{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Mapreduce with bash \n",
"\n",
"In this notebook we're going to use `bash` to write a mapper and a reducer to count words in a file. This example will serve to illustrate the main features of Hadoop's MapReduce framework."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Table of contents\n",
"- [What is MapReduce?](#mapreduce)\n",
"- [The mapper](#mapper)\n",
" - [Test the mapper](#testmapper)\n",
"- [Hadoop it up](#hadoop)\n",
" - [What is Hadoop Streaming?](#hadoopstreaming)\n",
" - [List your Hadoop directory](#hdfs_ls)\n",
" - [Test MapReduce with a dummy reducer](#dummyreducer)\n",
" - [Shuffling and sorting](#shuffling&sorting)\n",
"- [The reducer](#reducer)\n",
" - [Test and run](#run)\n",
"- [Run a mapreduce job with more data](#moredata)\n",
" - [Sort the output with `sort`](#sortoutput)\n",
" - [Sort the output with another MapReduce job](#sortoutputMR)\n",
" - [Configure sort with `KeyFieldBasedComparator`](#KeyFieldBasedComparator)\n",
" - [Specifying Configuration Variables with the -D Option](#configuration_variables)\n",
" - [What is word count useful for?](#wordcount)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## What is MapReduce? \n",
"\n",
"MapReduce is a computing paradigm designed to allow parallel distributed processing of massive amounts of data.\n",
"\n",
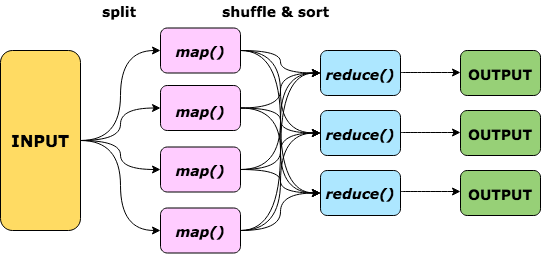
"Data is split across several computer nodes, there it is processed by one or more mappers. The results emitted by the mappers are first sorted and then passed to one or more reducers that process and combine the data to return the final result.\n",
"\n",
"",
"\n",
"With [Hadoop Streaming](https://hadoop.apache.org/docs/current/hadoop-streaming/HadoopStreaming.html) it is possible to use any programming language to define a mapper and/or a reducer. Here we're going to use the Unix `bash` scripting language ([here](https://www.gnu.org/software/bash/manual/html_node/index.html) is the official documentation for the language)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The mapper \n",
"Let's write a mapper script called `map.sh`. The mapper splits each input line into words and for each word it outputs a line containing the word and `1` separated by a tab.\n",
"\n",
"Example: for the input \n",
"\n",
"\n",
"apple orange\n",
"banana apple peach\n",
"\n",
"\n",
"\n",
"`map.sh` outputs:\n",
"\n",
"\n",
"apple 1\n",
"orange 1\n",
"banana 1\n",
"apple 1\n",
"peach 1\n",
"\n",
"\n",
"\n",
"\n",
"The _cell magic_ [`%%writefile`](https://ipython.readthedocs.io/en/stable/interactive/magics.html#cellmagic-writefile) allows us to write the contents of the cell to a file."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Overwriting map.sh\n"
]
}
],
"source": [
"%%writefile map.sh\n",
"#!/bin/bash\n",
"\n",
"while read line\n",
"do\n",
" for word in $line \n",
" do\n",
" if [ -n \"$word\" ] \n",
" then\n",
" echo -e ${word}\"\\t1\"\n",
" fi\n",
" done\n",
"done"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After running the cell above, you should have a new file `map.sh` in your current directory. \n",
"The file can be seen in the left panel of JupyterLab or by using a list command on the bash command-line.\n",
"\n",
"**Note:** you can execute a single bash command in a Jupyter notebook cell by prepending an exclamation point to the command."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-rwx------ 1 datalab hadoopusers 126 Nov 18 08:49 map.sh\n"
]
}
],
"source": [
"!ls -hl map.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test the mapper \n",
"We're going to test the mapper on on the command line with a small text file `fruits.txt` by first creating the text file.\n",
"In this file `apple` for instance appears two times, that's what we want our mapreduce job to compute."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Overwriting fruits.txt\n"
]
}
],
"source": [
"%%writefile fruits.txt\n",
"apple banana\n",
"peach orange peach peach\n",
"pineapple peach apple"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"apple banana\n",
"peach orange peach peach\n",
"pineapple peach apple\n"
]
}
],
"source": [
"!cat fruits.txt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Test the mapper"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"apple\t1\n",
"banana\t1\n",
"peach\t1\n",
"orange\t1\n",
"peach\t1\n",
"peach\t1\n",
"pineapple\t1\n",
"peach\t1\n",
"apple\t1\n"
]
}
],
"source": [
"!cat fruits.txt|./map.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If the script `map.sh` does not have the executable bit set, you need to set the correct permissions."
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"!chmod 700 map.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Hadoop it up \n",
"Let us now run a MapReduce job with Hadoop Streaming. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### What is Hadoop Streaming \n",
"\n",
"Hadoop Streaming is a library included in the Hadoop distribution that enables you to develop MapReduce executables in languages other than Java. \n",
"\n",
"Mapper and/or reducer can be any sort of executables that read the input from stdin and emit the output to stdout. By default, input is read line by line and the prefix of a line up to the first tab character is the key; the rest of the line (excluding the tab character) will be the value.\n",
"\n",
"If there is no tab character in the line, then the entire line is considered as key and the value is null. The default input format is specified in the class `TextInputFormat` (see the [API documentation](https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapred/TextInputFormat.html)) but this can can be customized for instance by defining another field separator (see the [Hadoop Streaming documentation](https://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html#Customizing_How_Lines_are_Split_into_KeyValue_Pairs).\n",
"\n",
"This is an example of MapReduce streaming invocation syntax:\n",
"\n",
"\n",
" mapred streaming \\\n",
" -input myInputDirs \\\n",
" -output myOutputDir \\\n",
" -mapper /bin/cat \\\n",
" -reducer /usr/bin/wc\n",
"\n",
"\n",
"\n",
"\n",
"You can find the full official documentation for Hadoop Streaming from Apache Hadoop here: [https://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html](https://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html).\n",
"\n",
"All options for the Hadoop Streaming command are described here: [Streaming Command Options](https://hadoop.apache.org/docs/current/hadoop-streaming/HadoopStreaming.html#Streaming_Command_Options) and can be listed with the command"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Usage: $HADOOP_HOME/bin/hadoop jar hadoop-streaming.jar [options]\n",
"Options:\n",
" -input DFS input file(s) for the Map step.\n",
" -output DFS output directory for the Reduce step.\n",
" -mapper Optional. Command to be run as mapper.\n",
" -combiner Optional. Command to be run as combiner.\n",
" -reducer Optional. Command to be run as reducer.\n",
" -file Optional. File/dir to be shipped in the Job jar file.\n",
" Deprecated. Use generic option \"-files\" instead.\n",
" -inputformat \n",
" Optional. The input format class.\n",
" -outputformat \n",
" Optional. The output format class.\n",
" -partitioner Optional. The partitioner class.\n",
" -numReduceTasks Optional. Number of reduce tasks.\n",
" -inputreader Optional. Input recordreader spec.\n",
" -cmdenv = Optional. Pass env.var to streaming commands.\n",
" -mapdebug Optional. To run this script when a map task fails.\n",
" -reducedebug Optional. To run this script when a reduce task fails.\n",
" -io Optional. Format to use for input to and output\n",
" from mapper/reducer commands\n",
" -lazyOutput Optional. Lazily create Output.\n",
" -background Optional. Submit the job and don't wait till it completes.\n",
" -verbose Optional. Print verbose output.\n",
" -info Optional. Print detailed usage.\n",
" -help Optional. Print help message.\n",
"\n",
"Generic options supported are:\n",
"-conf specify an application configuration file\n",
"-D define a value for a given property\n",
"-fs specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.\n",
"-jt specify a ResourceManager\n",
"-files specify a comma-separated list of files to be copied to the map reduce cluster\n",
"-libjars specify a comma-separated list of jar files to be included in the classpath\n",
"-archives specify a comma-separated list of archives to be unarchived on the compute machines\n",
"\n",
"The general command line syntax is:\n",
"command [genericOptions] [commandOptions]\n",
"\n",
"\n",
"For more details about these options:\n",
"Use $HADOOP_HOME/bin/hadoop jar hadoop-streaming.jar -info\n"
]
}
],
"source": [
"!mapred streaming --help"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now in order to run a mapreduce job that we need to \"upload\" the input file to the Hadoop file system."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### List your Hadoop directory \n",
"\n",
"With the command `hdfs dfs -l` you can view the content of your HDFS home directory. \n",
"\n",
"`hdfs dfs` you can run a filesystem command on the Hadoop fileystem. The complete list of commands can be found in the [System Shell Guide](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#dfs)."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Found 8 items\n",
"drwx------ - datalab supergroup 0 2019-11-18 08:34 .Trash\n",
"drwxr-xr-x - datalab supergroup 0 2019-11-17 20:56 .sparkStaging\n",
"drwx------ - datalab supergroup 0 2019-11-18 08:49 .staging\n",
"-rw-r--r-- 3 datalab supergroup 2623070 2019-11-17 20:53 FME_BaumdatenBearbeitet_OGD_20190205.csv\n",
"drwxr-xr-x - datalab supergroup 0 2019-11-16 12:14 data\n",
"drwxr-xr-x - datalab supergroup 0 2019-11-13 17:26 test\n",
"-rw-r--r-- 3 datalab supergroup 71041024 2019-11-15 11:50 wiki_sample._COPYING_\n",
"drwxr-xr-x - datalab supergroup 0 2019-11-18 08:49 wordcount\n"
]
}
],
"source": [
"!hdfs dfs -ls "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now create a directory `wordcount` with a subdirectory `input` on the Hadoop filesystem."
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"hdfs dfs -mkdir -p wordcount"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Copy the file fruits.txt to Hadoop in the folder `wordcount/input`.\n",
"\n",
"Why do we need this step? Because the file `fruits.txt` needs to reside on the Hadoop filesystem in order to enjoy of all of the features of Hadoop (data partitioning, distributed processing, fault tolerance). "
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"hdfs dfs -rm -r wordcount/input 2>/dev/null\n",
"hdfs dfs -mkdir wordcount/input\n",
"hdfs dfs -put fruits.txt wordcount/input"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's check if the file is there now.\n",
"\n",
"**Note:** it is convenient use the option `-h` for `ls` to show file sizes in human-readable form (showing sizes in Kilobytes, Megabytes, Gigabytes, etc.)"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-rw-r--r-- 3 datalab supergroup 60 2019-11-18 08:49 wordcount/input/fruits.txt\n"
]
}
],
"source": [
"!hdfs dfs -ls -h -R wordcount/input"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test MapReduce with a dummy reducer \n",
"\n",
"Let's try to run the mapper using a dummy reducer (`/bin/cat` does nothing else than echoing the data it receives).\n",
"\n",
"**Warning:** mapreduce tends to produce a verbose output, so be ready to see a long output. What you should look for is a message of the kind \"INFO mapreduce.Job: Job ... completed successfully\"
\n",
"\n",
"**Note:** at the beginning of next cell you'll see a command `hadoop fs -rmr wordcount/output 2>/dev/null`. This is needed because when you run a job several times mapreduce will give an error if you try to overwrite the same output directory."
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"packageJobJar: [] [/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars/hadoop-streaming-3.0.0-cdh6.3.0.jar] /tmp/streamjob6050042463478216172.jar tmpDir=null\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"19/11/18 08:49:53 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm472\n",
"19/11/18 08:49:53 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/datalab/.staging/job_1571899345744_0251\n",
"19/11/18 08:49:53 INFO mapred.FileInputFormat: Total input files to process : 1\n",
"19/11/18 08:49:54 INFO mapreduce.JobSubmitter: number of splits:2\n",
"19/11/18 08:49:54 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address\n",
"19/11/18 08:49:54 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled\n",
"19/11/18 08:49:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1571899345744_0251\n",
"19/11/18 08:49:54 INFO mapreduce.JobSubmitter: Executing with tokens: []\n",
"19/11/18 08:49:54 INFO conf.Configuration: resource-types.xml not found\n",
"19/11/18 08:49:54 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.\n",
"19/11/18 08:49:54 INFO impl.YarnClientImpl: Submitted application application_1571899345744_0251\n",
"19/11/18 08:49:54 INFO mapreduce.Job: The url to track the job: http://c101.local:8088/proxy/application_1571899345744_0251/\n",
"19/11/18 08:49:54 INFO mapreduce.Job: Running job: job_1571899345744_0251\n",
"19/11/18 08:50:03 INFO mapreduce.Job: Job job_1571899345744_0251 running in uber mode : false\n",
"19/11/18 08:50:03 INFO mapreduce.Job: map 0% reduce 0%\n",
"19/11/18 08:50:09 INFO mapreduce.Job: map 100% reduce 0%\n",
"19/11/18 08:50:14 INFO mapreduce.Job: map 100% reduce 100%\n",
"19/11/18 08:50:15 INFO mapreduce.Job: Job job_1571899345744_0251 completed successfully\n",
"19/11/18 08:50:15 INFO mapreduce.Job: Counters: 54\n",
"\tFile System Counters\n",
"\t\tFILE: Number of bytes read=79\n",
"\t\tFILE: Number of bytes written=687174\n",
"\t\tFILE: Number of read operations=0\n",
"\t\tFILE: Number of large read operations=0\n",
"\t\tFILE: Number of write operations=0\n",
"\t\tHDFS: Number of bytes read=312\n",
"\t\tHDFS: Number of bytes written=78\n",
"\t\tHDFS: Number of read operations=11\n",
"\t\tHDFS: Number of large read operations=0\n",
"\t\tHDFS: Number of write operations=2\n",
"\t\tHDFS: Number of bytes read erasure-coded=0\n",
"\tJob Counters \n",
"\t\tLaunched map tasks=2\n",
"\t\tLaunched reduce tasks=1\n",
"\t\tRack-local map tasks=2\n",
"\t\tTotal time spent by all maps in occupied slots (ms)=474032\n",
"\t\tTotal time spent by all reduces in occupied slots (ms)=140348\n",
"\t\tTotal time spent by all map tasks (ms)=9116\n",
"\t\tTotal time spent by all reduce tasks (ms)=2699\n",
"\t\tTotal vcore-milliseconds taken by all map tasks=9116\n",
"\t\tTotal vcore-milliseconds taken by all reduce tasks=2699\n",
"\t\tTotal megabyte-milliseconds taken by all map tasks=46673920\n",
"\t\tTotal megabyte-milliseconds taken by all reduce tasks=13818880\n",
"\tMap-Reduce Framework\n",
"\t\tMap input records=3\n",
"\t\tMap output records=9\n",
"\t\tMap output bytes=78\n",
"\t\tMap output materialized bytes=108\n",
"\t\tInput split bytes=222\n",
"\t\tCombine input records=0\n",
"\t\tCombine output records=0\n",
"\t\tReduce input groups=5\n",
"\t\tReduce shuffle bytes=108\n",
"\t\tReduce input records=9\n",
"\t\tReduce output records=9\n",
"\t\tSpilled Records=18\n",
"\t\tShuffled Maps =2\n",
"\t\tFailed Shuffles=0\n",
"\t\tMerged Map outputs=2\n",
"\t\tGC time elapsed (ms)=139\n",
"\t\tCPU time spent (ms)=2630\n",
"\t\tPhysical memory (bytes) snapshot=1531457536\n",
"\t\tVirtual memory (bytes) snapshot=18885754880\n",
"\t\tTotal committed heap usage (bytes)=4521459712\n",
"\t\tPeak Map Physical memory (bytes)=571957248\n",
"\t\tPeak Map Virtual memory (bytes)=6292967424\n",
"\t\tPeak Reduce Physical memory (bytes)=388386816\n",
"\t\tPeak Reduce Virtual memory (bytes)=6301384704\n",
"\tShuffle Errors\n",
"\t\tBAD_ID=0\n",
"\t\tCONNECTION=0\n",
"\t\tIO_ERROR=0\n",
"\t\tWRONG_LENGTH=0\n",
"\t\tWRONG_MAP=0\n",
"\t\tWRONG_REDUCE=0\n",
"\tFile Input Format Counters \n",
"\t\tBytes Read=90\n",
"\tFile Output Format Counters \n",
"\t\tBytes Written=78\n",
"19/11/18 08:50:15 INFO streaming.StreamJob: Output directory: wordcount/output\n"
]
}
],
"source": [
"%%bash\n",
"hdfs dfs -rm -r wordcount/output 2>/dev/null\n",
"mapred streaming \\\n",
" -files map.sh \\\n",
" -input wordcount/input \\\n",
" -output wordcount/output \\\n",
" -mapper map.sh \\\n",
" -reducer /bin/cat"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The output of the mapreduce job is in the `output` subfolder of the input directory. Let's check what's inside it."
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Found 2 items\n",
"-rw-r--r-- 3 datalab supergroup 0 2019-11-18 08:50 wordcount/output/_SUCCESS\n",
"-rw-r--r-- 3 datalab supergroup 78 2019-11-18 08:50 wordcount/output/part-00000\n"
]
}
],
"source": [
"!hdfs dfs -ls wordcount/output"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If `output` contains a file named `_SUCCESS` that means that the mapreduce job completed successfully.\n",
"\n",
"**Note:** when dealing with Big Data it's always advisable to pipe the output of `cat` commands to `head` (or `tail`)."
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"apple\t1\n",
"apple\t1\n",
"banana\t1\n",
"orange\t1\n",
"peach\t1\n",
"peach\t1\n",
"peach\t1\n",
"peach\t1\n",
"pineapple\t1\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output/part*|head"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We have gotten as expected all the output from the mapper. Something worth of notice is that the data outputted from the mapper _**has been sorted**_. We haven't asked for that but this step is automatically performed by the mapper as soon as the number of reducers is $\\gt 0$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Shuffling and sorting \n",
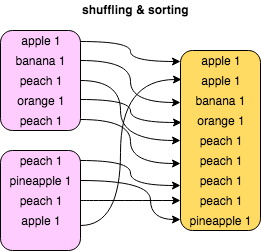
"The following picture illustrates the concept of shuffling and sorting that is automatically performed by Hadoop after each map before passing the output to reduce. In the picture the outputs of the two mapper tasks are shown. The arrows represent shuffling and sorting done before delivering the data to one reducer (rightmost box).\n",
"",
"\n",
"The shuffling and sorting phase is often one of the most costly in a MapReduce job.\n",
"\n",
"\n",
"Note: the job ran with two mappers because $2$ is the default number of mappers in Hadoop. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The reducer \n",
"Let's now write a reducer script called `reduce.sh`. "
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Overwriting reduce.sh\n"
]
}
],
"source": [
"%%writefile reduce.sh\n",
"#!/bin/bash\n",
"\n",
"currkey=\"\"\n",
"currcount=0\n",
"while IFS=$'\\t' read -r key val\n",
"do\n",
" if [[ $key == $currkey ]]\n",
" then\n",
" currcount=$(( currcount + val ))\n",
" else\n",
" if [ -n \"$currkey\" ]\n",
" then\n",
" echo -e ${currkey} \"\\t\" ${currcount} \n",
" fi\n",
" currkey=$key\n",
" currcount=1\n",
" fi\n",
"done\n",
"# last one\n",
"echo -e ${currkey} \"\\t\" ${currcount}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set permission for the reducer script."
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [],
"source": [
"!chmod 700 reduce.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test and run \n",
"\n",
"Test map and reduce on the shell"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"apple \t 2\n",
"banana \t 1\n",
"orange \t 1\n",
"peach \t 4\n",
"pineapple \t 1\n"
]
}
],
"source": [
"!cat fruits.txt|./map.sh|sort|./reduce.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Once we've made sure that the reducer script runs correctly on the shell, we can run it on the cluster."
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"packageJobJar: [map.sh, reduce.sh] [/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars/hadoop-streaming-3.0.0-cdh6.3.0.jar] /tmp/streamjob4511756596880012363.jar tmpDir=null\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"19/11/18 08:50:23 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.\n",
"19/11/18 08:50:25 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm472\n",
"19/11/18 08:50:25 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/datalab/.staging/job_1571899345744_0252\n",
"19/11/18 08:50:26 INFO mapred.FileInputFormat: Total input files to process : 1\n",
"19/11/18 08:50:26 INFO mapreduce.JobSubmitter: number of splits:2\n",
"19/11/18 08:50:26 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address\n",
"19/11/18 08:50:26 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled\n",
"19/11/18 08:50:26 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1571899345744_0252\n",
"19/11/18 08:50:26 INFO mapreduce.JobSubmitter: Executing with tokens: []\n",
"19/11/18 08:50:26 INFO conf.Configuration: resource-types.xml not found\n",
"19/11/18 08:50:26 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.\n",
"19/11/18 08:50:26 INFO impl.YarnClientImpl: Submitted application application_1571899345744_0252\n",
"19/11/18 08:50:26 INFO mapreduce.Job: The url to track the job: http://c101.local:8088/proxy/application_1571899345744_0252/\n",
"19/11/18 08:50:26 INFO mapreduce.Job: Running job: job_1571899345744_0252\n",
"19/11/18 08:50:36 INFO mapreduce.Job: Job job_1571899345744_0252 running in uber mode : false\n",
"19/11/18 08:50:36 INFO mapreduce.Job: map 0% reduce 0%\n",
"19/11/18 08:50:43 INFO mapreduce.Job: map 100% reduce 0%\n",
"19/11/18 08:50:49 INFO mapreduce.Job: map 100% reduce 100%\n",
"19/11/18 08:50:50 INFO mapreduce.Job: Job job_1571899345744_0252 completed successfully\n",
"19/11/18 08:50:50 INFO mapreduce.Job: Counters: 54\n",
"\tFile System Counters\n",
"\t\tFILE: Number of bytes read=79\n",
"\t\tFILE: Number of bytes written=687864\n",
"\t\tFILE: Number of read operations=0\n",
"\t\tFILE: Number of large read operations=0\n",
"\t\tFILE: Number of write operations=0\n",
"\t\tHDFS: Number of bytes read=312\n",
"\t\tHDFS: Number of bytes written=56\n",
"\t\tHDFS: Number of read operations=11\n",
"\t\tHDFS: Number of large read operations=0\n",
"\t\tHDFS: Number of write operations=2\n",
"\t\tHDFS: Number of bytes read erasure-coded=0\n",
"\tJob Counters \n",
"\t\tLaunched map tasks=2\n",
"\t\tLaunched reduce tasks=1\n",
"\t\tRack-local map tasks=2\n",
"\t\tTotal time spent by all maps in occupied slots (ms)=484692\n",
"\t\tTotal time spent by all reduces in occupied slots (ms)=241904\n",
"\t\tTotal time spent by all map tasks (ms)=9321\n",
"\t\tTotal time spent by all reduce tasks (ms)=4652\n",
"\t\tTotal vcore-milliseconds taken by all map tasks=9321\n",
"\t\tTotal vcore-milliseconds taken by all reduce tasks=4652\n",
"\t\tTotal megabyte-milliseconds taken by all map tasks=47723520\n",
"\t\tTotal megabyte-milliseconds taken by all reduce tasks=23818240\n",
"\tMap-Reduce Framework\n",
"\t\tMap input records=3\n",
"\t\tMap output records=9\n",
"\t\tMap output bytes=78\n",
"\t\tMap output materialized bytes=108\n",
"\t\tInput split bytes=222\n",
"\t\tCombine input records=0\n",
"\t\tCombine output records=0\n",
"\t\tReduce input groups=5\n",
"\t\tReduce shuffle bytes=108\n",
"\t\tReduce input records=9\n",
"\t\tReduce output records=5\n",
"\t\tSpilled Records=18\n",
"\t\tShuffled Maps =2\n",
"\t\tFailed Shuffles=0\n",
"\t\tMerged Map outputs=2\n",
"\t\tGC time elapsed (ms)=158\n",
"\t\tCPU time spent (ms)=2550\n",
"\t\tPhysical memory (bytes) snapshot=1526378496\n",
"\t\tVirtual memory (bytes) snapshot=18883096576\n",
"\t\tTotal committed heap usage (bytes)=4490002432\n",
"\t\tPeak Map Physical memory (bytes)=580694016\n",
"\t\tPeak Map Virtual memory (bytes)=6292299776\n",
"\t\tPeak Reduce Physical memory (bytes)=368877568\n",
"\t\tPeak Reduce Virtual memory (bytes)=6298894336\n",
"\tShuffle Errors\n",
"\t\tBAD_ID=0\n",
"\t\tCONNECTION=0\n",
"\t\tIO_ERROR=0\n",
"\t\tWRONG_LENGTH=0\n",
"\t\tWRONG_MAP=0\n",
"\t\tWRONG_REDUCE=0\n",
"\tFile Input Format Counters \n",
"\t\tBytes Read=90\n",
"\tFile Output Format Counters \n",
"\t\tBytes Written=56\n",
"19/11/18 08:50:50 INFO streaming.StreamJob: Output directory: wordcount/output\n"
]
}
],
"source": [
"%%bash\n",
"hdfs dfs -rm -r wordcount/output 2>/dev/null\n",
"mapred streaming \\\n",
" -file map.sh \\\n",
" -file reduce.sh \\\n",
" -input wordcount/input \\\n",
" -output wordcount/output \\\n",
" -mapper map.sh \\\n",
" -reducer reduce.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's check the output on the HDFS filesystem"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"apple \t 2\n",
"banana \t 1\n",
"orange \t 1\n",
"peach \t 4\n",
"pineapple \t 1\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output/part*|head"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Run a mapreduce job with more data \n",
"\n",
"Let's create a datafile by downloading some real data, for instance from a Web page. This example will be used to introduce some advanced configurations.\n",
"\n",
"Next, we download a URL with `wget` and filter out HTML tags with a `sed` regular expression."
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"URL=https://www.derstandard.at/story/2000110819049/und-wo-warst-du-beim-fall-der-mauer\n",
"wget -qO- $URL | sed -e 's/<[^>]*>//g;s/^ //g' >sample_article.txt"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\t1\n",
"\t1\n",
"\t1\n",
"\t1\n",
"Und\t1\n",
"wo\t1\n",
"warst\t1\n",
"du\t1\n",
"beim\t1\n",
"Fall\t1\n"
]
}
],
"source": [
"!cat sample_article.txt|./map.sh|head"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As usual, with real data there's some more work to do. Here we see that the mapper script doesn't skip empty lines. Let's modify it so that empty lines are skipped."
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Overwriting map.sh\n"
]
}
],
"source": [
"%%writefile map.sh\n",
"#!/bin/bash\n",
"\n",
"while read line\n",
"do\n",
" for word in $line\n",
" do\n",
" if [[ \"$line\" =~ [^[:space:]] ]]\n",
" then\n",
" if [ -n \"$word\" ]\n",
" then\n",
" echo -e ${word} \"\\t1\"\n",
" fi\n",
" fi\n",
" done\n",
"done"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Und \t1\n",
"wo \t1\n",
"warst \t1\n",
"du \t1\n",
"beim \t1\n",
"Fall \t1\n",
"der \t1\n",
"Mauer? \t1\n",
"- \t1\n",
" \t1\n"
]
}
],
"source": [
"!cat sample_article.txt|./map.sh|head"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now the output of `map.sh` looks better!\n",
"\n",
"Note: when working with real data we need in general some more preprocessing in order to remove control characters or invalid unicode.\n",
"\n",
"Time to run MapReduce again with the new data, but first we need to \"put\" the data on HDFS."
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"hdfs dfs -rm -r wordcount/input 2>/dev/null\n",
"hdfs dfs -put sample_article.txt wordcount/input"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-rw-r--r-- 3 datalab supergroup 4.1 K 2019-11-18 08:50 wordcount/input\n"
]
}
],
"source": [
"# check that the folder wordcount/input on HDFS only contains sample_article.txt\n",
"!hdfs dfs -ls -h wordcount/input"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check the reducer"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Und \t 1\n",
"wo \t 1\n",
"warst \t 1\n",
"du \t 1\n",
"beim \t 1\n",
"Fall \t 1\n",
"der \t 1\n",
"Mauer? \t 1\n",
"- \t 1\n",
" \t 2\n"
]
}
],
"source": [
"!cat sample_article.txt|./map.sh|./reduce.sh|head"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"packageJobJar: [map.sh, reduce.sh] [/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars/hadoop-streaming-3.0.0-cdh6.3.0.jar] /tmp/streamjob1458624376542077747.jar tmpDir=null\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"19/11/18 08:51:03 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.\n",
"19/11/18 08:51:04 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm472\n",
"19/11/18 08:51:04 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/datalab/.staging/job_1571899345744_0253\n",
"19/11/18 08:51:05 INFO mapred.FileInputFormat: Total input files to process : 1\n",
"19/11/18 08:51:05 INFO mapreduce.JobSubmitter: number of splits:2\n",
"19/11/18 08:51:05 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address\n",
"19/11/18 08:51:05 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled\n",
"19/11/18 08:51:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1571899345744_0253\n",
"19/11/18 08:51:05 INFO mapreduce.JobSubmitter: Executing with tokens: []\n",
"19/11/18 08:51:06 INFO conf.Configuration: resource-types.xml not found\n",
"19/11/18 08:51:06 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.\n",
"19/11/18 08:51:06 INFO impl.YarnClientImpl: Submitted application application_1571899345744_0253\n",
"19/11/18 08:51:06 INFO mapreduce.Job: The url to track the job: http://c101.local:8088/proxy/application_1571899345744_0253/\n",
"19/11/18 08:51:06 INFO mapreduce.Job: Running job: job_1571899345744_0253\n",
"19/11/18 08:51:14 INFO mapreduce.Job: Job job_1571899345744_0253 running in uber mode : false\n",
"19/11/18 08:51:14 INFO mapreduce.Job: map 0% reduce 0%\n",
"19/11/18 08:51:21 INFO mapreduce.Job: map 100% reduce 0%\n",
"19/11/18 08:51:27 INFO mapreduce.Job: map 100% reduce 100%\n",
"19/11/18 08:51:28 INFO mapreduce.Job: Job job_1571899345744_0253 completed successfully\n",
"19/11/18 08:51:28 INFO mapreduce.Job: Counters: 54\n",
"\tFile System Counters\n",
"\t\tFILE: Number of bytes read=2056\n",
"\t\tFILE: Number of bytes written=691913\n",
"\t\tFILE: Number of read operations=0\n",
"\t\tFILE: Number of large read operations=0\n",
"\t\tFILE: Number of write operations=0\n",
"\t\tHDFS: Number of bytes read=6428\n",
"\t\tHDFS: Number of bytes written=2273\n",
"\t\tHDFS: Number of read operations=11\n",
"\t\tHDFS: Number of large read operations=0\n",
"\t\tHDFS: Number of write operations=2\n",
"\t\tHDFS: Number of bytes read erasure-coded=0\n",
"\tJob Counters \n",
"\t\tLaunched map tasks=2\n",
"\t\tLaunched reduce tasks=1\n",
"\t\tData-local map tasks=2\n",
"\t\tTotal time spent by all maps in occupied slots (ms)=482924\n",
"\t\tTotal time spent by all reduces in occupied slots (ms)=209040\n",
"\t\tTotal time spent by all map tasks (ms)=9287\n",
"\t\tTotal time spent by all reduce tasks (ms)=4020\n",
"\t\tTotal vcore-milliseconds taken by all map tasks=9287\n",
"\t\tTotal vcore-milliseconds taken by all reduce tasks=4020\n",
"\t\tTotal megabyte-milliseconds taken by all map tasks=47549440\n",
"\t\tTotal megabyte-milliseconds taken by all reduce tasks=20582400\n",
"\tMap-Reduce Framework\n",
"\t\tMap input records=191\n",
"\t\tMap output records=211\n",
"\t\tMap output bytes=2492\n",
"\t\tMap output materialized bytes=2180\n",
"\t\tInput split bytes=200\n",
"\t\tCombine input records=0\n",
"\t\tCombine output records=0\n",
"\t\tReduce input groups=164\n",
"\t\tReduce shuffle bytes=2180\n",
"\t\tReduce input records=211\n",
"\t\tReduce output records=164\n",
"\t\tSpilled Records=422\n",
"\t\tShuffled Maps =2\n",
"\t\tFailed Shuffles=0\n",
"\t\tMerged Map outputs=2\n",
"\t\tGC time elapsed (ms)=146\n",
"\t\tCPU time spent (ms)=2820\n",
"\t\tPhysical memory (bytes) snapshot=1466261504\n",
"\t\tVirtual memory (bytes) snapshot=18885009408\n",
"\t\tTotal committed heap usage (bytes)=4507828224\n",
"\t\tPeak Map Physical memory (bytes)=549105664\n",
"\t\tPeak Map Virtual memory (bytes)=6292787200\n",
"\t\tPeak Reduce Physical memory (bytes)=372985856\n",
"\t\tPeak Reduce Virtual memory (bytes)=6300979200\n",
"\tShuffle Errors\n",
"\t\tBAD_ID=0\n",
"\t\tCONNECTION=0\n",
"\t\tIO_ERROR=0\n",
"\t\tWRONG_LENGTH=0\n",
"\t\tWRONG_MAP=0\n",
"\t\tWRONG_REDUCE=0\n",
"\tFile Input Format Counters \n",
"\t\tBytes Read=6228\n",
"\tFile Output Format Counters \n",
"\t\tBytes Written=2273\n",
"19/11/18 08:51:28 INFO streaming.StreamJob: Output directory: wordcount/output\n"
]
}
],
"source": [
"%%bash\n",
"hadoop fs -rmr wordcount/output 2>/dev/null\n",
"mapred streaming \\\n",
" -file map.sh \\\n",
" -file reduce.sh \\\n",
" -input wordcount/input \\\n",
" -output wordcount/output \\\n",
" -mapper map.sh \\\n",
" -reducer reduce.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check the output on HDFS"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Found 2 items\n",
"-rw-r--r-- 3 datalab supergroup 0 2019-11-18 08:51 wordcount/output/_SUCCESS\n",
"-rw-r--r-- 3 datalab supergroup 2273 2019-11-18 08:51 wordcount/output/part-00000\n"
]
}
],
"source": [
"!hdfs dfs -ls wordcount/output"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This job took a few seconds and this is quite some time for such a small file (4KB). This is due to the overhead of distributing the data and running the Hadoop framework. \n",
"The advantage of Hadoop can be appreciated only for large datasets."
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"& \t 1\n",
"(Herder-Verlag) \t 1\n",
"- \t 1\n",
"/ \t 2\n",
"1950 \t 1\n",
"24 \t 1\n",
"30 \t 1\n",
"30-Jährige \t 1\n",
"\n",
"\n",
"We've obtained a list of tokens that appear in the file followed by their frequencies. \n",
"\n",
"The output of the reducer is sorted by key (the word) because that's the ordering that the reducer becomes from the mapper. If we're interested in sorting the data by frequency, we can use the Unix `sort` command (with the options `k2`, `n`, `r` respectively \"by field 2\", \"numeric\", \"reverse\")."
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"die \t 8\n",
"der \t 6\n",
"Cookies \t 4\n",
"und \t 4\n",
"derStandard.at \t 3\n",
"Fall \t 3\n",
"ich \t 3\n",
"in \t 3\n",
"kann \t 3\n",
"ohne \t 3\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output/part-00000|sort -k2nr|head"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The most common word appears to be \"die\" (the German for the definite article \"the\")."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Sort the output with another MapReduce job \n",
"\n",
"If we wanted to sort the output of the reducer using the mapreduce framework, we could employ a simple trick: create a mapper that interchanges words with their frequency values. Since by construction mappers sort their output by key, we get the desired sorting as a side-effect.\n",
"\n",
"Call the new mapper `swap_keyval.sh`."
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Overwriting swap_keyval.sh\n"
]
}
],
"source": [
"%%writefile swap_keyval.sh\n",
"#!/bin/bash\n",
"# This script will read one line at a time and swap key/value\n",
"# For instance, the line \"word 100\" will become \"100 word\"\n",
"\n",
"while read key val\n",
"do\n",
" printf \"%s\\t%s\\n\" \"$val\" \"$key\"\n",
"done "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are going to run the swap mapper script on the output of the previous mapreduce job. Note that in the below cell we are not deleting the previous output but instead we're saving the output from the current job in a new folder `output_sorted`. \n",
"\n",
"Nice thing about running a job on the output of a preceding job is that we do not need to upload files to HDFS because the data is already on HDFS. Not so nice: writing data to disk at each step of a data transformation pipeline takes time and this can be costly for longer data pipelines. This is one of the shortcomings of MapReduce that are addressed by [Apache Spark](https://spark.apache.org/)."
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"packageJobJar: [swap_keyval.sh] [/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars/hadoop-streaming-3.0.0-cdh6.3.0.jar] /tmp/streamjob8599577742606945962.jar tmpDir=null\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"19/11/18 08:51:38 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.\n",
"19/11/18 08:51:39 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm472\n",
"19/11/18 08:51:40 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/datalab/.staging/job_1571899345744_0254\n",
"19/11/18 08:51:40 INFO mapred.FileInputFormat: Total input files to process : 1\n",
"19/11/18 08:51:40 INFO mapreduce.JobSubmitter: number of splits:2\n",
"19/11/18 08:51:40 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address\n",
"19/11/18 08:51:40 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled\n",
"19/11/18 08:51:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1571899345744_0254\n",
"19/11/18 08:51:41 INFO mapreduce.JobSubmitter: Executing with tokens: []\n",
"19/11/18 08:51:41 INFO conf.Configuration: resource-types.xml not found\n",
"19/11/18 08:51:41 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.\n",
"19/11/18 08:51:41 INFO impl.YarnClientImpl: Submitted application application_1571899345744_0254\n",
"19/11/18 08:51:41 INFO mapreduce.Job: The url to track the job: http://c101.local:8088/proxy/application_1571899345744_0254/\n",
"19/11/18 08:51:41 INFO mapreduce.Job: Running job: job_1571899345744_0254\n",
"19/11/18 08:51:50 INFO mapreduce.Job: Job job_1571899345744_0254 running in uber mode : false\n",
"19/11/18 08:51:50 INFO mapreduce.Job: map 0% reduce 0%\n",
"19/11/18 08:51:56 INFO mapreduce.Job: map 100% reduce 0%\n",
"19/11/18 08:52:03 INFO mapreduce.Job: map 100% reduce 100%\n",
"19/11/18 08:52:04 INFO mapreduce.Job: Job job_1571899345744_0254 completed successfully\n",
"19/11/18 08:52:04 INFO mapreduce.Job: Counters: 54\n",
"\tFile System Counters\n",
"\t\tFILE: Number of bytes read=1833\n",
"\t\tFILE: Number of bytes written=688625\n",
"\t\tFILE: Number of read operations=0\n",
"\t\tFILE: Number of large read operations=0\n",
"\t\tFILE: Number of write operations=0\n",
"\t\tHDFS: Number of bytes read=3634\n",
"\t\tHDFS: Number of bytes written=1945\n",
"\t\tHDFS: Number of read operations=11\n",
"\t\tHDFS: Number of large read operations=0\n",
"\t\tHDFS: Number of write operations=2\n",
"\t\tHDFS: Number of bytes read erasure-coded=0\n",
"\tJob Counters \n",
"\t\tLaunched map tasks=2\n",
"\t\tLaunched reduce tasks=1\n",
"\t\tRack-local map tasks=2\n",
"\t\tTotal time spent by all maps in occupied slots (ms)=482976\n",
"\t\tTotal time spent by all reduces in occupied slots (ms)=236028\n",
"\t\tTotal time spent by all map tasks (ms)=9288\n",
"\t\tTotal time spent by all reduce tasks (ms)=4539\n",
"\t\tTotal vcore-milliseconds taken by all map tasks=9288\n",
"\t\tTotal vcore-milliseconds taken by all reduce tasks=4539\n",
"\t\tTotal megabyte-milliseconds taken by all map tasks=47554560\n",
"\t\tTotal megabyte-milliseconds taken by all reduce tasks=23239680\n",
"\tMap-Reduce Framework\n",
"\t\tMap input records=164\n",
"\t\tMap output records=164\n",
"\t\tMap output bytes=1945\n",
"\t\tMap output materialized bytes=1920\n",
"\t\tInput split bytes=224\n",
"\t\tCombine input records=0\n",
"\t\tCombine output records=0\n",
"\t\tReduce input groups=6\n",
"\t\tReduce shuffle bytes=1920\n",
"\t\tReduce input records=164\n",
"\t\tReduce output records=164\n",
"\t\tSpilled Records=328\n",
"\t\tShuffled Maps =2\n",
"\t\tFailed Shuffles=0\n",
"\t\tMerged Map outputs=2\n",
"\t\tGC time elapsed (ms)=156\n",
"\t\tCPU time spent (ms)=2570\n",
"\t\tPhysical memory (bytes) snapshot=1477533696\n",
"\t\tVirtual memory (bytes) snapshot=18889134080\n",
"\t\tTotal committed heap usage (bytes)=4451205120\n",
"\t\tPeak Map Physical memory (bytes)=558252032\n",
"\t\tPeak Map Virtual memory (bytes)=6294482944\n",
"\t\tPeak Reduce Physical memory (bytes)=372002816\n",
"\t\tPeak Reduce Virtual memory (bytes)=6301200384\n",
"\tShuffle Errors\n",
"\t\tBAD_ID=0\n",
"\t\tCONNECTION=0\n",
"\t\tIO_ERROR=0\n",
"\t\tWRONG_LENGTH=0\n",
"\t\tWRONG_MAP=0\n",
"\t\tWRONG_REDUCE=0\n",
"\tFile Input Format Counters \n",
"\t\tBytes Read=3410\n",
"\tFile Output Format Counters \n",
"\t\tBytes Written=1945\n",
"19/11/18 08:52:04 INFO streaming.StreamJob: Output directory: wordcount/output2\n"
]
}
],
"source": [
"%%bash\n",
"hdfs dfs -rm -r wordcount/output2 2>/dev/null\n",
"mapred streaming \\\n",
" -file swap_keyval.sh \\\n",
" -input wordcount/output \\\n",
" -output wordcount/output2 \\\n",
" -mapper swap_keyval.sh"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check the output on HDFS"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Found 2 items\n",
"-rw-r--r-- 3 datalab supergroup 0 2019-11-18 08:52 wordcount/output2/_SUCCESS\n",
"-rw-r--r-- 3 datalab supergroup 1945 2019-11-18 08:52 wordcount/output2/part-00000\n"
]
}
],
"source": [
"!hdfs dfs -ls wordcount/output2"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\tan\n",
"1\t–\n",
"1\tüberraschen.\n",
"1\tÜber\n",
"1\tzustimmungspflichtige\n",
"1\tzustimmen\n",
"1\tzum\n",
"1\tzu.\n",
"1\twiderrufen.\n",
"1\twerden.\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output2/part-00000|head "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Mapper uses by default ascending order to sort by key. We could have changed that with an option but for now let's look at the end of the file."
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3\tkann\n",
"3\tin\n",
"3\tderStandard.at\n",
"3\tich\n",
"3\tFall\n",
"3\tSie\n",
"4\tCookies\n",
"4\tund\n",
"6\tder\n",
"8\tdie\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output2/part-00000|tail"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Configure sort with `KeyFieldBasedComparator` \n",
"\n",
"In general, we can determine how mappers are going to sort their output by configuring the comparator directive to use the special class [`KeyFieldBasedComparator`](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/mapreduce/lib/partition/KeyFieldBasedComparator.html)\n",
"-D mapreduce.job.output.key.comparator.class=\\\n",
" org.apache.hadoop.mapred.lib.KeyFieldBasedComparator\n",
" \n",
"This class has some options similar to the Unix `sort`(`-n` to sort numerically, `-r` for reverse sorting, `-k pos1[,pos2]` for specifying fields to sort by).\n",
"\n",
"Let us see the comparator in action on our data to get the desired result. Note that this time we are removing `output2` because we're running the second mapreduce job again."
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"packageJobJar: [swap_keyval.sh] [/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars/hadoop-streaming-3.0.0-cdh6.3.0.jar] /tmp/streamjob1477140608741397366.jar tmpDir=null\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"19/11/18 08:52:14 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.\n",
"19/11/18 08:52:16 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm472\n",
"19/11/18 08:52:16 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/datalab/.staging/job_1571899345744_0255\n",
"19/11/18 08:52:16 INFO mapred.FileInputFormat: Total input files to process : 1\n",
"19/11/18 08:52:17 INFO mapreduce.JobSubmitter: number of splits:2\n",
"19/11/18 08:52:17 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address\n",
"19/11/18 08:52:17 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled\n",
"19/11/18 08:52:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1571899345744_0255\n",
"19/11/18 08:52:17 INFO mapreduce.JobSubmitter: Executing with tokens: []\n",
"19/11/18 08:52:17 INFO conf.Configuration: resource-types.xml not found\n",
"19/11/18 08:52:17 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.\n",
"19/11/18 08:52:17 INFO impl.YarnClientImpl: Submitted application application_1571899345744_0255\n",
"19/11/18 08:52:17 INFO mapreduce.Job: The url to track the job: http://c101.local:8088/proxy/application_1571899345744_0255/\n",
"19/11/18 08:52:17 INFO mapreduce.Job: Running job: job_1571899345744_0255\n",
"19/11/18 08:52:25 INFO mapreduce.Job: Job job_1571899345744_0255 running in uber mode : false\n",
"19/11/18 08:52:25 INFO mapreduce.Job: map 0% reduce 0%\n",
"19/11/18 08:52:32 INFO mapreduce.Job: map 100% reduce 0%\n",
"19/11/18 08:52:39 INFO mapreduce.Job: map 100% reduce 100%\n",
"19/11/18 08:52:40 INFO mapreduce.Job: Job job_1571899345744_0255 completed successfully\n",
"19/11/18 08:52:40 INFO mapreduce.Job: Counters: 54\n",
"\tFile System Counters\n",
"\t\tFILE: Number of bytes read=1827\n",
"\t\tFILE: Number of bytes written=689819\n",
"\t\tFILE: Number of read operations=0\n",
"\t\tFILE: Number of large read operations=0\n",
"\t\tFILE: Number of write operations=0\n",
"\t\tHDFS: Number of bytes read=3634\n",
"\t\tHDFS: Number of bytes written=1945\n",
"\t\tHDFS: Number of read operations=11\n",
"\t\tHDFS: Number of large read operations=0\n",
"\t\tHDFS: Number of write operations=2\n",
"\t\tHDFS: Number of bytes read erasure-coded=0\n",
"\tJob Counters \n",
"\t\tLaunched map tasks=2\n",
"\t\tLaunched reduce tasks=1\n",
"\t\tRack-local map tasks=2\n",
"\t\tTotal time spent by all maps in occupied slots (ms)=483288\n",
"\t\tTotal time spent by all reduces in occupied slots (ms)=238472\n",
"\t\tTotal time spent by all map tasks (ms)=9294\n",
"\t\tTotal time spent by all reduce tasks (ms)=4586\n",
"\t\tTotal vcore-milliseconds taken by all map tasks=9294\n",
"\t\tTotal vcore-milliseconds taken by all reduce tasks=4586\n",
"\t\tTotal megabyte-milliseconds taken by all map tasks=47585280\n",
"\t\tTotal megabyte-milliseconds taken by all reduce tasks=23480320\n",
"\tMap-Reduce Framework\n",
"\t\tMap input records=164\n",
"\t\tMap output records=164\n",
"\t\tMap output bytes=1945\n",
"\t\tMap output materialized bytes=1929\n",
"\t\tInput split bytes=224\n",
"\t\tCombine input records=0\n",
"\t\tCombine output records=0\n",
"\t\tReduce input groups=6\n",
"\t\tReduce shuffle bytes=1929\n",
"\t\tReduce input records=164\n",
"\t\tReduce output records=164\n",
"\t\tSpilled Records=328\n",
"\t\tShuffled Maps =2\n",
"\t\tFailed Shuffles=0\n",
"\t\tMerged Map outputs=2\n",
"\t\tGC time elapsed (ms)=163\n",
"\t\tCPU time spent (ms)=2630\n",
"\t\tPhysical memory (bytes) snapshot=1525448704\n",
"\t\tVirtual memory (bytes) snapshot=18887892992\n",
"\t\tTotal committed heap usage (bytes)=4505206784\n",
"\t\tPeak Map Physical memory (bytes)=578318336\n",
"\t\tPeak Map Virtual memory (bytes)=6292914176\n",
"\t\tPeak Reduce Physical memory (bytes)=370286592\n",
"\t\tPeak Reduce Virtual memory (bytes)=6302941184\n",
"\tShuffle Errors\n",
"\t\tBAD_ID=0\n",
"\t\tCONNECTION=0\n",
"\t\tIO_ERROR=0\n",
"\t\tWRONG_LENGTH=0\n",
"\t\tWRONG_MAP=0\n",
"\t\tWRONG_REDUCE=0\n",
"\tFile Input Format Counters \n",
"\t\tBytes Read=3410\n",
"\tFile Output Format Counters \n",
"\t\tBytes Written=1945\n",
"19/11/18 08:52:40 INFO streaming.StreamJob: Output directory: wordcount/output2\n"
]
}
],
"source": [
"%%bash\n",
"hdfs dfs -rmr wordcount/output2 2>/dev/null\n",
"comparator_class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator\n",
"mapred streaming \\\n",
" -D mapreduce.job.output.key.comparator.class=$comparator_class \\\n",
" -D mapreduce.partition.keycomparator.options=-nr \\\n",
" -file swap_keyval.sh \\\n",
" -input wordcount/output \\\n",
" -output wordcount/output2 \\\n",
" -mapper swap_keyval.sh"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Found 2 items\n",
"-rw-r--r-- 3 datalab supergroup 0 2019-11-18 08:52 wordcount/output2/_SUCCESS\n",
"-rw-r--r-- 3 datalab supergroup 1945 2019-11-18 08:52 wordcount/output2/part-00000\n"
]
}
],
"source": [
"!hdfs dfs -ls wordcount/output2"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"8\tdie\n",
"6\tder\n",
"4\tund\n",
"4\tCookies\n",
"3\tFall\n",
"3\tSie\n",
"3\tich\n",
"3\tkann\n",
"3\twarst\n",
"3\tin\n"
]
}
],
"source": [
"!hdfs dfs -cat wordcount/output2/part-00000|head "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we get the output in the desired order."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Specifying Configuration Variables with the -D Option \n",
"\n",
"With the `-D` option it is possible to override options set in the default configuration file [`mapred_default.xml`](https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml)\n",
"(see the [Apache Hadoop documentation](https://hadoop.apache.org/docs/current/hadoop-streaming/HadoopStreaming.html#Specifying_Configuration_Variables_with_the_-D_Option)).\n",
"\n",
"One option that might come handy when dealing with out-of-memory issues in the sorting phase is the size in MB of the memory reserved for sorting `mapreduce.task.io.sort.mb`:\n",
" \n",
" -D mapreduce.task.io.sort.mb=512\n",
" \n",
" \n",
"\n",
" **Note:** the maximum value for `mapreduce.task.io.sort.mb` is 2047. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## What is word count useful for? \n",
"Counting the frequencies of words is at the basis of _indexing_ and it facilitates the retrieval of relevant documents in search engines."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 2
}