{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Python 101 \n",
"## Part IX.\n",
"\n",
"---\n",
"\n",
"## Web Scraping - Part III.\n",
"\n",
"### I. [SelectorGadget](https://chrome.google.com/webstore/detail/selectorgadget/mhjhnkcfbdhnjickkkdbjoemdmbfginb)\n",
"\n",
"__Making life easier to select the proper content from a website. The ones and only the ones you need.__\n",
"\n",
"1. Click on the SelectorGadget icon to activate it. It is located in the upper right corner.\n",
"2. Right after clicking it, a bar will appear in the bottom right corner of your chrome window. Also you will realise that as you start moving the cursor, things will get frames. Do not panick, this is normal!
\n",
"\n",
"3. You will probably want to get multiple instances of the same type of content (e.g. pictures from the main page of telex.hu). This program will help you select what they have in common.\n",
"4. Rules for selection:\n",
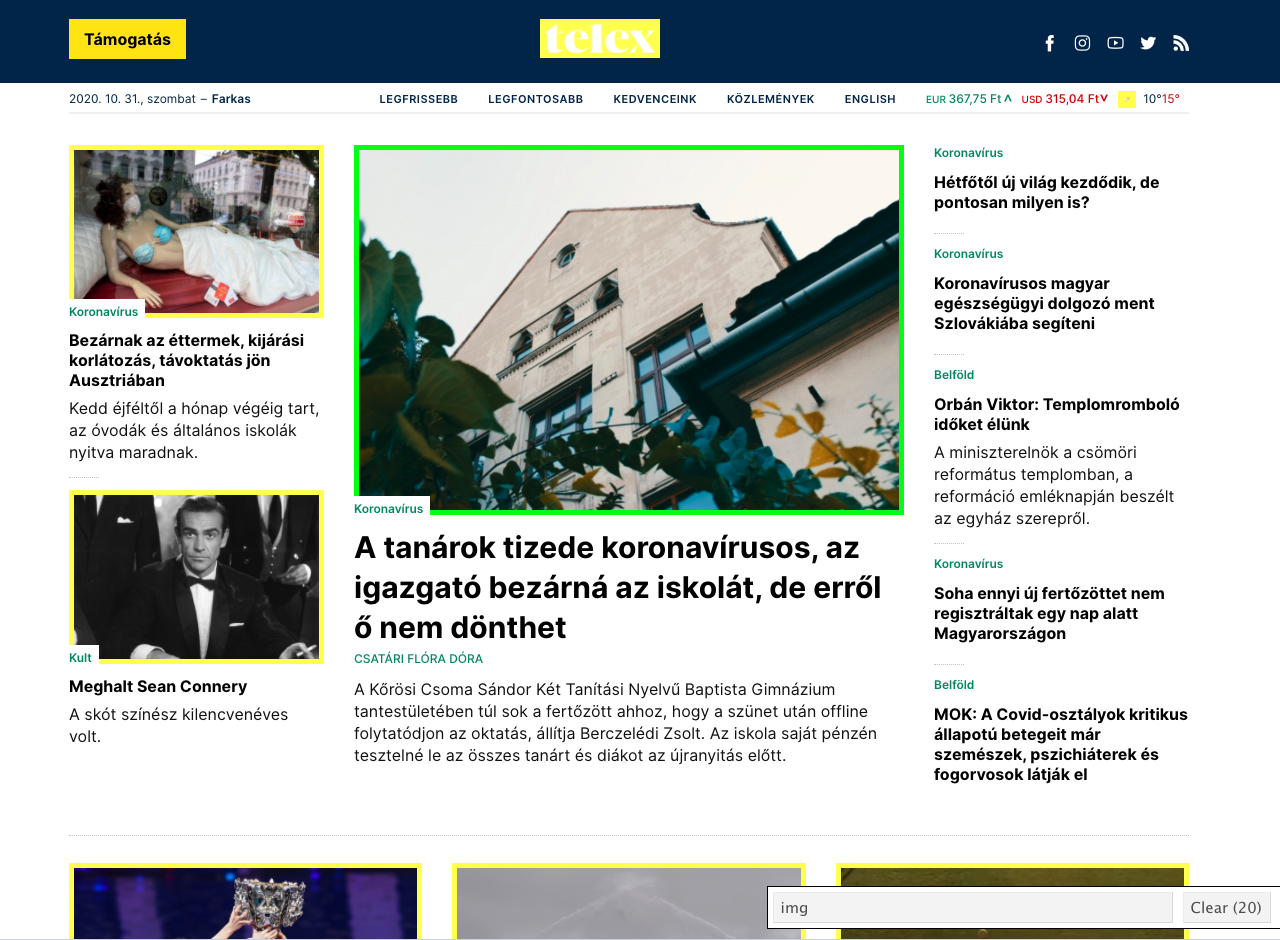
" - First click to mark an instace of the type of content you like. It will become green, other things the program thinks to be similar will become yellow.\n",
" 
\n",
" - Again, the same type of content will also be framed. If there is something you want to exclude (e.g. the telex logo at the top or the tiny weather icon), click on one of them. Starting with the second click, you may exclude anything. The program is smart enough to figure out that if you did not want the telex logo, it is likely that you will want to exclude the weather icon as well. Therefore, it is going to be removed automatically.
\n",
" 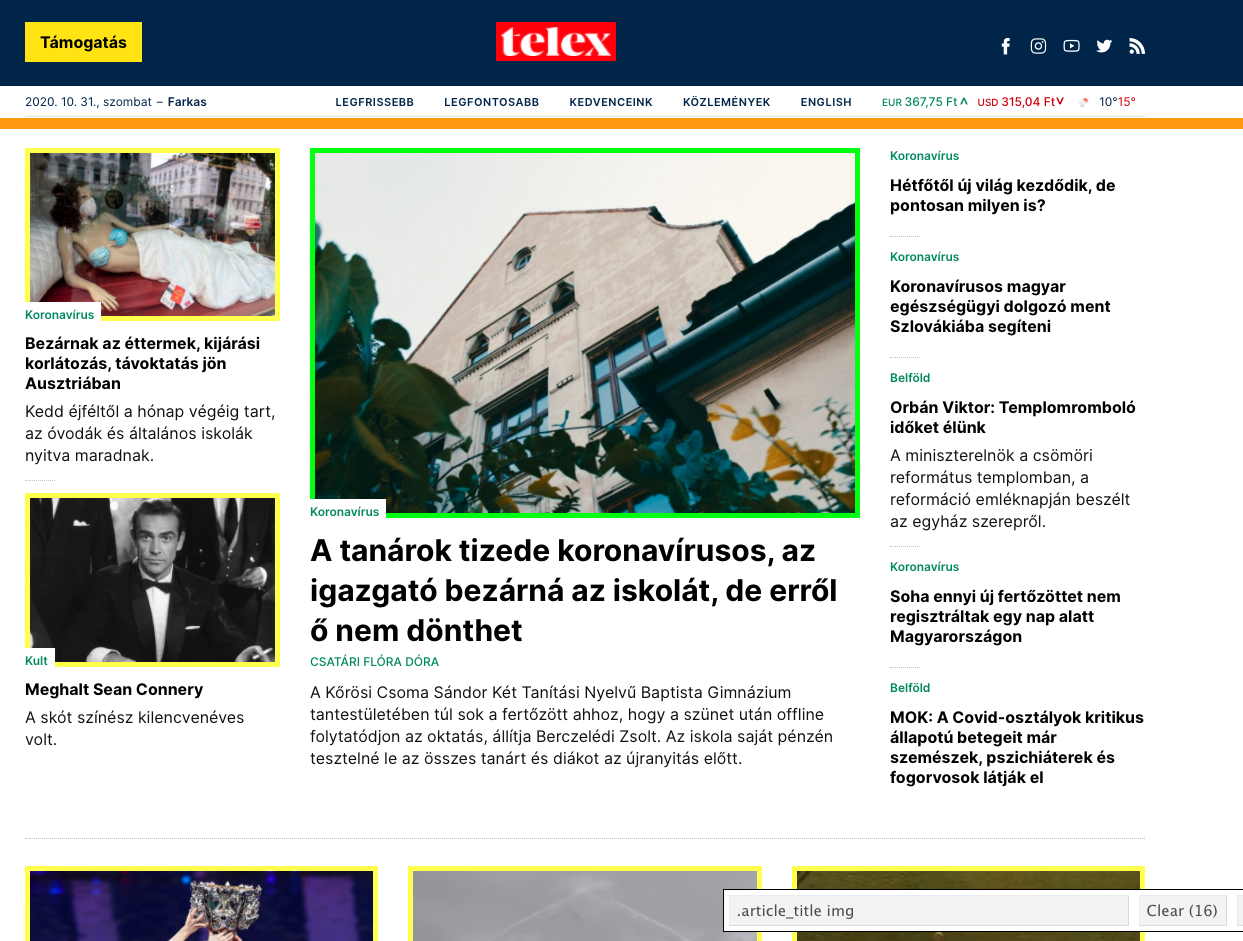\n",
"- In the bottom right corner, you will see the magic command (`.article_title img`) you should use to select all the content you want. Run `soup.select()` to get a list of instances."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As most of the sites', `telex.hu`'s code is constantly updated. The image we use above is a great example of that as you might discovered it for yourself. Today's site has a different style, layout and CSS selectors: the `img` tag itself will be enough to find the images we are looking for. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let try it!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests\n",
"from bs4 import BeautifulSoup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"url = \"https://telex.hu\"\n",
"response = requests.get(url)\n",
"soup = BeautifulSoup(response.content)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So far, this is business as usual. Let's get the pictures!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"image_list = []\n",
"for image in soup.select(\".placeholder_ img\"): # select will always return a list\n",
" image_list.append(image.get(\"src\"))\n",
"image_list"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Ooooor the way cool kids do it. List comprehension:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"[image.get(\"src\") for image in soup.select(\".placeholder_ img\")]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Exercise I: I want to be the very best...\n",
"So search for pokemon cards in [vatera.hu](https://www.vatera.hu/listings/index.php?q=pokemon+kartya) and list the card urls from the __first page__."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"USER_AGENTS = [\n",
" # Chrome OS-based laptop using Chrome browser (Chromebook)\n",
" 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36',\n",
" # Windows 7-based PC using a Chrome browser\n",
" 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36',\n",
" # Linux-based PC using a Firefox browser\n",
" 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1',\n",
" # Mac OS X-based computer using a Safari browser\n",
" 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',\n",
" # Windows 10-based PC using Edge browser\n",
" 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246',\n",
" # Playstation 4 Browser\n",
" 'Mozilla/5.0 (PlayStation 4 3.11) AppleWebKit/537.73 (KHTML, like Gecko)',\n",
"]\n",
"\n",
"import random\n",
"def get_header(agents):\n",
" return {'User-agent': random.choice(agents)}\n",
"\n",
"soup = BeautifulSoup(requests.get(\"https://www.vatera.hu/listings/index.php?q=pokemon+kartya\", headers=get_header(USER_AGENTS)).content)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Exercise II: Like no one ever was\n",
"\n",
"So catch some pieces of information on the Pokemon Cards from amazon listings. Check out pokemon cards on [amazon.de](https://www.amazon.de/s?k=pokemon+cards&language=en_GB) and get the following content for the __first page__.\n",
"- Advertisment title\n",
"- User review score\n",
"- The price\n",
"- When you could recieve the package\n",
"\n",
"Make sure you select the proper format of storing these variable! Printing them is not enough, save them!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"### II. Dynamically generated pages\n",
"\n",
"Dynamically generated pages could not be parsed by simply downloading them since the generated content won't be present. For this case there is an another library called selenium. This library also requires a browser to operate. A browser will be started and every operation will be executed inside that browser. We have to download it first (eg. from [here](https://sites.google.com/chromium.org/driver/)), then the path to the downloaded executable must be set in order to use it.\n",
"\n",
"Install selenium with:\n",
"```bash\n",
"pip install selenium\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from helpers import get_download_dir, chromedriver_download\n",
"\n",
"chromium_path = chromedriver_download(version=\"142.0.7444.59\") # check the latest version number here: https://googlechromelabs.github.io/chrome-for-testing/\n",
"os.environ['PATH'] = chromium_path + os.pathsep + os.environ['PATH']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"os.environ['PATH']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from selenium import webdriver\n",
"from selenium.webdriver.common.by import By\n",
"from selenium.common.exceptions import NoSuchElementException"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### a) Simple lookup\n",
"- initialize the browser which will be used by the library"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"driver = webdriver.Chrome()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- request a page"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"driver.get('https://bit.ly/ShuffleNav')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- find items"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" media = (\n",
" driver\n",
" .find_element(By.CSS_SELECTOR, '.post-container')\n",
" .find_element(By.TAG_NAME, 'img')\n",
" .get_attribute('src')\n",
" )\n",
"except NoSuchElementException:\n",
" media = (\n",
" driver\n",
" .find_element(By.CSS_SELECTOR, '.post-container')\n",
" .find_element(By.TAG_NAME, 'video')\n",
" .find_element(By.TAG_NAME, 'source')\n",
" .get_attribute('src')\n",
" )\n",
"\n",
"print(media)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Available alternative By classes:\n",
"- `find_element(By.ID, \"id\")`\n",
"- `find_element(By.NAME, \"name\")`\n",
"- `find_element(By.XPATH, \"xpath\")`\n",
"- `find_element(By.LINK_TEXT, \"link text\")`\n",
"- `find_element(By.PARTIAL_LINK_TEXT, \"partial link text\")`\n",
"- `find_element(By.TAG_NAME, \"tag name\")`\n",
"- `find_element(By.CLASS_NAME, \"class name\")`\n",
"- `find_element(By.CSS_SELECTOR, \"css selector\")`\n",
"\n",
"#### CSS selectors\n",
"- `tagname`\n",
"- `.classname`\n",
"- `#id`\n",
"- `[attribute=value]`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" media = (driver\n",
" .find_element(By.CSS_SELECTOR, '#individual-post .post-container img')\n",
" .get_attribute('src'))\n",
"except NoSuchElementException:\n",
" media = (driver\n",
" .find_element(By.CSS_SELECTOR, '#individual-post .post-container video source')\n",
" .get_attribute('src'))\n",
"\n",
"media\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### b) Interaction with the site\n",
"- request the page"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"driver.get('https://telex.hu')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- find accept cookies button and click on it"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cookie_agree_button = driver.find_element(By.CSS_SELECTOR, 'button#accept-btn')\n",
"cookie_agree_button.click()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- click on search button"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"search_button = driver.find_element(By.CSS_SELECTOR, '.search')\n",
"search_button.click()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- find search field"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"search_field = driver.find_element(By.CSS_SELECTOR, 'input.ti-valid.ti-new-tag-input')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- fill in search query"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"search_field.send_keys('migráns')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- find submit button and click on it"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"submit_button = driver.find_element(By.CSS_SELECTOR, 'div.ti-autocomplete li.ti-valid.ti-item')\n",
"submit_button.click()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- find related content"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"urls = []\n",
"for article in driver.find_elements(By.CSS_SELECTOR, 'div.article'):\n",
" urls.append(article.find_element(By.TAG_NAME, 'a').get_attribute('href'))\n",
"len(urls)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- solution for infinite scrolldown"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"\n",
"\n",
"def scrolldown():\n",
" lastHeight = driver.execute_script(\"return document.body.scrollHeight\")\n",
" while True:\n",
" driver.execute_script(\"window.scrollTo(0, document.body.scrollHeight);\")\n",
" time.sleep(1)\n",
" newHeight = driver.execute_script(\"return document.body.scrollHeight\")\n",
" if newHeight == lastHeight:\n",
" break\n",
" lastHeight = newHeight\n",
" return True\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"urls = []\n",
"next_page = True\n",
"page_counter, page_limit = 0, 10\n",
"\n",
"while next_page:\n",
" # report progress\n",
" print('.', end='')\n",
"\n",
" # scroll to the end of the page\n",
" scrolldown()\n",
"\n",
" # check if we have continue button at the end of the page and click on it\n",
" try:\n",
" # we are searching for a next-page button tag which does not have the type attribute set to `submit`\n",
" next_page = driver.find_element(By.CSS_SELECTOR, 'a.page__icon')\n",
" driver.get(next_page.get_attribute('href'))\n",
" page_counter += 1\n",
"\n",
" # otherwise stop the iteration\n",
" except NoSuchElementException:\n",
" next_page = False\n",
"\n",
" # telex is no longer an infinite-scroll page, so we cheat and extract the contents here\n",
" for article in driver.find_elements(By.CSS_SELECTOR, 'div.article'):\n",
" urls.append(article.find_element(By.TAG_NAME, 'a').get_attribute('href'))\n",
"\n",
"\n",
" # stop the iteration in case we hit the page limit\n",
" if page_counter > page_limit:\n",
" next_page = False\n",
"\n",
"\n",
"# In a real infinite-scroll page, we should collect all of the articles here VVV\n",
"\n",
"# after collect loading the infinite scroll page,\n",
"# find all articles and collect them into the urls list\n",
"# for article in driver.find_elements(By.CSS_SELECTOR, 'div.article'):\n",
"# urls.append(article.find_element(By.TAG_NAME, 'a').get_attribute('href'))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"len(set(urls))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"### III. Querying APIs\n",
"\n",
"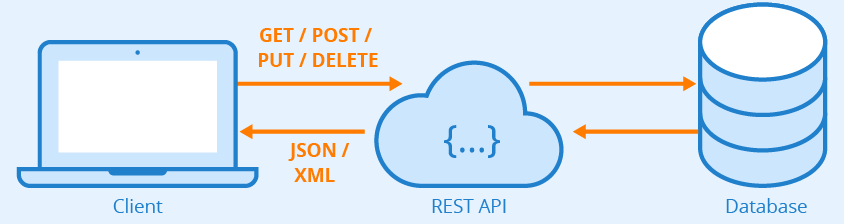\n",
"**Figure:** REST API - Author: Seobility - License: [CC BY-SA 4.0](\"/en/wiki/Creative_Commons_License_BY-SA_4.0\")\n",
"\n",
"Websites sometimes use a different approach to serve their content - instead of generating and returning a complete site, they send a skeleton of a site with javascript code snippets which queries the server for contents to dynamically populate the aforementioned site-skeleton. It is a widespread solution, most of the sites applies this approach to provide their contents. This architecture style is called a **[REST API](https://en.wikipedia.org/wiki/Representational_state_transfer)**. It has three main component:\n",
"- Client (the javascript code running in the webbrowser)\n",
"- API (the software running on a server)\n",
"- Database (the storage solution)\n",
"\n",
"The client communicates with the API (but it has no direct access to the database itself) through different commands:\n",
"- GET: the receive data\n",
"- POST: to send (and possibly receive) data\n",
"- PUT: to add new content\n",
"- DELETE: to remove content\n",
"\n",
"Throughout the communication the data is sent in a structured format, generally in [JSON](https://en.wikipedia.org/wiki/JSON) or [XML](https://en.wikipedia.org/wiki/XML). The client side code is responsible to transform the received data and populate the site.\n",
"\n",
"The API will wait for incoming commands in a so called [endpoint](https://en.wikipedia.org/wiki/Service-oriented_architecture). Some sites tell you about (expose) their endpoint directly - in this case you are encouraged to use them to gather information. Other sites don't but that doesn't mean they are not using one. We are going to use this information for our advantage."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### General algorithm to uncover and exploit REST APIs:\n",
"\n",
"__Warning #1:__ Sometimes, the direct usage of APIs is forbidden for commercial purposes. Before you start building a business on it, you might want to read the related terms and conditions of the website. Rare and non-commercial usage should not result in any actions.\n",
"\n",
"__Warning #2:__ Not every website uses REST API (or they are restricted in some ways). Therefore, this method will __not__ work in every single case. Sometimes, parsing an HTML is just not something you can avoid. However, it is surely worth checking as you may retrieve the whole dataset without having to parse and clean anything. \n",
"\n",
"__Task__: Say you want to scrape the departing flights for a given day from [Budapest Liszt Ferenc Airport](https://www.bud.hu/indulo_jaratok). You need every detail that is accessible."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
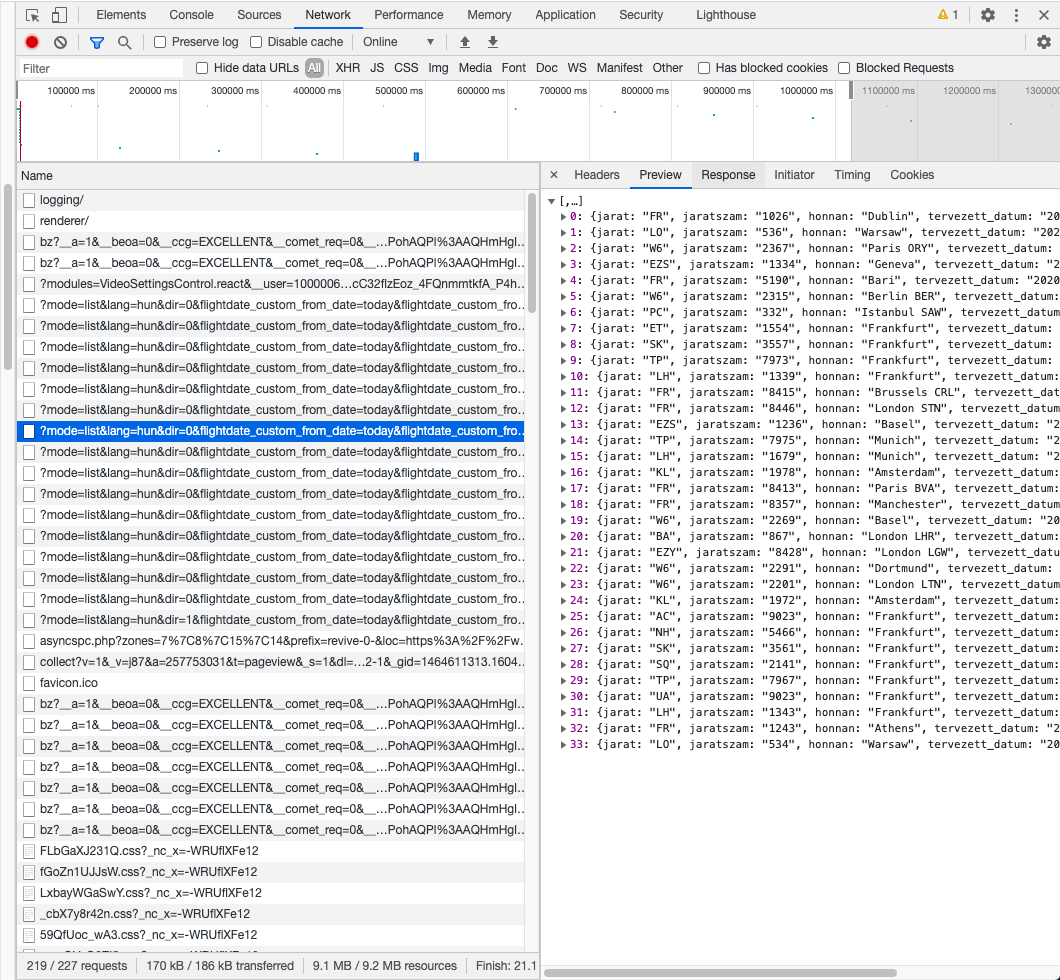
"1. Open the [website](https://www.bud.hu/indulo_jaratok), right click and go inspect. On the top bar, instead of browsing the `Elements` tab, change to `Network`. If nothing is displayed here, refresh the page. This will show you the list of network traffic that happens under the hoods. There are pictures here, JavaScript codes and a bunch of scary process that we will avoid, don't worry. You will want to order the requests by `Type`. In most of the cases, `xhr` and `document` types will be the ones we care about. If you click on one of the `xhr` types, this is what should pop up.\n",
"\n",
"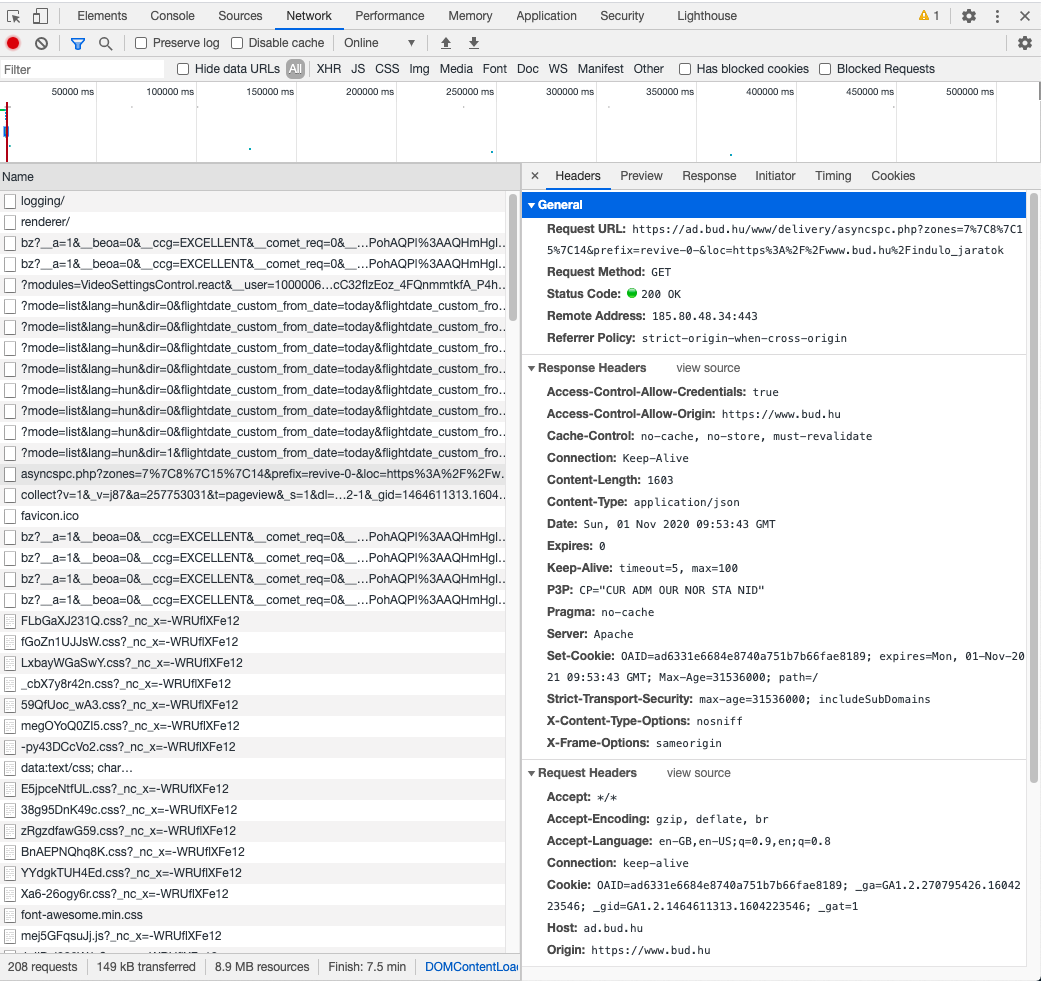\n",
"\n",
"2. The `Headers` tab shows you the input details of the request that was sent out retrieve this specific content. If you change to the `Preview` or the `Response` tabs, the result of this request will be shown to you. While clicking the former will give you a nicer and rendered look, the latter returns a raw version.\n",
"\n",
"3. Now, the task is to find the entry that returns the pieces of flights data we need. Let's check all the ones with `Type` = `xhr` first and check their `Preview` tabs to find the right one. I think we have a winner here, this looks great: \n",
"\n",
" \n",
" \n",
"4. Click on the \"play button looking\" triangle to expand an entry. Okay, this is very cool, we have it.\n",
"\n",
"5. Next, we need to find a way replicate it so that we can get the data programmatically. If only there was a way to retrieve the input data for this very request. Oh wait! This is what the `Headers` tab is there for, isn't it? It is!\n",
"\n",
"6. Now, the `Headers` tab contains details in a non-Python format (this is not entirely true, but at this point you are not assumed to have the skills needed to transform it manually).\n",
"\n",
"7. We are going to transform it with a third party service: https://curlconverter.com/\n",
"\n",
"8. We need to copy the [curl](https://en.wikipedia.org/wiki/CURL) equivalent of the request by right clicking -> Copy -> copy as curl. At this point, the curl command is copied to the keyboard. Go to https://curlconverter.com/ and paste it to the curl command box. This will generate the Python code we can use.\n",
"\n",
"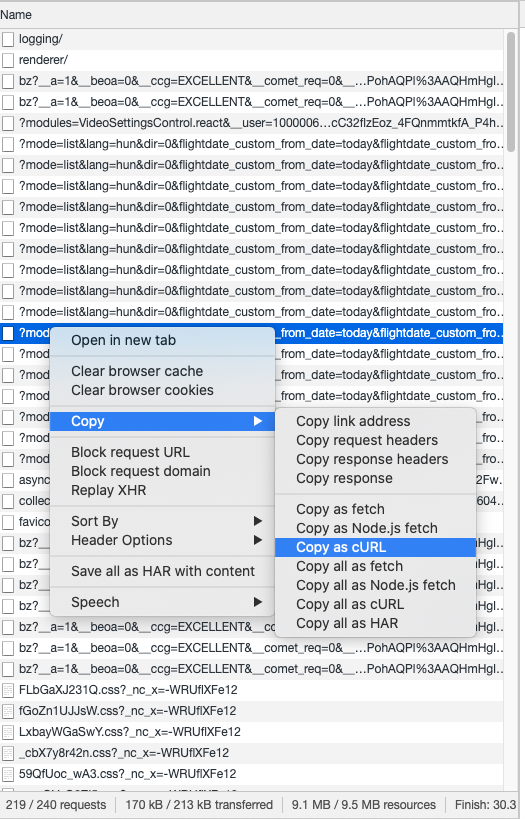\n",
"\n",
"9. You are all done :) From now in, the sucess only depends on your Python skills."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# This is the code snippet curl.trillworks.com generated to me\n",
"import requests\n",
"\n",
"cookies = {\n",
" 'CookieConsent': '{stamp:%27R1NK4ELY2atw1RqOJKczg43nUm5h/GK7hCe88Si5f7EtAD3CkHXCVQ==%27%2Cnecessary:true%2Cpreferences:false%2Cstatistics:false%2Cmarketing:false%2Cmethod:%27explicit%27%2Cver:1%2Cutc:1730656322987%2Cregion:%27hu%27}',\n",
" '_tt_enable_cookie': '1',\n",
" '_ttp': '01K92K0VKXRC2GYNZHMMJ4PYCY_.tt.1',\n",
" 'ttcsid': '1762097393286::KD2DUl6cAkGQrEc5UQlP.1.1762097393501.0',\n",
" 'ttcsid_CVIG123C77UBSQI78650': '1762097393286::URGkVXa53SoYzIxrUSOt.1.1762097393501.0',\n",
" 'XSRF-TOKEN': 'eyJpdiI6InYzMTIxREZ6U1wvTlkzSkM5cXpQU013PT0iLCJ2YWx1ZSI6IlpmSENZOXYxOVpCKzdPZld4ZFR2d0NcL1JiRHNQbnVGeWM2cDEybEhxbUhXNlwvRmpkclVDWDZBOW5FclVYR01mdTB3Q0VxKyt2dHY1eEJcL21DcjZuQndnPT0iLCJtYWMiOiJiYThiYzAwOGFhMTdhMDU0MzkzN2M5NTY2YzQ0OTk0ZWQ0MDg2ZGVkYWU0MTkwZDQwOWRhNDk0ZTAyOWZlZjAzIn0%3D',\n",
" 'budhu_session': 'eyJpdiI6IkJvVHp2TzRhT1lGMXQ1cisyT0Q4WVE9PSIsInZhbHVlIjoiZGFSUmtGVWRCMlFac0xqdjBmblozXC9vWlpmQmVGdHQ4QVpZdzd6aVUrZ2V0TVJzNHBZUnRhKzhIdGlcLzduckZcL0pOTSs4QjhnZ0dSTFwvWXVcL1MwdmszZz09IiwibWFjIjoiNDRkZTNlNjczZWRkMTk1MjM4MjdiMzgzNzlkMzc3ZWQ5YTA0NzNlYzc0ZGEzNGQ5ODdmMzE0N2RjNjExZThjMyJ9',\n",
"}\n",
"\n",
"headers = {\n",
" 'Accept': '*/*',\n",
" 'Accept-Language': 'en-US,en;q=0.9,hu;q=0.8',\n",
" 'Connection': 'keep-alive',\n",
" 'Referer': 'https://www.bud.hu/indulo_jaratok',\n",
" 'Sec-Fetch-Dest': 'empty',\n",
" 'Sec-Fetch-Mode': 'cors',\n",
" 'Sec-Fetch-Site': 'same-origin',\n",
" 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36',\n",
" 'X-Requested-With': 'XMLHttpRequest',\n",
" 'sec-ch-ua': '\"Chromium\";v=\"140\", \"Not=A?Brand\";v=\"24\", \"Google Chrome\";v=\"140\"',\n",
" 'sec-ch-ua-mobile': '?0',\n",
" 'sec-ch-ua-platform': '\"macOS\"',\n",
" # 'Cookie': 'CookieConsent={stamp:%27R1NK4ELY2atw1RqOJKczg43nUm5h/GK7hCe88Si5f7EtAD3CkHXCVQ==%27%2Cnecessary:true%2Cpreferences:false%2Cstatistics:false%2Cmarketing:false%2Cmethod:%27explicit%27%2Cver:1%2Cutc:1730656322987%2Cregion:%27hu%27}; _tt_enable_cookie=1; _ttp=01K92K0VKXRC2GYNZHMMJ4PYCY_.tt.1; ttcsid=1762097393286::KD2DUl6cAkGQrEc5UQlP.1.1762097393501.0; ttcsid_CVIG123C77UBSQI78650=1762097393286::URGkVXa53SoYzIxrUSOt.1.1762097393501.0; XSRF-TOKEN=eyJpdiI6InYzMTIxREZ6U1wvTlkzSkM5cXpQU013PT0iLCJ2YWx1ZSI6IlpmSENZOXYxOVpCKzdPZld4ZFR2d0NcL1JiRHNQbnVGeWM2cDEybEhxbUhXNlwvRmpkclVDWDZBOW5FclVYR01mdTB3Q0VxKyt2dHY1eEJcL21DcjZuQndnPT0iLCJtYWMiOiJiYThiYzAwOGFhMTdhMDU0MzkzN2M5NTY2YzQ0OTk0ZWQ0MDg2ZGVkYWU0MTkwZDQwOWRhNDk0ZTAyOWZlZjAzIn0%3D; budhu_session=eyJpdiI6IkJvVHp2TzRhT1lGMXQ1cisyT0Q4WVE9PSIsInZhbHVlIjoiZGFSUmtGVWRCMlFac0xqdjBmblozXC9vWlpmQmVGdHQ4QVpZdzd6aVUrZ2V0TVJzNHBZUnRhKzhIdGlcLzduckZcL0pOTSs4QjhnZ0dSTFwvWXVcL1MwdmszZz09IiwibWFjIjoiNDRkZTNlNjczZWRkMTk1MjM4MjdiMzgzNzlkMzc3ZWQ5YTA0NzNlYzc0ZGEzNGQ5ODdmMzE0N2RjNjExZThjMyJ9',\n",
"}\n",
"\n",
"response = requests.get(\n",
" 'https://www.bud.hu/api/ajaxFlights/?mode=list&lang=hun&dir=1&flightdate_custom_from_date=today&flightdate_custom_from_time=16:00',\n",
" cookies=cookies,\n",
" headers=headers,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Always check the status code!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.status_code"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Remember, 200 is great, means success. It is usually the case, that you do not need to include cookies in the request. Just saying, but up to you."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = requests.get('https://www.bud.hu/api/ajaxFlights/'\n",
" '?mode=list'\n",
" '&lang=hun'\n",
" '&dir=1'\n",
" '&flightdate_custom_from_date=today'\n",
" '&flightdate_custom_from_time=01:00',\n",
" headers=headers) # deleted cookies from here\n",
"response.status_code"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, as the response is a JSON file, we don't need to parse it with `BeautifulSoup`, just simply convert it to a variable. If you are not familiar with the format JSON, just think of it as a Python dictionary or a list of dictionaries."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data = response.json() # interpreting it as JSON\n",
"type(data) # result object is a list this time"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As there is no documentation in what format data are coming, we need to uncover the pattern. But relax, it is usually not very handy. First, have a look at the first item of the list."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data[0] # First item of the list, a dictionary"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This will probably be a list of dictionaries, each item containing pieces of information on one spicific departing flight. Hurray!!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Let's do some...\n",
"\n",
" \n",
"
\n",
"
\n",
"\n",
"### Cool library of the week: tqdm\n",
"\n",
"#### A progressbar to follow the progress of your computation\n",
"\n",
"- Install it with:\n",
" ```bash\n",
" pip install tqdm\n",
" ```\n",
"\n",
"- import and try it!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from tqdm import tqdm"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for i in tqdm(range(100)):\n",
" time.sleep(.01)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- Let's use it with the LOTR example"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests\n",
"from bs4 import BeautifulSoup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import nltk\n",
"\n",
"base_url ='https://github.com/ganesh-k13/shell/raw/refs/heads/master/test_search/www.glozman.com/TextPages/{book}'\n",
"book_names = {\n",
" 1: '01%20-%20The%20Fellowship%20Of%20The%20Ring.txt',\n",
" 2: '02%20-%20The%20Two%20Towers.txt',\n",
" 3: '03%20-%20The%20Return%20Of%20The%20King.txt',\n",
"} \n",
"LOTR = requests.get(base_url.format(book=book_names[1])).text\n",
"LOTR = BeautifulSoup(LOTR, \"html.parser\").getText()\n",
"\n",
"def needed(token):\n",
" stopword = token not in nltk.corpus.stopwords.words('english')\n",
" number = not token.isnumeric()\n",
" length = len(token) > 1 # can be 2 as well\n",
" return stopword and number and length"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tokens = filter(needed, tqdm(nltk.word_tokenize(LOTR.lower())))\n",
"\n",
"wordcount = nltk.FreqDist(tokens)\n",
"wordcount.most_common(25)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"----\n",
"\n",
"Back to more...\n",
"\n",
"#### Exercise III: Let's hack the system!\n",
"
\n",
" Change the parameters so that:\n",
" \n",
" - Instead of today, it will return flights from the day before (that is, yesterday). \n",
" - Instead of departing flights, it will return the arrivals.\n",
" - Instead of showing flights after 10.30 AM, it will return all the flights that day.\n",
" \n",
"__Warning #3:__ Note, that every single website has different API and hence parameters. What we are doing is specific to [bud.hu](https://www.bud.hu/). When scraping another website, you need to uncover the parameter space and find the possibilities you have."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"custom_params = {} # FILL this out\n",
"\n",
"response = requests.get('https://www.bud.hu/api/ajaxFlights/', headers=headers, params=custom_params)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Check your result here\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Exercise IV: More flying with Wizz\n",
"\n",
"- Go to the [fare finder](https://wizzair.com/en-gb/flights/fare-finder#/) page of wizzair.\n",
"- Pick an origin and a destination (make sure you choose something that they operate a flight on). Budapest/London surely works.\n",
"- Get the dates and prices for a given month.\n",
"- Start messing with the input parameters to find out their meanings.\n",
"\n",
"__Extra:__ Functionise it!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Exercise V: Vote counting\n",
"\n",
"- Go to [this](https://www.valasztas.hu/ogy2018) page which contains data on the 2018 parliamentary elections in Hungary. Wait for the regional map load, it takes some seconds. \n",
"- Then scrape all the data for a given sub-region (e.g _Veszprém megye 3. számú OEVK (székhely: Tapolca)_).\n",
"\n",
"__Extra:__ Iterate over every single sub-region to collect all the pieces of data for the whole of the country. This way you would get the whole dataset of the election in just a couple of lines of code. Cool, huhh?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "szisz_python_2025_automn",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.13.7"
}
},
"nbformat": 4,
"nbformat_minor": 2
}