containing this function to update the function's definition.\n",
"\n",
"\n",
"When you are finished, use the next cell to run your gradient function using theta initialized at `[1, 1]`. You should expect to see a gradient of `[-15.30, 598.250]`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"theta = np.array([1, 1])\n",
"J, grad = linearRegCostFunction(np.concatenate([np.ones((m, 1)), X], axis=1), y, theta, 1)\n",
"\n",
"print('Gradient at theta = [1, 1]: [{:.6f}, {:.6f}] '.format(*grad))\n",
"print(' (this value should be about [-15.303016, 598.250744])\\n')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*You should now submit your solutions.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"grader[2] = linearRegCostFunction\n",
"grader.grade()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Fitting linear regression\n",
"\n",
"Once your cost function and gradient are working correctly, the next cell will run the code in `trainLinearReg` (found in the module `utils.py`) to compute the optimal values of $\\theta$. This training function uses `scipy`'s optimization module to minimize the cost function.\n",
"\n",
"In this part, we set regularization parameter $\\lambda$ to zero. Because our current implementation of linear regression is trying to fit a 2-dimensional $\\theta$, regularization will not be incredibly helpful for a $\\theta$ of such low dimension. In the later parts of the exercise, you will be using polynomial regression with regularization.\n",
"\n",
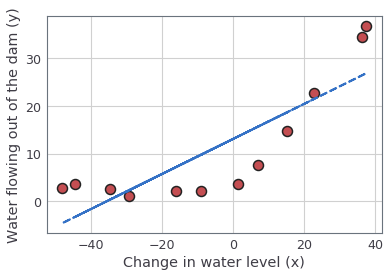
"Finally, the code in the next cell should also plot the best fit line, which should look like the figure below. \n",
"\n",
"\n",
"\n",
"The best fit line tells us that the model is not a good fit to the data because the data has a non-linear pattern. While visualizing the best fit as shown is one possible way to debug your learning algorithm, it is not always easy to visualize the data and model. In the next section, you will implement a function to generate learning curves that can help you debug your learning algorithm even if it is not easy to visualize the\n",
"data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# add a columns of ones for the y-intercept\n",
"X_aug = np.concatenate([np.ones((m, 1)), X], axis=1)\n",
"theta = utils.trainLinearReg(linearRegCostFunction, X_aug, y, lambda_=0)\n",
"\n",
"# Plot fit over the data\n",
"pyplot.plot(X, y, 'ro', ms=10, mec='k', mew=1.5)\n",
"pyplot.xlabel('Change in water level (x)')\n",
"pyplot.ylabel('Water flowing out of the dam (y)')\n",
"pyplot.plot(X, np.dot(X_aug, theta), '--', lw=2);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## 2 Bias-variance\n",
"\n",
"An important concept in machine learning is the bias-variance tradeoff. Models with high bias are not complex enough for the data and tend to underfit, while models with high variance overfit to the training data.\n",
"\n",
"In this part of the exercise, you will plot training and test errors on a learning curve to diagnose bias-variance problems.\n",
"\n",
"### 2.1 Learning Curves\n",
"\n",
"You will now implement code to generate the learning curves that will be useful in debugging learning algorithms. Recall that a learning curve plots training and cross validation error as a function of training set size. Your job is to fill in the function `learningCurve` in the next cell, so that it returns a vector of errors for the training set and cross validation set.\n",
"\n",
"To plot the learning curve, we need a training and cross validation set error for different training set sizes. To obtain different training set sizes, you should use different subsets of the original training set `X`. Specifically, for a training set size of $i$, you should use the first $i$ examples (i.e., `X[:i, :]`\n",
"and `y[:i]`).\n",
"\n",
"You can use the `trainLinearReg` function (by calling `utils.trainLinearReg(...)`) to find the $\\theta$ parameters. Note that the `lambda_` is passed as a parameter to the `learningCurve` function.\n",
"After learning the $\\theta$ parameters, you should compute the error on the training and cross validation sets. Recall that the training error for a dataset is defined as\n",
"\n",
"$$ J_{\\text{train}} = \\frac{1}{2m} \\left[ \\sum_{i=1}^m \\left(h_\\theta \\left( x^{(i)} \\right) - y^{(i)} \\right)^2 \\right] $$\n",
"\n",
"In particular, note that the training error does not include the regularization term. One way to compute the training error is to use your existing cost function and set $\\lambda$ to 0 only when using it to compute the training error and cross validation error. When you are computing the training set error, make sure you compute it on the training subset (i.e., `X[:n,:]` and `y[:n]`) instead of the entire training set. However, for the cross validation error, you should compute it over the entire cross validation set. You should store\n",
"the computed errors in the vectors error train and error val.\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def learningCurve(X, y, Xval, yval, lambda_=0):\n",
" \"\"\"\n",
" Generates the train and cross validation set errors needed to plot a learning curve\n",
" returns the train and cross validation set errors for a learning curve. \n",
" \n",
" In this function, you will compute the train and test errors for\n",
" dataset sizes from 1 up to m. In practice, when working with larger\n",
" datasets, you might want to do this in larger intervals.\n",
" \n",
" Parameters\n",
" ----------\n",
" X : array_like\n",
" The training dataset. Matrix with shape (m x n + 1) where m is the \n",
" total number of examples, and n is the number of features \n",
" before adding the bias term.\n",
" \n",
" y : array_like\n",
" The functions values at each training datapoint. A vector of\n",
" shape (m, ).\n",
" \n",
" Xval : array_like\n",
" The validation dataset. Matrix with shape (m_val x n + 1) where m is the \n",
" total number of examples, and n is the number of features \n",
" before adding the bias term.\n",
" \n",
" yval : array_like\n",
" The functions values at each validation datapoint. A vector of\n",
" shape (m_val, ).\n",
" \n",
" lambda_ : float, optional\n",
" The regularization parameter.\n",
" \n",
" Returns\n",
" -------\n",
" error_train : array_like\n",
" A vector of shape m. error_train[i] contains the training error for\n",
" i examples.\n",
" error_val : array_like\n",
" A vecotr of shape m. error_val[i] contains the validation error for\n",
" i training examples.\n",
" \n",
" Instructions\n",
" ------------\n",
" Fill in this function to return training errors in error_train and the\n",
" cross validation errors in error_val. i.e., error_train[i] and \n",
" error_val[i] should give you the errors obtained after training on i examples.\n",
" \n",
" Notes\n",
" -----\n",
" - You should evaluate the training error on the first i training\n",
" examples (i.e., X[:i, :] and y[:i]).\n",
" \n",
" For the cross-validation error, you should instead evaluate on\n",
" the _entire_ cross validation set (Xval and yval).\n",
" \n",
" - If you are using your cost function (linearRegCostFunction) to compute\n",
" the training and cross validation error, you should call the function with\n",
" the lambda argument set to 0. Do note that you will still need to use\n",
" lambda when running the training to obtain the theta parameters.\n",
" \n",
" Hint\n",
" ----\n",
" You can loop over the examples with the following:\n",
" \n",
" for i in range(1, m+1):\n",
" # Compute train/cross validation errors using training examples \n",
" # X[:i, :] and y[:i], storing the result in \n",
" # error_train[i-1] and error_val[i-1]\n",
" .... \n",
" \"\"\"\n",
" # Number of training examples\n",
" m = y.size\n",
"\n",
" # You need to return these values correctly\n",
" error_train = np.zeros(m)\n",
" error_val = np.zeros(m)\n",
"\n",
" # ====================== YOUR CODE HERE ======================\n",
" \n",
"\n",
" \n",
" # =============================================================\n",
" return error_train, error_val"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
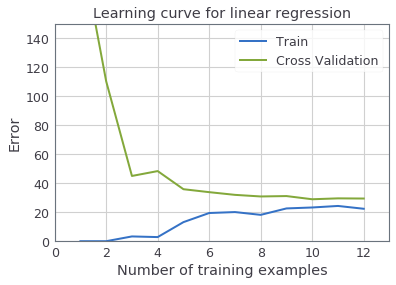
"When you are finished implementing the function `learningCurve`, executing the next cell prints the learning curves and produce a plot similar to the figure below. \n",
"\n",
"\n",
"\n",
"In the learning curve figure, you can observe that both the train error and cross validation error are high when the number of training examples is increased. This reflects a high bias problem in the model - the linear regression model is too simple and is unable to fit our dataset well. In the next section, you will implement polynomial regression to fit a better model for this dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"X_aug = np.concatenate([np.ones((m, 1)), X], axis=1)\n",
"Xval_aug = np.concatenate([np.ones((yval.size, 1)), Xval], axis=1)\n",
"error_train, error_val = learningCurve(X_aug, y, Xval_aug, yval, lambda_=0)\n",
"\n",
"pyplot.plot(np.arange(1, m+1), error_train, np.arange(1, m+1), error_val, lw=2)\n",
"pyplot.title('Learning curve for linear regression')\n",
"pyplot.legend(['Train', 'Cross Validation'])\n",
"pyplot.xlabel('Number of training examples')\n",
"pyplot.ylabel('Error')\n",
"pyplot.axis([0, 13, 0, 150])\n",
"\n",
"print('# Training Examples\\tTrain Error\\tCross Validation Error')\n",
"for i in range(m):\n",
" print(' \\t%d\\t\\t%f\\t%f' % (i+1, error_train[i], error_val[i]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*You should now submit your solutions.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"grader[3] = learningCurve\n",
"grader.grade()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"## 3 Polynomial regression\n",
"\n",
"The problem with our linear model was that it was too simple for the data\n",
"and resulted in underfitting (high bias). In this part of the exercise, you will address this problem by adding more features. For polynomial regression, our hypothesis has the form:\n",
"\n",
"$$\n",
"\\begin{align}\n",
"h_\\theta(x) &= \\theta_0 + \\theta_1 \\times (\\text{waterLevel}) + \\theta_2 \\times (\\text{waterLevel})^2 + \\cdots + \\theta_p \\times (\\text{waterLevel})^p \\\\\n",
"& = \\theta_0 + \\theta_1 x_1 + \\theta_2 x_2 + \\cdots + \\theta_p x_p\n",
"\\end{align}\n",
"$$\n",
"\n",
"Notice that by defining $x_1 = (\\text{waterLevel})$, $x_2 = (\\text{waterLevel})^2$ , $\\cdots$, $x_p =\n",
"(\\text{waterLevel})^p$, we obtain a linear regression model where the features are the various powers of the original value (waterLevel).\n",
"\n",
"Now, you will add more features using the higher powers of the existing feature $x$ in the dataset. Your task in this part is to complete the code in the function `polyFeatures` in the next cell. The function should map the original training set $X$ of size $m \\times 1$ into its higher powers. Specifically, when a training set $X$ of size $m \\times 1$ is passed into the function, the function should return a $m \\times p$ matrix `X_poly`, where column 1 holds the original values of X, column 2 holds the values of $X^2$, column 3 holds the values of $X^3$, and so on. Note that you don’t have to account for the zero-eth power in this function.\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def polyFeatures(X, p):\n",
" \"\"\"\n",
" Maps X (1D vector) into the p-th power.\n",
" \n",
" Parameters\n",
" ----------\n",
" X : array_like\n",
" A data vector of size m, where m is the number of examples.\n",
" \n",
" p : int\n",
" The polynomial power to map the features. \n",
" \n",
" Returns \n",
" -------\n",
" X_poly : array_like\n",
" A matrix of shape (m x p) where p is the polynomial \n",
" power and m is the number of examples. That is:\n",
" \n",
" X_poly[i, :] = [X[i], X[i]**2, X[i]**3 ... X[i]**p]\n",
" \n",
" Instructions\n",
" ------------\n",
" Given a vector X, return a matrix X_poly where the p-th column of\n",
" X contains the values of X to the p-th power.\n",
" \"\"\"\n",
" # You need to return the following variables correctly.\n",
" X_poly = np.zeros((X.shape[0], p))\n",
"\n",
" # ====================== YOUR CODE HERE ======================\n",
"\n",
"\n",
"\n",
" # ============================================================\n",
" return X_poly"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now you have a function that will map features to a higher dimension. The next cell will apply it to the training set, the test set, and the cross validation set."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"p = 8\n",
"\n",
"# Map X onto Polynomial Features and Normalize\n",
"X_poly = polyFeatures(X, p)\n",
"X_poly, mu, sigma = utils.featureNormalize(X_poly)\n",
"X_poly = np.concatenate([np.ones((m, 1)), X_poly], axis=1)\n",
"\n",
"# Map X_poly_test and normalize (using mu and sigma)\n",
"X_poly_test = polyFeatures(Xtest, p)\n",
"X_poly_test -= mu\n",
"X_poly_test /= sigma\n",
"X_poly_test = np.concatenate([np.ones((ytest.size, 1)), X_poly_test], axis=1)\n",
"\n",
"# Map X_poly_val and normalize (using mu and sigma)\n",
"X_poly_val = polyFeatures(Xval, p)\n",
"X_poly_val -= mu\n",
"X_poly_val /= sigma\n",
"X_poly_val = np.concatenate([np.ones((yval.size, 1)), X_poly_val], axis=1)\n",
"\n",
"print('Normalized Training Example 1:')\n",
"X_poly[0, :]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*You should now submit your solutions.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"grader[4] = polyFeatures\n",
"grader.grade()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.1 Learning Polynomial Regression\n",
"\n",
"After you have completed the function `polyFeatures`, we will proceed to train polynomial regression using your linear regression cost function.\n",
"\n",
"Keep in mind that even though we have polynomial terms in our feature vector, we are still solving a linear regression optimization problem. The polynomial terms have simply turned into features that we can use for linear regression. We are using the same cost function and gradient that you wrote for the earlier part of this exercise.\n",
"\n",
"For this part of the exercise, you will be using a polynomial of degree 8. It turns out that if we run the training directly on the projected data, will not work well as the features would be badly scaled (e.g., an example with $x = 40$ will now have a feature $x_8 = 40^8 = 6.5 \\times 10^{12}$). Therefore, you will\n",
"need to use feature normalization.\n",
"\n",
"Before learning the parameters $\\theta$ for the polynomial regression, we first call `featureNormalize` and normalize the features of the training set, storing the mu, sigma parameters separately. We have already implemented this function for you (in `utils.py` module) and it is the same function from the first exercise.\n",
"\n",
"After learning the parameters $\\theta$, you should see two plots generated for polynomial regression with $\\lambda = 0$, which should be similar to the ones here:\n",
"\n",
"\n",
" \n",
"  | \n",
"  | \n",
"
\n",
"
\n",
"\n",
"You should see that the polynomial fit is able to follow the datapoints very well, thus, obtaining a low training error. The figure on the right shows that the training error essentially stays zero for all numbers of training samples. However, the polynomial fit is very complex and even drops off at the extremes. This is an indicator that the polynomial regression model is overfitting the training data and will not generalize well.\n",
"\n",
"To better understand the problems with the unregularized ($\\lambda = 0$) model, you can see that the learning curve shows the same effect where the training error is low, but the cross validation error is high. There is a gap between the training and cross validation errors, indicating a high variance problem."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"lambda_ = 0\n",
"theta = utils.trainLinearReg(linearRegCostFunction, X_poly, y,\n",
" lambda_=lambda_, maxiter=55)\n",
"\n",
"# Plot training data and fit\n",
"pyplot.plot(X, y, 'ro', ms=10, mew=1.5, mec='k')\n",
"\n",
"utils.plotFit(polyFeatures, np.min(X), np.max(X), mu, sigma, theta, p)\n",
"\n",
"pyplot.xlabel('Change in water level (x)')\n",
"pyplot.ylabel('Water flowing out of the dam (y)')\n",
"pyplot.title('Polynomial Regression Fit (lambda = %f)' % lambda_)\n",
"pyplot.ylim([-20, 50])\n",
"\n",
"pyplot.figure()\n",
"error_train, error_val = learningCurve(X_poly, y, X_poly_val, yval, lambda_)\n",
"pyplot.plot(np.arange(1, 1+m), error_train, np.arange(1, 1+m), error_val)\n",
"\n",
"pyplot.title('Polynomial Regression Learning Curve (lambda = %f)' % lambda_)\n",
"pyplot.xlabel('Number of training examples')\n",
"pyplot.ylabel('Error')\n",
"pyplot.axis([0, 13, 0, 100])\n",
"pyplot.legend(['Train', 'Cross Validation'])\n",
"\n",
"print('Polynomial Regression (lambda = %f)\\n' % lambda_)\n",
"print('# Training Examples\\tTrain Error\\tCross Validation Error')\n",
"for i in range(m):\n",
" print(' \\t%d\\t\\t%f\\t%f' % (i+1, error_train[i], error_val[i]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"One way to combat the overfitting (high-variance) problem is to add regularization to the model. In the next section, you will get to try different $\\lambda$ parameters to see how regularization can lead to a better model.\n",
"\n",
"### 3.2 Optional (ungraded) exercise: Adjusting the regularization parameter\n",
"\n",
"In this section, you will get to observe how the regularization parameter affects the bias-variance of regularized polynomial regression. You should now modify the the lambda parameter and try $\\lambda = 1, 100$. For each of these values, the script should generate a polynomial fit to the data and also a learning curve.\n",
"\n",
"For $\\lambda = 1$, the generated plots should look like the the figure below. You should see a polynomial fit that follows the data trend well (left) and a learning curve (right) showing that both the cross validation and training error converge to a relatively low value. This shows the $\\lambda = 1$ regularized polynomial regression model does not have the high-bias or high-variance problems. In effect, it achieves a good trade-off between bias and variance.\n",
"\n",
"\n",
" \n",
"  | \n",
"  | \n",
"
\n",
"
\n",
"\n",
"For $\\lambda = 100$, you should see a polynomial fit (figure below) that does not follow the data well. In this case, there is too much regularization and the model is unable to fit the training data.\n",
"\n",
"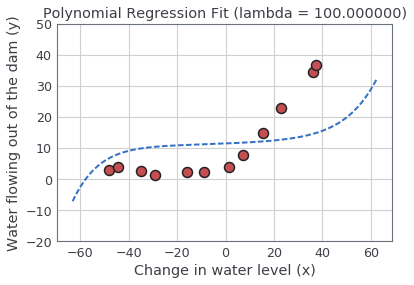\n",
"\n",
"*You do not need to submit any solutions for this optional (ungraded) exercise.*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### 3.3 Selecting $\\lambda$ using a cross validation set\n",
"\n",
"From the previous parts of the exercise, you observed that the value of $\\lambda$ can significantly affect the results of regularized polynomial regression on the training and cross validation set. In particular, a model without regularization ($\\lambda = 0$) fits the training set well, but does not generalize. Conversely, a model with too much regularization ($\\lambda = 100$) does not fit the training set and testing set well. A good choice of $\\lambda$ (e.g., $\\lambda = 1$) can provide a good fit to the data.\n",
"\n",
"In this section, you will implement an automated method to select the $\\lambda$ parameter. Concretely, you will use a cross validation set to evaluate how good each $\\lambda$ value is. After selecting the best $\\lambda$ value using the cross validation set, we can then evaluate the model on the test set to estimate\n",
"how well the model will perform on actual unseen data. \n",
"\n",
"Your task is to complete the code in the function `validationCurve`. Specifically, you should should use the `utils.trainLinearReg` function to train the model using different values of $\\lambda$ and compute the training error and cross validation error. You should try $\\lambda$ in the following range: {0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10}.\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def validationCurve(X, y, Xval, yval):\n",
" \"\"\"\n",
" Generate the train and validation errors needed to plot a validation\n",
" curve that we can use to select lambda_.\n",
" \n",
" Parameters\n",
" ----------\n",
" X : array_like\n",
" The training dataset. Matrix with shape (m x n) where m is the \n",
" total number of training examples, and n is the number of features \n",
" including any polynomial features.\n",
" \n",
" y : array_like\n",
" The functions values at each training datapoint. A vector of\n",
" shape (m, ).\n",
" \n",
" Xval : array_like\n",
" The validation dataset. Matrix with shape (m_val x n) where m is the \n",
" total number of validation examples, and n is the number of features \n",
" including any polynomial features.\n",
" \n",
" yval : array_like\n",
" The functions values at each validation datapoint. A vector of\n",
" shape (m_val, ).\n",
" \n",
" Returns\n",
" -------\n",
" lambda_vec : list\n",
" The values of the regularization parameters which were used in \n",
" cross validation.\n",
" \n",
" error_train : list\n",
" The training error computed at each value for the regularization\n",
" parameter.\n",
" \n",
" error_val : list\n",
" The validation error computed at each value for the regularization\n",
" parameter.\n",
" \n",
" Instructions\n",
" ------------\n",
" Fill in this function to return training errors in `error_train` and\n",
" the validation errors in `error_val`. The vector `lambda_vec` contains\n",
" the different lambda parameters to use for each calculation of the\n",
" errors, i.e, `error_train[i]`, and `error_val[i]` should give you the\n",
" errors obtained after training with `lambda_ = lambda_vec[i]`.\n",
"\n",
" Note\n",
" ----\n",
" You can loop over lambda_vec with the following:\n",
" \n",
" for i in range(len(lambda_vec))\n",
" lambda = lambda_vec[i]\n",
" # Compute train / val errors when training linear \n",
" # regression with regularization parameter lambda_\n",
" # You should store the result in error_train[i]\n",
" # and error_val[i]\n",
" ....\n",
" \"\"\"\n",
" # Selected values of lambda (you should not change this)\n",
" lambda_vec = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]\n",
"\n",
" # You need to return these variables correctly.\n",
" error_train = np.zeros(len(lambda_vec))\n",
" error_val = np.zeros(len(lambda_vec))\n",
"\n",
" # ====================== YOUR CODE HERE ======================\n",
"\n",
"\n",
"\n",
" # ============================================================\n",
" return lambda_vec, error_train, error_val"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
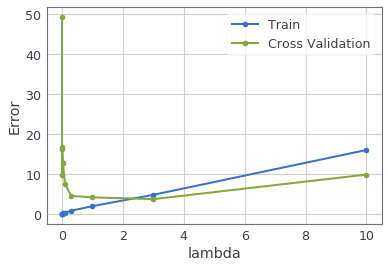
"After you have completed the code, the next cell will run your function and plot a cross validation curve of error v.s. $\\lambda$ that allows you select which $\\lambda$ parameter to use. You should see a plot similar to the figure below. \n",
"\n",
"\n",
"\n",
"In this figure, we can see that the best value of $\\lambda$ is around 3. Due to randomness\n",
"in the training and validation splits of the dataset, the cross validation error can sometimes be lower than the training error."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"lambda_vec, error_train, error_val = validationCurve(X_poly, y, X_poly_val, yval)\n",
"\n",
"pyplot.plot(lambda_vec, error_train, '-o', lambda_vec, error_val, '-o', lw=2)\n",
"pyplot.legend(['Train', 'Cross Validation'])\n",
"pyplot.xlabel('lambda')\n",
"pyplot.ylabel('Error')\n",
"\n",
"print('lambda\\t\\tTrain Error\\tValidation Error')\n",
"for i in range(len(lambda_vec)):\n",
" print(' %f\\t%f\\t%f' % (lambda_vec[i], error_train[i], error_val[i]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*You should now submit your solutions.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"grader[5] = validationCurve\n",
"grader.grade()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.4 Optional (ungraded) exercise: Computing test set error\n",
"\n",
"In the previous part of the exercise, you implemented code to compute the cross validation error for various values of the regularization parameter $\\lambda$. However, to get a better indication of the model’s performance in the real world, it is important to evaluate the “final” model on a test set that was not used in any part of training (that is, it was neither used to select the $\\lambda$ parameters, nor to learn the model parameters $\\theta$). For this optional (ungraded) exercise, you should compute the test error using the best value of $\\lambda$ you found. In our cross validation, we obtained a test error of 3.8599 for $\\lambda = 3$.\n",
"\n",
"*You do not need to submit any solutions for this optional (ungraded) exercise.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.5 Optional (ungraded) exercise: Plotting learning curves with randomly selected examples\n",
"\n",
"In practice, especially for small training sets, when you plot learning curves to debug your algorithms, it is often helpful to average across multiple sets of randomly selected examples to determine the training error and cross validation error.\n",
"\n",
"Concretely, to determine the training error and cross validation error for $i$ examples, you should first randomly select $i$ examples from the training set and $i$ examples from the cross validation set. You will then learn the parameters $\\theta$ using the randomly chosen training set and evaluate the parameters $\\theta$ on the randomly chosen training set and cross validation set. The above steps should then be repeated multiple times (say 50) and the averaged error should be used to determine the training error and cross validation error for $i$ examples.\n",
"\n",
"For this optional (ungraded) exercise, you should implement the above strategy for computing the learning curves. For reference, the figure below shows the learning curve we obtained for polynomial regression with $\\lambda = 0.01$. Your figure may differ slightly due to the random selection of examples.\n",
"\n",
"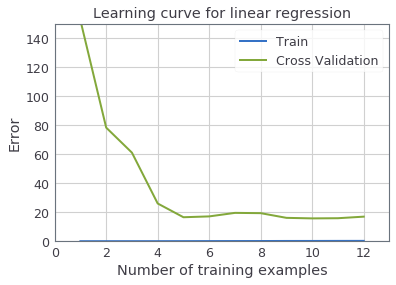\n",
"\n",
"*You do not need to submit any solutions for this optional (ungraded) exercise.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}