- [前言](#前言)
- [Linux](#linux)
- [1. 顶层目录结构](#1-顶层目录结构)
- [2. 深入理解 inode](#2-深入理解-inode)
- [inode是什么](#inode是什么)
- [inode的内容](#inode的内容)
- [inode的大小](#inode的大小)
- [inode号码](#inode号码)
- [目录文件](#目录文件)
- [inode的特殊作用](#inode的特殊作用)
- [3. 什么是硬链接与软链接](#3-什么是硬链接与软链接)
- [硬链接](#硬链接)
- [软链接](#软链接)
- [4. Linux查看CPU、内存占用的命令](#4-linux查看cpu内存占用的命令)
- [top](#top)
- [cat /proc/meminfo](#cat-procmeminfo)
- [free](#free)
- [5. 定时任务 crontab](#5-定时任务-crontab)
- [6. 文件权限](#6-文件权限)
- [7. chmod 修改权限](#7-chmod-修改权限)
- [8. 文件与目录的基本操作](#8-文件与目录的基本操作)
- [1. ls](#1-ls)
- [2. cd](#2-cd)
- [3. mkdir](#3-mkdir)
- [4. rmdir](#4-rmdir)
- [5. touch](#5-touch)
- [6. cp](#6-cp)
- [7. rm](#7-rm)
- [8. mv](#8-mv)
- [9. 获取文件内容](#9-获取文件内容)
- [1. cat](#1-cat)
- [2. tac](#2-tac)
- [3. more](#3-more)
- [4. less](#4-less)
- [5. head](#5-head)
- [6. tail](#6-tail)
- [7. od](#7-od)
- [问:Linux查看日志文件的方式](#问linux查看日志文件的方式)
- [10. 指令与文件搜索](#10-指令与文件搜索)
- [1. which](#1-which)
- [2. whereis](#2-whereis)
- [3. locate](#3-locate)
- [4. find](#4-find)
- [*. grep的使用,一定要掌握,每次都会问在文件中查找(包含匹配)](#-grep的使用一定要掌握每次都会问在文件中查找包含匹配)
- [*. 管道](#-管道)
- [11. 压缩与解压缩命令](#11-压缩与解压缩命令)
- [.zip](#zip)
- [.gz](#gz)
- [.bz2](#bz2)
- [tar](#tar)
- [.tar.gz](#targz)
- [.tar.bz2](#tarbz2)
- [12. Bash](#12-bash)
- [特性](#特性)
- [变量操作](#变量操作)
- [指令搜索顺序](#指令搜索顺序)
- [输出重定向](#输出重定向)
- [输入重定向](#输入重定向)
- [13. 正则表达式](#13-正则表达式)
- [cut](#cut)
- [grep](#grep)
- [printf](#printf)
- [awk](#awk)
- [sed](#sed)
- [14. 进程管理](#14-进程管理)
- [查看进程](#查看进程)
- [1. ps](#1-ps)
- [2. top](#2-top)
- [3. pstree](#3-pstree)
- [4. netstat](#4-netstat)
- [进程状态](#进程状态)
- [SIGCHLD](#sigchld)
- [wait()](#wait)
- [waitpid()](#waitpid)
- [孤儿进程](#孤儿进程)
- [僵尸进程](#僵尸进程)
- [15. 进程和线程的区别](#15-进程和线程的区别)
- [16. kill用法,某个进程杀不掉的原因(进入内核态,忽略kill信号)](#16-kill用法某个进程杀不掉的原因进入内核态忽略kill信号)
- [17. 包管理工具](#17-包管理工具)
- [软件类型](#软件类型)
- [发行版](#发行版)
- [18. 网络配置和网络诊断命令](#18-网络配置和网络诊断命令)
- [19. 磁盘管理](#19-磁盘管理)
- [20. VIM 三个模式](#20-vim-三个模式)
- [21. 用户管理](#21-用户管理)
- [创建用户](#创建用户)
- [删除用户](#删除用户)
- [查看所有用户](#查看所有用户)
- [普通用户改为高级用户](#普通用户改为高级用户)
- [创建的用户 SSH 生效](#创建的用户-ssh-生效)
- [22. lspci](#22-lspci)
- [23. Screen命令](#23-screen命令)
- [screen命令是什么](#screen命令是什么)
- [安装](#安装)
- [使用方法](#使用方法)
- [远程演示](#远程演示)
- [常用快捷键](#常用快捷键)
- [24. Linux 下如何查看系统版本](#24-linux-下如何查看系统版本)
- [25. 常用快捷方式](#25-常用快捷方式)
- [26. 高并发网络编程之epoll详解](#26-高并发网络编程之epoll详解)
- [参考资料](#参考资料)
- [更新日志](#更新日志)
# 前言
在本文将讲解常用的 Linux 核心知识,但并不保证知识的系统性,只列举最常见的命令和知识点。
参考资料:
- 《快乐的 Linux 命令行》
# Linux
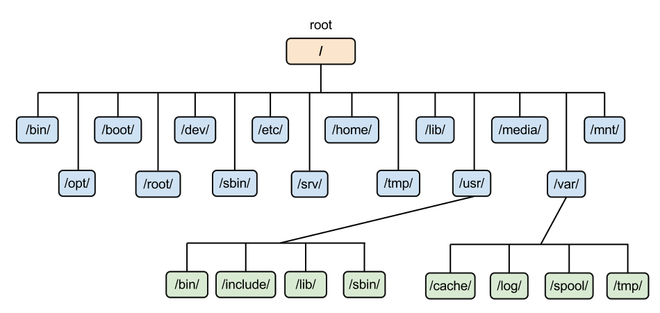
## 1. 顶层目录结构
| 目录 | 说明 |
| --------------- | ------------------------------------------------------------ |
| **/root** | 根目录,万物起源 |
| **/boot** | 包含 Linux 内核,最初的 RMA 磁盘映像(系统启动时,由驱动程序所需),和启动加载程序
**有趣的文件**:
/boot/grub/grub.conf or menu.lst,被用来配置启动
加载程序
/boot/vmlinuz, Linux 内核 |
| **/bin** | 包含系统启动和运行所必须的二进制程序 |
| **/sbin** | s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序 |
| **/usr** | 这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。usr (unix software resource) |
| **/usr/bin** | 系统用户使用的应用程序 |
| **/usr/sbin** | 超级用户使用的比较高级的管理程序和系统守护程序 |
| /usr/src | 内核源代码默认的放置目录 |
| **/proc** | 系统内存的映射目录,提供内核与进程信息 |
| **/lost+found** | 一般情况下是空的,当系统非法关机后,这里就存放了一些文件,文件系统恢复时的恢复文件 |
| **/var** | 这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。存放邮件、系统日志等变化文件,存放系统或程序运行过程中的数据文件(variable) |
| **/tmp** | 这个目录是用来存放一些临时文件的 |
| **/etc** | 存放系统配置文件。它也包含一系列的 shell 脚本,在系统启动时,这些脚本会运行每个系统服务。这个目录中的任何文件应该是可读的文本文件。
`/etc/crontab`,定义自动运行的任务。
`/etc/fstab`,包含存储设备的列表,以及与他们相关的
挂载点。
`/etc/passwd`,包含用户帐号列表。 |
| **/home** | 用户主目录,在通常的配置环境下,系统会在 /home 下,给每个用户分配一个目录。普通只能在他们自己的目录下创建文件。这个限制保护系统免受错误的用户活动破坏。 |
| **/dev** | 这是一个包含设备结点的特殊目录。“一切都是文件”,也使用于设备。在这个目录里,内核维护着它支持的设备 |
| **/lib** | 动态连接共享库,`.so` 文件,类似于 Windows 里的 dll 文件。 |
| **/mnt** | 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。 |
| **/media** | 系统会自动识别一些设备,例如 U 盘、光驱等等,把识别的设备挂载到这个目录下。 |
| /sys | sys 虚拟文件系统挂载点 |
| /srv | 存放服务相关数据 |
| /opt | 这是给主机额外安装软件所摆放的目录。比如你安装一个 ORACLE 数据库则就可以放到这个目录下。默认是空的。 |
| /srv | 该目录存放一些服务启动之后需要提取的数据。 |
| /selinux | 这个目录是 Redhat/CentOS 所特有的目录,Selinux 是一个安全机制,类似于windows 的防火墙,但是这套机制比较复杂,这个目录就是存放selinux 相关的文件的。 |
**问:proc下都放什么文件?**
- 此目录的所有数据都在内存里,如 系统核心,外部设备,网络状态。由于所有数据都储存在内存里,所以不占用磁盘空间; 这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
```shell
more /proc/meminfo
```
- 这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的 ping 命令,使别人无法 ping 你的机器:
```shell
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
```
**注意事项**
在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
- **/etc:** 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
- **/bin, /sbin, /usr/bin, /usr/sbin:** 这是系统预设的执行文件的放置目录,比如 ls 就是在 /bin/ls 目录下的。
- 值得提出的是,**/bin, /usr/bin** 是给系统用户使用的指令(除 root 外的通用户)
- 而**/sbin, /usr/sbin** 则是给 root 使用的指令。
- **/var:** 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。
总而言之,在Linux中一切皆文件!
## 2. 深入理解 inode
### inode是什么
理解 inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做 "扇区"(Sector)。每个扇区储存 512 字节(相当于 0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是 4KB,即连续八个 sector 组成一个 block。
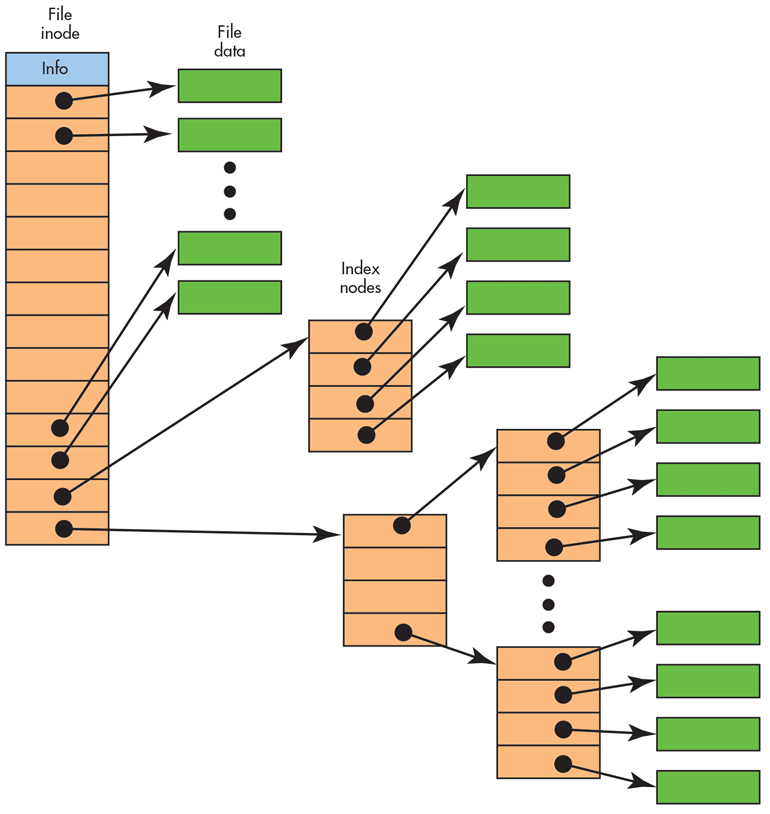
文件数据都储存在 "块" 中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做 inode,中文译名为 "索引节点"。
每一个文件都有对应的 inode,里面包含了与该文件有关的一些信息。
### inode的内容
node 包含文件的元信息,具体来说有以下内容:
```
* 文件的字节数
* 文件拥有者的 User ID
* 文件的 Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime:指inode上一次变动的时间,mtime:指文件内容上一次变动的时间,atime:指文件上一次打开的时间。
* 链接数,即有多少文件名指向这个inode
* 文件数据block的位置
```
可以用 stat 命令,查看某个文件的 inode 信息:
```
$ stat abby.txt
File: ‘abby.txt’
Size: 22 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 2106782 Links: 2
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2018-07-22 16:37:18.640787898 +0800
Modify: 2018-07-22 16:37:10.678607855 +0800
Change: 2018-07-22 16:37:10.833611360 +0800
Birth: -
```
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
### inode的大小
inode 也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是**数据区**,存放文件数据;另一个是 **inode 区**(inode table),存放 inode 所包含的信息。
每个 inode 节点的大小,一般是 128 字节或 256 字节。inode 节点的总数,在格式化时就给定,一般是每 1KB 或每 2KB 就设置一个 inode。假定在一块 1GB 的硬盘中,每个 inode 节点的大小为 128 字节,每 1KB 就设置一个 inode,那么 inode table 的大小就会达到 128 MB,占整块硬盘的 12.8%。
查看每个硬盘分区的 inode 总数和已经使用的数量,可以使用df 命令。
```shell
$ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda1 3932160 189976 3742184 5% /
devtmpfs 998993 339 998654 1% /dev
tmpfs 1001336 1 1001335 1% /dev/shm
tmpfs 1001336 397 1000939 1% /run
tmpfs 1001336 16 1001320 1% /sys/fs/cgroup
tmpfs 1001336 1 1001335 1% /run/user/0
```
查看每个 inode 节点的大小,可以用如下命令:
```shell
$ sudo dumpe2fs -h /dev/vda1 | grep "Inode size"
dumpe2fs 1.42.9 (28-Dec-2013)
Inode size: 256
```
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
### inode号码
每个 inode 都有一个号码,操作系统用 inode 号码来识别不同的文件。
这里值得重复一遍,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。对于系统来说,文件名只是 inode 号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的 inode 号码;其次,通过 inode 号码,获取 inode 信息;最后,根据 inode 信息,找到文件数据所在的 block,读出数据。
使用 `ls -i` 命令,可以看到文件名对应的 inode 号码:
```shell
$ ls -i test.txt
1712426 test.txt
```
### 目录文件
Unix/Linux 系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的 inode 号码。
ls 命令只列出目录文件中的所有文件名:
```shell
ls /etc
```
ls -i 命令列出整个目录文件,即文件名和 inode 号码:
```shell
ls -i /etc
```
如果要查看文件的详细信息,就必须根据 inode 号码,访问 inode 节点,读取信息。`ls -l` 命令列出文件的详细信息。
```shell
ls -l /etc
```
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和 inode 号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在 inode 节点中,而读取 inode 节点内的信息需要目录文件的执行权限(x)。
### inode的特殊作用
由于 inode 号码与文件名分离,这种机制导致了一些 Unix/Linux 系统特有的现象。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除 inode 节点,就能起到删除文件的作用。
2. 移动文件或重命名文件,只是改变文件名,不影响 inode 号码。
3. 打开一个文件以后,系统就以 inode 号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从 inode 号码得知文件名。
第 3 点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的 inode 则被回收。
## 3. 什么是硬链接与软链接
### 硬链接
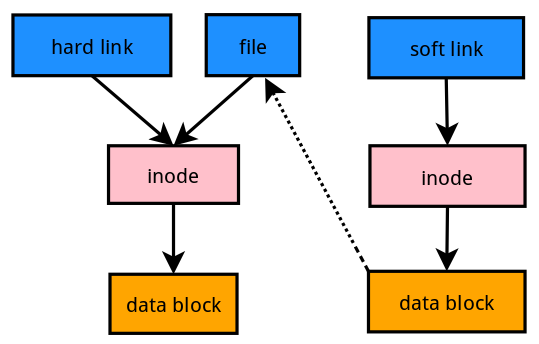
一般情况下,文件名和 inode 号码是 "一一对应" 关系,每个 inode 号码对应一个文件名。但是,Unix/Linux 系统允许,多个文件名指向同一个 inode 号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为 "硬链接"(hard link)。
运行上面这条命令以后,源文件与目标文件的 inode 号码相同,都指向同一个 inode。inode 信息中有一项叫做 "链接数",记录指向该 inode 的文件名总数,这时就会增加 1。
反过来,删除一个文件名,就会使得 inode 节点中的 "链接数" 减1。当这个值减到 0,表明没有文件名指向这个 inode,系统就会回收这个 inode 号码,以及其所对应 block 区域。
这里顺便说一下目录文件的 "链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的 inode 号码就是当前目录的 inode 号码,等同于当前目录的 "硬链接";后者的 inode 号码就是当前目录的父目录的inode号码,等同于父目录的 "硬链接"。所以,任何一个目录的 "硬链接" 总数,总是等于 2 加上它的子目录总数(含隐藏目录)。
几个硬连接=几个名字的同一个房子
**硬链接(Hard Link)**:硬连接不能跨越不同的文件系统,硬连接记录的是目标的 inode;只能指向文件。硬连接与原始文件都删除才意味着文件被删除。
- 特征
- 拥有相同的 i 节点和存储 block 块,可以看做是同一个文件
- 可通过 i 节点识别
- 不能跨分区
- 不能针对目录使用
### 软链接
除了硬链接以外,还有一种特殊情况。
文件 A 和文件 B 的 inode 号码虽然不一样,但是文件 A 的内容是文件 B 的路径。读取文件 A 时,系统会自动将访问者导向文件 B。因此,无论打开哪一个文件,最终读取的都是文件 B。这时,文件 A 就称为文件 B 的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件 A 依赖于文件 B 而存在,如果删除了文件 B,打开文件 A 就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件 A 指向文件 B 的文件名,而不是文件 B 的 inode 号码,文件 B 的 inode "链接数"不会因此发生变化。
几个软链接=几个指向源文件的路标
**软链接(Symbolic Link,又称符号链接)**:软链接能跨越不同的文件系统,软链接记录的是目标的 path。源文件删除后,则软链接无效。**相当于Windows系统中的“快捷方式”**
- 特征:
- 类似 windows 的快捷方式
- 软链接拥有自己的 i 节点和 block 块,但是数据块中只保存原文件的文件名和 i 节点号,并没有实际的文件数据
- 修改任意一个文件,另一个都会改变
- 删除源文件,则软链接无法使用
- 软链接的文件权限都为 rwxrwxrwx (文件权限以原文件为准)
- 若要创建软链接,则创建的源文件必须使用绝对路径,否则在使用软链接时会报错
注意:复制是建造一个一模一样的房子,inode是不同的。
命令
```
硬链接:ln 源文件 链接名
软链接:ln -s 源文件 链接名
```
区别: 若将源文件删除,硬链接依旧有效,而软链接会无效,即找不到源文件
参考资料:
- [ln命令_Linux ln 命令用法详解:用来为文件创件连接](http://man.linuxde.net/ln)
- [linux 硬链接与软连接简单的对比试验_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili](https://www.bilibili.com/video/av9769329?from=search&seid=5663546178393951142)
- [【 linux从入门到放弃】10:文件和文件夹进阶inode_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili](https://www.bilibili.com/video/av6068432?from=search&seid=12178075587929134931)
## 4. Linux查看CPU、内存占用的命令
### top
**top命令**可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理。
### cat /proc/meminfo
查看RAM使用情况最简单的方法是通过 `/proc/meminfo`。这个动态更新的虚拟文件实际上是许多其他内存相关工具(如:free / ps / top)等的组合显示。`/proc/meminfo` 列出了所有你想了解的内存的使用情况。
### free
free 命令是一个快速查看内存使用情况的方法,它是对 `/proc/meminfo` 收集到的信息的一个概述。
这个命令用于显示系统当前内存的使用情况,包括已用内存、可用内存和交换内存的情况
默认情况下 free 会以字节为单位输出内存的使用量
```shell
$ free
total used free shared buffers cached
Mem: 3566408 1580220 1986188 0 203988 902960
-/+ buffers/cache: 473272 3093136
Swap: 4000176 0 4000176
```
如果你想以其他单位输出内存的使用量,需要加一个选项,`-g` 为GB,`-m` 为MB,`-k` 为KB,`-b` 为字节
```shell
$ free -g
total used free shared buffers cached
Mem: 3 1 1 0 0 0
-/+ buffers/cache: 0 2
Swap: 3 0 3
```
如果你想查看所有内存的汇总,请使用 -t 选项,使用这个选项会在输出中加一个汇总行
```shell
$ free -t
total used free shared buffers cached
Mem: 3566408 1592148 1974260 0 204260 912556
-/+ buffers/cache: 475332 3091076
Swap: 4000176 0 4000176
Total: 7566584 1592148 5974436
```
## 5. 定时任务 crontab
> 该词来源于希腊语chronos(χρόνος),原意是时间。
crontab 命令常见于 Unix和类 Unix 的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于 `crontab` 文件中,以供之后读取和执行。
通常,crontab 储存的指令被守护进程激活,crond 常常在后台运行,每一分钟检查是否有预定的作业需要执行。这类作业一般称为 cron jobs。
**crontab文件**
crontab 文件包含送交 cron 守护进程的一系列作业和指令。每个用户可以拥有自己的 crontab 文件;同时,操作系统保存一个针对整个系统的 crontab 文件,该文件通常存放于/etc或者/etc之下的子目录中,而这个文件只能由系统管理员来修改。
crontab 文件的每一行均遵守特定的格式,由空格或 tab 分隔为数个领域,每个领域可以放置单一或多个数值。
```shell
# cron服务是Linux的内置服务,但它不会开机自动启动。
# 可以用以下命令启动和停止服务:
/sbin/service crond start
/sbin/service crond stop
/sbin/service crond restart
/sbin/service crond reload
```
要把 cron 设为在开机的时候自动启动,在 `/etc/rc.d/rc.local` 脚本中加入 `/sbin/service crond start` 即可
查看当前用户的 crontab,输入 crontab -l;
编辑 crontab,输入 crontab -e;
删除 crontab,输入 crontab -r
**操作符号**
在一个区域里填写多个数值的方法:
逗号(',')分开的值,例如:“1,3,4,7,8”
连词符('-')指定值的范围,例如:“1-6”,意思等同于“1,2,3,4,5,6”
星号('*')代表任何可能的值。例如,在“小时域”里的星号等于是“每一个小时”,等等
某些cron程序的扩展版本也支持斜线('/')操作符,用于表示跳过某些给定的数。例如,“/3”在小时域中等于“0,3,6,9,12,15,18,21”等被3整除的数;
**时间设置**
```linux
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 7,星期日=0或7)
# | | | | |
# * * * * * 被执行的命令
```
注:
1. 在“星期域”(第五个域),0和7都被视为星期日。
2. 不很直观的用法:如果日期和星期同时被设定,那么其中的一个条件被满足时,指令便会被执行。请参考下例。
3. 前5个域称之**分时日月周**,可方便个人记忆。
从第六个域起,指明要执行的命令。
**实例**
每1分钟执行一次command
```shell
* * * * * command
```
每小时的第3和第15分钟执行
```shell
3,15 * * * * command
```
在上午8点到11点的第3和第15分钟执行
```shell
3,15 8-11 * * * command
```
每隔两天的上午8点到11点的第3和第15分钟执行
```shell
3,15 8-11 */2 * * command
```
### 应用场景:定时备份MySQL数据库
**参考资料**:
- [crontab命令_Linux crontab 命令用法详解:提交和管理用户的需要周期性执行的任务](http://man.linuxde.net/crontab)
## 6. 文件权限
- `Type`: 很多种 (最常见的是 `-` 为文件, `d` 为文件夹, 其他的还有`l`, `n` … 这种东西, 真正自己遇到了, 网上再搜就好, 一次性说太多记不住的).
- d:目录
- -:文件
- l:链接文件
- `User`: 后面跟着的三个空是使用 User 的身份能对这个做什么处理 (`r` 可读; `w` 可写; `x可`执行; `-` 不能完成某个操作).
- `Group`: 一个 Group 里可能有一个或多个 user, 这些权限的样式和 User 一样.
- `Others`: 除了 User 和 Group 以外人的权限.
- `.`:代表 ACL 权限
如果有朋友对 User, group, others 这几个没什么概念的话, 我这里补充一下. User 一般就是指你, 这个正在使用电脑的人. Group 是一个 User 的集合, 最开始创建新 User 的时候, 他也为这个 User 创建了一个和 User 一样名字的 Group, 这个新 Group 里只有这个 User. 一般来说, 像一个企业部门的电脑, 都可以放在一个 Group 里, 分享了一些共享文件和权限. Others 就是除了上面提到的 User 和 Group 以外的人.
**文件时间有以下三种:**
- modification time (mtime):文件的内容更新就会更新;
- status time (ctime):文件的状态(权限、属性)更新就会更新;
- access time (atime):读取文件时就会更新。
## 7. chmod 修改权限
可以将一组权限用数字来表示,此时一组权限的 3 个位当做二进制数字的位,从左到右每个位的权值为 4. 2. 1,即每个权限对应的数字权值为 `r:4,w:2,x:1`。
```shell
# chmod [-R] xyz dirname/filename
```
示例:将 .bashrc 文件的权限修改为 -rwxr-xr--。
```shell
# chmod 754 .bashrc
```
也可以使用符号来设定权限。
```shell
# chmod [ugoa] [+-=] [rwx] dirname/filename
- u:拥有者
- g:所属群组
- o:其他人
- a:所有人
- +:添加权限
- -:移除权限
- =:设定权限
```
示例:为 .bashrc 文件的所有用户添加写权限。
```shell
# chmod a+w .bashrc
```
参考资料:
- [Linux 文件权限 - Linux 简易教学 | 莫烦Python](https://morvanzhou.github.io/tutorials/others/linux-basic/3-01-file-permissions/)
- [带你玩转Linux命令行(基础入门篇) - CSDN博客](https://blog.csdn.net/u012104219/article/details/79125771)
## 8. 文件与目录的基本操作
### 1. ls
列出文件或者目录的信息,目录的信息就是其中包含的文件。
```
# ls [-aAdfFhilnrRSt] file|dir
-a :列出全部的文件
-d :仅列出目录本身
-l :以长数据串行列出,包含文件的属性与权限等等数据
```
### 2. cd
更换当前目录。
```
cd [相对路径或绝对路径]
```
### 3. mkdir
创建目录。
```
# mkdir [-mp] 目录名称
-m :配置目录权限
-p :递归创建目录(这个很常用)
```
### 4. rmdir
删除目录,目录必须为空。
```
rmdir [-p] 目录名称
-p :递归删除目录
```
### 5. touch
更新文件时间或者建立新文件。
```
# touch [-acdmt] filename
-a : 更新 atime
-c : 更新 ctime,若该文件不存在则不建立新文件
-m : 更新 mtime
-d : 后面可以接更新日期而不使用当前日期,也可以使用 --date="日期或时间"
-t : 后面可以接更新时间而不使用当前时间,格式为[YYYYMMDDhhmm]
```
### 6. cp
复制文件。
如果源文件有两个以上,则目的文件一定要是目录才行。
```
cp [-adfilprsu] source destination
-r 复制目录
-p 连带文件属性复制
-d 若源文件是链接文件,则复制链接属性
-a 相当于 -pdr,包括文件的时间信息等.
```
### 7. rm
删除文件。
```
# rm [-fir] 文件或目录
-r :递归删除
```
### 8. mv
移动文件。
```
# mv [-fiu] source destination
# mv [options] source1 source2 source3 .... directory
-f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
```
## 9. 获取文件内容
### 1. cat
取得文件内容。
```
# cat [-AbEnTv] filename
-n :打印出行号,连同空白行也会有行号,-b 不会
```
### 2. tac
是 cat 的反向操作,从最后一行开始打印。
### 3. more
和 cat 不同的是它可以一页一页查看文件内容,比较适合大文件的查看。
- 按 Space 键:显示文本的下一屏内容。
- 按 Enter 键:只显示文本的下一行内容。
- 按斜线符 `/` :接着输入一个模式,可以在文本中寻找下一个相匹配的模式。
- 按 H 键:显示帮助屏,该屏上有相关的帮助信息。
- 按 B 键:显示上一屏内容。
- 按 Q 键:退出 more 命令。
### 4. less
和 more 类似,但是多了一个向前翻页的功能。
### 5. head
取得文件前几行。
```
# head [-n number] filename
-n :后面接数字,代表显示几行的意思
```
### 6. tail
是 head 的反向操作,只是取得是后几行。
### 7. od
以字符或者十六进制的形式显示二进制文件。
### 问:Linux查看日志文件的方式
- /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
- /var/log/secure 与安全相关的日志信息
- /var/log/maillog 与邮件相关的日志信息
- /var/log/cron 与定时任务相关的日志信息
- /var/log/spooler 与UUCP和news设备相关的日志信息
- /var/log/boot.log 守护进程启动和停止相关的日志消息
- /var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件
## 10. 指令与文件搜索
### 1. which
指令搜索。
- 搜索系统命令所在路径及别名
- PATH环境变量:定义的是系统搜索命令的路径
```
echo $PATH
```
```
# which [-a] command
-a :将所有指令列出,而不是只列第一个
```
### 2. whereis
文件搜索。搜索系统命令所在路径及帮助文档所在位置。速度比较快,因为它只搜索几个特定的目录。
```
# whereis [-bmsu] dirname/filename
```
选项:
- -b 只查找可执行文件
- -m 只查找帮助文件
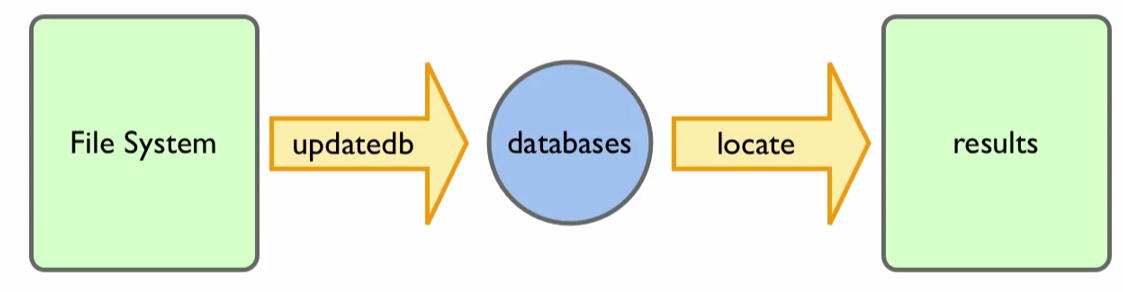
### 3. locate
文件搜索。可以用关键字或者正则表达式进行搜索。
**注意:** locate 是从数据库中读取数据(`/var/lib/mlocate`),而不是从文件系统中读取。从数据库中读取时是读取 updatedb 命令返回的结果,而 updatedb 命令默认是一天(24小时)才自动运行一次,这就意味着如果是最新创建的文件,使用 locate 命令可能查找不到。
**解决方法:**
在使用 locate命令前,先手动运行updatedb命令(需要 root 权限):`sudo updatedb`
```shell
# locate安装
sudo yum install mlocate
updatedb
```
**实例**
搜索 etc 目录下所有以 sh 开头的文件:
```
locate /etc/sh
```
搜索用户主目录下,所有以m开头的文件:
```
locate ~/m
```
搜索用户主目录下,所有以m开头的文件,并且忽略大小写:
```
locate -i ~/m
```
### 4. find
- find 搜索范围
搜索文件
- `find / -name install.log`
避免大范围搜索,会非常耗费系统资源
find 是在系统当中搜索符合条件的文件名。如果需要匹配,使用通配符匹配,通配符是完全匹配。
- Linux 通配符
```
* 匹配任意内容
? 匹配任意一个字符
[] 匹配任意一个中括号内的字符
```
- `find /root -iname install.log`
不区分大小写
- `find /root -user root`
按照所有者搜索
- `find /root -nouser`
查找没有所有者的文件
- `find /var/log/ -mtime +10`
查找 10 天前修改的文件
```
-10 10天内修改的文件
10 10天当天修改的文件
+10 10天前修改的文件
atime 文件访问时间
ctime 改变文件属性
mtime 修改文件内容
```
- `find . -size 25k`
查找文件大小是 25kb 的文件
```
-25k 小于25kb的文件
25k 等于25kb的文件
+25k 大于25kb的文件
```
- `find . -inum 262422`
查找 i 节点是 262422 的文件
- `find /etc/ -size +20k -a -size -50k`
查找 /etc/ 目录下,大于 20k 并且小于 50k 的文件
- -a and 逻辑与,两个条件都满足
- -o or 逻辑或,两个条件满足一个即可
- `find /etc/ -size +20k -a -size -50k -exec ls -lh {} ;`
查找/etc/目录下,大于20k并且小于50k的文件,并显示详细信息
-exec/ 命令 {} ; 对搜索结果执行操作
### *. grep的使用,一定要掌握,每次都会问在文件中查找(包含匹配)
**grep**(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
例子:在目录~/test下递归查找包含字符串 "hello" 的所有文件,并显示匹配行的行号
```shell
$ grep -Rn "hello" ~/test
/home/slot/test/aa:1:hello world!
/home/slot/test/cc:1:hello world!
/home/slot/test/bb:1:hello world!
```
### *. 管道
管线是将一个命令的标准输出作为另一个命令的标准输入,在数据需要经过多个步骤的处理之后才能得到我们想要的内容时就可以使用管线。
在命令之间使用 | 分隔各个管线命令。
```
$ ls -al /etc | less
```
查看已经建立TCP请求的个数
```
netstat -an | grep ESTABLISHED| wc -l
```
- 子进程从父进程继承文件描述符
- file descriptor 0 stdin, 1 stdout, 2stderr
- 进程不知道(或不关心!)从键盘,文件,程序读取或写入到终端,文件,程序。
- shell( # ls | more)
- 创建管道
- 为 ls 创建一个进程,设置 stdout 为管道写端
- 为 more 创建一个进程,设置 stdin 为管道读端
参考资料
- [Linux查找命令 - 简书](https://www.jianshu.com/p/72c579528337)
## 11. 压缩与解压缩命令
常用压缩格式如下:
| 扩展名 | 压缩程序 |
| --------- | ------------------------------------- |
| *.zip | zip |
| *.gz | gzip |
| *.bz2 | bzip2 |
| *.tar | tar 程序打包的数据,没有经过压缩 |
| *.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
| *.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
### .zip
(一)压缩
- zip 压缩文件名 源文件
压缩文件
- zip -r 压缩文件名 源目录
压缩目录
(二)解压缩
- unzip 压缩文件
解压.zip文件
### .gz
(一)压缩
- gzip 源文件
压缩为.gz格式的压缩文件,源文件会消失
- gzip -c 源文件 > 压缩文件
压缩为.gz格式的压缩文件,源文件保留
> 注:-c是将压缩的格式不写入新文件,打印到屏幕上,利用输出重定向造成一个既压缩.gz格式源文件也不消失的现象。但是gzip本身是不支持保留源文件压缩的。
- gzip -r 目录
压缩目录下所有的子文件,但是不能压缩目录
(二)解压缩
- gzip -d 压缩文件
解压缩文件
- gunzip 压缩文件
解压缩文件
### .bz2
(一)压缩
- bzip2 源文件
压缩为.bz2格式,不能保留源文件
- bzip2 -k 源文件
压缩之后保留源文件
- 注意:bzip2命令不能压缩目录
(二)解压缩
- bzip2 -d 压缩文件
解压缩,-k保留压缩文件
- bunzip2 压缩文件
解压缩,-k保留压缩文件
### tar
将一个目录打包成文件.tar格式,这样 `.gz` 和 `.bz2` 可压缩,解压缩目录
- tar -cvf 打包文件名 源文件
- 选项:
```
-c 打包
-x 解打包
-v 显示过程
-f 指定打包后的文件名
```
解打包命令
- tar -xvf 打包文件名
### .tar.gz
- 其实.tar.gz格式是先打包为.tar格式,再压缩为.gz格式
- tar -zcvf 压缩包名.tar.gz 源文件
- 选项:
-z: 压缩为.tar.gz格式
- tar -zxvf 压缩包名.tar.gz
- 选项:
-x: 解压缩.tar.gz格式
### .tar.bz2
其实 `.tar.gz` 格式是先打包成 `.tar` 格式,再压缩为 `.gz` 格式
- tar -jcvf 压缩包名 .tar.bz2 源文件
- 选项:
-z:压缩为.tar.gz格式
-j:支持bzip2解压文件
- tar -jxvf 压缩包名.tar.bz2
- 选项:
-x: 解压缩.tar.gz格式
tar命令参考选项
```shell
-A或--catenate:新增文件到以存在的备份文件;
-B:设置区块大小;
-c或--create:建立新的备份文件;
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
-d:记录文件的差别;
-x或--extract或--get:从备份文件中还原文件;
-t或--list:列出备份文件的内容;
-z或--gzip或--ungzip:通过gzip指令处理备份文件;
-Z或--compress或--uncompress:通过compress指令处理备份文件;
-f<备份文件>或--file=<备份文件>:指定备份文件;
-v或--verbose:显示指令执行过程;
-r:添加文件到已经压缩的文件;
-u:添加改变了和现有的文件到已经存在的压缩文件;
-j:支持bzip2解压文件;
-v:显示操作过程;
-l:文件系统边界设置;
-k:保留原有文件不覆盖;
-m:保留文件不被覆盖;
-w:确认压缩文件的正确性;
-p或--same-permissions:用原来的文件权限还原文件;
-P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号;
-N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;
--exclude=<范本样式>:排除符合范本样式的文件。
```
参考资料:
- [Linux达人养成记课程笔记](https://github.com/wangworld/hexo-blog/blob/8e95371d51f18a06b2800caf45b14c4505a6a8db/source/_posts/Linux%E5%91%BD%E4%BB%A4%E5%AD%A6%E4%B9%A0.md)
## 12. Bash
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。可以通过 Shell 请求内核提供服务,Bash 正是 Shell 的一种。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
Shell 编程跟 Java、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- **Bourne Again Shell(/bin/bash)**
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
- ……
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 **#!/bin/sh**,它同样也可以改为 **#!/bin/bash**。
\#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
参考资料:
- [Linux脚本开头#!/bin/bash和#!/bin/sh是什么意思以及区别 - CSDN博客](https://blog.csdn.net/y_hanxiao/article/details/78638479)
### 特性
- 命令历史:记录使用过的命令
- 命令与文件补全:快捷键:tab
- 命名别名:例如 lm 是 ls -al 的别名
- shell scripts
- 通配符:例如 ls -l /usr/bin/X* 列出 /usr/bin 下面所有以 X 开头的文件
### 变量操作
对一个变量赋值直接使用 =。
对变量取用需要在变量前加上 $ ,也可以用 ${} 的形式;
输出变量使用 echo 命令。
```
$ x=abc
$ echo $x
$ echo ${x}
```
变量内容如果有空格,必须使用双引号或者单引号。
- **双引号内的特殊字符可以保留原本特性**,例如 x="lang is $LANG",则 x 的值为 lang is zh_TW.UTF-8;
- **单引号内的特殊字符就是特殊字符本身**,例如 x='lang is \$LANG',则 x 的值为 lang is $LANG。
可以使用 `指令` 或者 (指令) 的方式将指令的执行结果赋值给变量。例如 version=(uname -r),则 version 的值为 4.15.0-22-generic。
可以使用 export 命令将自定义变量转成环境变量,环境变量可以在子程序中使用,所谓子程序就是由当前 Bash 而产生的子 Bash。
Bash 的变量可以声明为数组和整数数字。注意数字类型没有浮点数。如果不进行声明,默认是字符串类型。变量的声明使用 declare 命令:
```
$ declare [-aixr] variable
-a : 定义为数组类型
-i : 定义为整数类型
-x : 定义为环境变量
-r : 定义为 readonly 类型
```
使用 [ ] 来对数组进行索引操作:
```
$ array[1]=a
$ array[2]=b
$ echo ${array[1]}
```
### 指令搜索顺序
- 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
- 由别名找到该指令来执行;
- 由 Bash 内建的指令来执行;
- 按 $PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
### 输出重定向
重定向指的是使用文件代替标准输入、标准输出和标准错误输出。
| 设备 | 类型 | 设备文件名 | 文件描述符 | 运算符 |
| ------ | ------------ | ----------- | ---------- | --------- |
| 键盘 | 标准输入 | /dev/stdin | 0 | < 或 << |
| 显示器 | 标准输出 | /dev/stdout | 1 | > 或 >> |
| 显示器 | 标准错误输出 | /dev/stderr | 2 | 2> 或 2>> |
其中,**有一个箭头(>或者<)的表示以覆盖的方式重定向**,**而有两个箭头(>>或者<<)的表示以追加的方式重定向**。
可以将不需要的标准输出以及标准错误输出重定向到 `/dev/null`(黑洞),相当于扔进垃圾箱。
**注意:**在错误输出的时候 `2>` 或 `2>>` 后加文件名不能出现空格
```
$ llc 2>index.txt
$ cat index.txt
程序“llc”尚未安装。 您可以使用以下命令安装:
sudo apt install llvm
```
在实际的应用中,上面的写法有一定问题,因为我们编写的时候并不能确定我们写的是正确的还是错误的,也就无法确定写入正确的文件还是错误的文件,因此这里仅作了解,用处不大。
**正确输出和错误输出同时保存:**
| 命令 | 例子 | 说明 |
| ------------------------ | ---------------------------------- | -------------------------------------------------------- |
| 命令 > 文件 2>&1 | ll > abby.txt 2>&1 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中 |
| **命令 >> 文件 2>&1** | ll >> abby.txt 2>&1 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中 |
| 命令 &>文件 | llc &> abby.txt | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中 |
| **命令&>>文件** | llc &>> abby.txt | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中 |
| **命令>>文件1 2>>文件2** | netstat >>success.txt 2>>error.txt | 把正确的输出追加到文件1中,把错误的输出追加到文件2中 |
如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 `2>&1` 表示将标准错误输出转换为标准输出。
```
$ find /home -name .bashrc > list 2>&1
```
### 输入重定向
**wc命令** 用来计算数字。利用 wc 指令我们可以计算文件的 Byte 数、字数或是列数,若不指定文件名称,或是所给予的文件名为 “-”,则 wc 指令会从标准输入设备读取数据。
语法
```
wc(选项)(参数)
```
选项
```
-c或--bytes或——chars:只显示Bytes数;
-l或——lines:只显示列数;
-w或——words:只显示字数。
```
参数
文件:需要统计的文件列表。
参考资料:
- [Shell 教程 | 菜鸟教程](http://www.runoob.com/linux/linux-shell.html)
## 13. 正则表达式
### cut
cut 对数据进行切分,取出想要的部分。切分过程一行一行地进行。
```shell
$ cut
-d :分隔符
-f :经过 -d 分隔后,使用 -f n 取出第 n 个区间
-c :以字符为单位取出区间
```
例如有一个学生报表信息,包含No、Name、Mark、Percent:
```shell
$ cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
```
使用 `-f` 选项提取指定字段:
```shell
$ cut -f 1 test.txt
No
01
02
03
```
```shell
$ cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
```
`--complement` 选项提取指定字段之外的列(打印除了第二列之外的列):
```shell
$ cut -f2 --complement test.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
```
使用 `-d` 选项指定字段分隔符:
```shell
$ cat test2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
```
```shell
$ cut -f2 -d";" test2.txt
Name
tom
jack
alex
```
### grep
g/re/p(globally search a regular expression and print),使用正则表示式进行全局查找并打印。
```shell
$ grep [-acinv] [--color=auto] 搜寻字符串 filename
-c : 计算找到个数
-i : 忽略大小写
-n : 输出行号
-v : 反向选择,亦即显示出没有 搜寻字符串 内容的那一行
--color=auto :找到的关键字加颜色显示
```
示例:把含有 the 字符串的行提取出来(注意默认会有 --color=auto 选项,因此以下内容在 Linux 中有颜色显示 the 字符串)
```shell
$ grep -n 'the' regular_express.txt
8:I can't finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world Happy is the same with "glad".
18:google is the best tools for search keyword
```
因为 { 和 } 在 shell 是有特殊意义的,因此必须要使用转义字符进行转义。
```shell
$ grep -n 'go\{2,5\}g' regular_express.txt
```
### printf
用于格式化输出。
它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
```shell
$ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt)
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
```
### awk
是由 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 创造,awk 这个名字就是这三个创始人名字的首字母。
awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:\$n,n 为字段号,从 1 开始,$0 表示一整行。
示例 1:取出登录用户的用户名和 ip
```shell
$ last -n 5
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 (03:22)
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 (06:12)
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 (00:14)
dmtsai tty1 Fri May 29 11:55 - 12:11 (00:15)
$ last -n 5 | awk '{print $1 "\t" $3}
```
可以根据字段的某些条件进行匹配,例如匹配字段小于某个值的那一行数据。
```shell
$ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename
```
示例 2:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
```shell
$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
daemon 2
```
awk 变量:
| 变量名称 | 代表意义 |
| -------- | ---------------------------- |
| NF | 每一行拥有的字段总数 |
| NR | 目前所处理的是第几行数据 |
| FS | 目前的分隔字符,默认是空格键 |
示例 3:输出正在处理的行号,并显示每一行有多少字段
```shell
$ last -n 5 | awk '{print $1 "\t lines: " NR "\t columns: " NF}'
dmtsai lines: 1 columns: 10
dmtsai lines: 2 columns: 10
dmtsai lines: 3 columns: 10
dmtsai lines: 4 columns: 10
dmtsai lines: 5 columns: 9
```
### sed
Linux sed命令是利用script来处理文本文件。使得文本替换脚本化,操作很类似于vim
sed可依照script的指令,来处理、编辑文本文件。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
**语法**
```
sed [-hnV][-e