{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| include: false\n",
"! [ -e /content ] && pip install -Uqq fastbook\n",
"import fastbook\n",
"fastbook.setup_book()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| include: false\n",
"from fastbook import *"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# A Language Model from Scratch {#sec-nlp-dive}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We're now ready to go deep... deep into deep learning! You already learned how to train a basic neural network, but how do you go from there to creating state-of-the-art models? In this part of the book we're going to uncover all of the mysteries, starting with language models.\n",
"\n",
"You saw in @sec-nlp how to fine-tune a pretrained language model to build a text classifier. In this chapter, we will explain to you what exactly is inside that model, and what an RNN is. First, let's gather some data that will allow us to quickly prototype our various models. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The Data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Whenever we start working on a new problem, we always first try to think of the simplest dataset we can that will allow us to try out methods quickly and easily, and interpret the results. When we started working on language modeling a few years ago we didn't find any datasets that would allow for quick prototyping, so we made one. We call it *Human Numbers*, and it simply contains the first 10,000 numbers written out in English."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> j: One of the most common practical mistakes I see even amongst highly experienced practitioners is failing to use appropriate datasets at appropriate times during the analysis process. In particular, most people tend to start with datasets that are too big and too complicated."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can download, extract, and take a look at our dataset in the usual way:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from fastai.text.all import *\n",
"path = untar_data(URLs.HUMAN_NUMBERS)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| include: false\n",
"Path.BASE_PATH = path"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#2) [Path('train.txt'),Path('valid.txt')]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"path.ls()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's open those two files and see what's inside. At first we'll join all of the texts together and ignore the train/valid split given by the dataset (we'll come back to that later):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#9998) ['one \\n','two \\n','three \\n','four \\n','five \\n','six \\n','seven \\n','eight \\n','nine \\n','ten \\n'...]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"lines = L()\n",
"with open(path/'train.txt') as f: lines += L(*f.readlines())\n",
"with open(path/'valid.txt') as f: lines += L(*f.readlines())\n",
"lines"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We take all those lines and concatenate them in one big stream. To mark when we go from one number to the next, we use a `.` as a separator:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'one . two . three . four . five . six . seven . eight . nine . ten . eleven . twelve . thirteen . fo'"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"text = ' . '.join([l.strip() for l in lines])\n",
"text[:100]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can tokenize this dataset by splitting on spaces:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"['one', '.', 'two', '.', 'three', '.', 'four', '.', 'five', '.']"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"tokens = text.split(' ')\n",
"tokens[:10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To numericalize, we have to create a list of all the unique tokens (our *vocab*):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#30) ['one','.','two','three','four','five','six','seven','eight','nine'...]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"vocab = L(*tokens).unique()\n",
"vocab"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then we can convert our tokens into numbers by looking up the index of each in the vocab:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#63095) [0,1,2,1,3,1,4,1,5,1...]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"word2idx = {w:i for i,w in enumerate(vocab)}\n",
"nums = L(word2idx[i] for i in tokens)\n",
"nums"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that we have a small dataset on which language modeling should be an easy task, we can build our first model."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Our First Language Model from Scratch"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"One simple way to turn this into a neural network would be to specify that we are going to predict each word based on the previous three words. We could create a list of every sequence of three words as our independent variables, and the next word after each sequence as the dependent variable. \n",
"\n",
"We can do that with plain Python. Let's do it first with tokens just to confirm what it looks like:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#21031) [(['one', '.', 'two'], '.'),(['.', 'three', '.'], 'four'),(['four', '.', 'five'], '.'),(['.', 'six', '.'], 'seven'),(['seven', '.', 'eight'], '.'),(['.', 'nine', '.'], 'ten'),(['ten', '.', 'eleven'], '.'),(['.', 'twelve', '.'], 'thirteen'),(['thirteen', '.', 'fourteen'], '.'),(['.', 'fifteen', '.'], 'sixteen')...]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L((tokens[i:i+3], tokens[i+3]) for i in range(0,len(tokens)-4,3))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we will do it with tensors of the numericalized values, which is what the model will actually use:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(#21031) [(tensor([0, 1, 2]), 1),(tensor([1, 3, 1]), 4),(tensor([4, 1, 5]), 1),(tensor([1, 6, 1]), 7),(tensor([7, 1, 8]), 1),(tensor([1, 9, 1]), 10),(tensor([10, 1, 11]), 1),(tensor([ 1, 12, 1]), 13),(tensor([13, 1, 14]), 1),(tensor([ 1, 15, 1]), 16)...]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"seqs = L((tensor(nums[i:i+3]), nums[i+3]) for i in range(0,len(nums)-4,3))\n",
"seqs"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can batch those easily using the `DataLoader` class. For now we will split the sequences randomly:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"bs = 64\n",
"cut = int(len(seqs) * 0.8)\n",
"dls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], bs=64, shuffle=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now create a neural network architecture that takes three words as input, and returns a prediction of the probability of each possible next word in the vocab. We will use three standard linear layers, but with two tweaks.\n",
"\n",
"The first tweak is that the first linear layer will use only the first word's embedding as activations, the second layer will use the second word's embedding plus the first layer's output activations, and the third layer will use the third word's embedding plus the second layer's output activations. The key effect of this is that every word is interpreted in the information context of any words preceding it. \n",
"\n",
"The second tweak is that each of these three layers will use the same weight matrix. The way that one word impacts the activations from previous words should not change depending on the position of a word. In other words, activation values will change as data moves through the layers, but the layer weights themselves will not change from layer to layer. So, a layer does not learn one sequence position; it must learn to handle all positions.\n",
"\n",
"Since layer weights do not change, you might think of the sequential layers as \"the same layer\" repeated. In fact, PyTorch makes this concrete; we can just create one layer, and use it multiple times."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Our Language Model in PyTorch"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now create the language model module that we described earlier:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel1(Module):\n",
" def __init__(self, vocab_sz, n_hidden):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden) \n",
" self.h_h = nn.Linear(n_hidden, n_hidden) \n",
" self.h_o = nn.Linear(n_hidden,vocab_sz)\n",
" \n",
" def forward(self, x):\n",
" h = F.relu(self.h_h(self.i_h(x[:,0])))\n",
" h = h + self.i_h(x[:,1])\n",
" h = F.relu(self.h_h(h))\n",
" h = h + self.i_h(x[:,2])\n",
" h = F.relu(self.h_h(h))\n",
" return self.h_o(h)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you see, we have created three layers:\n",
"\n",
"- The embedding layer (`i_h`, for *input* to *hidden*)\n",
"- The linear layer to create the activations for the next word (`h_h`, for *hidden* to *hidden*)\n",
"- A final linear layer to predict the fourth word (`h_o`, for *hidden* to *output*)\n",
"\n",
"This might be easier to represent in pictorial form, so let's define a simple pictorial representation of basic neural networks. @fig-img-simple-nn shows how we're going to represent a neural net with one hidden layer."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"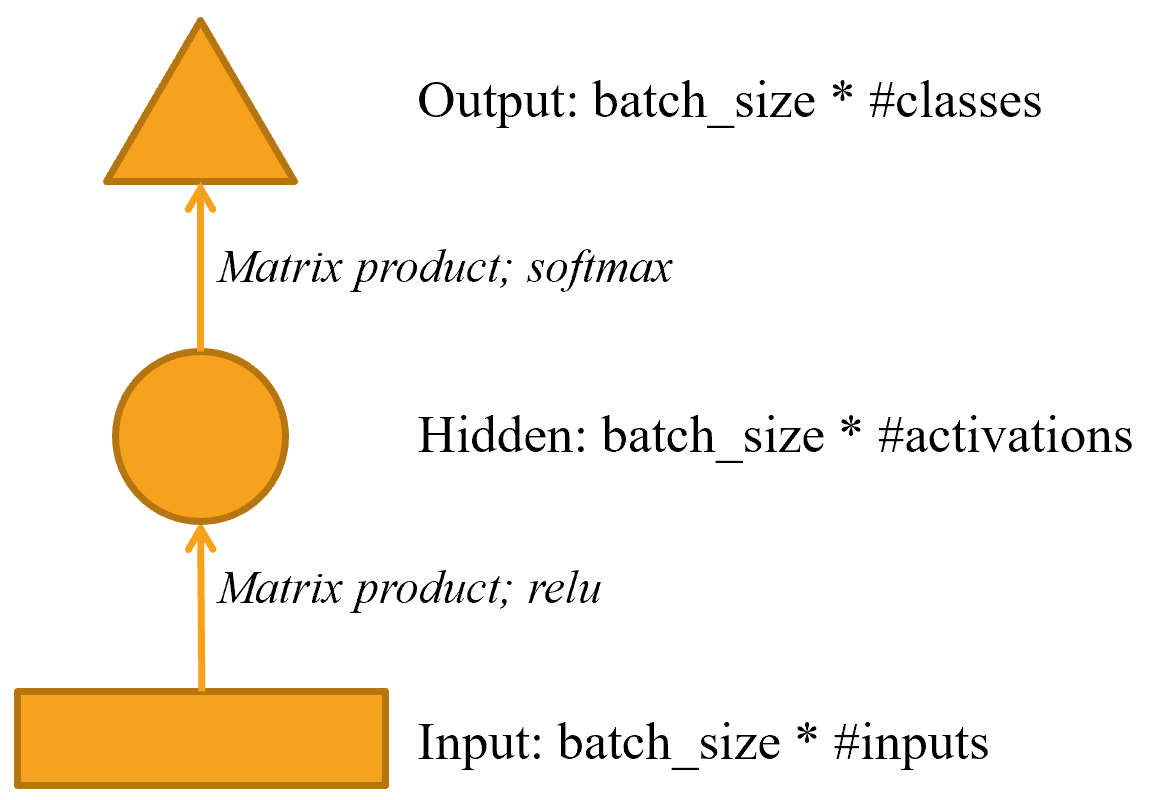{width=\"400\" id=\"fig-img-simple-nn\" fig-alt=\"Pictorial representation of simple neural network\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Each shape represents activations: rectangle for input, circle for hidden (inner) layer activations, and triangle for output activations. We will use those shapes (summarized in @fig-img-shapes) in all the diagrams in this chapter."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"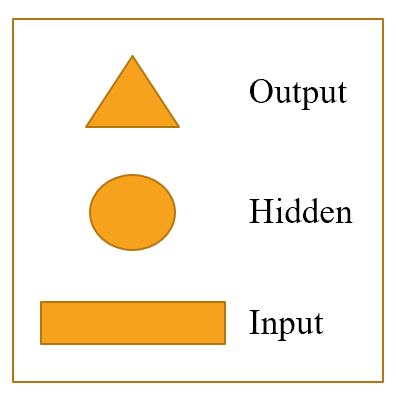{width=\"200\" id=\"fig-img-shapes\" fig-alt=\"Shapes used in our pictorial representations\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"An arrow represents the actual layer computation—i.e., the linear layer followed by the activation function. Using this notation, @fig-lm-rep shows what our simple language model looks like."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"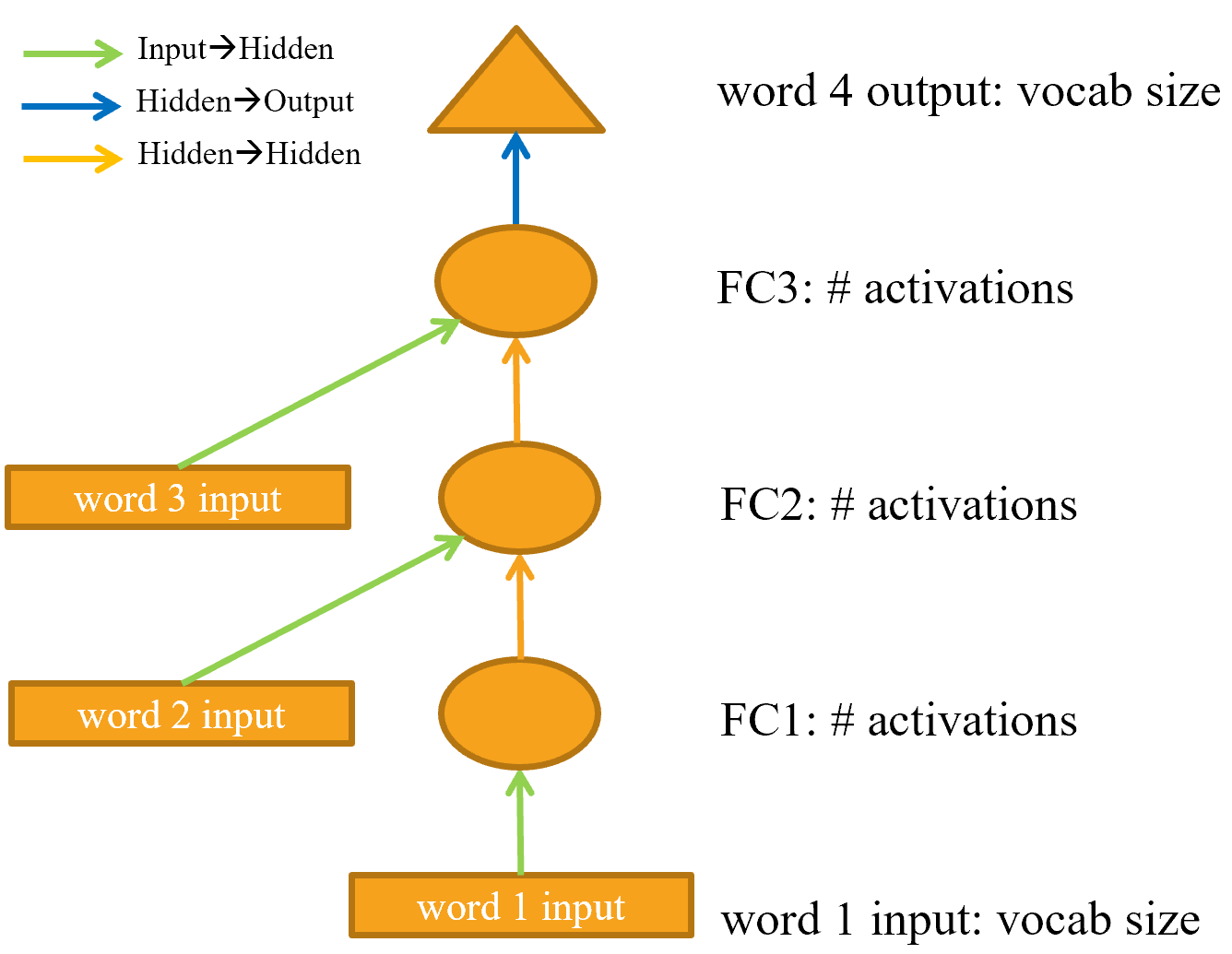{width=\"500\" id=\"fig-lm-rep\" fig-alt=\"Representation of our basic language model\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To simplify things, we've removed the details of the layer computation from each arrow. We've also color-coded the arrows, such that all arrows with the same color have the same weight matrix. For instance, all the input layers use the same embedding matrix, so they all have the same color (green).\n",
"\n",
"Let's try training this model and see how it goes:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.824297 | \n",
" 1.970941 | \n",
" 0.467554 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1.386973 | \n",
" 1.823242 | \n",
" 0.467554 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.417556 | \n",
" 1.654497 | \n",
" 0.494414 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.376440 | \n",
" 1.650849 | \n",
" 0.494414 | \n",
" 00:02 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel1(len(vocab), 64), loss_func=F.cross_entropy, \n",
" metrics=accuracy)\n",
"learn.fit_one_cycle(4, 1e-3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To see if this is any good, let's check what a very simple model would give us. In this case we could always predict the most common token, so let's find out which token is most often the target in our validation set:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(tensor(29), 'thousand', 0.15165200855716662)"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"n,counts = 0,torch.zeros(len(vocab))\n",
"for x,y in dls.valid:\n",
" n += y.shape[0]\n",
" for i in range_of(vocab): counts[i] += (y==i).long().sum()\n",
"idx = torch.argmax(counts)\n",
"idx, vocab[idx.item()], counts[idx].item()/n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The most common token has the index 29, which corresponds to the token `thousand`. Always predicting this token would give us an accuracy of roughly 15\\%, so we are faring way better!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> A: My first guess was that the separator would be the most common token, since there is one for every number. But looking at `tokens` reminded me that large numbers are written with many words, so on the way to 10,000 you write \"thousand\" a lot: five thousand, five thousand and one, five thousand and two, etc. Oops! Looking at your data is great for noticing subtle features and also embarrassingly obvious ones."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is a nice first baseline. Let's see how we can refactor it with a loop."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Our First Recurrent Neural Network"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Looking at the code for our module, we could simplify it by replacing the duplicated code that calls the layers with a `for` loop. As well as making our code simpler, this will also have the benefit that we will be able to apply our module equally well to token sequences of different lengths—we won't be restricted to token lists of length three:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel2(Module):\n",
" def __init__(self, vocab_sz, n_hidden):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden) \n",
" self.h_h = nn.Linear(n_hidden, n_hidden) \n",
" self.h_o = nn.Linear(n_hidden,vocab_sz)\n",
" \n",
" def forward(self, x):\n",
" h = 0\n",
" for i in range(3):\n",
" h = h + self.i_h(x[:,i])\n",
" h = F.relu(self.h_h(h))\n",
" return self.h_o(h)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's check that we get the same results using this refactoring:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.816274 | \n",
" 1.964143 | \n",
" 0.460185 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1.423805 | \n",
" 1.739964 | \n",
" 0.473259 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.430327 | \n",
" 1.685172 | \n",
" 0.485382 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.388390 | \n",
" 1.657033 | \n",
" 0.470406 | \n",
" 00:02 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel2(len(vocab), 64), loss_func=F.cross_entropy, \n",
" metrics=accuracy)\n",
"learn.fit_one_cycle(4, 1e-3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can also refactor our pictorial representation in exactly the same way, as shown in @fig-basic-rnn (we're also removing the details of activation sizes here, and using the same arrow colors as in @fig-lm-rep)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"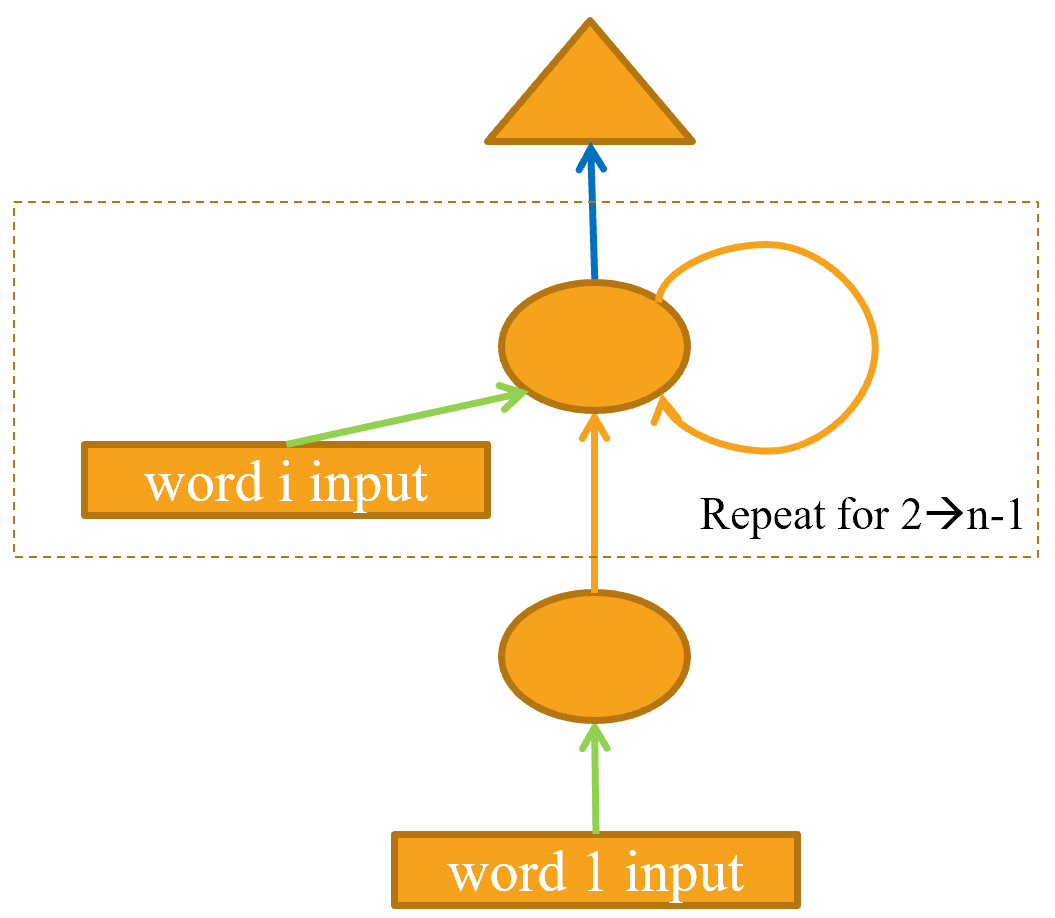{width=\"400\" id=\"fig-basic-rnn\" fig-alt=\"Basic recurrent neural network\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You will see that there is a set of activations that are being updated each time through the loop, stored in the variable `h`—this is called the *hidden state*."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> Jargon: hidden state: The activations that are updated at each step of a recurrent neural network."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A neural network that is defined using a loop like this is called a *recurrent neural network* (RNN). It is important to realize that an RNN is not a complicated new architecture, but simply a refactoring of a multilayer neural network using a `for` loop.\n",
"\n",
"> A: My true opinion: if they were called \"looping neural networks,\" or LNNs, they would seem 50% less daunting!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that we know what an RNN is, let's try to make it a little bit better."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Improving the RNN"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Looking at the code for our RNN, one thing that seems problematic is that we are initializing our hidden state to zero for every new input sequence. Why is that a problem? We made our sample sequences short so they would fit easily into batches. But if we order the samples correctly, those sample sequences will be read in order by the model, exposing the model to long stretches of the original sequence. \n",
"\n",
"Another thing we can look at is having more signal: why only predict the fourth word when we could use the intermediate predictions to also predict the second and third words? \n",
"\n",
"Let's see how we can implement those changes, starting with adding some state."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Maintaining the State of an RNN"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Because we initialize the model's hidden state to zero for each new sample, we are throwing away all the information we have about the sentences we have seen so far, which means that our model doesn't actually know where we are up to in the overall counting sequence. This is easily fixed; we can simply move the initialization of the hidden state to `__init__`.\n",
"\n",
"But this fix will create its own subtle, but important, problem. It effectively makes our neural network as deep as the entire number of tokens in our document. For instance, if there were 10,000 tokens in our dataset, we would be creating a 10,000-layer neural network.\n",
"\n",
"To see why this is the case, consider the original pictorial representation of our recurrent neural network in @fig-lm-rep, before refactoring it with a `for` loop. You can see each layer corresponds with one token input. When we talk about the representation of a recurrent neural network before refactoring with the `for` loop, we call this the *unrolled representation*. It is often helpful to consider the unrolled representation when trying to understand an RNN.\n",
"\n",
"The problem with a 10,000-layer neural network is that if and when you get to the 10,000th word of the dataset, you will still need to calculate the derivatives all the way back to the first layer. This is going to be very slow indeed, and very memory-intensive. It is unlikely that you'll be able to store even one mini-batch on your GPU.\n",
"\n",
"The solution to this problem is to tell PyTorch that we do not want to back propagate the derivatives through the entire implicit neural network. Instead, we will just keep the last three layers of gradients. To remove all of the gradient history in PyTorch, we use the `detach` method.\n",
"\n",
"Here is the new version of our RNN. It is now stateful, because it remembers its activations between different calls to `forward`, which represent its use for different samples in the batch:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel3(Module):\n",
" def __init__(self, vocab_sz, n_hidden):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden) \n",
" self.h_h = nn.Linear(n_hidden, n_hidden) \n",
" self.h_o = nn.Linear(n_hidden,vocab_sz)\n",
" self.h = 0\n",
" \n",
" def forward(self, x):\n",
" for i in range(3):\n",
" self.h = self.h + self.i_h(x[:,i])\n",
" self.h = F.relu(self.h_h(self.h))\n",
" out = self.h_o(self.h)\n",
" self.h = self.h.detach()\n",
" return out\n",
" \n",
" def reset(self): self.h = 0"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This model will have the same activations whatever sequence length we pick, because the hidden state will remember the last activation from the previous batch. The only thing that will be different is the gradients computed at each step: they will only be calculated on sequence length tokens in the past, instead of the whole stream. This approach is called *backpropagation through time* (BPTT)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> jargon: Back propagation through time (BPTT): Treating a neural net with effectively one layer per time step (usually refactored using a loop) as one big model, and calculating gradients on it in the usual way. To avoid running out of memory and time, we usually use _truncated_ BPTT, which \"detaches\" the history of computation steps in the hidden state every few time steps."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To use `LMModel3`, we need to make sure the samples are going to be seen in a certain order. As we saw in @sec-nlp, if the first line of the first batch is our `dset[0]` then the second batch should have `dset[1]` as the first line, so that the model sees the text flowing.\n",
"\n",
"`LMDataLoader` was doing this for us in @sec-nlp. This time we're going to do it ourselves.\n",
"\n",
"To do this, we are going to rearrange our dataset. First we divide the samples into `m = len(dset) // bs` groups (this is the equivalent of splitting the whole concatenated dataset into, for example, 64 equally sized pieces, since we're using `bs=64` here). `m` is the length of each of these pieces. For instance, if we're using our whole dataset (although we'll actually split it into train versus valid in a moment), that will be:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(328, 64, 21031)"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"m = len(seqs)//bs\n",
"m,bs,len(seqs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The first batch will be composed of the samples:\n",
"\n",
" (0, m, 2*m, ..., (bs-1)*m)\n",
"\n",
"the second batch of the samples: \n",
"\n",
" (1, m+1, 2*m+1, ..., (bs-1)*m+1)\n",
"\n",
"and so forth. This way, at each epoch, the model will see a chunk of contiguous text of size `3*m` (since each text is of size 3) on each line of the batch.\n",
"\n",
"The following function does that reindexing:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def group_chunks(ds, bs):\n",
" m = len(ds) // bs\n",
" new_ds = L()\n",
" for i in range(m): new_ds += L(ds[i + m*j] for j in range(bs))\n",
" return new_ds"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then we just pass `drop_last=True` when building our `DataLoaders` to drop the last batch that does not have a shape of `bs`. We also pass `shuffle=False` to make sure the texts are read in order:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cut = int(len(seqs) * 0.8)\n",
"dls = DataLoaders.from_dsets(\n",
" group_chunks(seqs[:cut], bs), \n",
" group_chunks(seqs[cut:], bs), \n",
" bs=bs, drop_last=True, shuffle=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The last thing we add is a little tweak of the training loop via a `Callback`. We will talk more about callbacks in @sec-accel-sgd; this one will call the `reset` method of our model at the beginning of each epoch and before each validation phase. Since we implemented that method to zero the hidden state of the model, this will make sure we start with a clean state before reading those continuous chunks of text. We can also start training a bit longer:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.677074 | \n",
" 1.827367 | \n",
" 0.467548 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1.282722 | \n",
" 1.870913 | \n",
" 0.388942 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.090705 | \n",
" 1.651793 | \n",
" 0.462500 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.005092 | \n",
" 1.613794 | \n",
" 0.516587 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 4 | \n",
" 0.965975 | \n",
" 1.560775 | \n",
" 0.551202 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 5 | \n",
" 0.916182 | \n",
" 1.595857 | \n",
" 0.560577 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 6 | \n",
" 0.897657 | \n",
" 1.539733 | \n",
" 0.574279 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.836274 | \n",
" 1.585141 | \n",
" 0.583173 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.805877 | \n",
" 1.629808 | \n",
" 0.586779 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 9 | \n",
" 0.795096 | \n",
" 1.651267 | \n",
" 0.588942 | \n",
" 00:02 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel3(len(vocab), 64), loss_func=F.cross_entropy,\n",
" metrics=accuracy, cbs=ModelResetter)\n",
"learn.fit_one_cycle(10, 3e-3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is already better! The next step is to use more targets and compare them to the intermediate predictions."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Creating More Signal"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
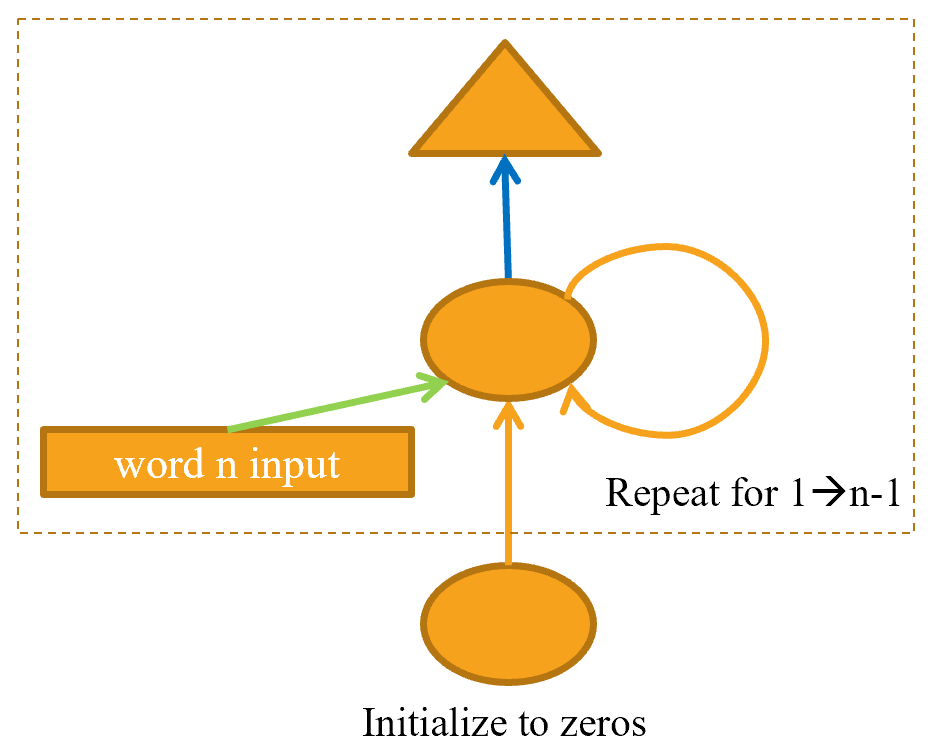
"Another problem with our current approach is that we only predict one output word for each three input words. That means that the amount of signal that we are feeding back to update weights with is not as large as it could be. It would be better if we predicted the next word after every single word, rather than every three words, as shown in @fig-stateful-rep."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"{width=\"400\" id=\"fig-stateful-rep\" fig-alt=\"RNN predicting after every token\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is easy enough to add. We need to first change our data so that the dependent variable has each of the three next words after each of our three input words. Instead of `3`, we use an attribute, `sl` (for sequence length), and make it a bit bigger:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sl = 16\n",
"seqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))\n",
" for i in range(0,len(nums)-sl-1,sl))\n",
"cut = int(len(seqs) * 0.8)\n",
"dls = DataLoaders.from_dsets(group_chunks(seqs[:cut], bs),\n",
" group_chunks(seqs[cut:], bs),\n",
" bs=bs, drop_last=True, shuffle=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Looking at the first element of `seqs`, we can see that it contains two lists of the same size. The second list is the same as the first, but offset by one element:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[(#16) ['one','.','two','.','three','.','four','.','five','.'...],\n",
" (#16) ['.','two','.','three','.','four','.','five','.','six'...]]"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[L(vocab[o] for o in s) for s in seqs[0]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we need to modify our model so that it outputs a prediction after every word, rather than just at the end of a three-word sequence:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel4(Module):\n",
" def __init__(self, vocab_sz, n_hidden):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden) \n",
" self.h_h = nn.Linear(n_hidden, n_hidden) \n",
" self.h_o = nn.Linear(n_hidden,vocab_sz)\n",
" self.h = 0\n",
" \n",
" def forward(self, x):\n",
" outs = []\n",
" for i in range(sl):\n",
" self.h = self.h + self.i_h(x[:,i])\n",
" self.h = F.relu(self.h_h(self.h))\n",
" outs.append(self.h_o(self.h))\n",
" self.h = self.h.detach()\n",
" return torch.stack(outs, dim=1)\n",
" \n",
" def reset(self): self.h = 0"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This model will return outputs of shape `bs x sl x vocab_sz` (since we stacked on `dim=1`). Our targets are of shape `bs x sl`, so we need to flatten those before using them in `F.cross_entropy`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def loss_func(inp, targ):\n",
" return F.cross_entropy(inp.view(-1, len(vocab)), targ.view(-1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now use this loss function to train the model:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 3.103298 | \n",
" 2.874341 | \n",
" 0.212565 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2.231964 | \n",
" 1.971280 | \n",
" 0.462158 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.711358 | \n",
" 1.813547 | \n",
" 0.461182 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.448516 | \n",
" 1.828176 | \n",
" 0.483236 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1.288630 | \n",
" 1.659564 | \n",
" 0.520671 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1.161470 | \n",
" 1.714023 | \n",
" 0.554932 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 6 | \n",
" 1.055568 | \n",
" 1.660916 | \n",
" 0.575033 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.960765 | \n",
" 1.719624 | \n",
" 0.591064 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.870153 | \n",
" 1.839560 | \n",
" 0.614665 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 9 | \n",
" 0.808545 | \n",
" 1.770278 | \n",
" 0.624349 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 10 | \n",
" 0.758084 | \n",
" 1.842931 | \n",
" 0.610758 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 11 | \n",
" 0.719320 | \n",
" 1.799527 | \n",
" 0.646566 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 12 | \n",
" 0.683439 | \n",
" 1.917928 | \n",
" 0.649821 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 13 | \n",
" 0.660283 | \n",
" 1.874712 | \n",
" 0.628581 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 14 | \n",
" 0.646154 | \n",
" 1.877519 | \n",
" 0.640055 | \n",
" 00:01 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel4(len(vocab), 64), loss_func=loss_func,\n",
" metrics=accuracy, cbs=ModelResetter)\n",
"learn.fit_one_cycle(15, 3e-3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We need to train for longer, since the task has changed a bit and is more complicated now. But we end up with a good result... At least, sometimes. If you run it a few times, you'll see that you can get quite different results on different runs. That's because effectively we have a very deep network here, which can result in very large or very small gradients. We'll see in the next part of this chapter how to deal with this.\n",
"\n",
"Now, the obvious way to get a better model is to go deeper: we only have one linear layer between the hidden state and the output activations in our basic RNN, so maybe we'll get better results with more."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Multilayer RNNs"
]
},
{
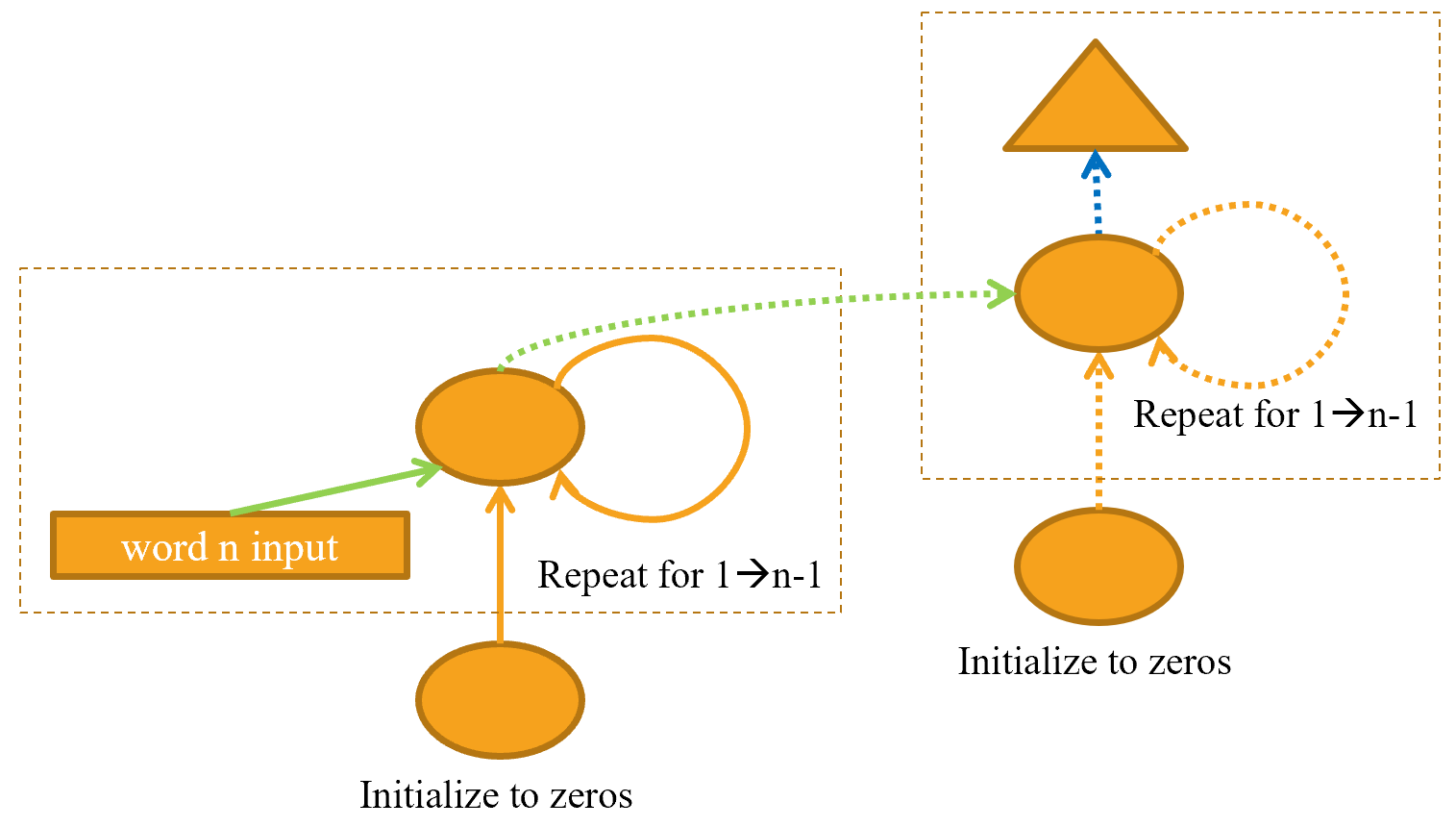
"cell_type": "markdown",
"metadata": {},
"source": [
"In a multilayer RNN, we pass the activations from our recurrent neural network into a second recurrent neural network, like in @fig-stacked-rnn-rep."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"{width=\"550\" id=\"fig-stacked-rnn-rep\" fig-alt=\"2-layer RNN\"}"
]
},
{
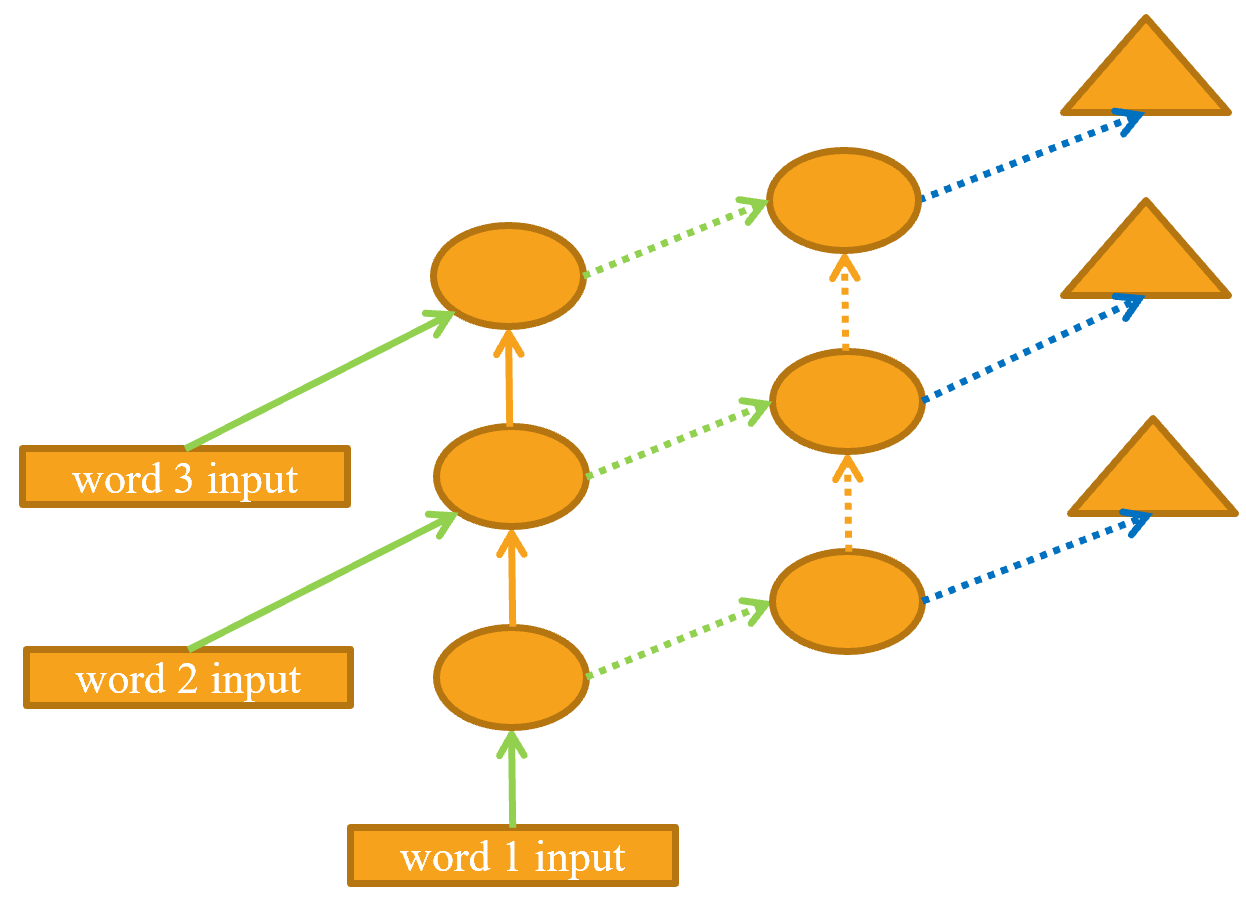
"cell_type": "markdown",
"metadata": {},
"source": [
"The unrolled representation is shown in @fig-unrolled-stack-rep (similar to @fig-lm-rep)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"{width=\"500\" id=\"fig-unrolled-stack-rep\" fig-alt=\"2-layer unrolled RNN\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's see how to implement this in practice."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### The Model"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can save some time by using PyTorch's `RNN` class, which implements exactly what we created earlier, but also gives us the option to stack multiple RNNs, as we have discussed:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel5(Module):\n",
" def __init__(self, vocab_sz, n_hidden, n_layers):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden)\n",
" self.rnn = nn.RNN(n_hidden, n_hidden, n_layers, batch_first=True)\n",
" self.h_o = nn.Linear(n_hidden, vocab_sz)\n",
" self.h = torch.zeros(n_layers, bs, n_hidden)\n",
" \n",
" def forward(self, x):\n",
" res,h = self.rnn(self.i_h(x), self.h)\n",
" self.h = h.detach()\n",
" return self.h_o(res)\n",
" \n",
" def reset(self): self.h.zero_()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 3.055853 | \n",
" 2.591640 | \n",
" 0.437907 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2.162359 | \n",
" 1.787310 | \n",
" 0.471598 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.710663 | \n",
" 1.941807 | \n",
" 0.321777 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.520783 | \n",
" 1.999726 | \n",
" 0.312012 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1.330846 | \n",
" 2.012902 | \n",
" 0.413249 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1.163297 | \n",
" 1.896192 | \n",
" 0.450684 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 6 | \n",
" 1.033813 | \n",
" 2.005209 | \n",
" 0.434814 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.919090 | \n",
" 2.047083 | \n",
" 0.456706 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.822939 | \n",
" 2.068031 | \n",
" 0.468831 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 9 | \n",
" 0.750180 | \n",
" 2.136064 | \n",
" 0.475098 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 10 | \n",
" 0.695120 | \n",
" 2.139140 | \n",
" 0.485433 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 11 | \n",
" 0.655752 | \n",
" 2.155081 | \n",
" 0.493652 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 12 | \n",
" 0.629650 | \n",
" 2.162583 | \n",
" 0.498535 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 13 | \n",
" 0.613583 | \n",
" 2.171649 | \n",
" 0.491048 | \n",
" 00:01 | \n",
"
\n",
" \n",
" | 14 | \n",
" 0.604309 | \n",
" 2.180355 | \n",
" 0.487874 | \n",
" 00:01 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel5(len(vocab), 64, 2), \n",
" loss_func=CrossEntropyLossFlat(), \n",
" metrics=accuracy, cbs=ModelResetter)\n",
"learn.fit_one_cycle(15, 3e-3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that's disappointing... our previous single-layer RNN performed better. Why? The reason is that we have a deeper model, leading to exploding or vanishing activations."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Exploding or Disappearing Activations"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In practice, creating accurate models from this kind of RNN is difficult. We will get better results if we call `detach` less often, and have more layers—this gives our RNN a longer time horizon to learn from, and richer features to create. But it also means we have a deeper model to train. The key challenge in the development of deep learning has been figuring out how to train these kinds of models.\n",
"\n",
"The reason this is challenging is because of what happens when you multiply by a matrix many times. Think about what happens when you multiply by a number many times. For example, if you multiply by 2, starting at 1, you get the sequence 1, 2, 4, 8,... after 32 steps you are already at 4,294,967,296. A similar issue happens if you multiply by 0.5: you get 0.5, 0.25, 0.125… and after 32 steps it's 0.00000000023. As you can see, multiplying by a number even slightly higher or lower than 1 results in an explosion or disappearance of our starting number, after just a few repeated multiplications.\n",
"\n",
"Because matrix multiplication is just multiplying numbers and adding them up, exactly the same thing happens with repeated matrix multiplications. And that's all a deep neural network is —each extra layer is another matrix multiplication. This means that it is very easy for a deep neural network to end up with extremely large or extremely small numbers.\n",
"\n",
"This is a problem, because the way computers store numbers (known as \"floating point\") means that they become less and less accurate the further away the numbers get from zero. The diagram in @fig-float-prec, from the excellent article [\"What You Never Wanted to Know About Floating Point but Will Be Forced to Find Out\"](http://www.volkerschatz.com/science/float.html), shows how the precision of floating-point numbers varies over the number line."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"{width=\"1000\" id=\"fig-float-prec\" fig-alt=\"Precision of floating point numbers\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This inaccuracy means that often the gradients calculated for updating the weights end up as zero or infinity for deep networks. This is commonly referred to as the *vanishing gradients* or *exploding gradients* problem. It means that in SGD, the weights are either not updated at all or jump to infinity. Either way, they won't improve with training.\n",
"\n",
"Researchers have developed a number of ways to tackle this problem, which we will be discussing later in the book. One option is to change the definition of a layer in a way that makes it less likely to have exploding activations. We'll look at the details of how this is done in @sec-convolutions, when we discuss batch normalization, and @sec-resnet, when we discuss ResNets, although these details don't generally matter in practice (unless you are a researcher that is creating new approaches to solving this problem). Another strategy for dealing with this is by being careful about initialization, which is a topic we'll investigate in @sec-foundations.\n",
"\n",
"For RNNs, there are two types of layers that are frequently used to avoid exploding activations: *gated recurrent units* (GRUs) and *long short-term memory* (LSTM) layers. Both of these are available in PyTorch, and are drop-in replacements for the RNN layer. We will only cover LSTMs in this book; there are plenty of good tutorials online explaining GRUs, which are a minor variant on the LSTM design."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## LSTM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"LSTM is an architecture that was introduced back in 1997 by Jürgen Schmidhuber and Sepp Hochreiter. In this architecture, there are not one but two hidden states. In our base RNN, the hidden state is the output of the RNN at the previous time step. That hidden state is then responsible for two things:\n",
"\n",
"- Having the right information for the output layer to predict the correct next token\n",
"- Retaining memory of everything that happened in the sentence\n",
"\n",
"Consider, for example, the sentences \"Henry has a dog and he likes his dog very much\" and \"Sophie has a dog and she likes her dog very much.\" It's very clear that the RNN needs to remember the name at the beginning of the sentence to be able to predict *he/she* or *his/her*. \n",
"\n",
"In practice, RNNs are really bad at retaining memory of what happened much earlier in the sentence, which is the motivation to have another hidden state (called *cell state*) in the LSTM. The cell state will be responsible for keeping *long short-term memory*, while the hidden state will focus on the next token to predict. Let's take a closer look at how this is achieved and build an LSTM from scratch."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Building an LSTM from Scratch"
]
},
{
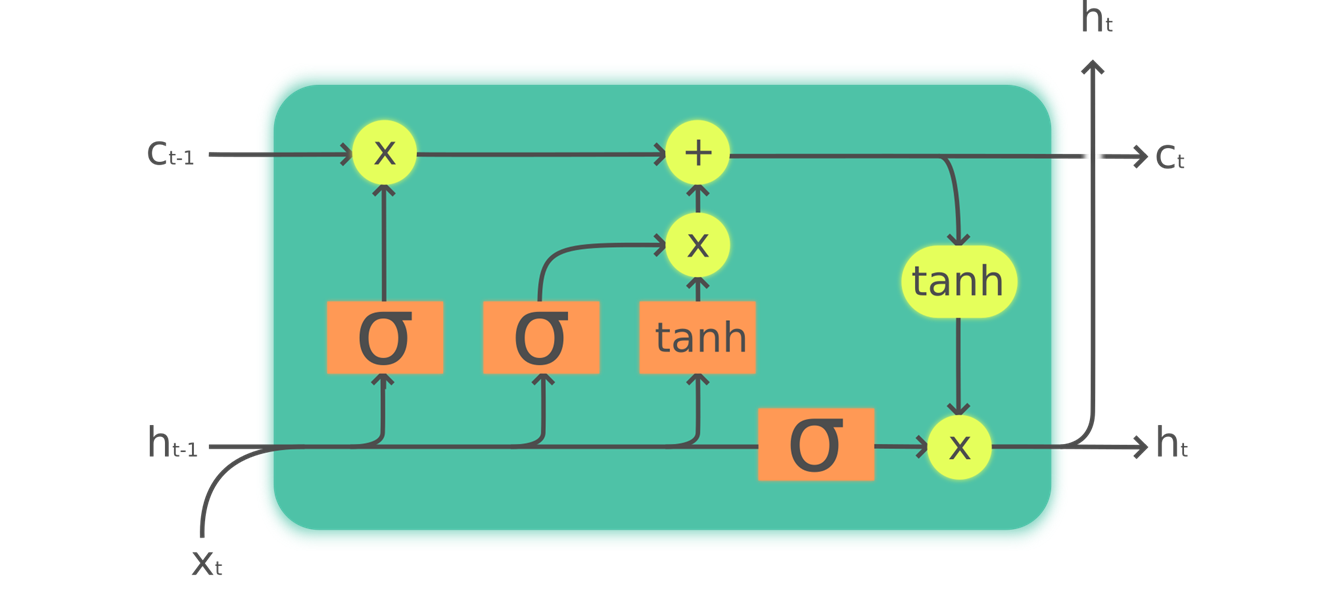
"cell_type": "markdown",
"metadata": {},
"source": [
"In order to build an LSTM, we first have to understand its architecture. @fig-lstm shows its inner structure.\n",
" \n",
"{width=\"700\" id=\"fig-lstm\" fig-alt=\"A graph showing the inner architecture of an LSTM\"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this picture, our input $x_{t}$ enters on the left with the previous hidden state ($h_{t-1}$) and cell state ($c_{t-1}$). The four orange boxes represent four layers (our neural nets) with the activation being either sigmoid ($\\sigma$) or tanh. tanh is just a sigmoid function rescaled to the range -1 to 1. Its mathematical expression can be written like this:\n",
"\n",
"$$\\tanh(x) = \\frac{e^{x} - e^{-x}}{e^{x}+e^{-x}} = 2 \\sigma(2x) - 1$$\n",
"\n",
"where $\\sigma$ is the sigmoid function. The green circles are elementwise operations. What goes out on the right is the new hidden state ($h_{t}$) and new cell state ($c_{t}$), ready for our next input. The new hidden state is also used as output, which is why the arrow splits to go up.\n",
"\n",
"Let's go over the four neural nets (called *gates*) one by one and explain the diagram—but before this, notice how very little the cell state (at the top) is changed. It doesn't even go directly through a neural net! This is exactly why it will carry on a longer-term state.\n",
"\n",
"First, the arrows for input and old hidden state are joined together. In the RNN we wrote earlier in this chapter, we were adding them together. In the LSTM, we stack them in one big tensor. This means the dimension of our embeddings (which is the dimension of $x_{t}$) can be different than the dimension of our hidden state. If we call those `n_in` and `n_hid`, the arrow at the bottom is of size `n_in + n_hid`; thus all the neural nets (orange boxes) are linear layers with `n_in + n_hid` inputs and `n_hid` outputs.\n",
"\n",
"The first gate (looking from left to right) is called the *forget gate*. Since it’s a linear layer followed by a sigmoid, its output will consist of scalars between 0 and 1. We multiply this result by the cell state to determine which information to keep and which to throw away: values closer to 0 are discarded and values closer to 1 are kept. This gives the LSTM the ability to forget things about its long-term state. For instance, when crossing a period or an `xxbos` token, we would expect to it to (have learned to) reset its cell state.\n",
"\n",
"The second gate is called the *input gate*. It works with the third gate (which doesn't really have a name but is sometimes called the *cell gate*) to update the cell state. For instance, we may see a new gender pronoun, in which case we'll need to replace the information about gender that the forget gate removed. Similar to the forget gate, the input gate decides which elements of the cell state to update (values close to 1) or not (values close to 0). The third gate determines what those updated values are, in the range of –1 to 1 (thanks to the tanh function). The result is then added to the cell state.\n",
"\n",
"The last gate is the *output gate*. It determines which information from the cell state to use to generate the output. The cell state goes through a tanh before being combined with the sigmoid output from the output gate, and the result is the new hidden state.\n",
"\n",
"In terms of code, we can write the same steps like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LSTMCell(Module):\n",
" def __init__(self, ni, nh):\n",
" self.forget_gate = nn.Linear(ni + nh, nh)\n",
" self.input_gate = nn.Linear(ni + nh, nh)\n",
" self.cell_gate = nn.Linear(ni + nh, nh)\n",
" self.output_gate = nn.Linear(ni + nh, nh)\n",
"\n",
" def forward(self, input, state):\n",
" h,c = state\n",
" h = torch.cat([h, input], dim=1)\n",
" forget = torch.sigmoid(self.forget_gate(h))\n",
" c = c * forget\n",
" inp = torch.sigmoid(self.input_gate(h))\n",
" cell = torch.tanh(self.cell_gate(h))\n",
" c = c + inp * cell\n",
" out = torch.sigmoid(self.output_gate(h))\n",
" h = out * torch.tanh(c)\n",
" return h, (h,c)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In practice, we can then refactor the code. Also, in terms of performance, it's better to do one big matrix multiplication than four smaller ones (that's because we only launch the special fast kernel on the GPU once, and it gives the GPU more work to do in parallel). The stacking takes a bit of time (since we have to move one of the tensors around on the GPU to have it all in a contiguous array), so we use two separate layers for the input and the hidden state. The optimized and refactored code then looks like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LSTMCell(Module):\n",
" def __init__(self, ni, nh):\n",
" self.ih = nn.Linear(ni,4*nh)\n",
" self.hh = nn.Linear(nh,4*nh)\n",
"\n",
" def forward(self, input, state):\n",
" h,c = state\n",
" # One big multiplication for all the gates is better than 4 smaller ones\n",
" gates = (self.ih(input) + self.hh(h)).chunk(4, 1)\n",
" ingate,forgetgate,outgate = map(torch.sigmoid, gates[:3])\n",
" cellgate = gates[3].tanh()\n",
"\n",
" c = (forgetgate*c) + (ingate*cellgate)\n",
" h = outgate * c.tanh()\n",
" return h, (h,c)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here we use the PyTorch `chunk` method to split our tensor into four pieces. It works like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"t = torch.arange(0,10); t"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(tensor([0, 1, 2, 3, 4]), tensor([5, 6, 7, 8, 9]))"
]
},
"execution_count": null,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"t.chunk(2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's now use this architecture to train a language model!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Training a Language Model Using LSTMs"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here is the same network as `LMModel5`, using a two-layer LSTM. We can train it at a higher learning rate, for a shorter time, and get better accuracy:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel6(Module):\n",
" def __init__(self, vocab_sz, n_hidden, n_layers):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden)\n",
" self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)\n",
" self.h_o = nn.Linear(n_hidden, vocab_sz)\n",
" self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]\n",
" \n",
" def forward(self, x):\n",
" res,h = self.rnn(self.i_h(x), self.h)\n",
" self.h = [h_.detach() for h_ in h]\n",
" return self.h_o(res)\n",
" \n",
" def reset(self): \n",
" for h in self.h: h.zero_()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 3.000821 | \n",
" 2.663942 | \n",
" 0.438314 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2.139642 | \n",
" 2.184780 | \n",
" 0.240479 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.607275 | \n",
" 1.812682 | \n",
" 0.439779 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.347711 | \n",
" 1.830982 | \n",
" 0.497477 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1.123113 | \n",
" 1.937766 | \n",
" 0.594401 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 5 | \n",
" 0.852042 | \n",
" 2.012127 | \n",
" 0.631592 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 6 | \n",
" 0.565494 | \n",
" 1.312742 | \n",
" 0.725749 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.347445 | \n",
" 1.297934 | \n",
" 0.711263 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.208191 | \n",
" 1.441269 | \n",
" 0.731201 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 9 | \n",
" 0.126335 | \n",
" 1.569952 | \n",
" 0.737305 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 10 | \n",
" 0.079761 | \n",
" 1.427187 | \n",
" 0.754150 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 11 | \n",
" 0.052990 | \n",
" 1.494990 | \n",
" 0.745117 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 12 | \n",
" 0.039008 | \n",
" 1.393731 | \n",
" 0.757894 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 13 | \n",
" 0.031502 | \n",
" 1.373210 | \n",
" 0.758464 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 14 | \n",
" 0.028068 | \n",
" 1.368083 | \n",
" 0.758464 | \n",
" 00:02 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn = Learner(dls, LMModel6(len(vocab), 64, 2), \n",
" loss_func=CrossEntropyLossFlat(), \n",
" metrics=accuracy, cbs=ModelResetter)\n",
"learn.fit_one_cycle(15, 1e-2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that's better than a multilayer RNN! We can still see there is a bit of overfitting, however, which is a sign that a bit of regularization might help."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Regularizing an LSTM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Recurrent neural networks, in general, are hard to train, because of the problem of vanishing activations and gradients we saw before. Using LSTM (or GRU) cells makes training easier than with vanilla RNNs, but they are still very prone to overfitting. Data augmentation, while a possibility, is less often used for text data than for images because in most cases it requires another model to generate random augmentations (e.g., by translating the text into another language and then back into the original language). Overall, data augmentation for text data is currently not a well-explored space.\n",
"\n",
"However, there are other regularization techniques we can use instead to reduce overfitting, which were thoroughly studied for use with LSTMs in the paper [\"Regularizing and Optimizing LSTM Language Models\"](https://arxiv.org/abs/1708.02182) by Stephen Merity, Nitish Shirish Keskar, and Richard Socher. This paper showed how effective use of *dropout*, *activation regularization*, and *temporal activation regularization* could allow an LSTM to beat state-of-the-art results that previously required much more complicated models. The authors called an LSTM using these techniques an *AWD-LSTM*. We'll look at each of these techniques in turn."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Dropout"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
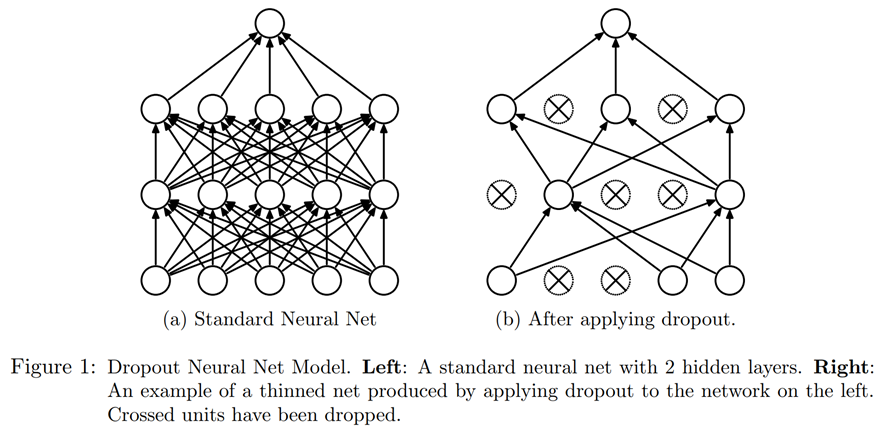
"Dropout is a regularization technique that was introduced by Geoffrey Hinton et al. in [Improving neural networks by preventing co-adaptation of feature detectors](https://arxiv.org/abs/1207.0580). The basic idea is to randomly change some activations to zero at training time. This makes sure all neurons actively work toward the output, as seen in @fig-img-dropout (from \"Dropout: A Simple Way to Prevent Neural Networks from Overfitting\" by Nitish Srivastava et al.).\n",
"\n",
"{width=\"800\" id=\"fig-img-dropout\" fig-alt=\"A figure from the article showing how neurons go off with dropout\"}\n",
"\n",
"Hinton used a nice metaphor when he explained, in an interview, the inspiration for dropout:\n",
"\n",
"> I went to my bank. The tellers kept changing and I asked one of them why. He said he didn’t know but they got moved around a lot. I figured it must be because it would require cooperation between employees to successfully defraud the bank. This made me realize that randomly removing a different subset of neurons on each example would prevent conspiracies and thus reduce overfitting.\n",
"\n",
"In the same interview, he also explained that neuroscience provided additional inspiration:\n",
"\n",
"> We don't really know why neurons spike. One theory is that they want to be noisy so as to regularize, because we have many more parameters than we have data points. The idea of dropout is that if you have noisy activations, you can afford to use a much bigger model."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This explains the idea behind why dropout helps to generalize: first it helps the neurons to cooperate better together, then it makes the activations more noisy, thus making the model more robust."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
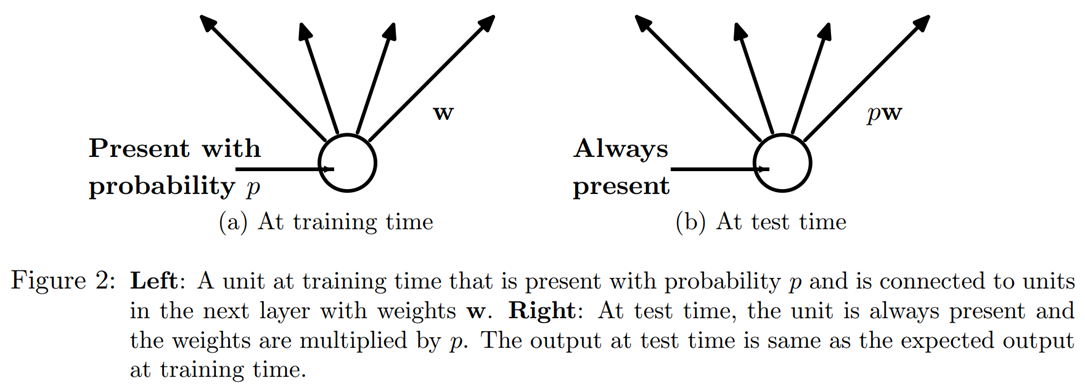
"We can see, however, that if we were to just zero those activations without doing anything else, our model would have problems training: if we go from the sum of five activations (that are all positive numbers since we apply a ReLU) to just two, this won't have the same scale. Therefore, if we apply dropout with a probability `p`, we rescale all activations by dividing them by `1-p` (on average `p` will be zeroed, so it leaves `1-p`), as shown in @fig-img-dropout1.\n",
"\n",
"{width=\"600\" id=\"fig-img-dropout1\" fig-alt=\"A figure from the article introducing dropout showing how a neuron is on/off\"}\n",
"\n",
"This is a full implementation of the dropout layer in PyTorch (although PyTorch's native layer is actually written in C, not Python):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class Dropout(Module):\n",
" def __init__(self, p): self.p = p\n",
" def forward(self, x):\n",
" if not self.training: return x\n",
" mask = x.new(*x.shape).bernoulli_(1-p)\n",
" return x * mask.div_(1-p)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The `bernoulli_` method is creating a tensor of random zeros (with probability `p`) and ones (with probability `1-p`), which is then multiplied with our input before dividing by `1-p`. Note the use of the `training` attribute, which is available in any PyTorch `nn.Module`, and tells us if we are doing training or inference.\n",
"\n",
"> note: Do Your Own Experiments: In previous chapters of the book we'd be adding a code example for `bernoulli_` here, so you can see exactly how it works. But now that you know enough to do this yourself, we're going to be doing fewer and fewer examples for you, and instead expecting you to do your own experiments to see how things work. In this case, you'll see in the end-of-chapter questionnaire that we're asking you to experiment with `bernoulli_`—but don't wait for us to ask you to experiment to develop your understanding of the code we're studying; go ahead and do it anyway!\n",
"\n",
"Using dropout before passing the output of our LSTM to the final layer will help reduce overfitting. Dropout is also used in many other models, including the default CNN head used in `fastai.vision`, and is available in `fastai.tabular` by passing the `ps` parameter (where each \"p\" is passed to each added `Dropout` layer), as we'll see in @sec-arch-details."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Dropout has different behavior in training and validation mode, which we specified using the `training` attribute in `Dropout`. Calling the `train` method on a `Module` sets `training` to `True` (both for the module you call the method on and for every module it recursively contains), and `eval` sets it to `False`. This is done automatically when calling the methods of `Learner`, but if you are not using that class, remember to switch from one to the other as needed."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Activation Regularization and Temporal Activation Regularization"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*Activation regularization* (AR) and *temporal activation regularization* (TAR) are two regularization methods very similar to weight decay, discussed in @sec-collab. When applying weight decay, we add a small penalty to the loss that aims at making the weights as small as possible. For activation regularization, it's the final activations produced by the LSTM that we will try to make as small as possible, instead of the weights.\n",
"\n",
"To regularize the final activations, we have to store those somewhere, then add the means of the squares of them to the loss (along with a multiplier `alpha`, which is just like `wd` for weight decay):\n",
"\n",
"``` python\n",
"loss += alpha * activations.pow(2).mean()\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Temporal activation regularization is linked to the fact we are predicting tokens in a sentence. That means it's likely that the outputs of our LSTMs should somewhat make sense when we read them in order. TAR is there to encourage that behavior by adding a penalty to the loss to make the difference between two consecutive activations as small as possible: our activations tensor has a shape `bs x sl x n_hid`, and we read consecutive activations on the sequence length axis (the dimension in the middle). With this, TAR can be expressed as:\n",
"\n",
"``` python\n",
"loss += beta * (activations[:,1:] - activations[:,:-1]).pow(2).mean()\n",
"```\n",
"\n",
"`alpha` and `beta` are then two hyperparameters to tune. To make this work, we need our model with dropout to return three things: the proper output, the activations of the LSTM pre-dropout, and the activations of the LSTM post-dropout. AR is often applied on the dropped-out activations (to not penalize the activations we turned into zeros afterward) while TAR is applied on the non-dropped-out activations (because those zeros create big differences between two consecutive time steps). There is then a callback called `RNNRegularizer` that will apply this regularization for us."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Training a Weight-Tied Regularized LSTM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can combine dropout (applied before we go into our output layer) with AR and TAR to train our previous LSTM. We just need to return three things instead of one: the normal output of our LSTM, the dropped-out activations, and the activations from our LSTMs. The last two will be picked up by the callback `RNNRegularization` for the contributions it has to make to the loss.\n",
"\n",
"Another useful trick we can add from [the AWD LSTM paper](https://arxiv.org/abs/1708.02182) is *weight tying*. In a language model, the input embeddings represent a mapping from English words to activations, and the output hidden layer represents a mapping from activations to English words. We might expect, intuitively, that these mappings could be the same. We can represent this in PyTorch by assigning the same weight matrix to each of these layers:\n",
"\n",
" self.h_o.weight = self.i_h.weight\n",
"\n",
"In `LMModel7`, we include these final tweaks:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class LMModel7(Module):\n",
" def __init__(self, vocab_sz, n_hidden, n_layers, p):\n",
" self.i_h = nn.Embedding(vocab_sz, n_hidden)\n",
" self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)\n",
" self.drop = nn.Dropout(p)\n",
" self.h_o = nn.Linear(n_hidden, vocab_sz)\n",
" self.h_o.weight = self.i_h.weight\n",
" self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]\n",
" \n",
" def forward(self, x):\n",
" raw,h = self.rnn(self.i_h(x), self.h)\n",
" out = self.drop(raw)\n",
" self.h = [h_.detach() for h_ in h]\n",
" return self.h_o(out),raw,out\n",
" \n",
" def reset(self): \n",
" for h in self.h: h.zero_()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can create a regularized `Learner` using the `RNNRegularizer` callback:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"learn = Learner(dls, LMModel7(len(vocab), 64, 2, 0.5),\n",
" loss_func=CrossEntropyLossFlat(), metrics=accuracy,\n",
" cbs=[ModelResetter, RNNRegularizer(alpha=2, beta=1)])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A `TextLearner` automatically adds those two callbacks for us (with those values for `alpha` and `beta` as defaults), so we can simplify the preceding line to:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"learn = TextLearner(dls, LMModel7(len(vocab), 64, 2, 0.4),\n",
" loss_func=CrossEntropyLossFlat(), metrics=accuracy)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can then train the model, and add additional regularization by increasing the weight decay to `0.1`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" | epoch | \n",
" train_loss | \n",
" valid_loss | \n",
" accuracy | \n",
" time | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 2.693885 | \n",
" 2.013484 | \n",
" 0.466634 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1.685549 | \n",
" 1.187310 | \n",
" 0.629313 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.973307 | \n",
" 0.791398 | \n",
" 0.745605 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 3 | \n",
" 0.555823 | \n",
" 0.640412 | \n",
" 0.794108 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 4 | \n",
" 0.351802 | \n",
" 0.557247 | \n",
" 0.836100 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 5 | \n",
" 0.244986 | \n",
" 0.594977 | \n",
" 0.807292 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 6 | \n",
" 0.192231 | \n",
" 0.511690 | \n",
" 0.846761 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.162456 | \n",
" 0.520370 | \n",
" 0.858073 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.142664 | \n",
" 0.525918 | \n",
" 0.842285 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 9 | \n",
" 0.128493 | \n",
" 0.495029 | \n",
" 0.858073 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 10 | \n",
" 0.117589 | \n",
" 0.464236 | \n",
" 0.867188 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 11 | \n",
" 0.109808 | \n",
" 0.466550 | \n",
" 0.869303 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 12 | \n",
" 0.104216 | \n",
" 0.455151 | \n",
" 0.871826 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 13 | \n",
" 0.100271 | \n",
" 0.452659 | \n",
" 0.873617 | \n",
" 00:02 | \n",
"
\n",
" \n",
" | 14 | \n",
" 0.098121 | \n",
" 0.458372 | \n",
" 0.869385 | \n",
" 00:02 | \n",
"
\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"learn.fit_one_cycle(15, 1e-2, wd=0.1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now this is far better than our previous model!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Conclusion"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You have now seen everything that is inside the AWD-LSTM architecture we used in text classification in @sec-nlp. It uses dropout in a lot more places:\n",
"\n",
"- Embedding dropout (inside the embedding layer, drops some random lines of embeddings)\n",
"- Input dropout (applied after the embedding layer)\n",
"- Weight dropout (applied to the weights of the LSTM at each training step)\n",
"- Hidden dropout (applied to the hidden state between two layers)\n",
"\n",
"This makes it even more regularized. Since fine-tuning those five dropout values (including the dropout before the output layer) is complicated, we have determined good defaults and allow the magnitude of dropout to be tuned overall with the `drop_mult` parameter you saw in that chapter (which is multiplied by each dropout).\n",
"\n",
"Another architecture that is very powerful, especially in \"sequence-to-sequence\" problems (that is, problems where the dependent variable is itself a variable-length sequence, such as language translation), is the Transformers architecture. You can find it in a bonus chapter on the [book's website](https://book.fast.ai/)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Questionnaire"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. If the dataset for your project is so big and complicated that working with it takes a significant amount of time, what should you do?\n",
"1. Why do we concatenate the documents in our dataset before creating a language model?\n",
"1. To use a standard fully connected network to predict the fourth word given the previous three words, what two tweaks do we need to make to our model?\n",
"1. How can we share a weight matrix across multiple layers in PyTorch?\n",
"1. Write a module that predicts the third word given the previous two words of a sentence, without peeking.\n",
"1. What is a recurrent neural network?\n",
"1. What is \"hidden state\"?\n",
"1. What is the equivalent of hidden state in ` LMModel1`?\n",
"1. To maintain the state in an RNN, why is it important to pass the text to the model in order?\n",
"1. What is an \"unrolled\" representation of an RNN?\n",
"1. Why can maintaining the hidden state in an RNN lead to memory and performance problems? How do we fix this problem?\n",
"1. What is \"BPTT\"?\n",
"1. Write code to print out the first few batches of the validation set, including converting the token IDs back into English strings, as we showed for batches of IMDb data in @sec-nlp.\n",
"1. What does the `ModelResetter` callback do? Why do we need it?\n",
"1. What are the downsides of predicting just one output word for each three input words?\n",
"1. Why do we need a custom loss function for `LMModel4`?\n",
"1. Why is the training of `LMModel4` unstable?\n",
"1. In the unrolled representation, we can see that a recurrent neural network actually has many layers. So why do we need to stack RNNs to get better results?\n",
"1. Draw a representation of a stacked (multilayer) RNN.\n",
"1. Why should we get better results in an RNN if we call `detach` less often? Why might this not happen in practice with a simple RNN?\n",
"1. Why can a deep network result in very large or very small activations? Why does this matter?\n",
"1. In a computer's floating-point representation of numbers, which numbers are the most precise?\n",
"1. Why do vanishing gradients prevent training?\n",
"1. Why does it help to have two hidden states in the LSTM architecture? What is the purpose of each one?\n",
"1. What are these two states called in an LSTM?\n",
"1. What is tanh, and how is it related to sigmoid?\n",
"1. What is the purpose of this code in `LSTMCell`: `h = torch.cat([h, input], dim=1)`\n",
"1. What does `chunk` do in PyTorch?\n",
"1. Study the refactored version of `LSTMCell` carefully to ensure you understand how and why it does the same thing as the non-refactored version.\n",
"1. Why can we use a higher learning rate for `LMModel6`?\n",
"1. What are the three regularization techniques used in an AWD-LSTM model?\n",
"1. What is \"dropout\"?\n",
"1. Why do we scale the acitvations with dropout? Is this applied during training, inference, or both?\n",
"1. What is the purpose of this line from `Dropout`: `if not self.training: return x`\n",
"1. Experiment with `bernoulli_` to understand how it works.\n",
"1. How do you set your model in training mode in PyTorch? In evaluation mode?\n",
"1. Write the equation for activation regularization (in math or code, as you prefer). How is it different from weight decay?\n",
"1. Write the equation for temporal activation regularization (in math or code, as you prefer). Why wouldn't we use this for computer vision problems?\n",
"1. What is \"weight tying\" in a language model?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Further Research"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. In ` LMModel2`, why can `forward` start with `h=0`? Why don't we need to say `h=torch.zeros(...)`?\n",
"1. Write the code for an LSTM from scratch (you may refer to @fig-lstm).\n",
"1. Search the internet for the GRU architecture and implement it from scratch, and try training a model. See if you can get results similar to those we saw in this chapter. Compare your results to the results of PyTorch's built in `GRU` module.\n",
"1. Take a look at the source code for AWD-LSTM in fastai, and try to map each of the lines of code to the concepts shown in this chapter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"jupytext": {
"split_at_heading": true
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}