### A Pluto.jl notebook ###
# v0.20.4
using Markdown
using InteractiveUtils
# This Pluto notebook uses @bind for interactivity. When running this notebook outside of Pluto, the following 'mock version' of @bind gives bound variables a default value (instead of an error).
macro bind(def, element)
#! format: off
quote
local iv = try Base.loaded_modules[Base.PkgId(Base.UUID("6e696c72-6542-2067-7265-42206c756150"), "AbstractPlutoDingetjes")].Bonds.initial_value catch; b -> missing; end
local el = $(esc(element))
global $(esc(def)) = Core.applicable(Base.get, el) ? Base.get(el) : iv(el)
el
end
#! format: on
end
# ╔═╡ 36610294-87dc-11eb-21e8-5b1dd06c6020
begin
using PlutoUI
using Interpolations
using Roots
using LaTeXStrings
using Plots
using Optim
end
# ╔═╡ d367efe3-f2e1-40b2-8bd1-47bb827424d0
html"""
"""
# ╔═╡ 5fab5e80-87ce-11eb-111a-d5288227b97c
html""
# ╔═╡ 705e96f2-87ce-11eb-3f5a-eb6cdb8c49d4
md"
# Dynamic Programming 2
> Florian Oswald, Carlo Alberto 2025
* In this notebook we'll add uncertainty to our simple setup from the last time.
* We'll stay in the finite time framework, but everything we say will be easily portable to infinite time.
* We'll write code (of course). We won't worry about performance so far, but try to be as explicit as possible.
* We'll do something that looks reasonable but works terribly.
* Then we'll fix it and celebrate! 🎉
"
# ╔═╡ 34403942-87d2-11eb-1172-7bd285bf7d75
md"
#
* A good place to start is a so called decision tree.
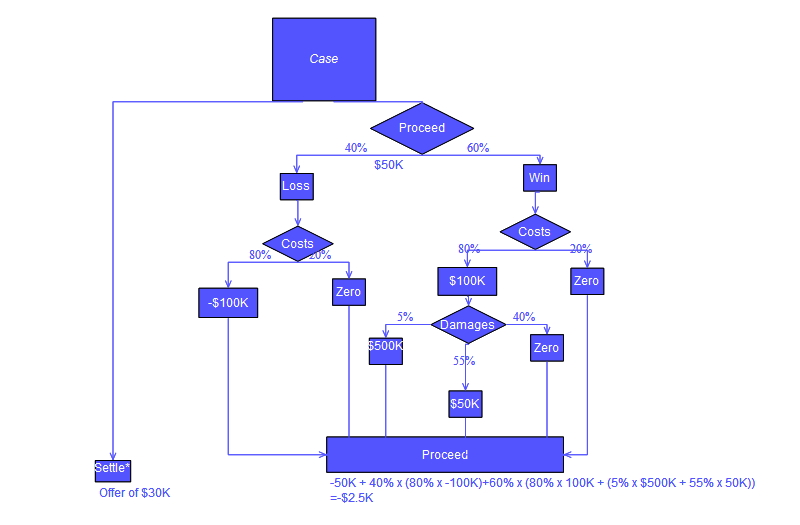"
# ╔═╡ b9ed265e-87d2-11eb-1028-05b4c4ccbc74
md"
## Markov Decision Problems (MDPs)
* Assume a finite set of states $S$
* A finite set of actions $A$
* For state $s\in S$ and action $a \in A$ we can compute the *cost* or the *contribution* $C(s,a)$
* There is a *transition matrix* $p_t(S_{t+1} | S_{t}, a_t)$ which tells us with which probability we go from state $S_{t}$ to $S_{t+1}$ upen taking decision $a_t$
* Even though many problems have *continuous* state and action spaces, this is a very useful class of problems to study.
"
# ╔═╡ 07992abe-87d4-11eb-0fd7-1bef7fc2ada8
md"
## Optimality (Bellman) Equations
* But let's start with _no uncertainty_. If we are at state $S_t$, we know how $S_{t+1}$ will look like with certainty if we choose a certain action $a_t$
* Then we just choose the best action:
$$a_t^*(S_t) = \arg \max_{a_t \in A_t} \left(C_t(S_t,a_t) + \beta V_{t+1}(S_{t+1}(S_t,a_t)) \right)$$
* The associated *value* of this choice is then the same Bellman Equation we know from last time,
$$\begin{align}V_t(S_t) &= \max_{a_t \in A_t} \left(C_t(S_t,a_t) + \beta V_{t+1}(S_{t+1}(S_t,a_t)) \right) \\ &= C_t(S_t,a^*_t(S_t)) + \beta V_{t+1}(S_{t+1}(S_t,a^*_t(S_t)))\end{align}$$
"
# ╔═╡ 93148b06-87d2-11eb-2356-fb460acf8e66
md"
## Enter Uncertainty
* Uncertainty comes into play if we *don't know exactly what state* $S_{t+1}$ we'll end up in.
* We may have partial information on the likelihood of each state occuring, like a belief, or prior information.
* We have our transition matrix $p_t(S_{t+1} | S_{t}, a_t)$, and can define the *standard form of the Bellman Equation*:
$$V_t(S_t) = \max_{a_t \in A_t} \left(C_t(S_t,a_t) + \beta \sum_{s' \in S} p_t\left( S_{t+1} = s' | S_t, a_t \right)V_{t+1}(s') \right)$$
"
# ╔═╡ 3d97787a-87d2-11eb-3713-ab3dad6e5e8b
md"
#
* we can also write it more general without the summation
$$V_t(S_t) = \max_{a_t \in A_t} \left(C_t(S_t,a_t) + \beta \mathbb{E} \left[ V_{t+1}(S_{t+1}(S_t,a_t)) | S_t \right] \right)$$"
# ╔═╡ a41aff3a-87d8-11eb-00fe-e16c14870ba2
md"
## Let's Do it!
* Let's look at this specific problem where the *action* is *consumption*, and $u$ is a *utility function* and the state is $R_t$:
$$V_t(R_t) = \max_{0 \leq c_t \leq R_t} \left(u(c_t) + \beta \mathbb{E} \left[ V_{t+1}(R_{t+1}(R_t,c_t)) |R_t \right] \right)$$
* Here $R_t$ could be available cash on hand of the consumer.
* Let us specify a *law of motion* for the state as
$$R_{t+1} = R_t - c_t + y_{t+1}$$ where $y_t$ is a random variable.
* We have to compute expectations wrt to $y$
"
# ╔═╡ c6ed3824-87d9-11eb-3e0a-b5a473fdb952
md"
## I.I.D. Shock
* Let's start with the simplest case: $y_t \in \{\overline{y}, \underline{y}\}, 0 < \overline{y} < \underline{y}$
* There is a probability π associated to $P(y = \overline{y}) = \pi$
* There is *no state dependence* in the $y$ process: the current $y_t$ does not matter for the future $y_{t+1}$
"
# ╔═╡ 51983542-87f9-11eb-226a-81fe383f0763
md"
#
"
# ╔═╡ 6ddfc91c-87da-11eb-3b5c-dfe006576f29
"""
Bellman(grid::Vector,vplus::Vector,π::Float64,yvec::Vector)
Given a grid and a next period value function `vplus`, and a probability distribution
calculate current period optimal value and actions.
"""
function Bellman(grid::Vector,vplus::Vector,π::Float64,yvec::Vector{Float64},β::Float64)
points = length(grid)
w = zeros(points) # temporary vector for each choice or R'
Vt = zeros(points) # optimal value in T-1 at each state of R
ix = 0 # optimal action index in T-1 at each state of R
at = zeros(points) # optimal action in T-1 at each state of R
for (ir,r) in enumerate(grid) # for all possible R-values
# loop over all possible action choices
for (ia,achoice) in enumerate(grid)
if r <= achoice # check whether that choice is feasible
w[ia] = -Inf
else
rlow = r - achoice + yvec[1] # tomorrow's R if y is low
rhigh = r - achoice + yvec[2] # tomorrow's R if y is high
jlow = argmin(abs.(grid .- rlow)) # index of that value in Rspace
jhigh = argmin(abs.(grid .- rhigh)) # index of that value in Rspace
w[ia] = sqrt(achoice) + β * ((1-π) * vplus[jlow] + (π) * vplus[jhigh] ) # value of that achoice
end
end
# find best action
Vt[ir], ix = findmax(w) # stores Value und policy (index of optimal choice)
at[ir] = grid[ix] # record optimal action level
end
return (Vt, at)
end
# ╔═╡ aeb2b692-87db-11eb-3c9a-114acdc3d159
md"
#
"
# ╔═╡ b3f20522-87db-11eb-325d-7ba201c66452
begin
points = 500
lowR = 0.01
highR = 10.0
# more points towards zero to make nicer plot
Rspace = exp.(range(log(lowR), stop = log(highR), length = points))
aT = Rspace # consume whatever is left
VT = sqrt.(aT) # utility of that consumption
yvec = [1.0, 3.0]
nperiods = 10
β = 1.0 # irrelevant for now
π = 0.7
end
# ╔═╡ 6e8aec5e-87f9-11eb-2e53-bf5ba90fa750
md"
#
"
# ╔═╡ f00890ee-87db-11eb-153d-bb9244b46e89
# identical
function backwards(grid, nperiods, β, π, yvec)
points = length(grid)
V = zeros(nperiods,points)
c = zeros(nperiods,points)
V[end,:] = sqrt.(grid) # from before: final period
c[end,:] = collect(grid)
for it in (nperiods-1):-1:1
x = Bellman(grid, V[it+1,:], π, yvec, β)
V[it,:] = x[1]
c[it,:] = x[2]
end
return (V,c)
end
# ╔═╡ 4da91e08-87dc-11eb-3238-433fbdda7df7
V,a = backwards(Rspace, nperiods, β, π, yvec);
# ╔═╡ 7a97ba6a-87f9-11eb-1c88-a999bcff4647
md"
#
"
# ╔═╡ ca3e6b12-87dc-11eb-31c6-8d3be744def0
let
cg = cgrad(:viridis)
cols = cg[range(0.0,stop=1.0,length = nperiods)]
pa = plot(Rspace, a[1,:], xlab = "R", ylab = "Action",label = L"a_1",leg = :topleft, color = cols[1])
for it in 2:nperiods
plot!(pa, Rspace, a[it,:], label = L"a_{%$(it)}", color = cols[it])
end
pv = plot(Rspace, V[1,:], xlab = "R", ylab = "Value",label = L"V_1",leg = :bottomright, color = cols[1])
for it in 2:nperiods
plot!(pv, Rspace, V[it,:], label = L"V_{%$(it)}", color = cols[it])
end
plot(pv,pa, layout = (1,2))
end
# ╔═╡ 027875e0-87e0-11eb-0ca5-317b58b0f8fc
PlutoUI.Resource("https://i.ytimg.com/vi/wAbnNZDhYrA/maxresdefault.jpg")
# ╔═╡ 48cc5fa2-87dd-11eb-309b-9708941fd8d5
md"
#
* Oh wow! That's like...total disaster!
* 😩
* This way of interpolating the future value function does *not work very well*
* Let's use proper interpolation instead!
* Instead of `vplus[jlow]` we want to have `vplus[Rprime]` where `Rprime` $\in \mathbb{R}$!
#
"
# ╔═╡ 04b6c4b8-87df-11eb-21dd-15a443042bd1
"""
Bellman(grid::Vector,vplus::Vector,π::Float64,yvec::Vector)
Given a grid and a next period value function `vplus`, and a probability distribution
calculate current period optimal value and actions.
"""
function Bellman2(grid::Vector,vplus::Vector,π::Float64,yvec::Vector,β::Float64)
points = length(grid)
w = zeros(points) # temporary vector for each choice or R'
Vt = zeros(points) # optimal value in T-1 at each state of R
ix = 0 # optimal action index in T-1 at each state of R
at = zeros(points) # optimal action in T-1 at each state of R
# interpolator
vitp = interpolate((grid,), vplus, Gridded(Linear()))
vitp = extrapolate(vitp, Interpolations.Flat())
for (ir,r) in enumerate(grid) # for all possible R-values
# loop over all possible action choices
for (ia,achoice) in enumerate(grid)
if r <= achoice # check whether that choice is feasible
w[ia] = -Inf
else
rlow = r - achoice + yvec[1] # tomorrow's R if y is low
rhigh = r - achoice + yvec[2] # tomorrow's R if y is high
w[ia] = sqrt(achoice) + (1-π) * vitp(rlow) + (π) * vitp(rhigh) # value of that achoice
end
end
# find best action
Vt[ir], ix = findmax(w) # stores Value und policy (index of optimal choice)
at[ir] = grid[ix] # record optimal action level
end
return (Vt, at)
end
# ╔═╡ 99b19ed4-92c8-11eb-2daa-2df3db8736bd
md"
#
"
# ╔═╡ 43539482-87e0-11eb-22c8-b9380ae1ebdb
function backwards2(grid, nperiods, π, yvec, β)
points = length(grid)
V = zeros(nperiods,points)
a = zeros(nperiods,points)
V[end,:] = sqrt.(grid) # from before: final period
a[end,:] = collect(grid)
for it in (nperiods-1):-1:1
x = Bellman2(grid, V[it+1,:], π, yvec, β)
V[it,:] = x[1]
a[it,:] = x[2]
end
return (V,a)
end
# ╔═╡ a361963a-92c8-11eb-0543-7decc61720a8
md"
#
"
# ╔═╡ 5f764692-87df-11eb-3b9d-e5823eb4d1b3
let
V,a = backwards2(Rspace,nperiods,π,yvec,β)
cg = cgrad(:viridis)
cols = cg[range(0.0,stop=1.0,length = nperiods)]
pa = plot(Rspace, a[1,:], xlab = "R", ylab = "Action",label = L"a_1",leg = :topleft, color = cols[1])
for it in 2:nperiods
plot!(pa, Rspace, a[it,:], label = L"a_{%$(it)}", color = cols[it])
end
pv = plot(Rspace, V[1,:], xlab = "R", ylab = "Value",label = L"V_1",leg = :bottomright, color = cols[1])
for it in 2:nperiods
plot!(pv, Rspace, V[it,:], label = L"V_{%$(it)}", color = cols[it])
end
plot(pv,pa, layout = (1,2))
end
# ╔═╡ 8eb731f6-87e0-11eb-35dd-61ba070afc8b
md"
#
* Well at least a little bit better.
* Still, what about those steps in there? What's going on?
"
# ╔═╡ 02d26410-87e2-11eb-0278-99ee0bbd2923
md"
## Continuous Choice
* In fact our action space is continuous here:
$$V_t(R_t) = \max_{0 \leq a_t \leq R_t} \left(u(a_t) + \beta \mathbb{E} \left[ V_{t+1}(R_{t+1}(R_t,a_t)) |R_t \right] \right)$$
* So let's treat it as such. We could direct optimization for the Bellman Operator!
#
"
# ╔═╡ 3b1f5120-87e2-11eb-1b10-85900b6fbeb6
function bellman3(grid,v0,β::Float64, π, yvec)
n = length(v0)
v1 = zeros(n) # next guess
pol = zeros(n) # consumption policy function
Interp = interpolate((collect(grid),), v0, Gridded(Linear()) )
Interp = extrapolate(Interp,Interpolations.Flat())
# loop over current states
# of current resources
for (i,r) in enumerate(grid)
objective(c) = - (sqrt.(c) + β * (π * Interp(r - c + yvec[2]) + (1-π) * Interp(r - c + yvec[1])) )
res = optimize(objective, 1e-6, r) # search in [1e-6,r]
pol[i] = res.minimizer
v1[i] = -res.minimum
end
return (v1,pol) # return both value and policy function
end
# ╔═╡ c6990bb0-92c8-11eb-2523-9f8a7ec1cd4a
md"
#
"
# ╔═╡ 0b83e920-87e3-11eb-0792-479eb843b429
function backwards3(grid, nperiods,β, π, yvec)
points = length(grid)
V = zeros(nperiods,points)
a = zeros(nperiods,points)
V[end,:] = sqrt.(grid) # from before: final period
a[end,:] = collect(grid)
for it in (nperiods-1):-1:1
x = bellman3(grid, V[it+1,:],β, π, yvec)
V[it,:] = x[1]
a[it,:] = x[2]
end
return (V,a)
end
# ╔═╡ d391139e-92c8-11eb-0888-b325a75fb10f
md"
#
"
# ╔═╡ 7003b4e8-87e3-11eb-28a9-f7e3668beac3
let
V,a = backwards3(Rspace,nperiods,β,π,yvec)
cg = cgrad(:viridis)
cols = cg[range(0.0,stop=1.0,length = nperiods)]
pa = plot(Rspace, a[1,:], xlab = "R", ylab = "Action",label = L"a_1",leg = :topleft, color = cols[1])
for it in 2:nperiods
plot!(pa, Rspace, a[it,:], label = L"a_{%$(it)}", color = cols[it])
end
pv = plot(Rspace, V[1,:], xlab = "R", ylab = "Value",label = L"V_1",leg = :bottomright, color = cols[1])
for it in 2:nperiods
plot!(pv, Rspace, V[it,:], label = L"V_{%$(it)}", color = cols[it])
end
plot(pv,pa, layout = (1,2))
end
# ╔═╡ 4504d988-87e4-11eb-05d5-c9f9f215f785
md"
#
* It's getting there!
* Much fewer wiggles in the consumption function.
* But we can do even better than that.
* Let's do *Policy Iteration* rather than *Value Iteration*!
"
# ╔═╡ 6828b538-87e4-11eb-3cdd-71c31dad5a6e
md"
## Policy Iteration
* In most economic contexts, there is more structure on a problem.
* In our consumption example, we know that the Euler Equation must hold.
* Sometimes there are other *optimality conditions* that one could leverage.
* In our case, we have this equation at an optimal policy $c^*(R_t)$:
$$\begin{align}
u'(c^*(R_t)) & = \beta \mathbb{E} \left[ u'(c(R_{t+1})) \right] \\
& = \beta \mathbb{E} \left[ u'(R_t - c^*(R_t) + y) \right]
\end{align}$$
* So: We *just* have to find the function $c^*(R_t)$!
"
# ╔═╡ ba19759c-87eb-11eb-1bec-51de9ac10e31
md"
## *Just*?
* There is a slight issue here. The Euler Equation in itself does not enforce the contraint that we cannot borrow any $R$.
* In particular, $R_{t} \geq 0$ is missing from the above equation.
* look back above at the last plot of the consumption function. It has a kink!
* The Euler Equation applies only to the *right* of that kink!
* If tomorrow's consumption is low (we are saving a lot), today's consumption is relatively high, implying that we consume more than we have in terms of $R_t$.
* Satisfying the Euler Equation would require to set $R_t <0$ sometimes, which is ruled out.
"
# ╔═╡ a4018f28-87ec-11eb-07f0-af86523dd26e
md"
#
* So if we want to use the Euler Equation, we need to manually adjust for that.
* 😩
* Alright, let's do it. It's not too bad in the end.
#
* First, let's put down the marginal utility function and it's inverse:
"
# ╔═╡ 027fda74-87f1-11eb-1441-55d6e410bf4c
u_prime(c) = 0.5 .* c.^(-0.5)
# ╔═╡ 540d8814-87f1-11eb-0b8c-23357c46f93c
u_primeinv(u) = (2 .* u).^(-2)
# ╔═╡ d2788ffe-92c4-11eb-19e7-4b41d9f9ebdd
md"
#
* We need the _inverse_ of the marginal utility function?
* Yes. Here is why. For any candidate consumption level $c_t$
$$\begin{align}
u'(c_t) & = \beta \mathbb{E} \left[ u'(c(R_{t+1})) \right] \\
u'(c_t) & = \text{RHS}
\end{align}$$
* So, if we have computed the RHS, current period optimal consumption is just
$$c_t = \left( u' \right)^{-1}\left(\text{RHS}\right)\hspace{1cm}(\text{EEresid})$$
where $\left( u' \right)^{-1}(z)$ denotes the _inverse_ of function $u'(x)$.
#
### Example
* Suppose tomorrow's consumption function _does_ have the kink at $R_{t+1} = 1.5$
* I.e. $c_{t+1}^*(R_{t+1}) = R_{t+1},\forall R_{t+1} \leq 1.5$
* Let $y_{t+1} = 1.5, R_t = 1$. Now try out consumption choice $c_t = 1$!
$$\begin{align}
R_{t+1} &= R_t - c_t+ y_{t+1} \\
&= 1 - 1 + 1.5 = 1.5 \\
\Rightarrow c_{t+1}^*(1.5) &= 1.5
\end{align}$$
because right at the kink!
* Then, the Euler equation says:
$$\begin{align}
u'(c_t) & = u'(c_{t+1}) \\
c_t & = (u')^{-1}\left(u'(c_{t+1})\right) \\
c_t & = c_{t+1} = 1.5
\end{align}$$
* Well, that in turn means that $R_t - c_t = 1 - 1.5 < 0$, i.e. we would have to borrow 0.5 units of $R$ in order to satisfy that Euler Equation!
#
"
# ╔═╡ c75eed74-87ee-11eb-3e9a-3b893294baec
function EEresid(ct::Number, # candidate current (t) consumption choice
Rt::Number, # current level of resources
cfunplus::Vector, # next period's consumption *function*
grid::Vector, # grid values on which cfunplus is defined
yvec::Vector, # vector of values for shock
β::Number, # discount factor
π::Number) # prob of high y
# next period resources, given candidate choice ct
Rplus = Rt - ct .+ yvec # a (2,1) vector: Rplus for each income level
# get implied next period consumption from cplus
# we add point (0,0) here to make sure that this is part of the grid.
citp = extrapolate(
interpolate(([0.0, grid...],), [0.0,cfunplus...], Gridded(Linear())), Interpolations.Flat())
cplus = citp.(Rplus)
RHS = β * [1-π π] * u_prime(cplus) # expecte marginal utility of tomorrows consumption
# euler residual: expression EEresid from above
r = ct .- u_primeinv(RHS)
r[1] # array of size 1
end
# ╔═╡ ae56f4e2-87f9-11eb-10fc-e3eda66e8a1f
md"
#
"
# ╔═╡ 17ea7f6a-87e7-11eb-2d3e-b9a1e771b08e
function policy_iter(grid,c0,u_prime,β::Float64, π, yvec)
c1 = zeros(length(grid)) # next guess
# loop over current states
# of current resources
for (i,r) in enumerate(grid)
# get euler residual if we consume all resources
res = EEresid(r,r,c0, grid, yvec,β , π)
if res < 0
# we consume too little today, c_t is too small for the Euler Equation.
# could only make it bigger by borrowing next period.
# but we cant! so really we are consuming all we have:
c1[i] = r
else
# no problem here: Euler Equation holds
# just need to find that ct that makes it zero:
c1[i] = fzero( x-> EEresid(x,r,c0, grid, yvec, β, π) , 1e-6, r)
end
end
return c1
end
# ╔═╡ bcca454c-87f9-11eb-0670-0d85db6b6e37
md"
#
"
# ╔═╡ c1e65340-87f9-11eb-3cd7-05f14edf71d2
md"
#
"
# ╔═╡ 6fbaac56-87e0-11eb-3d09-39a4fd293e88
PlutoUI.Resource("https://s3.getstickerpack.com/storage/uploads/sticker-pack/meme-pack-1/sticker_19.png?363e7ee56d4d8ad53813dae0907ef4c0&d=200x200")
# ╔═╡ a510ff40-9302-11eb-091e-6929367f6783
md"
# Infinite Time Problems
* Let's now introduce the infinite time version of this.
* For that purpose, let's rely on the well known Optimal Growth model:
$$\begin{align}
V(k) &= \max_{0